Если вы используете API для генерации изображений через Gemini 3 Pro Image и выводите пользователю самое первое изображение, которое возвращает модель, результат часто выглядит странно: «кривая» композиция, нечеткие детали или вовсе обрезанное полотно. Это происходит не из-за снижения качества работы самой модели, а из-за того, что вы выбираете не то изображение. Скорее всего, первое изображение — это лишь «черновик» модели, а финальный результат находится в последнем элементе ответа.
В этой статье мы подробно разберем механизм «мышления» изображений в Gemini 3, основываясь на официальной документации Google. Объясним, почему вызов модели может возвращать 2–3 изображения, как с помощью поля part.thought и сигнатуры thought_signature точно идентифицировать финальный результат, а также приведем примеры кода на Python, Node.js и cURL. Все примеры работают через сервис-прокси API APIYI (apiyi.com) — сервис-прокси полностью сохраняет исходную структуру ответа Gemini, поэтому разработчикам нужно просто следовать официальным правилам обработки данных.
Принцип работы механизма «мышления» Gemini 3
Прежде чем переходить к коду, давайте разберемся, почему один вызов может возвращать несколько изображений.
Почему «мышление» Gemini 3 нельзя отключить
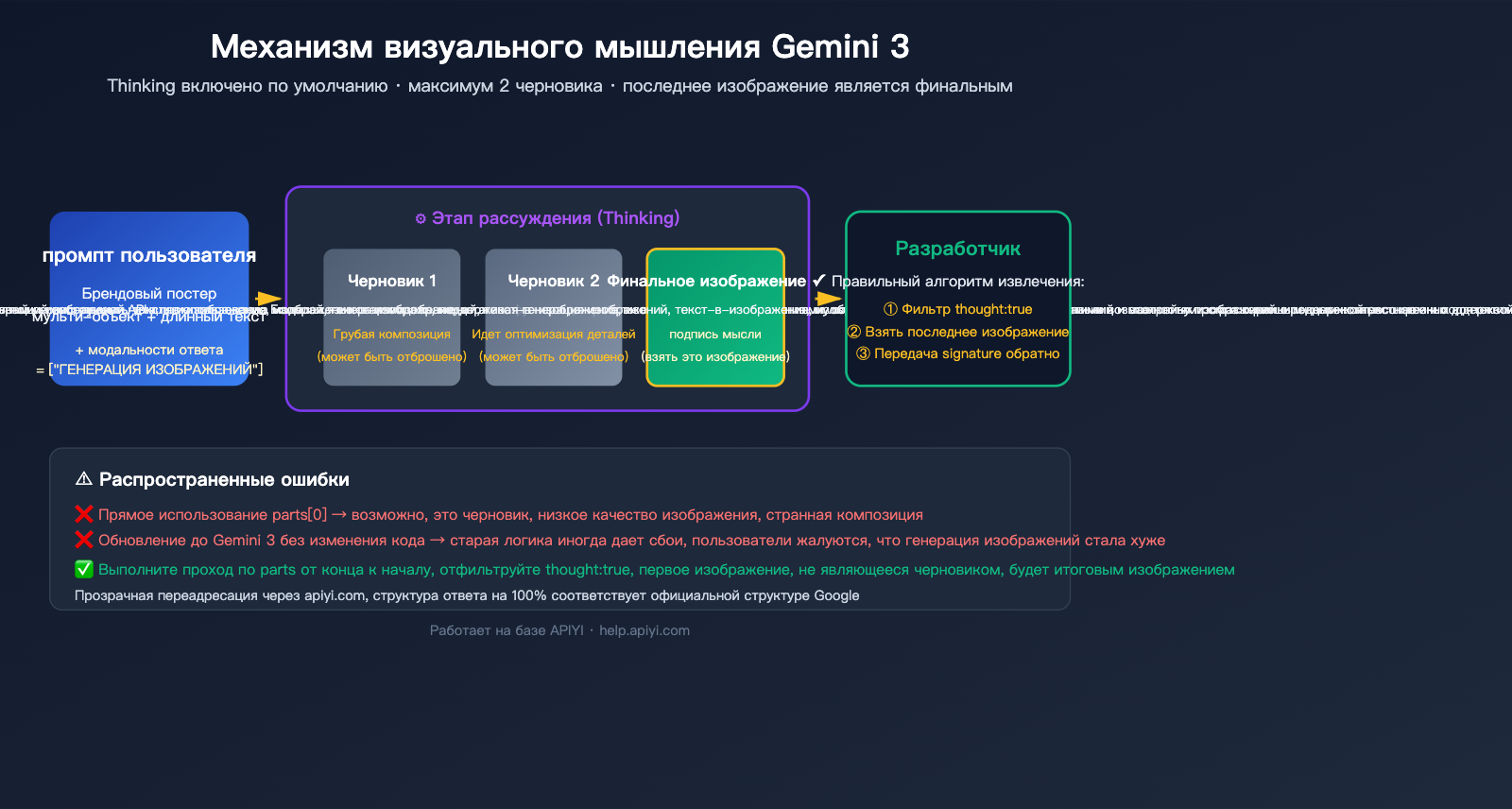
В модели gemini-3-pro-image-preview (коммерческое название Nano Banana Pro) Google внедрила механизм «мышления» (Thinking), аналогичный текстовым моделям Gemini. Прежде чем выдать итоговое изображение, модель создает до 2 промежуточных изображений, чтобы протестировать композицию, верстку и рендеринг текста — прямо как дизайнер, который сначала делает наброски, а затем чистовой вариант.
Официальная документация выделяет три ключевых факта:
| Факт | Пояснение |
|---|---|
| Включено по умолчанию | Функция Thinking принудительно включена на уровне API, параметров для отключения нет |
| До 2 черновиков | Модель может создать до 2 пробных изображений, но не обязательно каждый раз |
| Последнее — финальное | Именно последнее изображение в цепочке «мышления» является конечным результатом |
| Оплата за токены мышления | Даже если вы не запрашиваете сами мысли, токены «мышления» расходуются и оплачиваются |
Иными словами, получение нескольких изображений — это норма, а не баг. Суть не в том, чтобы «отключить» функцию, а в том, чтобы правильно выбрать финальный результат.
🎯 Архитектурный взгляд: Механизм мышления Gemini 3 при генерации изображений использует тот же движок, что и текстовые модели Gemini 3 Pro. Это объясняет, почему Nano Banana Pro значительно лучше справляется с рендерингом длинного текста и сохранением согласованности лиц по сравнению с Nano Banana предыдущих версий. При использовании сервиса-прокси API APIYI (apiyi.com) все процессы «мышления» идентичны прямому подключению к Google; слой прокси не удаляет никаких данных о процессе мышления.
Разбор типичных ошибок пользователей
Типичная ошибка в сообществе выглядит так:
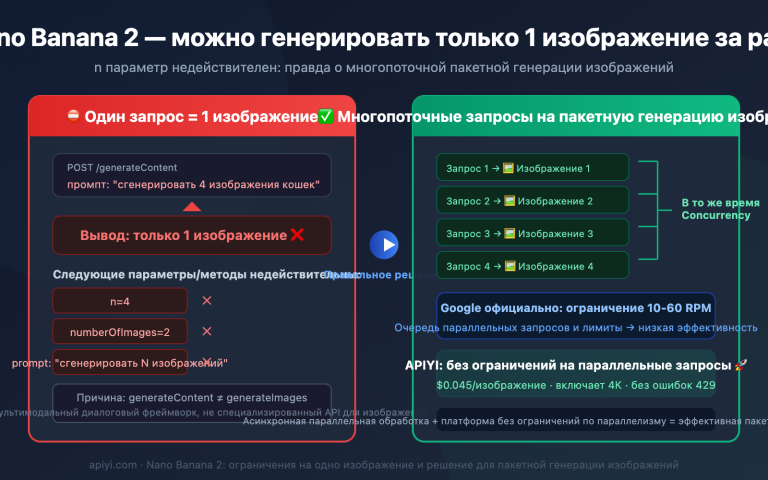
Вызов API → Получение ответа → В ответе массив parts → Берем parts[0] с изображением → Отображаем пользователю
Этот псевдокод отлично работал в старой версии Nano Banana (Gemini 2.5 Flash Image), так как она возвращала только одно изображение. После перехода на Gemini 3 Pro Image тот же код принимает «черновик» за готовый продукт, и в итоге пользователь видит «полуфабрикат», который не соответствует промпту или имеет странную композицию.
