Bagaimana cara menggunakan konteks super panjang lebih dari 200 ribu Token dalam panggilan API adalah kebutuhan nyata yang dihadapi semakin banyak pengembang. Anthropic telah meluncurkan fitur Jendela Konteks 1 Juta Token (1M Context Window) Claude API, yang memungkinkan satu permintaan untuk memproses konten teks sekitar 750 ribu kata—setara dengan membaca seluruh "Dream of the Red Chamber" ditambah "Romance of the Three Kingdoms" sekaligus.
Nilai Inti: Setelah membaca artikel ini, Anda akan menguasai cara lengkap untuk mengaktifkan jendela konteks 1M Claude API, memahami aturan perhitungan harga, dan mendapatkan template kode untuk 5 skenario praktis.

Detail Harga Jendela Konteks 1M Claude API
Harga untuk konteks panjang adalah salah satu hal yang paling dikhawatirkan oleh para pengembang. Claude API menggunakan strategi penagihan bertingkat—apakah Token input melebihi 200K akan menentukan tingkat biaya Anda.
Perbandingan Harga Konteks Panjang Berbagai Model
| Model | Input Standar (≤200K) | Input Konteks Panjang (>200K) | Output Standar | Output Konteks Panjang | Multiplier |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $10/MTok | $25/MTok | $37.50/MTok | Input 2x / Output 1.5x |
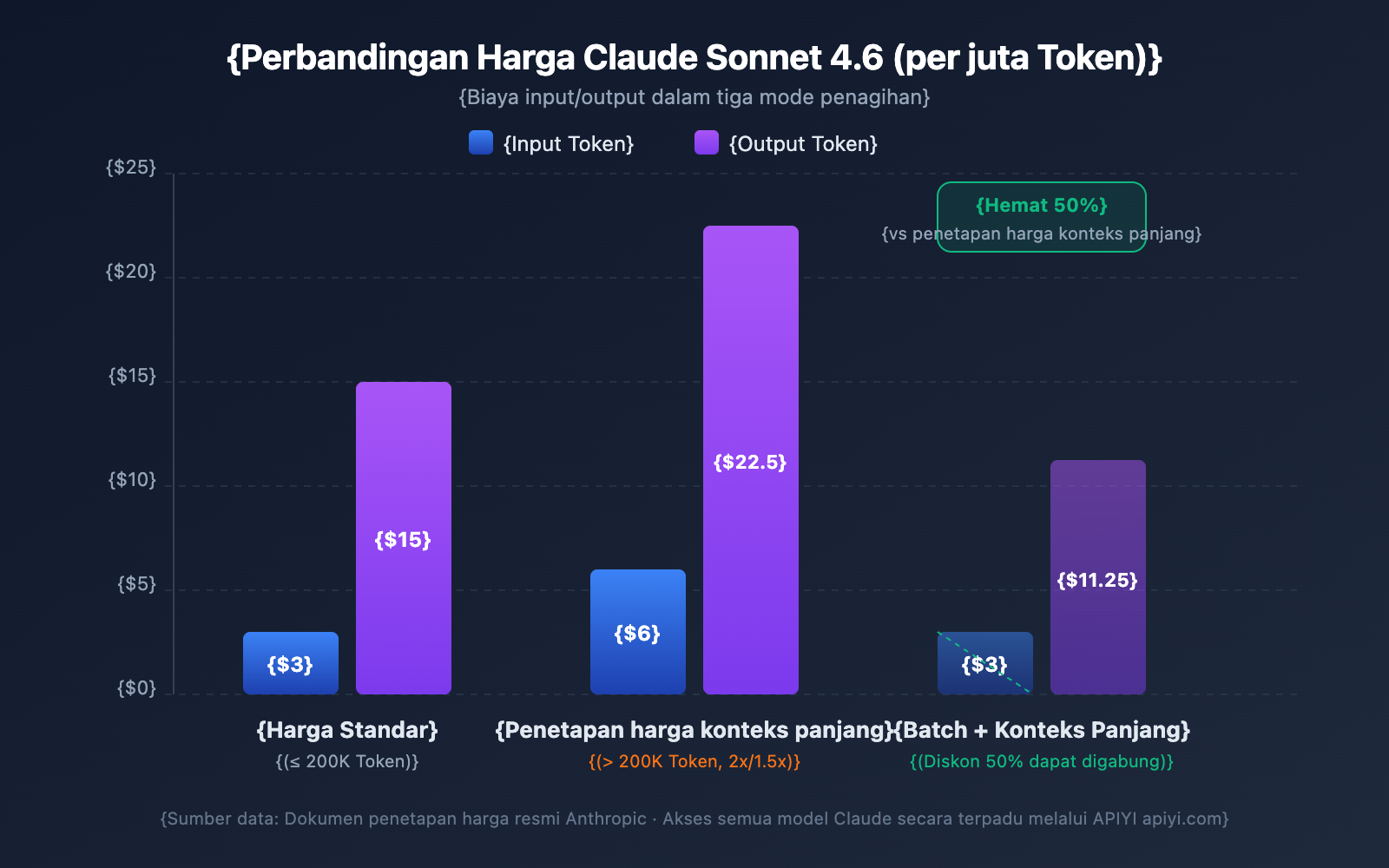
| Claude Sonnet 4.6 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Input 2x / Output 1.5x |
| Claude Sonnet 4.5 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Input 2x / Output 1.5x |
| Claude Sonnet 4 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Input 2x / Output 1.5x |
MTok = Juta Token
Aturan Perhitungan Harga
Pahami beberapa aturan kunci berikut untuk menghindari biaya yang membengkak di luar ekspektasi:
- Ambang batas 200K adalah sakelar: Begitu total Token input melebihi 200K, seluruh Token dalam permintaan tersebut akan dikenakan harga konteks panjang, bukan hanya bagian yang melebihi ambang batas saja.
- Total Token input mencakup cache: Jumlah dari
