Как использовать в API-запросах сверхдлинный контекст объемом более 200 000 токенов — это насущная задача, с которой сталкивается все больше разработчиков. Anthropic представила функцию контекстного окна Claude API в 1 миллион токенов (1M Context Window). Теперь за один запрос можно обработать около 750 тысяч слов — это все равно что за один присест прочитать целиком «Сон в красном тереме» и «Троецарствие».
Главная ценность: Из этой статьи вы узнаете, как активировать окно в 1 млн токенов в Claude API, разберетесь в правилах расчета стоимости и получите готовые шаблоны кода для 5 реальных сценариев.
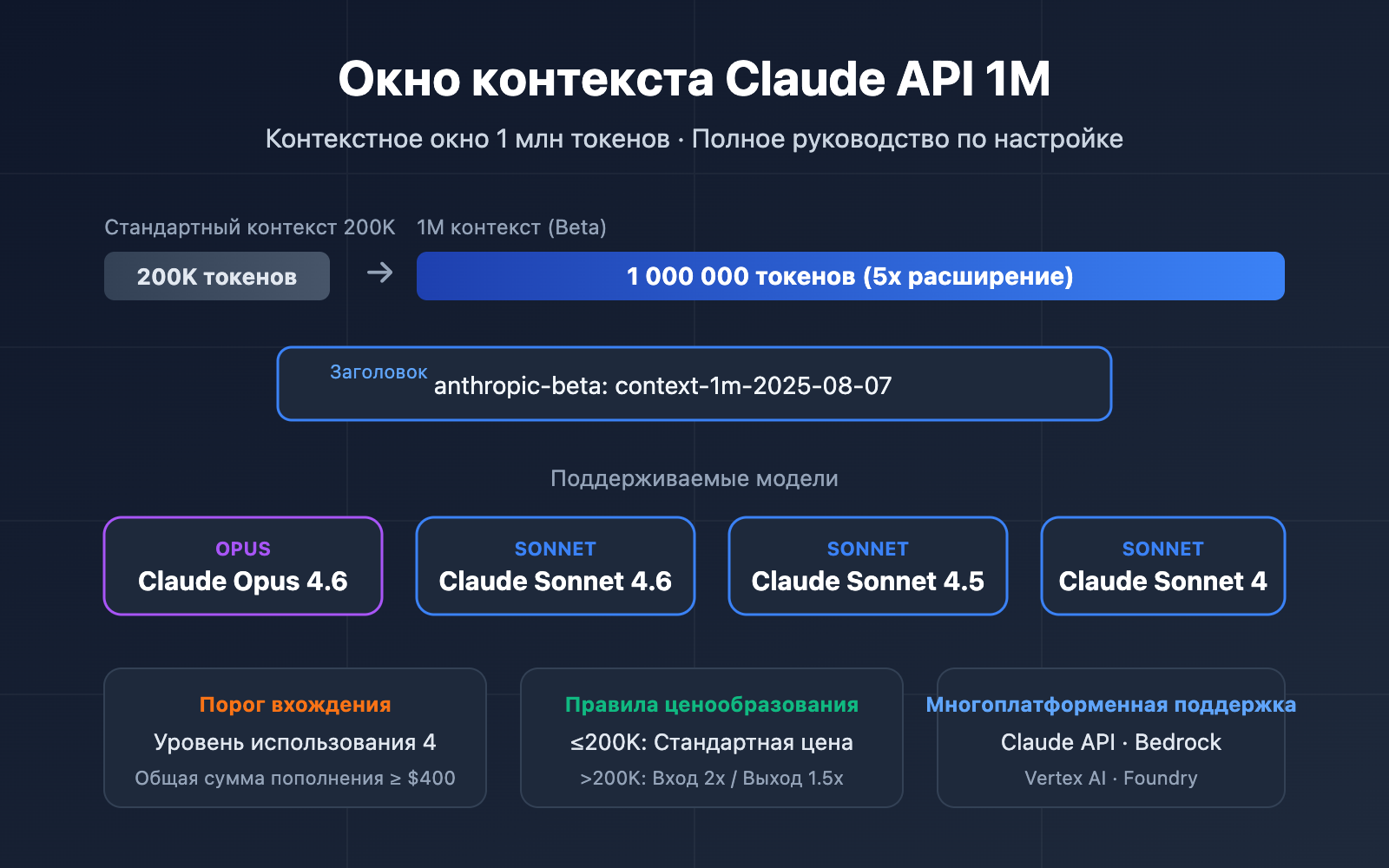
Основные моменты контекстного окна Claude API 1M
Прежде чем переходить к деталям настройки, давайте разберем ключевую информацию об этой функции.
| Параметр | Описание | Ценность |
|---|---|---|
| Бета-функция | Активируется через заголовок context-1m-2025-08-07 |
Не нужно подавать заявку, достаточно добавить header |
| Поддерживаемые модели | Opus 4.6, Sonnet 4.6, Sonnet 4.5, Sonnet 4 | Охватывает всю основную линейку моделей |
| Порог входа | Требуется Usage Tier 4 или индивидуальные лимиты скорости | Достигается при суммарном пополнении баланса на $400 |
| Правила тарификации | Автоматический переход на тариф длинного контекста после 200K токенов | Ввод в 2 раза дороже, вывод в 1.5 раза дороже стандартной цены |
| Мультиплатформенность | Claude API, AWS Bedrock, Google Vertex AI, Microsoft Foundry | Единый опыт на разных платформах |
Как работает контекстное окно Claude API 1M
Стандартное контекстное окно Claude API составляет 200K токенов. Когда вы активируете окно в 1M через бета-заголовок, модель может обрабатывать до 1 миллиона токенов входных данных за один запрос.
