如何在 API 調用中使用超過 20 萬 Token 的超長上下文,是越來越多開發者面臨的真實需求。Anthropic 推出了 Claude API 100 萬 Token 上下文窗口(1M Context Window)功能,讓單次請求可以處理約 75 萬字的文本內容——相當於一次性讀完整部《紅樓夢》加《三國演義》。
核心價值: 讀完本文,你將掌握 Claude API 1M 上下文窗口的完整開啓方法,瞭解定價計算規則,並獲得 5 種實戰場景的代碼模板。

Claude API 1M 上下文窗口核心要點
在深入配置細節之前,先了解這個功能的關鍵信息。
| 要點 | 說明 | 價值 |
|---|---|---|
| Beta 功能 | 通過 context-1m-2025-08-07 header 開啓 |
無需額外申請,添加 header 即可 |
| 支持模型 | Opus 4.6、Sonnet 4.6、Sonnet 4.5、Sonnet 4 | 覆蓋主力模型系列 |
| 使用門檻 | 需要 Usage Tier 4 或自定義速率限制 | 累計充值 $400 即可達到 Tier 4 |
| 定價規則 | 超過 200K Token 後自動切換長上下文定價 | 輸入 2 倍、輸出 1.5 倍標準價格 |
| 多平臺支持 | Claude API、AWS Bedrock、Google Vertex AI、Microsoft Foundry | 跨平臺統一體驗 |
Claude API 1M 上下文窗口的工作原理
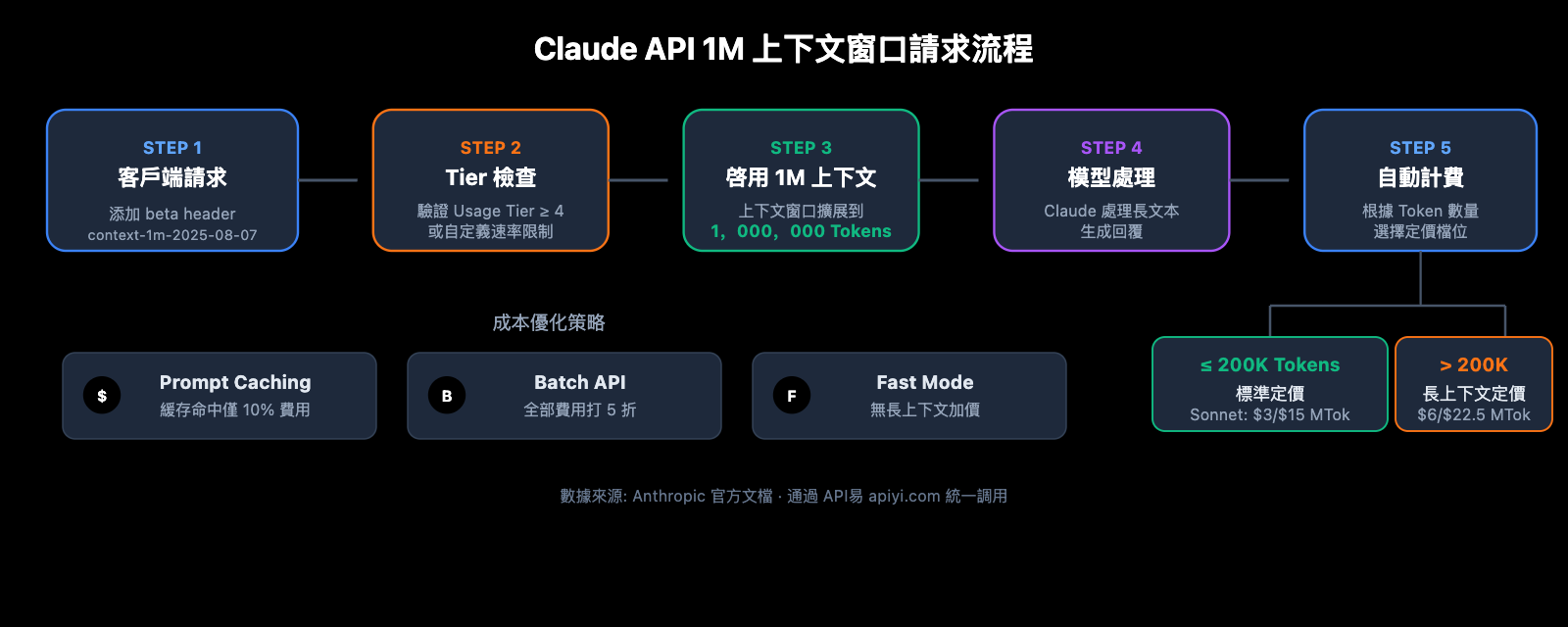
Claude API 的標準上下文窗口爲 200K Token。當你通過 beta header 開啓 1M 上下文窗口後,模型可以在單次請求中處理最多 100 萬個 Token 的輸入內容。
需要特別注意的是,上下文窗口包含了所有內容:
- 輸入 Token: 系統提示詞、對話歷史、當前用戶消息
- 輸出 Token: 模型生成的回覆內容
- 思考 Token: 如果啓用了 Extended Thinking,思考過程也會計入
🎯 技術建議: Claude API 的 1M 上下文窗口特別適合處理大規模代碼庫分析、長文檔理解等場景。我們建議通過 API易 apiyi.com 平臺快速驗證長上下文方案,該平臺支持 Claude 全系列模型的統一接口調用。
Claude API 1M 上下文窗口快速上手
開啓前提條件
在使用 1M 上下文窗口之前,確認你滿足以下條件:
| 條件 | 要求 | 檢查方式 |
|---|---|---|
| Usage Tier | Tier 4 或自定義速率限制 | 登錄 Claude Console → Settings → Limits |
| 累計充值 | ≥ $400(達到 Tier 4 門檻) | 查看賬戶充值記錄 |
| 模型選擇 | Opus 4.6 / Sonnet 4.6 / Sonnet 4.5 / Sonnet 4 | 其他模型不支持 1M 上下文 |
| API 版本 | anthropic-version: 2023-06-01 |
請求 header 中指定 |
極簡示例
只需在標準 API 請求中添加一行 beta header,即可解鎖 1M 上下文窗口:
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 使用 API易 統一接口
)
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[
