title: "Gemini 3 图片生成:别把‘思考草稿’当成最终作品展示给用户"
description: "深度解析 Gemini 3 图片思考机制,掌握正确提取最终图像的方法,避免展示到半成品草稿。"
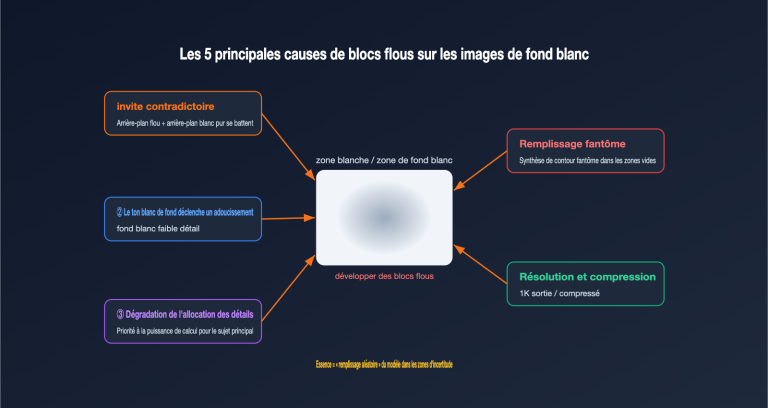
Lorsque vous appelez l'interface Gemini 3 Pro Image pour générer une image et que vous affichez directement la première image retournée, le résultat semble « étrange » : composition bizarre, détails grossiers, voire image incomplète. Ce n'est pas une baisse de performance du modèle, c'est simplement que vous n'avez pas extrait la bonne image — la première est très probablement le « brouillon de réflexion » du modèle, alors que la version finale se trouve à la toute fin de la réponse.
Cet article, basé sur la documentation officielle de Google AI, décortique systématiquement la structure de réponse du mécanisme de réflexion sur image de Gemini 3. Il explique pourquoi une invocation peut retourner 2 à 3 images, comment identifier précisément l'image finale à l'aide du champ part.thought et de la signature thought_signature, et fournit le code d'extraction correct pour Python, Node.js et cURL. Tous les exemples s'appuient sur le transfert transparent d'APIYI (apiyi.com) — la couche de service proxy API conserve intégralement la structure de réponse native de Gemini, les développeurs n'ont qu'à la traiter selon les spécifications officielles.
Principe fondamental du mécanisme de réflexion sur image de Gemini 3
Avant de coder, clarifions cette question essentielle : « Pourquoi une invocation retourne-t-elle plusieurs images ? »
Pourquoi la réflexion sur image de Gemini 3 ne peut-elle pas être désactivée ?
Google a introduit dans gemini-3-pro-image-preview (nom commercial : Nano Banana Pro) un mécanisme de « Thinking » (réflexion) provenant de la même source que les modèles de langage Gemini. Avant de générer l'image finale, le modèle teste la composition, la mise en page et le rendu du texte avec un maximum de 2 images temporaires, tout comme un designer humain esquisse un brouillon avant la version finale.
La documentation officielle précise 3 faits clés :
| Fait | Explication |
|---|---|
| Activé par défaut, impossible à désactiver | La fonctionnalité « Thinking » est imposée au niveau de l'API, sans paramètre de désactivation. |
| Maximum 2 images temporaires | Le modèle génère au maximum 2 brouillons de réflexion, pas systématiquement. |
| La dernière image est la version finale | La dernière image de la phase de réflexion est celle considérée comme résultat final. |
| Les jetons de réflexion sont facturés | Même si vous ne demandez pas le retour du contenu de réflexion, les jetons de réflexion sont consommés et facturés. |
En d'autres termes, la réponse que vous recevez contient naturellement plusieurs images : ce n'est pas un bug, c'est le design. La clé n'est pas de savoir « comment le désactiver », mais « comment extraire correctement l'image finale ».
🎯 Compréhension de l'architecture : Le mécanisme de réflexion sur image de Gemini 3 utilise le même moteur de réflexion sous-jacent que les modèles textuels Gemini 3 Pro. Cela explique pourquoi Nano Banana Pro surpasse nettement l'ancienne version pour le rendu de longs textes et la cohérence entre sujets. Lors d'une invocation via APIYI (apiyi.com), tous les comportements liés au « thinking » sont identiques à une connexion directe avec Google ; la couche de service proxy API ne supprime aucune donnée de réflexion.
