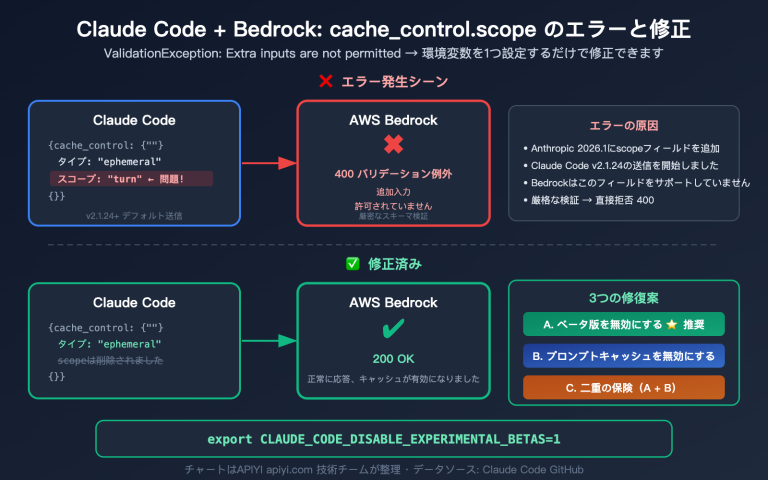
開発者にとって見逃せないアップデート情報をお届けします。ByteDanceのDola大規模言語モデルファミリーに、2026年4月28日、初の全模態(Omnimodal)理解モデル「Seed-2.0-lite-260428」が登場しました。このモデルは、動画、画像、音声、テキストの4つのモダリティのネイティブ入力を統合的にサポートしています。Dola Seedファミリーにおいて「見て、聞く」ことが可能な初のモデルであり、エージェント、コーディング、GUIなどのタスクにおいても強化が図られています。本記事では、BytePlus ModelArkの公式スペックとByteDance Seedの公開ベンチマークに基づき、APIYI(apiyi.com)での接続テストを交えながら、モデルの能力、音声理解の詳細、そして典型的な応用シナリオについて解説します。

一、Seed-2.0-lite-260428とは:核心的な位置付けとアップグレードのポイント
Seed-2.0-lite-260428は、ByteDance Seedが2026年4月28日にリリースした重要なアップデートです。ベースモデルには3月初旬にリリースされたSeed-2.0-Liteを採用していますが、今回初めて「音声入力」をネイティブ機能として追加し、この製品ラインを真の「全模態(Omnimodal)」段階へと引き上げました。モデル名の「260428」は、2026年4月28日というバージョン番号を示しています。
1.1 ByteDance Dolaファミリー初の全模態モデル
これまでのDola Seedファミリーでは、テキスト能力とマルチモーダル能力はそれぞれ異なるブランチで提供されていました。Seed-2.0-lite-260428は、動画、画像、音声、テキストを同一モデル内で推論するため、動画の映像と音声の内容を同時に「見て、聞く」ことができ、それに基づいた統合的な判断や時系列検索が可能です。この統一されたアーキテクチャは、エージェント型アプリケーションにとって非常に重要です。動画審査、会議の議事録作成、カスタマーサポートの品質チェックなど、多くの実際のタスクでは本質的にクロスモーダルな推論が求められるからです。
1.3 モデルの核心スペック概要
以下の表は、BytePlus ModelArkにおけるSeed-2.0-lite-260428の主要なパラメータをまとめたものです。ご自身のビジネスニーズに適合するかどうかを素早く判断する際にお役立てください。
| 項目 | パラメータ詳細 |
|---|---|
| APIモデルID | seed-2-0-lite-260428 |
| モデルファミリー | ByteDance Seed / Dola |
| リリース日 | 2026-04-28 |
| コンテキストウィンドウ | 262,144 tokens(約256K) |
| 最大出力 | 131,072 tokens(約128K) |
| 入力モダリティ | テキスト + 画像 + 動画 + 音声 |
| 入力価格 | $0.25 / M tokens |
| 出力価格 | $2.00 / M tokens |
| インターフェース互換性 | OpenAI Compatible API |
