デザイナーが初めて GPT-Image-2 に触れる際、多くの人が抱く疑問があります。「写真をアップロードして『服を青くして』と指示したとき、AI は Photoshop のようにピクセルを正確に塗り替えているのか、それとも裏で画像を再描画しているのか?」この疑問への答えは、AI 画像編集ツールをどのように使いこなし、出力結果の予測可能性をどう理解するかという点に直結します。
実は、これは非常に誤解されやすい技術的な詳細です。本記事では、AI 画像編集の原理から出発し、GPT-Image-2 や Nano Banana といった次世代の自己回帰画像モデルの動作メカニズムを深く掘り下げます。「部分的な修正なのか、それとも再描画なのか」という核心的な問いに答え、画像全体を再描画する前提で、いかにして驚異的な視覚的一貫性を維持しているのかを明らかにします。
| 核心問題 | 直感的な答え | 実際の答え |
|---|---|---|
| 編集方法 | PSのような部分的な上書き | 画像全体のトークン再描画 |
| 一貫性の源泉 | 未編集ピクセルの保持 | 自己注意機構による原画特徴の固定 |
| 主流アーキテクチャ | 拡散モデル(デノイズ) | 自己回帰Transformer |
| 多段階編集 | 偽影(アーティファクト)が蓄積しやすい | GPT-Image-2はドリフトが少ない |
この原理を理解すれば、プロンプトの書き方、マスクの使用方法、参照画像の入力戦略などに新たな理論的根拠が生まれます。読者の皆様には、APIYI (apiyi.com) プラットフォーム上の GPT-Image-2 インターフェースを使い、実際に試しながら原理を体感することをお勧めします。
AI 画像編集の原理:PSのような部分修正ではなく、インテリジェントな再描画
多くのユーザーは、ChatGPT のウェブ版での対話体験から、AI による画像編集は Photoshop の「部分修正」のようなものだと直感的に考えがちです。つまり、システムが修正したい領域を認識し、元の画像の上に数ピクセルを上書きし、残りの部分はそのまま残しているというイメージです。このメンタルモデルは直感的ですが、完全に誤っています。
主流の AI 画像編集モデルは、すべて本質的に「再描画」のロジックで動いています。 GPT-Image-2、Nano Banana、あるいは Stable Diffusion シリーズのいずれであっても、まず元の画像を何らかの内部表現(トークンや潜在変数)にエンコードし、モデルが新しい画像の完全な内部表現を「想像」し、最後にピクセルへとデコードする必要があります。このプロセスにおいて、「元画像に直接筆を入れる」というステップは存在しません。
