Ao usar a API do Gemini 3 Pro Image para gerar imagens e exibir diretamente a primeira imagem retornada, o resultado costuma parecer "estranho": composição bizarra, detalhes mal acabados ou até partes faltantes na tela. Isso não significa que o desempenho do modelo caiu, mas que você está escolhendo a imagem errada — a primeira imagem provavelmente é apenas um "rascunho de pensamento" do modelo, e a versão final está, na verdade, na última posição da resposta.
Este artigo detalha, com base na documentação oficial do Google AI, a estrutura de resposta do mecanismo de pensamento de imagem do Gemini 3, explica por que uma chamada pode retornar de 2 a 3 imagens, como identificar a imagem final com precisão usando o campo part.thought e a assinatura thought_signature, e fornece o código de extração correto em Python, Node.js e cURL. Todos os exemplos baseiam-se no encaminhamento transparente da APIYI (apiyi.com) — a camada de proxy mantém a estrutura de resposta original do Gemini, permitindo que desenvolvedores tratem os dados conforme a especificação oficial.
Princípios fundamentais do mecanismo de pensamento de imagem do Gemini 3
Antes de colocar a mão na massa, vamos entender o problema básico: "por que uma chamada retorna várias imagens?".
Por que o pensamento de imagem do Gemini 3 não pode ser desativado
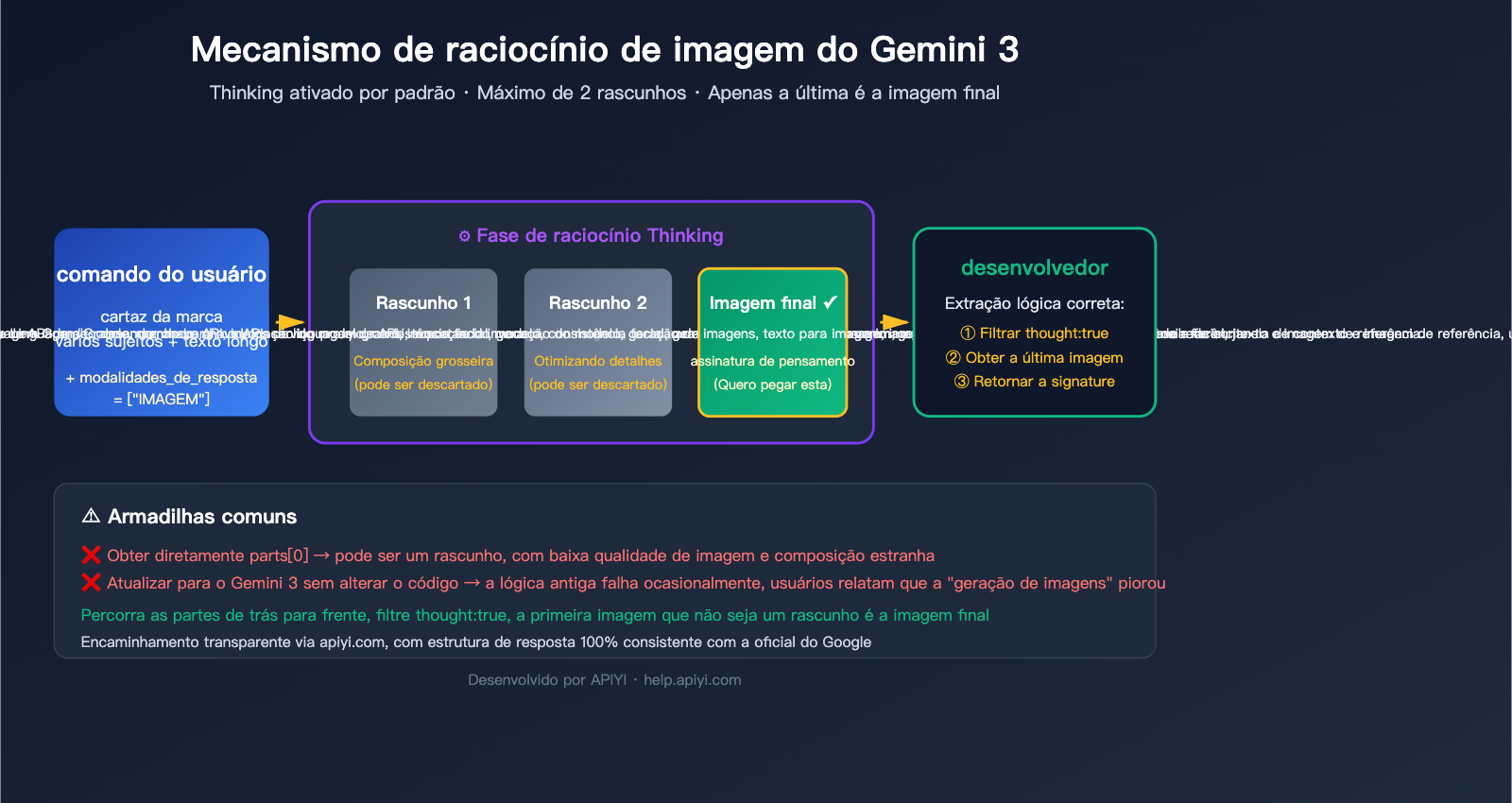
O Google introduziu no gemini-3-pro-image-preview (nome comercial Nano Banana Pro) um mecanismo de "Thinking" (pensamento) originado do mesmo modelo de texto do Gemini — antes de gerar a imagem final, o modelo usa até 2 imagens temporárias para testar composição, layout e renderização de texto, agindo como um designer que faz um rascunho antes da versão final.
