عند استخدام واجهة Gemini 3 Pro Image لتوليد الصور، قد تلاحظ أن الصور التي تحصل عليها تبدو "غريبة": تكوين غير متزن، تفاصيل ناقصة، أو حتى مشوهة. هذا ليس تراجعاً في أداء النموذج، بل هو خطأ في آلية اختيار الصورة؛ فمن المرجح أن الصورة الأولى هي "مسودة تفكير" للنموذج، بينما الصورة الحقيقية النهائية هي آخر صورة في الاستجابة.
يعتمد هذا المقال على وثائق Google AI الرسمية، حيث نفكك آلية تفكير الصور في Gemini 3، ونشرح سبب إرجاع استدعاء واحد لصور متعددة، وكيفية تحديد الصورة النهائية بدقة باستخدام حقل part.thought وتوقيع thought_signature. كما نقدم أمثلة برمجية بلغات Python وNode.js وcURL. كل الأمثلة مبنية على خدمة وكيل API الخاص بـ APIYI (apiyi.com)، حيث تحتفظ خدمة الوكيل بهيكل استجابة Gemini الأصلي بالكامل، ما عليك سوى معالجته وفقًا للمواصفات الرسمية.
المبدأ الأساسي لآلية تفكير الصور في Gemini 3
قبل كتابة الكود، دعنا نوضح السبب الجوهري وراء إرجاع استدعاء واحد لصور متعددة.
لماذا لا يمكن تعطيل التفكير في صور Gemini 3
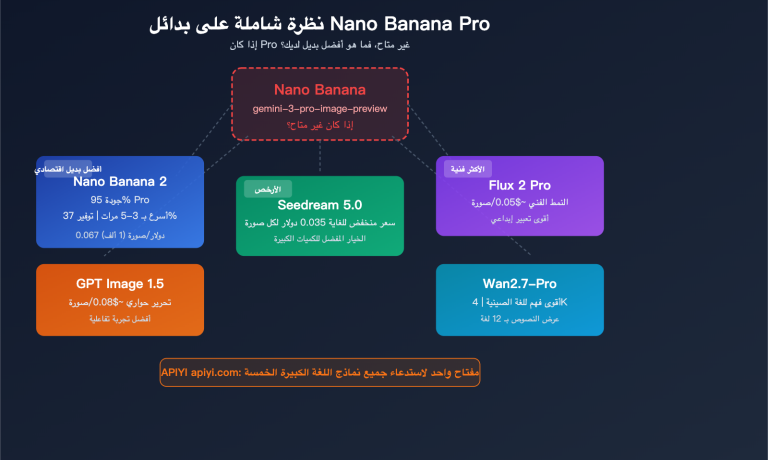
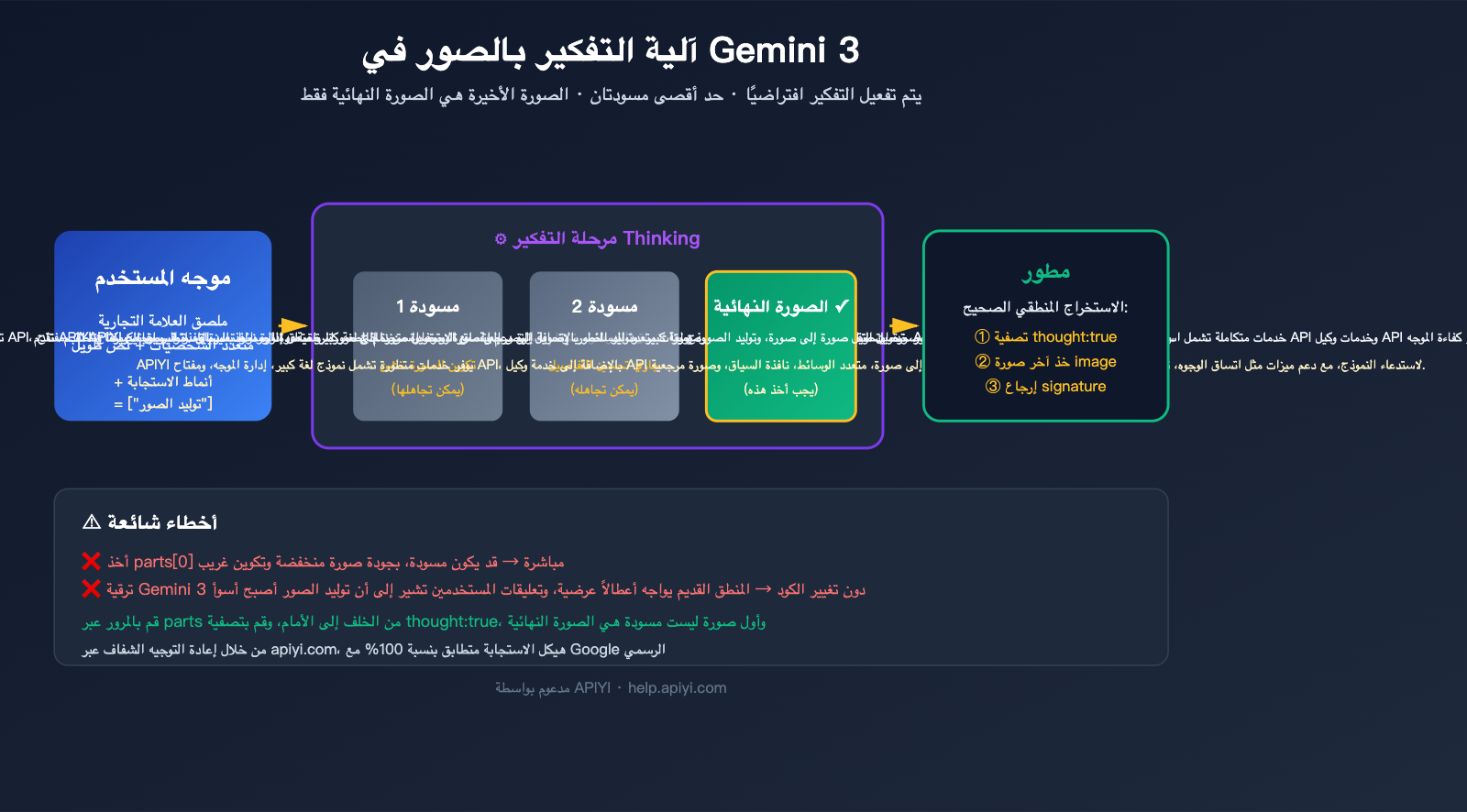
قدمت Google في نموذج gemini-3-pro-image-preview (المعروف تجارياً بـ Nano Banana Pro) آلية "تفكير" (Thinking) تماثل تلك الموجودة في نماذج النصوص؛ حيث يقوم النموذج قبل إخراج الصورة النهائية بتجربة تكوين الصورة وتنسيق العناصر والنصوص باستخدام ما يصل إلى صورتين مؤقتیين، تماماً مثلما يقوم المصمم برسم المسودة قبل العمل النهائي.
توضح الوثائق الرسمية 3 حقائق أساسية:
| الحقيقة | الشرح |
|---|---|
| مفعل افتراضياً ولا يمكن إيقافه | خاصية التفكير مفعلة إجبارياً على مستوى الـ API، ولا يوجد بارامتر لإيقافها |
| ما يصل إلى صورتين مؤقتیين | قد يقوم النموذج بإنشاء صورتين للمسودة بحد أقصى، وليس دائماً |