これが、AI に目の色だけを変えるよう指示したのに、髪の毛の質感や背景のテクスチャまで微妙に変化してしまう理由です。モデルが手抜きをしているわけではなく、実際に画像全体を「再描画」しており、ほとんどの領域で元の画像に非常に近い結果を出力しているに過ぎません。
では、再描画であるにもかかわらず、なぜ GPT-Image-2 で編集した画像は元画像と高度な一貫性を保ち、複数回の編集を繰り返しても「崩れない」のでしょうか?その答えはアーキテクチャに隠されています。この挙動を直接検証したい場合は、APIYI (apiyi.com) で gpt-image-2 の /v1/images/edits エンドポイントを呼び出し、同じプロンプトで繰り返し同じ画像を編集して、細部の変化を観察してみてください。
Photoshopの部分修正とAI再描画の本質的な違い
| 比較項目 | Photoshopの部分修正 | GPT-Image-2のインテリジェント再描画 |
|---|---|---|
| 操作単位 | ピクセル | ビジュアルトークン(8×8または16×16ピクセルブロック) |
| 未編集領域 | 物理的に変化なし | エンコード・デコードを経るため、理論上は微小な再構成が発生 |
| 一貫性の保証 | 100%(元のピクセルを直接コピー) | モデルの注意(アテンション)機構により保証 |
| 意味の理解 | なし、ピクセル値のみを参照 | 「服」「背景」「光」などの意味を理解 |
| 境界の馴染み | 手動でのぼかし処理が必要 | 意味に基づいて自動的に自然な境界を生成 |
Photoshop はピクセルベースの「機械的な修正」であり、AI は意味を「理解した上で再描画する」ものです。これが、AI が「昼間を夕方に変える」といった、Photoshop では不可能な全体的な編集をこなせる理由です。AI は画像の RGB 値ではなく、画像の意味的な表現を修正しているのです。
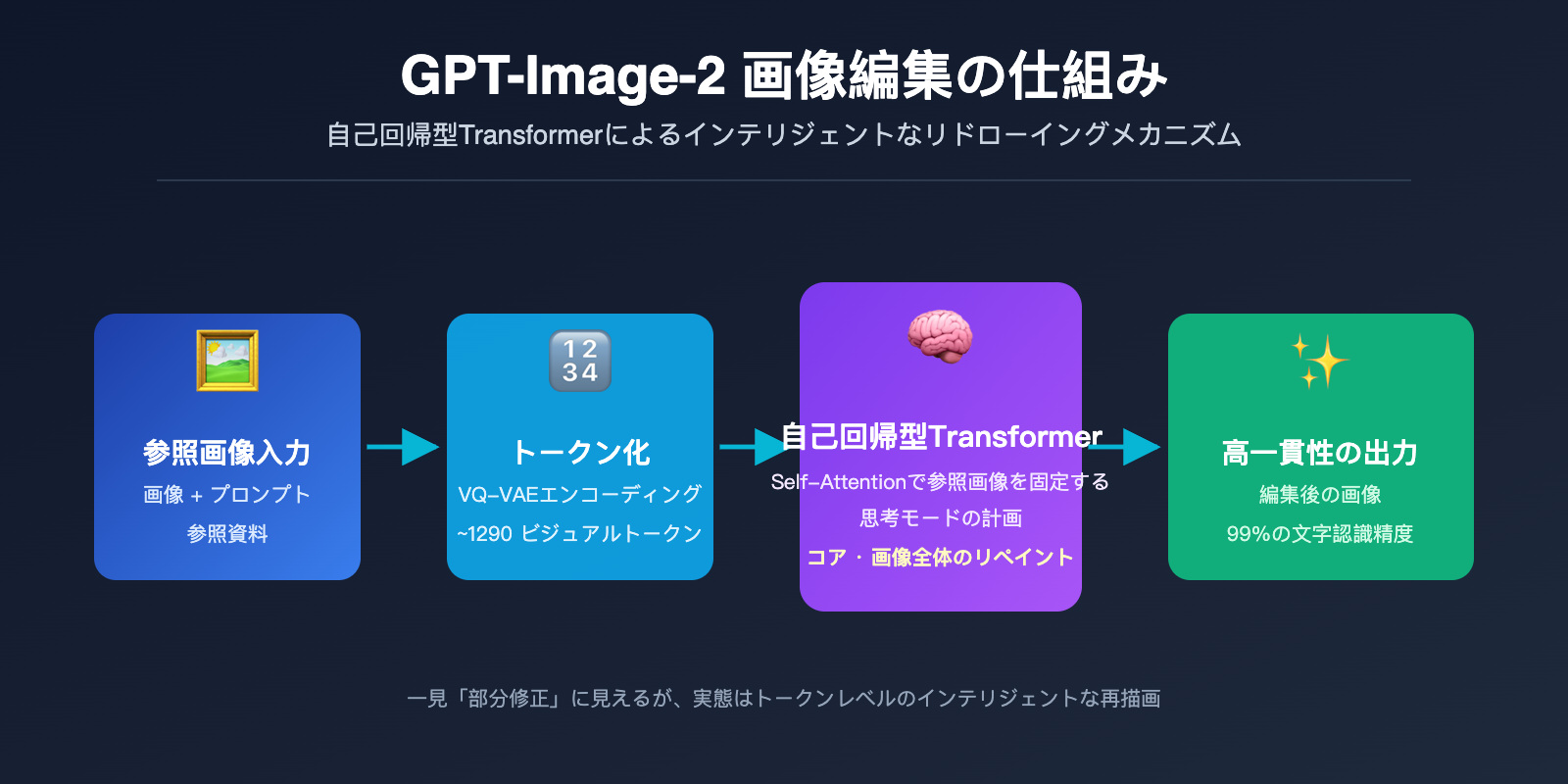
gpt-image-2 の編集原理:自己回帰型 Transformer はどのように原画像を「理解」するのか
gpt-image-2 の編集原理を真に理解するには、OpenAI が 2026 年 4 月 21 日にこのモデルを公開した際に行った重要なアーキテクチャの選択を避けて通れません。それは、DALL-E シリーズで使用されていた拡散モデルを捨て、自己回帰型 Transformer を採用したことです。この決定は、GPT-4o のマルチモーダルアーキテクチャから直接着想を得ています。
自己回帰生成は、本質的に ChatGPT が文章を書くのと同じメカニズム、つまり「次のトークンを予測する」という仕組みです。違いは、ここでの「トークン」が文字ではなく視覚トークンである点です。モデルは以下のプロセスを実行します。
