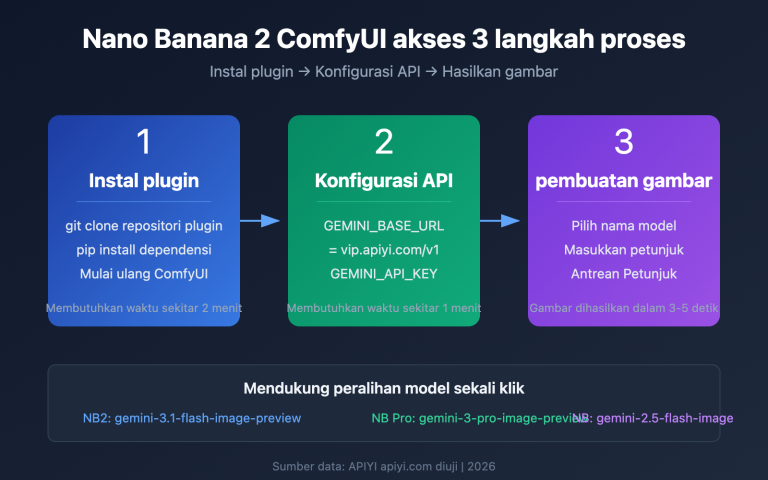
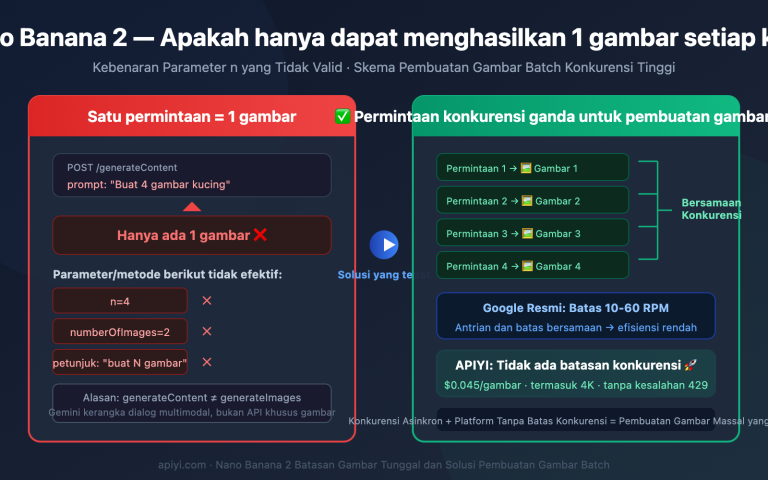
Saat Anda memanggil antarmuka Gemini 3 Pro Image untuk menghasilkan gambar dan langsung menampilkan gambar pertama yang dikembalikan kepada pengguna, hasilnya sering kali terlihat "aneh": komposisi janggal, detail kasar, atau bahkan gambar yang tidak lengkap. Ini bukan berarti performa model menurun, melainkan Anda salah mengambil gambar—gambar pertama kemungkinan besar adalah "draf pemikiran" model, sedangkan hasil yang sebenarnya adalah gambar terakhir dalam respons.