{"role": "user", "content": "請分析以下長文檔的核心論點..."}
],
betas=["context-1m-2025-08-07"],
)
print(response.content[0].text)
使用 cURL 的等效調用:
curl https://api.apiyi.com/v1/messages \
-H "x-api-key: $API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: context-1m-2025-08-07" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [
{"role": "user", "content": "分析這份長文檔..."}
]
}'
關鍵代碼說明:
betas=["context-1m-2025-08-07"]: Python SDK 的寫法,自動添加anthropic-betaheaderanthropic-beta: context-1m-2025-08-07: cURL / HTTP 請求的 header 寫法- 當輸入 Token 不超過 200K 時,即使添加了 beta header,也按標準價格計費
查看 TypeScript 完整代碼
import Anthropic from "@anthropic-ai/sdk";
import * as fs from "fs";
const anthropic = new Anthropic({
apiKey: "YOUR_API_KEY",
baseURL: "https://api.apiyi.com/v1" // 使用 API易 統一接口
});
async function analyzeLongDocument(filePath: string) {
// 讀取大文件
const document = fs.readFileSync(filePath, "utf-8");
const response = await anthropic.beta.messages.create({
model: "claude-opus-4-6",
max_tokens: 8192,
messages: [
{
role: "user",
content: `請對以下文檔進行全面分析,包括:
1. 核心論點摘要
2. 關鍵數據提取
3. 邏輯結構評估
4. 改進建議
文檔內容:
${document}`
}
],
betas: ["context-1m-2025-08-07"]
});
console.log(response.content[0].text);
// 檢查 Token 使用情況
console.log("Input tokens:", response.usage.input_tokens);
console.log("Output tokens:", response.usage.output_tokens);
}
analyzeLongDocument("./large-report.txt");
🚀 快速開始: 推薦使用 API易 apiyi.com 平臺快速測試 Claude 1M 上下文窗口。該平臺提供 OpenAI 兼容接口,無需複雜配置,支持 Claude 全系列模型。
Claude API 1M 上下文窗口定價詳解
長上下文的定價是開發者最關心的問題之一。Claude API 採用了分段計費策略——輸入 Token 是否超過 200K 決定了你的計費檔位。