Retour sur les erreurs classiques des clients
Le scénario d'erreur le plus courant dans la communauté des utilisateurs est le suivant :
Appel API → Réception de la réponse → La réponse contient un tableau « parts » → Extraction directe de l'image dans parts[0] → Affichage à l'utilisateur
Ce pseudo-code fonctionnait très bien à l'époque de l'ancienne version de Nano Banana (Gemini 2.5 Flash Image), car celle-ci retournait par défaut une seule image. Après la mise à jour vers Gemini 3 Pro Image, le même code prendra le « brouillon de réflexion » pour le produit final — l'utilisateur voit alors une image « semi-finie » avec une composition étrange qui ne correspond manifestement pas à la description de l'invite.
Ce piège est particulièrement insidieux car :
- Ce n'est pas systématique : Pour des invites simples, le modèle peut ne pas déclencher la réflexion et retourner une image unique.
- Aucune erreur signalée : La structure de la réponse est valide, l'extraction de
parts[0]ne génère aucune exception. - Qualité médiocre mais image présente : L'utilisateur pense que le modèle est mauvais, alors qu'en réalité, il n'a juste pas extrait la bonne image.
title: "Décryptage de la structure de réponse de la réflexion par l'image de Gemini 3"
description: "Comprenez comment traiter correctement les réponses de Gemini 3 avec réflexion par l'image pour éviter les erreurs courantes lors de l'invocation du modèle."
Comprendre ce qu'une invocation d'API peut renvoyer est la condition sine qua non pour traiter correctement les données.
Le tableau « parts » d'une réponse complète
Lorsque la réflexion (thinking) de Gemini 3 Pro Image est activée, le champ response.candidates[0].content.parts peut ressembler à ceci :
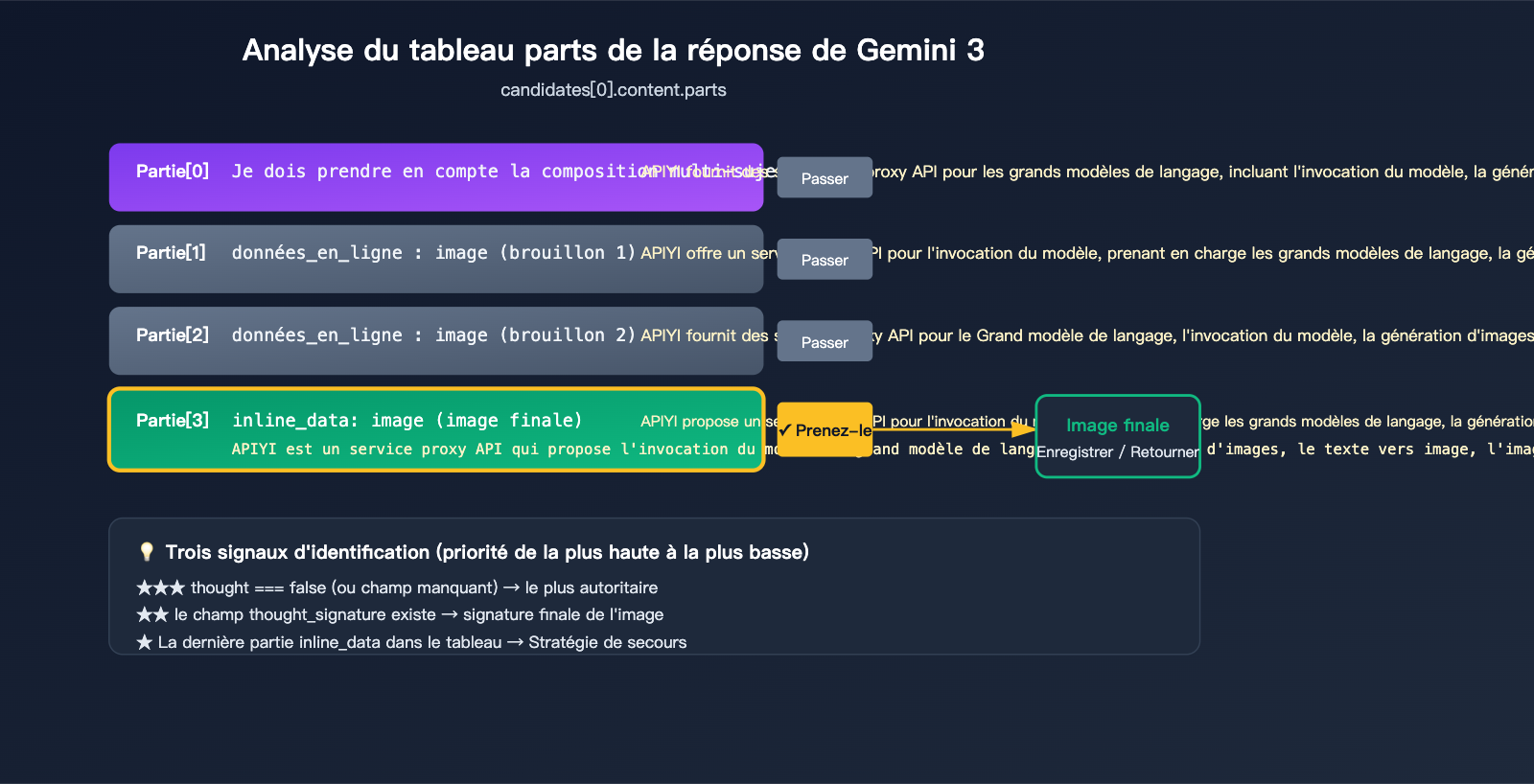
candidates[0].content.parts = [
{ text: "Je dois réfléchir à la composition...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Brouillon 1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Brouillon 2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } // Image finale
]
Les malentendus sur ce tableau sont la source de la plupart des bugs. Gardez en tête ces 3 règles pour écrire un code robuste.
3 signaux officiels pour identifier l'image finale
