モデルの知識にはカットオフ(期限)がありますが、実際のビジネス上の課題には「現在」のデータが必要です。Claude公式は2025年にネイティブな web_search ツールを導入し、2026年には動的フィルタリングをサポートする web_search_20260209 バージョンへとアップグレードしました。これにより、Claude APIのインターネット検索は「自前で構築する苦労」から「1行のパラメータを追加するだけ」へと進化しました。

本記事では、2026年時点での Claude API ネットワーク検索 の最新実装スキームを体系的に整理します。公式のネイティブツールである web_search / web_fetch のパラメータ、課金体系、制限、およびコードテンプレートを詳しく解説し、サードパーティ製MCPや自前構築のRAGといった3つの手法の比較を行います。記事の最後には、APIYI (apiyi.com) を活用した透過的転送の統合サンプルを掲載しています。base_url と api_key を書き換えるだけで、国内環境からでもスムーズに一連のフローを実行可能です。
Claude API ネットワーク検索の核心ポイント
コードを書く前に、まずは概念を整理しましょう。Claude APIのネットワーク検索は、本質的にAnthropicが公式に提供する Server Tool(サーバーサイドツール) です。つまり、検索はAnthropicのクラウド側で実行されるため、GoogleやBingのAPIを自分で接続したり、クローラーをデプロイしたりする必要はありません。
3つの主要な実装スキーム概要
| 手法 | 統合の複雑さ | コスト | リアルタイム性 | 引用とコンプライアンス |
|---|---|---|---|---|
公式ネイティブ web_search |
★☆☆ (toolフィールドのみ) | $10 / 1000回 + トークン | 高 (Anthropicのリアルタイムインデックス) | 自動引用 |
| サードパーティ MCP (例: Brave/Tavily) | ★★☆ (MCPサーバーの立ち上げが必要) | サードパーティ検索APIの料金 | 中〜高 | 自前で処理が必要 |
| 自前構築 (Google CSE + ツール呼び出し) | ★★★ (カスタムツール + 解析) | Google APIのクォータ | 中 | 完全自己管理 |
🎯 手法選択のアドバイス: もし「Claudeに直近の出来事を回答させ、リアルタイムデータを補完させたい」というニーズが核心であれば、公式ネイティブの
web_searchが現在の最適解です。運用コストゼロで、引用も適切に行われ、Sonnet 4.6やOpus 4.7などの主力モデルをカバーしています。APIYI (apiyi.com) の透過的転送経由でアクセスすれば、VPNなしでAnthropic公式APIの全機能を呼び出せるため、強く推奨します。
Claude API ネットワーク検索対応モデル一覧
すべてのClaudeモデルが web_search をサポートしているわけではありません。新版の web_search_20260209 にはモデル要件が明確に定められています。
| モデル | ベーシック版 web_search_20250305 |
動的フィルタ版 web_search_20260209 |
|---|---|---|
| Claude Opus 4.7 | ✅ | ✅ |
| Claude Opus 4.6 | ✅ | ✅ |
| Claude Sonnet 4.6 | ✅ | ✅ |
| Claude Sonnet 4.5 | ✅ | ❌ |
| Claude Haiku 4.5 | ✅ | ❌ |
動的フィルタリング (Dynamic Filtering) は2026年バージョンの核心的なアップグレードです。Claudeは検索結果をコンテキストに含める前に、コード実行ツールを使用して一度フィルタリングを行い、関連性の高いセグメントのみを保持します。長文ドキュメントの検索や技術文献のレビューにおいて、トークン消費量を大幅に削減できます。
Claude API ネット検索用公式ネイティブツール詳細解説
Anthropic社は、相互補完的な2つのネイティブツールを提供しています。これらの境界を理解することが、Claude API ネット検索を使いこなすための前提条件となります。
web_search と web_fetch の役割分担
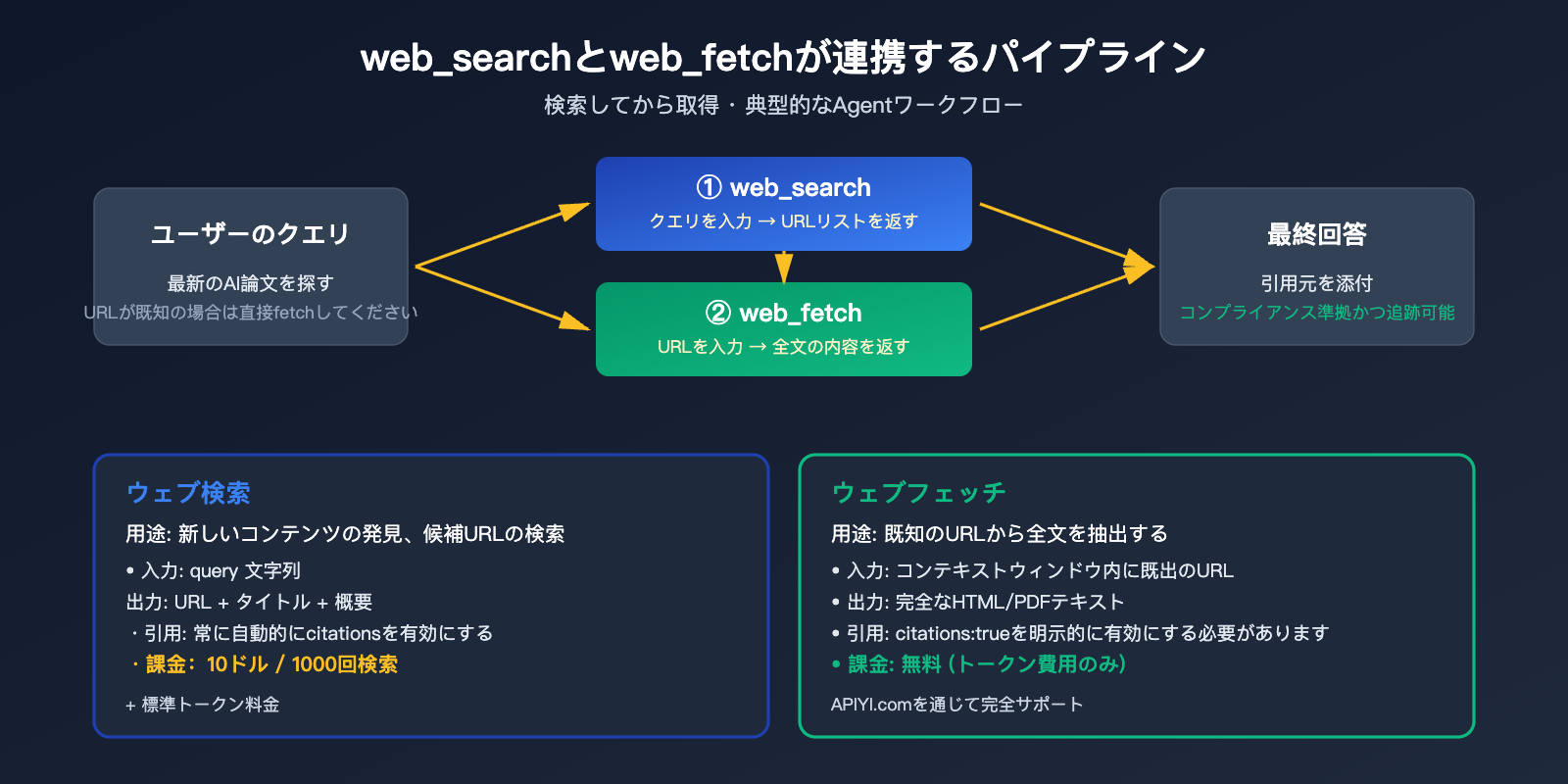