A documentação oficial esclarece 3 fatos fundamentais:
| Fato | Explicação |
|---|---|
| Ativado por padrão, impossível desativar | A funcionalidade Thinking é forçada na camada da API, não existem parâmetros de controle |
| Até 2 imagens temporárias | O modelo pode gerar até 2 rascunhos de pensamento, mas nem sempre acontece |
| A última é a imagem final | A última imagem da etapa de pensamento é o resultado final renderizado |
| Tokens de pensamento são cobrados | Mesmo que você não peça o conteúdo do pensamento, os tokens são consumidos e cobrados |
Em resumo: a resposta que você recebe já contém várias imagens por natureza — isso não é um bug, é o design do produto. A questão não é "como desligar", mas "como pegar apenas a imagem final corretamente".
🎯 Compreensão de Arquitetura: O mecanismo de pensamento do Gemini 3 compartilha o mesmo motor de "Thinking" de cadeia de raciocínio do modelo de texto Gemini 3 Pro. Isso explica por que o Nano Banana Pro supera significativamente o antigo Nano Banana em renderização de textos longos e consistência entre múltiplos sujeitos. Ao usar a APIYI, todos os comportamentos de pensamento são idênticos à conexão direta com o Google; a camada de proxy não descarta nenhum dado de pensamento.
Revisão de erros comuns dos clientes
O cenário de falha mais comum na comunidade de usuários é:
Chamar API → Receber resposta → A resposta contém um array de "parts" → Pegar diretamente a imagem em "parts[0]" → Exibir ao usuário
Esse pseudocódigo funcionava bem na era do Nano Banana anterior (Gemini 2.5 Flash Image), porque aquela versão retornava apenas uma imagem por padrão. Ao atualizar para o Gemini 3 Pro Image, o mesmo código trata o "rascunho de pensamento" como o produto final — resultando em uma imagem que claramente não condiz com a descrição do comando ou apresenta composições estranhas (um "semiproduto").
Esse problema é sorrateiro porque:
- Não falha sempre: Em comandos simples, o modelo pode não acionar o pensamento e retornar apenas uma imagem.
- Não gera erros: A estrutura da resposta é válida, e acessar
parts[0]não causa exceções. - Qualidade baixa, mas existe imagem: O usuário acha que o modelo é ruim, quando na verdade o erro é na seleção da imagem.
title: "Guia detalhado: Entendendo a estrutura de resposta do Gemini 3 com processamento de imagem"
Entender o que pode vir em uma resposta de API é o primeiro passo para processar os dados corretamente.