| الصورة الأخيرة هي النهائية | الصورة الأخيرة في مرحلة التفكير هي النتيجة النهائية المعتمدة |
| استهلاك الـ Token | حتى لو لم تطلب إرجاع محتوى التفكير، يتم استهلاك رموز التفكير وحساب تكلفتها |
بكلمات أخرى، الاستجابة التي تحصل عليها تحتوي بطبيعتها على صور متعددة، هذا ليس خطأ برمجياً (Bug)، بل هو تصميم. السؤال ليس "كيف نعطلها"، بل "كيف نستخرج الصورة النهائية بشكل صحيح".
🎯 فهم المعمارية: تشترك آلية تفكير الصور في Gemini 3 مع محرك التفكير في نموذج النصوص Gemini 3 Pro في نفس المحرك الأساسي. وهذا يفسر سبب تفوق Nano Banana Pro بشكل ملحوظ في توليد النصوص داخل الصور واتساق الوجوه مقارنة بالإصدارات السابقة. عند الاستدعاء عبر APIYI (apiyi.com)، تظل جميع سلوكيات التفكير متطابقة تماماً مع الاتصال المباشر بـ Google، حيث لا تقوم خدمة الوكيل بحذف أي بيانات متعلقة بالتفكير.
مراجعة لأخطاء المطورين الشائعة
السيناريو الأكثر شيوعاً للفشل بين المستخدمين هو:
استدعاء الـ API ← الحصول على الاستجابة ← الوصول لمصفوفة parts ← أخذ الصورة من parts[0] مباشرة ← عرضها للمستخدم
كان هذا الكود يعمل بشكل جيد في عصر Nano Banana السابق (Gemini 2.5 Flash Image)، لأن ذلك الإصدار كان يرجع صورة واحدة فقط. بعد الترقية إلى Gemini 3 Pro Image، سيقوم نفس الكود باعتبار "مسودة التفكير" هي المنتج النهائي، وبالتالي يرى المستخدم نتيجة مشوهة لا تطابق الموجه (Prompt) الخاص به.
هذا الخطأ خفي بشكل خاص لأن:
- ليس دائماً يحدث فشل: في الموجهات البسيطة، قد لا يقوم النموذج بتفعيل خاصية التفكير، فيرجع صورة واحدة فقط.
- لا توجد رسائل خطأ: بنية الاستجابة قانونية، والوصول إلى
parts[0]لا يسبب استثناءً (Exception). - جودة منخفضة ولكن توجد صورة: يعتقد المستخدم أن النموذج ضعيف، بينما في الواقع هو اختيار خاطئ للصورة.
إن فهم ما قد تعيده عملية استدعاء واحدة من واجهة برمجة التطبيقات (API) هو الخطوة الأساسية للتعامل معها بشكل صحيح.