各模型長上下文定價對比
| 模型 | 標準輸入 (≤200K) | 長上下文輸入 (>200K) | 標準輸出 | 長上下文輸出 | 倍率 |
|---|---|---|---|---|---|
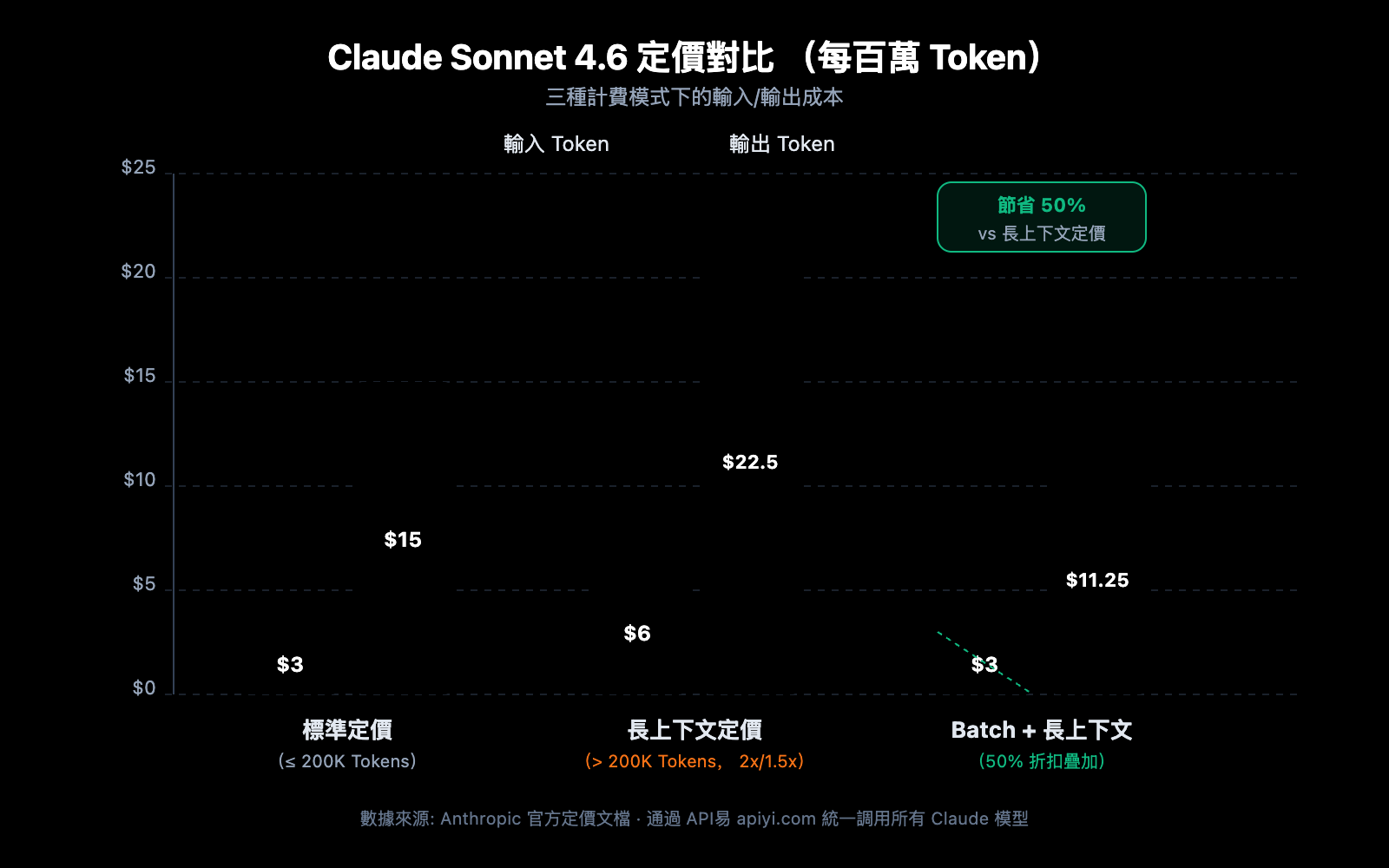
| Claude Opus 4.6 | $5/MTok | $10/MTok | $25/MTok | $37.50/MTok | 輸入 2x / 輸出 1.5x |
| Claude Sonnet 4.6 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | 輸入 2x / 輸出 1.5x |
| Claude Sonnet 4.5 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | 輸入 2x / 輸出 1.5x |
| Claude Sonnet 4 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | 輸入 2x / 輸出 1.5x |
MTok = 百萬 Token
定價計算規則
理解幾個關鍵規則,避免費用超預期:
- 200K 閾值是開關: 一旦輸入 Token 總量超過 200K,整個請求的所有 Token 都按長上下文價格計費,而不是隻對超出部分加價
- 輸入 Token 總量包含緩存:
input_tokens+cache_creation_input_tokens+cache_read_input_tokens的總和決定定價檔位 - 輸出 Token 不影響檔位: 輸出 Token 數量不影響是否觸發長上下文定價,但一旦觸發,輸出也按 1.5 倍計費
- 低於 200K 仍按標準價: 即使你開啓了 beta header,只要輸入不超過 200K,就按標準價計費
費用實例計算
場景: 使用 Claude Sonnet 4.6 分析一份 50 萬 Token 的長文檔,生成 2000 Token 的分析報告。
輸入費用: 500,000 Token × $6/MTok = $3.00
輸出費用: 2,000 Token × $22.50/MTok = $0.045
總計: $3.045
同樣的輸出,如果輸入只有 15 萬 Token:
輸入費用: 150,000 Token × $3/MTok = $0.45
輸出費用: 2,000 Token × $15/MTok = $0.03
總計: $0.48
4 種省錢策略
| 策略 | 節省幅度 | 適用場景 |
|---|---|---|
| Prompt Caching | 緩存命中僅收 10% 費用 | 重複使用相同長文檔 |
| Batch API | 所有費用打 5 折 | 非實時批量處理任務 |
| Fast Mode (Opus 4.6) | 無額外長上下文加價 | 需要快速響應的場景 |
| 控制輸入在 200K 以內 | 避免 2x 定價 | 可以分段處理的文檔 |
💰 成本優化: 對於需要頻繁調用 Claude 長上下文的項目,可以通過 API易 apiyi.com 平臺獲取靈活的計費方案。結合 Prompt Caching 和 Batch API,單次調用成本可降低 70% 以上。
Claude API 1M 上下文窗口速率限制
開啓 1M 上下文後,長上下文請求(輸入超過 200K Token)有獨立的速率限制,與標準請求的限額分開計算。
