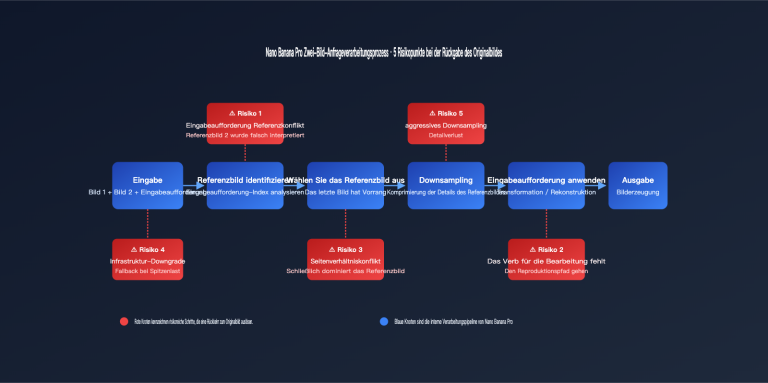
Wenn Sie die Gemini 3 Pro Image-Schnittstelle zur Bilderzeugung nutzen und das erste Bild aus der Antwort direkt dem Benutzer anzeigen, wirkt das Ergebnis oft „seltsam“: Die Komposition ist wirr, Details sind grob oder das Bild ist sogar unvollständig. Das liegt nicht daran, dass das Modell schlechter geworden ist – Sie haben schlichtweg das falsche Bild ausgewählt. Das erste Bild ist höchstwahrscheinlich ein „Denk-Entwurf“ des Modells; die echte, finale Version befindet sich fast immer an letzter Stelle der Antwort.
Dieser Artikel basiert auf der offiziellen Google AI-Dokumentation und erläutert systematisch die Antwortstruktur des Gemini 3 Bild-Denkprozesses. Wir erklären, warum ein Aufruf 2–3 Bilder zurückgeben kann, wie Sie das finale Bild mithilfe des Feldes part.thought und der Signatur thought_signature präzise identifizieren, und stellen korrekte Extraktionscodes für Python, Node.js und cURL bereit. Alle Beispiele basieren auf dem transparenten API-Proxy-Dienst von APIYI – die API-Proxy-Schicht behält die native Gemini-Antwortstruktur vollständig bei, Entwickler müssen lediglich die offiziellen Vorgaben umsetzen.
Kernprinzip des Gemini 3 Bild-Denkprozesses
Bevor wir in den Code einsteigen, klären wir das grundlegende Problem: Warum liefert ein einzelner Aufruf mehrere Bilder?
Warum der Gemini 3 Bild-Denkprozess standardmäßig nicht deaktivierbar ist
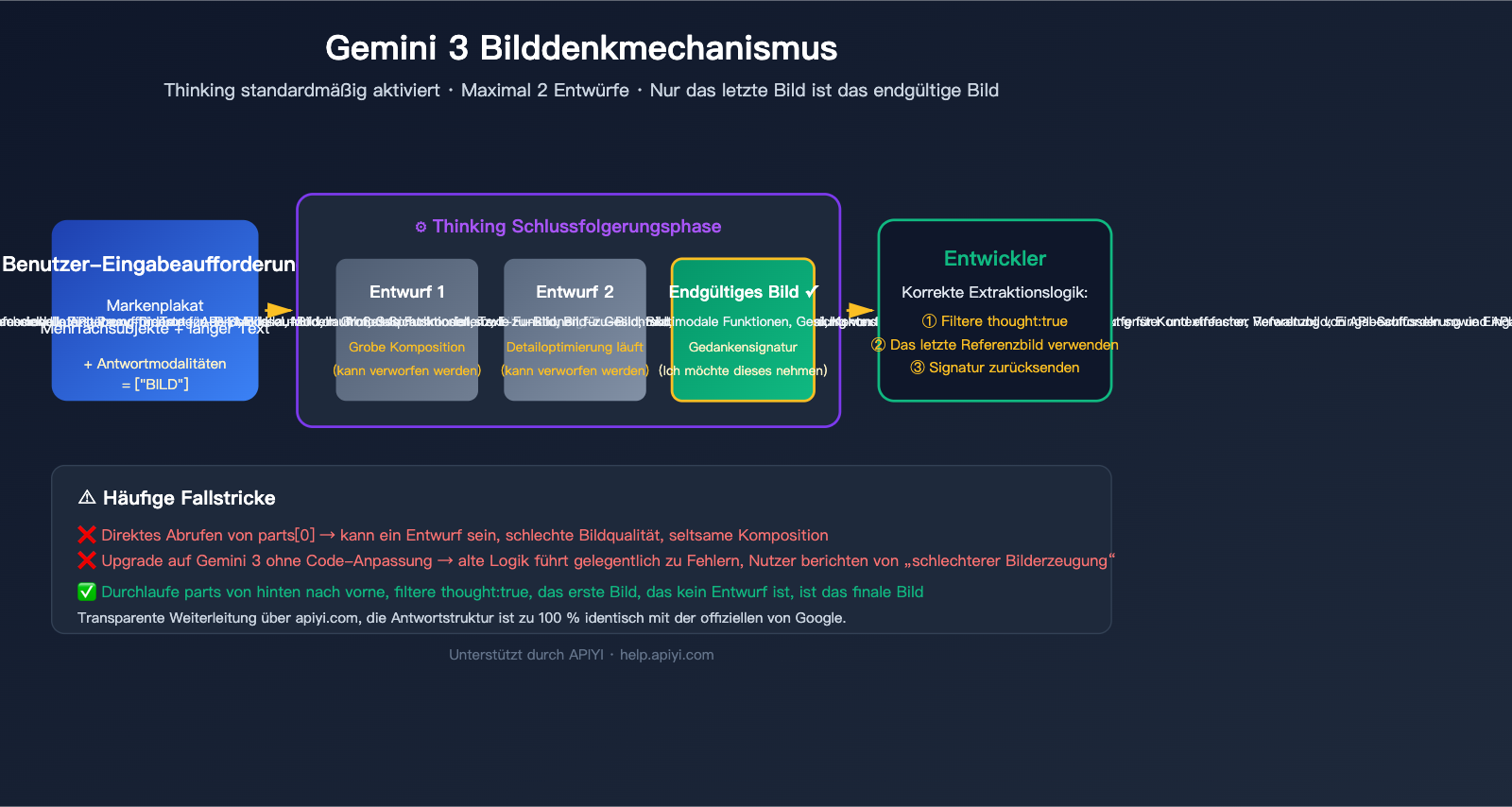
Google hat in gemini-3-pro-image-preview (Produktname Nano Banana Pro) einen Mechanismus namens „Thinking“ eingeführt, der auf derselben Technologie basiert wie die Textmodelle von Gemini. Vor der Ausgabe des finalen Bildes erstellt das Modell bis zu zwei vorläufige Bilder, um Komposition, Layout und Textdarstellung zu testen – fast so, als würde ein menschlicher Designer erst Skizzen anfertigen, bevor er das Endwerk erstellt.
Die offizielle Dokumentation bestätigt drei entscheidende Fakten:
| Fakt | Erläuterung |
|---|---|
| Standardmäßig aktiv | Die Thinking-Funktion ist auf API-Ebene fest aktiviert und hat keinen Parameter zur Deaktivierung |
| Bis zu 2 Entwürfe | Das Modell erstellt maximal 2 Entwürfe; dies geschieht nicht zwingend bei jedem Aufruf |
| Letztes Bild = Final | Das letzte Bild in der Thinking-Phase ist das finale Ergebnis |
| Thinking-Token kosten Geld | Auch wenn man keine Thinking-Inhalte anfordert, werden Thinking-Token verbraucht und berechnet |
Mit anderen Worten: Die erhaltene Antwort enthält naturgemäß mehrere Bilder – das ist kein Fehler, sondern das Design. Die Frage ist nicht, „wie man es abschaltet“, sondern „wie man korrekt nur das finale Bild entnimmt“.
🎯 Architekturverständnis: Der Thinking-Mechanismus von Gemini 3 für Bilder nutzt dieselbe Engine wie das logische Denken der Gemini 3 Pro Textmodelle. Dies erklärt, warum Nano Banana Pro bei der Darstellung komplexer Texte und der Konsistenz mehrerer Bildmotive deutlich besser ist als die ältere Version von Nano Banana. Bei der Nutzung über APIYI bleibt das gesamte Thinking-Verhalten identisch mit einer direkten Verbindung zu Google; die Proxy-Schicht entfernt keinerlei Denkdaten.
Häufige Fehlerquellen in der Praxis
Der typische Fehler in Entwickler-Communities sieht so aus:
API aufrufen → Antwort erhalten → Die Antwort enthält ein parts-Array → Direkt das Bild in parts[0] abgreifen → Dem Benutzer anzeigen
Dieser Pseudo-Code funktionierte in Zeiten von Nano Banana (Gemini 2.5 Flash Image) einwandfrei, da diese Version standardmäßig nur ein Bild lieferte. Nach dem Upgrade auf Gemini 3 Pro Image behandelt derselbe Code die „Denk-Entwürfe“ als fertiges Produkt – und der Benutzer sieht ein Bild, das offensichtlich nicht dem Prompt entspricht oder fehlerhaft ist.
Diese Fehlerquelle ist besonders heimtückisch, weil:
- Nicht jeder Aufruf schlägt fehl: Bei einfachen Prompts löst das Modell möglicherweise kein „Thinking“ aus und liefert nur ein Bild.