| ツール | 用途 | 入力 | 出力 | 課金 |
|---|---|---|---|---|
web_search |
新規情報の発見 | クエリ文字列 | URL + タイトル + 概要 | $10 / 1000回 |
web_fetch |
特定URLの全文取得 | URL文字列 | 完全なHTML/PDFテキスト | 無料 (トークン課金のみ) |
🎯 アーキテクチャのヒント: 一般的なエージェントのワークフローは「まず検索し、次に取得する」という流れです。
web_searchで候補ページを見つけ、web_fetchで最も関連性の高いページの全文を読み込みます。ユーザーがすでにURLを指定している場合(例:「example.com/article の記事を分析して」)は、検索枠を消費せずに直接web_fetchを使用してください。APIYI (apiyi.com) では、これら両方のツールが透過的にサポートされており、追加設定は不要です。
web_search ツールの完全なパラメータ定義
以下の表は公式のJSONパラメータ説明です。用途に合わせて組み合わせてください。
| パラメータ | 型 | 必須 | デフォルト | 説明 |
|---|---|---|---|---|
type |
string | ✅ | – | web_search_20250305 または web_search_20260209 に固定 |
name |
string | ✅ | – | web_search に固定 |
max_uses |
integer | ❌ | 無制限 | 1回のリクエストで許可される最大検索回数 |
allowed_domains |
string[] | ❌ | – | 指定ドメインの結果のみ許可(blockedと排他) |
blocked_domains |
string[] | ❌ | – | 指定ドメインの結果を禁止 |
user_location |
object | ❌ | – | ローカライズ検索のためのユーザーのおおよその位置情報 |
user_location のフィールド構造:
{
"type": "approximate",
"city": "Shanghai",
"region": "Shanghai",
"country": "CN",
"timezone": "Asia/Shanghai"
}
Claude API ネット検索のエラー処理
検索が失敗した場合でも、Anthropic API は HTTP 200 を返します。エラー情報はレスポンスボディの web_search_tool_result 内に埋め込まれます。クライアント側のコードで以下のエラーコードを識別するようにしてください。
| エラーコード | 意味 | 対処法 |
|---|---|---|
too_many_requests |
レート制限超過 | バックオフ再試行、並列数を下げる |
max_uses_exceeded |
max_uses 制限超過 |
上限を引き上げるかリクエストを分割 |
query_too_long |
クエリ文字列が長すぎる | クエリを短縮または書き直す |
invalid_input |
パラメータ形式エラー | JSON構造を確認 |
unavailable |
Anthropic 内部エラー | 少し時間を置いて再試行 |
⚠️ 課金に関する注意: エラーとなった
web_searchリクエストは課金されません。ただし、一度成功した検索の後に失敗した場合、先行した成功分は $10 / 1000回 のレートで課金されます。APIYI (apiyi.com) のコンソールで詳細なリクエスト明細を確認し、異常な消費がないかチェックすることをお勧めします。
Claude API ネット検索のクイックスタート
最小限のコードで一連のフローを実行してみましょう。すべての例で APIYI (apiyi.com) の透過的な転送インターフェースを使用します。ビジネスロジックを変更する必要はなく、base_url を中継ノードに向け、ANTHROPIC_API_KEY を APIYI のキーに置き換えるだけです。
cURL による最小構成例
Claude API ネット検索を実行する最小限のリクエスト例です:
curl https://vip.apiyi.com/v1/messages \
-H "x-api-key: $APIYI_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "2026年4月にOpenAIが発表した最新モデルについて中国語でまとめて"}