Tier 4 速率限制
| 限制類型 | 標準請求限制 | 長上下文請求限制 |
|---|---|---|
| 最大輸入 Token/分鐘 (ITPM) | Sonnet: 2,000,000 / Opus: 2,000,000 | 1,000,000 |
| 最大輸出 Token/分鐘 (OTPM) | Sonnet: 400,000 / Opus: 400,000 | 200,000 |
| 最大請求數/分鐘 (RPM) | 4,000 | 按比例降低 |
重要說明:
- 長上下文速率限制與標準速率限制獨立計算,互不影響
- 使用 Prompt Caching 時,緩存命中的 Token 不計入 ITPM 限額(大多數模型)
- 如果需要更高的長上下文速率限制,可以聯繫 Anthropic 銷售團隊申請自定義限額
如何升級到 Tier 4
| Tier | 累計充值要求 | 單次最大充值 | 月消費上限 |
|---|---|---|---|
| Tier 1 | $5 | $100 | $100 |
| Tier 2 | $40 | $500 | $500 |
| Tier 3 | $200 | $1,000 | $1,000 |
| Tier 4 | $400 | $5,000 | $5,000 |
達到累計充值門檻後會自動升級,無需人工審覈。
Claude API 1M 上下文窗口 5 大實戰場景
場景 1: 大型代碼庫分析
將整個項目代碼打包發送給 Claude,進行架構審查、Bug 排查或重構建議。
import anthropic
import os
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def collect_codebase(directory, extensions=(".py", ".ts", ".js")):
"""收集項目中所有指定類型的源代碼文件"""
code_content = []
for root, dirs, files in os.walk(directory):
# 跳過 node_modules 等目錄
dirs[:] = [d for d in dirs if d not in ("node_modules", ".git", "__pycache__")]
for file in files:
if file.endswith(extensions):
filepath = os.path.join(root, file)
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
code_content.append(f"### {filepath}\n```\n{content}\n```")
return "\n\n".join(code_content)
codebase = collect_codebase("./my-project")
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=8192,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""請對以下代碼庫進行全面架構審查:
{codebase}
請分析:
1. 整體架構設計的優缺點
2. 潛在的安全漏洞
3. 性能優化建議
4. 代碼質量改進點"""
}]
)
場景 2: 長文檔綜合分析
處理法律合同、研究論文集、財報等超長文檔。