- Keine Fehlermeldung: Die Antwortstruktur ist korrekt, der Zugriff auf
parts[0]löst keine Exception aus. - Qualität mangelhaft, aber Bild vorhanden: Benutzer glauben, das Modell sei schlecht, obwohl in Wahrheit nur das falsche Bild ausgewählt wurde.
Erläuterung der Antwortstruktur bei Gemini 3 Image Thinking
Um Bilder korrekt zu verarbeiten, ist es essenziell zu verstehen, was eine API-Antwort enthalten kann.
Das vollständige parts-Array einer Antwort
Wenn die Thinking-Funktion von Gemini 3 Pro Image ausgelöst wird, sieht response.candidates[0].content.parts in etwa so aus:
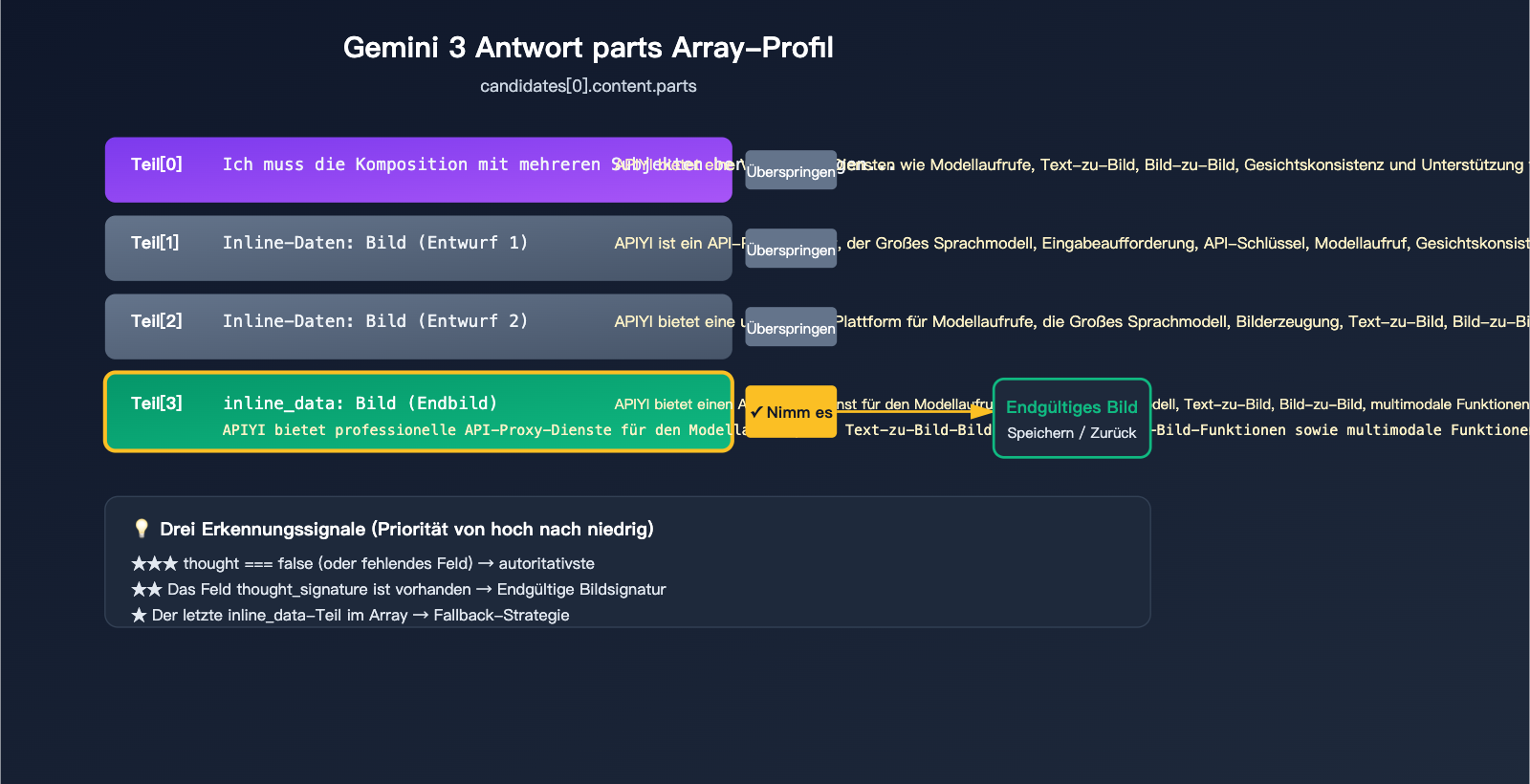
candidates[0].content.parts = [
{ text: "Ich muss über die Komposition nachdenken...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Entwurf 1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Entwurf 2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } // Endgültiges Bild
]
Missverständnisse bei diesem Array sind die Hauptursache für die meisten Bugs. Befolgen Sie diese 3 Regeln für korrekten Code.
