如何在 API 调用中使用超过 20 万 Token 的超长上下文,是越来越多开发者面临的真实需求。Anthropic 推出了 Claude API 100 万 Token 上下文窗口(1M Context Window)功能,让单次请求可以处理约 75 万字的文本内容——相当于一次性读完整部《红楼梦》加《三国演义》。
核心价值: 读完本文,你将掌握 Claude API 1M 上下文窗口的完整开启方法,了解定价计算规则,并获得 5 种实战场景的代码模板。

Claude API 1M 上下文窗口核心要点
在深入配置细节之前,先了解这个功能的关键信息。
| 要点 | 说明 | 价值 |
|---|---|---|
| ベータ機能 | context-1m-2025-08-07 ヘッダーを通じて有効化 |
追加の申請は不要、ヘッダーを追加するだけ |
| 対応モデル | Opus 4.6、Sonnet 4.6、Sonnet 4.5、Sonnet 4 | 主要なモデルシリーズをカバー |
| 利用条件 | Usage Tier 4 またはカスタムレート制限が必要 | 累計 400 ドルのチャージで Tier 4 に到達 |
| 料金体系 | 200K トークンを超えると自動的に長文コンテキスト料金に切り替え | 入力は標準価格の 2 倍、出力は 1.5 倍 |
| マルチプラットフォーム対応 | Claude API、AWS Bedrock、Google Vertex AI、Microsoft Foundry | プラットフォームを問わず統一された体験 |
Claude API 1M 上下文窗口的工作原理
Claude API の標準コンテキストウィンドウは 200K トークンです。ベータヘッダーを通じて 1M コンテキストウィンドウを有効にすると、モデルは 1 回のリクエストで最大 100 万トークンの入力内容を処理できるようになります。
特に注意が必要なのは、コンテキストウィンドウには以下のすべての内容が含まれる点です:
- 入力トークン: システムプロンプト、会話履歴、現在のユーザーメッセージ
- 出力トークン: モデルが生成した回答内容
- 思考トークン: Extended Thinking(拡張思考)を有効にしている場合、その思考プロセスもカウントされます
🎯 技術的なアドバイス: Claude API の 1M コンテキストウィンドウは、大規模なコードベースの解析や長大なドキュメントの理解といったシナリオに最適です。APIYI (apiyi.com) プラットフォームを利用すれば、Claude 全シリーズのモデルを統合インターフェースで呼び出し、長文コンテキストのソリューションを迅速に検証できるため、お勧めです。
Claude API 1M コンテキストウィンドウ クイックスタートガイド
利用開始の前提条件
1M コンテキストウィンドウを使用する前に、以下の条件を満たしているか確認してください。
| 条件 | 要求事項 | 確認方法 |
|---|---|---|
| Usage Tier | Tier 4 またはカスタムレート制限 | Claude Console → Settings → Limits にログイン |
| 累計チャージ額 | $400 以上(Tier 4 の基準) | アカウントのチャージ履歴を確認 |
| モデルの選択 | Opus 4.6 / Sonnet 4.6 / Sonnet 4.5 / Sonnet 4 | その他のモデルは 1M コンテキスト非対応 |
| API バージョン | anthropic-version: 2023-06-01 |
リクエストヘッダーで指定 |
最小構成の例
標準の API リクエストに 1 行の beta ヘッダーを追加するだけで、1M コンテキストウィンドウを有効にできます。
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェースを使用
)
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[
{"role": "user", "content": "以下の長大なドキュメントの核心的な論点を分析してください..."}
],
betas=["context-1m-2025-08-07"],
)
print(response.content[0].text)
cURL を使用した同等の呼び出し:
curl https://api.apiyi.com/v1/messages \
-H "x-api-key: $API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: context-1m-2025-08-07" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [
{"role": "user", "content": "この長大なドキュメントを分析して..."}
]
}'
重要なコードの解説:
betas=["context-1m-2025-08-07"]: Python SDK での書き方です。自動的にanthropic-betaヘッダーが追加されます。anthropic-beta: context-1m-2025-08-07: cURL / HTTP リクエストでのヘッダーの書き方です。- 入力トークンが 200K を超えない場合、beta ヘッダーを追加していても標準価格で計算されます。
TypeScript の完全なコードを表示
import Anthropic from "@anthropic-ai/sdk";
import * as fs from "fs";
const anthropic = new Anthropic({
apiKey: "YOUR_API_KEY",
baseURL: "https://api.apiyi.com/v1" // APIYI 統合インターフェースを使用
});
async function analyzeLongDocument(filePath: string) {
// 大きなファイルを読み込む
const document = fs.readFileSync(filePath, "utf-8");
const response = await anthropic.beta.messages.create({
model: "claude-opus-4-6",
max_tokens: 8192,
messages: [
{
role: "user",
content: `以下のドキュメントについて包括的な分析を行ってください:
1. 核心的な論点の要約
2. 重要なデータの抽出
3. 論理構造の評価
4. 改善案の提案
ドキュメント内容:
${document}`
}
],
betas: ["context-1m-2025-08-07"]
});
console.log(response.content[0].text);
// トークン使用量を確認
console.log("Input tokens:", response.usage.input_tokens);
console.log("Output tokens:", response.usage.output_tokens);
}
analyzeLongDocument("./large-report.txt");
🚀 クイックスタート: Claude 1M コンテキストウィンドウを素早くテストするには、APIYI (apiyi.com) プラットフォームの使用をお勧めします。このプラットフォームは OpenAI 互換インターフェースを提供しており、複雑な設定なしで Claude 全シリーズのモデルをサポートしています。

Claude API 1M コンテキストウィンドウの料金体系詳解
長文コンテキストの料金体系は、開発者にとって最も関心の高い事項の一つです。Claude APIでは段階的な料金プランが採用されており、入力トークン数が200K(20万)を超えるかどうかで料金区分が決まります。
各モデルの長文コンテキスト料金比較
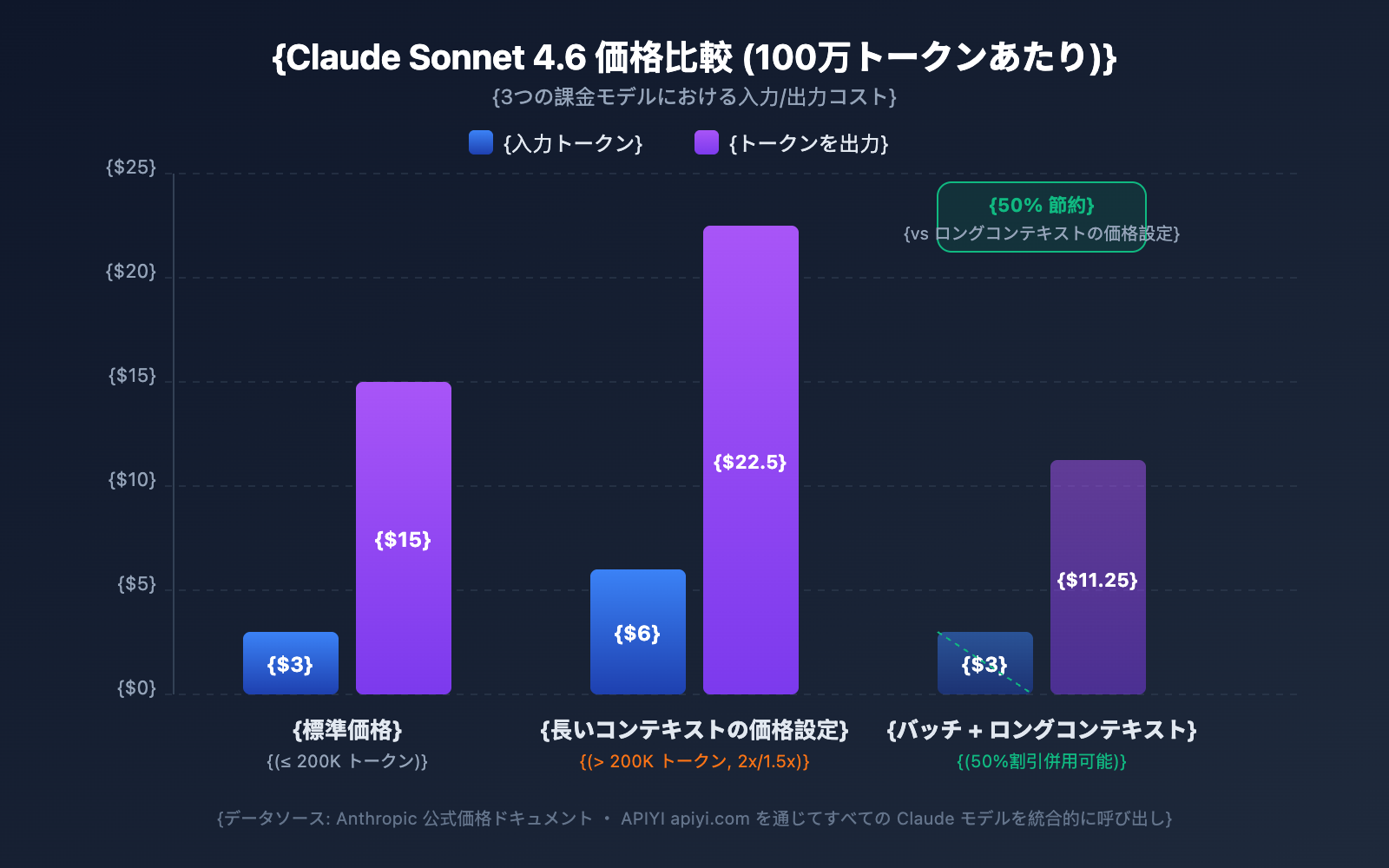
| モデル | 標準入力 (≤200K) | 長文入力 (>200K) | 標準出力 | 長文出力 | 倍率 |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $10/MTok | $25/MTok | $37.50/MTok | 入力 2倍 / 出力 1.5倍 |
| Claude Sonnet 4.6 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | 入力 2倍 / 出力 1.5倍 |
| Claude Sonnet 4.5 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | 入力 2倍 / 出力 1.5倍 |