- 画像のトークン化: VQ-VAE に似た離散化メカニズムを通じて、画像を約 1024〜1290 個の視覚トークンに分割します。各トークンは、原画像の約 8×8 または 16×16 ピクセルブロックに対応します。
- シーケンスの結合: ユーザーのテキストプロンプトのトークンと、原画像の視覚トークンを一つの長いシーケンスに連結し、統合された Transformer に入力します。
- トークンごとの逐次生成: モデルは左から右へ(あるいはラスタースキャン順に)、出力画像の各視覚トークンを一つずつ予測します。新しいトークンを生成するたびに、それまでのすべての入力と生成済みの内容を「参照」できます。
- ピクセルへのデコード: すべての視覚トークンが生成された後、デコーダーを通じて最終的なピクセル画像に復元されます。
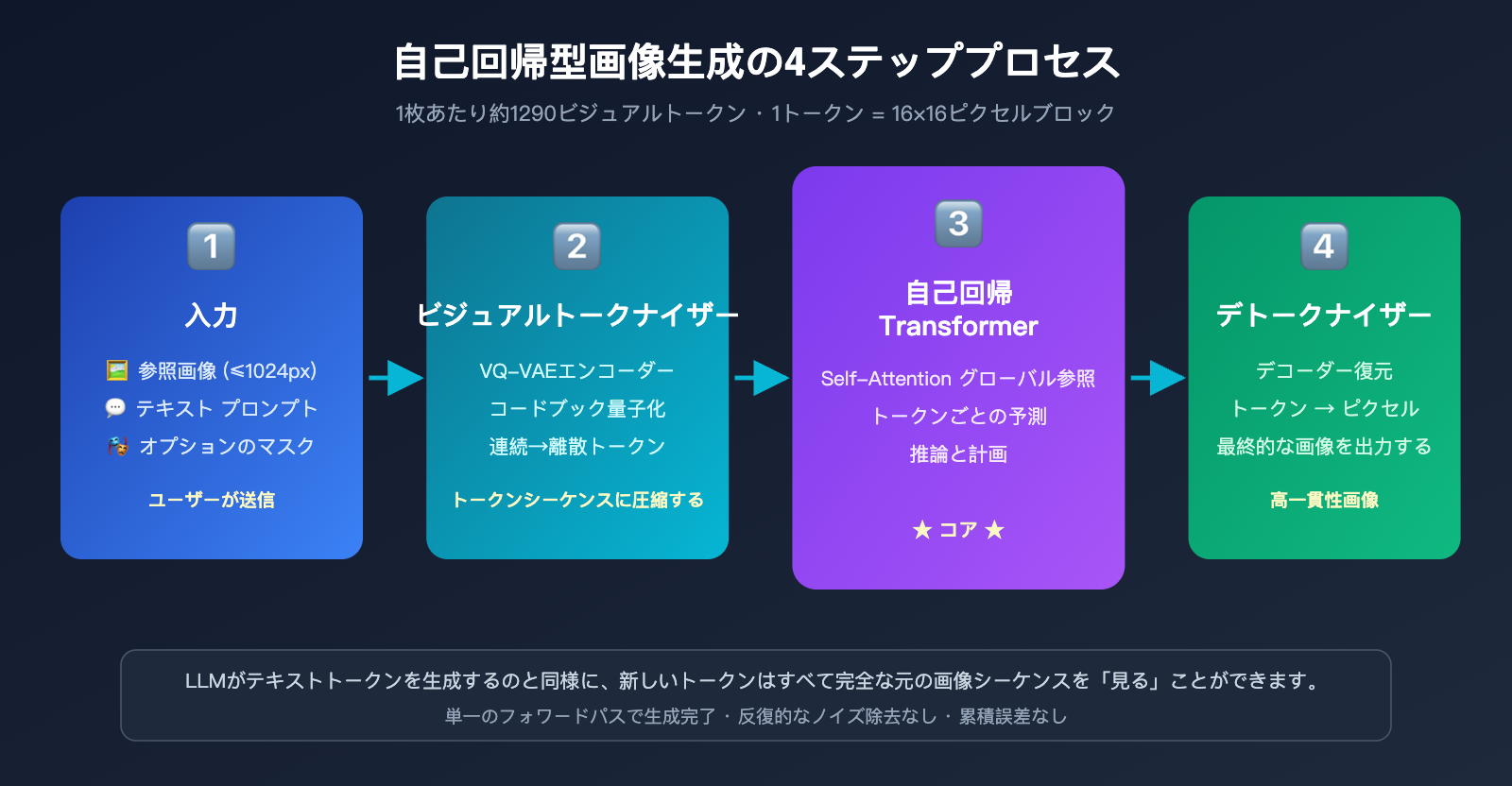
ここでの重要な洞察は、GPT-Image-2 が新しい画像を生成する際、原画像のすべてのトークンがその「視野」内にあるということです。これは、ChatGPT と対話する際に、モデルがそれまでのすべてのメッセージを見ることができるのと同じ原理です。Self-Attention 機構により、新しく生成される各トークンは、原画像の任意の場所にある特徴を「参照」できます。
OpenAI は GPT-Image-2 に「Thinking モード」を導入しました。これにより、モデルは視覚トークンの生成を開始する前に、内部的な推論を通じて「ユーザーは何を変更したいのか」「どの部分を保持すべきか」「空間レイアウトをどう配置するか」を整理します。これにより、複雑な編集指示の実行精度がさらに向上し、99% のテキスト正確性と正確なマルチオブジェクト配置を実現しています。これらの機能を本番環境でテストしたい場合は、APIYI (apiyi.com) を通じて gpt-image-2 に接続できます。このプラットフォームは、公式と一致するインターフェース仕様と、便利なマルチモデル切り替え機能を提供しています。
視覚 Tokenizer:圧縮と情報保持のバランス
視覚 Tokenizer は、自己回帰型画像生成システム全体の重要なボトルネックです。以下の二つの目標の間でトレードオフを調整する必要があります。
- 高い圧縮率: トークン数が少ないほど、Transformer の処理が速くなり、コストも抑えられます。
- 高い再構築品質: デコードされたピクセルが可能な限り原画像を再現し、詳細を損なわないようにする必要があります。
主流の手法は VQ-VAE (Vector Quantized Variational Autoencoder) です。エンコーダーを使用して画像領域を連続ベクトルに圧縮し、それを有限の「コードブック」にマッピングして最も近いコードワードインデックスを探します。このインデックスがトークンとなります。1024×1024 の画像は通常約 1024 個のトークンに圧縮され、情報密度が非常に高くなります。