Die 3 offiziellen Signale zur Identifizierung des finalen Bildes
Google bietet 3 Signale zur Identifizierung des endgültigen Bildes an, nutzen Sie diese nach Priorität:
| Priorität | Signal | Erläuterung | Zuverlässigkeit |
|---|---|---|---|
| ★★★ | part.thought === false(oder Feld fehlt) |
Klar als Nicht-Denk-Inhalt markierter Part | Höchste |
| ★★ | Vorhandensein des Feldes thought_signature |
Nur das finale Bild trägt eine Signatur | Hoch |
| ★ | Das letzte inline_data im Array |
Offiziell bestätigt: "Das letzte ist das Endergebnis" | Fallback |
Die sicherste Vorgehensweise ist eine Kombination: Prüfen Sie zuerst das thought-Feld, nutzen Sie thought_signature als Fallback und nehmen Sie im Notfall das letzte inline_data.
Unterschiede im thinking_level bei Gemini 3.1 Flash Image
Beachten Sie, dass sich nicht alle Gemini-Bildmodelle gleich verhalten:
| Modell | Thinking-Standard | Konfigurierbares thinking_level |
Anwendungsfall |
|---|---|---|---|
gemini-3-pro-image-preview |
Aktiviert (erzwungen) | ❌ Nicht anpassbar | Hohe Wiedergabetreue, professionelles Material |
gemini-3-flash-image |
Standardmäßig minimal |
✅ minimal / high |
Echtzeit-Interaktion, Batch-Generierung |
gemini-2.5-flash-image |
Kein Thinking | – | Abwärtskompatibilität |
Gemini 3.1 Flash erlaubt die manuelle Anpassung des thinking_level für detailliertere Kompositionen oder schnellere Antwortzeiten – eine Flexibilität, die bei der Pro-Version nicht existiert.
🎯 Empfehlung zur Auswahl: Für die Bildgenerierung in C-Endkunden-Produkten empfehlen wir standardmäßig
gemini-3-flash-imagemitthinking_level=minimal(schneller, günstiger). Bei Aktivierung des "High-Quality-Modus" durch den Benutzer sollte aufgemini-3-pro-image-preview(Denkprozess, hohe Treue) gewechselt werden. Auf der APIYI-Plattform (apiyi.com) können beide Modelle nahtlos mit demselben API-Schlüssel und derbase_urlverwendet werden.
Code zur korrekten Verarbeitung von Gemini 3 Bild-Thinking
Nach der Theorie folgt der Code. Die Beispiele basieren auf der transparenten Weiterleitung über APIYI (apiyi.com) – Ihr Code, der normalerweise direkt mit dem Google AI Studio kommuniziert, benötigt lediglich eine angepasste base_url und den APIYI-API-Schlüssel, die Verarbeitungslogik bleibt identisch.
Korrekte Implementierung mit dem offiziellen Python SDK
from google import genai
# APIYI-Plattform nutzen
client = genai.Client(
api_key="sk-your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Ein Shiba Inu im Cyberpunk-Stil, stehend unter Neonreklamen, 4K HD",
config={"response_modalities": ["IMAGE"]}
)
# ✅ Korrekt: Filtern Sie alle "thought parts" heraus und speichern Sie nur das finale Bild
for part in response.parts:
if getattr(part, "thought", False):
continue # Denk-Entwürfe überspringen
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("final_output.png")
break # Das erste nicht-Denk-Bild ist das finale Ergebnis
Negativbeispiel (Typischer Fehler bei Benutzern):
# ❌ Fehlerhaft: Direktes Abrufen des ersten Bildes liefert oft einen Denk-Entwurf
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# Das generierte Bild könnte ein unfertiger Entwurf sein
Korrekte Implementierung mit Node.js / TypeScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "Ein Shiba Inu im Cyberpunk-Stil, stehend unter Neonreklamen, 4K HD",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ Von hinten nach vorne durchlaufen: Das erste nicht-thought Bild ist das finale Bild
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
cURL + jq Befehlszeilen-Version
Falls Sie den Aufruf in einem Shell-Skript durchführen, können Sie jq zum Filtern verwenden:
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "Ein Shiba Inu im Cyberpunk-Stil"}]
}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
Der jq-Ausdruck erfüllt drei Aufgaben: Filtern von thought: true, Beschränkung auf den Image-Mime-Type und Auswahl des last-Elements – perfekt konform mit den 3 offiziellen Erkennungsregeln.
🎯 Code-Review-Tipp: Achten Sie bei Code-Reviews darauf, dass Gemini-Bildantworten immer gefiltert werden. Wir empfehlen die Kapselung einer zentralen
extractFinalImage()-Hilfsfunktion im Team. Bei einer Anbindung über APIYI (apiyi.com) können Sie diesen Code lokal testen und produktiv direkt wiederverwenden.
Fortgeschrittene Themen zur Bild-Denkfähigkeit von Gemini 3
„thought_signature“ bei der mehrstufigen Bearbeitung erforderlich
Nano Banana Pro unterstützt „kontinuierliche Bearbeitung“ – zum Beispiel wenn ein Benutzer sagt: „Ändere den Hintergrund zum Strand“ und danach „Lass den Hund glücklicher aussehen“. Die offizielle Dokumentation schreibt jedoch vor, dass die thought_signature aus der vorherigen Runde in jedem weiteren Dialogschritt zurückgegeben werden muss. Andernfalls kann das Modell den vorherigen Schlussfolgerungskontext nicht fortführen, was zu einer deutlichen Qualitätsminderung führt.
Korrekte Vorgehensweise bei mehrstufigen Dialogen:
# Erste Runde
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Ein Shiba Inu rennt durch einen Park"
)
# Extraktion des Part-Objekts des finalen Bildes (enthält thought_signature)
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# Zweite Runde: Den gesamten final_part wieder in den Verlauf einfügen
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "Ein Shiba Inu rennt durch einen Park"}]},
{"role": "model", "parts": [final_part]}, # Enthält thought_signature
{"role": "user", "parts": [{"text": "Ändere den Hintergrund zum Sonnenuntergang am Strand"}]}
]
)
Einblick in den Denkprozess (für Debugging-Zwecke)
Wenn Sie nachvollziehen möchten, was das Modell „gedacht“ hat, können Sie include_thoughts aktivieren:
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Komplexes Werbeplakat Prompt...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# Denkprozess ausgeben
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[Gedanke] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"draft_{id(part)}.png") # Entwurf speichern
Dies ist beim Debugging, warum ein Ergebnis nicht wie gewünscht ausfällt, extrem hilfreich – an den Entwürfen lässt sich ableiten, welchen Teil des Prompts das Modell falsch interpretiert hat.

Abrechnungslogik für Thinking-Token
Bei der Abrechnung von Gemini 3 Pro Image sollten Entwickler besonders auf Folgendes achten:
| Token-Typ | Preis (pro Mio.) | Erzwungen? |
|---|---|---|
| Eingabe-Prompt | $2 | ✅ Ja |
| Ausgabe Bild/Text | $12 | ✅ Ja |
| Thinking reasoning | Zählt als Output-Token | ✅ Erzwungen, nicht deaktivierbar |
Das bedeutet, selbst wenn Sie nur das finale Bild haben wollen und sich nicht für den Denkprozess interessieren, fallen Thinking-Token an und werden berechnet. Was Sie sparen können, ist lediglich die Übermittlung der Denkinhalte an Sie (per include_thoughts-Parameter), nicht aber die Ausführung des Denkprozesses selbst.
🎯 Empfehlungen zur Kostenoptimierung: Nutzen Sie für einfache Szenarien (wie Produktbilder oder Illustrationen)
gemini-3-flash-imagemitthinking_level=minimal, da die Kosten deutlich niedriger als bei der Pro-Version liegen. Setzen Sie die Pro-Version erst bei komplexen Anforderungen ein (Konsistenz mehrerer Subjekte, hochpräzises Text-Rendering). Wir empfehlen, bei der Nutzung über APIYI (apiyi.com) eine Nutzungsüberwachung zu aktivieren, um das Kosten-Leistungs-Verhältnis beider Modelle in Ihrem Anwendungsfall zu vergleichen, bevor Sie die Produktionskonfiguration festlegen.
Praxiserprobte Fehlerbehebung für Gemini 3 Bild-Denkprozesse
Problem 1: Durchgehend schlechte Bildqualität
Diagnoseschritte:
# Alle 'thought'-Felder der 'parts' ausgeben
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"Teil {i}: thought={is_thought}, bild={has_image}, signatur={has_sig}")
Wenn in der Ausgabe mehrere Teile mit image=True vorhanden sind, liegt ein klassischer Fall von „mehrere Bilder zurückgegeben“ vor. Überprüfen Sie, ob Ihr Code fälschlicherweise einen Teil mit niedrigem Index erfasst.
Problem 2: Das 'thought'-Feld fehlt in der Antwortstruktur
Mögliche Ursache: Sie verwenden das rohe JSON der REST-API. Die CamelCase-Benennung ist thought, aber in einigen SDK-Versionen können Felder in snake_case konvertiert werden. Sie sollten beide Varianten unterstützen:
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
Problem 3: Speichern aller Bilder (für Debugging-Zwecke)
Die von offizieller Seite empfohlene Methode zur vollständigen Iteration:
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "entwurf" if is_draft else "final"
filename = f"gemini_ausgabe_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"Gespeichert: {filename}")
Anpassung von Gemini 3 Bild-Denkprozessen an reale Geschäftsszenarien
Über die Theorie und den Basiscode hinaus gibt es in verschiedenen Szenarien wichtige Details zu beachten.
Szenario 1: Direktanzeige von erzeugten Bildern im Web-Frontend
Das Frontend muss Base64-Bilder in das Format data:image/png;base64,xxx konvertieren. Vermeiden Sie die Filterung des Denkprozesses im Frontend – lassen Sie das Backend gefilterte, saubere Ergebnisse liefern, sonst muss das Frontend die Gemini-Antwortstruktur verstehen:
// ❌ Nicht empfohlen: Frontend verarbeitet die rohe Gemini-Antwort direkt
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ Empfohlen: Backend filtert einheitlich, Frontend konsumiert nur das finale Bild
// Backend-API-Antwort: { "image": "base64-string" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
Szenario 2: Bilderzeugung + Speicherung in OSS / CDN
Verwenden Sie bei der Batch-Generierung und anschließenden Speicherung in einem Object Storage Hashes, um redundante Schreibvorgänge zu vermeiden:
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
Stellen Sie sicher, dass nur das finale Bild hochgeladen wird, da Denkentwürfe den OSS-Speicher unnötig belasten und Kosten verursachen.
Szenario 3: Korrekte Handhabung von Streaming-Antworten
Gemini 3 unterstützt für Bilder Streaming; Denkentwürfe treffen zuerst ein, das finale Bild später. Im Streaming-Szenario empfiehlt sich das „Überschreiben während des Empfangs“:
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # Entwurf überspringen
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # Jedes Mal überschreiben, das letzte Bild bleibt bestehen
# Nach Ende des Streams ist 'current_image' das finale Bild
🎯 Streaming-Optimierung: Für eine bessere User Experience können Sie die Denkentwürfe ebenfalls an das Frontend pushen, um eine „Lade-Vorschau“ zu ermöglichen, die dann durch das finale Bild ersetzt wird – diese „schrittweise Darstellung“ ist bei Consumer-Produkten sehr beliebt. APIYI (apiyi.com) unterstützt das SSE-Streaming-Protokoll von Gemini vollständig, sodass die Frontend-Wahrnehmung identisch mit der einer Direktverbindung ist.
Gemini 3 Bild-Denkprozesse und ihre geschäftlichen Auswirkungen
Quantifizierbare Qualitätssteigerungen
Basierend auf offiziellen Angaben von Google und Community-Tests führt die Aktivierung der „Thinking“-Funktion zu einer signifikanten Verbesserung der Bildqualität:
| Metrik | Gemini 2.5 Flash Image | Gemini 3 Pro Image (Thinking) | Steigerung |
|---|---|---|---|
| Genauigkeit bei Langtext-Rendering | ~70% | ~95% | +35% |
| Konsistenz bei mehreren Personen (5) | ~60% | ~90% | +50% |
| Einhaltung komplexer Kompositionen | ~75% | ~92% | +22% |
| Nutzbarkeit des ersten Bildes | ~80% | ~95% | +18% |
Der Preis dafür ist eine um 40–80 % höhere Antwortzeit und um 20–40 % steigende Token-Kosten. Lohnt sich das? Das hängt von Ihrem Szenario ab:
- Professionelle Design-Assets & Werbematerialien: Die Qualitätssteigerung überwiegt die Kosten bei weitem, daher sehr zu empfehlen.
- UGC-Bilderzeugung & Batch-Content: Hier empfiehlt sich Flash in Kombination mit
thinking_level=minimalfür eine gute Balance. - Echtzeit-Interaktion & Chatbots: Hier hat die Reaktionszeit Priorität, weshalb Flash die bessere Wahl ist.
🎯 A/B-Test-Empfehlung: Verlassen Sie sich nicht auf Ihr Bauchgefühl. Wir empfehlen, auf APIYI (apiyi.com) für beide Modelle jeweils einen API-Schlüssel zu erstellen und den Traffic zu 50/50 aufzuteilen. Vergleichen Sie nach 7 Tagen die tatsächlichen Nutzerzufriedenheits-Metriken (Likes, Regenerationsrate, Konversionsrate) – die Daten werden Ihnen zeigen, ob das Modell sein Geld wert ist.
FAQ: Häufige Fragen zu Gemini 3 Bild-Denkprozessen
F1: Warum liefern meine Bildgenerierungs-Skripte nach dem Upgrade auf Gemini 3 gelegentlich "halbfertige Ergebnisse"?
Da beim Gemini 3 Pro Image die Thinking-Funktion standardmäßig aktiviert ist, enthält die Antwort unter Umständen 1–3 Bilder. Ihr alter Code greift wahrscheinlich auf parts[0] zu, was jedoch ein Entwurf sein könnte. Lösung: Passen Sie Ihren Code so an, dass er thought: true filtert und das letzte Bild nimmt, das kein „Denk-Entwurf“ ist.
F2: Unterstützt die APIYI-Plattform ebenfalls die Thinking-Funktion für Gemini 3 Bilder?