input_tokens+cache_creation_input_tokens+cache_read_input_tokensmenentukan tingkatan harga. - Token output tidak memengaruhi tingkatan: Jumlah Token output tidak menentukan apakah harga konteks panjang dipicu atau tidak, namun jika sudah terpicu, output juga akan dikenakan biaya 1,5 kali lipat.
- Di bawah 200K tetap menggunakan harga standar: Meskipun Anda mengaktifkan beta header, selama input tidak melebihi 200K, biaya tetap dihitung dengan harga standar.
Contoh Perhitungan Biaya
Skenario: Menggunakan Claude Sonnet 4.6 untuk menganalisis dokumen panjang berisi 500.000 Token dan menghasilkan laporan analisis sebanyak 2.000 Token.
Biaya Input: 500.000 Token × $6/MTok = $3.00
Biaya Output: 2.000 Token × $22.50/MTok = $0.045
Total: $3.045
Dengan output yang sama, jika input hanya 150.000 Token:
Biaya Input: 150.000 Token × $3/MTok = $0.45
Biaya Output: 2.000 Token × $15/MTok = $0.03
Total: $0.48
4 Strategi Menghemat Biaya
| Strategi | Besar Penghematan | Skenario Penggunaan |
|---|---|---|
| Prompt Caching | Cache hit hanya dikenakan biaya 10% | Penggunaan berulang dokumen panjang yang sama |
| Batch API | Diskon 50% untuk semua biaya | Tugas pemrosesan batch non-real-time |
| Fast Mode (Opus 4.6) | Tanpa biaya tambahan konteks panjang | Skenario yang membutuhkan respons cepat |
| Kontrol input di bawah 200K | Menghindari harga 2x lipat | Dokumen yang bisa diproses secara bertahap |
💰 Optimasi Biaya: Untuk proyek yang membutuhkan pemanggilan konteks panjang Claude secara sering, Anda bisa mendapatkan skema penagihan yang fleksibel melalui platform APIYI (apiyi.com). Dengan menggabungkan Prompt Caching dan Batch API, biaya per pemanggilan dapat dikurangi hingga lebih dari 70%.
Batas Kecepatan (Rate Limit) Jendela Konteks 1M Claude API
Setelah mengaktifkan konteks 1M, permintaan konteks panjang (input lebih dari 200K Token) memiliki batas kecepatan independen yang dihitung terpisah dari batas permintaan standar.