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""以下是公司過去 12 個月的財務報告合集(約 40 萬 Token):
{financial_reports}
請完成:
1. 各季度核心財務指標趨勢分析
2. 收入結構變化及原因推斷
3. 成本控制效果評估
4. 下季度業績預測及風險提示"""
}]
)
場景 3: 多輪長對話與 Extended Thinking 結合
在長上下文中開啓 Extended Thinking,讓 Claude 進行深度推理:
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
betas=["context-1m-2025-08-07"],
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[{
"role": "user",
"content": f"""以下是一個複雜系統的完整技術文檔和源代碼:
{large_technical_document}
請深度分析這個系統的設計哲學,並給出改進方案。"""
}]
)
# Extended Thinking 的 token 不會在後續對話中累積
# API 會自動剝離之前輪次的 thinking blocks
場景 4: 使用 Prompt Caching 降低長上下文成本
當你需要對同一份長文檔進行多次不同維度的分析時,Prompt Caching 可以大幅降低成本:
# 第一次請求: 緩存長文檔
response1 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"} # 標記爲可緩存
}],
messages=[{"role": "user", "content": "總結這份文檔的核心論點"}]
)
# 第二次請求: 緩存命中,輸入 Token 僅收 10% 費用
response2 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "提取文檔中的所有數據表格"}]
)
場景 5: Batch API 批量處理長文檔
使用 Batch API 可以在長上下文定價的基礎上再打 5 折:
# 創建批量請求
batch = client.beta.messages.batches.create(
betas=["context-1m-2025-08-07"],
requests=[
{
"custom_id": "doc-analysis-1",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": f"分析文檔1: {doc1}"}]
}
},
{
"custom_id": "doc-analysis-2",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": "分析文檔2: {doc2}"}]
}
}
]
)
🎯 實戰建議: 在實際項目中,我們建議先通過 API易 apiyi.com 平臺進行小規模測試,確認 Token 用量和成本符合預期後,再進行大規模部署。平臺提供詳細的用量統計面板,便於精確控制成本。
Claude API 1M 上下文窗口模型選擇建議
4 款支持 1M 上下文的模型各有側重,選擇合適的模型能在效果和成本之間找到最佳平衡。
支持 1M 上下文的模型詳細對比