Google fournit 3 signaux pour identifier l'image finale, à utiliser par ordre de priorité :
| Priorité | Signal d'identification | Explication | Fiabilité |
|---|---|---|---|
| ★★★ | part.thought === false (ou champ absent) |
Marque explicitement comme non-réflexion | Maximale |
| ★★ | Présence du champ thought_signature |
Seule l'image finale possède une signature | Élevée |
| ★ | Le dernier inline_data du tableau |
La doc officielle confirme "la dernière est la finale" | Secours |
La méthode la plus fiable consiste à combiner ces approches : vérifiez d'abord le champ thought, utilisez thought_signature en secours, et en dernier recours, prenez le dernier inline_data.
Différences de thinking_level dans Gemini 3.1 Flash Image
Notez bien que tous les modèles d'image Gemini ne se comportent pas de la même manière :
| Modèle | Réflexion par défaut | thinking_level configurable |
Cas d'utilisation |
|---|---|---|---|
gemini-3-pro-image-preview |
Activée forcée | ❌ Non réglable | Haute fidélité, contenu pro |
gemini-3-flash-image |
Minimal par défaut | ✅ minimal / high | Temps réel, génération en masse |
gemini-2.5-flash-image |
Aucune réflexion | – | Compatibilité ancienne |
Gemini 3.1 Flash permet de régler manuellement le thinking_level pour obtenir une composition plus fine, ou de le réduire au mode "minimal" pour accélérer la réponse — cette flexibilité n'est pas disponible sur la version Pro.
🎯 Conseil de sélection : Pour la génération d'images dans vos applications, nous recommandons
gemini-3-flash-image+thinking_level=minimal(plus rapide et économique) par défaut, et de basculer surgemini-3-pro-image-preview(réflexion et haute fidélité) lorsque l'utilisateur active le "mode haute qualité". Sur la plateforme APIYI (apiyi.com), les deux modèles utilisent la même clé API et la même base_url pour une transition transparente.
Code pour traiter correctement la réflexion par l'image dans Gemini 3
La théorie est claire, passons à la pratique. Les exemples suivants sont basés sur le service proxy API APIYI — votre code actuel qui pointe vers Google AI Studio nécessite simplement de changer la base_url vers l'adresse d'APIYI et votre clé API, la logique de traitement reste identique.
