Claude Opus 4.7は2026年4月16日に正式リリースされましたが、公開翌日からコミュニティでは議論が真っ二つに分かれています。公式のベンチマークでは14項目中12項目で4.6を上回ったとされていますが、GitHubやX(旧Twitter)では多くの開発者が「4.6の方が優秀だ」と不満を漏らしており、中には「新バージョンを装った、改悪版の4.6」と呼ぶ声さえ上がっています。
本記事では、Anthropicの公式データ、第三者による独立したテスト、そしてコミュニティからの生のフィードバックに基づき、コーディング能力、視覚認識、長文コンテキスト、Tokenizerの変更、Task Budgetsなど8つの側面から Claude Opus 4.7 を徹底評価し、今すぐ移行すべきかどうかを判断する材料を提供します。
核心的な価値: この記事を読めば、あなたのビジネスシーンにおいてClaude Opus 4.7がアップグレードになるのか、それともダウングレードになるのか、そして移行に伴うリスクをどう回避すべきかが分かります。

Claude Opus 4.7 リリースの背景と主要情報
Claude Opus 4.7は、Anthropicが2026年4月16日にリリースしたフラッグシップモデルです。Opus 4.6の価格設定(100万トークンあたり入力5ドル/出力25ドル)を引き継ぎつつ、複数のベンチマークで新記録を打ち立てました。しかし、同時にTokenizerの再構築、MRCR長文コンテキストベンチマークの大幅な低下、新しい「xhigh」推論モードの導入など、システム全体にわたる変更も行われており、これらが実際のビジネスパフォーマンスに直接的な影響を与えています。
Claude Opus 4.7 リリース概要
| 項目 | 詳細 |
|---|---|
| リリース日 | 2026年4月16日 |
| 提供元 | Anthropic |
| 入力価格 | 5ドル / 100万トークン(4.6と同等) |
| 出力価格 | 25ドル / 100万トークン(4.6と同等) |
| コンテキストウィンドウ | 100万トークン(標準価格) |
| 最大画像解像度 | 長辺2576px / 375万画素 |
| 新規推論モード | xhigh(highとmaxの中間) |
| 新規実験機能 | Task Budgets(パブリックベータ) |
| 利用チャネル | Claude API、Amazon Bedrock、Google Vertex AI、Microsoft Foundry |
🎯 技術的なアドバイス: Claude Opus 4.7への正式な移行前に、APIYI (apiyi.com) プラットフォームを通じて4.6と4.7を同時に呼び出し、並行比較テストを行うことを推奨します。このプラットフォームは統一されたインターフェースを提供しており、モデルの切り替えはパラメータを変更するだけで済むため、パフォーマンスの差異を迅速に特定できます。
Claude Opus 4.7 の主なアップグレードポイント
Anthropicが公式に発表しているアップグレードは、主に以下の4点に集中しています。
- ソフトウェアエンジニアリング能力の著しい向上: SWE-bench Verifiedで80.8%から87.6%へ、SWE-bench Proで53.4%から64.3%へと飛躍的に向上。
- 視覚理解能力の飛躍的な向上: 375万画素の高解像度画像をサポートし、視覚ベンチマークスコアが54.5%から98.5%へ向上。
- Agentic(自律型)ツール使用能力の強化: MCP-Atlasベンチマークで単項目として最大の向上を達成し、ツールなしの条件でも13ポイント上昇。
- 指示追従の精度向上: 曖昧な指示に対する処理がより堅牢になり、実行の徹底度が増した。
しかし、コミュニティからの実際のフィードバックは、これとは異なる側面を映し出しています。