Важно помнить, что в контекстное окно входит абсолютно всё:
- Входящие токены: системный промпт, история диалога, текущее сообщение пользователя.
- Исходящие токены: ответ, сгенерированный моделью.
- Токены размышлений: если включена функция Extended Thinking, процесс «рассуждения» также учитывается.
🎯 Технический совет: Контекстное окно 1M в Claude API идеально подходит для анализа крупных кодовых баз, понимания объемных документов и подобных задач. Мы рекомендуем использовать платформу APIYI apiyi.com для быстрой проверки решений с длинным контекстом — она поддерживает единый интерфейс вызова для всей линейки моделей Claude.
Быстрый старт с контекстным окном Claude API 1M
Предварительные условия
Перед использованием окна в 1M убедитесь, что вы соответствуете следующим критериям:
| Условие | Требование | Как проверить |
|---|---|---|
| Usage Tier | Tier 4 или индивидуальные лимиты | Claude Console → Settings → Limits |
| Сумма пополнений | ≥ $400 (порог для Tier 4) | История платежей в личном кабинете |
| Выбор модели | Opus 4.6 / Sonnet 4.6 / Sonnet 4.5 / Sonnet 4 | Другие модели не поддерживают 1M контекст |
| Версия API | anthropic-version: 2023-06-01 |
Указывается в заголовках запроса |
Простейший пример
Чтобы разблокировать окно в 1M, достаточно добавить одну строку с бета-заголовком в стандартный запрос к API:
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Используем единый интерфейс APIYI
)
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[
{"role": "user", "content": "请分析以下长文档的核心论点..."}
],
betas=["context-1m-2025-08-07"],
)
print(response.content[0].text)
Аналогичный вызов через cURL:
curl https://api.apiyi.com/v1/messages \
-H "x-api-key: $API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: context-1m-2025-08-07" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [
{"role": "user", "content": "分析这份长文档..."}
]
}'
Разбор ключевых моментов:
betas=["context-1m-2025-08-07"]: формат для Python SDK, который автоматически добавляет заголовокanthropic-beta.anthropic-beta: context-1m-2025-08-07: формат заголовка для cURL / HTTP запросов.- Если объем входящих токенов не превышает 200K, тарификация останется стандартной, даже если заголовок добавлен.
Посмотреть полный код на TypeScript
import Anthropic from "@anthropic-ai/sdk";
import * as fs from "fs";
const anthropic = new Anthropic({
apiKey: "YOUR_API_KEY",
baseURL: "https://api.apiyi.com/v1" // Используем единый интерфейс APIYI
});
async function analyzeLongDocument(filePath: string) {
// 读取大文件
const document = fs.readFileSync(filePath, "utf-8");
const response = await anthropic.beta.messages.create({
model: "claude-opus-4-6",
max_tokens: 8192,
messages: [
{
role: "user",
content: `请对以下文档进行全面分析,包括:
1. 核心论点摘要
2. 关键数据提取
3. 逻辑结构评估
4. 改进建议
文档内容:
${document}`
}
],
betas: ["context-1m-2025-08-07"]
});
console.log(response.content[0].text);
// 检查 Token 使用情况
console.log("Input tokens:", response.usage.input_tokens);
console.log("Output tokens:", response.usage.output_tokens);
}
analyzeLongDocument("./large-report.txt");
🚀 Быстрый старт: Рекомендуем использовать платформу APIYI apiyi.com для оперативного тестирования окна 1M в Claude. Платформа предоставляет OpenAI-совместимый интерфейс, не требует сложной настройки и поддерживает всю линейку моделей Claude.
