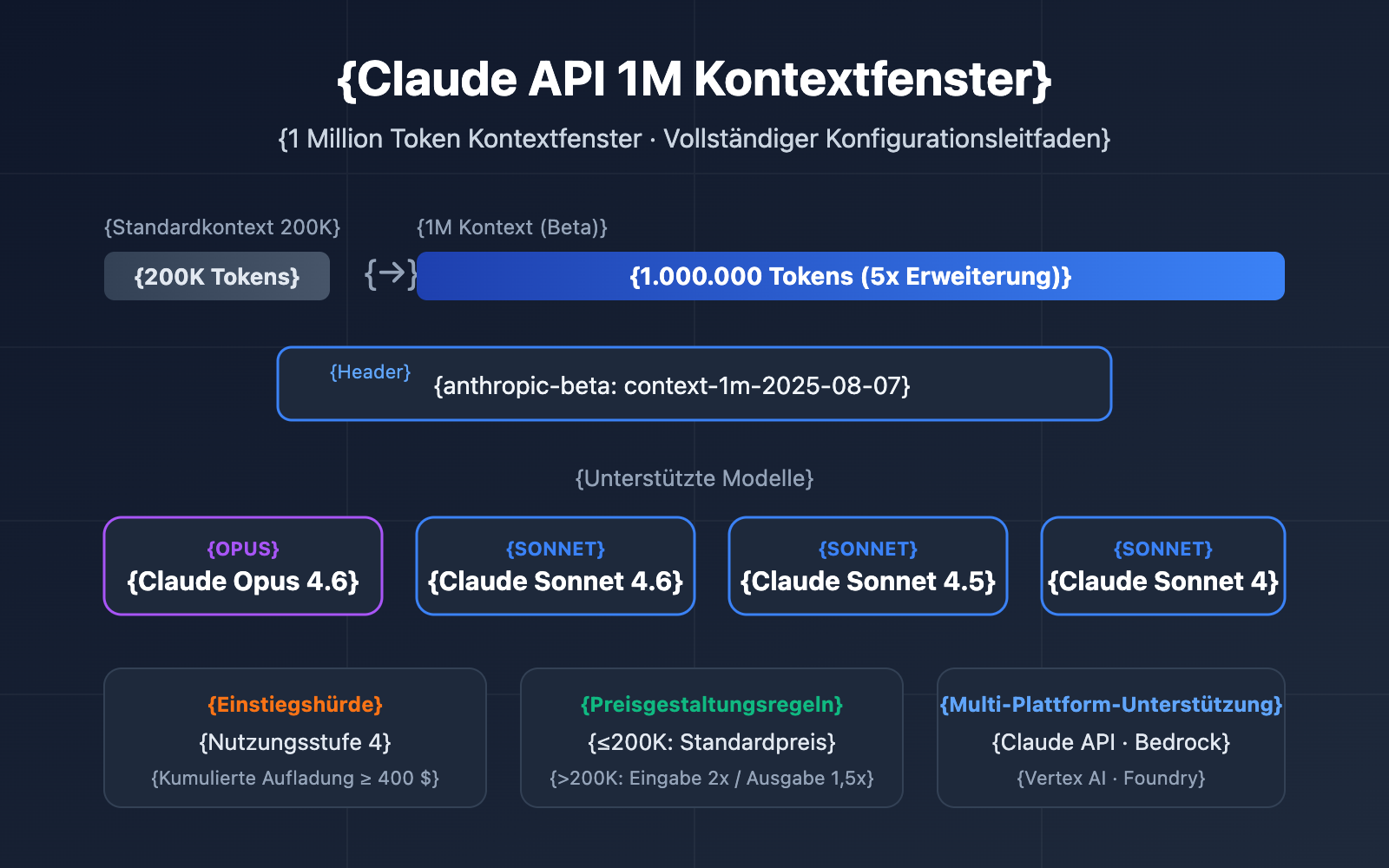
Wie man in API-Aufrufen einen ultralangen Kontext von mehr als 200.000 Token nutzt, ist ein reales Bedürfnis, vor dem immer mehr Entwickler stehen. Anthropic hat die Funktion Claude API 1 Million Token Kontextfenster (1M Context Window) eingeführt. Damit kann eine einzelne Anfrage etwa 750.000 Wörter Text verarbeiten – das entspricht dem gleichzeitigen Lesen von „Der Traum der Roten Kammer“ und „Die Geschichte der Drei Reiche“.
Kernwert: Nach der Lektüre dieses Artikels werden Sie die vollständige Methode zur Aktivierung des 1M-Kontextfensters der Claude API beherrschen, die Preisberechnungsregeln verstehen und Code-Vorlagen für 5 Praxisszenarien erhalten.