Absolut. APIYI (apiyi.com) nutzt eine transparente Proxy-Architektur. Das thought-Feld, thought_signature sowie inline_data aus der nativen Gemini-Antwort werden unverändert durchgereicht, ohne dass Inhalte entfernt oder verändert werden. Sie können Ihren Code, der bisher direkt an das Google AI Studio ging, eins zu eins auf APIYI umstellen; die Antwortstruktur bleibt vollständig kompatibel.
F3: Kann ich per Parameter erzwingen, dass nur das finale Bild zurückgegeben wird?
Nein. Die offizielle Dokumentation besagt explizit: "This feature is enabled by default and cannot be disabled in the API" (Standardmäßig aktiviert, in der API nicht deaktivierbar). Sie können zwar include_thoughts: false setzen, damit keine Denk-Texte übertragen werden, aber Bildentwürfe können weiterhin vorhanden sein, weshalb eine Filterung auf Code-Ebene unerlässlich bleibt.
F4: Das „Thinking“ erhöht die Latenz, wie kann ich das optimieren?
Drei Ansätze:
- Für einfache Szenarien auf
gemini-3-flash-imagemitthinking_level=minimalwechseln. - Bei weniger komplexen Anforderungen den Prompt präziser formulieren, um „Überdenken“ des Modells zu vermeiden.
- Streaming verwenden, damit der Nutzer die Entwürfe des Denkprozesses sieht, während das finale Bild am Ende geliefert wird.
F5: Wie erkenne ich, ob bei einer Antwort tatsächlich ein Denkprozess (Thinking) stattgefunden hat?
Überprüfen Sie das Feld response.usage_metadata.thoughts_token_count. Ist der Wert größer als 0, wurde der Denkprozess ausgelöst. Dieser Wert hilft Ihnen zudem, die tatsächlichen Inferenzkosten besser abzuschätzen.
F6: Kann ich thought_signature selbst erstellen oder modifizieren?
Nein. thought_signature ist ein kryptografisches Zertifikat, das serverseitig von Google ausgestellt wird, um die Kontextkontinuität in Multi-Turn-Dialogen zu gewährleisten. Selbst erstellte Signaturen werden vom Server abgelehnt. Übergeben Sie bei Multi-Turn-Bearbeitungen einfach den gesamten Part inklusive der Signatur zurück.
F7: Wie gehe ich bei der Generierung von 100 Bildern mit der Unvorhersehbarkeit durch „Thinking“ um?
Wir empfehlen, jeden Request einzeln zu verarbeiten und den thoughts_token_count zu protokollieren. Im Dashboard von APIYI (apiyi.com) können Sie den Token-Verbrauch pro Aufruf einsehen und Anfragen mit ungewöhnlich hohem Denk-Aufwand zur Überprüfung filtern. Für Batch-Szenarien sollten Sie zudem die Batch-API in Betracht ziehen (wird von Gemini 3 Pro Image unterstützt), um Kosten zu halbieren und die Antworten asynchron zu verarbeiten.