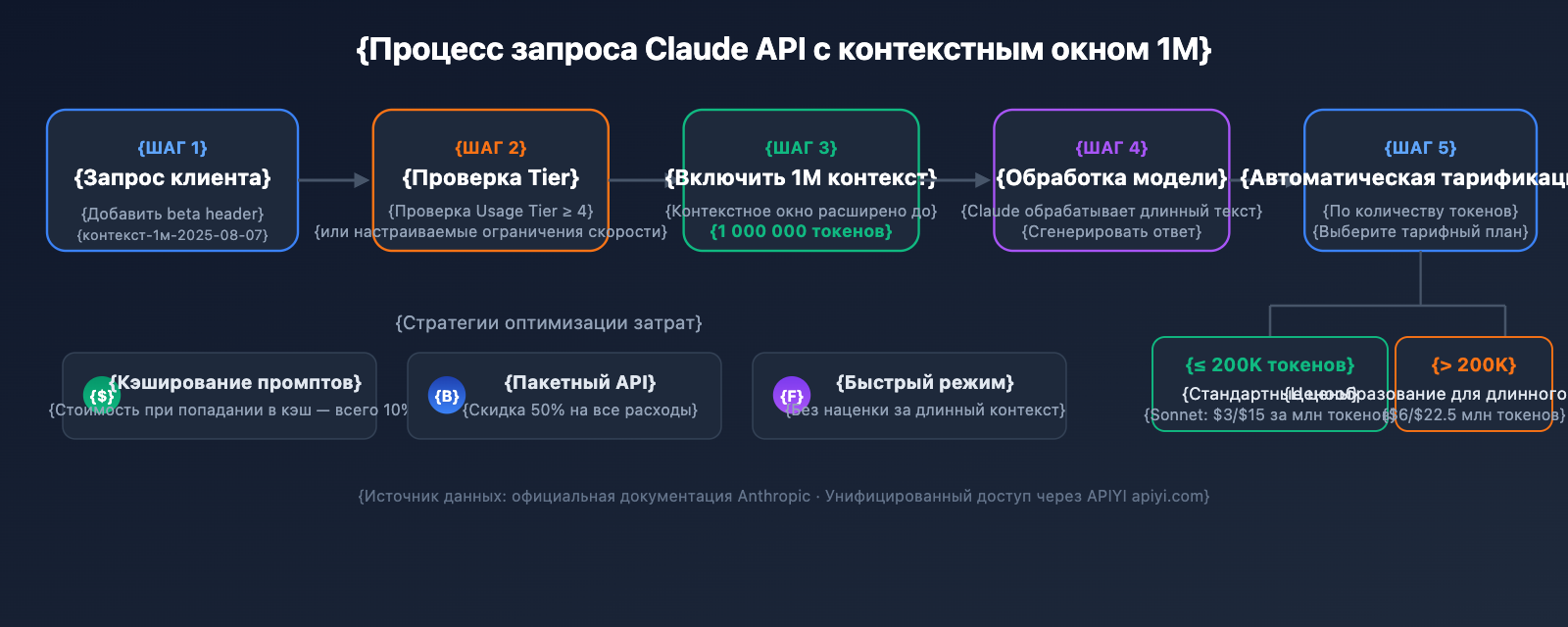
Подробный разбор цен на контекстное окно 1M в Claude API
Ценообразование для длинного контекста — один из самых важных вопросов для разработчиков. Claude API использует ступенчатую стратегию тарификации: превышает ли объем входных токенов 200K, определяет ваш тарифный план.
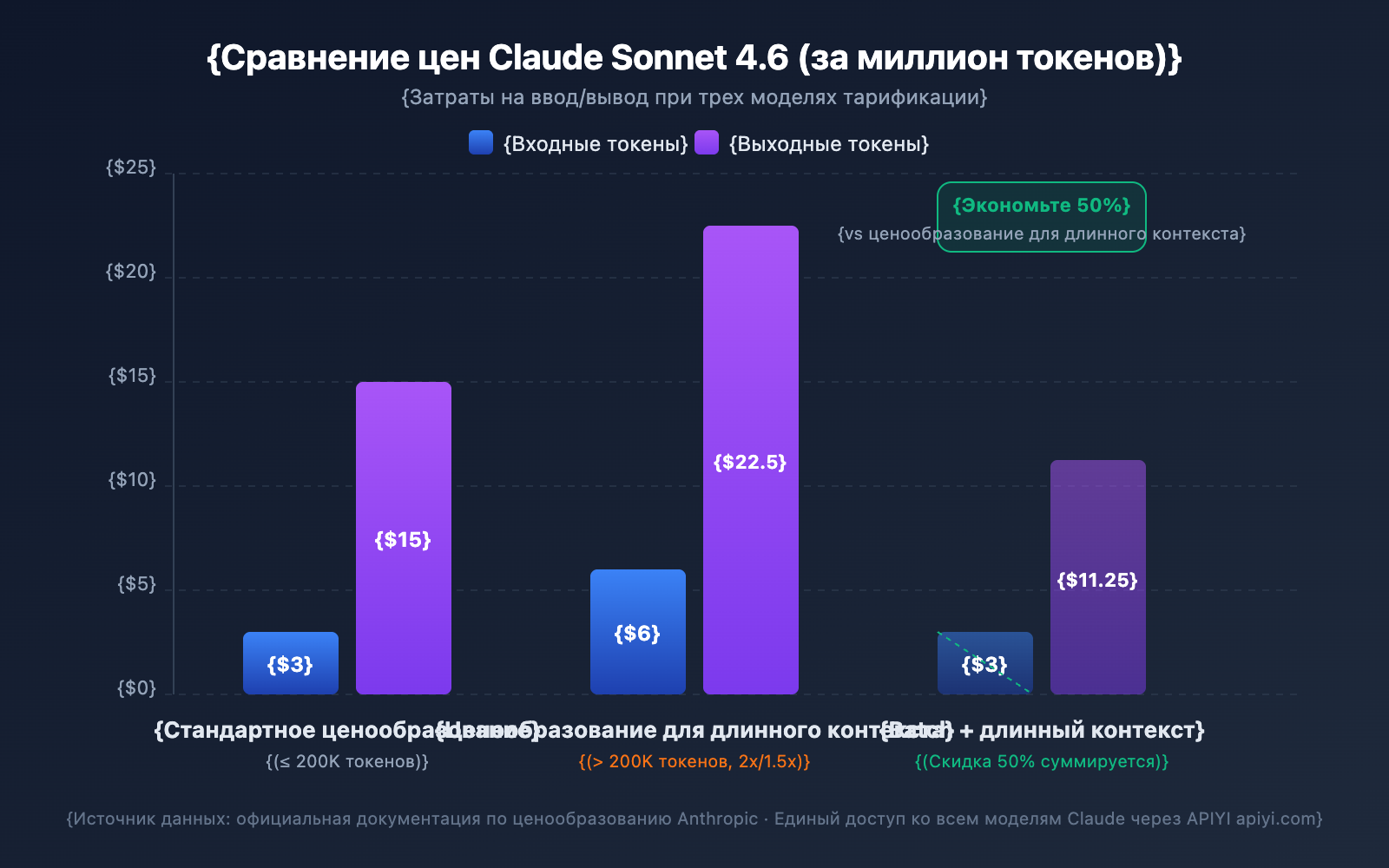
Сравнение цен на длинный контекст для разных моделей
| Модель | Стандартный ввод (≤200K) | Ввод длинного контекста (>200K) | Стандартный вывод | Вывод длинного контекста | Множитель |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $10/MTok | $25/MTok | $37.50/MTok | Ввод 2x / Вывод 1.5x |
| Claude Sonnet 4.6 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Ввод 2x / Вывод 1.5x |
| Claude Sonnet 4.5 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Ввод 2x / Вывод 1.5x |
| Claude Sonnet 4 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Ввод 2x / Вывод 1.5x |
MTok = миллион токенов
Правила расчета стоимости
Чтобы избежать неожиданных расходов, важно понимать несколько ключевых правил:
- Порог в 200K — это переключатель: Как только общий объем входных токенов превышает 200K, все токены в этом запросе тарифицируются по цене длинного контекста, а не только те, что сверх лимита.
- Общий объем входных токенов включает кэш: Сумма
input_tokens+cache_creation_input_tokens+cache_read_input_tokensопределяет ваш тарифный уровень. - Выходные токены не влияют на уровень: Количество выходных токенов не определяет, сработает ли цена за длинный контекст, но если она сработала, вывод также тарифицируется с коэффициентом 1.5x.
- Ниже 200K — стандартная цена: Даже если вы включили beta-заголовок, пока ввод не превышает 200K, расчет идет по стандартному тарифу.
Пример расчета стоимости
Сценарий: Использование Claude Sonnet 4.6 для анализа длинного документа объемом 500 000 токенов с генерацией отчета на 2000 токенов.
Стоимость ввода: 500,000 токенов × $6/MTok = $3.00
Стоимость вывода: 2,000 токенов × $22.50/MTok = $0.045
Итого: $3.045
Тот же вывод, но если ввод составляет всего 150 000 токенов:
Стоимость ввода: 150,000 токенов × $3/MTok = $0.45
Стоимость вывода: 2,000 токенов × $15/MTok = $0.03