Batas Kecepatan Tier 4
| Jenis Batasan | Batas Permintaan Standar | Batas Permintaan Konteks Panjang |
|---|---|---|
| Maksimal Token Input/Menit (ITPM) | Sonnet: 2.000.000 / Opus: 2.000.000 | 1.000.000 |
| Maksimal Token Output/Menit (OTPM) | Sonnet: 400.000 / Opus: 400.000 | 200.000 |
| Maksimal Permintaan/Menit (RPM) | 4.000 | Dikurangi secara proporsional |
Catatan Penting:
- Batas kecepatan konteks panjang dihitung secara independen dari batas kecepatan standar dan tidak saling memengaruhi.
- Saat menggunakan Prompt Caching, Token yang terkena cache hit tidak dihitung ke dalam batas ITPM (pada sebagian besar model).
- Jika Anda membutuhkan batas kecepatan konteks panjang yang lebih tinggi, Anda dapat menghubungi tim penjualan Anthropic untuk mengajukan batas khusus.
Cara Upgrade ke Tier 4
| Tier | Syarat Akumulasi Top-up | Maksimal Top-up Sekali | Batas Pengeluaran Bulanan |
|---|---|---|---|
| Tier 1 | $5 | $100 | $100 |
| Tier 2 | $40 | $500 | $500 |
| Tier 3 | $200 | $1.000 | $1.000 |
| Tier 4 | $400 | $5.000 | $5.000 |
Setelah mencapai ambang batas akumulasi top-up, akun akan di-upgrade secara otomatis tanpa perlu peninjauan manual.
5 Skenario Praktis Claude API dengan Jendela Konteks 1M
Skenario 1: Analisis Basis Kode Skala Besar
Kirimkan seluruh kode proyek ke Claude untuk melakukan tinjauan arsitektur, pelacakan bug, atau saran refactoring.
import anthropic
import os
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def collect_codebase(directory, extensions=(".py", ".ts", ".js")):
"""Mengumpulkan semua file kode sumber dengan ekstensi tertentu dalam proyek"""
code_content = []
for root, dirs, files in os.walk(directory):
# Lewati direktori seperti node_modules
dirs[:] = [d for d in dirs if d not in ("node_modules", ".git", "__pycache__")]
for file in files:
if file.endswith(extensions):
filepath = os.path.join(root, file)
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
code_content.append(f"### {filepath}\n```\n{content}\n```")
return "\n\n".join(code_content)
codebase = collect_codebase("./my-project")
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=8192,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Tolong lakukan tinjauan arsitektur menyeluruh terhadap basis kode berikut:
{codebase}
Mohon analisis:
1. Kelebihan dan kekurangan desain arsitektur secara keseluruhan
2. Potensi celah keamanan
3. Saran optimasi performa
4. Poin-poin peningkatan kualitas kode"""
}]
)
Skenario 2: Analisis Komprehensif Dokumen Panjang
Memproses dokumen super panjang seperti kontrak hukum, kumpulan makalah riset, atau laporan keuangan.
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Berikut adalah kumpulan laporan keuangan perusahaan selama 12 bulan terakhir (sekitar 400 ribu Token):
{financial_reports}
Mohon selesaikan:
1. Analisis tren indikator keuangan inti setiap kuartal
2. Perubahan struktur pendapatan dan inferensi penyebabnya
3. Evaluasi efektivitas pengendalian biaya
4. Prediksi kinerja kuartal berikutnya dan peringatan risiko"""
}]
)
Skenario 3: Kombinasi Percakapan Panjang Multi-putaran dengan Extended Thinking
Aktifkan Extended Thinking dalam konteks panjang agar Claude dapat melakukan penalaran mendalam:
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
betas=["context-1m-2025-08-07"],
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[{
"role": "user",
"content": f"""Berikut adalah dokumen teknis lengkap dan kode sumber dari sebuah sistem yang kompleks:
{large_technical_document}
Mohon analisis secara mendalam filosofi desain sistem ini dan berikan solusi peningkatannya."""