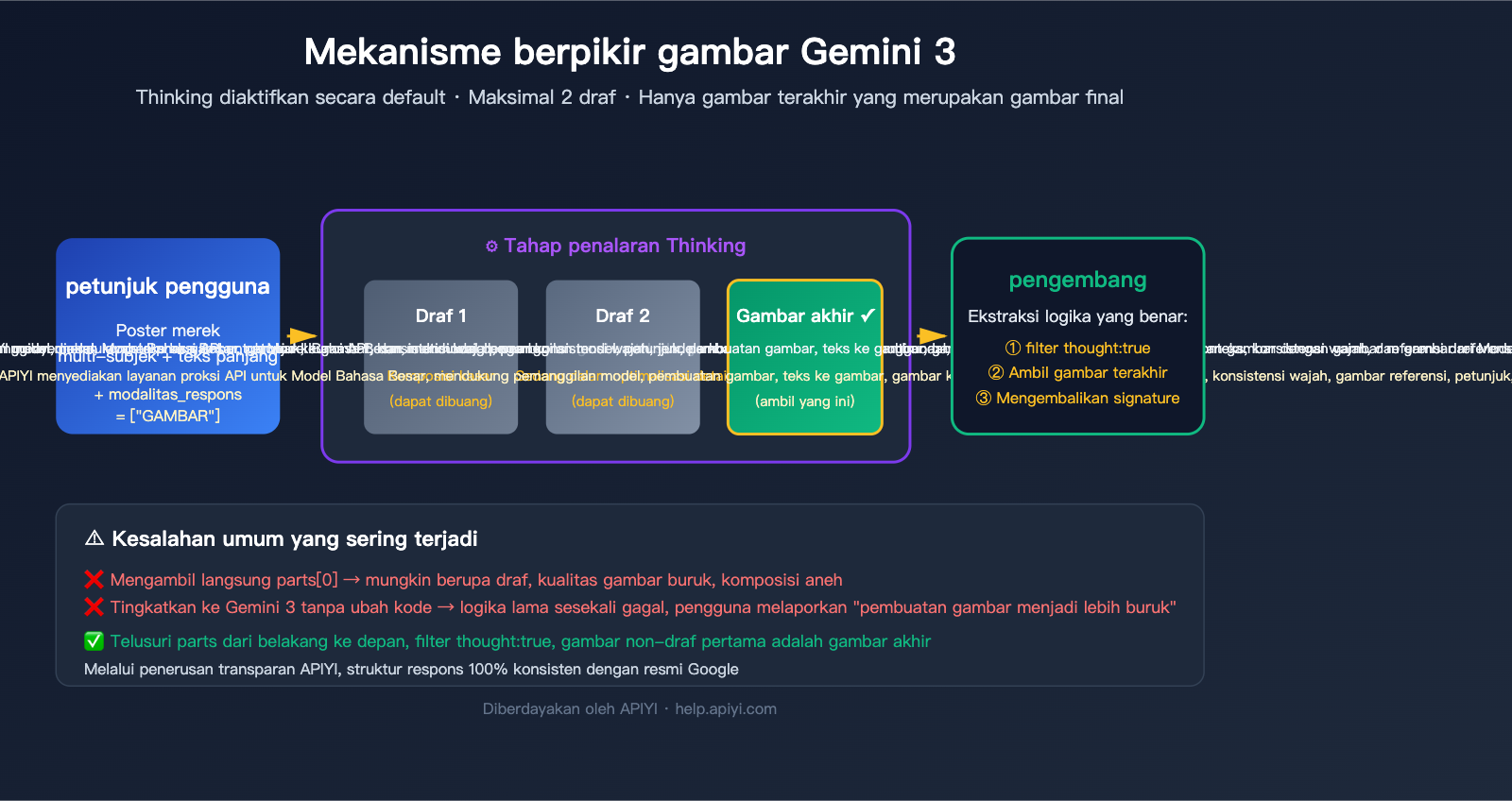
Artikel ini didasarkan pada dokumentasi resmi Google AI untuk mengurai mekanisme pemikiran gambar Gemini 3 secara sistematis. Kami menjelaskan mengapa satu pemanggilan dapat mengembalikan 2-3 gambar, bagaimana menggunakan field part.thought dan tanda thought_signature untuk mengidentifikasi gambar akhir secara akurat, serta memberikan contoh kode dalam Python, Node.js, dan cURL. Semua contoh didasarkan pada penerusan transparan APIYI (apiyi.com)—lapisan layanan proksi API sepenuhnya mempertahankan struktur respons asli Gemini, pengembang hanya perlu menanganinya sesuai spesifikasi resmi.
Prinsip Inti Mekanisme Pemikiran Gambar Gemini 3
Sebelum menulis kode, mari pahami masalah mendasar: "mengapa satu pemanggilan menghasilkan beberapa gambar".
Mengapa Pemikiran Gambar Gemini 3 Tidak Dapat Dinonaktifkan Secara Default
Google memperkenalkan mekanisme "Thinking" yang berasal dari sumber yang sama dengan model teks Gemini pada gemini-3-pro-image-preview (nama produk Nano Banana Pro). Sebelum menghasilkan gambar akhir, model akan menggunakan hingga 2 gambar sementara untuk menguji komposisi, tata letak, dan render teks, layaknya desainer yang membuat draf sebelum hasil final.
