「なぜ Gemini 3.1 Pro Preview がまた遅いの?」「429 RESOURCE_EXHAUSTED って一体何?」——もしあなたが最近 Google の最新 Gemini 3.1 Pro Preview API を使用しているなら、この2つの問題に毎日遭遇しているかもしれません。初回トークン応答時間(TTFT)が最大41秒、有料ユーザーでも頻発する429エラー、Previewモデルのグローバル共有クォータがリソース競争をさらに悪化させています。
これはあなたのコードに問題があるのではなく、Gemini 3.1 Pro Preview の現段階における普遍的な現象です。Google AI 開発者フォーラムや GitHub Issues には、同様のフィードバックが溢れています。
本記事の価値: この記事では「一発解決」の万能策は提供しません——なぜなら、実際には存在しないからです。しかし、技術的な観点から、遅延と429エラーの5つの根本原因を分解し、コミュニティで検証された7つの対策を共有します。これにより、この確かに強力なモデルを現段階でより良く活用できるようお手伝いします。

Gemini 3.1 Pro Preview はどれほど強力なのか?まずはデータから
問題を議論する前に、なぜこのモデルがこれらの課題に耐える価値があるのかを理解しておく必要があります。Gemini 3.1 Pro Preview は 2026 年 2 月 19 日にリリースされた、Google が現在提供する最も強力な推論モデルです。
| 指標 | Gemini 3.1 Pro Preview | 比較基準 |
|---|---|---|
| ARC-AGI-2 スコア | 77.1%(検証済み) | Gemini 3 Pro の 2 倍以上 |
| GPQA Diamond | 94.3% | このベンチマークの史上最高スコア |
| ベンチマーク順位 | 18 項目中 12+ 項目で 1 位 | コーディング、推論、エージェントタスク |
| コンテキストウィンドウ | 1,048,576 トークン(1M) | 業界トップレベル |
| 最大出力 | 65,536 トークン(64K) | 多くの競合製品を大きく上回る |
| 入力モダリティ | テキスト+画像+音声+動画+コード | ネイティブマルチモーダル |
| 出力速度 | ~108 トークン/秒 | 中程度のレベル |
| TTFT(初回トークン) | ~41.54 秒 | 同類モデル中央値はわずか 2.65 秒 |
| 価格(入力) | $2.00/M トークン | 中程度からやや高め |
| 価格(出力) | $12.00/M トークン | 高い |
| インテリジェンス指数 | 57 点 | 中央値 31 点を大きく上回る |
データソース:Artificial Analysis(artificialanalysis.ai)、Google 公式ブログ
一言でまとめると:Gemini 3.1 Pro Preview は現在最も賢い公開モデルの一つであるが、同時に最も遅いモデルの一つでもあります。これは完全な欠点ではありません——その「遅さ」の一部は設計上の選択に起因しています。
Gemini 3.1 Pro Preview が遅延する 5 つの主な理由
理由 1: Deep Think(深い思考)——遅さは「意図的」なもの
Gemini 3.1 Pro Preview には「Deep Think」機能が導入されています——モデルは意図的に速度を落とし、より深い推論を行います。Google は thinking_level パラメータを提供しており、low、medium(新規)、high、max の 4 つのレベルをサポートしています。
デフォルトでは、モデルは高い思考レベルを使用する傾向があり、これが TTFT が 41.54 秒 という高い値になる直接の原因です——同類モデルの中央値はわずか 2.65 秒 であり、その差は 15 倍以上 にもなります。