}]
)
# Token dari Extended Thinking tidak akan terakumulasi dalam percakapan selanjutnya
# API akan secara otomatis menghapus blok thinking dari putaran sebelumnya
Skenario 4: Menggunakan Prompt Caching untuk Mengurangi Biaya Konteks Panjang
Saat Anda perlu melakukan beberapa analisis dari dimensi yang berbeda pada dokumen panjang yang sama, Prompt Caching dapat memangkas biaya secara signifikan:
# Permintaan pertama: Cache dokumen panjang
response1 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"} # Tandai sebagai dapat di-cache
}],
messages=[{"role": "user", "content": "Rangkum poin-poin utama dari dokumen ini"}]
)
# Permintaan kedua: Cache hit, token input hanya dikenakan biaya 10%
response2 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "Ekstrak semua tabel data dalam dokumen ini"}]
)
Skenario 5: Pemrosesan Dokumen Panjang Secara Massal dengan Batch API
Menggunakan Batch API dapat memberikan diskon tambahan 50% di atas harga konteks panjang:
# Membuat permintaan batch
batch = client.beta.messages.batches.create(
betas=["context-1m-2025-08-07"],
requests=[
{
"custom_id": "doc-analysis-1",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": f"Analisis dokumen 1: {doc1}"}]
}
},
{
"custom_id": "doc-analysis-2",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": "Analisis dokumen 2: {doc2}"}]
}
}
]
)
🎯 Saran Praktis: Dalam proyek nyata, kami menyarankan untuk melakukan pengujian skala kecil terlebih dahulu melalui platform APIYI (apiyi.com) untuk memastikan penggunaan Token dan biaya sesuai ekspektasi sebelum melakukan deployment skala besar. Platform ini menyediakan panel statistik penggunaan yang mendetail untuk memudahkan pengendalian biaya secara presisi.
Saran Pemilihan Model Jendela Konteks Claude API 1M
Keempat model yang mendukung konteks 1M memiliki fokus yang berbeda. Memilih model yang tepat akan membantu Anda menemukan keseimbangan terbaik antara efektivitas dan biaya.
Perbandingan Detail Model yang Mendukung Konteks 1M
| Dimensi Perbandingan | Claude Opus 4.6 | Claude Sonnet 4.6 | Claude Sonnet 4.5 | Claude Sonnet 4 |
|---|---|---|---|---|
| Tingkat Kecerdasan | Terkuat | Kuat | Kuat | Menengah ke Atas |
| Harga Input Standar | $5/MTok | $3/MTok | $3/MTok | $3/MTok |
| Harga Input Konteks Panjang | $10/MTok | $6/MTok | $6/MTok | $6/MTok |
| Fast Mode | Mendukung (Harga 6x) | Tidak mendukung | Tidak mendukung | Tidak mendukung |
| Kesadaran Konteks | Tidak mendukung | Mendukung | Mendukung | Tidak mendukung |
| Interleaved Thinking | Mendukung | Mendukung | Tidak mendukung | Mendukung |
| Skenario Rekomendasi | Penalaran kompleks, analisis kode | Pemrosesan dokumen panjang umum | Sesi agen multi-putaran | Tugas analisis harian |

Memilih Model Berdasarkan Skenario
Skenario untuk memilih Claude Opus 4.6:
- Tugas analisis kompleks yang membutuhkan kemampuan penalaran terkuat.
- Tinjauan arsitektur dan audit keamanan untuk basis kode skala besar.
- Skenario real-time yang membutuhkan Fast Mode (respons cepat tanpa biaya tambahan konteks panjang).
- Aplikasi tingkat perusahaan dengan anggaran yang cukup dan mengutamakan kualitas.
Skenario untuk memilih Claude Sonnet 4.6:
- Analisis dokumen panjang harian dan ekstraksi ringkasan.
- Percakapan panjang yang membutuhkan kemampuan kesadaran konteks.
- Proyek yang sensitif terhadap biaya namun memiliki standar kualitas yang tinggi.
- Membutuhkan Interleaved Thinking untuk penalaran di antara pemanggilan alat (tool calls).
Skenario untuk memilih Claude Sonnet 4.5 / Sonnet 4:
- Pemrosesan dokumen massal (dikombinasikan dengan Batch API untuk menekan biaya).
- Ekstraksi informasi terstruktur dan perapian data.
- Lingkungan produksi stabil yang tidak memerlukan fitur model terbaru.
💡 Saran Pemilihan: Model mana yang akan dipilih sangat bergantung pada skenario aplikasi spesifik dan anggaran Anda. Kami menyarankan untuk melakukan pengujian perbandingan nyata melalui platform APIYI (apiyi.com). Platform ini mendukung pemanggilan antarmuka terpadu untuk semua model di atas, memudahkan Anda untuk beralih dan melakukan evaluasi dengan cepat.