مصفوفة parts في الاستجابة الكاملة
عندما يتم تفعيل "التفكير" (Thinking) في نموذج Gemini 3 Pro Image، قد تبدو مصفوفة response.candidates[0].content.parts هكذا:
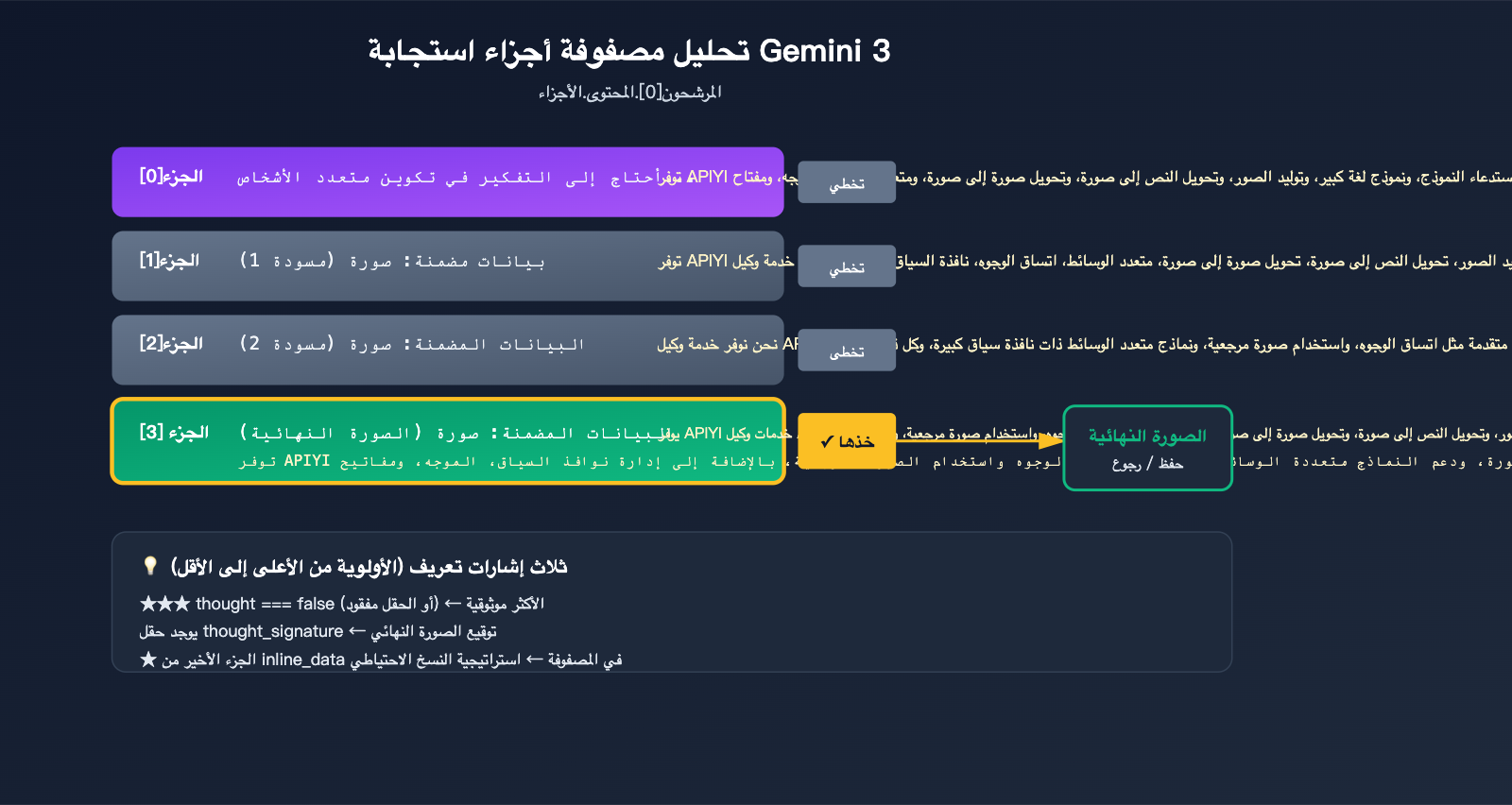
candidates[0].content.parts = [
{ text: "يجب أن أضع التكوين في الاعتبار...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // مسودة 1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // مسودة 2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } // الصورة النهائية
]
سوء فهم هذه المصفوفة هو السبب وراء معظم الأخطاء البرمجية. تذكر القواعد الثلاث التالية لتتمكن من كتابة شيفرة صحيحة.