O array parts de uma resposta completa
Quando o pensamento (thinking) do Gemini 3 Pro Image é acionado, o response.candidates[0].content.parts pode ter este formato:
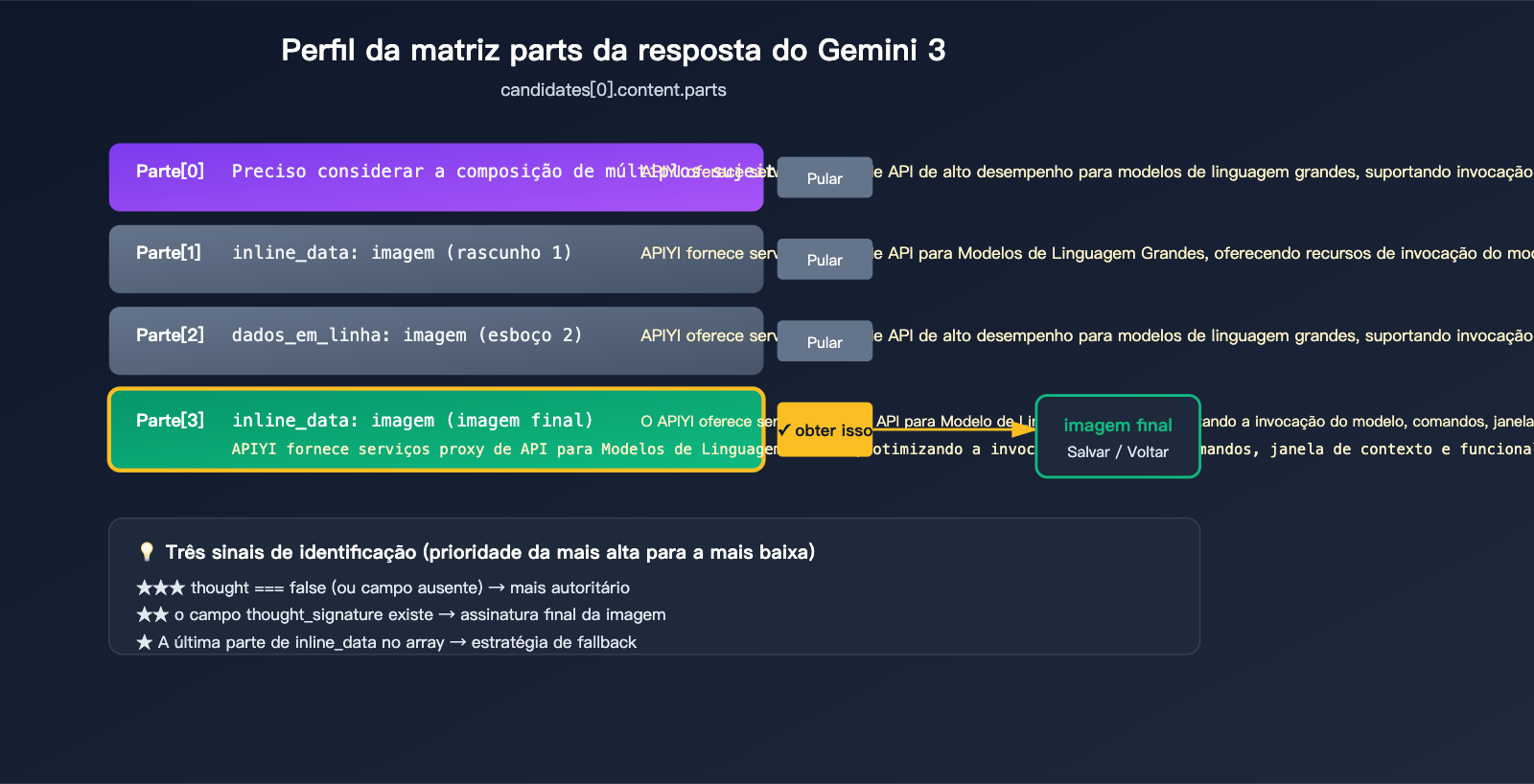
candidates[0].content.parts = [
{ text: "Preciso considerar a composição...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Rascunho 1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Rascunho 2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } // Imagem final
]
O mal-entendido sobre esse array é a fonte da maioria dos bugs. Lembre-se das 3 regras abaixo para escrever um código robusto.
3 Sinais Oficiais para identificar a imagem final
O Google forneceu 3 sinais para identificar a imagem final, use por ordem de prioridade:
| Prioridade | Sinal de Identificação | Explicação | Confiabilidade |
|---|---|---|---|
| ★★★ | part.thought === false (ou campo ausente) |
Marcado explicitamente como não sendo conteúdo de pensamento | Máxima |
| ★★ | Presença do campo thought_signature |
Apenas a imagem final contém a assinatura, rascunhos não | Alta |
| ★ | Último inline_data no array |
Documentação oficial confirma que a "última imagem é a final" | Backup |
A abordagem mais segura é combinar os usos: verifique primeiro o campo thought, se não houver, use thought_signature como backup e, se ainda assim não funcionar, pegue o último inline_data.
