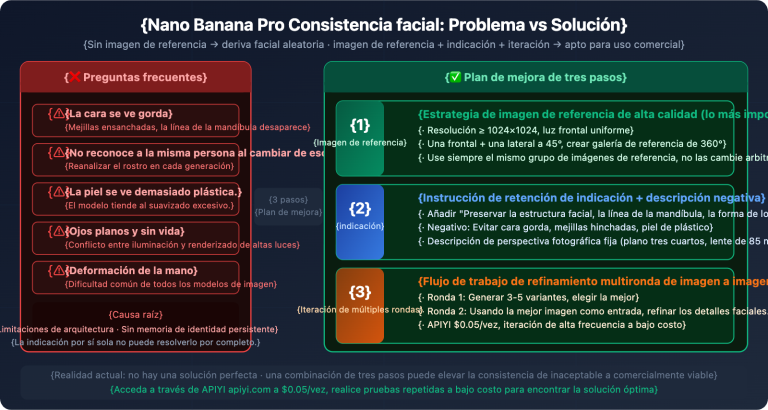
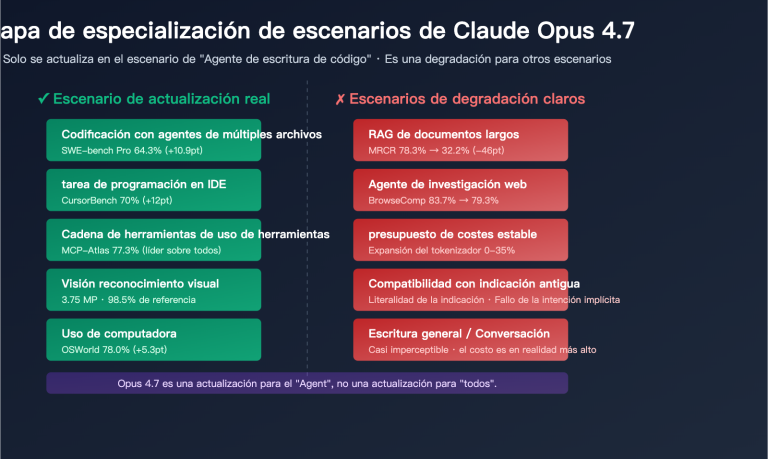
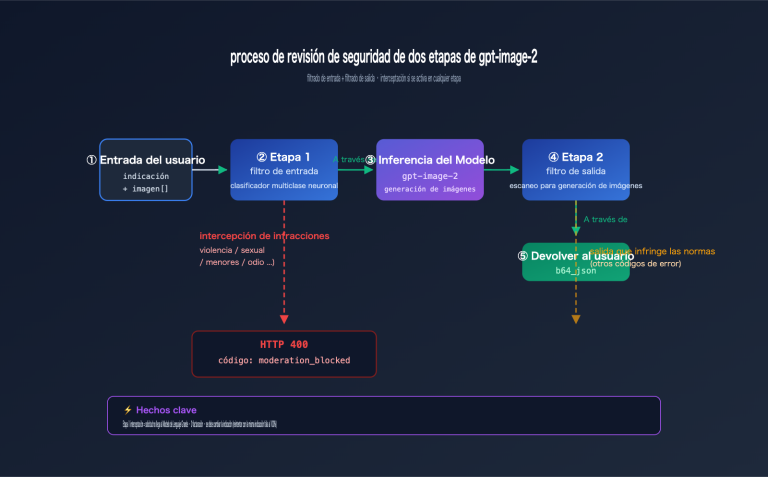
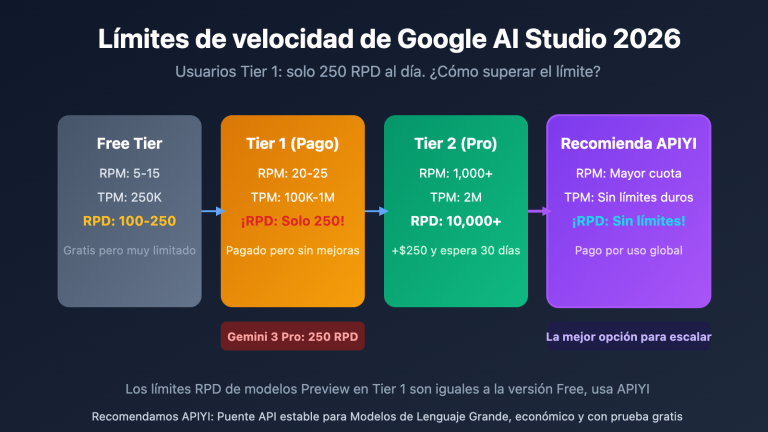
Cómo utilizar un contexto ultra largo de más de 200,000 tokens en llamadas a la API es una necesidad real a la que se enfrentan cada vez más desarrolladores. Anthropic ha lanzado la función de ventana de contexto de 1 millón de tokens (1M Context Window) de Claude API, permitiendo que una sola solicitud procese aproximadamente 750,000 palabras de contenido, lo que equivale a leer de una sola vez las novelas clásicas "Sueño en el pabellón rojo" y "Romance de los Tres Reinos" completas.
Valor principal: Al terminar de leer este artículo, dominarás el método completo para activar la ventana de contexto de 1M de Claude API, entenderás las reglas de cálculo de precios y obtendrás plantillas de código para 5 escenarios prácticos.