3 إشارات رسمية لتحديد الصورة النهائية
قدمت جوجل 3 إشارات لتحديد الصورة النهائية، استخدمها حسب الأولوية:
| الأولوية | إشارة التحديد | الشرح | الموثوقية |
|---|---|---|---|
| ★★★ | part.thought === false (أو الحقل مفقود) |
جزء محدد بوضوح على أنه ليس جزءاً من التفكير | الأعلى |
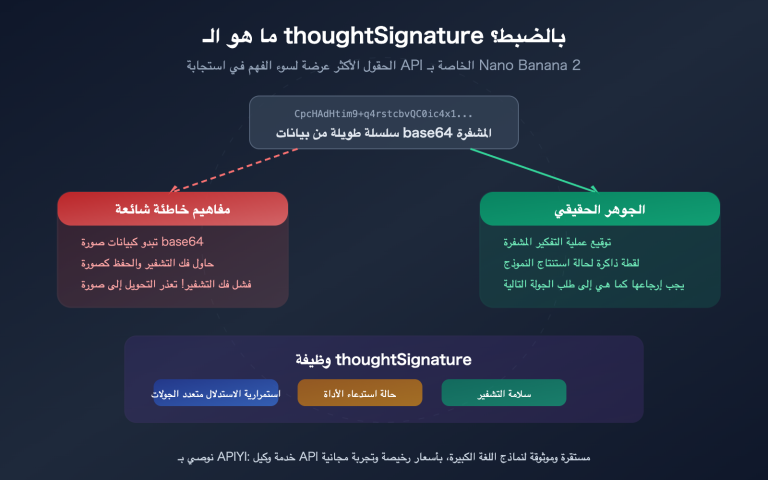
| ★★ | وجود حقل thought_signature |
الصورة النهائية فقط تحتوي على توقيع، المسودات لا تحتوي عليه | عالية |
| ★ | آخر عنصر inline_data في المصفوفة |
الوثائق الرسمية تؤكد أن "الصورة الأخيرة هي الصورة النهائية" | احتياطية |
الطريقة الأكثر استقراراً هي استخدام مزيج منها: ابحث أولاً عن حقل thought، إذا لم تجده استخدم thought_signature كخيار احتياطي، وإذا فشل ذلك، خذ آخر عنصر inline_data.
فروقات thinking_level في نموذج Gemini 3.1 Flash Image
من المهم ملاحظة أن سلوك نماذج الصور في Gemini ليس موحداً:
| النموذج | التفكير الافتراضي | مستوى التفكير القابل للضبط | سيناريو الاستخدام |
|---|---|---|---|
gemini-3-pro-image-preview |
إجباري | ❌ غير قابل للضبط | دقة عالية، مواد احترافية |
gemini-3-flash-image |
افتراضي minimal | ✅ minimal / high | تفاعل لحظي، توليد دفعات |
gemini-2.5-flash-image |
لا يوجد تفكير | – | توافق مع الإصدارات القديمة |
يمكنك ضبط thinking_level في Gemini 3.1 Flash يدوياً للحصول على تكوين أدق أو لتقليل وقت الاستجابة، وهي مرونة غير متاحة في إصدار Pro.
🎯 نصيحة اختيار النموذج: عند بناء وظيفة توليد صور للمستخدمين النهائيين، ننصح باستخدام
gemini-3-flash-imageمعthinking_level=minimal(أسرع وأرخص)، والتحول إلىgemini-3-pro-image-previewعندما يضغط المستخدم على "وضع الجودة العالية" (للحصول على تفكير ودقة عالية). على منصة APIYI (apiyi.com)، يمكنك التبديل بين النموذجين بسلاسة باستخدام نفس مفتاح الـ API و base_url.
المعالجة الصحيحة لـ "تفكير الصور" في Gemini 3
بعد أن فهمنا الجانب النظري، دعونا ننتقل إلى الكود. تستند جميع الأمثلة التالية إلى خدمة وكيل APIYI (apiyi.com) — كل ما عليك فعله في كود الاتصال المباشر بـ Google AI Studio هو تغيير base_url إلى عنوان APIYI، وتبديل api_key بمفتاح APIYI الخاص بك، وستظل منطقية معالجة الاستجابة كما هي دون أي تغيير.
الطريقة الصحيحة باستخدام Python SDK الرسمي
from google import genai
client = genai.Client(
api_key="sk-your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="كلب من فصيلة شيبا إينو بأسلوب سايبربانك، يقف تحت لافتة نيون، دقة 4K",
config={"response_modalities": ["IMAGE"]}
)
# ✅ صحيح: استبعاد جميع أجزاء التفكير (thought parts)، والاحتفاظ بالصورة النهائية فقط
for part in response.parts:
if getattr(part, "thought", False):
continue # تخطي مسودة التفكير
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("final_output.png")
break # أول صورة ليست "تفكير" هي الصورة النهائية
مثال خاطئ (كود يقع فيه المستخدمون عادة):
# ❌ خطأ: أخذ الصورة الأولى مباشرة، قد تحصل على مسودة تفكير
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# الصورة المولدة قد تكون مجرد عمل غير مكتمل
الطريقة الصحيحة باستخدام Node.js / TypeScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "كلب من فصيلة شيبا إينو بأسلوب سايبربانك، يقف تحت لافتة نيون، دقة 4K",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ التكرار من النهاية إلى البداية، أول صورة ليست "تفكير" هي الصورة النهائية
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
إصدار سطر الأوامر (cURL + jq)
إذا كنت تستخدمه في سكربت Shell، يمكنك استخدام jq للتصفية:
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "كلب من فصيلة شيبا إينو بأسلوب سايبربانك"}]
}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
هذا التعبير في jq يقوم بثلاث مهام: تصفية thought: true، الاحتفاظ فقط بـ MIME type الخاص بالصور، وأخذ last (الأخير) — وهو ما يتوافق تماماً مع القواعد الثلاث الرسمية للتعرف.