description: Claude Opus 4.7の主要な機能変更と、Tokenizerの再構築によるコストへの影響、新しい推論レベル「xhigh」、およびエージェントのコスト管理に役立つ「Task Budgets」について詳しく解説します。
Claude Opus 4.7 の主要機能の詳細解説
Claude Opus 4.7 の主要な機能変更は、モデルの能力向上だけでなく、提供形態における重要な調整も含んでいます。これらの変化を理解することは、モデルのパフォーマンスを正しく評価するために不可欠です。
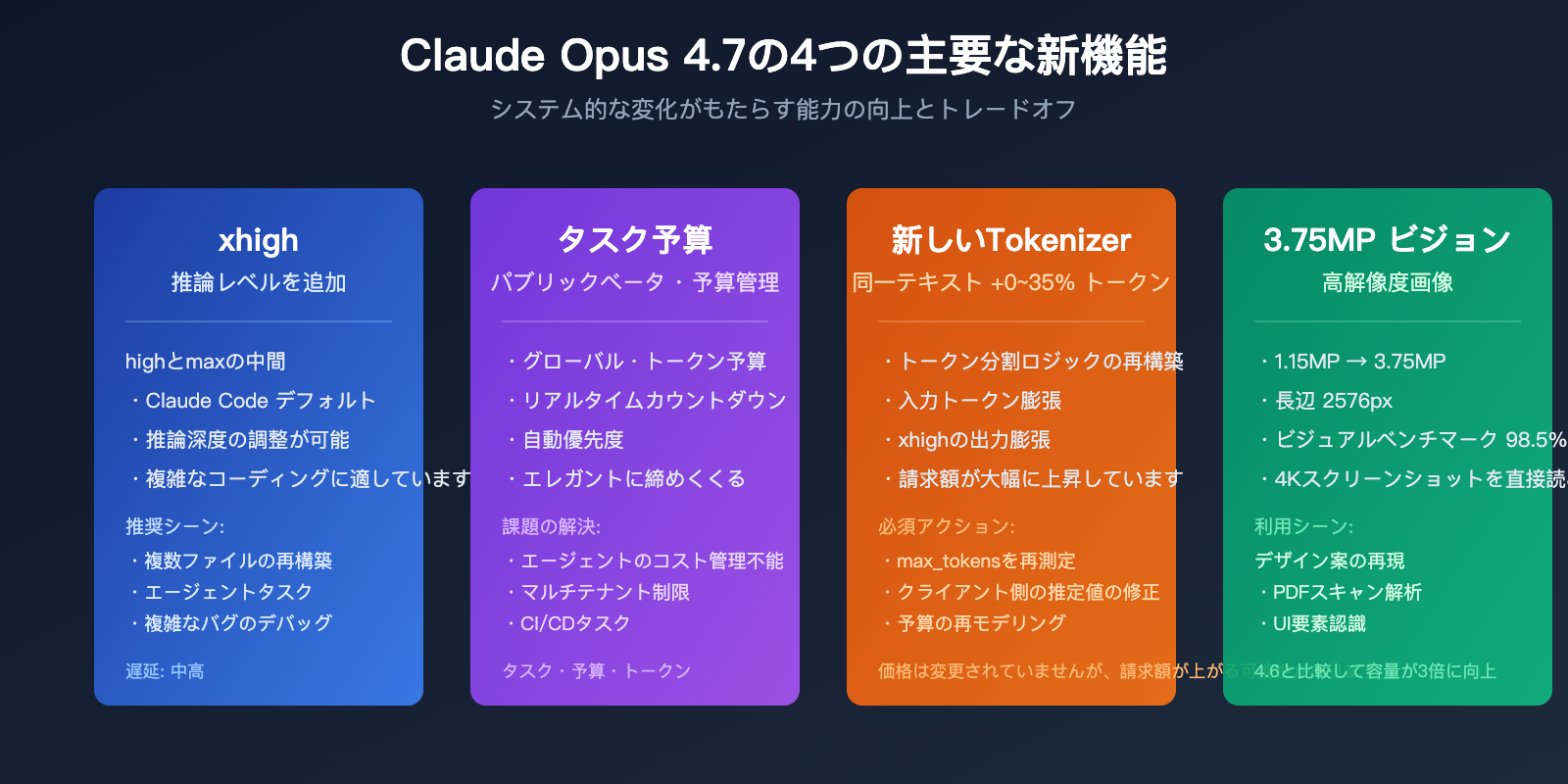
Claude Opus 4.7 の4つのシステム的変化
| 機能モジュール | 4.6 のパフォーマンス | 4.7 の変化 | ビジネスへの影響 |
|---|---|---|---|
| Tokenizer | オリジナルのトークン分割 | 同じテキストで 1.0–1.35倍のトークンを生成 | 実際の請求額が最大35%上昇する可能性 |
| 推論レベル | low / medium / high / max | 新たに xhigh を追加(Claude Code のデフォルト) | 推論の深さと遅延がより細かく調整可能 |
| Task Budgets | なし | パブリックベータ版、グローバルなトークン予算管理 | エージェントのループコストを制御可能 |
| 視覚入力 | 約 115万画素 | 約 375万画素(3倍) | 高解像度のスクリーンショットや図面を処理可能 |
| 長文コンテキスト MRCR | 78.3% | 32.2% | 長文ドキュメントの再現率が大幅に低下 |
| SWE-bench Verified | 80.8% | 87.6% | 実際のコードタスクの性能が大幅に向上 |
Tokenizer 変更による潜在的なコスト
Claude Opus 4.7 において最も重要でありながら見落とされがちなのが、Tokenizer の再構築です。公式ドキュメントでは、同じ入力テキストであっても、4.7 では 4.6 と比較して 1.0 倍から 1.35 倍のトークン数にマッピングされることが明記されています。これは以下のことを意味します。
- プロンプトの長さは変わらなくても、入力トークンの課金額が最大 35% 増加する可能性がある
- xhigh や max の推論レベルでは、出力トークンも同様に大幅に増加する可能性がある
- 以前 4.6 を基準に設定した
max_tokensの上限を全面的に再テストする必要がある - クライアント側で文字数に基づいてトークン数を推定していたロジックは書き直しが必要
💰 コスト最適化: トークンコストに敏感な本番環境では、Claude Opus 4.7 への移行前に、APIYI (apiyi.com) プラットフォームで実際のトラフィックを用いた請求額の比較を行うことを強く推奨します。同プラットフォームは柔軟な課金照会とリアルタイム監視をサポートしており、移行に伴うコスト増を定量化するのに役立ちます。
xhigh 推論レベルの活用戦略
xhigh は Opus 4.7 で新しく導入された推論レベルで、high と max の間に位置します。Anthropic は、コーディングやエージェントタスクにおいてデフォルトで xhigh を使用することを推奨しており、Claude Code のすべてのプランでもデフォルト設定となっています。
各推論レベルの推奨ユースケース:
| 推論レベル | 適したタスク | 遅延 | 推奨される使用シーン |
|---|---|---|---|
low |
簡単な質問、フォーマット変換 | 最低 | 高並列、低複雑度のタスク |
medium |
通常のコード生成 | 低 | 一般的な開発補助 |
high |
