Gemini 3 Pro Image インターフェースを使用して画像を生成し、返された最初の画像をそのままユーザーに表示している場合、画像が「どこかおかしい(構図が奇妙、細部が粗い、画面が欠けている)」といった問題が発生することがあります。これはモデルの性能が低下したのではなく、取得する画像が間違っている可能性が高いです。実は、最初の画像はモデルの「思考の草稿」である可能性が高く、真の完成版はレスポンスに含まれる最後の画像であるためです。
本記事では、Google AI公式ドキュメントに基づき、Gemini 3の「画像思考」メカニズムのレスポンス構造を分解します。なぜ1回の呼び出しで2〜3枚の画像が返されるのか、part.thought フィールドや thought_signature 署名を使ってどのように最終画像を指定・抽出するかを解説し、Python、Node.js、cURLの3言語での適切な抽出コードを提供します。すべての例は APIYI (apiyi.com) の透過的な転送に基づいています。API中継サービスはGeminiのネイティブなレスポンス構造を完全に保持しているため、開発者は公式の仕様に従って処理するだけで問題ありません。
Gemini 3 画像思考メカニズムの核心
コードを書く前に、なぜ1回の呼び出しで複数の画像が返されるのかという根本的な問題を整理しましょう。
なぜGemini 3の画像思考は無効化できないのか
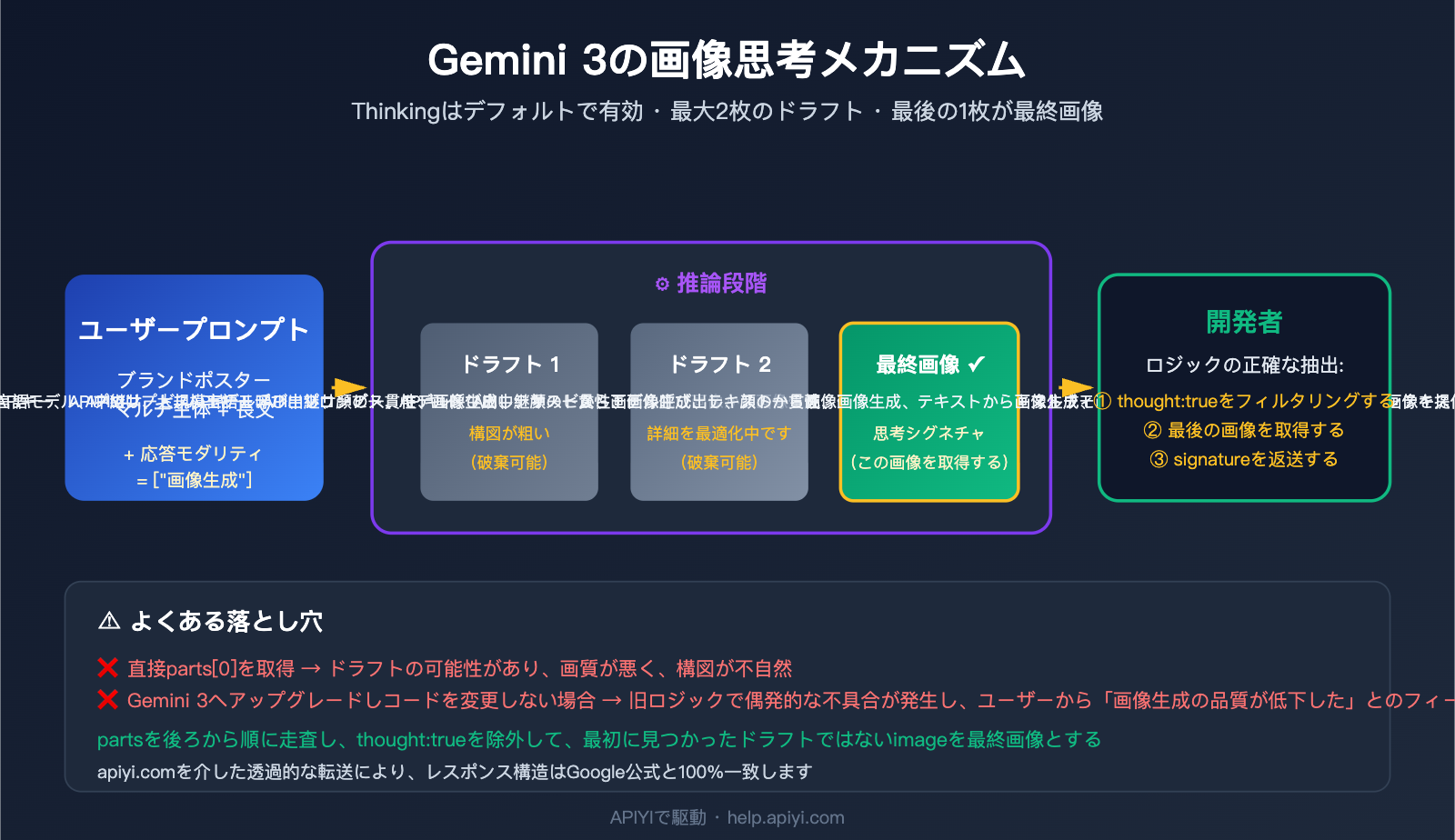
Google は gemini-3-pro-image-preview(商品名:Nano Banana Pro)において、Gemini テキストモデルと同源の「Thinking(思考)」メカニズムを導入しました。モデルは最終的な画像を出力する前に、最大2枚の一時的な画像を使って構図やレイアウト、文字のレンダリングを試行します。これは、人間のデザイナーが最終版の前に草稿を描くプロセスに似ています。
公式ドキュメントには以下の3つの重要な事実が明記されています。
| 事実 | 説明 |
|---|---|
| デフォルトで有効(無効化不可) | Thinking特性はAPI層で強制的に有効化されており、オフにするパラメータはありません |
| 最大2枚の一時画像 | モデルは最大2枚の思考草稿を生成しますが、毎回必ず生成されるわけではありません |
| 最後が最終画像 | Thinkingフェーズの最後の画像が、最終的なレンダリング結果となります |
| 思考トークンは課金対象 | 思考内容の返却を要求しなくても、思考トークンは消費され、課金されます |
つまり、受け取るレスポンスが最初から複数枚構成であることは仕様であり、バグではありません。 重要なのは「どうやってオフにするか」ではなく、「どうやって最終画像だけを正しく取得するか」です。
🎯 アーキテクチャの理解: Gemini 3の画像思考メカニズムは、Gemini 3 Pro テキストモデルの推論チェーンと同じ思考エンジンを使用しています。これが、Nano Banana Pro が長文レンダリングやマルチ主体の一貫性において、旧版の Nano Banana を圧倒的に凌駕している理由です。APIYI (apiyi.com) を経由して呼び出す際も、すべての思考動作はGoogleへの直接呼び出しと完全に一致しており、中継層が思考データを破棄することはありません。
よくあるトラブルの現場復旧
ユーザーコミュニティで見られる典型的な失敗例は以下の通りです。
API呼び出し → レスポンス受信 → parts配列が含まれている → parts[0] のimageをそのまま表示
この疑似コードは旧版の Nano Banana (Gemini 2.5 Flash Image) 時代にはうまく動作していました。なぜなら、そのバージョンではデフォルトで画像が1枚しか返されなかったからです。Gemini 3 Pro Image にアップグレードすると、同じコードでは「思考草稿」を最終製品として扱ってしまうため、ユーザーにはプロンプトの指示と一致しない、不自然な「未完成品」が表示されてしまいます。
この罠が特に見つけにくい理由は以下の通りです。
- 毎回失敗するわけではない: シンプルなプロンプトの場合、モデルがThinkingをトリガーせず、単一画像が返されることがあるため
- エラーが発生しない: レスポンス構造自体は適正であり、
parts[0]の取得に例外は発生しないため - 品質は低いが画像は表示される: ユーザーは「モデルの性能不足」だと勘違いしますが、実際には取得画像が間違っているだけであるため