Dokumentasi resmi menetapkan 3 fakta kunci:
| Fakta | Penjelasan |
|---|---|
| Aktif default, tidak bisa mati | Fitur Thinking dipaksakan aktif pada tingkat API, tidak ada parameter untuk menonaktifkannya |
| Maksimal 2 gambar draf | Model menghasilkan maksimal 2 draf pemikiran, tidak selalu ada di setiap pemanggilan |
| Terakhir adalah hasil akhir | Gambar terakhir dari tahap Thinking adalah hasil render final |
| Token pemikiran tetap ditagih | Meskipun Anda tidak meminta konten pemikiran, token pemikiran tetap dikonsumsi dan ditagih |
Singkatnya, respons yang Anda terima secara alami berisi beberapa gambar—ini bukan bug, melainkan desain. Kuncinya bukan "bagaimana cara mematikannya", melainkan "bagaimana cara mengambil gambar akhir dengan benar".
🎯 Pemahaman Arsitektur: Mekanisme pemikiran gambar Gemini 3 menggunakan mesin Thinking yang sama dengan model teks Gemini 3 Pro. Ini menjelaskan mengapa Nano Banana Pro jauh lebih unggul daripada versi lama dalam hal render teks panjang dan konsistensi subjek. Saat Anda memanggil melalui APIYI, semua perilaku thinking tetap identik dengan koneksi langsung ke Google, dan layanan proksi tidak menghapus data pemikiran apa pun.
Ulasan Kesalahan Umum Pengguna
Masalah paling umum dalam komunitas pengguna adalah sebagai berikut:
Panggil API → Terima respons → Ada array parts dalam respons → Langsung ambil image dari parts[0] → Tampilkan ke pengguna
Kode semu ini berfungsi dengan baik di era Nano Banana versi lama (Gemini 2.5 Flash Image), karena versi tersebut secara default hanya mengembalikan satu gambar. Setelah ditingkatkan ke Gemini 3 Pro Image, kode yang sama akan menganggap "draf pemikiran" sebagai produk akhir—sehingga pengguna melihat hasil "setengah jadi" yang tidak sesuai dengan deskripsi petunjuk atau memiliki komposisi aneh.
Kesalahan ini sangat tersembunyi karena:
- Tidak selalu gagal: Untuk petunjuk sederhana, model mungkin tidak memicu thinking dan hanya mengembalikan satu gambar.
- Tidak ada error: Struktur respons valid, dan pengambilan
parts[0]tidak memicu pengecualian. - Kualitas buruk namun ada gambar: Pengguna mengira model yang bermasalah, padahal itu karena gambar yang diambil salah.
Penjelasan Struktur Respons Pemikiran Gambar Gemini 3