| 對比維度 | Claude Opus 4.6 | Claude Sonnet 4.6 | Claude Sonnet 4.5 | Claude Sonnet 4 |
|---|---|---|---|---|
| 智能水平 | 最強 | 強 | 強 | 中上 |
| 標準輸入價格 | $5/MTok | $3/MTok | $3/MTok | $3/MTok |
| 長上下文輸入價格 | $10/MTok | $6/MTok | $6/MTok | $6/MTok |
| Fast Mode | 支持 (6x 定價) | 不支持 | 不支持 | 不支持 |
| 上下文感知 | 不支持 | 支持 | 支持 | 不支持 |
| Interleaved Thinking | 支持 | 支持 | 不支持 | 支持 |
| 推薦場景 | 複雜推理、代碼分析 | 通用長文檔處理 | 多輪代理會話 | 日常分析任務 |
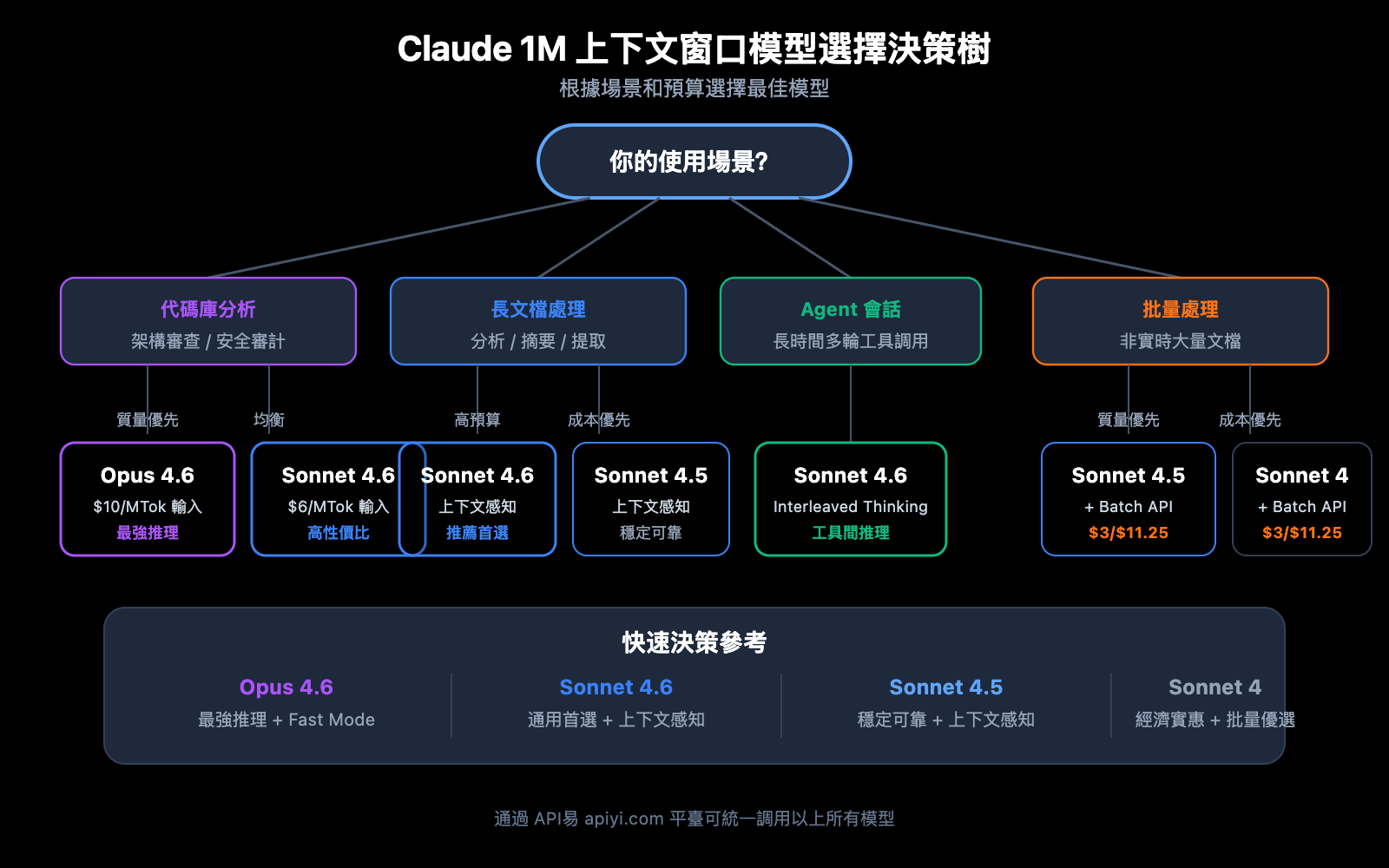
按場景選擇模型
選 Claude Opus 4.6 的場景:
- 需要最強推理能力的複雜分析任務
- 大型代碼庫的架構審查和安全審計
- 需要 Fast Mode(快速響應且無長上下文加價)的實時場景
- 預算充足、質量優先的企業級應用
選 Claude Sonnet 4.6 的場景:
- 日常長文檔分析和摘要提取
- 需要上下文感知能力的長對話
- 成本敏感但對質量有較高要求的項目
- 需要 Interleaved Thinking 進行工具調用間推理
選 Claude Sonnet 4.5 / Sonnet 4 的場景:
- 批量文檔處理(配合 Batch API 降低成本)
- 結構化信息提取和數據整理
- 不需要最新模型特性的穩定生產環境
💡 選擇建議: 選擇哪個模型主要取決於您的具體應用場景和預算。我們建議通過 API易 apiyi.com 平臺進行實際測試對比,該平臺支持上述所有模型的統一接口調用,便於快速切換和評估。
Claude API 1M 上下文窗口的 Token 估算參考
在規劃長上下文使用時,瞭解不同內容類型的 Token 消耗非常重要:
| 內容類型 | 大致 Token 數量 | 1M 窗口可容納量 |
|---|---|---|
| 英文文本 | ~1 Token / 4 字符 | 約 300 萬英文字符 |
| 中文文本 | ~1 Token / 1.5 字符 | 約 75 萬中文字符 |
| Python 代碼 | ~1 Token / 3.5 字符 | 約 250 萬字符代碼 |
| 普通網頁 (10KB) | ~2,500 Token | 約 400 個網頁 |
| 大型文檔 (100KB) | ~25,000 Token | 約 40 份文檔 |
| 研究論文 PDF (500KB) | ~125,000 Token | 約 8 篇論文 |
Claude API 1M 上下文窗口與上下文感知
Claude Sonnet 4.6、Sonnet 4.5 和 Haiku 4.5 具備 Context Awareness(上下文感知) 能力。模型能夠實時追蹤剩餘的上下文窗口容量,在長對話中更智能地管理 Token 預算。
工作原理:
對話開始時,Claude 會收到總上下文容量信息:
<budget:token_budget>1000000</budget:token_budget>
每次工具調用後,模型會收到剩餘容量更新:
<system_warning>Token usage: 350000/1000000; 650000 remaining</system_warning>