複雑なコード、技術設計 | 中 | 通常のエージェントタスク |
xhigh |
困難なデバッグ、大規模リファクタリング | 中高 | 推奨:Claude Code 等のコーディングシーン |
max |
極めて複雑な推論 | 高 | 研究目的、遅延を許容できるタスク |
Task Budgets:エージェントのループコストを終わらせる機能
Task Budgets は Opus 4.7 で導入されたパブリックベータ機能で、これまでエージェントのループ処理において総トークン消費量を制御しにくいという課題を解決します。仕組みは以下の通りです。
- 開発者はエージェントのループを開始する前に、全体的なトークン予算を設定する
- モデルは各レスポンスにおいて予算の残りを確認できる
- モデルは残りの予算に応じて、思考の深さやツール呼び出し回数を自動的に調整する
- 予算が尽きる前に、モデルは重要なタスクを優先的に完了させ、適切に終了処理を行う
この機能は、新しい redact-thinking-2026-02-12 UI ヘッダーと組み合わせることで、エージェントのコスト管理を実質的に改善します。
Claude Opus 4.7 実測データ全景
このセクションは本稿の核心です。Anthropic公式のベンチマーク、第三者による独立評価、およびコミュニティでの再テストデータを集約し、Claude Opus 4.7と4.6の真の実力差を明らかにします。
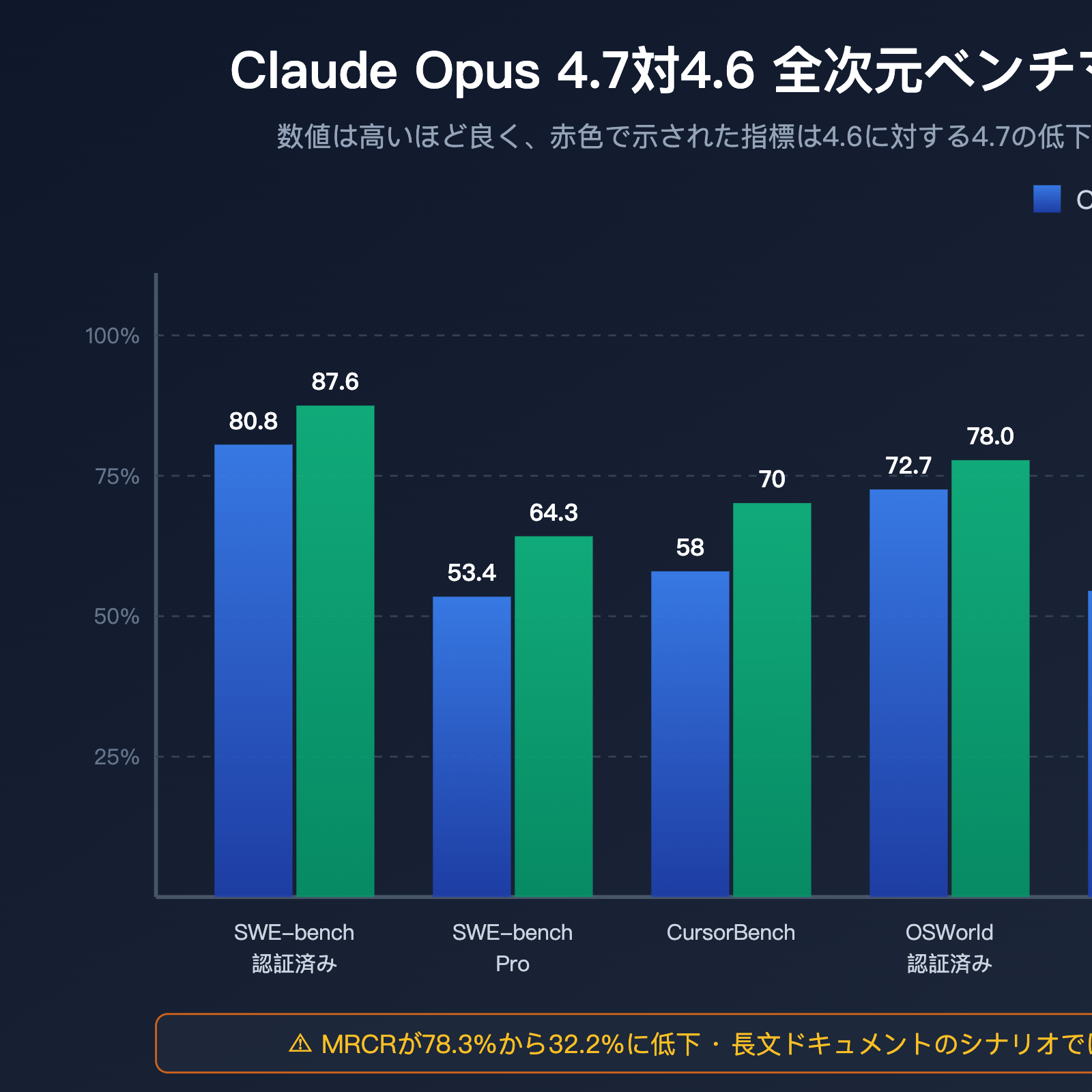
コーディング能力ベンチマーク:4.7が全面的にリード
| コーディング指標 | Opus 4.6 | Opus 4.7 | 向上幅 | 説明 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8pt | 実際のGitHub Issue修正タスク |
| SWE-bench Pro | 53.4% | 64.3% | +10.9pt | 多言語・高難易度バリアント |
| CursorBench | 58% | 70% | +12pt | IDE内での実際のコーディング |
| OSWorld-Verified | 72.7% | 78.0% | +5.3pt | デスクトップ操作とPC利用 |
| MCP-Atlas(ツールなし) | — | +13pt | 単項目で最大向上 | エージェントツールチェーン |
| MCP-Atlas(ツールあり) | — | +6pt | 明らかな向上 | ツール呼び出し精度 |
コーディング領域において、Claude Opus 4.7は間違いなく2026年第2四半期時点で最強の公開モデルです。SWE-bench Proで64.3%というスコアを叩き出し、エージェント型コーディングのランキングで首位を奪還しました。
🚀 クイックスタート: Claude Opus 4.7のコーディング能力をすぐに体験したい場合は、APIYI (apiyi.com) プラットフォームから直接呼び出すことができます。このプラットフォームはClaude公式APIと完全互換性があり、統一されたOpenAI SDK形式をサポートしているため、移行コストを最小限に抑えられます。
ビジュアルおよび長文コンテキストベンチマーク:二極化
| 指標 | Opus 4.6 | Opus 4.7 | 変化 | 評価 |
|---|---|---|---|---|
| ビジュアル認識(汎用) | 54.5% | 98.5% | +44pt | 質的な飛躍 |
| 最大画像解像度 | ~1.15 MP | ~3.75 MP | 3倍 | 4Kスクリーンショット対応 |
| MRCR 長文コンテキスト召回 | 78.3% | 32.2% | -46.1pt | 深刻な後退 |