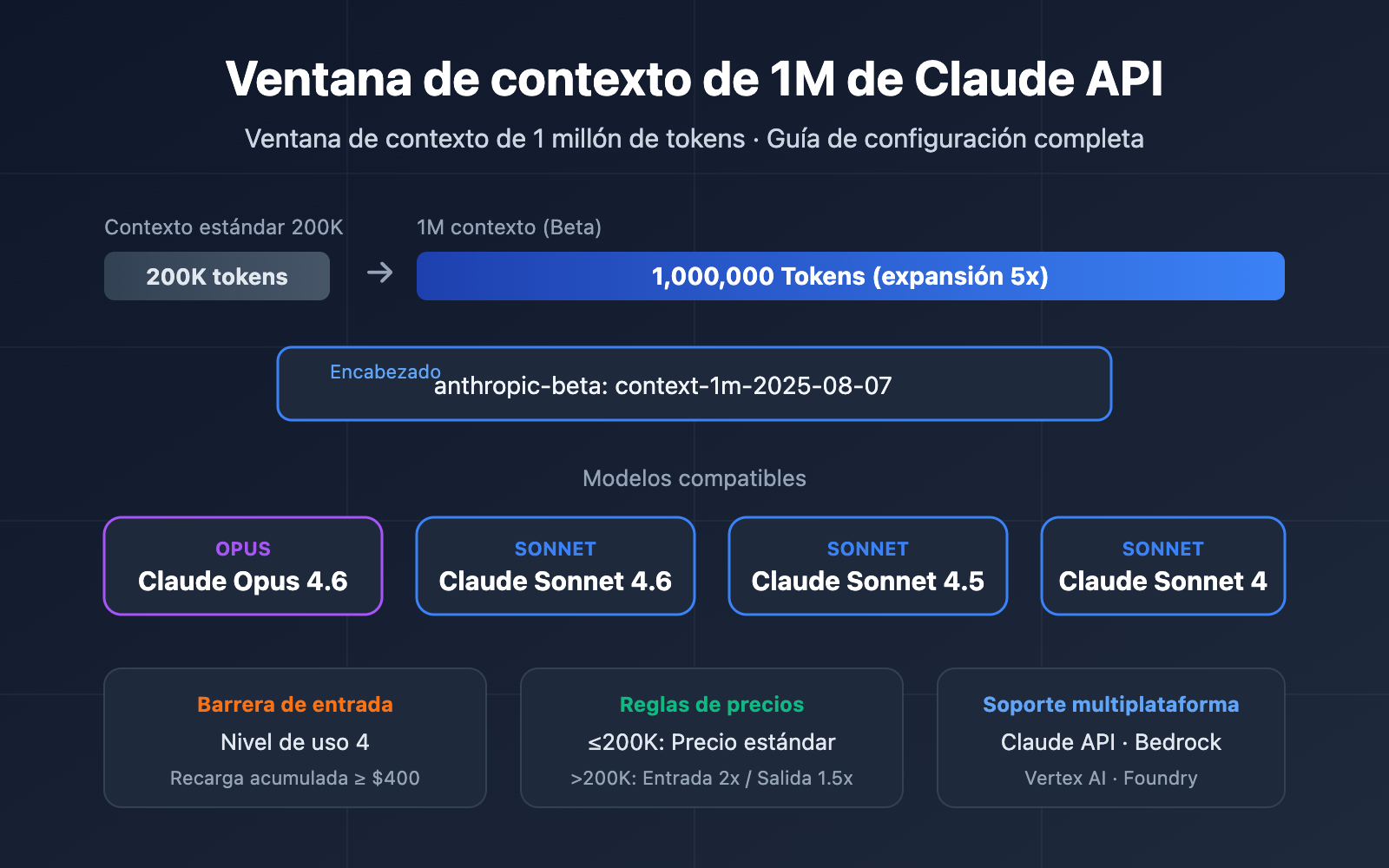
Puntos clave de la ventana de contexto de 1M de Claude API
Antes de profundizar en los detalles de configuración, conozcamos la información fundamental de esta función.
| Punto clave | Descripción | Valor |
|---|---|---|
| Función Beta | Se activa mediante el header context-1m-2025-08-07 |
No requiere solicitud adicional, solo añadir el header |
| Modelos compatibles | Opus 4.6, Sonnet 4.6, Sonnet 4.5, Sonnet 4 | Cubre las series de modelos principales |
| Requisitos de acceso | Requiere Usage Tier 4 o límites de velocidad personalizados | Se alcanza el Tier 4 con una recarga acumulada de $400 |
| Reglas de precios | Cambio automático a precios de contexto largo tras superar los 200K tokens | Entrada 2x, Salida 1.5x del precio estándar |
| Soporte multiplataforma | Claude API, AWS Bedrock, Google Vertex AI, Microsoft Foundry | Experiencia unificada entre plataformas |
Cómo funciona la ventana de contexto de 1M de Claude API
La ventana de contexto estándar de Claude API es de 200K tokens. Una vez que activas la ventana de contexto de 1M a través del header beta, el modelo puede procesar hasta 1 millón de tokens de entrada en una sola solicitud.
Es muy importante tener en cuenta que la ventana de contexto incluye todo el contenido:
- Tokens de entrada: indicación del sistema, historial de conversación, mensaje actual del usuario.
- Tokens de salida: contenido de la respuesta generada por el modelo.
- Tokens de pensamiento: si se activa el Extended Thinking, el proceso de razonamiento también se contabiliza.
🎯 Sugerencia técnica: La ventana de contexto de 1M de Claude API es ideal para escenarios como el análisis de grandes bases de código o la comprensión de documentos extensos. Recomendamos utilizar la plataforma APIYI (apiyi.com) para validar rápidamente soluciones de contexto largo, ya que ofrece una interfaz unificada para toda la serie de modelos Claude.