言い換えれば:あなたが待っている 40 秒間、モデルは「詰まっている」のではなく、「考えている」のです。
Medium に投稿されたある開発者の記事のタイトルはまさに「Gemini 3.1 Pro Isn't Faster, It's Deeper」(Gemini 3.1 Pro はより速くない、より深いのだ)でした。これは設計哲学のトレードオフです——Google は速度を犠牲にして推論の深さを選択しました。
理由 2: Preview モデルのグローバル共有クォータ
これは最も見落とされがちですが、影響が大きい要因です。
Preview(プレビュー版)モデルは「動的共有クォータ」(Dynamic Shared Quota)を使用しています——すべてのユーザーがグローバルな容量プールを共有します。これは、あなた個人の使用量が制限をはるかに下回っていても、世界中の他のユーザーの総リクエスト量が大きすぎる場合、あなたも同様にレート制限されることを意味します。
Preview モデルと GA(一般提供版)モデルの主な違い:
| 比較項目 | Preview モデル | GA(一般提供版)モデル |
|---|---|---|
| サーバー容量 | 低く、割り当てが限られている | 十分で、必要に応じて拡張可能 |
| クォータメカニズム | 動的共有クォータ | 独立したクォータ |
| 安定性保証 | なし、いつでも変更される可能性あり | SLA 保証あり |
| レート制限動作 | グローバルな混雑時にも発動 | 個人の制限超過時のみ発動 |
| 利用可能期間 | いつでも提供終了の可能性あり | 長期的にメンテナンス |
これはよくある疑問を説明します:「明らかに制限を超えていないのに、なぜ 429 エラーが出るの?」——クォータはあなた一人の使用量だけを見ているわけではないからです。
理由 3: Google が 2025 年末に大幅に無料枠の制限を削減
2025 年 12 月、Google は Gemini API の無料枠の制限を最大 80% 削減しました。Gemini 3.1 Pro Preview 自体は無料枠でのアクセスを提供していません(有料ユーザーのみ)が、この削減により、多くの開発者が有料枠の Preview モデルに流れ込み、リソースの奪い合いが激化しました。
現在の無料枠制限(2026 年 3 月時点):
| モデル | RPM(1 分あたりのリクエスト) | RPD(1 日あたりのリクエスト) | TPM(1 分あたりのトークン) |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250,000 |
| Gemini 2.5 Flash | 10 | 250 | 250,000 |
| Flash-Lite | 15 | 1,000 | 250,000 |
| Gemini 3.1 Pro Preview | 利用不可 | 利用不可 | 利用不可 |
有料 Tier 1 との比較:Gemini 2.5 Flash は 10 RPM から 2,000 RPM へと跳ね上がります——その差は 200 倍 です。しかし、有料枠であっても、3.1 Pro Preview の実際の制限はしばしば「ドキュメントで言われているよりも厳しい」と感じられます。
理由 4: 「ゴースト 429」バグ——既知だが完全には修正されていない
Google 開発者フォーラムで広く議論されているバグがあります:「Ghost 429」 です。
症状は以下の通りです:無料枠から有料 Tier 1 にアップグレードした後の 24-48 時間 以内に、ダッシュボードの使用量がゼロまたはゼロに近い場合でも、頻繁に 429 RESOURCE_EXHAUSTED エラーが発生します。
Google はすでに開発者フォーラムでこのバグの存在を確認しており、アカウントアップグレード後のクォータ計算システムの不正確な計算が原因であると説明しています。一時的な解決策は、システムが再調整されるまで 24-48 時間待つことです。