Эта проблема коварна, потому что:
- Проявляется не всегда: При простых промптах модель может не запускать процесс «мышления» и вернуть одно изображение.
- Ошибок нет: Структура ответа корректна, обращение к
parts[0]не вызывает исключений. - Есть результат: Пользователь думает, что модель «плохая», хотя на деле просто выбрано не то изображение.
Подробный разбор структуры ответов при генерации изображений в Gemini 3
Чтобы правильно обрабатывать ответы, нужно четко понимать, что именно может вернуться после вызова API.
Массив parts в полном ответе API
Когда в Gemini 3 Pro Image срабатывает механизм «мышления» (thinking), массив response.candidates[0].content.parts может выглядеть примерно так:

candidates[0].content.parts = [
{ text: "Я должен обдумать композицию...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // черновик 1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // черновик 2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } // финальное изображение
]
Неправильное понимание этого массива — главная причина багов. Запомните эти 3 правила, чтобы писать надежный код.
3 официальных признака финального изображения
Google выделил три признака, по которым можно распознать итоговый результат. Используйте их в порядке приоритета:
| Приоритет | Признак | Описание | Надежность |
|---|---|---|---|
| ★★★ | part.thought === false (или поле отсутствует) |
Явно помечен как не часть процесса мышления | Высочайшая |
| ★★ | Наличие поля thought_signature |
Есть только у финального изображения | Высокая |
| ★ | Последний inline_data в массиве |
Официальная документация подтверждает: «последний — это финал» | Резервный |
Лучший подход — комбинировать: сначала проверяем поле thought, если его нет — ищем thought_signature, и в крайнем случае берем последний inline_data.
Различия в thinking_level у Gemini 3.1 Flash Image
Важно помнить, что поведение разных моделей может отличаться:
| Модель | Мышление (default) | Настройка thinking_level | Сценарии |
|---|---|---|---|
gemini-3-pro-image-preview |
Включено всегда | ❌ Нельзя менять | Высокая точность, профессиональные задачи |
gemini-3-flash-image |
minimal | ✅ minimal / high | Интерактивы, массовая генерация |
gemini-2.5-flash-image |
нет | — | Старая версия |
В Gemini 3.1 Flash можно вручную повысить уровень мышления для более детальной проработки или снизить до «minimal» для скорости — в версии Pro такой гибкости нет.
🎯 Совет по выбору: Если вы делаете генерацию изображений для обычных пользователей, рекомендуем использовать
gemini-3-flash-image+thinking_level=minimal(быстрее и дешевле). А если пользователь переключается в «режим высокого качества» — активируйтеgemini-3-pro-image-preview(для глубокого анализа и точности). На платформе APIYI (apiyi.com) вы можете бесшовно переключаться между ними, используя один и тот же API-ключ и базовый URL.
Код для корректной обработки мышления Gemini 3
Теперь к практике. Примеры ниже основаны на прозрачном проксировании через APIYI — если вы уже писали код для Google AI Studio, просто замените base_url на адрес APIYI и вставьте свой ключ, остальное останется прежним.
Правильный вариант на Python SDK
from google import genai
client = genai.Client(
api_key="sk-your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Сиба-ину в стиле киберпанк под неоновой вывеской, 4K",
config={"response_modalities": ["IMAGE"]}
)
# ✅ Правильно: фильтруем все thought parts, сохраняем только финал
for part in response.parts:
if getattr(part, "thought", False):
continue # пропускаем черновики мышления
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("final_output.png")
break # первое не «мыслительное» изображение — это финал
Антипаттерн (типичная ошибка):
# ❌ Ошибка: берем первый попавшийся part, это может быть черновик
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# На выходе может оказаться полуфабрикат
Правильный вариант на Node.js / TypeScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "Сиба-ину в стиле киберпанк под неоновой вывеской, 4K",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ Идем с конца: первое изображение без флага thought — искомое
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
Версия через cURL + jq
Если вы вызываете API через shell-скрипт, используйте фильтрацию с помощью jq:
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "Сиба-ину в стиле киберпанк"}]
}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
Это выражение jq делает три вещи: отфильтровывает thought: true, оставляет только mime-типы изображений и берет last (последнее), что идеально соответствует официальным правилам.