MRCR(Multi-Round Context Recall)は、長文コンテキストの検索能力を評価する標準的なベンチマークです。Opus 4.7はこの指標において78.3%から32.2%へと急落しました。これは単なる誤差ではなく、構造的な後退と言えます。
この数値は、「800行のワークフロー文書を読み込ませたのに、モデルは読んだと答えるだけで、出力内容が文書と全く無関係」という開発者からの不満の理由を裏付けています。
ベンチマーク vs 実際の体験:なぜ評価が二極化するのか?
ベンチマークのスコアが高いからといって、実際の業務パフォーマンスが優れているとは限りません。Opus 4.7に対してコミュニティから多くの否定的なフィードバックが寄せられている理由は以下の通りです。
- トークナイザーの肥大化:同じタスクでもトークン消費量が増加しており、能力向上がコスト増に見合っていない。
- 指示への字面通りの追従:4.6は「意図を汲み取る」傾向がありましたが、4.7は指示を字面通りに厳格に実行するため、従来のプロンプトが機能しなくなるケースがある。
- MRCRの崩壊:長文検索能力が低下しており、大規模なコードベースや契約書を扱う際に問題が顕著になる。
- Claude Codeの誤検知:一部の開発者から、正常なコードを悪意あるコードと誤判定し、編集を拒否されるという報告がある。
💡 選択のアドバイス: Claude Opus 4.7を採用するか、引き続き4.6を使用するかは、あなたの主要な業務シナリオに依存します。まずはAPIYI (apiyi.com) プラットフォームを通じて両方のバージョンで並行して負荷テストを行い、判断することをお勧めします。同プラットフォームは複数モデルの統一インターフェース呼び出しをサポートしており、迅速な比較と切り替えが可能です。
Claude Opus 4.7 のリアルな使用体験
ベンチマーク数値とは裏腹に、Anthropic と開発者コミュニティからは、実際のワークフローにおける Opus 4.7 のパフォーマンスについて、正反対のフィードバックが寄せられています。
Anthropic の公式見解
Anthropic はリリース発表の中で、Opus 4.7 における 4.6 からの 4 つの主要な改善点を強調しています:
- エンジニアリングパイプラインでの高いパフォーマンス:以前は厳重な監視が必要だった「ハードワーク」を、安心して 4.7 に任せられるようになった
- 曖昧な問題への対応力向上:定義が不明確な要件に対してもより堅牢に対応可能
- より徹底した問題解決:途中で作業を放棄することがない
- 指示に従う精度の向上:細部に対する要求にも厳格に対応
Claude Code の責任者である Boris Cherny 氏はリリース後、「Opus 4.7 は 4.6 よりも『より賢く、エージェントらしく、正確である』」と公言しましたが、その新しい能力を十分に発揮させるには数日の慣れが必要であることも認めました。
開発者コミュニティのリアルな声
GitHub、Hacker News、X などのプラットフォームでは、開発者からのフィードバックは明らかに否定的なものも目立ちます:
不満点 1:トークン消費量の急増
新しいトークナイザーの採用により、同じ入力でも Opus 4.7 ではより多くのトークンに分割されるようになりました。さらに xhigh 設定での出力トークン増加も重なり、一部のユーザーからは請求額が最大 40% 増加したという報告があります。これは「AI シュリンクフレーション」(実質的な価格引き上げ)と揶揄されています。
不満点 2:長文ドキュメント処理の惨状
複数の開発者が次のように報告しています:Opus 4.7 に長いドキュメントを入力すると、モデルは「読んだ」と主張するものの、生成された内容はドキュメントの実質的な内容と無関係であるというものです。これは MRCR(長文読解能力)が 78.3% から 32.2% に急落した事実と合致しています。