Итого: $0.48
4 стратегии экономии
| Стратегия | Размер экономии | Сценарии использования |
|---|---|---|
| Prompt Caching | Кэш-хит стоит всего 10% | Повторное использование одного и того же длинного документа |
| Batch API | Скидка 50% на все расходы | Пакетная обработка задач не в реальном времени |
| Fast Mode (Opus 4.6) | Без наценки за длинный контекст | Сценарии, требующие быстрого ответа |
| Контроль ввода в пределах 200K | Избежание 2x тарифа | Документы, которые можно обрабатывать по частям |
💰 Оптимизация затрат: Для проектов, требующих частого обращения к длинному контексту Claude, можно воспользоваться гибкими тарифными планами на платформе APIYI (apiyi.com). Сочетая Prompt Caching и Batch API, стоимость одного вызова можно снизить более чем на 70%.
Лимиты скорости для контекстного окна 1M в Claude API
После включения окна в 1M запросы с длинным контекстом (ввод более 200K токенов) имеют отдельные лимиты скорости, которые рассчитываются независимо от стандартных запросов.
Лимиты скорости для Tier 4
| Тип лимита | Лимит для стандартных запросов | Лимит для запросов с длинным контекстом |
|---|---|---|
| Макс. входных токенов в минуту (ITPM) | Sonnet: 2,000,000 / Opus: 2,000,000 | 1,000,000 |
| Макс. выходных токенов в минуту (OTPM) | Sonnet: 400,000 / Opus: 400,000 | 200,000 |
| Макс. запросов в минуту (RPM) | 4,000 | Пропорционально ниже |
Важные примечания:
- Лимиты для длинного контекста и стандартные лимиты рассчитываются независимо и не влияют друг на друга.
- При использовании Prompt Caching токены, попавшие в кэш, не учитываются в лимите ITPM (для большинства моделей).
- Если вам требуются более высокие лимиты для длинного контекста, вы можете обратиться в отдел продаж Anthropic для запроса индивидуальных квот.
Как перейти на Tier 4
| Tier | Требование к сумме пополнений | Макс. разовое пополнение | Месячный лимит расходов |
|---|---|---|---|
| Tier 1 | $5 | $100 | $100 |
| Tier 2 | $40 | $500 | $500 |
| Tier 3 | $200 | $1,000 | $1,000 |
| Tier 4 | $400 | $5,000 | $5,000 |
Уровень повышается автоматически при достижении порога суммарных пополнений, ручное подтверждение не требуется.