Memahami apa yang mungkin dikembalikan dalam satu pemanggilan API adalah prasyarat untuk menangani respons dengan benar.
Array parts dalam Respons Pemanggilan Lengkap
Saat proses pemikiran (thinking) Gemini 3 Pro Image terpicu, response.candidates[0].content.parts mungkin terlihat seperti ini:
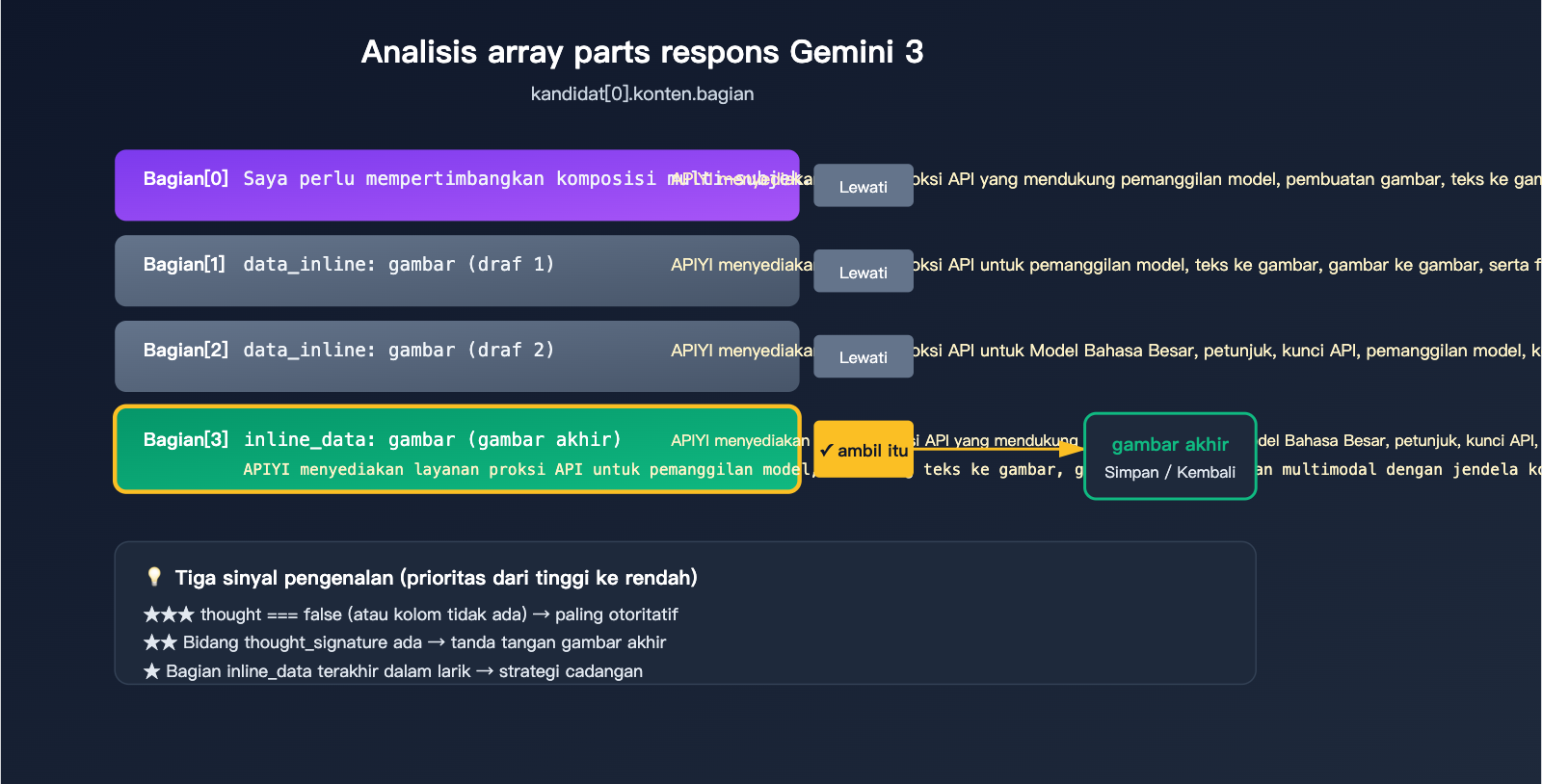
candidates[0].content.parts = [
{ text: "Saya perlu mempertimbangkan komposisi...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Draft 1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Draft 2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } // Gambar final
]
Kesalahpahaman mengenai array ini adalah sumber dari banyak bug. Ingat 3 aturan berikut agar Anda bisa menulis kode yang tepat.
3 Sinyal Resmi untuk Mengenali Gambar Final
Google memberikan 3 sinyal untuk mengenali gambar final, gunakan berdasarkan prioritas:
| Prioritas | Sinyal Pengenalan | Penjelasan | Keandalan |
|---|---|---|---|
| ★★★ | part.thought === false (atau kolom kosong) |
Ditandai secara eksplisit sebagai bagian non-pemikiran | Tertinggi |
| ★★ | Terdapat field thought_signature |
Hanya gambar final yang membawa tanda tangan, draft tidak | Tinggi |
| ★ | inline_data terakhir dalam array |
Dokumentasi resmi mengonfirmasi "gambar terakhir adalah gambar final" | Cadangan |
Cara paling stabil adalah menggunakan kombinasi: periksa field thought terlebih dahulu, jika tidak ada, gunakan thought_signature sebagai cadangan, dan jika masih belum, ambil inline_data terakhir.
Perbedaan thinking_level pada Gemini 3.1 Flash Image
Harap diperhatikan bahwa perilaku model gambar Gemini tidak selalu sama:
| Model | Default Thinking | thinking_level Dapat Dikonfigurasi |
Skenario Penggunaan |
|---|---|---|---|
gemini-3-pro-image-preview |
Wajib aktif | ❌ Tidak dapat diatur | Kesetiaan tinggi, materi profesional |
gemini-3-flash-image |
Default minimal | ✅ minimal / high | Interaksi real-time, generate massal |
gemini-2.5-flash-image |
Tanpa thinking | – | Kompatibilitas versi lama |
Gemini 3.1 Flash memungkinkan penyesuaian thinking_level ke tingkat tinggi untuk komposisi yang lebih detail, atau ke minimal untuk waktu respons lebih cepat—fleksibilitas ini tidak tersedia pada versi Pro.