description: Gemini 3 画像生成 API の思考プロセス(Thinking)を正しく扱い、最終的な生成画像のみを抽出するための技術ガイド。APIYI経由での実装例も紹介します。
Gemini 3 画像思考(Thinking)のレスポンス構造を徹底解説
API呼び出しがどのようなデータを返すのかを理解することは、正しく処理を行うための大前提です。
一度の呼び出しにおける完全な「parts」配列
Gemini 3 Pro Image の思考(thinking)機能がトリガーされた場合、response.candidates[0].content.parts は以下のような構造になります:

candidates[0].content.parts = [
{ text: "構成を考えています...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // 草稿1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // 草稿2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } // 最終画像
]
この配列に対する誤解こそが、多くのバグの原因となります。以下の3つのルールを覚えれば、正しいコードが書けます。
最終画像を識別する3つの公式シグナル
Googleは最終画像を識別するための3つのシグナルを提示しています。以下の優先順位で使用してください:
| 優先度 | 識別シグナル | 説明 | 信頼度 |
|---|---|---|---|
| ★★★ | part.thought === false(またはフィールド欠損) |
思考内容ではないことが明確にマークされている | 最高 |
| ★★ | thought_signature フィールドの存在 |
最終画像のみに署名が含まれる | 高 |
| ★ | 配列内の最後の inline_data |
"最後が最終画像である"と公式ドキュメントで規定 | フォールバック |
最も堅牢な方法は組み合わせることです:まず thought フィールドを確認し、なければ thought_signature で補完、それもダメなら最後の inline_data を採用するようにします。
Gemini 3.1 Flash Image の thinking_level の違い
注意が必要なのは、すべてのGemini画像モデルが同じ挙動をするわけではない点です:
| モデル | Thinking デフォルト | 可変 thinking_level | 適用シーン |
|---|---|---|---|
gemini-3-pro-image-preview |
強制ON | ❌ 不可 | 高忠実度、プロ向け素材 |
gemini-3-flash-image |
デフォルト minimal | ✅ minimal / high | リアルタイム対話、大量生成 |
gemini-2.5-flash-image |
Thinkingなし | – | 旧バージョン互換 |
Gemini 3.1 Flash は thinking_level を手動で引き上げて緻密な構成を得ることも、minimal に下げて応答速度を優先することも可能です。このような柔軟性は Pro 版にはありません。
🎯 選定のヒント: 一般ユーザー向けの画像生成機能を作る場合は、デフォルトで
gemini-3-flash-image+thinking_level=minimal(高速・安価)を使用し、ユーザーが「高品質モード」をオンにしたときにgemini-3-pro-image-preview(思考・高忠実度)に切り替えるのがおすすめです。APIYI プラットフォームでは、どちらのモデルも同じAPIキーとベースURLでシームレスに切り替え可能です。
Gemini 3 画像思考を正しく処理するコード例
理論が理解できたところで、コードを見てみましょう。以下の例はすべて APIYI を経由した透過転送を前提としています。Google AI Studio に直結していたコードのベースURLを APIYI のアドレスに、APIキーを APIYI のキーに置き換えるだけで、レスポンス処理ロジックはそのままで動作します。
Python 公式 SDK での正しい書き方
from google import genai
client = genai.Client(
api_key="sk-your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="サイバーパンクスタイルの柴犬、ネオン看板の下に立っている、4K高画質",
config={"response_modalities": ["IMAGE"]}
)