],
"tools": [{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5
}]
}'
レスポンスには、Claudeの思考テキスト、server_tool_use(実行されたクエリ)、web_search_tool_result(URLリスト)、および最終的な citations(引用)付きの回答が含まれます。
Python SDK 完全な例 (web_fetch との併用)
import anthropic
client = anthropic.Anthropic(
base_url="https://vip.apiyi.com",
api_key="sk-your-apiyi-key",
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "最近1ヶ月のAIエージェント評価に関する論文を探し、最も関連性の高い1本を詳細に要約してください"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search"
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
for block in response.content:
if block.type == "text":
print(block.text)
elif block.type == "server_tool_use":
print(f"[ツール呼び出し] {block.name}: {block.input}")
🎯 コードのヒント: 上記では
web_search_20260209とweb_fetch_20260209の動的フィルタリングを組み合わせており、Claude Opus 4.7 を使用することで長文ドキュメントにおけるトークン消費を大幅に削減できます。シンプルなリアルタイム回答が必要な場合は、モデルをclaude-sonnet-4-6に変更し、基本的なweb_search_20250305を使用すればコストを抑えられます。すべての呼び出しは APIYI (apiyi.com) 経由で転送され、安定性は公式と同等です。
TypeScript / Node.js の例
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
baseURL: "https://vip.apiyi.com",
apiKey: process.env.APIYI_API_KEY,
});
const response = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 2048,
messages: [
{ role: "user", content: "今日の上海の天気はどうですか?" }
],
tools: [{
type: "web_search_20250305",
name: "web_search",
max_uses: 3,
user_location: {
type: "approximate",
city: "Shanghai",
region: "Shanghai",
country: "CN",
timezone: "Asia/Shanghai"
}
}]
});
console.log(response.content);
ストリーミングレスポンスの処理
stream: true を有効にすると、検索プロセスが SSE イベントとしてリアルタイムにプッシュされます。検索実行中は一時的に「停止」状態になります。これは Claude が Anthropic サーバー側での検索完了を待機しているためです。
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=[{"role": "user", "content": "最新の Claude 4.7 の価格を調べて"}],
tools=[{"type": "web_search_20250305", "name": "web_search", "max_uses": 2}]
) as stream:
for event in stream:
if event.type == "content_block_start":
block = event.content_block
if block.type == "server_tool_use":
print(f"\n[検索中] クエリのストリーミング返信を開始します...")