不満点 3:Claude Code がコードを悪意あるものと誤認
Issue #47483 において、複数のエンジニアから報告がありました:Claude Opus 4.7 が一般的なファイル読み書きコードをマルウェアとしてマークし、基本的な編集リクエストの実行を拒否するという問題です。
不満点 4:プロンプトの互換性低下
4.6 ではうまく機能していたプロンプトが、4.7 に移行すると出力品質が低下するというケースです。理由は、4.7 が指示を文字通り厳格に実行するためで、4.6 のように「行間を読み取る」ような挙動が減ったためです。
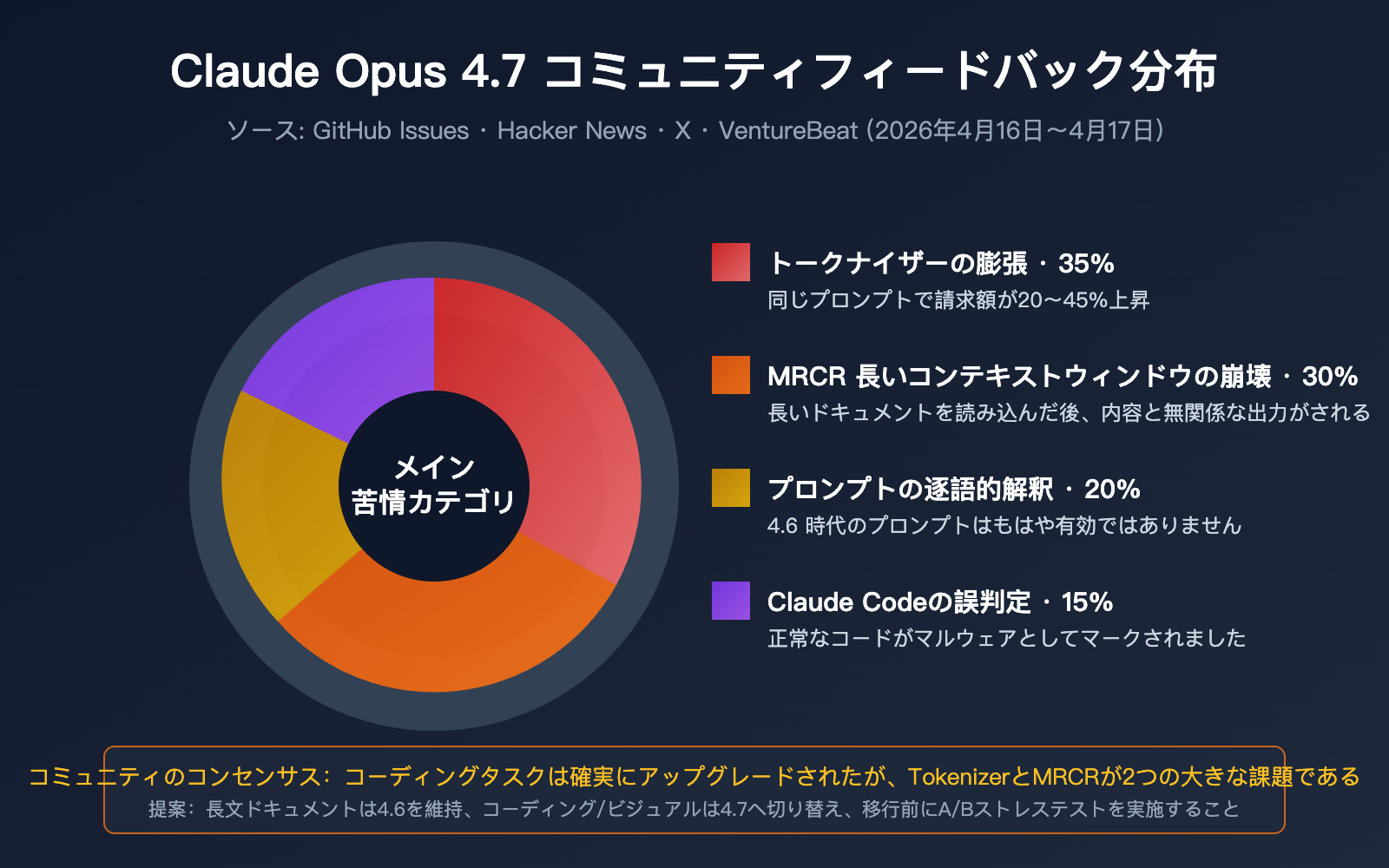
Claude Opus 4.7 リアルなシナリオ別評価
実測データとコミュニティからのフィードバックに基づき、Opus 4.7 の各シナリオにおけるパフォーマンスをスコアリングしました:
| 使用シナリオ | Opus 4.6 評価 | Opus 4.7 評価 | 変化 | 推奨 |
|---|---|---|---|---|
| 中短文コードのリファクタリング | 8/10 | 9/10 | ↑ | 即時移行 |
| 複雑なエージェントワークフロー | 7.5/10 | 9/10 | ↑ | 即時移行 |
| 大規模リポジトリのコードレビュー | 8/10 | 6.5/10 | ↓ | 4.6 を継続使用 |
| 長文ドキュメントの要約とQA | 8.5/10 | 5/10 | ↓↓ | 4.6 を継続使用 |
| 高解像度画像の理解 | 6.5/10 | 9.5/10 | ↑↑ | 即時移行 |
| 一般的な会話と執筆 | 9/10 | 9/10 | → | お好みで |
| コスト重視のプロダクション環境 | 9/10 | 7/10 | ↓ | 4.6 を継続使用 |
| プロトタイプ開発と実験 | 8/10 | 8.5/10 | ↑ | 移行推奨 |
Claude Opus 4.7 の長所と短所の徹底分析
データと体験談の比較を終え、長所と短所をより明確にまとめました。
Claude Opus 4.7 の 4 つの核心的なメリット
メリット 1:実用的なコーディング能力の顕著な向上
SWE-bench Verified で 87.6%、SWE-bench Pro で 64.3% というスコアは、ただのベンチマーク遊びではなく、実際の GitHub Issue 修復タスクにおける成果です。これは、Opus 4.7 が中小規模のコードタスクにおいて、より多くの人的作業を代替できることを意味します。
メリット 2:視覚理解能力の飛躍的進歩
高解像度画像の入力(3.75 メガピクセル)により、Opus 4.7 は 4K スクリーンショット、デザイン図、PDF スキャンデータなどの高密度な視覚コンテンツを直接処理できるようになりました。これは Claude シリーズにおける重大なブレイクスルーです。
メリット 3:Task Budgets によるエージェントのコスト管理
長年、エージェントのループ処理におけるトークン消費の暴走は、企業導入の最大の障壁でした。Task Budgets によって、開発者は初めてきめ細やかなグローバル予算管理を行えるようになりました。
メリット 4:xhigh 設定による推論と遅延の柔軟なバランス
high と max の間に新しい選択肢が加わったことで、開発者は同じシナリオ内でも SLA 要件に応じて柔軟に調整が可能になりました。
Claude Opus 4.7 の 4 つの主要な制限
制限 1:トークナイザーの肥大化による実コストの上昇
単価が変わらなくても、35% のトークン膨張と xhigh 設定での出力増が重なり、実際の請求額は 4.6 よりも 20〜45% 高くなる可能性があります。
対策:移行前にトークンカウント API を使用して、すべてのコードパスを再テストしてください。