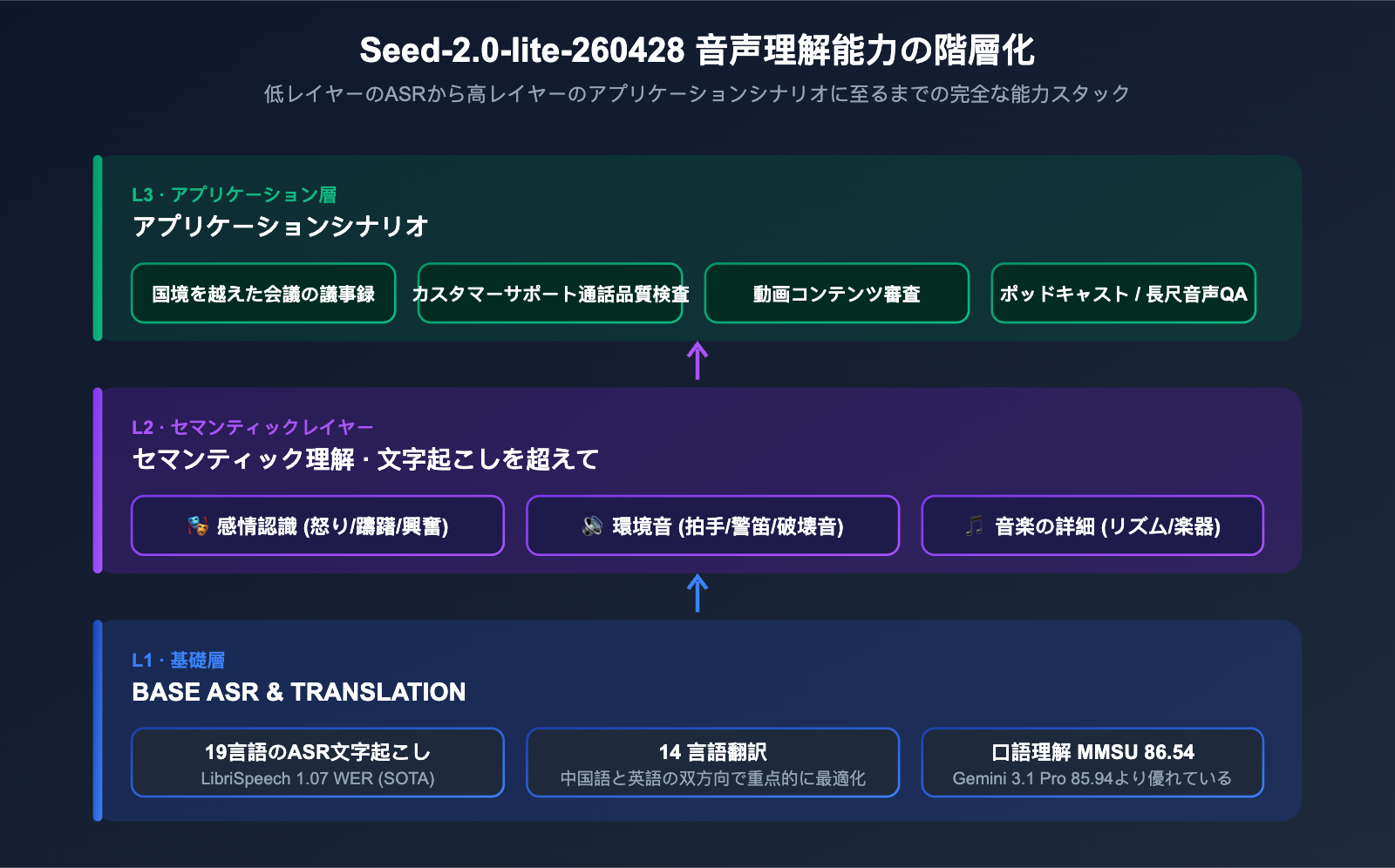
二、Seed-2.0-lite-260428 の全モーダル理解における4つの重要能力
モデルの全モーダル能力とは、単に複数の入力を「つなぎ合わせる」ことではなく、統一された表現を通じて統合的な推論を行うことにあります。公式ドキュメントでは、その核心的な能力を以下の4つの方向に要約しています。
2.1 音声・映像の統合推論と時系列検索
このモデルは、動画内の視覚情報と音声情報を同時に分析し、「目に見える映像」と「耳に聞こえる音声」が一致しているかを正確に判断できます。例えば、動画内の人物の表情が話している内容の感情と合致しているか、あるいは画面内の物体の動きが正しい効果音に対応しているかなどを判定可能です。この音声・映像の整合性チェック能力は、動画の審査やディープフェイク検知などのシナリオで非常に実用的です。
2.2 動画の深度分解と長時系列トラッキング
長尺動画に対して、Seed-2.0-lite-260428 は複数の時間帯から重要な手がかりを抽出し、人物やイベントの進展を継続的に追跡します。また、フレーム間での多段階推論を行い、イベントの関係性や行動のコンテキストを再構築します。フレームごとに記述する従来の手法に比べ、その「長時系列理解」能力は、監視カメラ映像の振り返りやドキュメンタリー制作の編集アシスタントといったタスクにより適しています。
2.3 強化されたエージェントとコーディング能力
このモデルは、複雑な長時系列タスクにおいて安定した実行能力を発揮し、高度なフルスタック開発能力を備えています。つまり、開発者はこれをエージェントフレームワークに組み込むことで、計画立案、ツールの呼び出し、履歴ステップの確認、コード生成といった一連のプロセスを一つのモデルで完結させることができ、タスクを複数の異なるモデルに分割する必要がありません。
2.4 GUI理解と操作実行の統一インターフェース
GUI操作能力が同一のインターフェースに統合されており、モデルはスクリーンショット(ボタン、フォーム、メニューなど)を理解するだけでなく、操作指示(クリック座標の指定、テキスト入力など)を出力することも可能です。これは、自動テスト、デスクトップエージェント、RPA系アプリケーションにとって直接的な能力のアップグレードとなります。
三、Seed-2.0-lite-260428 の音声理解能力の深掘り
今回のアップデートで最も大きな差別化要因となっているのが音声理解能力です。そのため、ここを詳しく解説します。モデルは複数の主要な音声ベンチマークにおいて、非常に優れた成績を収めています。
3.1 主要な音声ベンチマークの測定スコア
以下の表は、ByteDance Seedが公式に公開しているベンチマーク成績をまとめたもので、音声認識(ASR)、口語理解、野外音声シーンの3つの側面をカバーしています。
| ベンチマーク | タスクタイプ | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | 英語 ASR(クリーン) | 1.07 WER |
| LibriSpeech test-other | 英語 ASR(ノイズ) | 2.17 WER |
| WenetSpeech test-net | 中国語 ASR(ネット) | 4.47 WER |