Referensi Estimasi Token Jendela Konteks Claude API 1M
Saat merencanakan penggunaan konteks panjang, sangat penting untuk memahami konsumsi Token untuk berbagai jenis konten:
| Jenis Konten | Perkiraan Jumlah Token | Kapasitas Jendela 1M |
|---|---|---|
| Teks Bahasa Inggris | ~1 Token / 4 karakter | Sekitar 3 juta karakter Inggris |
| Teks Bahasa Mandarin | ~1 Token / 1,5 karakter | Sekitar 750 ribu karakter Mandarin |
| Kode Python | ~1 Token / 3,5 karakter | Sekitar 2,5 juta karakter kode |
| Halaman Web Biasa (10KB) | ~2.500 Token | Sekitar 400 halaman web |
| Dokumen Besar (100KB) | ~25.000 Token | Sekitar 40 dokumen |
| PDF Makalah Riset (500KB) | ~125.000 Token | Sekitar 8 makalah |
Jendela Konteks 1M Claude API dan Kesadaran Konteks
Claude Sonnet 4.6, Sonnet 4.5, dan Haiku 4.5 memiliki kemampuan Context Awareness (Kesadaran Konteks). Model ini mampu melacak sisa kapasitas jendela konteks secara real-time dan mengelola anggaran Token dengan lebih cerdas dalam percakapan yang panjang.
Cara Kerja:
Saat percakapan dimulai, Claude akan menerima informasi total kapasitas konteks:
<budget:token_budget>1000000</budget:token_budget>
Setelah setiap pemanggilan alat (tool call), model akan menerima pembaruan sisa kapasitas:
<system_warning>Token usage: 350000/1000000; 650000 remaining</system_warning>
Ini berarti dalam jendela konteks 1M, Claude mampu:
- Mengelola anggaran Token dengan presisi: Tidak akan tiba-tiba kehabisan konteks di akhir percakapan.
- Mengalokasikan panjang output secara wajar: Menyesuaikan tingkat detail jawaban berdasarkan sisa kapasitas yang ada.
- Mendukung sesi agen yang sangat panjang: Terus menjalankan tugas dalam alur kerja Agent hingga selesai.
Strategi Manajemen Jendela Konteks 1M Claude API: Compaction
Ketika panjang percakapan mendekati batas jendela konteks 1M, Claude API menyediakan fitur Compaction (Kompresi) untuk melanjutkan percakapan. Compaction adalah mekanisme ringkasan di sisi server yang secara otomatis mengompres konten awal percakapan menjadi ringkasan singkat, sehingga membebaskan ruang konteks dan mendukung percakapan super panjang yang melampaui batas jendela konteks.
Saat ini, fitur Compaction tersedia dalam bentuk Beta pada Claude Opus 4.6. Bagi pengembang yang perlu menjalankan tugas Agent dalam durasi lama dalam konteks 1M, Compaction adalah strategi utama untuk mengelola konteks.
Selain itu, Claude API juga menyediakan kemampuan Context Editing (Pengeditan Konteks), yang meliputi:
- Tool Result Clearing: Menghapus hasil pemanggilan alat yang lama dalam alur kerja Agent untuk membebaskan Token.
- Thinking Block Clearing: Secara aktif menghapus konten pemikiran dari putaran sebelumnya untuk lebih mengoptimalkan pemanfaatan konteks.
Strategi-strategi ini dapat digunakan bersama dengan jendela konteks 1M untuk memberikan performa dan keseimbangan biaya terbaik dalam skenario konteks super panjang.
Hal-hal yang Perlu Diperhatikan dalam Jendela Konteks 1M Claude API
Dalam penggunaan praktis jendela konteks 1M, ada beberapa detail teknis yang sering terlewatkan:
-
Model baru mengembalikan kesalahan validasi, bukan pemotongan diam-diam: Mulai dari Claude Sonnet 3.7, ketika total prompt dan output Token melebihi jendela konteks, API akan mengembalikan kesalahan validasi, bukan memotong konten secara diam-diam. Disarankan untuk menggunakan Token Counting API guna memperkirakan jumlah Token sebelum mengirim permintaan.