制限 2:MRCR(長文コンテキスト)での再現率低下
これが最も致命的な問題です。長いドキュメント、大きなコードベース、長時間の会話を処理する際、Opus 4.7 の再現精度は崖から落ちるように低下します。
対策:長文ドキュメントのシナリオでは引き続き Opus 4.6 を使用するか、RAG + 分割(チャンキング)戦略に変更してください。
制限 3:指示への忠実さが仇となる場合も
プロンプトが文字通りに解釈されるため、意図しない出力の変化が発生する可能性があります。
対策:プロンプトを体系的に書き直し、隠れた意図を排除して、明確な制約(明示的指示)を使用するようにしてください。
制限 4:一部シナリオでの誤判定とハルシネーションの増加
Claude Code の誤判定や、長文ドキュメントでのハルシネーションなどがコミュニティで広く報告されています。
対策:コアタスクでは人のレビューを併用し、重要なロジックについては複数のモデルでクロスチェックを行ってください。
🎯 移行のヒント: もし業務で短文のコーディングと長文ドキュメントの処理を併用している場合は、APIYI(apiyi.com)プラットフォーム経由で、シナリオごとに Claude のバージョンをルーティングすることをお勧めします。このプラットフォームは多モデルの統合呼び出しをサポートしており、同じプロジェクト内で Opus 4.6(長文用)と 4.7(コーディング/視覚用)を柔軟に組み合わせることで、「一律の移行」によるパフォーマンス低下を防ぐことができます。
Claude Opus 4.7 API 呼び出し実践
理論的な分析に加え、Claude Opus 4.7 をすぐに使い始められるよう、実際に動作するコード例を紹介します。
極めてシンプルな例(OpenAI SDK 互換)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Pythonで並行処理を行うクローラーのサンプルを書いてください"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
完全なコードを表示(xhigh推論レベル、Task Budgets、エラーハンドリングを含む)
import openai
import time
from typing import Optional
class ClaudeOpusClient:
"""Claude Opus 4.7 呼び出しの完全実装"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate(
self,
prompt: str,
model: str = "claude-opus-4-7",
effort: str = "xhigh",
task_budget: Optional[int] = None,
max_retries: int = 3
) -> str:
"""Claude Opus 4.7 の新機能をサポートした呼び出し"""
extra_headers = {}
if task_budget:
extra_headers["task-budget-tokens"] = str(task_budget)
if effort:
extra_headers["reasoning-effort"] = effort
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
extra_headers=extra_headers,
timeout=120
)
return response.choices[0].message.content
except openai.RateLimitError:
wait = 2 ** attempt
print(f"レート制限のため、{wait}秒待機します...")