Guía rápida de la ventana de contexto de 1M de la API de Claude
Requisitos previos
Antes de utilizar la ventana de contexto de 1M, asegúrate de cumplir con las siguientes condiciones:
| Condición | Requisito | Cómo verificar |
|---|---|---|
| Nivel de uso (Usage Tier) | Tier 4 o límites de velocidad personalizados | Entra en Claude Console → Settings → Limits |
| Recarga acumulada | ≥ $400 (umbral para alcanzar el Tier 4) | Consulta el historial de recargas de tu cuenta |
| Selección de modelo | Opus 4.6 / Sonnet 4.6 / Sonnet 4.5 / Sonnet 4 | Otros modelos no soportan el contexto de 1M |
| Versión de la API | anthropic-version: 2023-06-01 |
Especificar en el header de la solicitud |
Ejemplo minimalista
Solo necesitas añadir una línea de encabezado beta a tu solicitud estándar de la API para desbloquear la ventana de contexto de 1M:
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Usa la interfaz unificada de APIYI
)
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[
{"role": "user", "content": "Por favor, analiza los argumentos centrales del siguiente documento extenso..."}
],
betas=["context-1m-2025-08-07"],
)
print(response.content[0].text)
Llamada equivalente usando cURL:
curl https://api.apiyi.com/v1/messages \
-H "x-api-key: $API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: context-1m-2025-08-07" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [
{"role": "user", "content": "Analiza este documento extenso..."}
]
}'
Explicación del código clave:
betas=["context-1m-2025-08-07"]: Forma de escribirlo en el SDK de Python, añade automáticamente el encabezadoanthropic-beta.anthropic-beta: context-1m-2025-08-07: Forma de escribir el encabezado para solicitudes cURL / HTTP.- Cuando los tokens de entrada no superan los 200K, se factura al precio estándar incluso si se añade el encabezado beta.
Ver código completo en TypeScript
import Anthropic from "@anthropic-ai/sdk";
import * as fs from "fs";
const anthropic = new Anthropic({
apiKey: "YOUR_API_KEY",
baseURL: "https://api.apiyi.com/v1" // Usa la interfaz unificada de APIYI
});
async function analyzeLongDocument(filePath: string) {
// Leer archivo grande
const document = fs.readFileSync(filePath, "utf-8");
const response = await anthropic.beta.messages.create({
model: "claude-opus-4-6",
max_tokens: 8192,
messages: [
{
role: "user",
content: `Por favor, realiza un análisis exhaustivo del siguiente documento, que incluya:
1. Resumen de los argumentos centrales
2. Extracción de datos clave
3. Evaluación de la estructura lógica
4. Sugerencias de mejora
Contenido del documento:
${document}`
}
],
betas: ["context-1m-2025-08-07"]
});
console.log(response.content[0].text);
// Verificar el uso de tokens
console.log("Input tokens:", response.usage.input_tokens);
console.log("Output tokens:", response.usage.output_tokens);
}
analyzeLongDocument("./large-report.txt");
🚀 Inicio rápido: Recomendamos usar la plataforma APIYI (apiyi.com) para probar rápidamente la ventana de contexto de 1M de Claude. Esta plataforma ofrece una interfaz compatible con OpenAI, sin configuraciones complejas, y soporta toda la serie de modelos de Claude.

Detalles de precios de la ventana de contexto de 1M de Claude API
El precio del contexto largo es una de las mayores preocupaciones para los desarrolladores. Claude API utiliza una estrategia de facturación por tramos: el hecho de que tus tokens de entrada superen o no los 200K determinará tu nivel de facturación.
Comparativa de precios de contexto largo por modelo
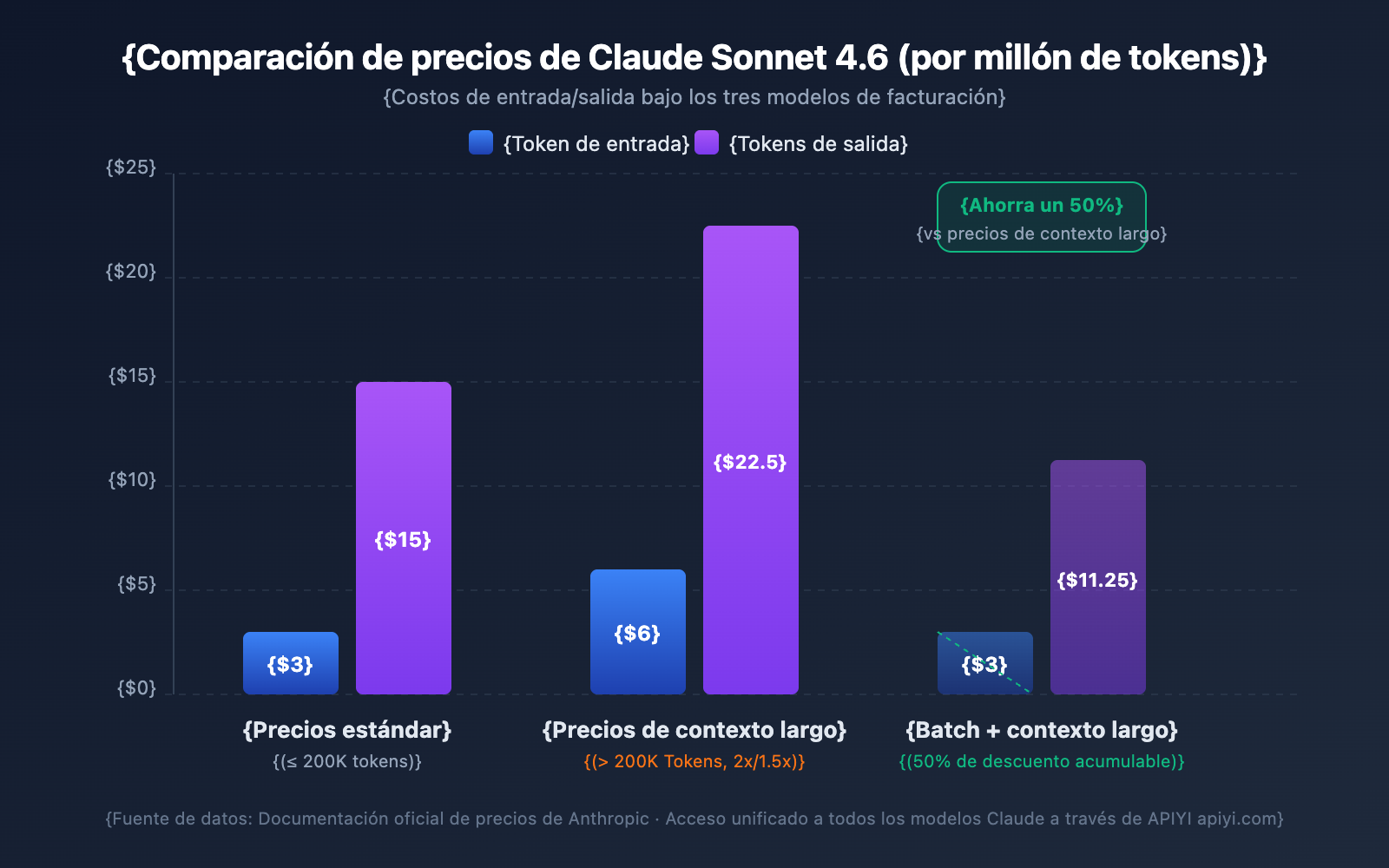
| Modelo | Entrada estándar (≤200K) | Entrada contexto largo (>200K) | Salida estándar | Salida contexto largo | Multiplicador |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $10/MTok | $25/MTok | $37.50/MTok | Entrada 2x / Salida 1.5x |