5 практических сценариев использования Claude API с контекстным окном 1M
Сценарий 1: Анализ крупных кодовых баз
Упакуйте код всего проекта и отправьте его Claude для проведения архитектурного аудита, поиска багов или получения рекомендаций по рефакторингу.
import anthropic
import os
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def collect_codebase(directory, extensions=(".py", ".ts", ".js")):
"""Собирает все файлы исходного кода указанных типов в проекте"""
code_content = []
for root, dirs, files in os.walk(directory):
# Пропускаем директории типа node_modules, .git и т.д.
dirs[:] = [d for d in dirs if d not in ("node_modules", ".git", "__pycache__")]
for file in files:
if file.endswith(extensions):
filepath = os.path.join(root, file)
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
code_content.append(f"### {filepath}\n```\n{content}\n```")
return "\n\n".join(code_content)
codebase = collect_codebase("./my-project")
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=8192,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Проведи полный архитектурный аудит следующей кодовой базы:
{codebase}
Пожалуйста, проанализируй:
1. Плюсы и минусы общей архитектуры
2. Потенциальные уязвимости безопасности
3. Рекомендации по оптимизации производительности
4. Точки улучшения качества кода"""
}]
)
Сценарий 2: Комплексный анализ длинных документов
Обработка сверхдлинных документов: юридических контрактов, сборников научных статей или финансовых отчетов.
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Ниже представлен сборник финансовых отчетов компании за последние 12 месяцев (около 400 000 токенов):
{financial_reports}
Пожалуйста, выполни:
1. Анализ трендов ключевых финансовых показателей по кварталам
2. Выявление изменений в структуре доходов и их причин
3. Оценку эффективности контроля затрат
4. Прогноз показателей на следующий квартал и предупреждение о рисках"""
}]
)
Сценарий 3: Сочетание многоэтапных диалогов и функции Extended Thinking
Включите Extended Thinking в длинном контексте, чтобы Claude провел глубокие рассуждения:
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
betas=["context-1m-2025-08-07"],
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[{
"role": "user",
"content": f"""Ниже приведена полная техническая документация и исходный код сложной системы:
{large_technical_document}
Проведи глубокий анализ философии дизайна этой системы и предложи план по её улучшению."""
}]
)
# Токены Extended Thinking не накапливаются в последующих диалогах
# API автоматически отсекает блоки рассуждений (thinking blocks) из предыдущих итераций
Сценарий 4: Использование Prompt Caching для снижения затрат
Если вам нужно провести несколько анализов одного и того же длинного документа с разных сторон, Prompt Caching поможет существенно сэкономить:
# Первый запрос: кэшируем длинный документ
response1 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"} # помечаем как кэшируемое
}],
messages=[{"role": "user", "content": "Сформулируй основные тезисы этого документа"}]
)
# Второй запрос: попадание в кэш, стоимость входных токенов составит всего 10%
response2 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "Извлеки все таблицы с данными из документа"}]
)
Сценарий 5: Пакетная обработка через Batch API
Использование Batch API позволяет получить дополнительную скидку 50% от цены за длинный контекст:
# Создание пакетного запроса
batch = client.beta.messages.batches.create(
betas=["context-1m-2025-08-07"],
requests=[
{
"custom_id": "doc-analysis-1",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": f"Проанализируй документ 1: {doc1}"}]
}
},
{
"custom_id": "doc-analysis-2",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": "Проанализируй документ 2: {doc2}"}]
}
}
]
)
🎯 Практический совет: Для реальных проектов мы рекомендуем сначала провести небольшое тестирование на платформе APIYI (apiyi.com), чтобы убедиться, что расход токенов и стоимость соответствуют вашим ожиданиям. Платформа предоставляет детальную панель статистики использования, что позволяет точно контролировать расходы.