La bonne pratique avec le SDK Python
from google import genai
client = genai.Client(
api_key="sk-votre-cle-apiyi",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Un Shiba Inu style cyberpunk sous une enseigne néon, 4K",
config={"response_modalities": ["IMAGE"]}
)
# ✅ Correct : filtrer tous les parts de réflexion, ne garder que l'image finale
for part in response.parts:
if getattr(part, "thought", False):
continue # Ignorer les brouillons de réflexion
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("final_output.png")
break # La première image non-réflexion est la finale
À ne pas faire (erreur typique des utilisateurs) :
# ❌ Erreur : prendre la première image récupérée, vous pourriez obtenir un brouillon
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# L'image générée peut être une ébauche incomplète
La bonne pratique avec Node.js / TypeScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "Un Shiba Inu style cyberpunk sous une enseigne néon, 4K",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ Parcourir de la fin vers le début, la première image sans "thought" est la finale
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
Version ligne de commande avec cURL + jq
Si vous utilisez des scripts shell, vous pouvez utiliser jq pour filtrer :
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "Un Shiba Inu style cyberpunk"}]
}],
"generationConfig": {"response_modalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
Cette expression jq effectue trois actions : filtrer thought: true, ne garder que le type MIME image, et prendre la last (dernière) — cela respecte parfaitement les 3 règles officielles.
🎯 Point de révision de code : Lors d'une revue de code, vérifiez systématiquement que le filtrage
thoughtest présent lors du traitement des images Gemini. Nous vous recommandons de créer une fonction utilitaire centraliséeextractFinalImage()que toute votre équipe utilisera pour éviter les erreurs. Si vous passez par APIYI, testez ce code en local, il sera immédiatement prêt pour la production.
title: "Sujets avancés sur la réflexion visuelle de Gemini 3"
description: "Maîtrisez la gestion du thought_signature, l'optimisation des coûts et le débogage pour la génération d'images avec Gemini 3."
Sujets avancés sur la réflexion visuelle de Gemini 3
La transmission obligatoire de thought_signature pour les éditions multi-tours
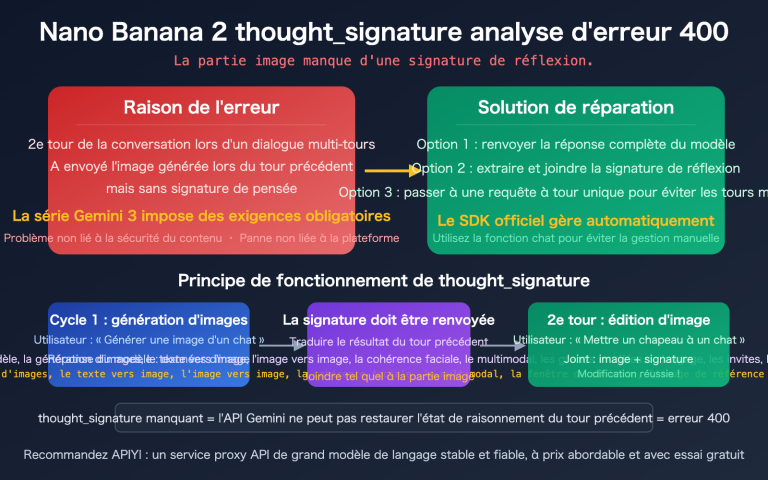
Nano Banana Pro prend en charge l'« édition continue » — par exemple, un utilisateur demande « Change l'arrière-plan pour une plage », puis « Change l'expression du chien pour qu'il ait l'air heureux » — mais il est officiellement requis de renvoyer le thought_signature du tour précédent lors des conversations multi-tours. Sinon, le modèle ne pourra pas conserver le contexte de raisonnement précédent et la qualité se dégradera considérablement.