| Claude Sonnet 4.6 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Entrada 2x / Salida 1.5x |
| Claude Sonnet 4.5 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Entrada 2x / Salida 1.5x |
| Claude Sonnet 4 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Entrada 2x / Salida 1.5x |
MTok = Millón de Tokens
Reglas de cálculo de precios
Entiende estas reglas clave para evitar que los costos superen tus expectativas:
- El umbral de 200K es un interruptor: Una vez que el total de tokens de entrada supera los 200K, todos los tokens de la solicitud completa se facturan al precio de contexto largo, no solo la parte que excede el límite.
- El total de tokens de entrada incluye la caché: La suma de
input_tokens+cache_creation_input_tokens+cache_read_input_tokenses lo que determina el nivel de precio. - Los tokens de salida no afectan al nivel: La cantidad de tokens de salida no influye en si se activa el precio de contexto largo, pero una vez activado, la salida también se factura con el recargo de 1.5x.
- Por debajo de 200K se mantiene el precio estándar: Incluso si tienes activado el beta header, mientras la entrada no supere los 200K, se te cobrará la tarifa estándar.
Ejemplo de cálculo de costos
Escenario: Usar Claude Sonnet 4.6 para analizar un documento largo de 500,000 tokens y generar un informe de 2,000 tokens.
Costo de entrada: 500,000 Tokens × $6/MTok = $3.00
Costo de salida: 2,000 Tokens × $22.50/MTok = $0.045
Total: $3.045
Con la misma salida, si la entrada fuera de solo 150,000 tokens:
Costo de entrada: 150,000 Tokens × $3/MTok = $0.45
Costo de salida: 2,000 Tokens × $15/MTok = $0.03
Total: $0.48
4 estrategias para ahorrar dinero
| Estrategia | Nivel de ahorro | Casos de uso ideales |
|---|---|---|
| Prompt Caching | Solo 10% del costo en aciertos de caché | Reutilización frecuente del mismo documento largo |
| Batch API | 50% de descuento en todos los costos | Tareas de procesamiento por lotes que no requieren tiempo real |
| Fast Mode (Opus 4.6) | Sin recargo por contexto largo | Escenarios que necesitan una respuesta rápida |
| Controlar la entrada bajo 200K | Evita el multiplicador 2x | Documentos que pueden procesarse por fragmentos |
💰 Optimización de costos: Para proyectos que requieren llamadas frecuentes al contexto largo de Claude, puedes obtener planes de facturación flexibles a través de la plataforma APIYI (apiyi.com). Combinando Prompt Caching y Batch API, el costo por llamada puede reducirse en más de un 70%.
Límites de velocidad de la ventana de contexto de 1M de Claude API
Al activar el contexto de 1M, las solicitudes de contexto largo (entrada superior a 200K tokens) tienen límites de velocidad independientes, calculados por separado de los límites de las solicitudes estándar.
Límites de velocidad del Tier 4
| Tipo de límite | Límite de solicitud estándar | Límite de solicitud de contexto largo |
|---|---|---|
| Tokens de entrada máx./minuto (ITPM) | Sonnet: 2,000,000 / Opus: 2,000,000 | 1,000,000 |
| Tokens de salida máx./minuto (OTPM) | Sonnet: 400,000 / Opus: 400,000 | 200,000 |
| Solicitudes máx./minuto (RPM) | 4,000 | Reducción proporcional |
Notas importantes:
- Los límites de velocidad de contexto largo se calculan de forma independiente a los límites estándar; no se afectan entre sí.
- Al usar Prompt Caching, los tokens que impactan en la caché no cuentan para el límite de ITPM (en la mayoría de los modelos).
- Si necesitas límites de velocidad de contexto largo más altos, puedes contactar al equipo de ventas de Anthropic para solicitar límites personalizados.