🎯 نقاط مراجعة الكود: عند مراجعة الكود، تأكد دائماً من وجود تصفية لـ
thought. نوصي بتغليف دالة موحدة باسمextractFinalImage()داخل فريقك، ليستخدمها الجميع وتجنب الأخطاء. عند الاتصال عبر APIYI (apiyi.com)، يمكنك اختبار هذا الكود محلياً وإعادة استخدامه في البيئة الإنتاجية مباشرة.
مواضيع متقدمة في "تفكير الصور" لـ Gemini 3
التعديلات متعددة الجولات تتطلب تمرير thought_signature
يدعم نموذج Nano Banana Pro "التعديل المستمر" — حيث يطلب المستخدم "غيّر الخلفية إلى شاطئ"، ثم "اجعل تعبير الكلب سعيداً" — لكن تطلب Google صراحة تمرير thought_signature الخاص بالجولة السابقة في المحادثات متعددة الجولات، وإلا لن يتمكن النموذج من متابعة سياق الاستنتاج السابق، وستنخفض الجودة بشكل ملحوظ.
الطريقة الصحيحة للجولات المتعددة:
# الجولة الأولى
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="كلب شيبا إينو يركض في حديقة"
)
# استخراج كائن part الخاص بالصورة النهائية (يحتوي على thought_signature)
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# الجولة الثانية: إضافة final_part بالكامل إلى التاريخ
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "كلب شيبا إينو يركض في حديقة"}]},
{"role": "model", "parts": [final_part]}, # يحتوي على thought_signature
{"role": "user", "parts": [{"text": "غيّر الخلفية إلى غروب الشمس على الشاطئ"}]}
]
)
عرض عملية التفكير (لأغراض التصحيح)
إذا كنت ترغب في رؤية "ما فكر فيه" النموذج، يمكنك تفعيل include_thoughts:
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="موجّه ملصق ترويجي لعلامة تجارية معقدة...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# طباعة عملية التفكير
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[تفكير] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"draft_{id(part)}.png") # حفظ المسودة
هذا مفيد جداً عند تصحيح سبب "عدم رضاك عن النتيجة"؛ فمشاهدة المسودات تساعدك على استنتاج أي جزء من الموجّه (prompt) قد أسيء فهمه.

منطق الفوترة لرموز التفكير (Thinking tokens)
تتطلب فوترة Gemini 3 Pro Image انتباهاً خاصاً من المطورين:
| نوع الرمز (Token) | السعر (لكل مليون) | هل هو إجباري؟ |
|---|---|---|
| المدخلات (prompt) | $2 | ✅ نعم |
| المخرجات (صورة/نص) | $12 | ✅ نعم |
| استنتاج التفكير | يُحتسب كرمز مخرج | ✅ إجباري، لا يمكن إيقافه |
هذا يعني أنه حتى لو كنت تريد فقط الصورة النهائية ولا تهتم بعملية التفكير، فإن رموز التفكير سيتم توليدها واحتساب تكاليفها. ما يمكنك توفيره فقط هو "هل يتم إرسال محتوى التفكير إليك" (معامل include_thoughts)، أما "هل يتم تنفيذ التفكير" فلا يمكن توفيره.
🎯 نصيحة لتحسين التكلفة: للمشاهد البسيطة (مثل توليد صور المنتجات، الرسوم التوضيحية)، استخدم
gemini-3-flash-imageمع ضبطthinking_level=minimal؛ فالتكلفة ستكون أقل بكثير من نسخة Pro. أما للمشاهد المعقدة (مثل اتساق العناصر المتعددة، عرض النصوص عالية الدقة)، انتقل إلى Pro. نوصي باستخدام مراقبة الاستهلاك عند الاتصال عبر APIYI (apiyi.com)، ومقارنة تكلفة/جودة النموذجين في سياق عملك قبل اعتماد الإعداد الإنتاجي.
دليل عملي لاستكشاف أخطاء Gemini 3 في معالجة الصور والتفكير
المشكلة 1: الحصول دائمًا على صور منخفضة الجودة
خطوات التشخيص:
# طباعة حقل التفكير (thought) لجميع الأجزاء (parts)
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"الجزء {i}: التفكير={is_thought}, الصورة={has_image}, التوقيع={has_sig}")
إذا كانت المخرجات تحتوي على أجزاء متعددة فيها image=True، فهذا يعني ببساطة أن "النموذج أعاد أكثر من صورة". تأكد مما إذا كان كود البرمجة الخاص بك يأخذ الجزء الأول (indexed part) فقط.
المشكلة 2: غياب حقل التفكير (thought) في هيكل الاستجابة
السبب المحتمل: أنت تستخدم JSON الخام المسترجع من REST API. التسمية القياسية هي thought، لكن في بعض إصدارات SDK قد يتم تحويل الحقول إلى نمط snake_case. يجب أن يدعم كودك الحالتين:
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
المشكلة 3: الرغبة في حفظ جميع الصور (للتحليل)
الطريقة الكاملة الموصى بها رسمياً للمرور على كافة الأجزاء:
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "draft" if is_draft else "final"
filename = f"gemini_output_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"تم الحفظ: {filename}")
مواءمة Gemini 3 في سيناريوهات الأعمال الحقيقية
بعيداً عن النظرية والكود الأساسي، هناك تفاصيل هامة يجب مراعاتها في بيئات العمل المختلفة.