🎯 Saran Pemilihan: Untuk fitur pembuatan gambar pada produk konsumen (C-end), kami sarankan menggunakan
gemini-3-flash-image+thinking_level=minimal(lebih cepat dan murah). Saat pengguna mengeklik "Mode Kualitas Tinggi", alihkan kegemini-3-pro-image-preview(pemikiran, kesetiaan tinggi). Di platform APIYI (apiyi.com), kedua model dapat beralih dengan mulus menggunakan kunci API dan base_url yang sama.
Kode Penanganan yang Tepat untuk Pemikiran Gambar Gemini 3
Teori sudah jelas, mari masuk ke kode. Contoh berikut sepenuhnya didasarkan pada proksi transparan APIYI (apiyi.com)—kode Anda yang tadinya terhubung langsung ke Google AI Studio hanya perlu mengubah base_url ke alamat APIYI dan mengganti api_key dengan Kunci APIYI, logika pemrosesan respons tetap sama persis.
Penulisan SDK Resmi Python yang Tepat
from google import genai
client = genai.Client(
api_key="sk-your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Seekor anjing Shiba Inu bergaya cyberpunk, berdiri di bawah papan lampu neon, 4K HD",
config={"response_modalities": ["IMAGE"]}
)
# ✅ Benar: Filter semua thought parts, hanya simpan gambar final
for part in response.parts:
if getattr(part, "thought", False):
continue # Lewati draf pemikiran
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("final_output.png")
break # Gambar non-pemikiran pertama adalah gambar final
Contoh Buruk (kode tipikal yang sering salah):
# ❌ Salah: Langsung mengambil gambar pertama, berisiko mendapatkan draf pemikiran
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# Gambar yang dihasilkan bisa jadi hanya setengah jadi
Penulisan Node.js / TypeScript yang Tepat
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "Seekor anjing Shiba Inu bergaya cyberpunk, berdiri di bawah papan lampu neon, 4K HD",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ Telusuri dari belakang ke depan, gambar non-thought pertama adalah gambar final
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
Versi Baris Perintah cURL + jq
Jika Anda melakukan pemanggilan dalam skrip shell, Anda bisa menggunakan filter jq:
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "Seekor anjing Shiba Inu bergaya cyberpunk"}]
}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
Ekspresi jq ini melakukan tiga hal: memfilter thought: true, hanya menyisakan tipe mime gambar, dan mengambil yang last (terakhir)—cocok sempurna dengan 3 aturan pengenalan resmi.
🎯 Poin Tinjauan Kode: Saat melakukan code review, pastikan kode yang memproses respons gambar Gemini memiliki penyaringan thought. Kami menyarankan untuk membungkus fungsi utilitas
extractFinalImage()yang terpadu di dalam tim, agar semua kode bisnis hanya memanggil fungsi tersebut untuk menghindari kesalahan yang tersebar. Jika mengakses melalui APIYI (apiyi.com), kode ini dapat diuji secara menyeluruh di lokal dan langsung digunakan di lingkungan produksi.
Topik Lanjutan Pemikiran Gambar Gemini 3
Pengeditan Multironde Wajib Mengirim Balik thought_signature
Nano Banana Pro mendukung "pengeditan berkelanjutan"—misalnya pengguna berkata "ubah latar belakang menjadi tepi pantai", lalu "buat ekspresi anjing menjadi lebih bahagia"—namun pihak resmi mewajibkan pengiriman balik thought_signature dari putaran sebelumnya dalam percakapan multironde. Jika tidak, model tidak dapat melanjutkan konteks penalaran sebelumnya dan kualitas akan menurun drastis.
Cara penulisan multironde yang benar:
# Putaran pertama
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Seekor anjing Shiba Inu sedang berlari di taman"
)
# Ekstrak objek part gambar akhir (termasuk thought_signature)
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# Putaran kedua: tambahkan seluruh final_part kembali ke history
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "Seekor anjing Shiba Inu sedang berlari di taman"}]},
{"role": "model", "parts": [final_part]}, # Termasuk thought_signature
{"role": "user", "parts": [{"text": "Ubah latar belakang menjadi matahari terbenam di tepi pantai"}]}
]
)
Melihat Proses Pemikiran (Untuk Debugging)
Jika Anda ingin melihat "apa yang dipikirkan" model, Anda dapat mengaktifkan include_thoughts:
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Prompt poster promosi brand yang kompleks...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# Cetak proses pemikiran
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[Pemikiran] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"draft_{id(part)}.png") # Simpan draf
Ini sangat berguna saat mendebug "mengapa hasil generasinya tidak ideal"—dengan melihat draf, Anda bisa menyimpulkan bagian mana dari prompt yang disalahpahami oleh model.