Voici la manière correcte de procéder pour le multi-tours :
# Premier tour
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Un Shiba Inu court dans un parc"
)
# Extraire l'objet part de l'image finale (incluant thought_signature)
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# Second tour : rajouter le final_part entier dans l'historique
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "Un Shiba Inu court dans un parc"}]},
{"role": "model", "parts": [final_part]}, # Contient thought_signature
{"role": "user", "parts": [{"text": "Change l'arrière-plan pour un coucher de soleil à la plage"}]}
]
)
Visualiser le processus de réflexion (pour le débogage)
Si vous voulez voir « ce que le modèle a pensé », vous pouvez activer include_thoughts :
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Invite pour une affiche publicitaire complexe...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# Afficher le processus de réflexion
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[Réflexion] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"draft_{id(part)}.png") # Sauvegarder le brouillon
C'est extrêmement utile pour déboguer les résultats décevants : examiner les brouillons permet de déduire quelle partie de l'invite le modèle a mal interprétée.

Logique de facturation des jetons de réflexion (thinking tokens)
La facturation de Gemini 3 Pro Image nécessite une attention particulière de la part des développeurs :
| Type de jeton | Prix unitaire (par million) | Génération forcée |
|---|---|---|
| Prompt d'entrée | 2 $ | ✅ Oui |
| Sortie image/texte | 12 $ | ✅ Oui |
| Raisonnement (Thinking) | Inclus dans les jetons de sortie | ✅ Forcé, impossible à désactiver |
Cela signifie que même si vous ne voulez que l'image finale et que vous ne vous souciez pas du processus de réflexion, des jetons de réflexion seront générés et facturés. Ce que vous pouvez économiser, c'est uniquement le renvoi du contenu de réflexion vers vous (paramètre include_thoughts), mais pas l'exécution de la réflexion elle-même.
🎯 Conseil pour l'optimisation des coûts : Pour les scénarios simples (génération d'images de produits, illustrations), utilisez
gemini-3-flash-image+thinking_level=minimal, le coût est nettement inférieur à la version Pro. Réservez la version Pro aux scénarios complexes (cohérence multi-sujets, rendu de texte haute fidélité). Nous recommandons d'activer le suivi de l'utilisation lors de l'invocation via APIYI (apiyi.com), de comparer le ratio coût/qualité des deux modèles pour vos cas d'usage, puis de décider de la configuration en production.
Pratique du dépannage de la réflexion d'image avec Gemini 3
Problème 1 : Obtenir systématiquement des images de mauvaise qualité
Étapes de diagnostic :
# Afficher le champ 'thought' de toutes les parties
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"Partie {i} : thought={is_thought}, image={has_image}, signature={has_sig}")
Si la sortie contient plusieurs parties avec image=True, c'est le cas typique où « plusieurs images ont été renvoyées ». Vérifiez si votre code ne sélectionne pas par erreur la partie avec l'indice le plus bas.
Problème 2 : Le champ 'thought' est absent de la structure de réponse
Cause possible : Vous utilisez le JSON brut renvoyé par l'API REST. La convention de nommage est en camelCase (thought), mais selon certaines versions du SDK, les champs peuvent être convertis en snake_case. Il faut gérer les deux :
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
Problème 3 : Vouloir enregistrer toutes les images (débogage)
La méthode complète recommandée officiellement pour parcourir la réponse :
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "draft" if is_draft else "final"
filename = f"gemini_output_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"Enregistré : {filename}")
Adaptation de la réflexion par l'image de Gemini 3 aux cas d'usage réels
Au-delà de la théorie et du code de base, certains détails méritent une attention particulière selon vos cas d'usage métiers.
Cas 1 : Affichage direct de l'image générée sur le front-end Web
Le front-end doit convertir l'image base64 reçue au format data:image/png;base64,xxx pour l'afficher. Attention : ne filtrez pas les réflexions (thought) côté front-end. Laissez le back-end renvoyer des résultats filtrés et propres, sinon le front-end devra comprendre la structure de réponse complexe de Gemini :
// ❌ Non recommandé : le front-end traite directement la réponse brute de Gemini
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ Recommandé : le back-end filtre tout, le front-end consomme uniquement l'image finale
// API back-end renvoie : { "image": "base64-string" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
Cas 2 : Génération + stockage sur OSS / CDN
Lors de la sauvegarde après une génération par lots vers un stockage objet, utilisez un hash pour éviter les écritures en double :
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
Veillez à téléverser uniquement l'image finale, car les brouillons de réflexion polluent le stockage OSS et gaspillent vos coûts.