🎯 Чек-лист для ревью: При проверке кода всегда смотрите, есть ли фильтрация по
thought. Лучше всего вынести логику в единую функцию-утилитуextractFinalImage(), чтобы вся команда использовала её для обработки ответов. При работе через APIYI вы можете протестировать этот код локально, а затем сразу пушить в продакшн.
Продвинутые аспекты генерации изображений в Gemini 3
В многоходовом редактировании необходимо передавать thought_signature
Nano Banana Pro поддерживает «последовательное редактирование» — например, когда пользователь сначала просит «замени фон на морской», а затем — «сделай выражение мордочки собаки более радостным». Однако есть важный нюанс: официальные требования обязывают передавать thought_signature из предыдущего шага в последующих итерациях диалога. В противном случае модель теряет контекст рассуждений, и качество генерации заметно падает.
Правильный подход для многоходового взаимодействия:
# Первый шаг
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Сиба-ину бежит по парку"
)
# Извлекаем объект part (содержащий thought_signature) для итогового изображения
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# Второй шаг: добавляем весь объект final_part обратно в историю
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "Сиба-ину бежит по парку"}]},
{"role": "model", "parts": [final_part]}, # Здесь содержится thought_signature
{"role": "user", "parts": [{"text": "Замени фон на морской закат"}]}
]
)
Просмотр процесса рассуждений (для отладки)
Если вы хотите заглянуть «под капот» и увидеть, как именно модель «думала», включите include_thoughts:
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Сложный промпт для рекламного постера бренда...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# Выводим процесс размышлений
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[Размышление] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"draft_{id(part)}.png") # Сохраняем черновик
Это очень полезно при отладке: если результат далек от идеала, изучение черновиков поможет понять, какую именно часть промпта модель интерпретировала неверно.

Логика биллинга thinking-токенов
Разработчикам стоит обратить особое внимание на то, как тарифицируется Gemini 3 Pro Image:
| Тип токена | Цена (за 1 млн) | Обязательно к генерации? |
|---|---|---|
| Входной промпт | $2 | ✅ Да |
| Выход (изображение/текст) | $12 | ✅ Да |
| Thinking reasoning | Включается в выходные токены | ✅ Обязательно, нельзя отключить |
Это означает, что даже если вам нужно только итоговое изображение и вас не интересует процесс «рассуждений», токены размышлений (thinking tokens) все равно будут создаваться и оплачиваться. Вы можете сэкономить только на передаче текста размышлений обратно себе (параметр include_thoughts), но не на самом факте их генерации.
🎯 Советы по оптимизации расходов: для простых задач (генерация изображений товаров, иллюстраций) используйте
gemini-3-flash-image+thinking_level=minimal— это будет стоить заметно дешевле версии Pro. Модель Pro стоит подключать только для сложных задач (поддержание согласованности лиц у персонажей, сложная рендеринг текста). Рекомендуем при вызове через APIYI (apiyi.com) отслеживать потребление, чтобы сравнить соотношение цена/качество в ваших сценариях, прежде чем переходить к продакшн-конфигурации.
Практика отладки «мышления» при генерации изображений в Gemini 3
Проблема 1: Постоянно получаю изображения низкого качества
Шаги для диагностики:
# Вывод поля thought для всех parts
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"Part {i}: thought={is_thought}, image={has_image}, signature={has_sig}")
Если в выводе есть несколько parts с image=True, значит, вы столкнулись с типичной ситуацией «возврата нескольких изображений». Проверьте, не берет ли ваш код первый попавшийся part по индексу.
Проблема 2: В структуре ответа отсутствует поле thought
Возможная причина: Вы используете «сырой» JSON от REST API. Имена полей записаны в camelCase (thought), но в некоторых версиях SDK они могли быть преобразованы в snake_case. Нужно поддерживать оба варианта:
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
Проблема 3: Нужно сохранить все изображения (для отладки)
Рекомендуемый официальный способ обхода всех элементов:
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "draft" if is_draft else "final"
filename = f"gemini_output_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"Сохранено: {filename}")
Адаптация «мышления» Gemini 3 под реальные бизнес-задачи
Помимо теории и базового кода, есть нюансы, которые важно учитывать в разных сценариях.
