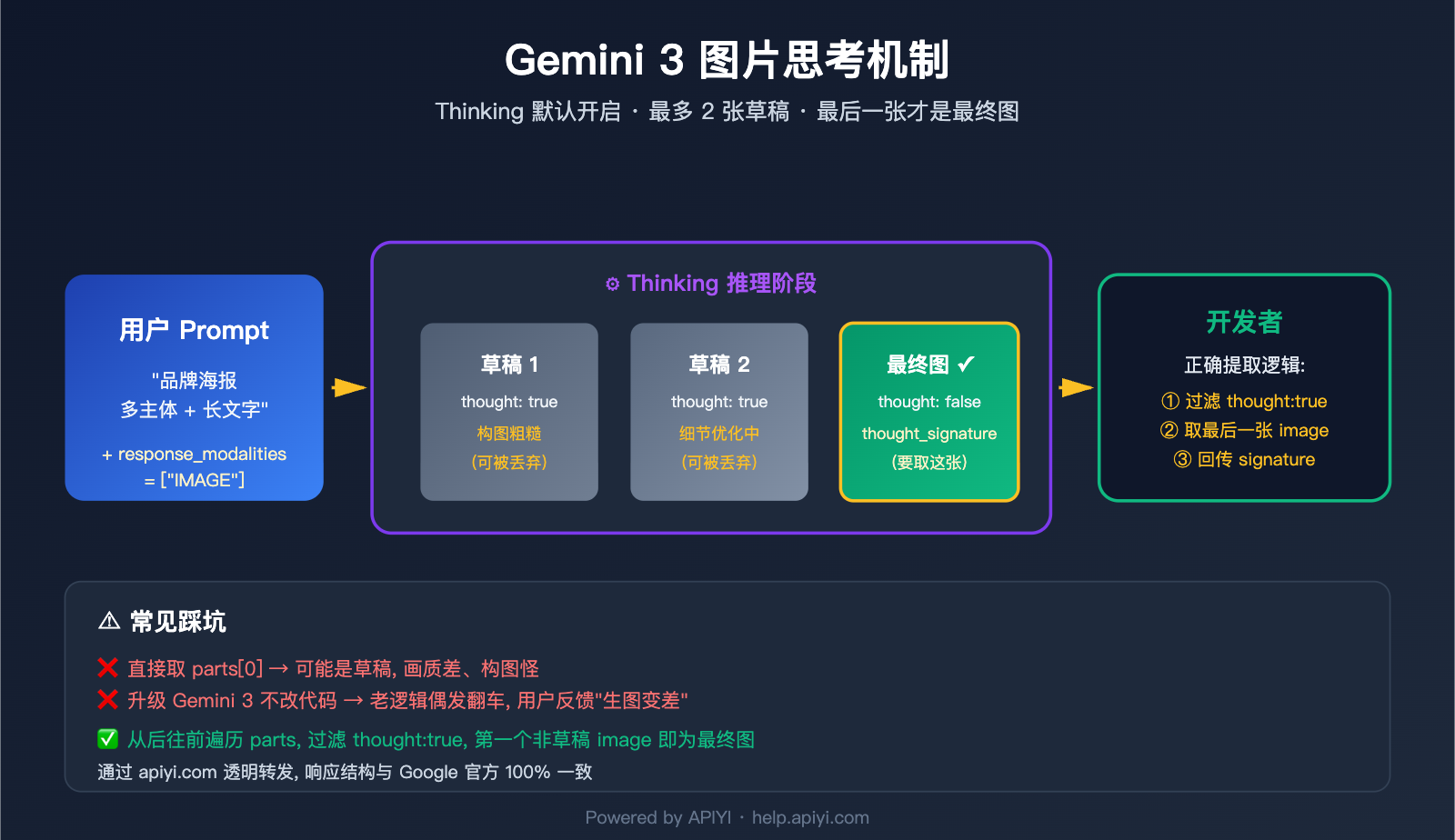
你调用 Gemini 3 Pro Image 接口生成图片,把返回的第一张图直接展示给用户——结果图片看起来"怪怪的":构图奇怪、细节粗糙、甚至画面残缺。这不是模型水平下降了,而是你取错了图——第一张很可能是模型的"思考草稿",真正完成版是响应里的最后一张。
本文基于 Google AI 官方文档,系统拆解 Gemini 3 图片思考 机制的响应结构,解释为什么一次调用可能返回 2-3 张图、如何用 part.thought 字段和 thought_signature 签名精准识别最终图,并给出 Python、Node.js、cURL 三语种的正确提取代码。所有示例基于 API易 apiyi.com 的透明转发——中转层完整保留 Gemini 原生响应结构,开发者只需按官方规范处理即可。
Gemini 3 图片思考机制的核心原理
在动手写代码之前,先理清楚"为什么一次调用会返回多张图"这个根本问题。
为什么 Gemini 3 图片思考默认无法关闭
Google 在 gemini-3-pro-image-preview(商品名 Nano Banana Pro)中引入了一个与 Gemini 文本模型同源的"Thinking"机制——模型在输出最终图片前,会先用最多 2 张临时图片试验构图、排版、文字渲染,像人类设计师先画草稿再出终稿。
官方文档明确了 3 条关键事实:
| 事实 | 说明 |
|---|---|
| 默认开启、无法关闭 | Thinking 特性在 API 层强制启用,没有开关参数 |
| 最多 2 张临时图 | 模型最多生成 2 张思考草稿,不一定每次都生成 |
| 最后一张是最终图 | Thinking 阶段的最后一张图即作为最终渲染结果 |
| 思考 Token 照常计费 | 即便不请求返回思考内容,思考 token 依然消耗并计费 |
换句话说,你拿到的响应天然就是多图的——不是 bug,是设计。问题的关键不是"怎么关掉它",而是"怎么正确地只取最终图"。
🎯 架构理解: Gemini 3 图片思考机制与 Gemini 3 Pro 文本模型的推理链是同一套底层 Thinking 引擎。这也解释了为什么 Nano Banana Pro 在长文本渲染、多主体一致性上显著超越老版 Nano Banana。通过 API易 apiyi.com 调用时,所有 thinking 行为与直连 Google 完全一致,中转层不剥离任何思考数据。
客户常见踩坑现场复盘
用户社区里最典型的翻车现场是这样的:
调用 API → 拿到响应 → 响应里有 parts 数组 → 直接取 parts[0] 里的 image → 显示给用户
这段伪代码在老版 Nano Banana(Gemini 2.5 Flash Image)时代工作良好,因为那版默认只返回一张图。升级到 Gemini 3 Pro Image 后,同样的代码会把"思考草稿"当成最终产品——于是用户看到的是一张明显不符合 prompt 描述、构图奇怪的"半成品"。
这个坑特别隐蔽,因为:
- 不是每次都翻车:简单 prompt 时模型可能不触发 thinking,返回的就是单图
- 错误不会报:响应结构合法,取
parts[0]没有异常 - 质量差但有图:用户以为是模型不行,实际是取错了图
Gemini 3 图片思考的响应结构详解
搞清楚一次 API 调用可能返回什么,是正确处理的前提。
一次调用的完整响应 parts 数组
当 Gemini 3 Pro Image 的 thinking 触发时,response.candidates[0].content.parts 可能长这样:

candidates[0].content.parts = [
{ text: "我需要考虑构图...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // 草稿1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // 草稿2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } // 最终图
]
对这个数组的误解是大多数 bug 的源头。记住以下 3 条规则,就能写出正确代码。
识别最终图的 3 个官方信号
Google 官方给出了 3 个识别最终图的信号,按优先级使用:
| 优先级 | 识别信号 | 说明 | 可靠度 |
|---|---|---|---|
| ★★★ | part.thought === false(或字段缺失) |
明确标记为非思考内容的 part | 最高 |
| ★★ | 存在 thought_signature 字段 |
最终图才带签名,草稿没有 | 高 |
| ★ | 数组中最后一个 inline_data |
官方文档确认"最后一张即最终图" | 兜底 |
最稳的写法是组合使用:优先查 thought 字段,没有就用 thought_signature 兜底,再不行取最后一张 inline_data。
Gemini 3.1 Flash Image 的 thinking_level 差异
需要特别注意,不是所有 Gemini 图片模型行为一致:
| 模型 | Thinking 默认 | 可配置 thinking_level | 适用场景 |
|---|---|---|---|
gemini-3-pro-image-preview |
强制开启 | ❌ 不可调 | 高保真、专业素材 |
gemini-3-flash-image |
默认 minimal | ✅ minimal / high | 实时交互、批量生成 |
gemini-2.5-flash-image |
无 thinking | – | 老版兼容 |
Gemini 3.1 Flash 可以手动调高 thinking_level 换取更精细的构图,也可以降到 minimal 换取更快的响应时间——这种灵活度在 Pro 版本上是没有的。
🎯 选型建议: 做 C 端产品的图片生成功能,我们建议默认用
gemini-3-flash-image+thinking_level=minimal(更快、更便宜),当用户点击"高质量模式"时切换到gemini-3-pro-image-preview(思考、高保真)。在 API易 apiyi.com 平台,两个模型用同一个 API Key 和 base_url 即可无缝切换。
Gemini 3 图片思考的正确处理代码
理论清楚了,上代码。以下示例全部基于 API易 apiyi.com 透明转发——你原本直连 Google AI Studio 的代码只需把 base_url 改成 API易的地址、api_key 换成 API易 Key,响应处理逻辑完全不变。
Python 官方 SDK 正确写法
from google import genai
client = genai.Client(
api_key="sk-your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="一只赛博朋克风格的柴犬,站在霓虹灯牌下,4K 高清",
config={"response_modalities": ["IMAGE"]}
)
# ✅ 正确:过滤掉所有 thought parts,只保存最终图
for part in response.parts:
if getattr(part, "thought", False):
continue # 跳过思考草稿
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("final_output.png")
break # 找到第一个非思考图即为最终图
反面教材(用户踩坑的典型代码):
# ❌ 错误:直接取第一张图,可能拿到思考草稿
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# 生成的图可能是半成品
Node.js / TypeScript 正确写法
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "一只赛博朋克风格的柴犬,站在霓虹灯牌下,4K 高清",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ 从后往前遍历,第一个非 thought 的 image 就是最终图
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
cURL + jq 命令行版
如果你在 shell 脚本里调用,可以用 jq 过滤:
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "一只赛博朋克风格的柴犬"}]