Diferenças de thinking_level no Gemini 3.1 Flash Image
É importante notar que nem todos os modelos de imagem do Gemini se comportam da mesma maneira:
| Modelo | Pensamento (Default) | thinking_level configurável |
Cenário ideal |
|---|---|---|---|
gemini-3-pro-image-preview |
Forçado (Ativado) | ❌ Não ajustável | Alta fidelidade,素材 profissional |
gemini-3-flash-image |
Padrão: minimal | ✅ minimal / high | Interação em tempo real, geração em lote |
gemini-2.5-flash-image |
Sem pensamento | – | Compatibilidade legada |
O Gemini 3.1 Flash permite ajustar manualmente o thinking_level para obter uma composição mais refinada ou reduzir para minimal para ter um tempo de resposta mais rápido — essa flexibilidade não existe na versão Pro.
🎯 Sugestão de escolha: Para funções de geração de imagem em produtos B2C, recomendamos o uso padrão do
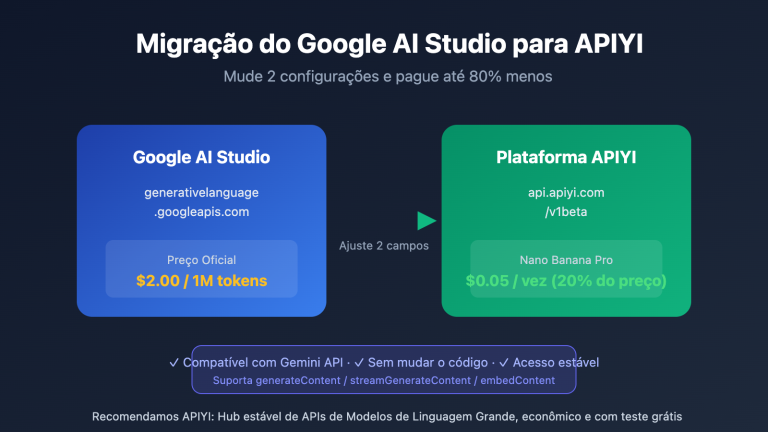
gemini-3-flash-image+thinking_level=minimal(mais rápido e barato). Quando o usuário clicar em "Modo de alta qualidade", mude para ogemini-3-pro-image-preview(pensamento ativo e alta fidelidade). Na plataforma APIYI (apiyi.com), ambos os modelos utilizam a mesma chave API e base_url, permitindo uma alternância transparente.
Código para processar corretamente o pensamento em imagens do Gemini 3
Com a teoria clara, vamos ao código. Os exemplos abaixo utilizam o encaminhamento transparente da APIYI (apiyi.com) — seu código que originalmente conectava ao Google AI Studio só precisa mudar a base_url para o endereço da APIYI e a api_key para uma chave da APIYI; a lógica de processamento da resposta permanece idêntica.
Implementação correta com o SDK oficial (Python)
from google import genai
client = genai.Client(
api_key="sk-sua-chave-apiyi",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Um Shiba Inu em estilo cyberpunk, sob um letreiro neon, alta definição 4K",
config={"response_modalities": ["IMAGE"]}
)
# ✅ Correto: Filtra todas as partes de pensamento (thought), salvando apenas a imagem final
for part in response.parts:
if getattr(part, "thought", False):
continue # Pular rascunhos de pensamento
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("resultado_final.png")
break # A primeira imagem não classificada como pensamento é a final
Exemplo de como NÃO fazer (erro comum dos usuários):
# ❌ Erro: Pegar diretamente a primeira imagem, corre o risco de pegar um rascunho
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# A imagem gerada pode ser um esboço inacabado
Implementação correta (Node.js / TypeScript)
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "Um Shiba Inu em estilo cyberpunk, sob um letreiro neon, alta definição 4K",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ Percorrer de trás para frente, a primeira imagem que não seja thought é a final
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
Versão via linha de comando (cURL + jq)
Se você estiver fazendo chamadas via script shell, pode usar o jq para filtrar:
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "Um Shiba Inu estilo cyberpunk"}]
}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
Esta expressão jq executa três tarefas: filtra thought: true, mantém apenas o mime type de imagem e seleciona a last (última) — seguindo perfeitamente as 3 regras oficiais de identificação.