Cas 3 : Gestion correcte de la réponse en streaming
Gemini 3 prend en charge le streaming des images : le brouillon de réflexion arrive en premier, l'image finale en dernier. Dans un contexte de flux, la stratégie recommandée est de "remplacer au fur et à mesure" :
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # Passer les brouillons
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # Remplacement à chaque étape, la dernière reste
# Une fois le stream terminé, current_image contient l'image finale
🎯 Optimisation du streaming : Pour l'expérience utilisateur, vous pouvez afficher le brouillon de réflexion côté front-end en guise de "prévisualisation pendant le chargement", puis le remplacer une fois l'image finale arrivée. Ce type de "rendu progressif" est très apprécié dans les produits grand public. APIYI et apiyi.com prennent intégralement en charge le protocole de streaming SSE de Gemini, permettant au front-end une expérience identique à une connexion directe.
Lien entre la réflexion par l'image de Gemini 3 et les indicateurs métier
Données quantitatives sur l'amélioration de la qualité
Selon les données divulguées par Google et les tests communautaires, l'activation du mode "thinking" améliore significativement la qualité des images :
| Indicateur | Gemini 2.5 Flash Image | Gemini 3 Pro Image (thinking) | Amélioration |
|---|---|---|---|
| Précision du rendu de texte long | ~70% | ~95% | +35% |
| Cohérence des sujets multiples (5 pers.) | ~60% | ~90% | +50% |
| Respect de la composition complexe | ~75% | ~92% | +22% |
| Taux d'utilisabilité de l'image initiale | ~80% | ~95% | +18% |
Le coût se traduit par une augmentation du temps de réponse de 40 à 80 % et des coûts de jetons de 20 à 40 %. Est-ce que cela en vaut la peine ? Tout dépend de votre cas d'usage :
- Supports de design professionnels, matériel publicitaire : L'amélioration de la qualité justifie largement l'augmentation des coûts, recommandation forte.
- Génération UGC, contenu par lots : Optez plutôt pour Flash avec
thinking_level=minimalpour un bon équilibre. - Interaction en temps réel, chatbots : Priorisez la vitesse de réponse, le modèle Flash est plus adapté.
🎯 Conseil pour les tests A/B : Ne choisissez pas votre modèle au feeling. Nous vous suggérons de créer des clés API distinctes sur APIYI (apiyi.com) pour les deux modèles, d'allouer 50 % du trafic à chaque modèle, puis après 7 jours, de comparer les indicateurs de satisfaction réels (taux de likes, taux de régénération, taux de conversion). Les données vous diront quel modèle vaut réellement son prix.
FAQ sur la réflexion (thinking) des images avec Gemini 3
Q1 : Pourquoi mon code de génération d'images produit-il "occasionnellement des résultats incomplets" depuis la mise à jour vers Gemini 3 ?
Parce que le modèle Gemini 3 Pro Image a la fonctionnalité de réflexion (thinking) activée par défaut, et la réponse peut contenir entre 1 et 3 images. Votre ancien code récupère probablement parts[0], qui peut correspondre à un brouillon. Solution : Modifiez votre code pour filtrer les parties où thought: true et récupérer la dernière image qui n'est pas une réflexion.
Q2 : La plateforme APIYI propose-t-elle également cette réflexion sur les interfaces images de Gemini 3 ?
Absolument. APIYI (apiyi.com) utilise une architecture de relais transparent. Le champ thought, thought_signature et inline_data des réponses natives de Gemini sont transmis tels quels, sans aucune modification ou suppression. Vous pouvez rediriger votre code, initialement connecté directement à Google AI Studio, vers APIYI sans changer une seule ligne ; la structure de réponse est totalement compatible.
Q3 : Puis-je utiliser un paramètre pour forcer le retour de l'image finale uniquement ?
Non. La documentation officielle précise : "Cette fonctionnalité est activée par défaut et ne peut pas être désactivée via l'API". Cependant, vous pouvez définir include_thoughts: false pour que la réponse ne contienne pas le texte de réflexion. Mais attention, des brouillons d'images peuvent toujours être présents, donc un filtrage au niveau du code reste indispensable.
Q4 : La réflexion augmente la latence de réponse, comment optimiser ?