| Claude Sonnet 4 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | 入力 2倍 / 出力 1.5倍 |
MTok = 100万トークン
料金計算のルール
予期せぬコストを避けるために、いくつかの重要なルールを理解しておきましょう。
- 200Kの閾値は「スイッチ」: 入力トークンの総量が一度200Kを超えると、リクエスト全体のすべてのトークンに長文コンテキストの価格が適用されます。超過分だけに加算されるわけではありません。
- 入力トークン総数にはキャッシュが含まれる:
input_tokens+cache_creation_input_tokens+cache_read_input_tokensの合計が料金区分を決定します。 - 出力トークンは区分に影響しない: 出力トークンの数は長文コンテキスト料金が適用されるかどうかの判定には影響しません。ただし、一度適用されると、出力も1.5倍の価格で計算されます。
- 200K未満なら標準価格: betaヘッダーを有効にしていても、入力が200Kを超えない限り、標準価格で計算されます。
料金計算の具体例
シナリオ: Claude Sonnet 4.6 を使用して 50万トークンの長文ドキュメントを分析し、2,000トークンのレポートを生成する場合。
入力費用: 500,000 トークン × $6/MTok = $3.00
出力費用: 2,000 トークン × $22.50/MTok = $0.045
合計: $3.045
同じ出力で、入力が 15万トークンの場合:
入力費用: 150,000 トークン × $3/MTok = $0.45
出力費用: 2,000 トークン × $15/MTok = $0.03
合計: $0.48
4つのコスト削減戦略
| 戦略 | 削減幅 | 適用シーン |
|---|---|---|
| Prompt Caching | キャッシュヒット時は料金の10%のみ | 同じ長文ドキュメントを繰り返し使用する場合 |
| Batch API | すべての料金が50%オフ | リアルタイム性を求めない一括処理タスク |
| Fast Mode (Opus 4.6) | 長文コンテキストによる追加料金なし | 素早いレスポンスが必要なシーン |
| 入力を200K以内に抑える | 2倍の料金設定を回避 | ドキュメントを分割して処理できる場合 |
💰 コスト最適化: Claudeの長文コンテキストを頻繁に利用するプロジェクトでは、APIYI(apiyi.com)プラットフォームを通じて柔軟な料金プランを利用することも可能です。Prompt CachingとBatch APIを組み合わせることで、1回あたりの呼び出しコストを70%以上削減できる場合があります。
Claude API 1M コンテキストウィンドウのレート制限
1Mコンテキストを有効にすると、長文コンテキストリクエスト(入力が200Kトークン超)には、標準リクエストとは別の独立したレート制限が適用されます。
Tier 4 のレート制限
| 制限タイプ | 標準リクエスト制限 | 長文コンテキスト制限 |
|---|---|---|
| 最大入力トークン/分 (ITPM) | Sonnet: 2,000,000 / Opus: 2,000,000 | 1,000,000 |
| 最大出力トークン/分 (OTPM) | Sonnet: 400,000 / Opus: 400,000 | 200,000 |
| 最大リクエスト数/分 (RPM) | 4,000 | 比例して低下 |
重要事項:
- 長文コンテキストのレート制限と標準のレート制限は個別に計算され、互いに影響しません。
- Prompt Cachingを使用する場合、キャッシュヒットしたトークンは(ほとんどのモデルで)ITPMの制限にカウントされません。
- より高い長文コンテキストのレート制限が必要な場合は、Anthropicのセールスチームにカスタム制限の申請を行うことができます。
Tier 4 へのアップグレード方法
| Tier | 累計入金要件 | 1回の最大入金額 | 月間消費上限 |
|---|---|---|---|
| Tier 1 | $5 | $100 | $100 |
| Tier 2 | $40 | $500 | $500 |