このバグの主な影響を受けるのは:
- 最近無料枠から Tier 1 にアップグレードしたユーザー
- 最近新しいプロジェクトを作成して課金を有効にしたユーザー
理由 5: ピーク時のサーバー混雑
コミュニティのフィードバックによると、Gemini 3.1 Pro Preview は以下の時間帯に遅延と 429 エラーの発生率が明らかに高くなります:
- 太平洋時間 9:00 AM – 6:00 PM(北京時間 翌日 1:00 – 10:00)
- これはアメリカの平日のピーク時間と完全に一致します
ピーク時には、一部のリクエストの遅延が 104 秒 に達することもあり、503 サービス利用不可エラーも時々発生します。GitHub Issues #22160 には「gemini-3.1-pro モデル使用時に極端な遅延または応答なしが発生する」問題が記録されています。
🎯 実体験:国内で Gemini API を使用していて頻繁な遅延に遭遇する場合、上記の理由に加えて、ネットワーク遅延も一因となります。APIYI apiyi.com などの API 中継サービスを利用して呼び出すことで、最適化されたネットワークルートを利用し、一部の伝送遅延を減らすことができます。

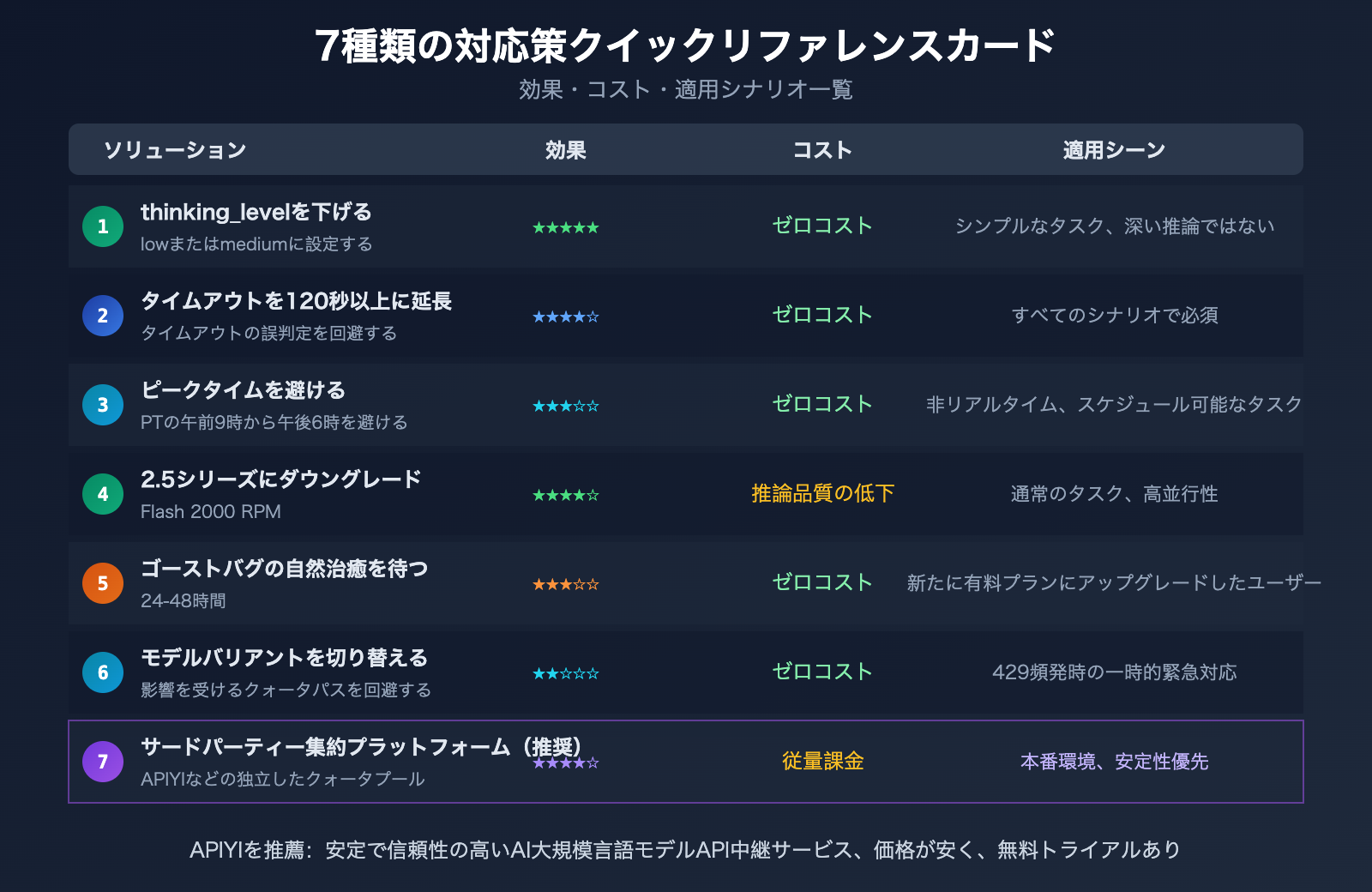
Gemini 3.1 Pro Preview の応答遅延と 429 エラーに対処する 7 つの方法
免責事項: 以下の方法は開発者コミュニティの実践共有に基づくものであり、Google 公式の推奨ではありません。効果は具体的なシナリオによって異なり、問題を完全に解決することを保証するものではありません。
方法 1: thinking_level パラメータを調整する
これは最も直接的な高速化手段です。thinking_level を low に設定することで、TTFT(Time To First Token)を大幅に短縮できます:
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # APIYI 統一インターフェース
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "user", "content": "量子コンピューティングを3文で説明してください"}
],
extra_body={
"thinking_level": "low" # 選択肢: low / medium / high / max
}
)
print(response.choices[0].message.content)
| thinking_level | TTFT 推定 | 推論深度 | 適応シナリオ |
|---|---|---|---|
| low | 5-10 秒 | 基礎推論 | 簡単な質問応答、要約、分類 |
| medium | 15-25 秒 | 中程度の推論 | 日常的なコーディング、コンテンツ生成 |
| high | 30-45 秒 | 深層推論 | 複雑な分析、数学的証明 |
| max | 45-100+ 秒 | 最深層推論 | 極めて難しい推論、研究レベルのタスク |
トレードオフ: low は高速ですが推論品質が低下します。3.1 Pro をその深い推論能力のために使用している場合、thinking_level を下げることは得策ではないかもしれません。
方法 2: クライアント側のタイムアウト時間を増やす
ほとんどの HTTP クライアントや SDK のデフォルトタイムアウトは 30 秒 です。しかし、Gemini 3.1 Pro Preview の通常の TTFT は 40 秒を超える可能性があります。タイムアウトを 少なくとも 120 秒 に設定することをお勧めします:
import httpx
import openai
# 120 秒タイムアウトを設定
http_client = httpx.Client(timeout=120.0)