elif block.type == "web_search_tool_result":
print(f"[検索完了] {len(block.content)} 件の結果が見つかりました")
elif event.type == "content_block_delta":
if hasattr(event.delta, "text"):
print(event.delta.text, end="", flush=True)
Claude API Web検索のソリューション比較と選定
公式インターフェースの仕様を理解したところで、選定の意思決定に戻りましょう。Claude APIのWeb検索には、実際には3つの選択肢があり、それぞれ適したシナリオが異なります。

ソリューション A: 公式ネイティブ web_search(推奨)
メリット:
- 運用不要: 自前サーバー構築不要、Anthropicによる完全管理
- 自動引用: 回答ごとに
citationsが自動付与され、信頼性が高い - モデル一体化: Claudeが自律的に検索のタイミングや内容を判断
- 課金が透明: 1,000回あたり10ドルで、Anthropicの請求に統合
デメリット:
- Anthropicがインデックスするソースのみ対応(検索エンジンを自由に切り替え不可)
- 一部のモデルバージョンで制限あり(Haikuや旧版Sonnetは基本機能のみ)
適したシナリオ: 90%の汎用的な対話型エージェント、Q&Aアシスタント、リサーチタスク。
ソリューション B: サードパーティ製 MCP サービス (Brave/Tavily/Serperなど)
Model Context Protocol を通じてローカルまたはリモートのMCPサーバーを起動し、Claudeに検索能力を注入します。
# Tavily MCPの例(事前に npm install -g @tavily/mcp-server が必要)
claude mcp add tavily-search npx -- @tavily/mcp-server
メリット:
- 検索バックエンドを自由に選択可能(プライバシー重視のBrave、LLMフレンドリーなTavilyなど)
- カスタマイズ可能: 結果の二次クリーニングやメタデータの付与が可能
- Claude Code、Cursorなどのクライアントでネイティブサポート
デメリット:
- MCPサーバープロセスの追加運用が必要
- 検索結果がAnthropic仕様の
citationsを自動生成しない - サードパーティ検索APIの枠や課金を自分で管理する必要がある
適したシナリオ: すでにBraveやTavilyの法人アカウントを保有している、または検索バックエンドに強いカスタマイズ要件がある場合。
ソリューション C: 自作ツール呼び出し (Google CSE + カスタムツール)
最も伝統的な手法です。独自の tool を定義し、バックエンドコードでGoogle Custom SearchやBing APIを呼び出し、結果を messages に戻します。
tools = [{
"name": "google_search",
"description": "Google検索を実行し、上位N件の結果を返す",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
}]
メリット: 完全な制御が可能。社内イントラネット検索やプライベート知識ベースへの接続が可能。
デメリット: プロンプト設計、結果の並び替え、引用生成、エラー時のリトライ処理など、すべての作業負荷を自分で負担する必要がある。また、Claudeが「自動的」に呼び出すわけではないため、システムプロンプトでの明示的な誘導が必要。
適したシナリオ: 高いコンプライアンス要件、高度なカスタマイズ、プライベートデータソースへの接続が必要なエンタープライズ向けシナリオ。
3つのソリューションの意思決定ツリー
| ニーズ | 推奨ソリューション |
|---|---|
| とにかく早く実装したい、機能は標準で十分 | ソリューション A ネイティブ web_search |
| 検索バックエンドを切り替えたい (プライバシー/コンプライアンス) | ソリューション B サードパーティ MCP |
| プライベートデータソースへの接続が必須 | ソリューション C 自作ツール + RAG |
| 国内からのAnthropicアクセスが不安定 | ソリューション A + APIYI apiyi.com 透明転送 |