🎯 Ponto de verificação de código: Durante o code review, ao encontrar código que percorre respostas de imagem do Gemini, certifique-se de que há filtragem de pensamento. Recomendamos encapsular uma função utilitária
extractFinalImage()em sua equipe; todos os códigos de negócio devem chamar essa função para evitar erros. Se você acessa via APIYI (apiyi.com), pode testar este código localmente e reutilizá-lo diretamente em produção.
Tópicos Avançados sobre o Raciocínio de Imagens no Gemini 3
Edições multirrodada exigem o retorno do thought_signature
O Nano Banana Pro oferece suporte a "edições contínuas" — quando um usuário diz "mude o fundo para a praia" e depois "mude a expressão do cachorro para feliz" — mas a documentação oficial exige explicitamente que o thought_signature da rodada anterior seja retornado em conversas multirrodada. Caso contrário, o modelo não consegue manter o contexto de raciocínio anterior e a qualidade cairá significativamente.
A forma correta de realizar chamadas multirrodada:
# Primeira rodada
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Um Shiba Inu correndo no parque"
)
# Extrair o objeto part da imagem final (contendo o thought_signature)
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# Segunda rodada: adicionar o final_part completo de volta ao histórico
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "Um Shiba Inu correndo no parque"}]},
{"role": "model", "parts": [final_part]}, # Contém thought_signature
{"role": "user", "parts": [{"text": "Mude o fundo para um pôr do sol na praia"}]}
]
)
Visualizando o processo de raciocínio (para depuração)
Se você quiser ver o que o modelo "pensou", pode ativar o include_thoughts:
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Um prompt complexo para um pôster de marca...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# Imprimir o processo de raciocínio
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[Raciocínio] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"rascunho_{id(part)}.png") # Salvar rascunho
Isso é extremamente útil ao depurar "por que o resultado gerado não está ideal" — ver os rascunhos ajuda a deduzir qual parte do comando o modelo interpretou mal.

Lógica de cobrança de tokens de raciocínio
A cobrança do Gemini 3 Pro Image exige atenção especial dos desenvolvedores:
| Tipo de Token | Preço (por milhão) | Produção obrigatória |
|---|---|---|
| Prompt de entrada | $2 | ✅ Sim |
| Saída de imagem/texto | $12 | ✅ Sim |
| Raciocínio (Thinking) | Incluído nos tokens de saída | ✅ Obrigatório, não pode ser desativado |
Isso significa que, mesmo que você queira apenas a imagem final e não se importe com o processo de raciocínio, os tokens de raciocínio ainda serão gerados e cobrados. O que você pode economizar é apenas o "retorno do conteúdo de raciocínio para você" (parâmetro include_thoughts), não o "processo de raciocínio em si".
🎯 Dicas de otimização de custo: Para cenários simples (como geração de imagens de produtos, ilustrações), use o
gemini-3-flash-image+thinking_level=minimal; o custo é significativamente menor que a versão Pro. Para cenários complexos (consistência entre vários objetos, renderização de texto de alta fidelidade), utilize o modelo Pro. Recomendamos ativar o monitoramento de uso ao realizar a invocação do modelo via APIYI (apiyi.com), comparar a relação custo/qualidade entre os dois modelos no seu cenário de negócio e só então definir a configuração de produção.
Prática de resolução de problemas de raciocínio de imagem no Gemini 3
Problema 1: Obter sempre uma imagem de baixa qualidade
Passos de diagnóstico:
# Imprimir o campo de raciocínio (thought) de todas as partes
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"Parte {i}: thought={is_thought}, image={has_image}, signature={has_sig}")
Se a saída contiver várias partes com image=True, o problema é que "várias imagens foram retornadas". Verifique se o seu código está selecionando a parte que aparece primeiro no índice.
Problema 2: Não há campo de raciocínio na estrutura de resposta
Possível causa: Você está usando o JSON bruto retornado pela REST API. O formato camelCase é thought, mas em algumas versões do SDK, o campo pode ter sido convertido para snake_case. É preciso ser compatível com ambos:
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
Problema 3: Desejo salvar todas as imagens (para depuração)
O método completo de iteração recomendado pela documentação oficial:
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "draft" if is_draft else "final"
filename = f"gemini_output_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"Salvo: {filename}")
Adaptação do Gemini 3 "Image Thinking" para cenários de negócios reais
Além da teoria e do código básico, existem alguns detalhes que merecem atenção ao aplicar isso em diferentes cenários de negócio.