Kernpunkte des Claude API 1M Kontextfensters
Bevor wir uns mit den Konfigurationsdetails befassen, sollten Sie die wichtigsten Informationen zu dieser Funktion kennen.
| Punkt | Beschreibung | Wert |
|---|---|---|
| Beta-Funktion | Aktivierung über den Header context-1m-2025-08-07 |
Keine zusätzliche Beantragung nötig, einfach Header hinzufügen |
| Unterstützte Modelle | Opus 4.6, Sonnet 4.6, Sonnet 4.5, Sonnet 4 | Abdeckung der Hauptmodellserien |
| Nutzungshürde | Erfordert Usage Tier 4 oder benutzerdefinierte Ratenlimits | Tier 4 wird bei einer Gesamteinzahlung von 400 $ erreicht |
| Preisregeln | Automatischer Wechsel zum Lang-Kontext-Tarif ab 200K Token | 2x Eingabe, 1,5x Ausgabe des Standardpreises |
| Multi-Plattform-Unterstützung | Claude API, AWS Bedrock, Google Vertex AI, Microsoft Foundry | Einheitliche Erfahrung über Plattformen hinweg |
Funktionsweise des Claude API 1M Kontextfensters
Das Standard-Kontextfenster der Claude API beträgt 200K Token. Sobald Sie das 1M-Kontextfenster über den Beta-Header aktivieren, kann das Modell bis zu 1 Million Token Eingabeinhalt in einer einzigen Anfrage verarbeiten.
Besonders wichtig ist, dass das Kontextfenster alle Inhalte umfasst:
- Eingabe-Token: System-Eingabeaufforderungen, Dialogverlauf, aktuelle Benutzernachrichten
- Ausgabe-Token: Vom Modell generierte Antwortinhalte
- Thinking-Token: Wenn Extended Thinking aktiviert ist, wird auch der Denkprozess mitgezählt
🎯 Technischer Rat: Das 1M-Kontextfenster der Claude API eignet sich besonders gut für die Analyse großer Codebasen, das Verständnis langer Dokumente und ähnliche Szenarien. Wir empfehlen, Lang-Kontext-Lösungen schnell über die Plattform APIYI (apiyi.com) zu validieren, die einen einheitlichen Schnittstellenaufruf für die gesamte Claude-Modellserie unterstützt.
Claude API 1M Kontextfenster: Schnelleinstieg
Voraussetzungen für die Aktivierung
Bevor Sie das 1M-Kontextfenster nutzen können, stellen Sie sicher, dass Sie die folgenden Bedingungen erfüllen:
| Bedingung | Anforderung | Prüfung |
|---|---|---|
| Nutzungsstufe (Usage Tier) | Tier 4 oder benutzerdefiniertes Ratenlimit | Login in die Claude Console → Settings → Limits |
| Kumulierte Aufladung | ≥ $400 (Erreichen der Tier-4-Schwelle) | Aufladeverlauf des Kontos einsehen |
| Modellauswahl | Opus 4.6 / Sonnet 4.6 / Sonnet 4.5 / Sonnet 4 | Andere Modelle unterstützen kein 1M-Kontextfenster |
| API-Version | anthropic-version: 2023-06-01 |
Im Request-Header angeben |
Minimalbeispiel
Fügen Sie einfach eine einzige Beta-Header-Zeile zu einer Standard-API-Anfrage hinzu, um das 1M-Kontextfenster freizuschalten:
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Verwendung der einheitlichen APIYI-Schnittstelle
)
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[
{"role": "user", "content": "Bitte analysieren Sie die Kernargumente des folgenden langen Dokuments..."}
],
betas=["context-1m-2025-08-07"],
)
print(response.content[0].text)
Gleichwertiger Aufruf mit cURL:
curl https://api.apiyi.com/v1/messages \
-H "x-api-key: $API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: context-1m-2025-08-07" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [
{"role": "user", "content": "Analysieren Sie dieses lange Dokument..."}
]
}'
Wichtige Code-Details:
- `betas=["context-1m-2025-08-07"]
Claude API 1M Kontextfenster: Preisgestaltung im Detail
Die Preisgestaltung für lange Kontexte ist eines der Themen, die Entwickler am meisten beschäftigen. Die Claude API nutzt eine gestaffelte Preisstrategie – ob Ihr Input 200.000 Token überschreitet, entscheidet über Ihre Preisstufe.
Preisvergleich der Modelle für lange Kontexte
| Modell | Standard-Input (≤200K) | Langer Kontext Input (>200K) | Standard-Output | Langer Kontext Output | Multiplikator |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $10/MTok | $25/MTok | $37.50/MTok | Input 2x / Output 1,5x |
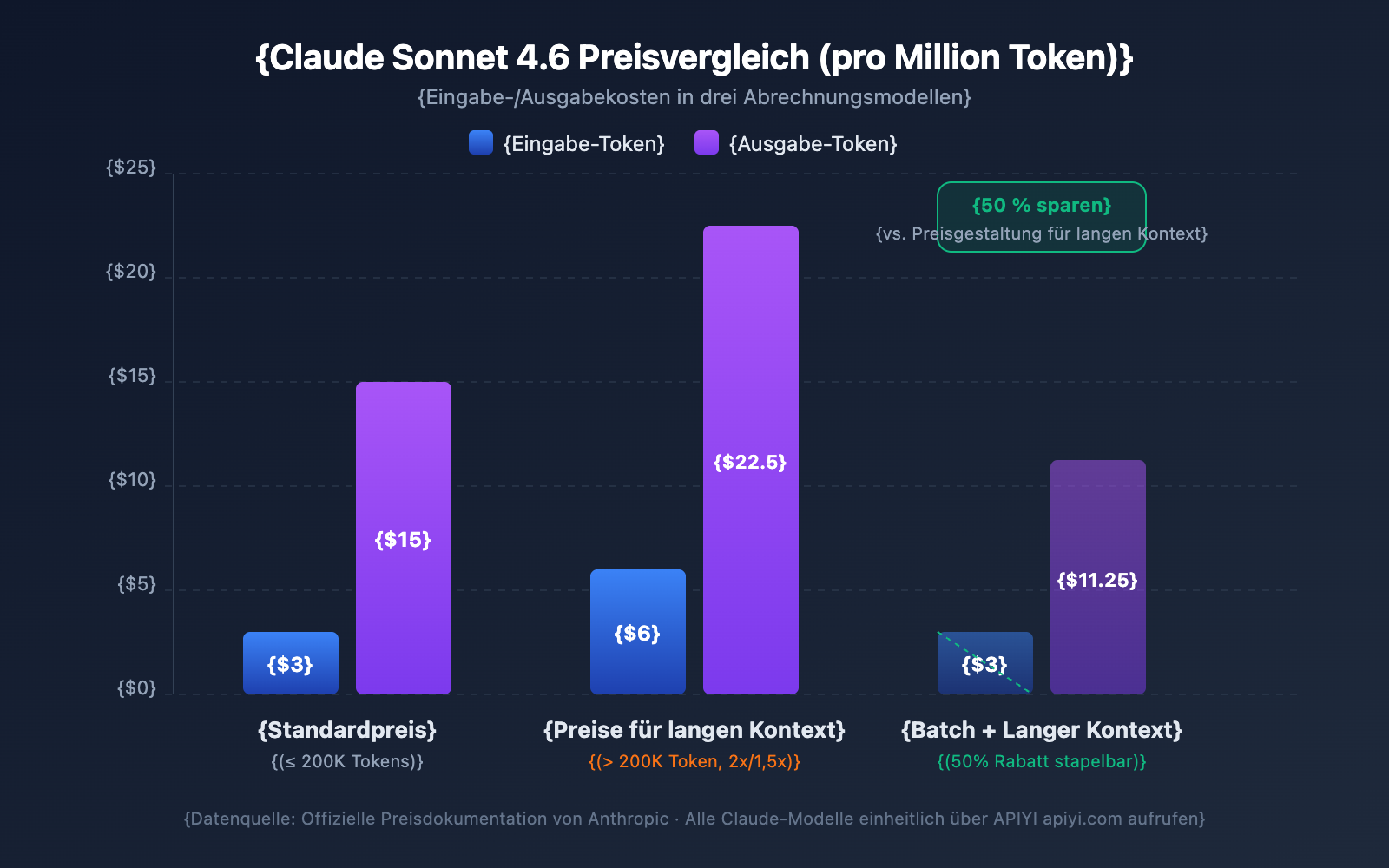
| Claude Sonnet 4.6 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Input 2x / Output 1,5x |
| Claude Sonnet 4.5 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Input 2x / Output 1,5x |
| Claude Sonnet 4 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Input 2x / Output 1,5x |
MTok = Eine Million Token
Regeln zur Preisberechnung
Hier sind einige wichtige Regeln, um unerwartete Kosten zu vermeiden:
- Der 200K-Schwellenwert fungiert als Schalter: Sobald die Gesamtmenge der Input-Token 200K überschreitet, werden alle Token der gesamten Anfrage zum Preis für lange Kontexte abgerechnet, nicht nur der Teil, der darüber hinausgeht.
- Gesamt-Input-Token inklusive Cache: Die Summe aus
input_tokens+cache_creation_input_tokens+cache_read_input_tokensbestimmt die Preisstufe. - Output-Token beeinflussen die Stufe nicht: Die Anzahl der Output-Token hat keinen Einfluss darauf, ob die Preisgestaltung für lange Kontexte ausgelöst wird. Wenn sie jedoch ausgelöst wird, wird auch der Output mit dem 1,5-fachen Preis berechnet.
- Unter 200K gilt weiterhin der Standardpreis: Selbst wenn Sie den Beta-Header aktiviert haben, wird zum Standardpreis abgerechnet, solange der Input 200K nicht überschreitet.
Beispielrechnung der Kosten
Szenario: Analyse eines langen Dokuments mit 500.000 Token unter Verwendung von Claude Sonnet 4.6, wobei ein Analysebericht mit 2.000 Token generiert wird.
Input-Kosten: 500.000 Token × $6/MTok = $3,00
Output-Kosten: 2.000 Token × $22,50/MTok = $0,045
Gesamt: $3,045
Gleicher Output, aber mit nur 150.000 Input-Token:
Input-Kosten: 150.000 Token × $3/MTok = $0,45
Output-Kosten: 2.000 Token × $15/MTok = $0,03
Gesamt: $0,48
4 Strategien zum Geldsparen
| Strategie | Ersparnis | Anwendungsfall |
|---|---|---|
| Prompt Caching | Cache-Hits kosten nur 10% | Wiederholte Verwendung desselben langen Dokuments |
| Batch API | 50% Rabatt auf alle Kosten | Batch-Verarbeitung von Aufgaben ohne Echtzeitanforderung |
| Fast Mode (Opus 4.6) | Kein Aufpreis für langen Kontext | Szenarien, die eine schnelle Reaktion erfordern |
| Input unter 200K halten | Vermeidung der 2x-Preise | Dokumente, die in Abschnitten verarbeitet werden können |
💰 Kostenoptimierung: Für Projekte, die häufig lange Kontexte von Claude benötigen, bietet die Plattform APIYI (apiyi.com) flexible Abrechnungsmodelle. In Kombination mit Prompt Caching und der Batch API lassen sich die Kosten pro Aufruf um mehr als 70% senken.