time.sleep(wait)
except openai.APIError as e:
print(f"APIエラー: {e}")
if attempt == max_retries - 1:
raise
time.sleep(1)
raise RuntimeError("最大再試行回数を超過しました")
def compare_versions(self, prompt: str) -> dict:
"""4.6と4.7を同時に呼び出して比較する"""
results = {}
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
start = time.time()
results[model] = {
"output": self.generate(prompt, model=model),
"latency": time.time() - start
}
return results
if __name__ == "__main__":
client = ClaudeOpusClient(api_key="YOUR_API_KEY")
result = client.generate(
prompt="このPythonコードをリファクタリングして、非同期並行処理に対応させてください",
effort="xhigh",
task_budget=50000
)
print(result)
🚀 クイックスタート: 上記コードの
base_urlは APIYI (apiyi.com) プラットフォームを指定しています。このプラットフォームは Claude 公式と完全互換のインターフェースを提供しており、Claude Opus 4.7 と 4.6 の並行呼び出しが可能なため、移行期間中の A/B テストに最適です。
移行時の重要チェックリスト
Opus 4.6 から 4.7 へ移行する際に行うべき必須ステップ:
# 1. max_tokens 上限の再測定(トークナイザーの変更に伴うもの)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 主要なプロンプトを両モデルで実行し、実際のトークン消費量を記録
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": YOUR_PROMPT}],
max_tokens=4096
)
print(f"{model}: input={resp.usage.prompt_tokens}, output={resp.usage.completion_tokens}")
# 2. 長文ドキュメント処理の再テスト(MRCR の低下)
# 長文ドキュメントのタスクは 4.6 に残すか、RAG によるチャンク分割を推奨
# 3. プロンプトの意図の監査
# 4.7 はより厳密に文字通り実行するため、"意図を読み取る"ような指示は、明示的な制約に書き換える必要があります
Claude Opus 4.7 に関するよくある質問(FAQ)
Q1: Claude Opus 4.7 は本当に 4.6 より優れていますか?
ユースケースによります。
- 中〜短編のコーディング:4.7 が明らかに優れています(SWE-bench Verified +6.8pt、CursorBench +12pt)
- 高解像度画像タスク:4.7 が 4.6 を圧倒しています(画像ベンチマークで 54.5% から 98.5% へ向上)
- Agentic ツールチェーン:4.7 の方が強力です(MCP-Atlas で 13pt 向上)
- 長いコンテキストウィンドウの検索:4.6 の方が明らかに優れています(MRCR で 78.3% 対 32.2%)
- コスト重視:4.6 の方が経済的です(4.7 ではトークン消費量が最大 35% 増加する場合があります)
複数のバージョンを使い分けたい場合は、APIYI (apiyi.com) プラットフォームの利用を推奨します。ビジネス要件に応じて適切なモデルにルーティングでき、一つの API キーで Claude シリーズ全モデルを呼び出せます。
Q2: なぜ一部で「Claude Opus 4.7 は 4.6 より劣る」と言われているのですか?
主な理由は 4 つあります:
- トークナイザーの再構築:同じタスクでもトークン消費量が最大 35% 増加しますが、コストに見合う能力向上が得られない場合があります。
- MRCR 長コンテキストでの性能低下:78.3% から 32.2% へ急落しており、長文ドキュメント処理が大幅に退行しています。
- 指示遵守が字義通りすぎる:4.6 時代の「意図を察する」プロンプトが 4.7 では機能しにくい場合があります。
- Claude Code の誤判定:正常なコードが誤って悪意あるコードとしてフラグ立てされるケースが一部で報告されています。
これらは誤解ではなく、構造的な変化が引き起こす実体験の差異です。
Q3: どうすれば Opus 4.6 から 4.7 へ安全に移行できますか?
3 ステップの移行法を提案します:
- 並行負荷テスト:本番トラフィックの 5〜10% で 4.6 と 4.7 を同時に呼び出し、出力品質、レイテンシ、コストを比較します。
- シーン別のルーティング:長文ドキュメントや大規模なコードベースは引き続き 4.6 を使用し、中短編のコーディングや画像タスクを 4.7 に切り替えます。
- 段階的な移行:10% → 30% → 50% → 100% と順次拡大し、各段階で 3〜7 日間様子を見ます。
このような移行テストには、柔軟なモデルルーティングとトラフィック分配をサポートする APIYI (apiyi.com) プラットフォームの利用をお勧めします。
Q4: Claude Opus 4.7 の xhigh レベルはいつ使うべきですか?
Anthropic は、コーディングおよび Agentic なタスクにおいてデフォルトで xhigh を使用することを推奨しています。適したシーン:
- 複雑なコードのリファクタリング
- 複数ファイルにまたがるバグ修正
- 大規模な単体テストの生成
- Agentic によるマルチステップツールチェーンタスク
適さないシーン:
- 単純な質問応答(medium で十分です)
- 高並行のリクエスト(xhigh はレイテンシが高めです)
- コストを抑えたいタスク(xhigh は出力トークン数が顕著に増加します)
Q5: Task Budgets とは何ですか?どのようなシーンに適していますか?
Task Budgets は現在パブリックベータ中の機能で、HTTP ヘッダーを介して指定します:
task-budget-tokens: 50000
適したシーン:
- 長期間動作するエージェントループ(総コストの抑制)
- マルチテナント型 SaaS(ユーザーごとにトークン予算を制限)
- CI/CD 自動化タスク(ジョブごとの上限設定)
モデルは残りの予算に応じて思考の深さを自動的に調整し、予算を使い切る前に適切に処理を終了させるため、途中で失敗するリスクを防げます。
Q6: Claude Opus 4.7 の画像認識能力は本当にそれほど強力ですか?