Cenário 1: Exibição direta de imagens geradas no front-end Web
O front-end recebe a imagem em base64 e precisa convertê-la para o formato data:image/png;base64,xxx para exibi-la. Evite fazer a filtragem de "thought" no front-end — deixe que o back-end retorne um resultado limpo. Caso contrário, o front-end precisará lidar desnecessariamente com a estrutura de resposta do Gemini:
// ❌ Não recomendado: Front-end processando a resposta original do Gemini
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ Recomendado: Back-end filtra, front-end consome apenas a imagem final
// API do back-end retorna: { "image": "base64-string" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
Cenário 2: Geração + salvamento em OSS / CDN
Ao salvar imagens geradas em lote no armazenamento de objetos, use o hash para evitar gravações duplicadas:
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
Certifique-se de fazer upload apenas da imagem final. Os rascunhos de raciocínio apenas poluirão seu OSS e desperdiçarão custos de armazenamento.
Cenário 3: Processamento correto de respostas em streaming
O Gemini 3 suporta streaming para imagens; os rascunhos de pensamento chegam primeiro, e a imagem final chega depois. Em cenários de streaming, recomendamos a técnica de "sobrescrever enquanto recebe":
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # Pula os rascunhos
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # Sobrescreve sempre, mantendo a última
# Após o fim do stream, current_image conterá a imagem final
🎯 Otimização de streaming: Para melhorar a experiência do usuário, você pode exibir os rascunhos de pensamento no front-end como um "preview de carregamento" e substituí-los quando a imagem final chegar. Essa "apresentação progressiva" é muito popular em produtos para o consumidor final (C-end). A APIYI (apiyi.com) suporta totalmente o protocolo de streaming SSE do Gemini, garantindo que o front-end tenha a mesma percepção que uma conexão direta.
Raciocínio de Imagem do Gemini 3 e indicadores de negócio
Dados quantitativos de melhoria de qualidade
De acordo com as divulgações oficiais do Google e testes da comunidade, a qualidade da imagem aumenta significativamente com o "thinking" ativado:
| Indicador | Gemini 2.5 Flash Image | Gemini 3 Pro Image (thinking) | Melhoria |
|---|---|---|---|
| Precisão em textos longos | ~70% | ~95% | +35% |
| Consistência multi-sujeito (5 pessoas) | ~60% | ~90% | +50% |
| Adesão a composições complexas | ~75% | ~92% | +22% |
| Taxa de usabilidade da primeira imagem | ~80% | ~95% | +18% |
O custo disso é um aumento de 40-80% no tempo de resposta e de 20-40% nos custos de token. Vale a pena? Depende do seu cenário:
- Materiais de design profissional, anúncios: O ganho de qualidade supera de longe o aumento de custo; altamente recomendado.
- UGC (conteúdo gerado pelo usuário), conteúdo em lote: Sugerimos usar o Flash com
thinking_level=minimalpara equilibrar. - Interação em tempo real, chatbots: Priorize a velocidade de resposta, o Flash é mais adequado.
🎯 Sugestão de teste A/B: Não escolha o modelo baseando-se apenas em intuição. Recomendamos que você crie chaves separadas para cada modelo na APIYI (apiyi.com), distribua o tráfego em 50/50 na camada de negócio e compare os indicadores reais de satisfação do usuário após 7 dias (taxa de likes, taxa de regeneração, taxa de conversão). Os dados dirão qual modelo realmente vale o investimento.
Perguntas Frequentes sobre o Pensamento Visual do Gemini 3
Q1: Por que meu código de geração de imagens começou a "entregar produtos semiacabados ocasionalmente" após o upgrade para o Gemini 3?
Porque o Gemini 3 Pro Image ativa o "pensamento" (thinking) por padrão, e a resposta pode conter de 1 a 3 imagens. Seu código antigo provavelmente buscava o parts[0], e o parts[0] pode ser apenas um rascunho. Solução: altere seu código para filtrar thought: true e capturar a última imagem que não seja de pensamento.
Q2: O serviço proxy de API da APIYI também tem esse comportamento de "thinking" no Gemini 3?
Exatamente igual. A APIYI (apiyi.com) utiliza uma arquitetura de encaminhamento transparente; os campos thought, thought_signature e inline_data da resposta original do Gemini são transmitidos integralmente, sem qualquer remoção ou alteração. Você pode apontar o código que antes conectava diretamente ao Google AI Studio para a APIYI sem alterar uma única linha, mantendo a compatibilidade total da estrutura de resposta.