Cómo subir al Tier 4
| Tier | Requisito de recarga acumulada | Recarga máxima única | Límite de gasto mensual |
|---|---|---|---|
| Tier 1 | $5 | $100 | $100 |
| Tier 2 | $40 | $500 | $500 |
| Tier 3 | $200 | $1,000 | $1,000 |
| Tier 4 | $400 | $5,000 | $5,000 |
Una vez alcanzado el umbral de recarga acumulada, la cuenta se actualizará automáticamente sin necesidad de revisión manual.
5 escenarios prácticos para la ventana de contexto de 1M de la API de Claude
Escenario 1: Análisis de grandes bases de código
Envía todo el código de tu proyecto a Claude para realizar revisiones de arquitectura, depuración de errores o sugerencias de refactorización.
import anthropic
import os
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def collect_codebase(directory, extensions=(".py", ".ts", ".js")):
"""Recopila todos los archivos de código fuente del tipo especificado en el proyecto"""
code_content = []
for root, dirs, files in os.walk(directory):
# Omite directorios como node_modules
dirs[:] = [d for d in dirs if d not in ("node_modules", ".git", "__pycache__")]
for file in files:
if file.endswith(extensions):
filepath = os.path.join(root, file)
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
code_content.append(f"### {filepath}\n```\n{content}\n```")
return "\n\n".join(code_content)
codebase = collect_codebase("./mi-proyecto")
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=8192,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Por favor, realiza una revisión exhaustiva de la arquitectura de la siguiente base de código:
{codebase}
Analiza:
1. Ventajas y desventajas del diseño de la arquitectura general
2. Posibles vulnerabilidades de seguridad
3. Sugerencias de optimización de rendimiento
4. Puntos de mejora en la calidad del código"""
}]
)
Escenario 2: Análisis integral de documentos extensos
Procesamiento de contratos legales, colecciones de artículos de investigación, informes financieros y otros documentos extremadamente largos.
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""A continuación se presenta una colección de informes financieros de la empresa de los últimos 12 meses (aprox. 400,000 tokens):
{financial_reports}
Por favor, completa:
1. Análisis de tendencias de los indicadores financieros clave de cada trimestre
2. Inferencia de los cambios en la estructura de ingresos y sus causas
3. Evaluación de la efectividad del control de costes
4. Previsión de resultados para el próximo trimestre y advertencias de riesgo"""
}]
)
Escenario 3: Combinación de conversaciones largas de varios turnos con Extended Thinking
Activa el Extended Thinking en contextos largos para que Claude realice razonamientos profundos:
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
betas=["context-1m-2025-08-07"],
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[{
"role": "user",
"content": f"""A continuación se presenta la documentación técnica completa y el código fuente de un sistema complejo:
{large_technical_document}
Analiza en profundidad la filosofía de diseño de este sistema y propón un plan de mejora."""
}]
)
# Los tokens de Extended Thinking no se acumulan en las conversaciones posteriores
# La API eliminará automáticamente los bloques de pensamiento de los turnos anteriores
Escenario 4: Uso de Prompt Caching para reducir costes en contextos largos
Cuando necesitas realizar múltiples análisis desde diferentes dimensiones sobre el mismo documento largo, el Prompt Caching puede reducir drásticamente los costes:
# Primera solicitud: Cachear el documento largo
response1 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"} # Marcar como cacheable
}],
messages=[{"role": "user", "content": "Resume los argumentos centrales de este documento"}]
)
# Segunda solicitud: Acierto de caché (Cache hit), el token de entrada solo cuesta el 10%
# de la tarifa estándar
response2 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "Extrae todas las tablas de datos del documento"}]
)
Escenario 5: Procesamiento por lotes de documentos largos con la Batch API
El uso de la Batch API permite obtener un descuento adicional del 50% sobre el precio base del contexto largo:
# Crear solicitud por lotes
batch = client.beta.messages.batches.create(
betas=["context-1m-2025-08-07"],
requests=[
{
"custom_id": "doc-analysis-1",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": f"Analiza el documento 1: {doc1}"}]
}
},
{
"custom_id": "doc-analysis-2",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": "Analiza el documento 2: {doc2}"}]
}
}
]
)
🎯 Consejo práctico: En proyectos reales, recomendamos realizar primero pruebas a pequeña escala a través de la plataforma APIYI (apiyi.com) para confirmar que el uso de tokens y los costes se ajustan a lo esperado antes de un despliegue masivo. La plataforma ofrece un panel detallado de estadísticas de uso para facilitar un control preciso de los costes.
Sugerencias para elegir el modelo de Claude API con ventana de contexto de 1M
Los 4 modelos que admiten un contexto de 1M tienen enfoques diferentes; elegir el adecuado permite encontrar el mejor equilibrio entre rendimiento y coste.