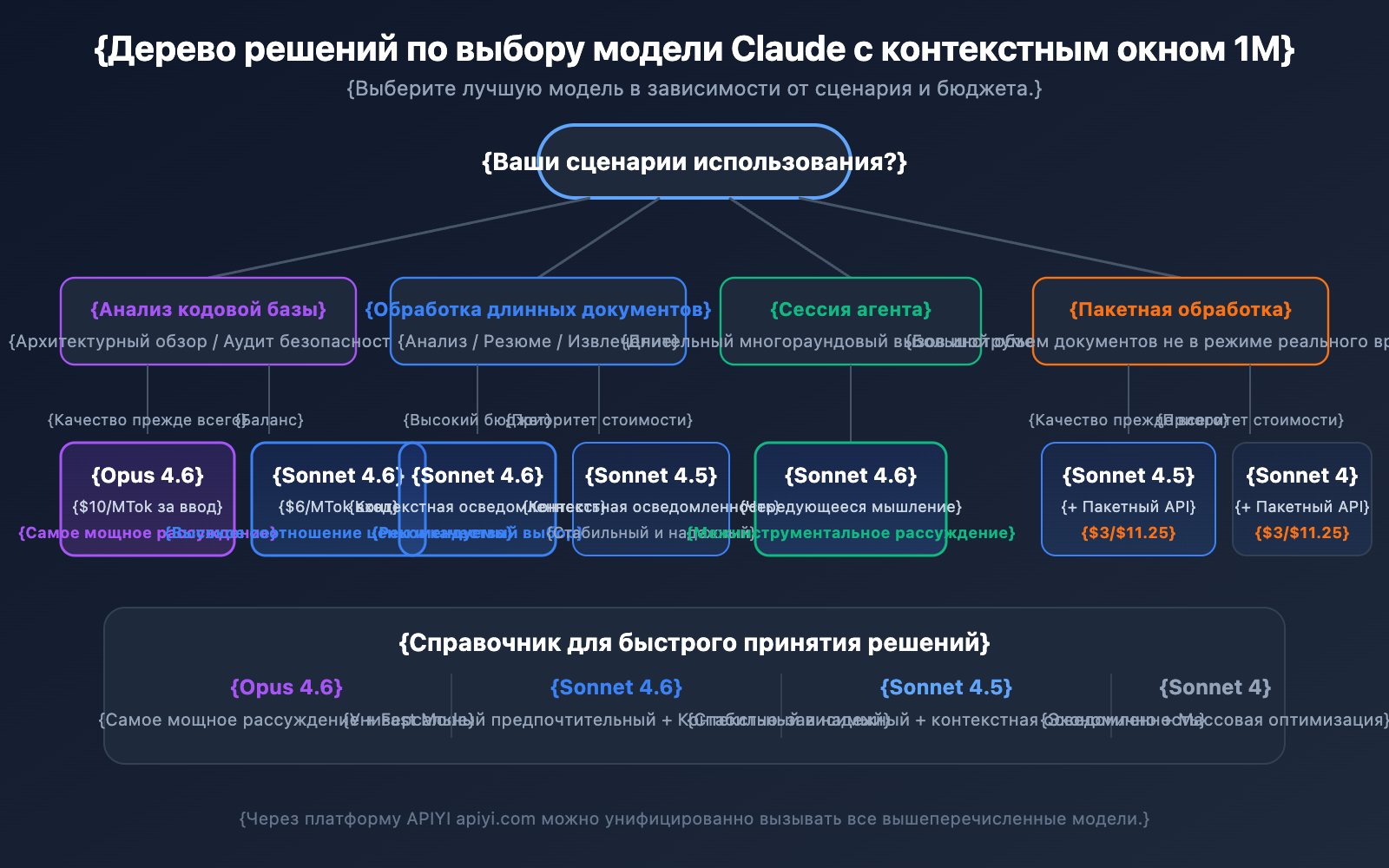
Рекомендации по выбору модели Claude API с окном 1M
Каждая из 4 моделей с поддержкой контекста 1M имеет свои сильные стороны. Правильный выбор поможет найти идеальный баланс между качеством и ценой.
Сравнение моделей с поддержкой 1M контекста
| Критерий | Claude Opus 4.6 | Claude Sonnet 4.6 | Claude Sonnet 4.5 | Claude Sonnet 4 |
|---|---|---|---|---|
| Уровень интеллекта | Максимальный | Высокий | Высокий | Выше среднего |
| Стандартная цена (вход) | $5/MTok | $3/MTok | $3/MTok | $3/MTok |
| Цена за длинный контекст | $10/MTok | $6/MTok | $6/MTok | $6/MTok |
| Fast Mode | Поддерживается (6x цена) | Нет | Нет | Нет |
| Context Awareness | Нет | Есть | Есть | Нет |
| Interleaved Thinking | Есть | Есть | Нет | Есть |
| Рекомендуемые сценарии | Сложная логика, анализ кода | Общая работа с доками | Многоэтапные агенты | Рутинный анализ |
Выбор модели по сценарию
Когда выбирать Claude Opus 4.6:
- Задачи комплексного анализа, требующие максимальных способностей к рассуждению.
- Архитектурный аудит и аудит безопасности крупных кодовых баз.
- Сценарии реального времени, где нужен Fast Mode (быстрый отклик без наценки за длинный контекст).
- Корпоративные приложения, где качество в приоритете, а бюджет позволяет.
Когда выбирать Claude Sonnet 4.6:
- Ежедневный анализ длинных документов и извлечение сводок.
- Длительные диалоги, требующие высокой способности к осознанию контекста (Context Awareness).
- Проекты с ограниченным бюджетом, но высокими требованиями к качеству.
- Использование Interleaved Thinking для рассуждений между вызовами инструментов.
Когда выбирать Claude Sonnet 4.5 / Sonnet 4:
- Пакетная обработка документов (в сочетании с Batch API для снижения затрат).
- Извлечение структурированной информации и упорядочивание данных.
- Стабильные производственные среды, не требующие новейших функций модели.
💡 Совет по выбору: Выбор модели зависит от ваших конкретных задач и бюджета. Мы рекомендуем провести сравнительное тестирование на платформе APIYI (apiyi.com). Платформа поддерживает единый интерфейс для всех вышеперечисленных моделей, что позволяет быстро переключаться между ними и оценивать результат.