🎯 国内開発者へのヒント: Anthropic公式APIは国内からのアクセスが不安定な場合があり、海外の電話番号による登録が必要です。APIYI apiyi.com の透明転送経由での接続をお勧めします。これはAnthropicのすべてのServer Tool(
web_search/web_fetch/code_executionを含む)を完全に透過的に転送するため、コードを一切変更せず、base_urlをhttps://vip.apiyi.comに変更し、api_keyをAPIYIのキーに差し替えるだけで利用可能です。
title: Claude API ネットワーク検索の高度な活用テクニック
description: Claude APIのネットワーク検索機能を使いこなすための高度な設定、ドメイン制限、コンテキスト維持のコツを解説。APIYIを活用した実戦的なシナリオも紹介します。
Claude API ネットワーク検索の高度な活用テクニック
ドメインホワイトリスト:効率的な「垂直検索」
Claude に特定のドメイン内だけで検索させたい場合は、allowed_domains を使用します。
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"docs.python.org",
"pypi.org",
"github.com"
]
}]
いくつかの注意点があります:
allowed_domainsとblocked_domainsは同時に使用できません。- サブドメインは完全一致で判定されます:
docs.example.comを指定してもapi.example.comは含まれません。 - リクエストレベルのドメイン制限は、組織レベルの設定と互換性がある必要があり、組織管理者が設定した範囲を拡大することはできません。
web_fetch 引用機能の有効化
web_search はデフォルトで引用(citations)が有効ですが、web_fetch は明示的に有効化する必要があります。
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 50000
}
max_content_tokens は巨大なドキュメントを切り詰めるために使用し、一度のフェッチでコンテキストウィンドウを圧迫するのを防ぎます。目安は以下の通りです:
| コンテンツタイプ | サイズ | 推定トークン数 |
|---|---|---|
| 一般的なWebページ | 10 KB | 約 2,500 |
| 大規模ドキュメント | 100 KB | 約 25,000 |
| 研究論文 PDF | 500 KB | 約 125,000 |
マルチターン対話における encrypted_content
web_search が返す各結果には encrypted_content フィールドが含まれています。マルチターン対話で Claude が以前の検索結果を継続して引用できるようにするには、このフィールドをそのまま送り返す必要があります。そうしないと、後続のターンで引用コンテキストが失われてしまいます。
messages.append({
"role": "assistant",
"content": previous_response.content # encrypted_content を含む全文を保持
})
messages.append({
"role": "user",
"content": "先ほど検索した2番目の記事について、詳細に分析してください"
})
🎯 エンジニアリングのヒント: LangChain や LlamaIndex などのエージェントフレームワークに組み込む際は、Claude のレスポンスに含まれるすべてのコンテンツブロックが正しく透過されているか確認してください。多くのフレームワークは
server_tool_useなどのフィールドを「クリーニング」してしまい、引用が機能しなくなることがあります。公式の挙動と完全に一致させるため、APIYI (apiyi.com) を通じて Anthropic SDK を直接利用することを推奨します。
Claude API ネットワーク検索の実践的なシナリオ
理論を理解したところで、実際のビジネスシーンにおける Claude API ネットワーク検索 のベストプラクティスをいくつか見ていきましょう。
シナリオ1:リアルタイムニュース回答アシスタント