}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
这段 jq 表达式做了三件事:过滤 thought: true、只保留 image mime type、取 last——完美契合官方 3 条识别规则。
🎯 代码审查要点: 在 code review 时,看到遍历 Gemini image 响应的代码,务必确认有 thought 过滤。我们建议在团队内部封装一个统一的
extractFinalImage()工具函数,所有业务代码只调用这个函数,避免分散出错。如果通过 API易 apiyi.com 接入,这段代码可以在本地充分测试,线上直接复用。
Gemini 3 图片思考的高级话题
多轮编辑必须回传 thought_signature
Nano Banana Pro 支持"连续编辑"——用户说"把背景换成海边",再说"把狗的表情变高兴"——但官方明确要求在多轮对话中将前一轮的 thought_signature 回传,否则模型无法延续之前的推理上下文,质量会显著下降。
正确的多轮写法:
# 第一轮
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="一只柴犬在公园里奔跑"
)
# 提取最终图的 part 对象(含 thought_signature)
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# 第二轮:把整个 final_part 加回 history
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "一只柴犬在公园里奔跑"}]},
{"role": "model", "parts": [final_part]}, # 含 thought_signature
{"role": "user", "parts": [{"text": "把背景换成海边日落"}]}
]
)
查看思考过程(调试用)
如果你想看看模型"想了什么",可以开启 include_thoughts:
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="复杂的品牌宣传海报 prompt...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# 打印思考过程
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[思考] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"draft_{id(part)}.png") # 保存草稿
这在调试"为什么生成效果不理想"时非常有用——看草稿能推断模型误解了 prompt 的哪一部分。

thinking token 的计费逻辑
Gemini 3 Pro Image 的计费需要开发者特别关注:
| Token 类型 | 单价(每百万) | 是否强制产生 |
|---|---|---|
| 输入 prompt | $2 | ✅ 是 |
| 输出图片/文本 | $12 | ✅ 是 |
| Thinking reasoning | 计入输出 token | ✅ 强制,不可关闭 |
这意味着即使你只想要最终图、不关心思考过程,thinking token 依然会产生、依然会计费。你能省的只是"是否回传思考内容给你"(include_thoughts 参数),不能省"是否执行思考"。
🎯 成本优化建议: 简单场景(如生成产品图、插画)用
gemini-3-flash-image+thinking_level=minimal,成本显著低于 Pro 版;复杂场景(多主体一致性、高保真文字渲染)才上 Pro。我们建议通过 API易 apiyi.com 调用时开启用量监控,对比两个模型在你业务场景下的成本/质量比,再决定生产配置。
Gemini 3 图片思考的排错实战
问题 1: 始终拿到质量差的图
诊断步骤:
# 打印所有 parts 的 thought 字段
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"Part {i}: thought={is_thought}, image={has_image}, signature={has_sig}")