| WenetSpeech test-meeting | 中国語会議 ASR | 5.31 WER |
| Fleurs(15言語) | 多言語 ASR | 74.70 |
| MMSU | 口語理解 | 86.54 |
| WildSpeech | 野外音声 | 75.81 |
LibriSpeech test-clean における 1.07 という WER(単語誤り率)は業界トップクラスの水準であり、公開されている Whisper large-v3 の同種成績を上回っています。MMSU や WildSpeech のスコアも Gemini 3.1 Pro の公開データをわずかに上回っており、単なる「書き起こし」にとどまらず、「理解」のレベルでも主要なフラッグシップモデルと同等の水準に達していることを示しています。
3.2 19言語の文字起こしと14言語の相互翻訳
公式ドキュメントによると、このモデルは19言語の音声文字起こしと14言語間の相互翻訳をサポートしており、中でも中英双方向の翻訳が重点的な最適化対象として挙げられています。これにより、多言語が混在する会議録音から、統一された言語の字幕や翻訳を出力することが可能となり、クロスボーダーチームや越境ECのカスタマーサポートなどのシーンに最適です。
3.3 「文字起こし」を超えて:感情、環境音、音楽の細部まで
従来のASRモデルとの最大の違いは、Seed-2.0-lite-260428 が「文字情報」以外のセマンティック(意味論的)な情報を捉えられる点にあります。話者の感情の揺れ(怒り、迷い、興奮)、背景の環境音(ガラスの割れる音、拍手、車のクラクション)、音楽の細部(リズム、楽器、スタイル)などを把握できます。これらの要素は、カスタマーサポートの品質管理、コンテンツ審査、音楽レコメンデーションなどの業務において直接的な価値をもたらします。
🎯 導入のヒント:クロスボーダー会議の議事録作成、カスタマーサポートの品質管理、動画コンテンツの審査など、「音声+テキスト」の連携が必要なシナリオでは、APIYI (apiyi.com) を通じて Seed-2.0-lite-260428 を呼び出すことを推奨します。1つの base_url でマルチモーダル推論と256Kのロングコンテキストの両方のメリットを享受でき、自前で音声処理パイプラインを構築する必要はありません。
四、Seed-2.0-lite-260428 と主要なマルチモーダルモデルの比較
2026年現在、このモデルがどのような立ち位置にあるのかを判断するために、GPT-4o や Gemini 3 Pro といった同世代のフラッグシップ・マルチモーダルモデルと比較してみましょう。
4.1 主要マルチモーダルモデルの能力比較
| 項目 | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| テキスト入力 | ✓ | ✓ | ✓ |
| 画像入力 | ✓ | ✓ | ✓ |
| 動画入力 | ✓ | ✓ | ✓ |
| 音声入力 | ✓ | ✓ | ✓ |
| コンテキストウィンドウ | 262K | 128K | 1M |
| 入力価格 / M | $0.25 | $2.50 | $1.25 |
| 出力価格 / M | $2.00 | $10.00 | $10.00 |
| 音声感情認識 | ✓ | ✓ | ✓ |