這意味着在 1M 上下文窗口中,Claude 能夠:
- 精確管理 Token 預算: 不會在對話後期突然耗盡上下文
- 合理分配輸出長度: 根據剩餘容量調整回覆的詳細程度
- 支持超長代理會話: 在 Agent 工作流中持續執行任務直到完成
Claude API 1M 上下文窗口管理策略: Compaction
當對話長度接近 1M 上下文窗口的極限時,Claude API 提供了 Compaction(壓縮) 功能來延續對話。Compaction 是一種服務端摘要機制,會自動將對話早期的內容壓縮成精簡摘要,釋放上下文空間,從而支持超越上下文窗口限制的超長對話。
目前 Compaction 功能在 Claude Opus 4.6 上以 Beta 形式提供。對於需要在 1M 上下文中運行長時間 Agent 任務的開發者,Compaction 是管理上下文的首選策略。
此外,Claude API 還提供了 Context Editing(上下文編輯) 能力,包括:
- Tool Result Clearing: 在 Agent 工作流中清除舊的工具調用結果,釋放 Token
- Thinking Block Clearing: 主動清除之前輪次的思考內容,進一步優化上下文利用率
這些策略可以和 1M 上下文窗口配合使用,讓你在超長上下文場景中獲得最佳的性能和成本平衡。
Claude API 1M 上下文窗口中的注意事項
在實際使用 1M 上下文窗口時,有幾個容易被忽略的技術細節:
-
新模型返回驗證錯誤而非靜默截斷: 從 Claude Sonnet 3.7 開始,當 prompt 和輸出 Token 總量超過上下文窗口時,API 會返回驗證錯誤,而不是悄悄截斷內容。建議在發送請求前使用 Token Counting API 預估 Token 數量。
-
圖片和 PDF 的 Token 消耗不固定: 多模態內容的 Token 計算與純文本不同,相同大小的圖片可能消耗差異很大的 Token 數量。在大量使用圖片時要預留充足的 Token 裕量。
-
請求大小限制 (Request Size Limits): 即使上下文窗口支持 1M Token,HTTP 請求本身也有大小限制。當發送超大文本時,需要關注 HTTP 層面的限制。
-
緩存感知的速率限制: 使用 Prompt Caching 時,緩存命中的 Token 不計入 ITPM 速率限制。這意味着在 1M 上下文場景中,合理利用緩存可以顯著提升實際吞吐量。
常見問題
Q1: 如何確認我的請求是否被按長上下文定價計費?
檢查 API 響應中的 usage 對象。將 input_tokens、cache_creation_input_tokens 和 cache_read_input_tokens 三個字段相加,如果總和超過 200,000,則整個請求按長上下文價格計費。通過 API易 apiyi.com 平臺調用時,用量統計面板會清晰標註每次請求的計費檔位。
Q2: 1M 上下文窗口支持哪些文件類型?
Claude API 的 1M 上下文窗口支持純文本、代碼、Markdown 等文本格式,也支持圖片和 PDF 文件。但需要注意,圖片和 PDF 的 Token 消耗通常較大且不固定。當大量圖片與長文本組合使用時,可能會觸及請求大小限制(Request Size Limits)。建議在 API易 apiyi.com 平臺先進行小規模測試,確認實際 Token 消耗後再大規模使用。
Q3: Extended Thinking 的 Token 會佔用 1M 上下文嗎?