Claude API 1M Kontextfenster: Rate Limits
Nach der Aktivierung des 1M-Kontexts haben Anfragen mit langem Kontext (Input über 200K Token) eigene Rate Limits, die separat von den Limits für Standardanfragen berechnet werden.
Rate Limits für Tier 4
| Limit-Typ | Limit für Standardanfragen | Limit für Anfragen mit langem Kontext |
|---|---|---|
| Max. Input Token/Minute (ITPM) | Sonnet: 2.000.000 / Opus: 2.000.000 | 1.000.000 |
| Max. Output Token/Minute (OTPM) | Sonnet: 400.000 / Opus: 400.000 | 200.000 |
| Max. Anfragen/Minute (RPM) | 4.000 | Proportional reduziert |
Wichtige Hinweise:
- Die Rate Limits für langen Kontext werden unabhängig von den Standard-Limits berechnet und beeinflussen sich nicht gegenseitig.
- Bei Verwendung von Prompt Caching werden Cache-Hit-Token bei den meisten Modellen nicht auf das ITPM-Limit angerechnet.
- Wenn Sie höhere Rate Limits für lange Kontexte benötigen, können Sie sich an das Anthropic-Vertriebsteam wenden, um benutzerdefinierte Limits zu beantragen.
So steigen Sie in Tier 4 auf
| Tier | Anforderung an Gesamteinzahlung | Maximale Einzeleinzahlung | Monatliches Ausgabenlimit |
|---|---|---|---|
| Tier 1 | $5 | $100 | $100 |
| Tier 2 | $40 | $500 | $500 |
| Tier 3 | $200 | $1.000 | $1.000 |
| Tier 4 | $400 | $5.000 | $5.000 |
Sobald die Schwelle für die Gesamteinzahlung erreicht ist, erfolgt das Upgrade automatisch ohne manuelle Prüfung.
Claude API 1M Kontextfenster: 5 Praxisszenarien
Szenario 1: Analyse großer Codebasen
Senden Sie den gesamten Projektcode gebündelt an Claude, um Architekturüberprüfungen, Fehlersuche oder Refactoring-Vorschläge durchzuführen.
import anthropic
import os
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def collect_codebase(directory, extensions=(".py", ".ts", ".js")):
"""Sammelt alle Quelldateien der angegebenen Typen im Projekt"""
code_content = []
for root, dirs, files in os.walk(directory):
# Überspringe Verzeichnisse wie node_modules
dirs[:] = [d for d in dirs if d not in ("node_modules", ".git", "__pycache__")]
for file in files:
if file.endswith(extensions):
filepath = os.path.join(root, file)
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
code_content.append(f"### {filepath}\n```\n{content}\n```")
return "\n\n".join(code_content)
codebase = collect_codebase("./my-project")
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=8192,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Bitte führen Sie eine umfassende Architekturüberprüfung der folgenden Codebasis durch:
{codebase}
Bitte analysieren Sie:
1. Vor- und Nachteile des gesamten Architekturdesigns
2. Potenzielle Sicherheitslücken
3. Vorschläge zur Leistungsoptimierung
4. Punkte zur Verbesserung der Codequalität"""
}]
)
Szenario 2: Umfassende Analyse langer Dokumente
Verarbeitung von extrem langen Dokumenten wie Rechtsverträgen, Sammlungen von Forschungsarbeiten oder Finanzberichten.
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Hier ist eine Sammlung der Finanzberichte des Unternehmens der letzten 12 Monate (ca. 400.000 Token):
{financial_reports}
Bitte erledigen Sie:
1. Trendanalyse der wichtigsten Finanzkennzahlen pro Quartal
2. Analyse der Veränderungen in der Umsatzstruktur und Ableitung der Gründe
3. Bewertung der Wirksamkeit der Kostenkontrolle
4. Ergebnisprognose für das nächste Quartal und Risikohinweise"""
}]
)
Szenario 3: Kombination von langen Multi-Turn-Dialogen mit Extended Thinking
Aktivieren Sie Extended Thinking im langen Kontext, um Claude tiefgehende Schlussfolgerungen ziehen zu lassen:
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
betas=["context-1m-2025-08-07"],
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[{
"role": "user",
"content": f"""Hier ist die vollständige technische Dokumentation und der Quellcode eines komplexen Systems:
{large_technical_document}
Bitte analysieren Sie die Designphilosophie dieses Systems tiefgehend und schlagen Sie Verbesserungen vor."""
}]
)
# Die Token des Extended Thinking summieren sich nicht in den folgenden Dialogen auf
# Die API entfernt automatisch die Thinking-Blöcke der vorherigen Runden
Szenario 4: Kostenreduzierung im langen Kontext durch Prompt Caching
Wenn Sie dasselbe lange Dokument mehrfach unter verschiedenen Aspekten analysieren müssen, kann Prompt Caching die Kosten erheblich senken:
# Erste Anfrage: Dokument im Cache speichern
response1 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"} # Als cachebar markieren
}],
messages=[{"role": "user", "content": "Fasse die Kernargumente dieses Dokuments zusammen"}]
)
# Zweite Anfrage: Cache-Hit, Eingabe-Token kosten nur 10 % der Gebühr
response2 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "Extrahiere alle Datentabellen aus dem Dokument"}]
)
Szenario 5: Stapelverarbeitung langer Dokumente mit der Batch API
Mit der Batch API können Sie zusätzlich zum Preisvorteil des langen Kontexts weitere 50 % Rabatt erhalten:
# Batch-Anfrage erstellen
batch = client.beta.messages.batches.create(
betas=["context-1m-2025-08-07"],
requests=[
{
"custom_id": "doc-analysis-1",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": f"Analysiere Dokument 1: {doc1}"}]
}
},
{
"custom_id": "doc-analysis-2",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": "Analysiere Dokument 2: {doc2}"}]
}
}
]
)
🎯 Praxistipp: In realen Projekten empfehlen wir, zunächst Tests in kleinem Maßstab auf der Plattform APIYI (apiyi.com) durchzuführen, um sicherzustellen, dass Token-Verbrauch und Kosten den Erwartungen entsprechen, bevor Sie mit dem großflächigen Rollout beginnen. Die Plattform bietet detaillierte Dashboards zur Nutzungsstatistik für eine präzise Kostenkontrolle.
Empfehlungen zur Modellauswahl für das Claude API 1M Kontextfenster
Die 4 Modelle, die das 1M-Kontextfenster unterstützen, haben unterschiedliche Schwerpunkte. Die Wahl des richtigen Modells hilft dabei, die optimale Balance zwischen Leistung und Kosten zu finden.
Detaillierter Vergleich der Modelle mit 1M-Kontext-Unterstützung
| Vergleichsdimension | Claude Opus 4.6 | Claude Sonnet 4.6 | Claude Sonnet 4.5 | Claude Sonnet 4 |
|---|---|---|---|---|
| Intelligenzniveau | Am stärksten | Stark | Stark | Mittel-Hoch |
| Standard-Eingabepreis | $5/MTok | $3/MTok | $3/MTok | $3/MTok |
| Preis für langen Kontext (Eingabe) | $10/MTok | $6/MTok | $6/MTok | $6/MTok |
| Fast Mode | Unterstützt (6x Preis) | Nicht unterstützt | Nicht unterstützt | Nicht unterstützt |
| Kontextbewusstsein | Nicht unterstützt | Unterstützt | Unterstützt | Nicht unterstützt |
| Interleaved Thinking | Unterstützt | Unterstützt | Nicht unterstützt | Unterstützt |
| Empfohlene Szenarien | Komplexe Logik, Code-Analyse | Allg. Dokumentenverarbeitung | Multi-Turn-Agent-Dialoge | Tägliche Analyseaufgaben |
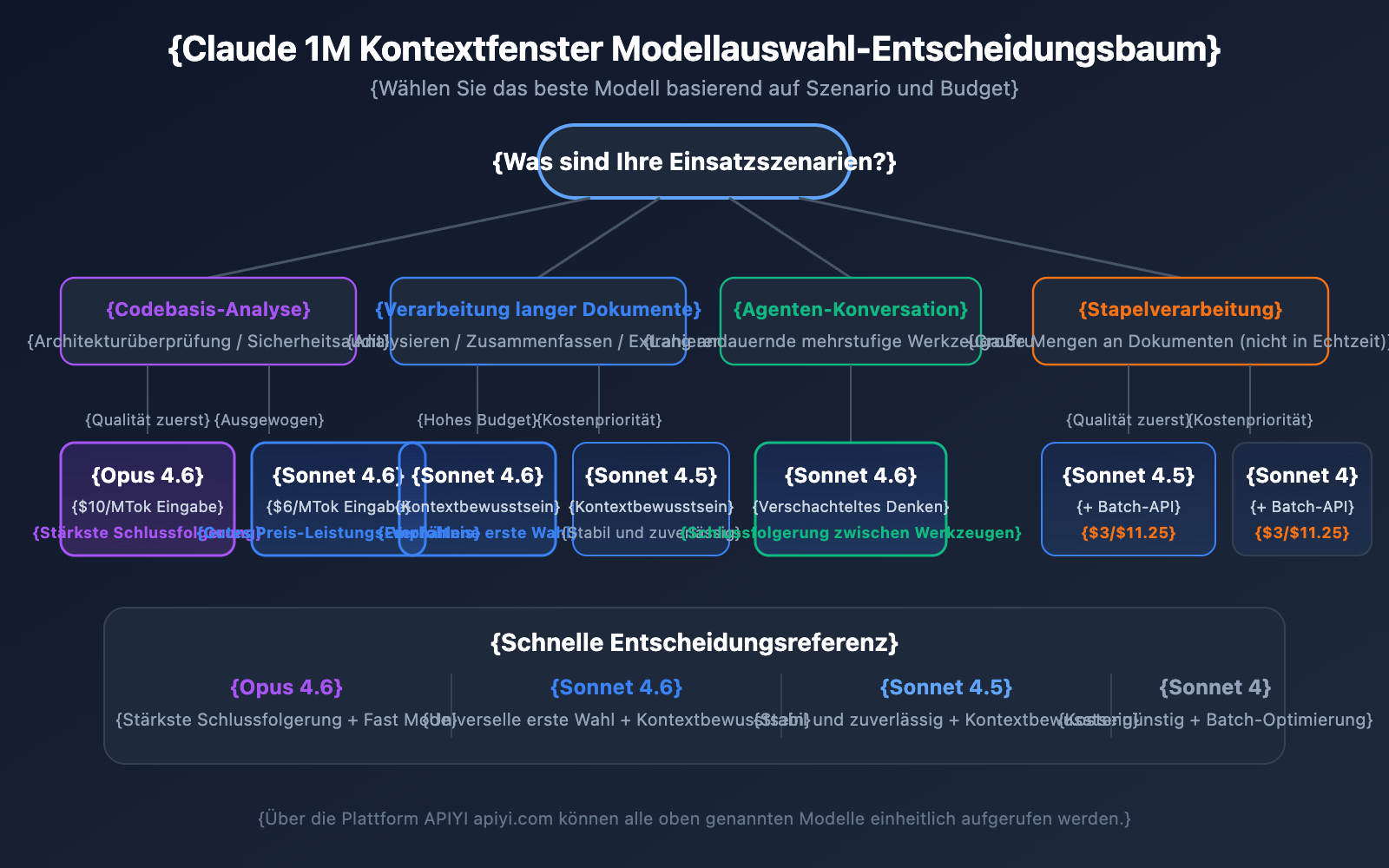
Modellauswahl nach Szenario
Wählen Sie Claude Opus 4.6 für:
- Komplexe Analyseaufgaben, die höchste Schlussfolgerungsfähigkeiten erfordern
- Architekturüberprüfungen und Sicherheitsaudits großer Codebasen
- Echtzeitszenarien, die den Fast Mode benötigen (schnelle Antwort ohne Aufpreis für langen Kontext)
- Anwendungen auf Unternehmensebene, bei denen Qualität Vorrang vor dem Budget hat
Wählen Sie Claude Sonnet 4.6 für:
- Tägliche Analyse langer Dokumente und Extraktion von Zusammenfassungen
- Lange Dialoge, die Kontextbewusstsein (Contextual Awareness) erfordern
- Kostensensible Projekte mit dennoch hohen Qualitätsanforderungen
- Szenarien, die Interleaved Thinking für Schlussfolgerungen zwischen Tool-Aufrufen benötigen
Wählen Sie Claude Sonnet 4.5 / Sonnet 4 für:
- Stapelverarbeitung von Dokumenten (in Kombination mit der Batch API zur Kostensenkung)
- Extraktion strukturierter Informationen und Datenaufbereitung
- Stabile Produktionsumgebungen, die keine der neuesten Modellfunktionen benötigen
💡 Empfehlung: Welches Modell Sie wählen, hängt primär von Ihrem spezifischen Anwendungsfall und Budget ab. Wir empfehlen einen praktischen Vergleichstest über die Plattform APIYI (apiyi.com). Die Plattform unterstützt den Zugriff auf alle oben genannten Modelle über eine einheitliche Schnittstelle, was einen schnellen Wechsel und eine einfache Evaluierung ermöglicht.
Referenz zur Token-Schätzung für das Claude API 1M Kontextfenster
Bei der Planung der Nutzung langer Kontexte ist es wichtig, den Token-Verbrauch verschiedener Inhaltstypen zu verstehen:
| Inhaltstyp | Ungefähre Token-Anzahl | Kapazität im 1M-Fenster |
|---|---|---|
| Englischer Text | ~1 Token / 4 Zeichen | ca. 3 Mio. englische Zeichen |
| Chinesischer Text | ~1 Token / 1,5 Zeichen | ca. 750.000 chinesische Zeichen |
| Python-Code | ~1 Token / 3,5 Zeichen | ca. 2,5 Mio. Zeichen Code |
| Normale Webseite (10KB) | ~2.500 Token | ca. 400 Webseiten |
| Großes Dokument (100KB) | ~25.000 Token | ca. 40 Dokumente |
| Forschungsarbeit PDF (500KB) | ~125.000 Token | ca. 8 Arbeiten |
Claude API 1M Kontextfenster und Context Awareness
Claude Sonnet 4.6, Sonnet 4.5 und Haiku 4.5 verfügen über Context Awareness (Kontextbewusstsein). Das Modell ist in der Lage, die verbleibende Kapazität des Kontextfensters in Echtzeit zu verfolgen und das Token-Budget in langen Dialogen intelligenter zu verwalten.
Funktionsweise:
Zu Beginn eines Dialogs erhält Claude Informationen über die gesamte Kontextkapazität:
<budget:token_budget>1000000</budget:token_budget>
Nach jedem Tool-Aufruf erhält das Modell ein Update zur verbleibenden Kapazität:
<system_warning>Token usage: 350000/1000000; 650000 remaining</system_warning>
Das bedeutet, dass Claude innerhalb des 1M-Kontextfensters zu Folgendem in der Lage ist:
- Präzises Management des Token-Budgets: Das Kontextfenster wird nicht plötzlich in einer späten Phase des Dialogs erschöpft.
- Angemessene Zuweisung der Ausgabelänge: Die Detailtiefe der Antworten wird basierend auf der verbleibenden Kapazität angepasst.
- Unterstützung für extrem lange Agent-Sitzungen: Aufgaben in Agent-Workflows werden kontinuierlich bis zum Abschluss ausgeführt.
Claude API 1M Kontextfenster-Management-Strategie: Compaction
Wenn die Dialoglänge das Limit des 1M-Kontextfensters erreicht, bietet die Claude API die Funktion Compaction (Komprimierung) an, um das Gespräch fortzusetzen. Compaction ist ein serverseitiger Zusammenfassungsmechanismus, der frühere Dialoginhalte automatisch in prägnante Zusammenfassungen komprimiert. Dies gibt Kontextraum frei und ermöglicht so extrem lange Dialoge, die über die ursprünglichen Grenzen des Kontextfensters hinausgehen.
Derzeit ist die Compaction-Funktion für Claude Opus 4.6 als Beta-Version verfügbar. Für Entwickler, die lang laufende Agent-Aufgaben in einem 1M-Kontext ausführen müssen, ist Compaction die bevorzugte Strategie zur Kontextverwaltung.
Darüber hinaus bietet die Claude API Möglichkeiten zur Kontextbearbeitung (Context Editing), darunter:
- Tool Result Clearing: Löschen alter Tool-Aufrufergebnisse in Agent-Workflows, um Token freizugeben.
- Thinking Block Clearing: Aktives Löschen von Denkprozessen (Thinking Blocks) aus vorherigen Runden, um die Kontextnutzung weiter zu optimieren.
Diese Strategien können in Kombination mit dem 1M-Kontextfenster genutzt werden, um in Szenarien mit extrem großem Kontext das beste Gleichgewicht zwischen Leistung und Kosten zu erzielen.
Wichtige Hinweise zum Claude API 1M Kontextfenster
Bei der praktischen Nutzung des 1M-Kontextfensters gibt es einige technische Details, die leicht übersehen werden:
-
Neue Modelle geben Validierungsfehler zurück statt stillschweigend abzuschneiden: Ab Claude Sonnet 3.7 gibt die API einen Validierungsfehler zurück, wenn die Gesamtzahl aus Prompt- und Output-Token das Kontextfenster überschreitet, anstatt den Inhalt einfach abzuschneiden. Es wird empfohlen, vor dem Senden einer Anfrage die Token-Zähl-API zu verwenden, um die Token-Menge abzuschätzen.
-
Variabler Token-Verbrauch für Bilder und PDFs: Die Token-Berechnung für multimodale Inhalte unterscheidet sich von reinem Text. Bilder derselben Größe können eine sehr unterschiedliche Anzahl an Token verbrauchen. Bei intensiver Nutzung von Bildern sollte ein ausreichender Token-Puffer eingeplant werden.
-
Beschränkungen der Anfrageröße (Request Size Limits): Auch wenn das Kontextfenster 1M Token unterstützt, unterliegen die HTTP-Anfragen selbst Größenbeschränkungen. Beim Senden von extrem großen Textmengen müssen die Limits auf HTTP-Ebene beachtet werden.
-
Cache-bewusste Ratenbegrenzungen: Bei Verwendung von Prompt Caching zählen Cache-Treffer nicht gegen die ITPM-Ratenbegrenzung (Requests per Minute). Das bedeutet, dass in 1M-Kontext-Szenarien die geschickte Nutzung des Caches den tatsächlichen Durchsatz erheblich steigern kann.
Häufig gestellte Fragen
Q1: Wie kann ich feststellen, ob meine Anfrage nach den Tarifen für langen Kontext abgerechnet wird?
Überprüfen Sie das usage-Objekt in der API-Antwort. Addieren Sie die drei Felder input_tokens, cache_creation_input_tokens und cache_read_input_tokens. Wenn die Summe 200.000 überschreitet, wird die gesamte Anfrage zum Preis für langen Kontext abgerechnet. Bei Aufrufen über die Plattform APIYI (apiyi.com) zeigt das Dashboard für die Nutzungsstatistik die Abrechnungsstufe für jede Anfrage übersichtlich an.
Q2: Welche Dateitypen unterstützt das 1M-Kontextfenster?
Das 1M-Kontextfenster der Claude API unterstützt Textformate wie Reintext, Code und Markdown sowie Bilder und PDF-Dateien. Beachten Sie jedoch, dass der Token-Verbrauch für Bilder und PDFs in der Regel höher und nicht fix ist. Wenn viele Bilder mit langem Text kombiniert werden, können die Limits für die Anfrageröße (Request Size Limits) erreicht werden. Es wird empfohlen, zunächst kleine Tests auf der Plattform APIYI (apiyi.com) durchzuführen, um den tatsächlichen Token-Verbrauch zu bestätigen, bevor Sie die Anwendung skalieren.
Q3: Belegen die Token von Extended Thinking das 1M-Kontextfenster?
Die Extended Thinking Token der aktuellen Runde werden auf das Kontextfenster angerechnet. Die Claude API entfernt jedoch automatisch die Thinking Blocks aus vorherigen Runden, sodass diese sich in nachfolgenden Dialogen nicht ansammeln. Das bedeutet, dass Sie Extended Thinking im 1M-Kontext sicher verwenden können, ohne befürchten zu müssen, dass der Denkprozess massiv Kontextraum verbraucht.
Q4: Was kann ich tun, wenn ich die Bedingungen für Tier 4 nicht erfülle?
Derzeit ist das 1M-Kontextfenster nur für Organisationen in Tier 4 oder mit benutzerdefinierten Ratenbegrenzungen offen. Um Tier 4 zu erreichen, ist lediglich eine kumulierte Aufladung von 400 $ erforderlich; das Upgrade erfolgt nach der Aufladung automatisch. Wenn Sie Tier 4 vorübergehend nicht erreichen können, ziehen Sie folgende Optionen in Betracht: ① Reduzieren Sie die Eingabe durch Segmentierung auf unter 200K; ② Nutzen Sie Retrieval-Augmented Generation (RAG), um relevante Inhalte zu extrahieren; ③ Kontaktieren Sie das Anthropic-Vertriebsteam für individuelle Lösungen.
Q5: Wie aktiviere ich die Funktion in AWS Bedrock und Google Vertex AI?
Das 1M-Kontextfenster ist in AWS Bedrock, Google Vertex AI und Microsoft Foundry verfügbar. Die Aktivierung unterscheidet sich je nach Plattform geringfügig – bei Bedrock erfolgt sie durch Angabe entsprechender Parameter im InvokeModel-Aufruf, bei Vertex AI über die API-Konfiguration. Einzelheiten zur Konfiguration entnehmen Sie bitte der offiziellen Dokumentation der jeweiligen Plattform.
Checkliste für Best Practices zum Claude API 1M Kontextfenster
Bei der Integration des 1M-Kontextfensters in reale Projekte empfiehlt es sich, die folgenden Best Practices zu beachten:
Entwicklungsphase
- Vorab-Schätzung mit der Token Counting API: Bevor Sie tatsächliche Anfragen senden, sollten Sie die Token Counting API nutzen, um die Anzahl der Eingabe-Token zu schätzen. So vermeiden Sie unerwartete Kosten durch die Preisgestaltung für lange Kontexte.
- Angemessene
max_tokensfestlegen: Der Parametermax_tokensbeeinflusst die Berechnung der Rate Limits nicht (OTPM wird basierend auf der tatsächlichen Ausgabe berechnet). Sie können einen höheren Wert festlegen, um sicherzustellen, dass die Ausgabe nicht abgeschnitten wird. - Tests in Etappen: Validieren Sie die Wirkung Ihrer Eingabeaufforderungs-Vorlagen (Prompt-Templates) zunächst mit kleinen Datenmengen, bevor Sie den Umfang der Eingabe schrittweise erhöhen.
Produktionsumgebung
- Prompt Caching bevorzugen: Bei wiederholt verwendeten langen Dokumenten kann Prompt Caching die Eingabekosten für die im Cache gespeicherten Teile auf 10 % des Standardpreises senken. Zudem zählen die Cache-Treffer-Token nicht zum ITPM-Rate-Limit.
- Batch API für nicht-echtzeitkritische Aufgaben: Die Batch API bietet einen zusätzlichen Rabatt von 50 % auf die Preise für lange Kontexte. In Kombination liegen die Kosten dann nur noch bei etwa 60 % des Standardpreises.
- Feld
usageüberwachen: Überprüfen Sie nach jeder Anfrage dasusage-Objekt in der Antwort und richten Sie einen Mechanismus für Kostenwarnungen ein. - Retries bei 429-Fehlern: Anfragen mit langem Kontext haben eigene Rate Limits. Wenn ein 429-Fehler auftritt, prüfen Sie den
retry-after-Header für angemessene Wiederholungsversuche.
Kostenkontrolle
- 200K-Schwellenwert kontrollieren: Wenn die Eingabe nahe an 200K Token liegt, sollten Sie in Erwägung ziehen, die Eingabeaufforderung zu kürzen, um die 2-fache Preisberechnung zu vermeiden.
- Wahl des passenden Modells: Die Sonnet-Serie ist etwa 40 % günstiger als Opus. Für alltägliche Aufgaben sollte Sonnet bevorzugt werden.
- Caching zur Entlastung der Rate Limits nutzen: Bei einer Cache-Trefferquote von 80 % kann der tatsächliche Durchsatz das Fünffache des nominalen Limits erreichen.
Claude API 1M Kontextfenster: Zusammenfassung
Das 1M-Kontextfenster der Claude API ermöglicht es Entwicklern, Inhalte von etwa 750.000 Wörtern auf einmal zu verarbeiten. Dies bietet enorme Möglichkeiten für die Analyse von Codebasen, die Verarbeitung langer Dokumente und komplexe Dialogszenarien. Hier die wichtigsten Punkte im Rückblick:
- Aktivierung mit einer Zeile Code: Fügen Sie einfach den Header
anthropic-beta: context-1m-2025-08-07hinzu. - Unterstützung für 4 Modelle: Claude Opus 4.6, Sonnet 4.6, Sonnet 4.5 und Sonnet 4.
- Transparente Preisgestaltung: Ab 200K Token gilt der 2-fache Preis für die Eingabe und der 1,5-fache für die Ausgabe; unter 200K Token gilt weiterhin der Standardpreis.
- Unabhängige Rate Limits: Anfragen mit langem Kontext beeinflussen nicht das Kontingent für Standardanfragen.
- Vielfältige Optimierungsmöglichkeiten: Prompt Caching, Batch API und Fast Mode können kombiniert werden, um die Kosten zu senken.
Wir empfehlen, die Funktionen des Claude 1M-Kontextfensters über APIYI (apiyi.com) auszuprobieren und die für Ihr spezifisches Geschäftsszenario beste Lösung zu finden.
Referenzen
-
Offizielle Anthropic-Dokumentation – Context Windows: Technische Erläuterungen zum Kontextfenster der Claude API
- Link:
platform.claude.com/docs/en/build-with-claude/context-windows
- Link:
-
Offizielle Anthropic-Dokumentation – Pricing: Vollständige Preisübersicht der Claude API
- Link:
platform.claude.com/docs/en/about-claude/pricing
- Link:
-
Offizielle Anthropic-Dokumentation – Rate Limits: Erläuterungen zu Ratenbegrenzungen und Usage Tiers
- Link:
platform.claude.com/docs/en/api/rate-limits
- Link:
📝 Autor: APIYI Team | Weitere Tutorials zur Nutzung von KI-Modell-APIs finden Sie im Hilfe-Center von APIYI unter apiyi.com.