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1",
http_client=http_client
)
方法 3: ピーク時間帯を避ける
タスクがリアルタイム応答を必要としない場合、以下の時間帯に API を呼び出してみてください:
- 太平洋時間 6:00 PM – 9:00 AM(日本時間 11:00 AM – 翌日 2:00 AM)
- 週末は通常、平日よりも安定しています
- RPD(1日あたりのリクエスト数)の割り当ては太平洋時間の深夜にリセットされます
方法 4: Gemini 2.5 Pro / 2.5 Flash にダウングレードする
すべてのタスクが 3.1 Pro の推論深度を必要とするわけではありません。通常のタスクには、Gemini 2.5 シリーズが依然として信頼できる選択肢です:
- Gemini 2.5 Flash: 無料枠で 10 RPM、有料枠では最大 2,000 RPM まで、はるかに高速です
- Gemini 2.5 Pro: 無料枠で 5 RPM、能力は依然として非常に高いです
3.1 Pro で頻繁に 429 エラーが発生する場合、2.5 シリーズは最も手軽なダウングレード方法です。
方法 5: 「ゴースト 429」バグが自然に解消されるのを待つ
無料枠から Tier 1 にアップグレードしたばかりの場合、または新しいプロジェクトを作成して課金を有効にしたばかりの場合:
- 割り当てシステムが再調整されるまで 24-48 時間待つ
- その間、他のモデルやプラットフォームを一時的に使用する
- 48 時間経過しても問題が解決しない場合は、Google AI 開発者フォーラムで Issue を投稿する
方法 6: モデルのバリアントを切り替えてレート制限を回避する
Google 開発者フォーラムで検証されている効果的なテクニックがあります:同じシリーズの異なるモデルバリアントに切り替えることで、影響を受けている割り当てパスを回避できる場合があります。
例:
gemini-3.1-pro-previewが 429 を返す場合、gemini-3.1-flash-preview(利用可能であれば)を試す- 異なるモデルバリアントは、異なる割り当て計算パスを通る可能性があります
方法 7: サードパーティの API 集約プラットフォームを利用する
サードパーティのプラットフォームは通常、独立した割り当てプールを持っており、Google 公式 API のグローバル共有割り当て制限の影響を受けません。これはコミュニティでますます多くの開発者に採用されている方法です。
完全なコードを表示(自動ダウングレードとエラー再試行ロジックを含む)
import openai
import time
# APIYI 集約プラットフォームを通じて呼び出し、独立した割り当てプールを利用
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# モデルフォールバックチェーン:最強のものを優先し、429 エラー時には自動的にダウングレード
model_fallback = [
"gemini-3.1-pro-preview",
"gemini-2.5-pro",
"gemini-2.5-flash",
]
def call_with_fallback(prompt, max_retries=3):
for model in model_fallback:
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=120
)
return {
"model": model,
"content": response.choices[0].message.content,
"attempt": attempt + 1
}
except openai.RateLimitError:
wait = 2 ** attempt
print(f"[{model}] 429 レート制限、{wait}秒待機して再試行...")