この圧縮自体が不可逆であるため、どのような AI 編集ツールも「未編集領域のピクセル値を 100% 保持する」ことはできません。これが、次の重要な問題である「一貫性」につながります。
AI 画像の一貫性を保つ核心メカニズム:視覚トークン化とアテンションの固定
GPT-Image-2 は画像全体を再描画するのに、なぜAI 画像の一貫性が実現できるのでしょうか?なぜ人物写真を修正しても、顔立ち、肌の色、髪型が別人のようにならないのでしょうか?答えは 4 つの層にあります。
第 1 層:視覚トークン自体の高度な抽象化。 人の顔が Tokenizer を通過すると、生成されたトークンシーケンスには、その人の核心的な特徴(顔の形、顔立ちの比率、肌の色調など)がすでに符号化されています。これらの「アイデンティティトークン」が新しい画像の生成時に基本的に保持される限り、人物が変わることはありません。
第 2 層:Self-Attention によるグローバルな参照。 自己回帰型 Transformer は、新しいトークンを生成するたびに、すべての入力トークン(原画像のトークンを含む)とのアテンションウェイトを計算します。ユーザーが変更を指定していない領域に対応する新しいトークンの場合、モデルは原画像の対応する位置のトークンに高いウェイトを与え、実質的に原画像を「コピー」します。
第 3 層:学習データの帰納的バイアス。 OpenAI は膨大な「原画像と編集画像」のペアデータを使用して GPT-Image-2 を学習させました。モデルは学習を通じて、「プロンプトで明示的に要求されない限り、他の領域は可能な限り変更しない」という暗黙のルールを学びました。このバイアスは重みの中に固定されており、推論時に自然に適用されます。
第 4 層:Thinking モードによる明示的な計画。 GPT-Image-2 は、まず内部的な思考プロセスを通じて「どの領域を変更し、どの領域を保持するか」を整理してから生成を行います。これは、生成前に自分自身のために保持リストを作成するようなものです。
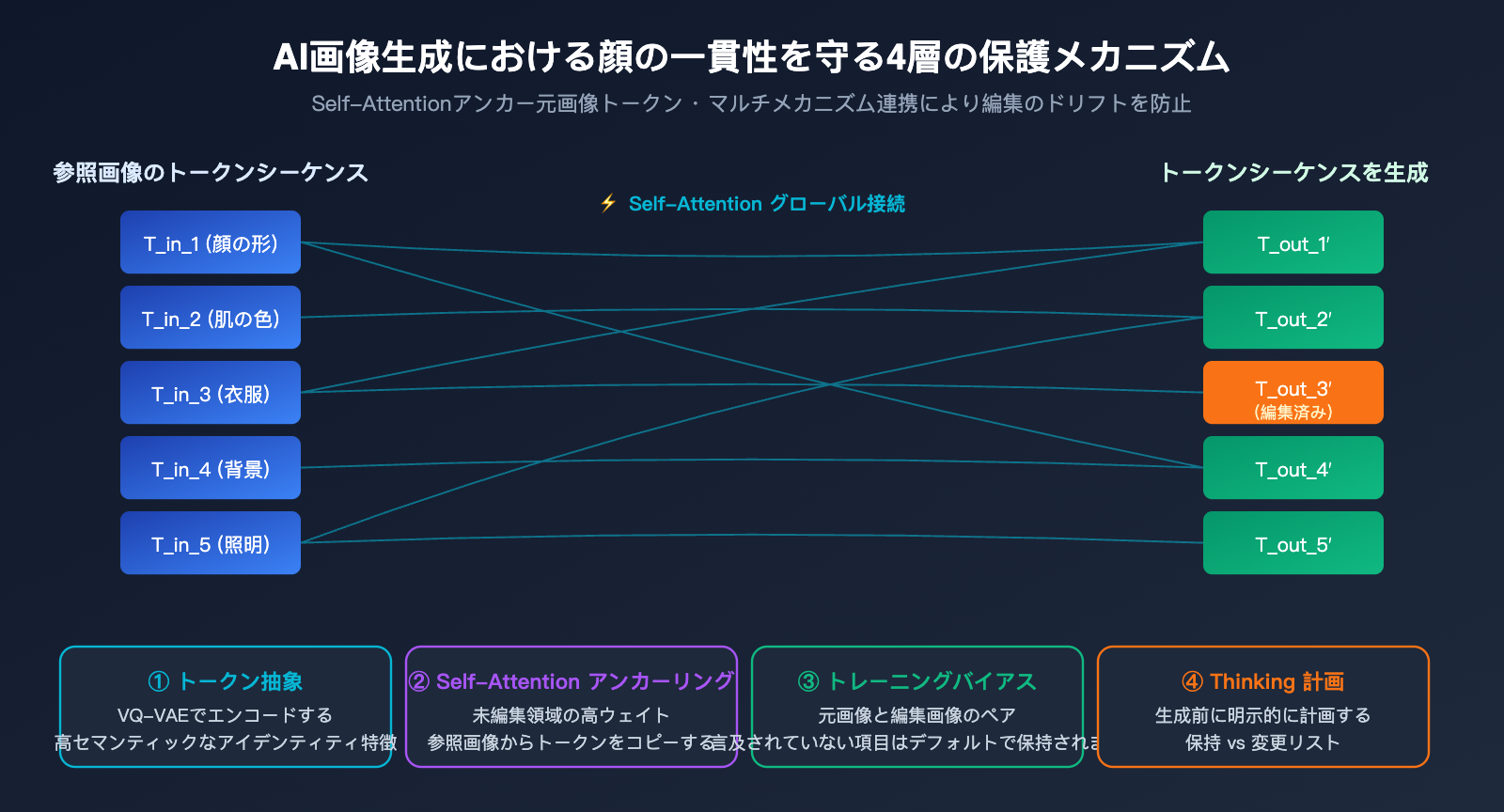
一貫性メカニズムの 4 層防御の比較
| メカニズム層 | 作用範囲 | 失効シナリオ |
|---|---|---|
| トークン抽象化 | グローバルなアイデンティティ | 顔が遠すぎてトークンが不足する場合 |
| Self-Attention | 局所的な詳細の固定 | プロンプトと原画像の意味が衝突する場合 |
| 学習バイアス | 未言及領域のデフォルト保持 | プロンプトが過度に攻撃的な場合 |