Logika Penagihan Token Pemikiran (Thinking Token)
Penagihan Gemini 3 Pro Image memerlukan perhatian khusus dari pengembang:
| Tipe Token | Harga Satuan (per juta) | Apakah Wajib Dihasilkan |
|---|---|---|
| Prompt input | $2 | ✅ Ya |
| Gambar/teks output | $12 | ✅ Ya |
| Thinking reasoning | Dihitung sebagai output token | ✅ Wajib, tidak bisa dimatikan |
Ini berarti meskipun Anda hanya menginginkan gambar akhir dan tidak peduli dengan proses pemikiran, token pemikiran tetap akan dihasilkan dan tetap akan ditagih. Yang bisa Anda hemat hanyalah "apakah konten pemikiran dikirimkan kembali kepada Anda" (parameter include_thoughts), bukan "apakah pemikiran dilakukan".
🎯 Saran Optimasi Biaya: Untuk skenario sederhana (seperti membuat gambar produk, ilustrasi), gunakan
gemini-3-flash-image+thinking_level=minimal, biayanya jauh lebih rendah daripada versi Pro; gunakan versi Pro hanya untuk skenario kompleks (konsistensi multi-objek, rendering teks fidelitas tinggi). Kami sarankan untuk mengaktifkan pemantauan penggunaan saat memanggil API melalui APIYI (apiyi.com), bandingkan rasio biaya/kualitas dari kedua model tersebut dalam skenario bisnis Anda, baru kemudian tentukan konfigurasi produksi.
Praktik Troubleshooting Pemikiran Gambar Gemini 3
Masalah 1: Selalu Mendapatkan Gambar dengan Kualitas Buruk
Langkah Diagnosis:
# Cetak bidang thought dari semua parts
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"Part {i}: thought={is_thought}, image={has_image}, signature={has_sig}")
Jika dalam output terdapat beberapa part dengan image=True, itu adalah kasus klasik "mengembalikan lebih dari satu gambar". Periksa kode Anda untuk memastikan Anda tidak mengambil part dengan indeks awal.
Masalah 2: Tidak Ada Bidang 'thought' dalam Struktur Respons
Kemungkinan penyebab: Anda menggunakan JSON mentah dari REST API, penamaan camelCase adalah thought, namun di beberapa versi SDK, bidang tersebut mungkin diubah menjadi snake_case. Kompatibelkan keduanya:
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
Masalah 3: Ingin Menyimpan Semua Gambar (Debugging)
Cara traversal lengkap yang direkomendasikan oleh pihak resmi:
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "draft" if is_draft else "final"
filename = f"gemini_output_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"Disimpan: {filename}")
Adaptasi Skenario Bisnis Nyata untuk Pemikiran Gambar Gemini 3
Di luar teori dan kode dasar, ada beberapa detail yang patut diperhatikan dalam berbagai skenario bisnis.
Skenario 1: Menampilkan Gambar Hasil Generasi Langsung di Frontend Web
Saat frontend menerima gambar base64, ia perlu diubah menjadi format data:image/png;base64,xxx untuk ditampilkan. Catatan: jangan lakukan pemfilteran thought di frontend—biarkan backend mengembalikan hasil yang sudah bersih, jika tidak, frontend akan dibuat repot untuk memahami struktur respons Gemini:
// ❌ Tidak disarankan: Frontend memproses respons mentah Gemini secara langsung
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ Disarankan: Backend melakukan pemfilteran terpusat, frontend hanya mengonsumsi gambar akhir
// Respons API backend: { "image": "string-base64" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
Skenario 2: Gambar Generasi + Simpan ke OSS / CDN
Saat menyimpan gambar yang dihasilkan secara massal ke penyimpanan objek (object storage), gunakan hash untuk mencegah penulisan berulang:
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
Pastikan untuk hanya mengunggah gambar akhir. Draf pemikiran (thought) akan mengotori OSS dan membuang-buang biaya penyimpanan.
Skenario 3: Penanganan yang Benar untuk Respons Streaming
Gemini 3 mendukung streaming untuk gambar, di mana draf pemikiran akan muncul lebih dulu, disusul oleh gambar akhir. Untuk skenario streaming, disarankan menggunakan pendekatan "tindih saat diterima" (overwrite on receive):
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # Lewati draf pemikiran
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # Tindih terus, ambil yang terakhir
# Setelah stream selesai, current_image adalah gambar akhir
🎯 Optimasi Streaming: Dari sisi pengalaman pengguna, Anda bisa menampilkan draf pemikiran ke frontend untuk memberikan kesan "pratinjau sedang memuat", lalu menggantinya saat gambar akhir tiba—"penyajian progresif" seperti ini sangat disukai di produk konsumen. APIYI apiyi.com mendukung penuh protokol SSE streaming Gemini, sehingga pengalaman di sisi frontend sama persis seperti koneksi langsung.
Kaitan Pemikiran Gambar Gemini 3 dengan Metrik Bisnis
Data Kuantitatif Peningkatan Kualitas
Berdasarkan pengungkapan resmi Google dan pengujian komunitas, mengaktifkan thinking memberikan peningkatan kualitas gambar yang signifikan:
| Metrik | Gemini 2.5 Flash Image | Gemini 3 Pro Image (thinking) | Peningkatan |
|---|---|---|---|
| Akurasi render teks panjang | ~70% | ~95% | +35% |
| Konsistensi multi-subjek (5 orang) | ~60% | ~90% | +50% |
| Kepatuhan komposisi kompleks | ~75% | ~92% | +22% |
| Tingkat keberhasilan gambar pertama | ~80% | ~95% | +18% |
Konsekuensinya adalah waktu respons meningkat 40-80% dan biaya token naik 20-40%. Apakah ini sepadan? Bergantung pada skenario bisnis Anda:
- Aset desain profesional, materi iklan: Peningkatan kualitas jauh melebihi kenaikan biaya, sangat disarankan.
- UGC (konten buatan pengguna), konten massal: Disarankan menggunakan Flash +
thinking_level=minimaluntuk menjaga keseimbangan. - Interaksi real-time, chatbot: Prioritaskan kecepatan respons, Flash lebih cocok digunakan.
🎯 Saran Pengujian A/B: Jangan memilih model hanya berdasarkan perasaan. Kami menyarankan untuk membuat kunci API terpisah bagi kedua model di APIYI apiyi.com, lakukan pembagian lalu lintas 50/50 di sisi bisnis, lalu bandingkan metrik kepuasan pengguna yang nyata (tingkat like, tingkat regenerasi, tingkat konversi) setelah 7 hari—data akan menunjukkan model mana yang benar-benar sepadan dengan biayanya.
FAQ Gemini 3 Pemikiran Gambar
Q1: Mengapa kode pembuatan gambar saya "terkadang menghasilkan produk setengah jadi" setelah upgrade ke Gemini 3?
Karena Gemini 3 Pro Image secara default mengaktifkan thinking, respons mungkin berisi 1-3 gambar. Kemungkinan besar kode lama Anda mengambil parts[0], padahal parts[0] bisa jadi adalah sketsa. Solusi perbaikan: Ubah kode Anda untuk memfilter thought: true + ambil gambar terakhir yang bukan merupakan proses berpikir.
Q2: Apakah platform APIYI (apiyi.com) juga memiliki perilaku thinking pada antarmuka gambar Gemini 3?
Sepenuhnya sama. APIYI apiyi.com menggunakan arsitektur penerusan transparan; thought, thought_signature, dan inline_data dalam respons asli Gemini diteruskan apa adanya tanpa dipisah atau ditulis ulang. Anda dapat mengarahkan kode yang sebelumnya terhubung langsung ke Google AI Studio ke APIYI tanpa mengubah satu karakter pun; struktur responsnya sepenuhnya kompatibel.
Q3: Bisakah saya memaksa API hanya mengembalikan gambar final menggunakan parameter tertentu?
Tidak bisa. Dokumentasi resmi menyatakan dengan jelas bahwa "Fitur ini diaktifkan secara default dan tidak dapat dimatikan di API". Namun, Anda bisa mengatur include_thoughts: false agar respons tidak berisi teks proses berpikir—tetapi sketsa gambar mungkin tetap ada, jadi pemfilteran di level kode tetap wajib dilakukan.
Q4: Thinking membuat latensi respons menjadi lebih tinggi, bagaimana cara mengoptimalkannya?