當前輪次的 Extended Thinking Token 會計入上下文窗口。但 Claude API 會自動剝離之前輪次的 thinking blocks,不會在後續對話中累積。這意味着你可以在 1M 上下文中安全使用 Extended Thinking,不用擔心思考過程喫掉大量上下文空間。
Q4: 不滿足 Tier 4 條件怎麼辦?
目前 1M 上下文窗口僅對 Tier 4 及自定義速率限制的組織開放。達到 Tier 4 只需累計充值 $400,充值後自動升級。如果你暫時無法達到 Tier 4,可以考慮: ① 通過分段處理將輸入控制在 200K 以內; ② 使用 Retrieval-Augmented Generation (RAG) 方案提取關鍵內容; ③ 聯繫 Anthropic 銷售團隊瞭解自定義方案。
Q5: AWS Bedrock 和 Google Vertex AI 上如何開啓?
1M 上下文窗口在 AWS Bedrock、Google Vertex AI 和 Microsoft Foundry 上均可使用。不同平臺的開啓方式略有不同——Bedrock 通過在 InvokeModel 請求中指定相應參數,Vertex AI 通過 API 配置。具體配置方式請參考各平臺的官方文檔。
Claude API 1M 上下文窗口最佳實踐清單
在實際項目中整合 1M 上下文窗口,建議遵循以下最佳實踐:
開發階段
- 先用 Token Counting API 預估: 在發送實際請求前,先用 Token Counting API 估算輸入 Token 數量,避免意外觸發長上下文定價
- 設置合理的 max_tokens:
max_tokens參數不影響速率限制計算(OTPM 按實際輸出計算),可以設置較高的值確保輸出不被截斷 - 分段測試: 先用小規模數據驗證 prompt 模板效果,再逐步增大輸入規模
生產環境
- 優先使用 Prompt Caching: 對於重複使用的長文檔,Prompt Caching 可以將緩存命中部分的輸入費用降到標準價的 10%,同時緩存命中的 Token 不計入 ITPM 速率限制
- 非實時任務用 Batch API: Batch API 可在長上下文定價基礎上再打 5 折,兩者疊加後費用僅爲標準價的約 60%
- 監控 usage 字段: 每次請求後檢查響應中的
usage對象,建立費用監控告警機制 - 429 錯誤重試: 長上下文請求有獨立速率限制,遇到 429 錯誤時檢查
retry-afterheader 進行合理重試
成本控制
- 控制 200K 閾值: 如果輸入接近 200K,考慮精簡 prompt 以避免觸發 2x 定價
- 選擇合適的模型: Sonnet 系列比 Opus 便宜 40%,日常任務優先選 Sonnet
- 利用緩存降低速率限制壓力: 80% 緩存命中率下,實際吞吐量可達名義限額的 5 倍
Claude API 1M 上下文窗口總結
Claude API 的 1M 上下文窗口讓開發者能夠一次性處理約 75 萬字的內容,爲代碼庫分析、長文檔處理、複雜對話等場景提供了強大能力。核心要點回顧:
- 一行代碼開啓: 添加
anthropic-beta: context-1m-2025-08-07header 即可 - 4 款模型支持: Claude Opus 4.6、Sonnet 4.6、Sonnet 4.5、Sonnet 4
- 透明定價: 超過 200K Token 後輸入 2 倍、輸出 1.5 倍,低於 200K 仍按標準價
- 獨立速率限制: 長上下文請求不影響標準請求的額度
- 多種優化手段: Prompt Caching、Batch API、Fast Mode 可疊加降低成本
推薦通過 API易 apiyi.com 快速體驗 Claude 1M 上下文窗口的能力,結合實際業務場景找到最佳實踐方案。
參考資料
-
Anthropic 官方文檔 – Context Windows: Claude API 上下文窗口技術說明
- 鏈接:
platform.claude.com/docs/en/build-with-claude/context-windows
- 鏈接:
-
Anthropic 官方文檔 – Pricing: Claude API 完整定價說明
- 鏈接:
platform.claude.com/docs/en/about-claude/pricing
- 鏈接:
-
Anthropic 官方文檔 – Rate Limits: 速率限制和 Usage Tier 說明
- 鏈接:
platform.claude.com/docs/en/api/rate-limits
- 鏈接:
📝 作者: APIYI Team | 更多 AI 模型 API 使用教程,請訪問 API易 apiyi.com 幫助中心