Q3: Posso forçar o retorno apenas da imagem final via algum parâmetro?
Não. A documentação oficial é clara ao dizer: "Este recurso é ativado por padrão e não pode ser desativado na API". No entanto, você pode definir include_thoughts: false para que a resposta não contenha o texto do raciocínio — mas os rascunhos de imagem ainda podem estar presentes, por isso a filtragem no nível do código é obrigatória.
Q4: O "thinking" aumentou a latência da resposta, como otimizar?
Três caminhos:
- Em cenários simples, mude para
gemini-3-flash-image+thinking_level=minimal. - Quando a demanda não for complexa, escreva o comando de forma mais precisa para evitar que o modelo "pense demais".
- Use a resposta em stream (streaming), permitindo que o usuário veja o processo de pensamento enquanto a imagem final chega por último.
Q5: Como saber se o "thinking" realmente ocorreu na resposta?
Verifique o campo response.usage_metadata.thoughts_token_count. Se o valor for maior que 0, significa que o "thinking" foi acionado. Esse valor também ajuda a estimar o custo real de inferência.
Q6: Posso construir ou modificar a thought_signature por conta própria?
Não. A thought_signature é uma credencial criptografada emitida pelo servidor do Google, usada para verificar a continuidade do contexto em conversas de vários turnos. Uma assinatura construída manualmente será rejeitada pelo servidor. Em edições de múltiplos turnos, basta reenviar a parte que contém a assinatura na íntegra.
Q7: Como lidar com a incerteza trazida pelo "thinking" ao gerar 100 imagens em lote?
Recomendamos processar a resposta de cada requisição individualmente e registrar o thoughts_token_count. No console da APIYI (apiyi.com), você pode verificar o consumo de tokens por chamada e filtrar as requisições com consumo de "thinking" anormalmente alto para revisão. Para cenários em lote, considere usar a Batch API (o Gemini 3 Pro Image oferece suporte), que reduz o custo pela metade e permite processamento assíncrono.
Resumo e Lista de Verificação de Implementação para o Pensamento Visual do Gemini 3
Revisando o conteúdo, o Pensamento Visual do Gemini 3 trouxe um upgrade de qualidade, mas mudou completamente a estrutura de resposta. Um resumo em uma frase:
✅ Princípio fundamental: Nunca pegue o
parts[0]diretamente, sempre filtrethought: truee sempre selecione a últimainline_datacomo a imagem final.

Lista de verificação de migração
Se o seu projeto está migrando do Gemini 2.5 para o Gemini 3, verifique esta lista:
- Substituir o ID do modelo:
gemini-2.5-flash-image→gemini-3-pro-image-previewougemini-3-flash-image. - Reescrever o parser de resposta: Substitua todos os
parts[0]por "filtrar thought + pegar a última". - Tratar nova assinatura: Preserve a parte que contém
thought_signatureem conversas de vários turnos. - Validar expectativas de cobrança: Note que os tokens de pensamento são contabilizados na saída, o custo pode subir entre 20% e 40%.
- Testes de regressão: Prepare mais de 20 prompts de exemplo e compare a saída do Gemini 2.5 com a do Gemini 3 para evitar surpresas.
Modelo de integração rápida
Use o código abaixo como "modelo padrão" para sua equipe em todas as chamadas de negócio:
def extract_final_image(response):
"""Extrai com segurança a imagem final da resposta do Gemini 3 Image"""
parts = response.candidates[0].content.parts if response.candidates else []
# Procure de trás para frente pela primeira imagem que não seja um "thought"
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # base64 bytes
return None # Imagem final não encontrada, tente novamente
🎯 Dica final: O mecanismo de pensamento visual do Gemini 3 é uma faca de dois gumes — usado corretamente, você obtém uma qualidade de geração de imagem de nível industrial; se usado incorretamente, você recebe um output "aleatório" de semiacabados. Recomendamos testar via APIYI (apiyi.com) com 10 a 20 prompts reais de negócios, garantindo que o código extraia corretamente a imagem final em vários cenários, antes de subir para produção. A plataforma suporta toda a linha Gemini 3 e a resposta da API é idêntica à do Google.
Autor: Equipe Técnica APIYI | Para mais tutoriais sobre geração de imagens com IA, acesse help.apiyi.com