如果输出里有多个 image=True 的 parts,就是典型的"返回了多张图"。检查你的代码是不是取了索引靠前的 part。
问题 2: 响应结构里没有 thought 字段
可能原因: 用的是 REST API 返回的原始 JSON,驼峰命名是 thought,但某些 SDK 版本下字段可能被转为 snake_case。两种都要兼容:
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
问题 3: 想保存所有图片(调试)
官方推荐的完整遍历写法:
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "draft" if is_draft else "final"
filename = f"gemini_output_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"Saved: {filename}")
Gemini 3 图片思考的真实业务场景适配
理论和基础代码之外,不同业务场景下还有一些值得注意的细节。
场景一: Web 前端直接展示生成图
前端拿到 base64 图片要转成 data:image/png;base64,xxx 格式显示。注意不要在前端做 thought 过滤——让后端返回已过滤的干净结果,否则前端还需要理解 Gemini 响应结构:
// ❌ 不推荐:前端直接处理 Gemini 原始响应
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ 推荐:后端统一过滤,前端只消费最终图
// 后端 API 返回: { "image": "base64-string" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
场景二: 生图 + 存 OSS / CDN
批量生成后保存到对象存储时,用 hash 防止重复写入:
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
务必只上传最终图,思考草稿会污染 OSS 且浪费存储费。
场景三: 流式响应的正确处理
Gemini 3 图片支持 streaming,思考草稿会先到、最终图后到。流式场景下推荐"边收边覆盖":
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # 跳过草稿
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # 每次覆盖,最后一张留下
# stream 结束后,current_image 就是最终图
🎯 流式优化: 用户体验上,可以把思考草稿也推到前端展示"加载中预览",最终图到了再替换——这种"渐进式呈现"在 C 端产品上很受欢迎。API易 apiyi.com 完整支持 Gemini 的 SSE 流式协议,前端感知与直连一致。
Gemini 3 图片思考与业务指标的关联
质量提升的量化数据
根据 Google 官方披露与社区实测,开启 thinking 后图片质量有显著提升:
| 指标 | Gemini 2.5 Flash Image | Gemini 3 Pro Image (thinking) | 提升幅度 |
|---|---|---|---|
| 长文本渲染准确率 | ~70% | ~95% | +35% |
| 多主体一致性(5 人) | ~60% | ~90% | +50% |
| 复杂构图遵循度 | ~75% | ~92% | +22% |
| 首图可用率 | ~80% | ~95% | +18% |
代价是响应时间增加 40-80%、token 成本上升 20-40%。是否值得?看你的业务场景:
- 专业设计素材、广告物料: 质量提升远超成本增加,强烈推荐
- UGC 用户生图、批量内容: 建议走 Flash + thinking_level=minimal 平衡
- 实时交互、聊天机器人: 优先响应速度,用 Flash 更合适
🎯 A/B 实测建议: 不要凭感觉选模型。我们建议在 API易 apiyi.com 上为两个模型分别建 Key,业务层做 50/50 流量分配,7 天后对比真实的用户满意度指标(点赞率、重生成率、转化率)——数据会告诉你哪个模型真正值这个钱。
Gemini 3 图片思考常见问题 FAQ
Q1: 为什么升级到 Gemini 3 后我的生图代码开始"偶尔出半成品"?
因为 Gemini 3 Pro Image 默认开启 thinking,响应里可能有 1-3 张图。你的老代码大概率在取 parts[0],而 parts[0] 可能是草稿。修复方案:把代码改成过滤 thought: true + 取最后一张非思考图。
Q2: API易 平台的 Gemini 3 图片接口也有 thinking 行为吗?
完全一致。API易 apiyi.com 是透明转发架构,Gemini 原生响应里的 thought、thought_signature、inline_data 全部原样透传,不做任何剥离或改写。你可以把原本直连 Google AI Studio 的代码一字不改地指向 API易,响应结构完全兼容。
Q3: 能不能通过某个参数强制只返回最终图?
不能。官方文档明确说明 "This feature is enabled by default and cannot be disabled in the API"(默认开启、API 无法关闭)。但你可以设置 include_thoughts: false,让响应不包含思考文字——不过图片草稿仍然可能存在,所以代码层面的过滤是必须的。
Q4: thinking 让响应延迟变高了,怎么优化?
三个方向:
- 简单场景换成
gemini-3-flash-image+thinking_level=minimal - 需求不复杂时,把 prompt 写得更精确、避免模型"过度思考"
- 使用流式响应(streaming),让用户先看到思考过程的草稿,最终图最后到
Q5: 怎么判断响应里是否确实发生了 thinking?
检查 response.usage_metadata.thoughts_token_count 字段——如果大于 0,说明 thinking 确实被触发了。这个值也能帮你估算实际的推理成本。
Q6: thought_signature 能自己构造或修改吗?
不能。thought_signature 是 Google 服务端签发的加密凭证,用于在多轮对话中验证上下文连续性。自己构造的 signature 会被服务端拒绝。多轮编辑时整体把含 signature 的 part 回传即可。
Q7: 批量生成 100 张图怎么处理 thinking 带来的不确定性?
推荐每个请求独立处理响应,并记录 thoughts_token_count。可以在 API易 apiyi.com 控制台按调用粒度查看 token 消耗,筛选出 thinking 消耗异常高的请求进行复查。批量场景也可以考虑用 Batch API(Gemini 3 Pro Image 支持),成本减半且响应可异步处理。
Gemini 3 图片思考总结与落地清单
回顾全文,Gemini 3 图片思考 带来了质量升级的同时,也彻底改变了响应结构。一句话总结:
✅ 核心原则: 永远不要硬取
parts[0],永远过滤thought: true,永远取最后一个inline_data作为最终图。

迁移检查清单
如果你的项目从 Gemini 2.5 升级到 Gemini 3,按以下清单检查:
- 替换模型 ID:
gemini-2.5-flash-image→gemini-3-pro-image-preview或gemini-3-flash-image - 重写响应解析: 把所有
parts[0]改为"过滤 thought + 取最后一张" - 新增 signature 处理: 多轮对话中保留含
thought_signature的 part - 验证计费预期: 注意 thinking token 计入输出,成本可能上升 20-40%
- 回归测试: 准备 20+ 样本 prompt,对比 Gemini 2.5 和 Gemini 3 的输出,避免偷偷翻车
快速集成模板
把以下代码作为你团队的"黄金模板",所有业务调用都走它:
def extract_final_image(response):
"""从 Gemini 3 Image 响应中安全提取最终图"""
parts = response.candidates[0].content.parts if response.candidates else []
# 从后往前找第一个非 thought 的 image
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # base64 bytes
return None # 没找到最终图,需要重试
🎯 最后建议: Gemini 3 图片思考机制是一把双刃剑——用对了你能拿到业界顶级的生图质量,用错了就是"随机抽签"式的半成品输出。我们建议通过 API易 apiyi.com 接入后,先用 10-20 个真实业务 prompt 跑一遍回归测试,确认代码在各种 thinking 触发状态下都能正确提取最终图,再上生产。该平台支持 Gemini 3 全系模型,API 响应与 Google 官方完全一致。
作者: APIYI 技术团队 | 更多 AI 图像生成教程,访问 help.apiyi.com