「今日の株価はどうなっている?」といった質問にはリアルタイムデータが必要です。設定戦略は以下の通りです:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system="あなたは金融アシスタントです。リアルタイムの相場やニュースに関わる場合、必ず web_search を使用してください。回答には必ず引用を付けてください。",
messages=[{"role": "user", "content": "今日の上海総合指数の終値はいくらですか?値動きはどうでしたか?"}],
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 3,
"allowed_domains": ["sina.com.cn", "eastmoney.com", "163.com"],
"user_location": {
"type": "approximate",
"country": "CN",
"timezone": "Asia/Shanghai"
}
}]
)
ポイント: allowed_domains で信頼できる金融サイトを固定し、user_location を設定することで、Claude が優先的に中国語の結果を返すようにします。
シナリオ2:技術ドキュメントの RAG 強化
技術的な質問に答える際、公式ドキュメントを優先的に検索させます:
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "FastAPI で WebSocket のハートビートによる接続維持を実装するには?完全なサンプルコードをください"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"fastapi.tiangolo.com",
"docs.python.org",
"github.com",
"stackoverflow.com"
]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
ポイント: web_search_20260209 の動的フィルタリングで不要な HTML を除外し、web_fetch で最も関連性の高い公式ドキュメントの全文を取得します。
シナリオ3:学術研究アシスタント
厳密な引用と長いコンテキスト分析が必要なシナリオでは、Opus 4.7 とデュアルツールの組み合わせが推奨されます:

response = client.messages.create(
model="claude-opus-4-7",
max_tokens=8192,
messages=[{
"role": "user",
"content": "2026年のLLMエージェントの安全性評価に関する論文を検索し、トップ3を比較分析してください"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 8,
"allowed_domains": ["arxiv.org", "openreview.net", "acm.org"]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 80000
}
]
)
🎯 シナリオ別のアドバイス: ビジネスごとに検索品質、引用のコンプライアンス、コストの優先順位は異なります。APIYI (apiyi.com) では、ビジネスシナリオごとに個別の API キーを作成することをお勧めします。これにより、すべての呼び出しを混在させるのではなく、シナリオごとに課金データの分割や、実際の検索回数とトークン消費量の監視が容易になります。
Claude API ネット検索のエンジニアリングにおけるベストプラクティス
デモを動かすのは簡単ですが、Claude API のネット検索機能を本番環境で本格的に運用するには、いくつか乗り越えるべきハードルがあります。
実践1: プロンプトキャッシュによるコスト削減と効率化
Server Tool の定義は簡潔ですが、システムプロンプトと組み合わせると、依然として無視できない固定コストが発生します。プロンプトキャッシュを有効にしましょう:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[{
"type": "text",
"text": "あなたはプロの研究アシスタントです...(以下、500文字のシステムプロンプトを省略)",
"cache_control": {"type": "ephemeral"}
}],
messages=[...],
tools=[