# ✅ 正解:すべての思考(thought)パーツを除外し、最終画像のみ保存する
for part in response.parts:
if getattr(part, "thought", False):
continue # 思考草稿をスキップ
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("final_output.png")
break # 最初の非思考画像が最終画像
悪い例(ユーザーがよくハマる典型的なコード):
# ❌ 間違い:最初の画像を直接取得すると、思考過程の草稿を掴んでしまう可能性がある
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# 生成された画像が未完成品である可能性がある
Node.js / TypeScript での正しい書き方
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "サイバーパンクスタイルの柴犬、ネオン看板の下に立っている、4K高画質",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ 後ろから走査し、最初に見つかった thought でない画像が最終画像
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
cURL + jq コマンドライン版
シェルスクリプトで呼び出す場合は jq でフィルタリング可能です:
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "サイバーパンクスタイルの柴犬"}]
}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
この jq 式は、「thought: true の除外」「画像 MIME タイプのみ保持」「last を取得」という3つのステップを行っており、公式の識別ルールに完璧に準拠しています。
🎯 コードレビューのポイント: Gemini の画像生成レスポンスを扱うコードをレビューする際は、thought フィルタリングが確実に実装されているかを確認してください。チーム内で
extractFinalImage()のような統一されたユーティリティ関数を定義し、すべてのビジネスロジックでそれを呼び出すようにすることをお勧めします。APIYI を介せば、ローカルでコードを十分にテストした上で、そのまま本番環境へ移行可能です。
Gemini 3 画像生成の高度なトピック
マルチターン編集では thought_signature の返却が必須
Nano Banana Pro は「連続編集」をサポートしています。たとえば、「背景を海辺に変更して」と言った後に「犬の表情を嬉しそうにして」と指示するようなケースです。しかし、公式はマルチターン対話において、前回の thought_signature を必ず返却することを強く求めています。これを行わないと、モデルは前回の推論コンテキストを引き継ぐことができず、生成品質が著しく低下します。
正しいマルチターンの実装例:
# 第1ターン
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="公園を走る柴犬"
)
# 最終画像の part オブジェクト(thought_signature を含む)を抽出
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# 第2ターン: history 全体に final_part を追加
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "公園を走る柴犬"}]},
{"role": "model", "parts": [final_part]}, # thought_signature を含む
{"role": "user", "parts": [{"text": "背景を海辺の夕暮れに変更して"}]}
]
)
思考プロセスの確認(デバッグ用)
モデルが「何を考えていたのか」を確認したい場合は、include_thoughts を有効にしてください。
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="複雑なブランド広告ポスターのプロンプト...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# 思考プロセスを出力