Ada tiga cara:
- Untuk skenario sederhana, ganti ke
gemini-3-flash-image+thinking_level=minimal. - Jika kebutuhan tidak kompleks, buat petunjuk lebih presisi untuk menghindari model "berpikir berlebihan".
- Gunakan streaming response agar pengguna melihat sketsa proses berpikir terlebih dahulu, dan gambar final muncul di akhir.
Q5: Bagaimana cara memastikan apakah thinking benar-benar terjadi dalam respons?
Periksa kolom response.usage_metadata.thoughts_token_count—jika nilainya lebih besar dari 0, berarti thinking memang terpicu. Nilai ini juga membantu Anda memperkirakan biaya inferensi sebenarnya.
Q6: Bisakah saya membuat atau memodifikasi thought_signature sendiri?
Tidak bisa. thought_signature adalah kredensial terenkripsi yang diterbitkan oleh server Google untuk memverifikasi kontinuitas konteks dalam percakapan multi-putaran. Signature yang dibuat sendiri akan ditolak oleh server. Saat melakukan pengeditan multi-putaran, cukup kirim balik bagian (part) yang berisi signature tersebut.
Q7: Bagaimana cara menangani ketidakpastian yang disebabkan oleh thinking saat membuat 100 gambar secara batch?
Kami sarankan untuk memproses respons setiap permintaan secara independen dan mencatat thoughts_token_count. Anda dapat memeriksa konsumsi token per pemanggilan di dasbor APIYI apiyi.com, lalu memfilter permintaan dengan konsumsi thinking yang tidak wajar untuk diperiksa ulang. Untuk skenario batch, pertimbangkan menggunakan Batch API (didukung oleh Gemini 3 Pro Image) karena biaya lebih hemat setengah dan respons dapat diproses secara asinkron.
Ringkasan Pemikiran Gambar Gemini 3 dan Daftar Tindakan
Melihat kembali keseluruhan konten, Pemikiran Gambar Gemini 3 menghadirkan peningkatan kualitas sekaligus mengubah struktur respons secara total. Ringkasannya:
✅ Prinsip Utama: Jangan pernah mengambil
parts[0]secara kaku, selalu filterthought: true, dan selalu ambilinline_dataterakhir sebagai gambar final.

Daftar Periksa Migrasi
Jika proyek Anda ditingkatkan dari Gemini 2.5 ke Gemini 3, periksa poin berikut:
- Ganti ID Model:
gemini-2.5-flash-image→gemini-3-pro-image-previewataugemini-3-flash-image. - Tulis Ulang Parsing Respons: Ubah semua
parts[0]menjadi "filter thought + ambil yang terakhir". - Tambahkan Penanganan Signature: Pertahankan part yang berisi
thought_signaturedalam percakapan multi-putaran. - Verifikasi Estimasi Biaya: Perhatikan bahwa token thinking dihitung sebagai output, biaya mungkin naik 20-40%.
- Uji Regresi: Siapkan 20+ contoh prompt, bandingkan output Gemini 2.5 dan Gemini 3 agar tidak terjadi penurunan kualitas secara diam-diam.
Templat Integrasi Cepat
Gunakan kode berikut sebagai "templat emas" untuk tim Anda; semua pemanggilan bisnis harus melalui cara ini:
def extract_final_image(response):
"""Mengekstrak gambar final dengan aman dari respons Gemini 3 Image"""
parts = response.candidates[0].content.parts if response.candidates else []
# Cari gambar non-thought pertama dari belakang
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # base64 bytes
return None # Gambar final tidak ditemukan, perlu coba lagi
🎯 Saran Terakhir: Mekanisme thinking pada gambar Gemini 3 adalah pedang bermata dua—jika digunakan dengan benar, Anda mendapatkan kualitas gambar kelas atas, namun jika salah, hasilnya bisa menjadi produk setengah jadi yang "acak". Kami menyarankan setelah terhubung melalui APIYI apiyi.com, lakukan uji regresi terlebih dahulu dengan 10-20 prompt bisnis nyata untuk memastikan kode Anda dapat mengekstrak gambar final dengan benar di berbagai status pemicu thinking sebelum masuk ke tahap produksi. Platform ini mendukung seluruh lini model Gemini 3 dengan respons API yang sepenuhnya sama dengan resmi Google.
Penulis: Tim Teknis APIYI | Untuk tutorial pembuatan gambar AI lainnya, kunjungi help.apiyi.com