Сценарий 1: Отображение сгенерированного изображения во фронтенде
Фронтенд должен преобразовывать base64 в формат data:image/png;base64,xxx. Важно: не фильтруйте thought на фронтенде — пусть бэкенд возвращает уже «чистый» результат. Иначе фронтенду придется вникать в структуру ответа Gemini:
// ❌ Не рекомендуется: фронтенд сам обрабатывает сырой ответ Gemini
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ Рекомендуется: бэкенд выполняет фильтрацию, фронтенд получает готовое изображение
// Бэкенд API возвращает: { "image": "base64-string" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
Сценарий 2: Генерация + сохранение в OSS / CDN
При пакетной генерации сохраняйте файлы в объектное хранилище с использованием хеша, чтобы избежать дубликатов:
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
Обязательно загружайте только финальное изображение, черновики «мышления» будут засорять хранилище и тратить ваш бюджет.
Сценарий 3: Правильная обработка потоковых (streaming) ответов
Gemini 3 поддерживает стриминг: черновики «мышления» приходят первыми, финальное изображение — в конце. В потоковом режиме рекомендуется использовать логику «перезаписи по мере поступления»:
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # Пропускаем черновики
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # Перезаписываем, оставляем последнее
🎯 Оптимизация стриминга: для улучшения пользовательского опыта можно отправлять черновики «мышления» на фронтенд для отображения «превью загрузки», а затем заменять их финальным результатом. Такой «постепенный рендеринг» очень популярен в B2C-продуктах. APIYI apiyi.com полностью поддерживает протокол SSE для Gemini, поэтому фронтенд будет работать так же, как при прямом подключении.
Gemini 3: визуальное мышление и связь с бизнес-метриками
Количественные показатели роста качества
Согласно официальным данным Google и тестам сообщества, активация функции «мышления» (thinking) значительно повышает качество генерации изображений:
| Показатель | Gemini 2.5 Flash Image | Gemini 3 Pro Image (thinking) | Прирост |
|---|---|---|---|
| Точность рендеринга длинного текста | ~70% | ~95% | +35% |
| Согласованность лиц (5 человек) | ~60% | ~90% | +50% |
| Следование сложным композициям | ~75% | ~92% | +22% |
| Уровень использования первого изображения | ~80% | ~95% | +18% |
Цена вопроса — увеличение времени отклика на 40–80% и рост стоимости токенов на 20–40%. Стоит ли оно того? Зависит от вашего бизнес-сценария:
- Профессиональный дизайн и рекламные материалы: прирост качества значительно перевешивает затраты, настоятельно рекомендуется.
- UGC, массовый контент: рекомендуем использовать Flash +
thinking_level=minimalдля баланса. - Интерактивные чат-боты в реальном времени: здесь приоритет — скорость, поэтому Flash остается более подходящим выбором.
🎯 Совет по A/B-тестированию: не выбирайте модель на интуитивном уровне. Мы рекомендуем создать отдельные API-ключи для каждой модели на APIYI (apiyi.com), распределить трафик между ними 50/50 и через 7 дней сравнить реальные показатели удовлетворенности пользователей (лайки, повторные генерации, конверсии) — цифры сами покажут, стоит ли модель своих денег.
FAQ: Gemini 3 и визуальное мышление
Q1: Почему после перехода на Gemini 3 в моем коде генерации «периодически появляются полуфабрикаты»?
Потому что у Gemini 3 Pro Image мышление включено по умолчанию, и в ответе может содержаться от 1 до 3 изображений. Скорее всего, ваш старый код забирает parts[0], а это может быть черновик. Решение: обновите код так, чтобы он отфильтровывал thought: true и забирал последнее изображение, не являющееся процессом мышления.
Q2: Есть ли функция мышления в интерфейсе Gemini 3 на платформе APIYI?
Абсолютно такая же. APIYI (apiyi.com) использует архитектуру прозрачной пересылки. Все поля thought, thought_signature и inline_data из нативного ответа Gemini передаются без изменений, мы ничего не вырезаем и не модифицируем. Вы можете просто перенаправить ваш код, который раньше обращался напрямую к Google AI Studio, на APIYI — структура ответа будет полностью совместима.
Q3: Можно ли каким-то параметром принудительно заставить модель выдавать только финальное изображение?