-
Konsumsi Token gambar dan PDF tidak tetap: Perhitungan Token untuk konten multimodal berbeda dengan teks biasa. Gambar dengan ukuran yang sama bisa mengonsumsi jumlah Token yang sangat berbeda. Berikan margin Token yang cukup saat menggunakan banyak gambar.
-
Batasan Ukuran Permintaan (Request Size Limits): Meskipun jendela konteks mendukung 1M Token, permintaan HTTP itu sendiri memiliki batasan ukuran. Saat mengirim teks yang sangat besar, Anda perlu memperhatikan batasan di level HTTP.
-
Batas Kecepatan Sadar Cache (Cache-aware Rate Limits): Saat menggunakan Prompt Caching, Token yang terkena hit cache tidak dihitung ke dalam batas kecepatan ITPM. Ini berarti dalam skenario konteks 1M, pemanfaatan cache yang tepat dapat meningkatkan throughput aktual secara signifikan.
Pertanyaan Umum (FAQ)
Q1: Bagaimana cara memastikan apakah permintaan saya dikenakan biaya harga konteks panjang?
Periksa objek usage dalam respons API. Jumlahkan tiga kolom: input_tokens, cache_creation_input_tokens, dan cache_read_input_tokens. Jika totalnya melebihi 200.000, maka seluruh permintaan akan dikenakan harga konteks panjang. Saat memanggil melalui platform APIYI (apiyi.com), panel statistik penggunaan akan dengan jelas menandai tingkat penagihan untuk setiap permintaan.
Q2: Jenis file apa saja yang didukung oleh jendela konteks 1M?
Jendela konteks 1M Claude API mendukung format teks seperti teks biasa, kode, Markdown, serta mendukung file gambar dan PDF. Namun perlu dicatat bahwa konsumsi Token untuk gambar dan PDF biasanya besar dan tidak tetap. Ketika banyak gambar digunakan bersama dengan teks panjang, hal itu mungkin akan menyentuh Batasan Ukuran Permintaan (Request Size Limits). Disarankan untuk melakukan pengujian skala kecil di platform APIYI (apiyi.com) terlebih dahulu untuk mengonfirmasi konsumsi Token aktual sebelum penggunaan skala besar.
Q3: Apakah Token dari Extended Thinking akan memakan jendela konteks 1M?
Token Extended Thinking pada putaran saat ini akan dihitung ke dalam jendela konteks. Namun, Claude API akan secara otomatis melepaskan blok pemikiran (thinking blocks) dari putaran sebelumnya, sehingga tidak akan terakumulasi dalam percakapan selanjutnya. Ini berarti Anda dapat menggunakan Extended Thinking dengan aman dalam konteks 1M tanpa khawatir proses pemikiran akan menghabiskan banyak ruang konteks.
Q4: Apa yang harus dilakukan jika tidak memenuhi syarat Tier 4?
Saat ini, jendela konteks 1M hanya terbuka untuk organisasi dengan Tier 4 dan batas kecepatan kustom. Untuk mencapai Tier 4, Anda hanya perlu melakukan isi ulang kumulatif sebesar $400, dan akun akan ditingkatkan secara otomatis setelah pengisian. Jika Anda belum bisa mencapai Tier 4 untuk sementara waktu, Anda dapat mempertimbangkan: ① Mengontrol input di bawah 200K melalui pemrosesan tersegmentasi; ② Menggunakan solusi Retrieval-Augmented Generation (RAG) untuk mengekstrak konten utama; ③ Menghubungi tim penjualan Anthropic untuk menanyakan solusi kustom.
Q5: Bagaimana cara mengaktifkannya di AWS Bedrock dan Google Vertex AI?
Jendela konteks 1M tersedia di AWS Bedrock, Google Vertex AI, dan Microsoft Foundry. Cara pengaktifannya sedikit berbeda di setiap platform—Bedrock melalui penentuan parameter yang sesuai dalam permintaan InvokeModel, dan Vertex AI melalui konfigurasi API. Silakan merujuk ke dokumentasi resmi masing-masing platform untuk metode konfigurasi spesifiknya.