| Thinking 計画 | 複雑な編集指示 | 複数回の試行錯誤が必要な場合 |
これら 4 層の防御を理解すれば、画像の「漂流」を防ぐプロンプトをより正確に記述できるようになります。例えば、「この人の服を描き直して」と言うよりも、「人物のアイデンティティを保持したまま、服の色だけを白から青に変更して」と指示する方が効果的です。APIYI (apiyi.com) で GPT-Image-2 をテストしたところ、「他の要素は変更しない」といった明示的な制約を加えることで、Thinking モードがより徹底的に機能することが分かりました。
mask モード:再描画を「部分的な修正」に見せる
ユーザーがより確実な「部分的な修正」を体験したい場合、GPT-Image-2 は /v1/images/edits エンドポイントの mask パラメータを提供しています。ユーザーは二値化されたマスク画像を渡すことができます。白い領域は AI による生成を許可し、黒い領域は原画像を保持する必要があります。
ただし、mask モードは再描画の本質を変えるものではないことに注意が必要です。その役割は、トークン生成時に「黒い領域に対応するトークンは、原画像のトークンと完全に一致しなければならない」というハード制約を加えることです。これは自己回帰生成フレームワーク内で行われる「制約付き生成」であり、Photoshop のようなピクセル単位の塗りつぶしではありません。
拡散モデル vs 自回帰画像生成:2つの実装原理の比較
GPT-Image-2 の強みを十分に理解するためには、前世代の拡散モデル(Stable Diffusion、DALL-E 3、Midjourney)とシステム的に比較する必要があります。これら2つの体系は、AI画像編集の原理において本質的な違いがあります。
拡散モデルのワークフローは、純粋なノイズ画像から始まり、数十ステップの反復的なノイズ除去を経て、徐々に最終的な画像が浮かび上がるというものです。編集を行う際、まずは元画像を潜在(latent)空間に圧縮し、その潜在空間に部分的なノイズを加えてから、プロンプトでノイズ除去プロセスを誘導し、最終的にピクセルへとデコードします。インペインティング(inpainting)モードでは、ノイズ除去の各ステップにおいて、マスク外の潜在変数を元の潜在変数にリセットすることで、編集されていない領域を「固定」します。
自回帰モデルのワークフローは全く異なります。画像をトークンにエンコードし、まるで文章を書くようにトークンを一つずつ予測して出力します。反復的なノイズ除去も、潜在空間のノイズも存在せず、一度の生成で完了します。
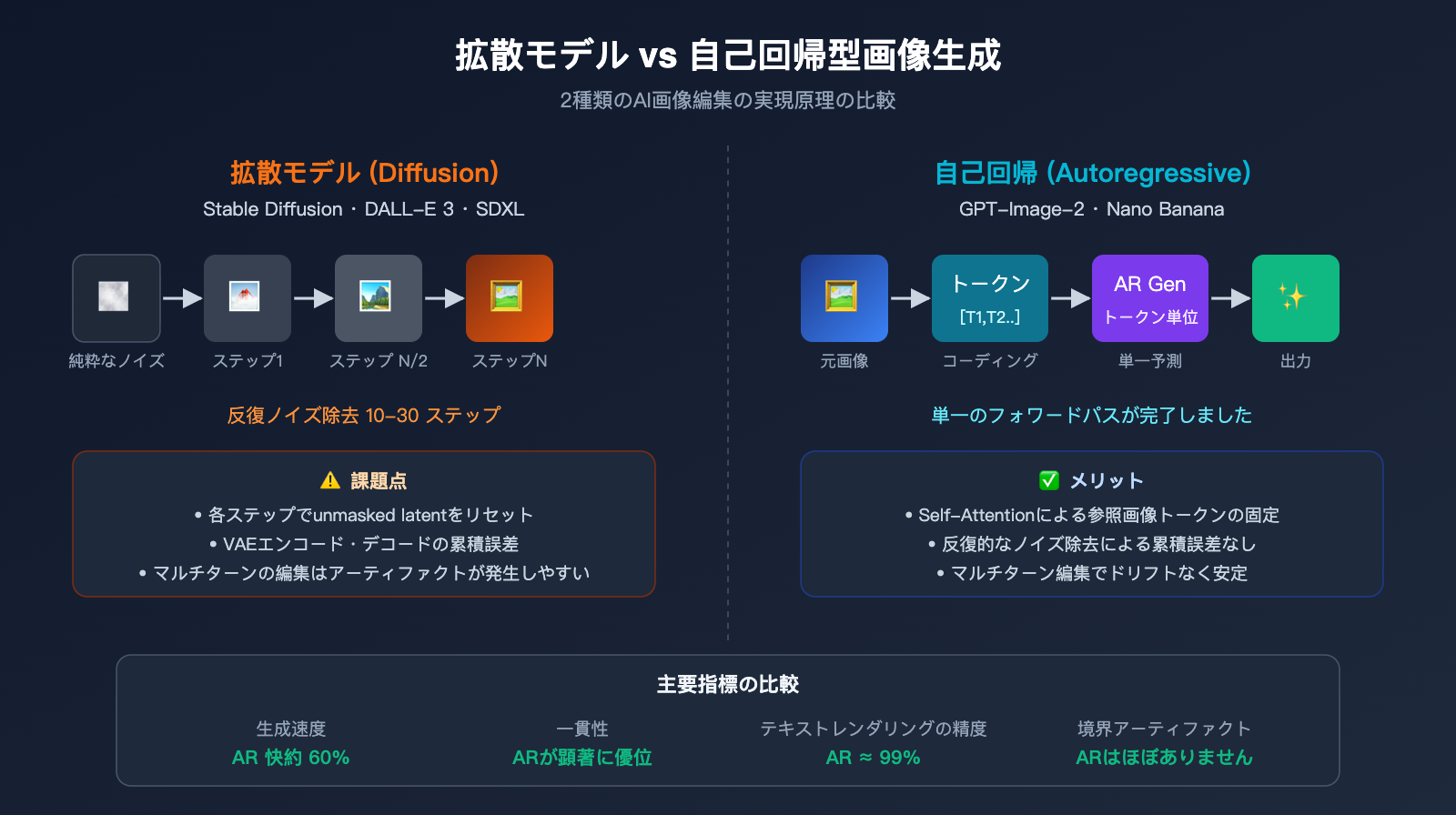
これら2つのパラダイムにおける画像編集シーンでのパフォーマンス差は非常に大きく、具体的な比較は以下の表の通りです。
| 比較項目 | 拡散モデル (SD/DALL-E 3) | 自回帰モデル (GPT-Image-2/Nano Banana) |
|---|---|---|
| 生成方式 | 多段階ノイズ除去反復 | 単一トークンシーケンス予測 |
| マスク実装 | 各ステップで未マスク領域の潜在変数をリセット | トークン単位のハード制約 |
| 境界処理 | 潜在変数の継ぎ目にアーティファクトが発生しやすい | 自然な移行(セマンティックレベル) |
| 文字レンダリング | 失敗が多い | 精度約 99% |
| 多段階編集 | 再エンコードによる損失が蓄積 | ドリフトがほぼ皆無 |
| 複雑な指示 | 精密なレイアウトが困難 | 100以上のオブジェクト配置をサポート |
| 速度 | 通常 10〜30 秒 | 拡散モデルより約 60% 高速 |
| 長文レンダリング | 困難 | あらゆる言語/スクリプトに対応 |
拡散モデルの核心的な課題は、VAEエンコード/デコードによる再エンコード損失です。理論上はマスクされていない領域が固定されていても、潜在変数とピクセル間の変換を繰り返すことで微小な色差が生じます。編集を繰り返すと、この損失が蓄積され、肉眼でも確認できる偽像(アーティファクト)となります。GPT-Image-2 は自回帰アーキテクチャを採用することでこの問題を回避しており、トークンのデコードは一度しか行われません。
しかし、自回帰モデルにも代償はあります。トークン数が多く、各トークンに対して完全なTransformerのフォワードパスが必要となるため、生成コストが高くなります。究極の一貫性と文字レンダリングを求めるシーンには GPT-Image-2(APIYI apiyi.com を通じて利用可能)を推奨し、コスト重視の高並行処理が必要なシーンでは、引き続き Stable Diffusion シリーズを補完として活用することをお勧めします。
GPT-Image-2 編集原理の実践:API 呼び出しと一貫性の最適化
GPT-Image-2 の編集原理を理解したところで、この仕組みを最大限に活用する方法を見ていきましょう。以下は、APIYI 互換エンドポイントを通じて GPT-Image-2 の編集インターフェースを呼び出すための最小構成のサンプルコードです。
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="人物のアイデンティティと背景を維持し、上着の色のみを白から濃紺に変更してください",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
プロンプトの書き方に注意してください。「何を維持し、何を修正するか」を明示することが重要です。これにより、GPT-Image-2 の Thinking モードがトリガーされ、意図した通りの生成計画が立てられます。精密な領域編集を行いたい場合は、mask パラメータを追加します。
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="白い服を濃紺のスーツに変更してください",
size="1024x1024"
)
mask は元画像と同じサイズの PNG ファイルです。白い領域は修正が許可される範囲、黒い領域は元の画像のトークンを強制的に維持する範囲となります。
一貫性最適化のための 5 つの実践的なヒント
AI 画像の一貫性を調整する際、実際のテストから得られた 5 つの経験則をまとめました。
- プロンプトで「何を維持するか」を明確にする: 単に「X を変えて」と言うのではなく、「Y を変えずに維持し、X を変更して」と指示します。
- 参照画像の解像度は適度にする: OpenAI は参照画像の長辺を 1024px 以内にすることを推奨しています。大きすぎるとかえってトークンの注意力が分散してしまいます。
- 複数回の編集には同一の基準画像を使用する: 前回の編集結果を次の入力にするのではなく、常に元の画像に基づいて異なる次元の編集を行い、最後にプロンプトを統合します。
- 複雑なシーンは指示を分割する: 「人物を夕暮れの背景の日本風スタイルに変えて」という指示を、「背景を夕暮れに変える」「スタイルを日本風に変える」という2ステップに分け、1ステップにつき1つの変数のみを操作します。
- 品質パラメータは high を選択する: 低品質設定はトークン数を減らし、結果として一貫性を低下させます。
GPT-Image-2 の価格と一貫性のトレードオフ
| パラメータの組み合わせ | 1枚あたりのコスト | 推奨シーン |
|---|---|---|
| 1024×1024 low | $0.006 | クリエイティブなラフ案/クイックプレビュー |
| 1024×1024 medium | $0.053 | ソーシャルメディア用画像 |
| 1024×1024 high | $0.211 | 商用レベルの編集/反復的なイテレーション |
| 4K high | $0.50+ | 印刷/高解像度展示 |
コストと一貫性は正の相関関係にあります。高品質モードはモデルにより多くのトークンを割り当てるため、自然と元の画像の特徴をより多く保持できます。本番環境では high モードを優先的に使用し、APIYI (apiyi.com) の Batch API を活用することで、コストをさらに 50% 削減することが可能です。
AI 画像編集原理に関する FAQ と今後の展望
Q1: GPT-Image-2 は Photoshop のような部分修正ですか、それとも再描画ですか?