time.sleep(wait)
except openai.APITimeoutError:
print(f"[{model}] タイムアウト、次のモデルを試します...")
break
return {"error": "すべてのモデルが利用できません"}
result = call_with_fallback("Transformer のアテンション機構の計算複雑性を分析してください")
print(f"使用モデル: {result.get('model')}")
print(f"応答: {result.get('content', result.get('error'))}")
🚀 推奨方法: APIYI apiyi.com プラットフォームを通じて Gemini 3.1 Pro Preview などの Google モデルを呼び出すことで、プラットフォームの独立した割り当てプールとマルチパスルーティングを活用し、429 エラーの発生確率を減らすことができます。登録すると無料枠が提供され、Claude、GPT、Gemini などの複数モデルを統一して呼び出すことができます。
未解決の疑問:Previewモデルは本当に使う価値があるのか?
これは標準的な答えのない問題ですが、すべての開発者が考える価値があります。
使用を支持する理由:
- 3.1 Pro Previewは18のベンチマーク中12項目以上で首位を獲得
- GPQA Diamond 94.3%は史上最高スコア
- Deep Thinkによる推論の深さは確かに唯一無二
- 最新モデルに早期適応し、GAバージョンリリース時に先行者優位性を得られる
使用に反対する理由:
- TTFT 41秒は、リアルタイムインタラクションシナリオには不向き
- 429エラーが頻発し、本番環境では不安定
- Previewモデルはいつでも変更またはサービス終了する可能性がある(Gemini 3 Pro Previewは2026年3月9日にサービス終了)
- SLA保証がなく、問題発生時は自己責任
中間路線:開発およびテスト段階では3.1 Pro Previewを使用して効果を検証し、本番環境では2.5シリーズや他の安定モデルを使用。3.1 Pro正式版(GA)リリース後に切り替える。
💡 実践的なアドバイス:あなたのアプリケーションシナリオが深い推論を必要とし、高い遅延を受け入れられるなら、3.1 Pro Previewは試す価値があります。安定性と速度が必要なら、2.5 Flashがより現実的な選択肢です。APIYI apiyi.comを通じて複数のGeminiモデルバージョンに同時に接続し、実際のシナリオで効果を比較してから決定することをお勧めします。
よくある質問
Q1:429 RESOURCE_EXHAUSTED エラーは、無料枠を使い切ったためですか?
必ずしもそうではありません。429エラーには複数の原因があります:個人の制限超過(RPM/RPD/TPM)、グローバル共有割り当ての混雑、そして「ゴースト429」バグです。特にPreviewモデルは動的共有割り当てを使用しているため、あなたの個人使用量が制限をはるかに下回っていても、世界的な混雑時にはレート制限がかかることがあります。まずGoogle AI Studioで実際の使用量を確認し、本当に制限を超えているかどうかを確認することをお勧めします。ダッシュボードに使用量が低く表示されているにもかかわらず429エラーが出る場合は、共有割り当てやバグによる可能性が高いです。
Q2:Tier 1への有料アップグレードで429問題は解決しますか?