{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"cache_control": {"type": "ephemeral"}
}
]
)
実測値:5分以内の重複リクエストにおいて、システムプロンプトとツール部分のトークンコストを90%削減可能です。
実践2: ストリーミングレスポンスによるタイムアウト回避
web_search は1回の実行に5〜15秒かかる場合があります。もし下流(ゲートウェイやクライアント)に30秒のタイムアウト制限がある場合は、必ず stream=True を有効にし、ストリーミングによるハートビートで接続を維持してください。
実践3: encrypted_content のマルチターンにおける一貫性
マルチターン対話において、Claude は過去の検索結果を参照することがあります。リクエストごとに、過去のすべてのアシスタントメッセージの content 配列全体を保持する必要があります。text 部分だけを保持してはいけません:
# ❌ 間違った方法
messages.append({"role": "assistant", "content": response.content[-1].text})
# ✅ 正しい方法
messages.append({"role": "assistant", "content": response.content})
実践4: レート制限とリトライ戦略
web_search のレート制限は、通常のメッセージAPIとは独立しています。SDK層で指数バックオフを伴うリトライロジックを実装することを推奨します:
| エラーコード | リトライ戦略 | 最大リトライ回数 |
|---|---|---|
too_many_requests |
指数バックオフ (2秒/4秒/8秒) | 3 |
unavailable |
固定遅延 (5秒) | 2 |
max_uses_exceeded |
リトライしない、max_usesを増やす | – |
query_too_long |
リトライしない、クエリを短縮する | – |
🎯 本番環境へのアドバイス:
web_searchのすべてのエラーレスポンスをログ監視システムに記録し、too_many_requestsの割合を定期的に分析してください。これは現在の同時実行数が拡張を必要としているかを判断する重要な指標です。APIYI (apiyi.com) プラットフォームで呼び出す場合は、コントロールパネルからリクエスト成功率や平均応答時間などの重要指標を直接確認できるため、運用が非常に楽になります。
Claude API ネット検索に関するFAQ
Q1: APIYI のAPI中継サービスはネイティブの web_search に対応していますか?コードの変更は必要ですか?
対応しており、コードの変更も不要です。APIYI (apiyi.com) は透過的転送アーキテクチャを採用しており、Anthropic 公式のすべての Server Tool を完全にパススルーします。base_url を https://vip.apiyi.com に変更し、api_key を APIYI のキーに差し替えるだけで、公式APIを呼び出す既存のコードがそのまま動作します。これには web_search / web_fetch / code_execution などのすべてのネイティブツールが含まれます。
Q2: web_search の課金体系はどうなっていますか?10ドル/1000回は高いですか?
検索1回につき0.01ドルで、結果が何件返ってきても1回とカウントされます。失敗した検索は課金されません。他社比較:Tavilyは0.005ドル/回、Braveは0.006ドル/回、Google CSEは0.005ドル/クエリ(無料枠超過後)。ネイティブの web_search はやや割高ですが、MCPサーバーの運用保守や引用のコンプライアンス対応といったエンジニアリングコストを削減できるため、中小規模のチームにとってはトータルで見てより経済的です。
Q3: なぜリクエストで max_uses_exceeded エラーが出るのですか?
Claude は1回の対話の中で web_search を複数回呼び出すことがあります(自律的に判断して検索回数を決定します)。もし "max_uses": 1 に設定していて、回答のために3回の検索が必要な場合、このエラーが発生します。複雑な質問には5〜10回の予算を与え、単純な質問には1〜2回に留めることを推奨します。
Q4: web_search は日本語のウェブサイトを検索できますか?