A: 再描画です。すべての自己回帰型画像モデルは、元の画像をトークンにエンコードし、完全な出力トークンシーケンスを生成してから、新しい画像にデコードする必要があります。マスクを有効にしても、それは再描画プロセスに制約を加えているだけであり、実際にピクセルを部分的に上書きしているわけではありません。
Q2: 再描画であるなら、なぜ編集後の画像はほとんど同じに見えるのですか?
A: 4 層の一貫性メカニズム(視覚トークンの特徴抽象化、Self-Attention による元画像のグローバル参照、学習データの帰納バイアス、Thinking モードによる明示的な計画)が働いているからです。これらのメカニズムにより、AI は言及されていない領域を「意図的に選択して」維持します。
Q3: 拡散モデルのインペインティングは、真の部分修正と言えますか?
A: 言えません。Stable Diffusion のインペインティングも、マスクされていない領域を VAE でエンコード/デコードする必要があり、微小な再エンコード損失が発生します。複数回の編集を行うと、それが蓄積して目に見えるアーティファクト(ノイズ)となります。これが、GPT-Image-2 が自己回帰型を採用した核心的な動機の一つです。APIYI (apiyi.com) を通じて両方のモデルを同時に呼び出し、比較検証が可能です。
Q4: なぜ GPT-Image-2 は複数回編集しても漂流(劣化)しないのですか?
A: 自己回帰アーキテクチャは生成のたびに完全な元の画像トークンシーケンスを参照するため、反復的なノイズ除去のような累積誤差が発生しないからです。Thinking モードによる明示的な維持計画と組み合わせることで、複数回編集の安定性は拡散モデルを大きく上回ります。
Q5: マスクを使うべきか、純粋なプロンプト編集を使うべきか?
A: まずはプロンプトと明確な維持指示を優先してください。これにより Thinking モードが自動的に計画を立てます。修正領域の境界が明確で、かつ極めて精密である必要がある場合(顔の特定のパーツなど)にのみ、マスクを追加してハード制約をかけます。
Q6: 今後の AI 画像編集はどう発展しますか?
A: 3 つのトレンドが予想されます。(1) トークナイザーの情報密度が向上し、トークン数とコストが削減される。(2) マルチモーダルが統合され、テキスト/画像/動画が同一の Transformer を共有する。(3) Thinking 推理能力が強化され、より長い多段階編集チェーンをサポートする。APIYI (apiyi.com) での新モデルのリリース情報を注視し、アップグレードのパスを迅速に評価することをお勧めします。
まとめ:原理を理解し、ツールを使いこなす
GPT-Image-2 のような自己回帰型画像モデルは、「AI による画像編集」に対する私たちの直感的な認識を覆しました。これらは Photoshop スタイルの部分修正ではなく、自己回帰型画像生成に基づくインテリジェントな再描画です。一貫性は、トークン化された意味の抽象化、Self-Attention によるグローバルな固定、学習バイアス、そして Thinking モードという 4 つのメカニズムの連携から生まれます。
この原理を理解することで、Thinking モードによる計画を確実にトリガーするプロンプトを作成し、複数回編集の落とし穴を避け、コストと品質のバランスを見つけることができます。APIYI (apiyi.com) プラットフォームでは、GPT-Image-2、Nano Banana、Stable Diffusion など、主要なモデルを統一されたインターフェースで呼び出すことができ、本記事で紹介したすべての原理と最適化テクニックを迅速に検証可能です。
本記事は APIYI チームが OpenAI、Google DeepMind 等の公式資料および実測データに基づき作成しました。本番環境で GPT-Image-2 を呼び出す場合は、APIYI 公式サイト(apiyi.com)にて接続ドキュメントをご確認ください。