はい、これは 4.7 の最も顕著なアップグレードの一つです。
- 最大解像度:115 万画素から 375 万画素へ(約 3 倍)向上
- 画像ベンチマーク:54.5% から 98.5% へ飛躍的に向上
- 実用性:4K のスクリーンショット、アーキテクチャ図、UI 設計図、PDF スキャン文書を直接読み取ることが可能です。
フロントエンド開発、デザインの復元、文書のデジタル化に携わるチームにとって、ワークフローを劇的に変えるアップグレードとなるでしょう。
Claude Opus 4.7 は誰に適しているか?意思決定のためのアドバイス
全文分析に基づき、明確な利用推奨事項をまとめました。
今すぐ Claude Opus 4.7 に移行すべきケース
- ✅ 中短編コードのコーディングとリファクタリング:SWE-bench と CursorBench のデータがすべてを物語っています
- ✅ 複雑なエージェントワークフロー:MCP-Atlas と Task Budgets のダブルサポートによる強化
- ✅ 高精細な画像処理:3.75 MP の視覚能力は質的な進化を遂げています
- ✅ プロトタイプの迅速な開発:xhigh 設定は中程度の複雑さのタスクにおいて卓越したパフォーマンスを発揮します
Claude Opus 4.6 を使い続けるべきケース
- 🔒 長文ドキュメントの要約とQA:MRCR(長文コンテキストの想起)の低下は避けられません
- 🔒 大規模リポジトリレベルのコードレビュー:長文コンテキストの想起能力は 4.6 の方がより安定しています
- 🔒 トークンコストに極めて敏感:4.6 のトークナイザーの方が経済的です
- 🔒 すでに安定稼働している本番環境:新機能のために回帰リスクを導入することは推奨されません
併用を推奨する戦略
多くのチームにとって、「すべてを移行する」よりもシナリオに応じたルーティングの方が実用的です:
- 長文ドキュメント関連 → Opus 4.6
- コーディング/視覚/エージェント → Opus 4.7
- 統一ゲートウェイを通じて両方のバージョンを管理することで、移行リスクを低減できます
💡 最終的なアドバイス: Claude Opus 4.7 を選択するか、4.6 を使い続けるかは、具体的なユースケースに大きく依存します。APIYI (apiyi.com) プラットフォームを活用して、実際の比較テストを行うことをお勧めします。このプラットフォームは、複数の主要モデルの統一インターフェース呼び出しをサポートしており、迅速な比較や切り替えが可能なため、移行プロセスにおいてもビジネスの柔軟性を維持できます。
まとめ
Claude Opus 4.7 は、「トレードオフを伴うアップグレード」の典型です。コーディング、視覚、エージェント能力において真の飛躍を遂げた一方で、長文コンテキストの想起、トークン効率、プロンプトの互換性において明確な代償を払っています。
リリース初日のコミュニティでの議論は決して根拠のないものではありません。Opus 4.7 は強力な新モデルであると同時に、代償を伴うアーキテクチャの調整でもあります。開発者にとって重要なのは「移行するかどうか」ではなく、「どのシナリオで移行するか」です。
- 複雑なコードタスクや高精細な視覚分析を行っている場合、4.7 は 2026 年第 2 四半期のベストな選択肢です
- コアビジネスが長文ドキュメント処理やコスト重視の推論である場合は、当面 4.6 を維持してください
- 移行プロセスにおいては、並行して負荷テストを行い、「一律移行」による潜在的なパフォーマンス低下を避けることを強く推奨します
APIYI (apiyi.com) プラットフォームを通じて、Claude Opus 4.7 と 4.6 を素早く体験してみてください。同プラットフォームは統一インターフェース、リアルタイムの請求監視、マルチモデルルーティング機能を提供しており、移行テストや本番環境への導入に最適な選択肢です。
参考資料
-
Anthropic 公式発表: Claude Opus 4.7 正式紹介
- リンク:
anthropic.com/news/claude-opus-4-7 - 説明: 公式の主要機能と料金体系に関する説明
- リンク:
-
Claude API 公式ドキュメント: Claude Opus 4.7 移行ガイド
- リンク:
platform.claude.com/docs/en/about-claude/models/migration-guide - 説明: 公式の移行アドバイスとトークナイザーの変更点について
- リンク:
-
AWS Bedrock 公式ブログ: Amazon Bedrock での Claude Opus 4.7 リリース
- リンク:
aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock - 説明: サードパーティクラウドプラットフォームでのデプロイに関する説明
- リンク:
-
Vellum AI ベンチマーク分析: Claude Opus 4.7 ベンチマークの徹底解説
- リンク:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - 説明: 第三者機関による独立したベンチマーク評価
- リンク:
-
GitHub Issue #47483: Claude Opus コミュニティからのフィードバック
- リンク:
github.com/anthropics/claude-code/issues/47483 - 説明: 開発者による実際の体験談とフィードバック
- リンク:
著者: APIYI 技術チーム
公開日: 2026-04-17
対象モデル: Claude Opus 4.7 / Claude Opus 4.6
技術交流: APIYI (apiyi.com) にてテスト用クレジットを提供しています。ぜひ Claude の各バージョンによる違いを実際に体験・比較してみてください。