Нет. В официальной документации четко сказано: "This feature is enabled by default and cannot be disabled in the API" (функция включена по умолчанию и не может быть отключена в API). Однако вы можете установить include_thoughts: false, чтобы в ответе не было текстовых рассуждений, но черновики изображений все равно могут остаться, поэтому фильтрация на стороне кода обязательна.
Q4: Мышление увеличивает задержку, как это оптимизировать?
Есть три пути:
- Для простых сценариев используйте
gemini-3-flash-image+thinking_level=minimal. - Если задача несложная, пишите промпт точнее, чтобы модель не «уходила в глубокие раздумья».
- Используйте стриминг (потоковую передачу), чтобы пользователь видел промежуточные черновики, а финальное изображение доходило в конце.
Q5: Как проверить, действительно ли в ответе сработало мышление?
Проверьте поле response.usage_metadata.thoughts_token_count. Если значение больше 0, значит, мышление было активировано. Это число также поможет вам оценить реальные затраты на логический вывод.
Q6: Можно ли создать или изменить thought_signature самостоятельно?
Нет. thought_signature — это криптографический ключ, выдаваемый сервером Google для проверки целостности контекста в многоходовых диалогах. Самодельные подписи будут отклонены сервером. При многоходовом редактировании просто отправляйте обратно всю часть (part), содержащую signature.
Q7: Как быть с неопределенностью, которую создает мышление при массовой генерации 100 изображений?
Рекомендуем обрабатывать ответ для каждого запроса отдельно и логировать thoughts_token_count. В личном кабинете APIYI (apiyi.com) можно просматривать потребление токенов по каждому вызову и выявлять запросы с аномально высоким потреблением ресурсов на «мышление». Для массовых сценариев также можно рассмотреть Batch API (Gemini 3 Pro Image его поддерживает) — это снизит стоимость вдвое, а ответы можно обрабатывать асинхронно.
Итоги и чек-лист по работе с Gemini 3 Image Thinking
Вспоминая всё вышесказанное: Gemini 3 Image Thinking не только повышает качество, но и полностью меняет структуру ответов модели. Если коротко:
✅ Ключевой принцип: никогда не берите
parts[0]напрямую, всегда фильтруйтеthought: trueи всегда берите последнийinline_dataв качестве итогового изображения.

Чек-лист по миграции
Если ваш проект переходит с Gemini 2.5 на Gemini 3, сверьтесь со списком:
- Замена ID модели:
gemini-2.5-flash-image→gemini-3-pro-image-previewилиgemini-3-flash-image. - Переработка парсинга ответа: Замените все
parts[0]на логику «фильтрация thought + выбор последнего элемента». - Обработка сигнатур: В многоходовых диалогах обязательно сохраняйте часть с
thought_signature. - Проверка затрат: Помните, что токены «мышления» (thinking tokens) засчитываются как выходные, поэтому расходы могут вырасти на 20–40%.
- Регрессионное тестирование: Подготовьте 20+ примеров промптов, сравните результаты Gemini 2.5 и Gemini 3, чтобы избежать неожиданных сбоев.
Шаблон для быстрой интеграции
Используйте этот код как «золотой стандарт» для вашей команды, через него должны проходить все запросы:
def extract_final_image(response):
"""Безопасное извлечение итогового изображения из ответа Gemini 3 Image"""
parts = response.candidates[0].content.parts if response.candidates else []
# Ищем с конца, чтобы найти первое изображение, не являющееся 'thought'
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # base64 байты
return None # Изображение не найдено, требуется повторный запрос
🎯 Совет напоследок: Механизм мышления Gemini 3 — палка о двух концах. Если использовать его правильно, вы получите качество генерации топового уровня, если нет — «лотерею» с полуготовым результатом. Мы рекомендуем после подключения через APIYI (apiyi.com) прогнать регрессионный тест на 10–20 реальных промптах, чтобы убедиться, что ваш код правильно извлекает финальное изображение при любых сценариях работы «мышления», и только потом деплоить в продакшн. Платформа поддерживает всю линейку моделей Gemini 3, а ответы API полностью идентичны официальным от Google.
Автор: Техническая команда APIYI | Больше туториалов по генерации изображений: help.apiyi.com