Zusammenfassung der Gemini 3 Bild-Denkprozesse und Checkliste für die Implementierung
Ein Rückblick auf den gesamten Prozess: Gemini 3 Image Thinking hat nicht nur die Qualität verbessert, sondern auch die Antwortstruktur grundlegend verändert. Kurz zusammengefasst:
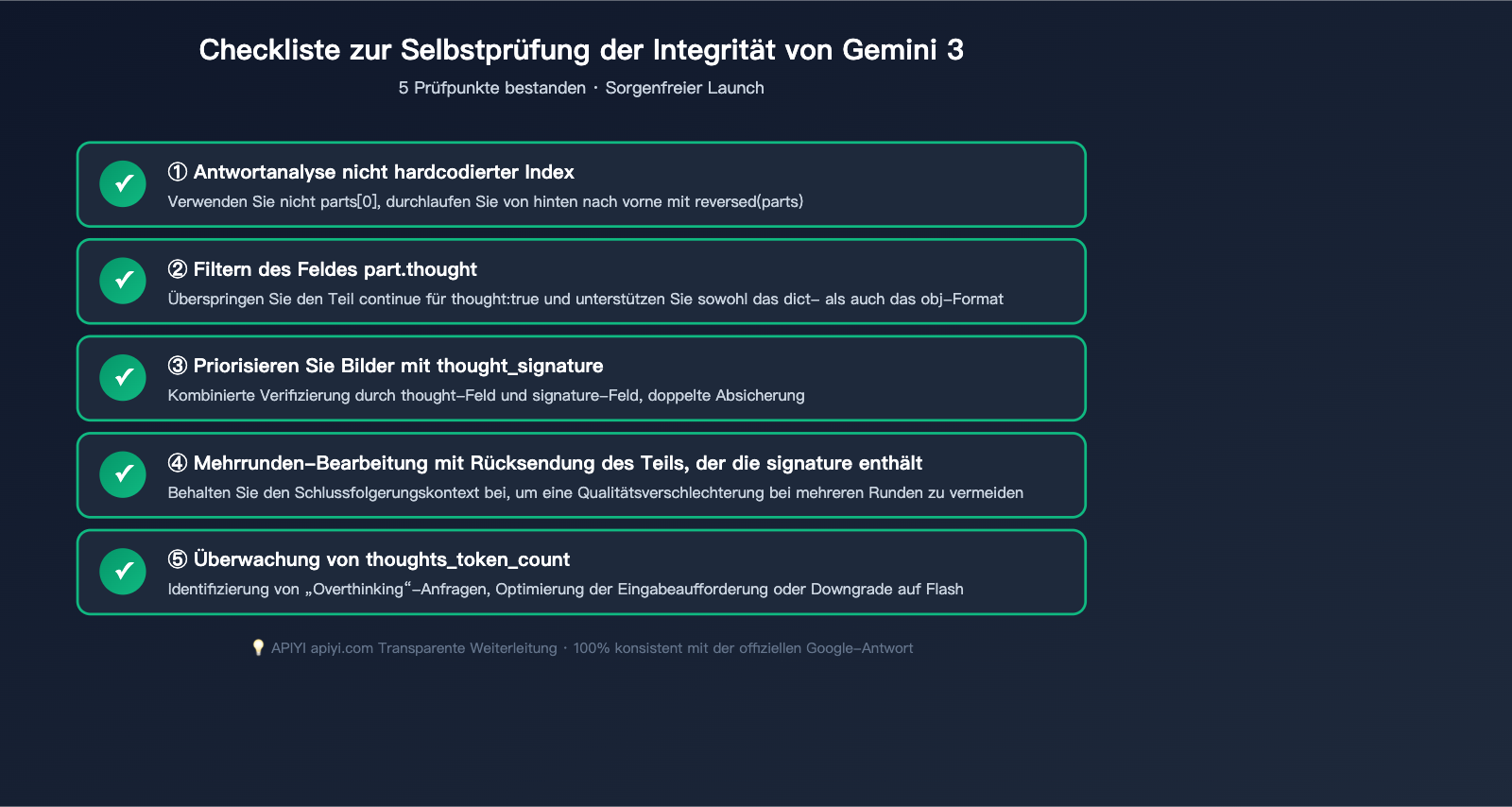
✅ Kernprinzipien: Greifen Sie niemals hart auf
parts[0]zu, filtern Sie immerthought: trueheraus und wählen Sie immer das letzteinline_dataals das finale Bild.
Checkliste für die Migration
Falls Sie Ihr Projekt von Gemini 2.5 auf Gemini 3 aktualisieren, gehen Sie diese Liste durch:
- Modell-ID ersetzen:
gemini-2.5-flash-image→gemini-3-pro-image-previewodergemini-3-flash-image - Antwort-Parsing umschreiben: Ändern Sie alle
parts[0]-Referenzen auf „Gedanken filtern + letztes Bild auswählen“. - Behandlung der Signatur: Bewahren Sie bei Dialogen mit mehreren Runden den Part mit der
thought_signatureauf. - Kosten-Validierung: Beachten Sie, dass Thinking-Token als Output-Token gezählt werden; die Kosten können um 20-40 % steigen.
- Regressions-Tests: Erstellen Sie 20+ Beispiel-Eingabeaufforderungen und vergleichen Sie die Ausgaben von Gemini 2.5 mit Gemini 3, um böse Überraschungen zu vermeiden.
Schnelle Integrationsvorlage
Verwenden Sie den folgenden Code als „Gold-Standard-Vorlage“ für Ihr Team bei allen Modellaufrufen:
def extract_final_image(response):
"""Extrahiert sicher das finale Bild aus einer Gemini 3 Image-Antwort"""
parts = response.candidates[0].content.parts if response.candidates else []
# Suche von hinten nach dem ersten Bild, das kein "Thought" ist
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # Base64-Bytes
return None # Kein finales Bild gefunden, erneuter Versuch erforderlich
🎯 Abschließende Empfehlung: Der Bild-Denkmechanismus von Gemini 3 ist ein zweischneidiges Schwert – bei korrekter Nutzung erhalten Sie eine erstklassige Bildqualität, bei falscher Nutzung jedoch halbfertige „Glückstreffer“. Wir empfehlen Ihnen, über APIYI (apiyi.com) zu starten, zunächst 10–20 reale Anwendungsfälle durch einen Regressions-Test laufen zu lassen und sicherzustellen, dass der Code bei allen Denkzuständen korrekt extrahiert, bevor Sie live gehen. Die Plattform unterstützt die gesamte Gemini 3-Modellreihe und die API-Antworten sind identisch mit denen von Google.
Autor: APIYI Tech-Team | Weitere Tutorials zur KI-Bilderzeugung finden Sie unter help.apiyi.com