Comparativa detallada de modelos con soporte de contexto de 1M
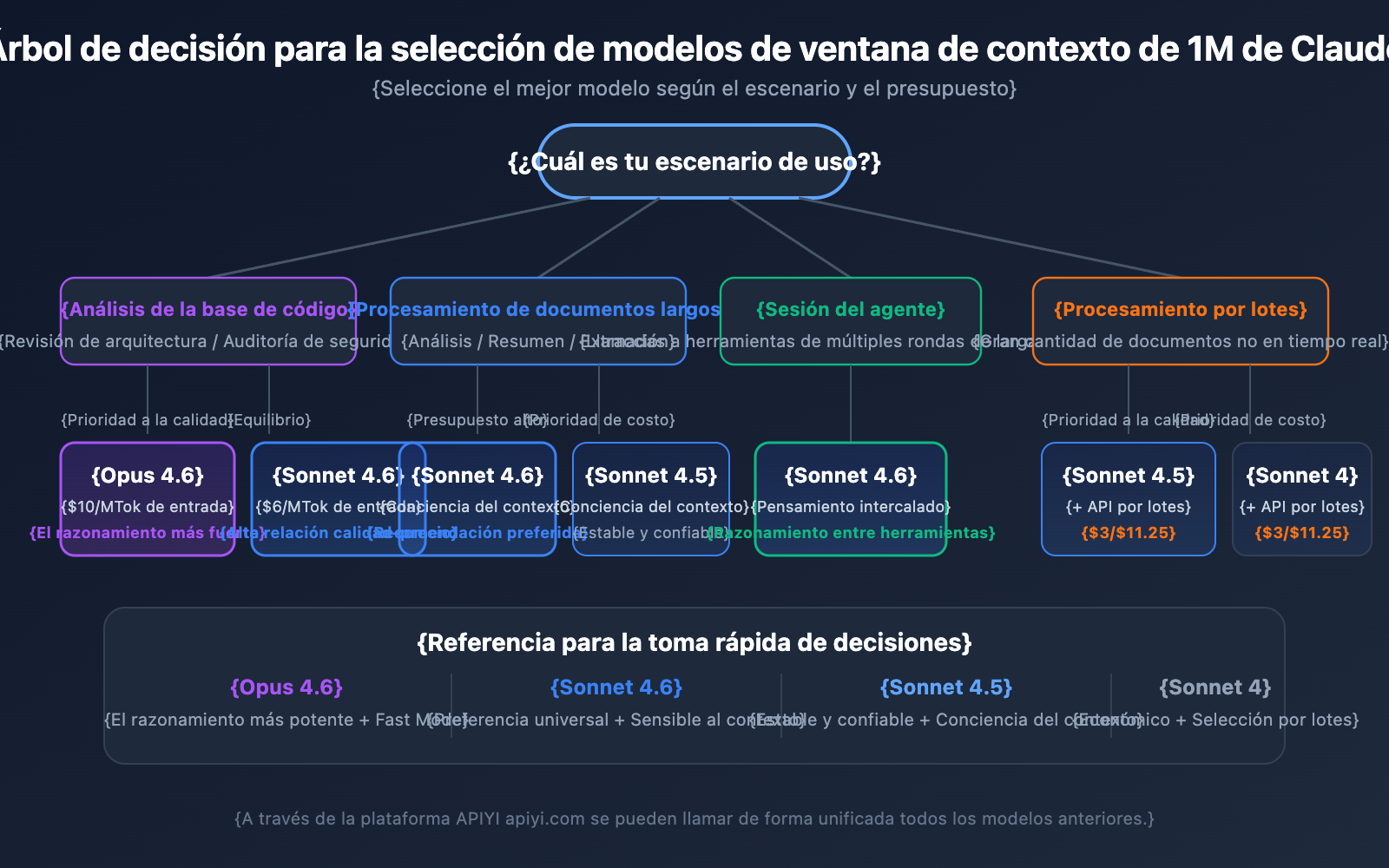
| Dimensión de comparación | Claude Opus 4.6 | Claude Sonnet 4.6 | Claude Sonnet 4.5 | Claude Sonnet 4 |
|---|---|---|---|---|
| Nivel de inteligencia | El más fuerte | Fuerte | Fuerte | Medio-alto |
| Precio de entrada estándar | $5/MTok | $3/MTok | $3/MTok | $3/MTok |
| Precio entrada contexto largo | $10/MTok | $6/MTok | $6/MTok | $6/MTok |
| Fast Mode | Soportado (6x precio) | No soportado | No soportado | No soportado |
| Conciencia del contexto | No soportado | Soportado | Soportado | No soportado |
| Interleaved Thinking | Soportado | Soportado | No soportado | Soportado |
| Escenarios recomendados | Razonamiento complejo, análisis de código | Procesamiento general de documentos largos | Sesiones de agentes de varios turnos | Tareas de análisis diarias |
Selección de modelo por escenario
Cuándo elegir Claude Opus 4.6:
- Tareas de análisis complejas que requieren la máxima capacidad de razonamiento.
- Revisión de arquitectura y auditoría de seguridad de grandes bases de código.
- Escenarios en tiempo real que requieren Fast Mode (respuesta rápida sin recargo por contexto largo).
- Aplicaciones de nivel empresarial donde la calidad es la prioridad y el presupuesto es suficiente.
Cuándo elegir Claude Sonnet 4.6:
- Análisis diario de documentos largos y extracción de resúmenes.
- Conversaciones largas que requieren capacidad de conciencia del contexto.
- Proyectos sensibles al coste pero con altos requisitos de calidad.
- Necesidad de Interleaved Thinking para razonamiento entre llamadas a herramientas.
Cuándo elegir Claude Sonnet 4.5 / Sonnet 4:
- Procesamiento de documentos por lotes (usando la Batch API para reducir costes).
- Extracción de información estructurada y organización de datos.
- Entornos de producción estables que no requieren las últimas características del modelo.
💡 Sugerencia de elección: El modelo que elijas dependerá principalmente de tu escenario de aplicación específico y de tu presupuesto. Recomendamos realizar comparaciones de pruebas reales a través de la plataforma APIYI (apiyi.com), que admite llamadas a través de una interfaz unificada para todos los modelos mencionados, facilitando el cambio y la evaluación rápida.