| Tier 3 | $200 | $1,000 | $1,000 |
| Tier 4 | $400 | $5,000 | $5,000 |
累計入金額がしきい値に達すると自動的にアップグレードされ、手動の審査は不要です。
Claude API 1M コンテキストウィンドウ 5 つの実践的な活用シナリオ
シナリオ 1: 大規模コードベースの分析
プロジェクト全体のコードをパッケージ化して Claude に送信し、アーキテクチャのレビュー、バグの特定、またはリファクタリングの提案を行います。
import anthropic
import os
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def collect_codebase(directory, extensions=(".py", ".ts", ".js")):
"""プロジェクト内の指定されたタイプのソースコードファイルをすべて収集します"""
code_content = []
for root, dirs, files in os.walk(directory):
# node_modules などのディレクトリをスキップ
dirs[:] = [d for d in dirs if d not in ("node_modules", ".git", "__pycache__")]
for file in files:
if file.endswith(extensions):
filepath = os.path.join(root, file)
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
code_content.append(f"### {filepath}\n```\n{content}\n```")
return "\n\n".join(code_content)
codebase = collect_codebase("./my-project")
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=8192,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""以下のコードベースに対して、包括的なアーキテクチャレビューを行ってください:
{codebase}
以下の項目を分析してください:
1. 全体的なアーキテクチャ設計の長所と短所
2. 潜在的なセキュリティの脆弱性
3. パフォーマンス最適化の提案
4. コード品質の改善点"""
}]
)
シナリオ 2: 長文ドキュメントの総合分析
法的契約書、研究論文集、決算報告書などの超長文ドキュメントを処理します。
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""以下は、過去 12 か月間の当社の財務報告書セット(約 40 万トークン)です:
{financial_reports}
以下を完了させてください:
1. 各四半期の主要な財務指標のトレンド分析
2. 収益構造の変化とその原因の推測
3. コスト管理効果の評価
4. 次四半期の業績予測およびリスクの指摘"""
}]
)
シナリオ 3: マルチターン長文会話と Extended Thinking の組み合わせ
長いコンテキスト内で Extended Thinking を有効にし、Claude に深い推論を行わせます。
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
betas=["context-1m-2025-08-07"],
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[{
"role": "user",
"content": f"""以下は、ある複雑なシステムの完全な技術ドキュメントとソースコードです:
{large_technical_document}
このシステムの設計思想を深く分析し、改善案を提示してください。"""
}]
)
# Extended Thinking のトークンは、その後の会話には蓄積されません
# API は前のターンの thinking ブロックを自動的に削除します
シナリオ 4: Prompt Caching を使用した長文コンテキストのコスト削減