Справочник по оценке токенов для окна 1M
При планировании использования длинного контекста важно понимать примерный расход токенов для разных типов контента:
| Тип контента | Примерное кол-во токенов | Вместимость в окно 1M |
|---|---|---|
| Английский текст | ~1 токен / 4 символа | ок. 3 млн символов |
| Китайский текст | ~1 токен / 1.5 символа | ок. 750 тыс. символов |
| Код Python | ~1 токен / 3.5 символа | ок. 2.5 млн символов кода |
| Обычная веб-страница (10 КБ) | ~2 500 токенов | ок. 400 страниц |
| Большой документ (100 КБ) | ~25 000 токенов | ок. 40 документов |
| Научная статья PDF (500 КБ) | ~125 000 токенов | ок. 8 статей |
Окно контекста 1M в Claude API и контекстная осведомленность
Claude Sonnet 4.6, Sonnet 4.5 и Haiku 4.5 обладают способностью Context Awareness (контекстная осведомленность). Модель может в реальном времени отслеживать оставшийся объем окна контекста и более разумно управлять бюджетом токенов в длинных диалогах.
Как это работает:
В начале диалога Claude получает информацию об общем объеме контекста:
<budget:token_budget>1000000</budget:token_budget>
После каждого вызова инструмента модель получает обновление об оставшемся объеме:
<system_warning>Token usage: 350000/1000000; 650000 remaining</system_warning>
Это означает, что в рамках окна контекста в 1 млн токенов Claude может:
- Точно управлять бюджетом токенов: контекст не закончится внезапно в самый разгар диалога.
- Разумно распределять длину вывода: корректировать степень детализации ответов в зависимости от оставшегося объема.
- Поддерживать сверхдлинные сессии агентов: продолжать выполнение задач в рабочих процессах агентов до их полного завершения.
Стратегия управления окном контекста 1M в Claude API: Compaction
Когда длина диалога приближается к пределу окна контекста в 1 млн токенов, Claude API предлагает функцию Compaction (компрессия) для продолжения беседы. Compaction — это механизм суммаризации на стороне сервера, который автоматически сжимает ранние части диалога в краткие резюме, освобождая место в контексте. Это позволяет поддерживать сверхдлинные диалоги, выходящие за рамки стандартных ограничений.
На данный момент функция Compaction доступна в режиме Beta для Claude Opus 4.6. Для разработчиков, чьи агенты выполняют длительные задачи в рамках 1M контекста, Compaction является приоритетной стратегией управления.
Кроме того, Claude API предоставляет возможности Context Editing (редактирование контекста), включая:
- Tool Result Clearing: удаление результатов старых вызовов инструментов в рабочих процессах агентов для освобождения токенов.
- Thinking Block Clearing: активная очистка блоков размышлений из предыдущих итераций для оптимизации использования контекста.
Эти стратегии можно комбинировать с окном контекста 1M, чтобы добиться идеального баланса производительности и затрат в сценариях со сверхбольшим объемом данных.
На что стоит обратить внимание при использовании окна контекста 1M
В реальной работе с окном в 1 млн токенов есть несколько технических нюансов, которые легко упустить из виду:
-
Новые модели возвращают ошибку валидации вместо незаметной обрезки: Начиная с Claude Sonnet 3.7, если суммарный объем промпта и выходных токенов превышает окно контекста, API вернет ошибку валидации, а не просто тихо обрежет содержимое. Рекомендуется использовать Token Counting API для предварительной оценки количества токенов перед отправкой запроса.
-
Расход токенов для изображений и PDF не фиксирован: Расчет токенов для мультимодального контента отличается от обычного текста. Изображения одного и того же размера могут потреблять разное количество токенов. При активном использовании изображений закладывайте достаточный запас токенов.
-
Ограничения на размер запроса (Request Size Limits): Даже если окно контекста поддерживает 1 млн токенов, у самого HTTP-запроса есть лимиты по размеру. При отправке огромных массивов текста следите за ограничениями на уровне HTTP.
-
Лимиты скорости с учетом кэширования: При использовании Prompt Caching токены, попавшие в кэш (cache hits), не учитываются в лимитах скорости ITPM. Это значит, что в сценариях с 1M контекстом грамотное использование кэша может значительно повысить реальную пропускную способность.
Часто задаваемые вопросы
Q1: Как проверить, тарифицируется ли мой запрос по ценам для длинного контекста?
Проверьте объект usage в ответе API. Сложите значения полей input_tokens, cache_creation_input_tokens и cache_read_input_tokens. Если сумма превышает 200 000, весь запрос тарифицируется по цене для длинного контекста. При использовании платформы APIYI (apiyi.com) панель статистики использования четко помечает тарифную категорию для каждого запроса.
Q2: Какие типы файлов поддерживает окно контекста 1M?
Окно контекста 1M в Claude API поддерживает текстовые форматы (обычный текст, код, Markdown), а также изображения и PDF-файлы. Однако помните, что изображения и PDF обычно потребляют много токенов, и этот расход не всегда предсказуем. При одновременном использовании большого количества изображений и длинного текста можно столкнуться с ограничениями на размер запроса (Request Size Limits). Рекомендуется сначала провести небольшие тесты на платформе APIYI (apiyi.com), чтобы подтвердить реальный расход токенов.
Q3: Занимают ли токены Extended Thinking место в контексте 1M?