| 中国語音声最適化 | 強(WenetSpeech最適化) | 普通 | 普通 |
ご覧の通り、Seed-2.0-lite-260428 の核心的な強みは「価格・中国語音声・262Kの長大なコンテキスト」の組み合わせにあります。多言語の音動画処理や長時間の会議の振り返りといったタスクにおいて、極めて高いコストパフォーマンスを発揮します。一方、GPT-4o と Gemini 3 Pro は、英語の総合能力やエコシステムの広さで依然として優位性があり、汎用的な用途に適しています。

🎯 選定のアドバイス:中国語の音動画処理がメインで、コストを重視される場合は、Seed-2.0-lite-260428 が現時点で極めて高いコストパフォーマンスを誇る選択肢です。英語が中心、あるいは多言語でのクリエイティブ生成を重視する場合は、APIYI (apiyi.com) の統合ゲートウェイ経由でこれら3社のフラッグシップモデルを接続し、用途に応じてルーティングすることをおすすめします。
五、APIYI を介した Seed-2.0-lite-260428 のクイックスタート
このモデルは OpenAI 形式のインターフェースと完全な互換性があり、移行コストを最小限に抑えられます。以下に、画像や音声を構造化されたテキストに変換するための最小限の呼び出し例を示します。
5.1 OpenAI 互換インターフェースの最小構成例
from openai import OpenAI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "この音声の内容、感情、背景音について説明してください。"},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
base_url を APIYI (apiyi.com) の統合エンドポイントに向け、model を切り替えるだけで、同じ SDK を使用して Seed-2.0-lite-260428 やその他のマルチモーダルモデルを呼び出すことができます。ビジネス側のコードを書き直す必要はありません。
5.2 Seed-2.0-lite-260428 の典型的な活用シーン
以下の表は、典型的な活用シーンと、このモデルの「音声 + 動画 + テキストの統合推論」という特性から得られるメリットをまとめたものです。
| 活用シーン | 主要な能力 | ビジネス価値 |
|---|---|---|
| 国際会議の議事録 | 19言語のASR + 14言語の翻訳 + 256Kのコンテキスト | 多言語会議をワンクリックでバイリンガル議事録に |
| カスタマーサポートの品質管理 | 感情認識 + 環境音検知 + 長尺音声分析 | 怒り/割り込み/時間超過を自動的にマーク |
| 動画コンテンツのモデレーション | 音声・動画の統合推論 + 長時間シーケンス追跡 | 危険な映像と疑わしい音声を同時に識別 |
| ポッドキャスト / 長尺動画のQA | 256Kのロングコンテキスト + 音声文字起こし | 数時間の音声内容に対して直接質問が可能 |
| デスクトップエージェントの自動化 | GUI理解 + ツール呼び出し | アプリケーションを横断した複雑なワークフローの実行 |
六、Seed-2.0-lite-260428 に関するよくある質問(FAQ)