السيناريو 1: عرض الصور المولدة مباشرة في الواجهة الأمامية (Web Frontend)
عندما تستلم الواجهة الأمامية صورة بصيغة base64، يجب تحويلها إلى data:image/png;base64,xxx لعرضها. تنبيه: لا تقم بعملية تصفية التفكير (thought filtering) في الواجهة الأمامية، دع الخلفية (Backend) تعيد نتائج نظيفة، وإلا فسيضطر المتصفح للتعامل مع هيكل استجابة Gemini المعقد:
// ❌ لا يُنصح به: معالجة استجابة Gemini الخام مباشرة في الواجهة الأمامية
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ يُنصح به: التصفية الموحدة في الخلفية، بحيث تستهلك الواجهة الأمامية الصورة النهائية فقط
// الخلفية تعيد API بالتنسيق: { "image": "base64-string" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
السيناريو 2: توليد الصور + الحفظ في OSS / CDN
عند التوليد بكميات كبيرة والحفظ في مساحة التخزين السحابي (OSS)، استخدم "البصمة" (Hash) لمنع التكرار:
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
احرص دائماً على رفع الصورة النهائية فقط، حيث أن مسودات التفكير ستستهلك مساحة التخزين وتزيد من التكاليف دون فائدة.
السيناريو 3: المعالجة الصحيحة للاستجابات المتدفقة (Streaming)
يدعم Gemini 3 خاصية التدفق (streaming)، حيث تصل مسودات التفكير أولاً ثم تليها الصورة النهائية. في سيناريوهات التدفق، نوصي باستراتيجية "الاستبدال أثناء الاستلام":
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # تخطي المسودات
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # استبدال مستمر، تبقى الصورة الأخيرة فقط
# عند انتهاء التدفق، تكون current_image هي الصورة النهائية
🎯 تحسين تجربة التدفق: من منظور تجربة المستخدم، يمكنك عرض مسودات التفكير في الواجهة الأمامية ليعرف المستخدم أن النموذج "يفكر/يحمل"، ثم استبدالها عند وصول الصورة النهائية. هذا النهج التراكمي (Progressive Rendering) محبوب جداً في تطبيقات المستخدمين. توفر منصة APIYI (apiyi.com) دعماً كاملاً لبروتوكول SSE للتدفق الخاص بـ Gemini، مما يضمن توافقاً تاماً في تجربة الواجهة الأمامية.
الربط بين التفكير البصري في Gemini 3 ومؤشرات الأداء
البيانات الكمية لتحسين الجودة
بناءً على الإفصاحات الرسمية من Google والاختبارات المجتمعية، هناك تحسن ملحوظ في جودة الصور بعد تفعيل ميزة التفكير (Thinking):
| المؤشر | Gemini 2.5 Flash Image | Gemini 3 Pro Image (thinking) | نسبة التحسن |
|---|---|---|---|
| دقة عرض النصوص الطويلة | ~70% | ~95% | +35% |
| اتساق الوجوه المتعددة (5 أشخاص) | ~60% | ~90% | +50% |
| الامتثال للتكوينات المعقدة | ~75% | ~92% | +22% |
| معدل جاهزية الصورة الأولى | ~80% | ~95% | +18% |
الضريبة هي زيادة زمن الاستجابة بنسبة 40-80%، وارتفاع تكلفة التوكن بنسبة 20-40%. هل يستحق الأمر ذلك؟ يعتمد على طبيعة عملك:
- مواد التصميم الاحترافية، مواد الإعلانات: تحسن الجودة يفوق تكلفة الزيادة بكثير، نوصي به بشدة.
- توليد الصور للمستخدمين (UGC)، المحتوى المجمع: نوصي باستخدام Flash مع ضبط
thinking_level=minimalلتحقيق التوازن. - التفاعل اللحظي، روبوتات الدردشة: الأولوية لسرعة الاستجابة، لذا فإن استخدام Flash هو الخيار الأنسب.
🎯 نصيحة لاختبار A/B: لا تختر النموذج بناءً على الحدس. نوصي بإنشاء مفتاح API لكل نموذج عبر منصة APIYI (apiyi.com)، وتوزيع حركة المرور بنسبة 50/50 على مستوى العمل، ثم مقارنة مؤشرات رضا المستخدم الحقيقية (معدل الإعجاب، معدل إعادة التوليد، معدل التحويل) بعد 7 أيام – فالأرقام ستخبرك أي نموذج يستحق تكلفته فعلياً.
الأسئلة الشائعة حول التفكير البصري في Gemini 3
س1: لماذا بدأت كودات توليد الصور الخاصة بي تنتج "نتائج غير مكتملة أحياناً" بعد الترقية إلى Gemini 3؟
لأن Gemini 3 Pro Image يُفعّل التفكير افتراضياً، وقد تحتوي الاستجابة على 1-3 صور. كودك القديم على الأرجح يسحب parts[0]، وقد تكون parts[0] مجرد مسودة. الحل: عدّل الكود ليقوم بتصفية thought: true واختيار آخر صورة ليست ضمن التفكير.