可能です。web_search の基盤は Anthropic のリアルタイムインデックスであり、日本語コンテンツのカバー率も良好です(WeChat公式アカウント、知乎、CSDNなどを含む)。特定の日本語サイトのみに限定したい場合は、allowed_domains ホワイトリストと組み合わせて使用してください。
Q5: web_search で長文のリサーチを行うとトークン消費が激しいのですが、最適化できますか?
3つの最適化の方向性があります:
web_search_20260209の動的フィルタ版(Claude Opus/Sonnet 4.6以降が必要)を使用し、無関係な断片を自動的に除外する。web_fetchのmax_content_tokensパラメータを併用し、1ページあたりの取得上限を制限する。- プロンプトキャッシュを有効にし、ツール定義とシステムプロンプトをキャッシュして、重複リクエストのコストを削減する。
Q6: サードパーティの MCP 検索ソリューションとネイティブの web_search を併用できますか?
可能です。Claude は複数のツールを同時に定義できますが、ツールの説明文で違いを明確にすることに注意してください。例えば、MCPの tavily_search を「学術論文の検索」、ネイティブの web_search を「一般的なウェブページの検索」と記述すれば、Claude は説明に基づいて自律的に選択します。ただし、曖昧さを避けるため、単一のシナリオでは単一の検索ツールを使用することを推奨します。
Q7: 中国国内から Claude API のネット検索を呼び出すと失敗しますが、どうすればいいですか?
主な原因は2つあります:Anthropic API への直接接続が不安定であること、および web_search 実行時に Anthropic のバックエンドが中国大陸のIPを遮断する可能性があることです。最も直接的な解決策は、APIYI (apiyi.com) を介した中継です。すべての web_search リクエストは APIYI の海外ノードを経由して Anthropic に転送され、レスポンスが国内に返されるため、海外からの直接接続と同等の安定性を確保できます。
Claude API インターネット検索ソリューションのまとめと選定アドバイス
本記事を振り返ると、Claude API のインターネット検索機能は 2026 年現在、「箱から出してすぐ使える」レベルまで成熟しています。結論をひとことで言うと:
✅ プロジェクトの 80% は公式のネイティブ機能
web_searchで十分です。設定が簡単で、引用も正確、かつ Anthropic による保守も万全です。残りの 20% の高度なカスタマイズが必要なケースにおいてのみ、サードパーティの MCP や自作ツールを検討しましょう。
実装チェックリスト
今日から Claude API のインターネット検索をプロジェクトに導入するなら、以下の手順で進めてください:
- モデルの選択: 一般的な用途には
claude-sonnet-4-6(コストパフォーマンス重視)、複雑な調査にはclaude-opus-4-7を推奨します。 - ツールバージョンの選択: 基本は
web_search_20260209(動的フィルタリング対応)を優先し、古いモデルを使用する場合はweb_search_20250305にフォールバックしてください。 - max_uses の設計: シンプルな質問には 1〜3 回、複雑な調査には 5〜10 回の検索回数を設定します。
- web_fetch との併用: 全文解析が必要な場合は、
web_fetchを組み合わせて候補ページのコンテンツを抽出しましょう。 - アクセス設定: 国内(日本)からは APIYI (apiyi.com) を通じて透過的に転送できるため、VPN は不要で、コードの修正も最小限で済みます。
🎯 最後のアドバイス: Claude API インターネット検索の鍵は「使えるかどうか」ではなく、「検索結果の品質、トークンコスト、応答遅延の 3 つをいかにバランスさせるか」にあります。まずは APIYI (apiyi.com) プラットフォームで実際の業務シナリオをいくつか試し、1 回の対話あたりの実際の検索回数とトークン消費量を計測してから、プロンプトキャッシングや動的フィルタリングなどの高度な最適化を導入することをお勧めします。同プラットフォームは Claude の全モデルとネイティブ Server Tool に対応しており、迅速なイテレーションが可能です。
著者: APIYI 技術チーム | Claude API の実践的なチュートリアルは help.apiyi.com をご覧ください。