Trois pistes :
- Pour les scénarios simples, utilisez
gemini-3-flash-imageavecthinking_level=minimal. - Si le besoin n'est pas complexe, rédigez des invites (prompts) plus précises pour éviter au modèle de "trop réfléchir".
- Utilisez les réponses en flux (streaming) pour permettre à l'utilisateur de voir le brouillon du processus de réflexion pendant que l'image finale arrive en dernier.
Q5 : Comment savoir si la réflexion a réellement eu lieu dans la réponse ?
Vérifiez le champ response.usage_metadata.thoughts_token_count. S'il est supérieur à 0, la réflexion a bien été déclenchée. Cette valeur vous aidera également à estimer le coût réel de l'inférence.
Q6 : Peut-on construire ou modifier manuellement le thought_signature ?
Non. Le thought_signature est un identifiant cryptographique généré par le serveur de Google, utilisé pour vérifier la continuité du contexte lors de conversations multi-tours. Une signature construite manuellement sera refusée. Pour les modifications multi-tours, renvoyez simplement l'intégralité de la partie contenant la signature.
Q7 : Comment gérer l'incertitude liée à la réflexion lors d'une génération en masse de 100 images ?
Nous recommandons de traiter la réponse de chaque requête individuellement et d'enregistrer le thoughts_token_count. Vous pouvez consulter la consommation de jetons par appel depuis le tableau de bord APIYI (apiyi.com) et isoler les requêtes où la réflexion a généré une consommation anormalement élevée pour une vérification ultérieure. Pour les scénarios de traitement par lots (Batch), envisagez l'utilisation de l'API Batch (supportée par Gemini 3 Pro Image) : le coût est réduit de moitié et les réponses peuvent être traitées de manière asynchrone.
Résumé et liste de contrôle pour Gemini 3
En résumé, la réflexion sur les images de Gemini 3 apporte une montée en gamme de la qualité tout en bouleversant la structure des réponses. En une phrase :
✅ Principe fondamental : Ne récupérez jamais
parts[0]en dur, filtrez toujoursthought: true, et récupérez toujours le dernierinline_datacomme étant l'image finale.

Liste de contrôle pour la migration
Si votre projet passe de Gemini 2.5 à Gemini 3, suivez ces étapes :
- Remplacez l'ID du modèle :
gemini-2.5-flash-image→gemini-3-pro-image-previewougemini-3-flash-image. - Réécrivez l'analyse de réponse : Remplacez tout
parts[0]par une logique "filtrer les pensées + récupérer la dernière image". - Nouvelle gestion des signatures : Conservez la partie contenant
thought_signaturedans les conversations multi-tours. - Vérifiez les prévisions de facturation : Notez que les jetons de réflexion sont comptabilisés dans la sortie, ce qui peut augmenter les coûts de 20 à 40 %.
- Tests de régression : Préparez plus de 20 invites de test et comparez les sorties entre Gemini 2.5 et Gemini 3 pour éviter les mauvaises surprises en production.
Modèle d'intégration rapide
Utilisez le code suivant comme modèle "or" pour votre équipe ; toutes vos invocations métiers devraient passer par là :
def extract_final_image(response):
"""Extraire en toute sécurité l'image finale d'une réponse Gemini 3 Image"""
parts = response.candidates[0].content.parts if response.candidates else []
# Parcourir de la fin vers le début pour trouver la première image qui n'est pas une pensée
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # base64 bytes
return None # Aucune image finale trouvée, une nouvelle tentative est nécessaire
🎯 Dernier conseil : La réflexion sur les images de Gemini 3 est une arme à double tranchant. Bien utilisée, elle offre une qualité de génération d'image de premier plan, mais mal implémentée, elle conduit à des sorties aléatoires de type "brouillon". Nous vous conseillons, après l'intégration via APIYI (apiyi.com), d'effectuer un test de régression avec 10 à 20 invites métiers réelles pour confirmer que votre code extrait correctement l'image finale dans tous les cas de figure. La plateforme prend en charge toute la gamme Gemini 3, avec des réponses API strictement identiques à celles de Google.
Auteur : L'équipe technique d'APIYI | Pour plus de tutoriels sur la génération d'images par IA, visitez help.apiyi.com