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[思考] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"draft_{id(part)}.png") # 下書きを保存
これは「なぜ生成結果が期待通りでないのか」をデバッグする際に非常に役立ちます。下書きを確認することで、モデルがプロンプトのどの部分を誤解したかを推測できます。

Thinking トークンの課金ロジック
Gemini 3 Pro Image の料金体系において、開発者が特に注意すべき点は以下の通りです。
| トークンタイプ | 単価(100万あたり) | 生成の強制 |
|---|---|---|
| 入力プロンプト | $2 | ✅ あり |
| 出力画像/テキスト | $12 | ✅ あり |
| Thinking reasoning | 出力トークンとして計上 | ✅ 強制、オフ不可 |
つまり、最終的な画像のみが必要で思考プロセスを気にしていない場合でも、thinking トークンは生成され、課金対象となります。削減できるのは「思考内容を自分に返すか」(include_thoughts パラメータ)だけであり、「思考プロセスを実行するかどうか」は選択できません。
🎯 コスト最適化のアドバイス: シンプルなシナリオ(製品画像やイラストの生成など)では
gemini-3-flash-image+thinking_level=minimalを使用することで、Pro 版よりもコストを大幅に抑えられます。複雑なシナリオ(複数被写体の一貫性、高精度な文字レンダリングなど)の場合にのみ Pro を使用してください。APIYI(apiyi.com)経由で利用する際は、使用量監視を有効にし、業務シナリオにおけるコストと品質のバランスを比較検討した上で本番環境の構成を決定することをお勧めします。
Gemini 3 画像生成のトラブルシューティング
問題 1: 常に品質の低い画像が生成される
診断ステップ:
# すべての parts の thought フィールドを出力
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"Part {i}: thought={is_thought}, image={has_image}, signature={has_sig}")
出力に image=True となっているパーツが複数ある場合は、典型的な「複数画像が返されている」状態です。コードがインデックスの若い part を取得していないか確認してください。
問題 2: レスポンス構造に thought フィールドがない
可能性のある原因: REST API が返す生の JSON を使用している場合、キャメルケースの thought となっていますが、一部の SDK バージョンではスネークケースに変換されている可能性があります。両方に対応できるようにしておくのが安全です。
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
問題 3: すべての画像を保存したい(デバッグ用)
公式が推奨する完全な走査方法は以下の通りです。
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "draft" if is_draft else "final"
filename = f"gemini_output_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"保存完了: {filename}")
Gemini 3 画像生成における思考プロセスの実務への適合
理論や基礎コードの先には、実際のビジネスシーンで注意すべき詳細がいくつか存在します。
シーン1: Webフロントエンドでの生成画像表示
フロントエンドでBase64画像を受け取ったら、data:image/png;base64,xxx 形式に変換して表示する必要があります。フロントエンド側で思考(thought)のフィルタリングを行わないでください。バックエンド側でフィルタリング済みのクリーンな結果を返すようにしましょう。そうしないと、フロントエンド側でGeminiの複雑なレスポンス構造を理解しなければならなくなります。
// ❌ 推奨しません:フロントエンドで直接Geminiの生レスポンスを処理する
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ 推奨:バックエンドで一括フィルタリングし、フロントエンドは最終画像のみを消費する
// バックエンド APIの戻り値: { "image": "base64-string" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