同じ長文ドキュメントに対して異なる視点から何度も分析を行う場合、Prompt Caching によってコストを大幅に削減できます。
# 最初のリクエスト: 長文ドキュメントをキャッシュする
response1 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"} # キャッシュ可能としてマーク
}],
messages=[{"role": "user", "content": "このドキュメントの主要な論点を要約してください"}]
)
# 2回目のリクエスト: キャッシュヒット、入力トークン料金が 10% に削減
response2 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "ドキュメント内のすべてのデータテーブルを抽出してください"}]
)
シナリオ 5: Batch API による長文ドキュメントの一括処理
Batch API を使用すると、長文コンテキストの料金からさらに 50% オフになります。
# バッチリクエストの作成
batch = client.beta.messages.batches.create(
betas=["context-1m-2025-08-07"],
requests=[
{
"custom_id": "doc-analysis-1",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": f"ドキュメント1を分析: {doc1}"}]
}
},
{
"custom_id": "doc-analysis-2",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": "ドキュメント2を分析: {doc2}"}]
}
}
]
)
🎯 実践的なアドバイス: 実際のプロジェクトでは、まず APIYI (apiyi.com) プラットフォームを通じて小規模なテストを行い、トークンの使用量とコストが予想通りであることを確認してから、大規模なデプロイを行うことをお勧めします。このプラットフォームは詳細な使用統計パネルを提供しており、コストを正確に管理するのに役立ちます。
Claude API 1M コンテキストウィンドウ モデル選択ガイド
1M コンテキストをサポートする 4 つのモデルにはそれぞれ特徴があり、適切なモデルを選択することで、効果とコストの最適なバランスを見つけることができます。
1M コンテキスト対応モデルの詳細比較
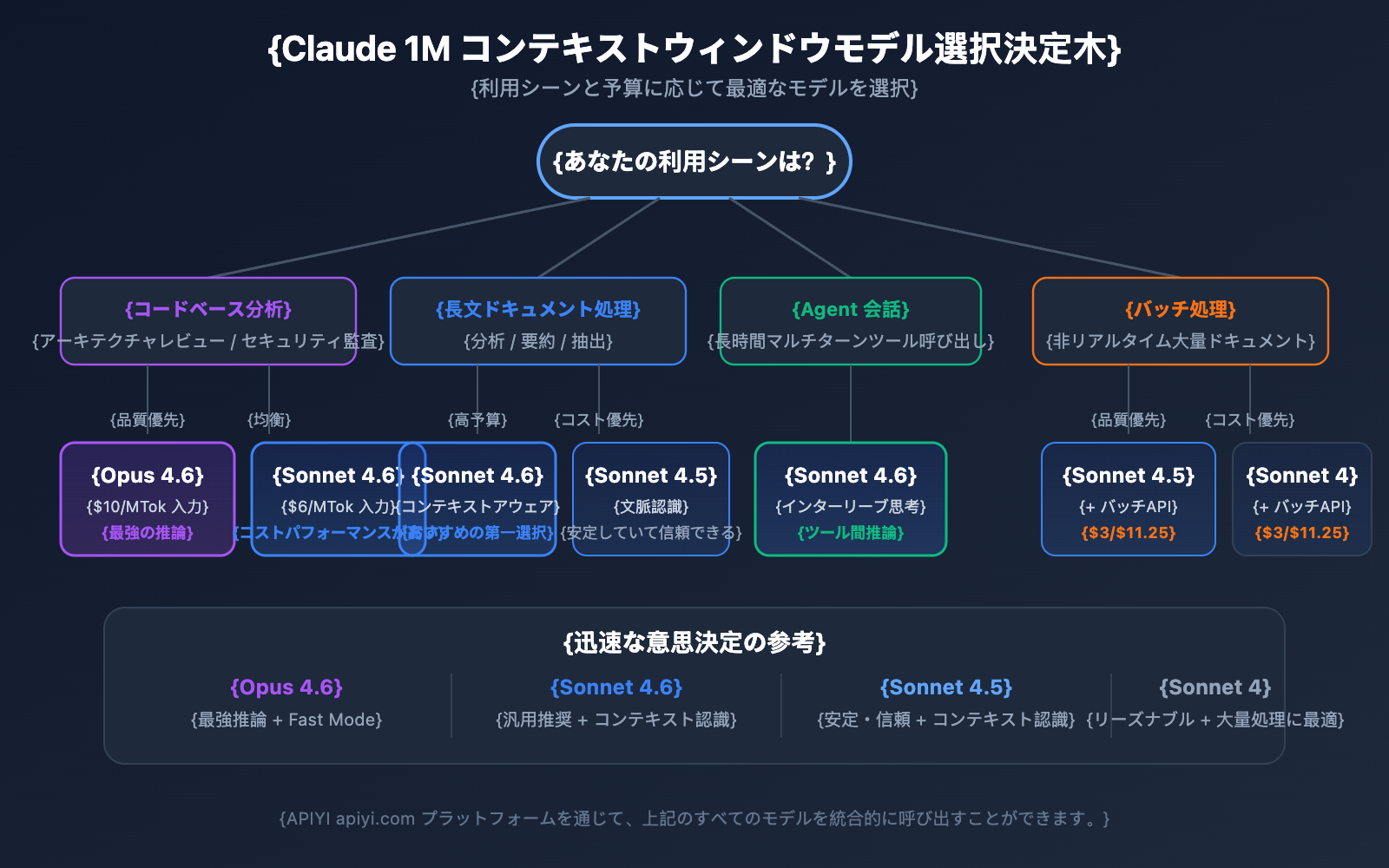
| 比較項目 | Claude Opus 4.6 | Claude Sonnet 4.6 | Claude Sonnet 4.5 | Claude Sonnet 4 |
|---|---|---|---|---|
| 知能レベル | 最強 | 強 | 強 | 中上 |
| 標準入力価格 | $5/MTok | $3/MTok | $3/MTok | $3/MTok |
| 長文コンテキスト入力価格 | $10/MTok | $6/MTok | $6/MTok | $6/MTok |
| Fast Mode | 対応 (6倍の価格) | 非対応 | 非対応 | 非対応 |
| コンテキスト認識 | 非対応 | 対応 | 対応 | 非対応 |
| Interleaved Thinking | 対応 | 対応 | 非対応 | 対応 |
| 推奨シナリオ | 複雑な推論、コード分析 | 一般的な長文ドキュメント処理 | マルチターンエージェント会話 | 日常的な分析タスク |
シナリオ別モデル選択
Claude Opus 4.6 を選ぶべきシナリオ:
- 最強の推論能力を必要とする複雑な分析タスク
- 大規模コードベースのアーキテクチャレビューおよびセキュリティ監査
- Fast Mode(高速レスポンスかつ長文コンテキストの追加料金なし)が必要なリアルタイムシナリオ
- 予算に余裕があり、品質を最優先するエンタープライズ級アプリケーション
Claude Sonnet 4.6 を選ぶべきシナリオ:
- 日常的な長文ドキュメントの分析および要約の抽出
- コンテキスト認識能力を必要とする長文会話
- コストを抑えつつ、高い品質が求められるプロジェクト
- ツール呼び出し間の推論に Interleaved Thinking を必要とする場合
Claude Sonnet 4.5 / Sonnet 4 を選ぶべきシナリオ:
- ドキュメントの一括処理(Batch API と組み合わせてコストを削減)
- 構造化情報の抽出およびデータの整理
- 最新モデルの機能を必要としない安定した本番環境
💡 選択のアドバイス: どのモデルを選択するかは、具体的なアプリケーションシナリオと予算によって決まります。APIYI (apiyi.com) プラットフォームを通じて実際のテストと比較を行うことをお勧めします。このプラットフォームは上記のすべてのモデルの統一インターフェース呼び出しをサポートしており、迅速な切り替えと評価が容易です。
Claude API 1M コンテキストウィンドウの Token 見積もりリファレンス
長文コンテキストの使用を計画する際、コンテンツタイプごとの Token 消費量を把握しておくことが重要です。
| コンテンツタイプ | おおよその Token 数 | 1M ウィンドウの収容量 |
|---|---|---|
| 英文テキスト | ~1 Token / 4 文字 | 約 300 万文字 |
| 日本語/中国語テキスト | ~1 Token / 1.2〜1.5 文字 | 約 70〜80 万文字 |
| Python コード | ~1 Token / 3.5 文字 | 約 250 万文字のコード |
| 一般的なウェブページ (10KB) | ~2,500 Token | 約 400 ページ |
| 大きなドキュメント (100KB) | ~25,000 Token | 約 40 份のドキュメント |
| 研究論文 PDF (500KB) | ~125,000 Token | 約 8 本の論文 |
Claude API 1M コンテキストウィンドウとコンテキスト認識
Claude Sonnet 4.6、Sonnet 4.5、および Haiku 4.5 は、コンテキスト認識(Context Awareness) 機能を備えています。モデルは残りのコンテキストウィンドウ容量をリアルタイムで追跡し、長い会話の中でトークン予算をよりスマートに管理できます。
仕組み:
会話の開始時、Claude は総コンテキスト容量の情報を受け取ります。
<budget:token_budget>1000000</budget:token_budget>
各ツール呼び出しの後、モデルは残り容量の更新を受け取ります。
<system_warning>Token usage: 350000/1000000; 650000 remaining</system_warning>
これにより、1M コンテキストウィンドウにおいて Claude は以下のことが可能になります。
- トークン予算の正確な管理: 会話の後半で突然コンテキストが枯渇するのを防ぎます。
- 出力の長さの合理的な配分: 残りの容量に応じて、回答の詳細度を調整します。
- 超長期のエージェントセッションのサポート: Agent ワークフローにおいて、タスクが完了するまで継続的にタスクを実行できます。
Claude API 1M コンテキストウィンドウ管理戦略: コンパクション(Compaction)
会話の長さが 1M コンテキストウィンドウの限界に近づくと、Claude API は会話を継続するための コンパクション(Compaction/圧縮) 機能を提供します。コンパクションはサーバー側の要約メカニズムであり、会話の初期の内容を自動的に簡潔な要約に圧縮してコンテキストスペースを解放することで、コンテキストウィンドウの制限を超えた超長期の会話をサポートします。
現在、コンパクション機能は Claude Opus 4.6 でベータ版として提供されています。1M コンテキスト内で長時間の Agent タスクを実行する必要がある開発者にとって、コンパクションはコンテキスト管理の第一選択肢となります。
さらに、Claude API は以下の コンテキスト編集(Context Editing) 機能も提供しています。
- ツール実行結果のクリア(Tool Result Clearing): Agent ワークフローにおいて古いツールの呼び出し結果を削除し、トークンを解放します。
- 思考ブロックのクリア(Thinking Block Clearing): 以前のターンの思考内容を能動的に削除し、コンテキストの利用効率をさらに最適化します。
これらの戦略を 1M コンテキストウィンドウと組み合わせることで、超長文コンテキストのシナリオにおいて最高のパフォーマンスとコストのバランスを実現できます。