Referencia de estimación de tokens para la ventana de contexto de 1M de Claude API
Al planificar el uso de contextos largos, es muy importante conocer el consumo de tokens según el tipo de contenido:
| Tipo de contenido | Cantidad aproximada de tokens | Capacidad en la ventana de 1M |
|---|---|---|
| Texto en inglés | ~1 Token / 4 caracteres | Aprox. 3 millones de caracteres |
| Texto en chino | ~1 Token / 1.5 caracteres | Aprox. 750,000 caracteres |
| Código Python | ~1 Token / 3.5 caracteres | Aprox. 2.5 millones de caracteres |
| Página web común (10KB) | ~2,500 Tokens | Aprox. 400 páginas web |
| Documento grande (100KB) | ~25,000 Tokens | Aprox. 40 documentos |
| PDF de artículo de investigación (500KB) | ~125,000 Tokens | Aprox. 8 artículos |
Ventana de contexto de 1M de la API de Claude y conciencia del contexto
Claude Sonnet 4.6, Sonnet 4.5 y Haiku 4.5 cuentan con la capacidad de Context Awareness (conciencia del contexto). El modelo puede rastrear en tiempo real la capacidad restante de la ventana de contexto, gestionando de forma más inteligente el presupuesto de tokens en conversaciones largas.
Cómo funciona:
Al inicio de la conversación, Claude recibe información sobre la capacidad total del contexto:
<budget:token_budget>1000000</budget:token_budget>
Después de cada llamada a una herramienta, el modelo recibe una actualización de la capacidad restante:
<system_warning>Token usage: 350000/1000000; 650000 remaining</system_warning>
Esto significa que, en una ventana de contexto de 1M, Claude es capaz de:
- Gestionar con precisión el presupuesto de tokens: Evita agotar repentinamente el contexto en las fases finales de la conversación.
- Asignar razonablemente la longitud de la salida: Ajusta el nivel de detalle de las respuestas según la capacidad restante.
- Soportar sesiones de agentes ultra largas: Ejecuta tareas de forma continua en flujos de trabajo de agentes hasta su finalización.
Estrategia de gestión de la ventana de contexto de 1M: Compaction
Cuando la longitud de la conversación se acerca al límite de la ventana de contexto de 1M, la API de Claude ofrece la función de Compaction (compactación) para dar continuidad al diálogo. La compactación es un mecanismo de resumen en el lado del servidor que comprime automáticamente el contenido inicial de la conversación en un resumen conciso, liberando espacio de contexto y permitiendo así conversaciones ultra largas que superan el límite original.
Actualmente, la función de Compaction está disponible en fase Beta para Claude Opus 4.6. Para los desarrolladores que necesitan ejecutar tareas de agentes prolongadas en un contexto de 1M, la compactación es la estrategia preferida para gestionar el contexto.
Además, la API de Claude ofrece capacidades de Context Editing (edición de contexto), que incluyen:
- Tool Result Clearing: Elimina resultados de llamadas a herramientas antiguas en flujos de trabajo de agentes para liberar tokens.
- Thinking Block Clearing: Elimina proactivamente el contenido de pensamiento de turnos anteriores para optimizar aún más el uso del contexto.
Estas estrategias pueden utilizarse junto con la ventana de contexto de 1M para obtener el mejor equilibrio entre rendimiento y coste en escenarios de contexto ultra largo.
Consideraciones sobre la ventana de contexto de 1M en la API de Claude
Al utilizar la ventana de contexto de 1M en la práctica, hay varios detalles técnicos que suelen pasarse por alto:
-
Los nuevos modelos devuelven errores de validación en lugar de truncamiento silencioso: A partir de Claude Sonnet 3.7, cuando el total de tokens de la indicación y la salida supera la ventana de contexto, la API devuelve un error de validación en lugar de truncar el contenido silenciosamente. Se recomienda utilizar la API de conteo de tokens para estimar la cantidad de tokens antes de enviar la solicitud.
-
El consumo de tokens de imágenes y PDFs no es fijo: El cálculo de tokens para contenido multimodal es diferente al del texto plano; imágenes del mismo tamaño pueden consumir cantidades de tokens muy distintas. Es necesario reservar un margen suficiente de tokens cuando se utilicen muchas imágenes.
-
Límites de tamaño de solicitud (Request Size Limits): Aunque la ventana de contexto soporte 1M de tokens, la solicitud HTTP en sí tiene límites de tamaño. Al enviar textos extremadamente grandes, es necesario prestar atención a las restricciones a nivel de HTTP.
-
Límites de velocidad con detección de caché: Al usar Prompt Caching (caché de indicaciones), los tokens que coinciden con la caché no cuentan para los límites de velocidad ITPM. Esto significa que, en escenarios de contexto de 1M, aprovechar adecuadamente la caché puede aumentar significativamente el rendimiento real.
Preguntas frecuentes
P1: ¿Cómo puedo confirmar si mi solicitud se está facturando con el precio de contexto largo?
Revisa el objeto usage en la respuesta de la API. Suma los campos input_tokens, cache_creation_input_tokens y cache_read_input_tokens. Si la suma supera los 200,000, toda la solicitud se facturará según el precio de contexto largo. Al realizar llamadas a través de la plataforma APIYI (apiyi.com), el panel de estadísticas de uso marcará claramente el nivel de facturación de cada solicitud.
P2: ¿Qué tipos de archivos admite la ventana de contexto de 1M?
La ventana de contexto de 1M de la API de Claude admite formatos de texto como texto plano, código y Markdown, así como imágenes y archivos PDF. Sin embargo, ten en cuenta que el consumo de tokens de imágenes y PDFs suele ser mayor y no es fijo. Cuando se combinan muchas imágenes con textos largos, se podrían alcanzar los límites de tamaño de solicitud (Request Size Limits). Se recomienda realizar pruebas a pequeña escala en la plataforma APIYI (apiyi.com) para confirmar el consumo real de tokens antes de un uso masivo.
P3: ¿Los tokens de Extended Thinking ocupan el contexto de 1M?