س2: هل تتوفر خاصية التفكير في واجهات Gemini 3 على منصة APIYI؟
نعم، وبشكل مطابق تماماً. منصة APIYI (apiyi.com) تعتمد بنية إعادة توجيه شفافة، حيث يتم تمرير thought و thought_signature و inline_data من استجابة Gemini الأصلية كما هي تماماً، دون أي تعديل أو حذف. يمكنك توجيه الكود الذي كان يتصل مباشرة بـ Google AI Studio إلى APIYI دون تغيير حرف واحد، فبنية الاستجابة متوافقة كلياً.
س3: هل يمكن فرض إرجاع الصورة النهائية فقط عبر معامل معين؟
لا يمكن. توضح الوثائق الرسمية أن هذه الميزة مفعلة افتراضياً ولا يمكن إيقافها في واجهة برمجة التطبيقات (API). ولكن يمكنك ضبط include_thoughts: false لجعل الاستجابة خالية من نصوص التفكير – ومع ذلك، قد تظل مسودات الصور موجودة، لذا فإن التصفية على مستوى الكود تظل ضرورية.
س4: أدى التفكير إلى زيادة زمن الاستجابة، كيف يمكنني تحسين ذلك؟
هناك ثلاثة مسارات:
- في السيناريوهات البسيطة، انتقل إلى
gemini-3-flash-imageمعthinking_level=minimal. - عندما لا تكون المتطلبات معقدة، اكتب الموجه (prompt) بدقة أكبر لتجنب "الإفراط في التفكير" من قبل النموذج.
- استخدم الاستجابة المتدفقة (streaming) ليتمكن المستخدم من رؤية مسودات عملية التفكير أولاً، مع وصول الصورة النهائية في النهاية.
س5: كيف يمكنني التأكد من حدوث "التفكير" (thinking) بالفعل في الاستجابة؟
تحقق من حقل response.usage_metadata.thoughts_token_count؛ إذا كانت قيمته أكبر من 0، فهذا يعني أن التفكير قد تم تفعيله فعلياً. تساعدك هذه القيمة أيضاً في تقدير تكلفة الاستدلال الفعلية.
س6: هل يمكنني بناء أو تعديل thought_signature بنفسي؟
لا يمكن. thought_signature هي شهادة مشفرة صادرة عن خادم Google، وتُستخدم للتحقق من استمرارية السياق في المحادثات المتعددة الجولات. أي توقيع منشأ ذاتياً سيتم رفضه من قبل الخادم. عند التعديل في المحادثات متعددة الجولات، قم ببساطة بإعادة الجزء الذي يحتوي على signature كما هو.
س7: كيف أتعامل مع عدم اليقين الناتج عن التفكير عند توليد 100 صورة دفعة واحدة؟
نوصي بمعالجة استجابة كل طلب بشكل مستقل، مع تسجيل thoughts_token_count. يمكنك مراجعة استهلاك التوكن في لوحة تحكم APIYI (apiyi.com) لكل استدعاء، وتحديد الطلبات التي استهلكت كميات غير طبيعية من التفكير لإعادة فحصها. في سيناريوهات التوليد المجمع، يمكنك أيضاً التفكير في استخدام Batch API (التي يدعمها Gemini 3 Pro Image)، مما يقلل التكلفة للنصف ويسمح بمعالجة الاستجابات بشكل غير متزامن.
ملخص وقائمة التحقق لخاصية التفكير في الصور في Gemini 3
بالنظر إلى المقال كاملاً، أحدثت خاصية التفكير في الصور في Gemini 3 نقلة نوعية في جودة المخرجات، كما غيرت هيكلية الاستجابة بشكل جذري. نلخص ذلك في قاعدة واحدة:
✅ المبدأ الأساسي: لا تعتمد أبداً على
parts[0]بشكل مباشر، قم دائماً بتصفيةthought: true، واحرص دائماً على اختيار آخرinline_dataلتكون هي الصورة النهائية.