Claude API 1M コンテキストウィンドウにおける注意点
実際の運用で 1M コンテキストウィンドウを使用する際、見落としがちないくつかの技術的詳細があります。
-
新しいモデルはサイレント・トランクネーションではなく検証エラーを返す: Claude Sonnet 3.7 以降、プロンプトと出力トークンの合計がコンテキストウィンドウを超えると、API は内容を黙って切り捨てる(トランクネーション)のではなく、検証エラーを返します。リクエストを送信する前に Token Counting API を使用してトークン数を見積もることをお勧めします。
-
画像と PDF のトークン消費量は固定ではない: マルチモーダルコンテンツのトークン計算はプレーンテキストとは異なり、同じサイズの画像でも消費されるトークン数が大きく異なる場合があります。画像を大量に使用する場合は、十分なトークンの余裕を持たせてください。
-
リクエストサイズ制限 (Request Size Limits): コンテキストウィンドウが 1M トークンをサポートしていても、HTTP リクエスト自体にサイズ制限があります。超大容量のテキストを送信する場合は、HTTP レイヤーの制限に注意する必要があります。
-
キャッシュを考慮したレート制限: プロンプトキャッシュ(Prompt Caching)を使用する場合、キャッシュにヒットしたトークンは ITPM レート制限にカウントされません。つまり、1M コンテキストのシナリオでは、キャッシュを合理的に利用することで実際のスループットを大幅に向上させることができます。
よくある質問
Q1: 自分のリクエストが長文コンテキストの価格で課金されているか確認するにはどうすればよいですか?
API レスポンス内の usage オブジェクトを確認してください。input_tokens、cache_creation_input_tokens、および cache_read_input_tokens の 3 つのフィールドを合計し、その合計が 200,000 を超えている場合、リクエスト全体が長文コンテキストの価格で課金されます。APIYI(apiyi.com)プラットフォームを通じて呼び出す場合、使用量統計パネルに各リクエストの課金ティアが明確に表示されます。
Q2: 1M コンテキストウィンドウはどのようなファイル形式をサポートしていますか?
Claude API の 1M コンテキストウィンドウは、プレーンテキスト、コード、Markdown などのテキスト形式のほか、画像や PDF ファイルもサポートしています。ただし、画像や PDF のトークン消費量は通常大きく、一定ではないことに注意してください。大量の画像と長文テキストを組み合わせて使用すると、リクエストサイズ制限(Request Size Limits)に達する可能性があります。まずは APIYI(apiyi.com)プラットフォームで小規模なテストを行い、実際のトークン消費量を確認してから大規模に運用することをお勧めします。
Q3: Extended Thinking のトークンは 1M コンテキストを占有しますか?
現在のターンの Extended Thinking トークンはコンテキストウィンドウにカウントされます。しかし、Claude API は以前のターンの思考ブロック(thinking blocks)を自動的に取り除くため、その後の会話で累積することはありません。つまり、思考プロセスによって大量のコンテキストスペースが消費されることを心配せずに、1M コンテキスト内で安全に Extended Thinking を使用できます。
Q4: Tier 4 の条件を満たしていない場合はどうすればよいですか?
現在、1M コンテキストウィンドウは Tier 4 およびカスタムレート制限が設定された組織にのみ開放されています。Tier 4 に到達するには、累計 400 ドルのチャージが必要で、チャージ後に自動的にアップグレードされます。一時的に Tier 4 に到達できない場合は、以下の方法を検討してください。① セグメント処理によって入力を 200K 以内に抑える、② RAG(検索拡張生成)スキームを使用して主要なコンテンツを抽出する、③ Anthropic の営業チームに連絡してカスタムプランについて相談する。
Q5: AWS Bedrock や Google Vertex AI で有効にするには?
1M コンテキストウィンドウは、AWS Bedrock、Google Vertex AI、および Microsoft Foundry で利用可能です。プラットフォームによって有効化の方法は若干異なります。Bedrock では InvokeModel リクエストで対応するパラメータを指定し、Vertex AI では API 設定を通じて行います。具体的な設定方法については、各プラットフォームの公式ドキュメントを参照してください。
Claude API 1M コンテキストウィンドウ ベストプラクティス・チェックリスト
実際のプロジェクトに 1M コンテキストウィンドウを統合する際は、以下のベストプラクティスに従うことをお勧めします。
開発フェーズ
- Token Counting API による事前見積もり: 実際の要求を送信する前に、Token Counting API を使用して入力トークン数を推定し、予期せぬ長いコンテキスト料金の発生を回避しましょう。
- 適切な max_tokens の設定:
max_tokensパラメータはレート制限の計算には影響しません(OTPM は実際の出力に基づいて計算されます)。出力が途切れないよう、高めの値を設定しておくことができます。 - 段階的なテスト: まずは小規模なデータでプロンプトテンプレートの効果を検証し、その後徐々に入力規模を拡大してください。
本番環境
- Prompt Caching(プロンプトキャッシュ)の優先利用: 繰り返し使用する長いドキュメントの場合、Prompt Caching を利用することで、キャッシュがヒットした部分の入力費用を標準価格の 10% に抑えることができます。また、キャッシュヒットしたトークンは ITPM レート制限にカウントされません。
- 非リアルタイムタスクには Batch API を活用: Batch API を使用すると、長いコンテキストの料金からさらに 50% オフになります。これらを組み合わせることで、費用は標準価格の約 60% まで抑えられます。
- usage フィールドの監視: 各リクエストの後にレスポンス内の
usageオブジェクトを確認し、費用の監視・アラートメカニズムを構築しましょう。 - 429 エラー時のリトライ: 長いコンテキストのリクエストには独立したレート制限があります。429 エラーが発生した場合は、
retry-afterヘッダーを確認して適切にリトライを行ってください。
コスト管理
- 200K のしきい値を意識する: 入力が 200K トークンに近い場合は、2 倍の料金設定が適用されるのを避けるために、プロンプトの簡略化を検討してください。
- 適切なモデルの選択: Sonnet シリーズは Opus よりも 40% 安価です。日常的なタスクでは Sonnet を優先的に選択しましょう。
- キャッシュによるレート制限の緩和: キャッシュヒット率が 80% の場合、実際のスループットは名目上の制限の 5 倍に達する可能性があります。
Claude API 1M コンテキストウィンドウ まとめ
Claude API の 1M コンテキストウィンドウにより、開発者は一度に約 75 万文字の内容を処理できるようになり、コードベースの分析、長大なドキュメントの処理、複雑な対話などのシナリオで強力な能力を発揮します。主なポイントの振り返りは以下の通りです。
- コード 1 行で有効化:
anthropic-beta: context-1m-2025-08-07ヘッダーを追加するだけです。 - 4 つのモデルが対応: Claude Opus 4.6、Sonnet 4.6、Sonnet 4.5、Sonnet 4。
- 透明性の高い料金体系: 200K トークンを超えると入力料金が 2 倍、出力料金が 1.5 倍になります。200K 未満は標準価格のままです。
- 独立したレート制限: 長いコンテキストのリクエストは、標準リクエストの枠に影響を与えません。
- 多様な最適化手法: Prompt Caching、Batch API、Fast Mode を組み合わせてコストを削減できます。
APIYI (apiyi.com) を通じて Claude 1M コンテキストウィンドウの能力をいち早く体験し、実際のビジネスシーンに合わせた最適な活用方法を見つけてみてください。
参考文献
-
Anthropic 公式ドキュメント – Context Windows: Claude API コンテキストウィンドウに関する技術解説
- リンク:
platform.claude.com/docs/en/build-with-claude/context-windows
- リンク:
-
Anthropic 公式ドキュメント – Pricing: Claude API の詳細な料金体系
- リンク:
platform.claude.com/docs/en/about-claude/pricing
- リンク:
-
Anthropic 公式ドキュメント – Rate Limits: レート制限と Usage Tier に関する説明
- リンク:
platform.claude.com/docs/en/api/rate-limits
- リンク:
📝 著者: APIYI チーム | AI モデル API の使い方の詳細については、APIYI(apiyi.com)ヘルプセンターをご覧ください