シーン2: 画像生成 + OSS/CDNへの保存
バッチ処理で生成した画像をオブジェクトストレージに保存する際は、ハッシュ値を利用して重複書き込みを防ぎましょう。
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
必ず最終画像のみをアップロードしてください。思考の草稿(thought draft)をアップロードしてしまうと、OSSが汚染され、ストレージコストも無駄になります。
シーン3: ストリーミングレスポンスの適切な処理
Gemini 3はストリーミングに対応しており、先に思考の草稿が届き、最後に最終画像が届きます。ストリーミング環境では「受け取りながら上書きする」アプローチを推奨します。
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # 草稿はスキップ
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # 毎回上書きし、最後の一つを残す
# ストリーム終了後、current_imageに最終画像が格納されている
🎯 ストリーミングの最適化: ユーザー体験向上のため、思考中の草稿もフロントエンドに送信して「読み込み中のプレビュー」として表示し、最終画像が届いたら差し替えるといった「プログレッシブ・レンダリング」は、コンシューマー向けサービスで非常に好まれます。APIYI(apiyi.com)はGeminiのSSEストリーミングプロトコルを完全サポートしており、フロントエンドの実装感は直結時と変わりません。
Gemini 3 画像思考とビジネス指標の関連性
品質向上の定量データ
Googleの公式発表およびコミュニティでの実測によると、Thinking機能を有効にすることで画像品質が大幅に向上しています。
| 指標 | Gemini 2.5 Flash Image | Gemini 3 Pro Image (thinking) | 向上幅 |
|---|---|---|---|
| 長文テキストの描画精度 | ~70% | ~95% | +35% |
| マルチ主体の一貫性(5人) | ~60% | ~90% | +50% |
| 複雑な構図への追従度 | ~75% | ~92% | +22% |
| 初回画像の利用率 | ~80% | ~95% | +18% |
代償として応答時間は40〜80%増加し、トークンコストも20〜40%上昇します。導入価値があるかどうかは、ビジネスモデル次第です。
- プロ向けの素材制作、広告用クリエイティブ: 品質向上がコスト増を大きく上回るため、強く推奨します。
- UGCユーザー向け画像生成、大量のコンテンツ作成: Flashモデル +
thinking_level=minimalでバランスを取ることを推奨します。 - リアルタイム対話、チャットボット: 応答速度を優先すべきであり、Flashモデルが適しています。
🎯 A/Bテストの推奨: 感覚だけでモデルを選ばないでください。APIYI (apiyi.com) 上で2つのモデル用に個別のAPIキーを作成し、業務層でトラフィックを50/50に振り分け、7日後に実際のユーザー満足度指標(「いいね」率、再生成率、転換率)を比較することを推奨します。データこそが、そのモデルが価格に見合う価値があるかを教えてくれます。
Gemini 3 画像生成の思考(Thinking)に関するFAQ
Q1: Gemini 3 にアップグレードしてから、画像生成コードで「たまに未完成品が出力される」のはなぜ?
Gemini 3 Pro Image では Thinking(思考機能)がデフォルトで有効 になっており、レスポンスに 1〜3 枚の画像が含まれる可能性があるためです。古いコードでは parts[0] を取得しているケースが多いと思われますが、parts[0] には草案が含まれている場合があります。修正案: thought: true を除外し、最後に含まれる「思考ではない画像」を取得するようにコードを書き換えてください。
Q2: APIYI プラットフォームの Gemini 3 画像生成 API でも Thinking 機能は働きますか?
全く同じ動作です。 APIYI (apiyi.com) は透過的な転送アーキテクチャを採用しており、Gemini のネイティブレスポンスに含まれる thought、thought_signature、inline_data はすべて変更や削除を加えることなくそのまま転送されます。これまで Google AI Studio に直接接続していたコードを、そのまま APIYI に向けるだけで完全に動作します。
Q3: パラメータで最終画像のみを返すよう強制できますか?