قائمة التحقق عند الترقية
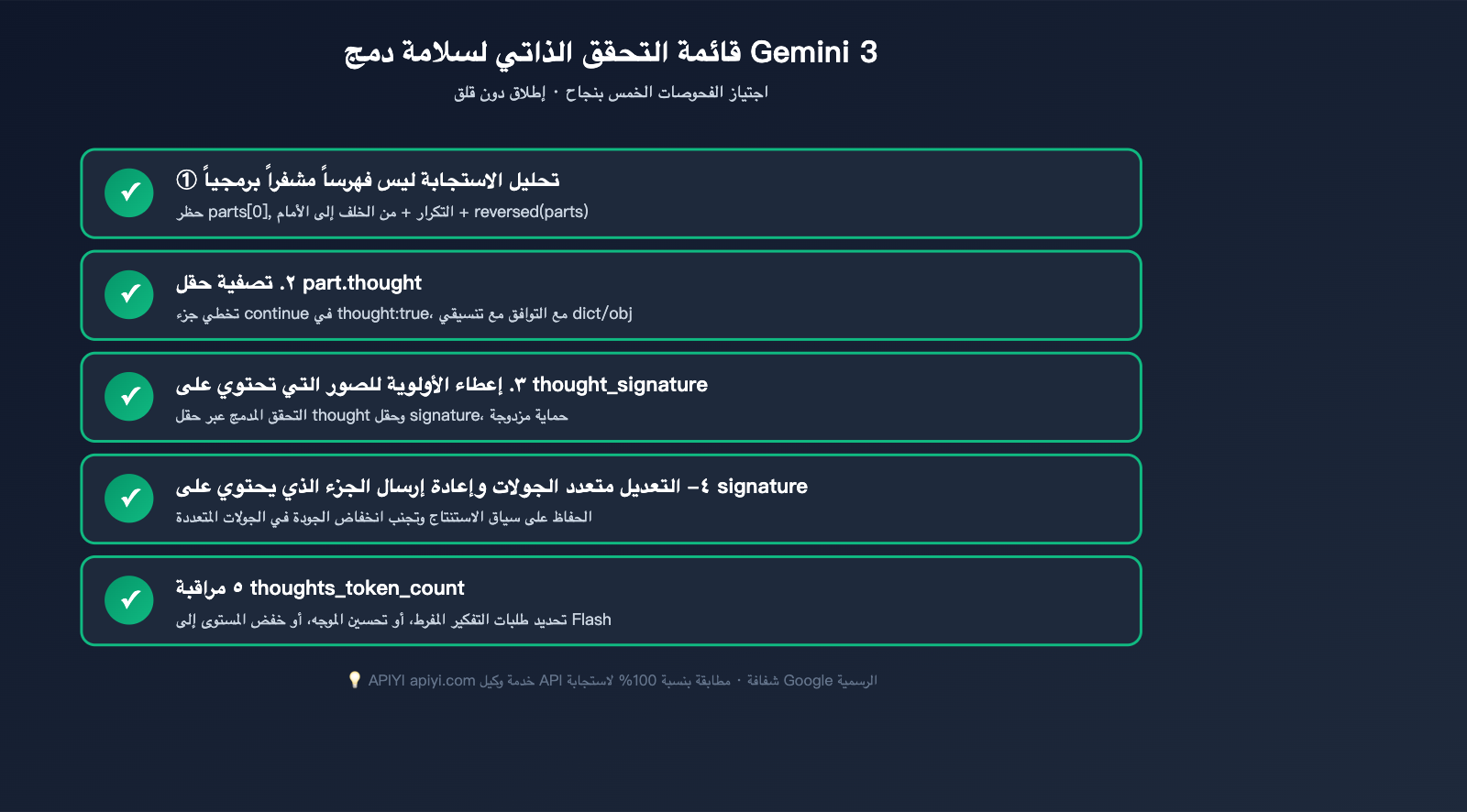
إذا كان مشروعك ينتقل من Gemini 2.5 إلى Gemini 3، اتبع هذه القائمة:
- تحديث معرف النموذج: استبدل
gemini-2.5-flash-imageبـgemini-3-pro-image-previewأوgemini-3-flash-image. - إعادة كتابة تحليل الاستجابة: قم بتغيير كل اعتماد على
parts[0]إلى منطق "تصفية thought + اختيار الصورة الأخيرة". - معالجة التوقيع (Signature): احتفظ بالجزء (part) الذي يحتوي على
thought_signatureفي المحادثات متعددة الجولات. - التحقق من التكلفة: لاحظ أن الرموز المميزة للتفكير (thinking tokens) تُحتسب ضمن المخرجات، مما قد يزيد التكلفة بنسبة 20-40%.
- اختبارات الانحدار: جهز أكثر من 20 عينة من الموجهات، وقارن مخرجات Gemini 2.5 مع Gemini 3 لتجنب أي تراجع غير متوقع في الأداء.
قالب الدمج السريع
استخدم الكود التالي كـ "قالب ذهبي" لفريقك، واعتمد عليه في جميع استدعاءات النموذج:
def extract_final_image(response):
"""استخراج الصورة النهائية بأمان من استجابة Gemini 3"""
parts = response.candidates[0].content.parts if response.candidates else []
# البحث من الخلف للأمام عن أول عنصر صورة ليس من نوع التفكير
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # base64 bytes
return None # لم يتم العثور على الصورة النهائية، يلزم إعادة المحاولة
🎯 نصيحة أخيرة: تُعد آلية التفكير في الصور في Gemini 3 سلاحاً ذا حدين؛ فإذا استخدمتها بشكل صحيح ستحصل على جودة توليد صور رائدة في الصناعة، أما إذا استخدمتها بشكل خاطئ فقد تحصل على مخرجات غير متوقعة. ننصح عبر منصة APIYI apiyi.com بإجراء اختبارات الانحدار باستخدام 10-20 موجه (prompt) فعلي، للتأكد من أن الكود يستخرج الصورة النهائية بشكل صحيح في حالات "التفكير" المختلفة قبل إطلاقه في بيئة الإنتاج. تدعم المنصة كامل سلسلة نماذج Gemini 3، وتطابق استجابات API الخاصة بها جوجل تماماً.
الكاتب: الفريق التقني لـ APIYI | للمزيد من دروس توليد الصور بالذكاء الاصطناعي، تفضل بزيارة help.apiyi.com