Los tokens de Extended Thinking del turno actual se contabilizan en la ventana de contexto. Sin embargo, la API de Claude elimina automáticamente los bloques de pensamiento (thinking blocks) de los turnos anteriores, por lo que no se acumulan en el diálogo posterior. Esto significa que puedes usar Extended Thinking de forma segura en un contexto de 1M sin preocuparte de que el proceso de pensamiento consuma demasiado espacio de contexto.
P4: ¿Qué pasa si no cumplo con los requisitos del Tier 4?
Actualmente, la ventana de contexto de 1M solo está abierta para organizaciones en el Tier 4 y aquellas con límites de velocidad personalizados. Para alcanzar el Tier 4, solo necesitas una recarga acumulada de $400; la actualización es automática tras la recarga. Si temporalmente no puedes alcanzar el Tier 4, puedes considerar: ① Controlar la entrada por debajo de 200K mediante procesamiento por segmentos; ② Usar soluciones de Generación Aumentada por Recuperación (RAG) para extraer contenido clave; ③ Contactar con el equipo de ventas de Anthropic para consultar planes personalizados.
P5: ¿Cómo se activa en AWS Bedrock y Google Vertex AI?
La ventana de contexto de 1M está disponible en AWS Bedrock, Google Vertex AI y Microsoft Foundry. La forma de activarlo varía ligeramente según la plataforma: en Bedrock se hace especificando los parámetros correspondientes en la solicitud InvokeModel, y en Vertex AI a través de la configuración de la API. Consulta la documentación oficial de cada plataforma para obtener los detalles de configuración específicos.
Lista de mejores prácticas para la ventana de contexto de 1M de Claude API
Al integrar la ventana de contexto de 1M en proyectos reales, te sugerimos seguir estas mejores prácticas:
Fase de desarrollo
- Estima primero con la API de conteo de tokens: Antes de enviar la solicitud real, usa la API de conteo de tokens para calcular la cantidad de tokens de entrada y evitar cargos inesperados por el precio de contexto largo.
- Configura un
max_tokensrazonable: El parámetromax_tokensno afecta el cálculo de los límites de velocidad (los OTPM se calculan según la salida real), por lo que puedes establecer un valor alto para asegurar que la respuesta no se corte. - Pruebas por etapas: Valida primero la efectividad de tu plantilla de indicación con datos a pequeña escala antes de aumentar gradualmente el volumen de entrada.
Entorno de producción
- Prioriza el Prompt Caching: Para documentos largos que se usan repetidamente, el Prompt Caching puede reducir el costo de entrada de la parte almacenada en caché hasta un 10% del precio estándar. Además, los tokens que impactan en el caché no cuentan para el límite de velocidad ITPM.
- Usa la Batch API para tareas que no sean en tiempo real: La Batch API ofrece un 50% de descuento adicional sobre el precio de contexto largo. Al combinar ambos, el costo es solo aproximadamente un 60% del precio estándar.
- Monitorea el campo
usage: Revisa el objetousageen cada respuesta y establece un mecanismo de alerta para el monitoreo de costos. - Reintentos ante errores 429: Las solicitudes de contexto largo tienen límites de velocidad independientes. Si encuentras un error 429, revisa el encabezado
retry-afterpara realizar reintentos de manera lógica.
Control de costos
- Controla el umbral de 200K: Si la entrada se acerca a los 200K, considera simplificar la indicación para evitar que se active el precio 2x.
- Elige el modelo adecuado: La serie Sonnet es un 40% más barata que Opus. Prioriza Sonnet para las tareas cotidianas.
- Aprovecha el almacenamiento en caché para reducir la presión de los límites de velocidad: Con una tasa de acierto de caché del 80%, el rendimiento real puede alcanzar hasta 5 veces el límite nominal.
Resumen de la ventana de contexto de 1M de Claude API
La ventana de contexto de 1M de Claude API permite a los desarrolladores procesar contenido equivalente a unas 750,000 palabras de una sola vez, ofreciendo una capacidad potente para el análisis de bases de código, procesamiento de documentos extensos y diálogos complejos. Repasemos los puntos clave:
- Actívalo con una línea de código: Solo necesitas añadir el encabezado
anthropic-beta: context-1m-2025-08-07. - Soporte para 4 modelos: Claude Opus 4.6, Sonnet 4.6, Sonnet 4.5 y Sonnet 4.
- Precios transparentes: Después de superar los 200K tokens, la entrada cuesta el doble y la salida 1.5 veces; por debajo de 200K, se mantiene el precio estándar.
- Límites de velocidad independientes: Las solicitudes de contexto largo no afectan la cuota de las solicitudes estándar.
- Múltiples métodos de optimización: Prompt Caching, Batch API y Fast Mode se pueden combinar para reducir costos.
Te recomendamos probar rápidamente las capacidades de la ventana de contexto de 1M de Claude a través de APIYI (apiyi.com) y encontrar la mejor solución para tus necesidades de negocio reales.
Referencias
-
Documentación oficial de Anthropic – Context Windows: Especificaciones técnicas sobre la ventana de contexto de la API de Claude.
- Enlace:
platform.claude.com/docs/en/build-with-claude/context-windows
- Enlace:
-
Documentación oficial de Anthropic – Pricing: Detalles completos sobre los precios de la API de Claude.
- Enlace:
platform.claude.com/docs/en/about-claude/pricing
- Enlace:
-
Documentación oficial de Anthropic – Rate Limits: Información sobre límites de velocidad y niveles de uso (Usage Tiers).
- Enlace:
platform.claude.com/docs/en/api/rate-limits
- Enlace:
📝 Autor: APIYI Team | Para más tutoriales sobre el uso de APIs de modelos de IA, visita el centro de ayuda de APIYI en apiyi.com