Daftar Praktik Terbaik Jendela Konteks 1M Claude API
Saat mengintegrasikan jendela konteks 1M ke dalam proyek nyata, sebaiknya ikuti praktik terbaik berikut:
Tahap Pengembangan
- Gunakan Token Counting API untuk estimasi terlebih dahulu: Sebelum mengirim permintaan yang sebenarnya, gunakan Token Counting API untuk memperkirakan jumlah token input guna menghindari biaya konteks panjang yang tidak terduga.
- Atur max_tokens yang wajar: Parameter
max_tokenstidak memengaruhi perhitungan batas kecepatan (OTPM dihitung berdasarkan output aktual), jadi Anda bisa mengatur nilai yang lebih tinggi untuk memastikan output tidak terpotong. - Pengujian bertahap: Validasi efektivitas template petunjuk dengan data skala kecil terlebih dahulu, baru kemudian tingkatkan skala input secara bertahap.
Lingkungan Produksi
- Prioritaskan penggunaan Prompt Caching: Untuk dokumen panjang yang digunakan berulang kali, Prompt Caching dapat memangkas biaya input bagian yang terkena cache hingga 10% dari harga standar. Selain itu, token yang terkena cache tidak dihitung dalam batas kecepatan ITPM.
- Gunakan Batch API untuk tugas non-real-time: Batch API memberikan diskon tambahan 50% di atas harga konteks panjang. Jika keduanya digabungkan, biayanya hanya sekitar 60% dari harga standar.
- Pantau field usage: Periksa objek
usagedalam respons setelah setiap permintaan dan buat mekanisme peringatan pemantauan biaya. - Retry untuk error 429: Permintaan konteks panjang memiliki batas kecepatan independen. Jika menemui error 429, periksa header
retry-afteruntuk melakukan percobaan ulang yang wajar.
Kontrol Biaya
- Kontrol ambang batas 200K: Jika input mendekati 200K, pertimbangkan untuk meringkas petunjuk agar tidak memicu harga 2x lipat.
- Pilih model yang tepat: Seri Sonnet 40% lebih murah daripada Opus, jadi prioritaskan Sonnet untuk tugas sehari-hari.
- Manfaatkan cache untuk mengurangi tekanan batas kecepatan: Dengan tingkat hit cache 80%, throughput aktual bisa mencapai 5 kali lipat dari batas nominal.
Ringkasan Jendela Konteks 1M Claude API
Jendela konteks 1M dari Claude API memungkinkan pengembang memproses sekitar 750.000 kata sekaligus, memberikan kemampuan luar biasa untuk analisis basis kode, pemrosesan dokumen panjang, percakapan kompleks, dan lainnya. Berikut poin-poin intinya:
- Aktifkan dengan satu baris kode: Cukup tambahkan header
anthropic-beta: context-1m-2025-08-07. - Dukungan untuk 4 model: Claude Opus 4.6, Sonnet 4.6, Sonnet 4.5, dan Sonnet 4.
- Harga transparan: Input 2x lipat dan output 1,5x lipat setelah melewati 200K token; di bawah 200K tetap menggunakan harga standar.
- Batas kecepatan independen: Permintaan konteks panjang tidak memengaruhi kuota permintaan standar.
- Berbagai metode optimasi: Prompt Caching, Batch API, dan Fast Mode dapat dikombinasikan untuk menekan biaya.
Kami merekomendasikan untuk mencoba kemampuan jendela konteks 1M Claude melalui APIYI apiyi.com dan temukan solusi praktik terbaik yang sesuai dengan skenario bisnis Anda.
Referensi
-
Dokumentasi Resmi Anthropic – Context Windows: Penjelasan teknis jendela konteks (context window) Claude API
- Link:
platform.claude.com/docs/en/build-with-claude/context-windows
- Link:
-
Dokumentasi Resmi Anthropic – Pricing: Penjelasan lengkap harga Claude API
- Link:
platform.claude.com/docs/en/about-claude/pricing
- Link:
-
Dokumentasi Resmi Anthropic – Rate Limits: Penjelasan batas kecepatan (rate limits) dan Tingkatan Penggunaan (Usage Tier)
- Link:
platform.claude.com/docs/en/api/rate-limits
- Link:
📝 Penulis: APIYI Team | Untuk tutorial penggunaan API model AI lainnya, silakan kunjungi Pusat Bantuan APIYI apiyi.com