Токены Extended Thinking текущей итерации учитываются в окне контекста. Однако Claude API автоматически отсекает блоки размышлений (thinking blocks) предыдущих ходов, поэтому они не накапливаются в последующем диалоге. Это значит, что вы можете смело использовать Extended Thinking в рамках 1M контекста, не опасаясь, что процесс «размышлений» съест всё свободное место.
Q4: Что делать, если я не соответствую условиям Tier 4?
На данный момент окно контекста 1M открыто только для организаций уровня Tier 4 и выше (или с кастомными лимитами скорости). Для достижения Tier 4 достаточно суммарно пополнить баланс на $400, после чего уровень повысится автоматически. Если вы пока не достигли Tier 4, можно: ① разбивать входные данные на части менее 200K; ② использовать RAG (Retrieval-Augmented Generation) для извлечения ключевого контента; ③ связаться с отделом продаж Anthropic для обсуждения индивидуального решения.
Q5: Как включить это на AWS Bedrock и Google Vertex AI?
Окно контекста 1M доступно на AWS Bedrock, Google Vertex AI и Microsoft Foundry. Способ активации немного отличается в зависимости от платформы: в Bedrock нужно указать соответствующие параметры в запросе InvokeModel, а в Vertex AI — через конфигурацию API. Подробные инструкции по настройке ищите в официальной документации каждой платформы.
Чек-лист лучших практик для работы с контекстным окном Claude API 1M
При интеграции контекстного окна 1M в реальные проекты рекомендуем придерживаться следующих правил:
Этап разработки
- Предварительная оценка через Token Counting API: Перед отправкой реального запроса используйте Token Counting API для оценки количества входных токенов. Это поможет избежать неожиданных расходов из-за тарификации длинного контекста.
- Установка разумного
max_tokens: Параметрmax_tokensне влияет на расчет лимитов скорости (OTPM считается по фактическому выводу), поэтому можно устанавливать высокие значения, чтобы гарантировать, что ответ не будет обрезан. - Поэтапное тестирование: Сначала проверьте эффективность шаблона промпта на небольшом объеме данных, а затем постепенно увеличивайте масштаб входных данных.
Продакшн-среда
- Приоритет на Prompt Caching: Для часто используемых длинных документов кэширование промптов (Prompt Caching) позволяет снизить стоимость ввода для закэшированных частей до 10% от стандартной цены. Кроме того, токены, попавшие в кэш, не учитываются в лимитах скорости ITPM.
- Batch API для несрочных задач: Batch API дает дополнительную скидку 50% к цене за длинный контекст. При сочетании этих факторов итоговая стоимость составит всего около 60% от стандартного тарифа.
- Мониторинг поля
usage: Проверяйте объектusageв каждом ответе и настройте систему оповещений для контроля расходов. - Обработка ошибок 429: У запросов с длинным контекстом есть свои независимые лимиты скорости. При возникновении ошибки 429 проверяйте заголовок
retry-afterдля корректной настройки повторных попыток.
Контроль затрат
- Контроль порога в 200K: Если объем ввода приближается к 200K токенов, попробуйте сократить промпт, чтобы избежать срабатывания двойного тарифа.
- Выбор подходящей модели: Модели серии Sonnet на 40% дешевле Opus. Для повседневных задач отдавайте предпочтение Sonnet.
- Снижение нагрузки на лимиты через кэширование: При уровне попадания в кэш 80% реальная пропускная способность может в 5 раз превышать номинальные лимиты.
Итоги: контекстное окно 1M в Claude API
Контекстное окно 1M в Claude API позволяет разработчикам обрабатывать около 750 тысяч слов за один раз, что открывает мощные возможности для анализа кодовых баз, работы с длинными документами и ведения сложных диалогов. Основные моменты:
- Включается одной строкой: Достаточно добавить заголовок
anthropic-beta: context-1m-2025-08-07. - Поддержка 4 моделей: Claude Opus 4.6, Sonnet 4.6, Sonnet 4.5 и Sonnet 4.
- Прозрачное ценообразование: При превышении 200K токенов ввод стоит в 2 раза дороже, вывод — в 1.5 раза. До 200K действует стандартная цена.
- Независимые лимиты скорости: Запросы с длинным контекстом не расходуют квоты стандартных запросов.
- Различные способы оптимизации: Prompt Caching, Batch API и Fast Mode можно комбинировать для снижения затрат.
Рекомендуем быстро протестировать возможности контекстного окна Claude 1M через APIYI (apiyi.com) и найти оптимальное решение для ваших бизнес-задач.
Источники
-
Официальная документация Anthropic — Context Windows: Техническое описание контекстного окна Claude API
- Ссылка:
platform.claude.com/docs/en/build-with-claude/context-windows
- Ссылка:
-
Официальная документация Anthropic — Pricing: Полная информация о тарифах Claude API
- Ссылка:
platform.claude.com/docs/en/about-claude/pricing
- Ссылка:
-
Официальная документация Anthropic — Rate Limits: Описание лимитов частоты запросов и уровней использования (Usage Tiers)
- Ссылка:
platform.claude.com/docs/en/api/rate-limits
- Ссылка:
📝 Автор: Команда APIYI | Больше руководств по использованию API различных ИИ-моделей вы найдете в справочном центре APIYI на сайте apiyi.com