6.1 API 呼び出し時の model フィールドは何を指定すればよいですか?
seed-2-0-lite-260428 をそのまま指定してください。中央はアンダースコアではなくハイフンである点に注意してください。末尾の 260428 はバージョン番号(2026年4月28日)ですので、省略しないでください。省略すると古いバージョンにルーティングされる可能性があります。モデル一覧は APIYI (apiyi.com) のコンソールで確認し、最新のリリースと一致していることを確認してください。
6.2 サポートされている音声フォーマットと長さは?
モデルは OpenAI 形式の input_audio フィールドの規約に従っており、一般的な MP3、WAV、M4A、FLAC 形式をサポートしています。具体的な最大長やサンプリングレートについては、公式の ModelArk ドキュメントを参照してください。推論の安定性を確保するため、1回の入力につき30分以内とすることを推奨します。長時間の音声は、セグメントに分割してから結果を統合してください。
6.3 260428 というサフィックスがない Seed-2.0-Lite との違いは?
サフィックスがないバージョンは3月10日にリリースされた初代 Seed-2.0-Lite で、テキスト、画像、動画のみをサポートしています。260428 は4月28日にリリースされた全モーダル対応のアップグレード版で、音声入力と音声・動画の統合推論機能が追加されています。音声を使用する場合は、必ずサフィックス付きのバージョンを使用してください。
6.4 課金はトークン単位ですか、それとも音声の長さ単位ですか?
モデルはトークン単位で一括課金されます。音声は内部的にトークンにエンコードされて計算されます。現在の価格は入力 100万トークンあたり $0.25、出力 100万トークンあたり $2.00 です。特定の音声が何トークンに相当するかは、APIYI (apiyi.com) コンソールの「請求明細」で確認でき、コスト予測や最適化に役立てることができます。
6.5 ストリーミング出力と Function Call に対応していますか?
完全に対応しています。Seed-2.0-lite-260428 は標準的な OpenAI Chat Completions プロトコルの stream=true および tools フィールドと互換性があるため、LangChain、LangGraph、OpenAI Agents SDK などの主要なフレームワークに特別な改造なしで直接組み込むことができます。
7. まとめ:全モーダルモデルがマルチモーダルアプリケーションを「統合推論」時代へ導く
Seed-2.0-lite-260428 の価値は、単に「音声機能が増えた」ことだけではありません。動画、画像、音声、そしてテキストを同一モデル内で推論できるようになった点にこそ真の価値があります。この「統合推論」は、会議、カスタマーサポート、コンテンツモデレーション、動画分析、エージェント自動化など、本質的にクロスモーダルな業務において、真の意味でのアーキテクチャ簡素化を実現します。ASR(自動音声認識)、視覚モデル、テキストモデルを個別に組み合わせる必要はなくなり、モデル間でのコンテキストの欠落を心配する必要もなくなります。
コストと日本語環境での利用という観点で見ると、本モデルは主要なフラッグシップモデルの中でも非常に優れたコストパフォーマンスを誇ります。入力100万トークンあたり0.25ドルという価格は、大規模な音声・動画処理をエンジニアリングの現実的な選択肢として可能にし、256Kのコンテキストウィンドウは、数時間に及ぶ長時間の音声や動画の処理にも十分対応可能です。
同一の base_url で Seed-2.0-lite-260428 と各社のフラッグシップマルチモーダルモデルを統合して呼び出したい場合は、APIYI (apiyi.com) の公式ドキュメントにて、完全な接続例とモデルリストをご確認ください。
著者: APIYI Team — 世界中のAI開発者に向けて、安定かつ効率的なAPI中継サービスとマルチモデルルーティングサービスを提供しています。詳細は apiyi.com をご覧ください。