できません。 公式ドキュメントには「この機能はデフォルトで有効になっており、API で無効にすることはできません(This feature is enabled by default and cannot be disabled in the API)」と明記されています。include_thoughts: false を設定して思考テキストを除外することは可能ですが、画像草案は依然として含まれる可能性があるため、コード側でのフィルタリングは必須です。
Q4: Thinking 機能のせいでレスポンスが遅くなりました。最適化の方法は?
以下の 3 つのアプローチがあります:
- シンプルな生成であれば
gemini-3-flash-image+thinking_level=minimalを使用する。 - 複雑な要求でない場合は、プロンプトをより正確に記述し、モデルの「過剰な思考」を防ぐ。
- ストリーミング応答を使用し、思考過程の草案を先に表示させ、最終画像を最後に受信するようにする。
Q5: レスポンスで実際に Thinking が発生したか確認する方法は?
response.usage_metadata.thoughts_token_count フィールドを確認してください。この値が 0 より大きければ、Thinking がトリガーされています。この値は、実際の推論コストを見積もる際にも役立ちます。
Q6: thought_signature は自分で作成や変更ができますか?
できません。 thought_signature は Google サーバー側で発行される暗号化された認証情報であり、マルチターン対話におけるコンテキストの連続性を検証するためのものです。自分で作成した signature はサーバー側で拒否されます。マルチターン編集を行う際は、signature を含む part 全体をそのまま返送してください。
Q7: 100 枚の画像をバッチ生成する際、Thinking による不確実性をどう処理すべき?
各リクエストのレスポンスを個別に処理し、thoughts_token_count を記録することを推奨します。APIYI (apiyi.com) の管理コンソールでは呼び出し単位でトークン消費量を確認できるため、Thinking の消費が異常に高いリクエストを絞り込んで確認できます。また、バッチ処理には(Gemini 3 Pro Image が対応している)Batch API を使用すれば、コストが半減し、非同期でレスポンスを処理できます。
Gemini 3 画像生成における思考機能のまとめとチェックリスト
本記事の要点として、Gemini 3 の画像生成における思考機能は、品質を向上させると同時にレスポンス構造を劇的に変化させました。一言で言えば:
✅ 核となる原則:
parts[0]を安易に取得せず、thought: trueを常に除外し、最後にあるinline_dataを最終画像として取得すること。

移行チェックリスト
プロジェクトを Gemini 2.5 から Gemini 3 にアップグレードする際は、以下のリストを確認してください:
- モデル ID の置換:
gemini-2.5-flash-image→gemini-3-pro-image-previewまたはgemini-3-flash-image - レスポンス解析の書き換え: 全ての
parts[0]を「thought を除外 + 最後の要素を取得」に変更 - signature 処理の追加: マルチターン対話では
thought_signatureを含む part を保持 - 課金予測の確認: Thinking トークンが出力に含まれるため、コストが 20〜40% 上昇する可能性がある点に注意
- 回帰テスト: 20 種類以上のサンプルプロンプトを用意し、Gemini 2.5 と Gemini 3 の出力を比較して予期せぬ不具合を防止
クイック統合テンプレート
以下のコードをチームの「ゴールデンテンプレート」として活用してください:
def extract_final_image(response):
"""Gemini 3 Image レスポンスから最終画像を安全に抽出する"""
parts = response.candidates[0].content.parts if response.candidates else []
# 後ろから順に、thought ではない画像を探す
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # base64 bytes
return None # 最終画像が見つからなかった場合、再試行が必要
🎯 最後のアドバイス: Gemini 3 の画像生成における思考機能は諸刃の剣です。正しく使えば業界トップレベルの生成品質が得られますが、間違えれば「ランダムな抽選」のような未完成品が出力されます。APIYI (apiyi.com) を経由して接続した後、まずは 10〜20 個の実際の業務プロンプトで回帰テストを行い、様々な思考トリガー状態でも最終画像が正しく取得できることを確認してから本番環境へデプロイすることをお勧めします。当プラットフォームは Gemini 3 の全シリーズに対応しており、API レスポンスは Google 公式と完全に一致します。
著者: APIYI テクニカルチーム | さらなる AI 画像生成チュートリアルについては help.apiyi.com をご覧ください。