緩和はできますが、完全には解決しません。有料層の制限は確かに大幅に向上します(例:Flashの10 RPMから2,000 RPMへ)が、3.1 Pro Previewの共有割り当てメカニズムは有料層でも同様に有効です。また、アップグレード直後は「ゴースト429」バグに遭遇する可能性があり、24〜48時間の安定化を待つ必要があります。より高い割り当てが必要なシナリオでは、APIYI apiyi.comなどの集約プラットフォームを介して呼び出すことで、独立した割り当てプールを利用でき、レート制限を受ける確率を減らすことができます。
Q3:Gemini 3.1 Proの正式版(GA)はいつリリースされますか?
Googleは具体的な日付をまだ公表していません。過去のリズムを参考にすると、PreviewからGAまで通常2〜4ヶ月かかります。3.1 Pro Previewは2026年2月19日にリリースされたため、楽観的に見積もるとGAバージョンは2026年第2四半期末から第3四半期にリリースされる可能性があります。GAバージョンは独立した割り当て(非共有)、SLA保証、より充実したサーバー容量を備える予定です。現在はAPIYI apiyi.comを通じて、Gemini全シリーズモデルの呼び出し効果を無料でテストできます。
まとめ:Gemini 3.1 Pro Preview の「不完全さ」と付き合う方法
Gemini 3.1 Pro Preview は、非常に強力だが「扱いにくい」モデルです。GPQA Diamond 94.3% と ARC-AGI-2 77.1% というスコアは、その推論能力が現在トップレベルであることを証明していますが、41秒のTTFT(初回トークン時間)と頻発する429エラーは、日常的な使用に多くの課題をもたらします。
根本的な原因:Deep Think 機能の設計上のトレードオフ、Preview モデルのグローバル共有クォータ、そして Google が無料枠の大幅削減後に引き起こしたエコシステムへの連鎖反応です。
現実的な対応策:
- 深い推論を必要としないタスクでは、
thinking_level: "low"を設定するか、2.5シリーズにダウングレードする - タイムアウトを120秒以上に延長し、誤判定によるタイムアウトを回避する
- APIYI (apiyi.com) などのサードパーティ統合プラットフォームを利用して独立したクォータプールを取得する
- 本番環境での使用は、GA(一般提供)版がリリースされるまで待つ
これらの問題の多くは、GA 版で改善される可能性が高いです。それまでは、モデルの特性を理解し、適切な方法で活用することが私たちにできることです。
著者:APIYI Team | Gemini、Claude、GPT 全シリーズモデルAPIを統一して呼び出せます。無料テスト枠は APIYI apiyi.com でご利用ください。
📚 参考資料
-
Google 公式 – Gemini API レート制限ドキュメント:各モデルの制限詳細
- リンク:
ai.google.dev/gemini-api/docs/rate-limits - 説明: 無料枠と有料枠の RPM/RPD/TPM 制限比較表
- リンク:
-
Google AI 開発者フォーラム – 429 エラースレッド:コミュニティからのフィードバックまとめ
- リンク:
discuss.ai.google.dev - 説明: 「ゴースト429」バグの確認と暫定解決策を含む
- リンク:
-
GitHub Issue #22160 – Gemini 3.1 Pro の極めて高い遅延:開発者からのフィードバック
- リンク:
github.com/google-gemini/gemini-cli/issues/22160 - 説明: 遅延データとコミュニティディスカッション
- リンク:
-
Artificial Analysis – Gemini 3.1 Pro Preview レビュー:独立したベンチマークテスト
- リンク:
artificialanalysis.ai/models/gemini-3-1-pro-preview - 説明: TTFT、出力速度、インテリジェンス指数などの客観的データ
- リンク:
-
Vertex AI 公式ドキュメント – 429 エラーコード説明:Google Cloud Platform のエラー処理
- リンク:
docs.cloud.google.com/vertex-ai/generative-ai/docs/provisioned-throughput/error-code-429 - 説明: 公式のエラー原因分類と推奨対応方法
- リンク: