著者注:GPT-5.4か、それともClaude Opus 4.6か?2026年で最も注目すべき2つのフラッグシップAIモデルが真っ向から対決します。本記事では、Chatbot Arena、SWE-bench、ARC-AGI-2、そしてOpenClaw PinchBenchの最新の実測データをまとめ、プログラミング、推論、エージェントタスク、コストパフォーマンスの4つの観点から明確な選択アドバイスを提示します。

GPT-5.4 vs Claude Opus 4.6:主要な違いをクイックチェック
フラッグシップAIモデルを選択する際、最も重要な指標は以下の通りです。
| 比較項目 | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| リリース時期 | 2025年末 | 2026年2月 |
| Chatbot Arena ELO | 1463 | 1503 (#1) |
| AI総合知能指数 | 57 | 53 |
| API入力価格 | $2.50/100万 tokens | $5.00/100万 tokens |
| API出力価格 | $15.00/100万 tokens | $25.00/100万 tokens |
| コンテキストウィンドウ | ~1M tokens | 200K(1M Beta) |
| 最大出力長 | — | 128K tokens |
| ステータス | 現役 | 現役 |
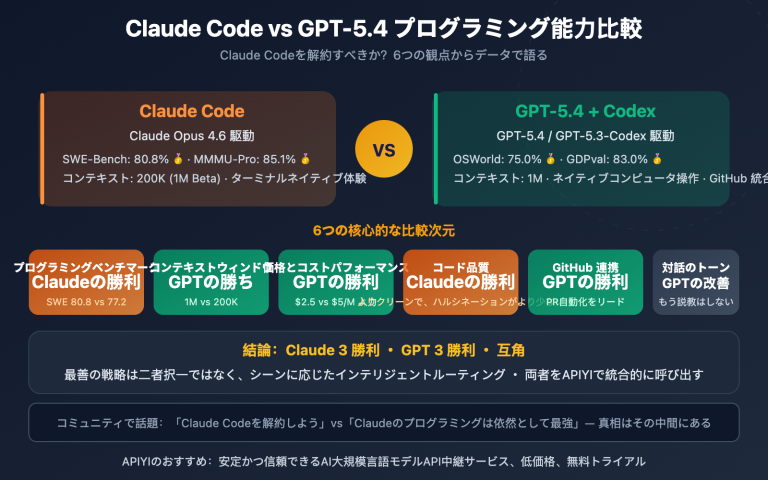
主要な結論:GPT-5.4はAI総合知能指数が高く、価格は約50%安価です。一方、Claude Opus 4.6はChatbot Arenaでのユーザー満足度で世界1位を獲得しており、複雑なプログラミングやエージェントタスクにおいてより強力です。
🎯 クイックアドバイス:価格を重視する開発者の方には、GPT-5.4の方がコストパフォーマンスに優れています。プロジェクトで複雑なコード生成や長文ドキュメントの処理が必要な場合は、Opus 4.6に投資する価値があります。APIYI (apiyi.com) を通じて両方のモデルを同時に導入し、実際の環境で比較テストを行うことをお勧めします。このプラットフォームは統一されたAPIインターフェースにより、素早い切り替えをサポートしています。
推論および知識能力の比較
| ベンチマーク | GPT-5.4 | Claude Opus 4.6 | 説明 |
|---|---|---|---|
| GPQA Diamond(大学院レベルの科学問題) | 93.2% | 91.3% | GPT-5.4 勝利 |
| MMLU(百科事典的知識) | 89.6% | 91.1% | Opus 4.6 勝利 |
| ARC-AGI-2(抽象的推論) | 52.9% | 68.8% | Opus 4.6 が大幅にリード |
| BigLaw Bench(法律専門) | — | 90.2% | Opus 4.6 特有の強み |
| MRCR v2(1M 長文コンテキスト) | — | 76% | Opus 4.6 が超長文ドキュメントでリード |
| GDPval-AA ELO(専門的タスク) | 1462 | 1606 | Opus 4.6 が明らかに優位 |
解説:GPT-5.4 は科学的推論(GPQA Diamond)においてわずかな優位性を示していますが、抽象的推論(ARC-AGI-2 で 16 ポイントのリード)、専門的なナレッジワーク、および長文コンテキスト処理においては、Claude Opus 4.6 がより強力なパフォーマンスを発揮しています。
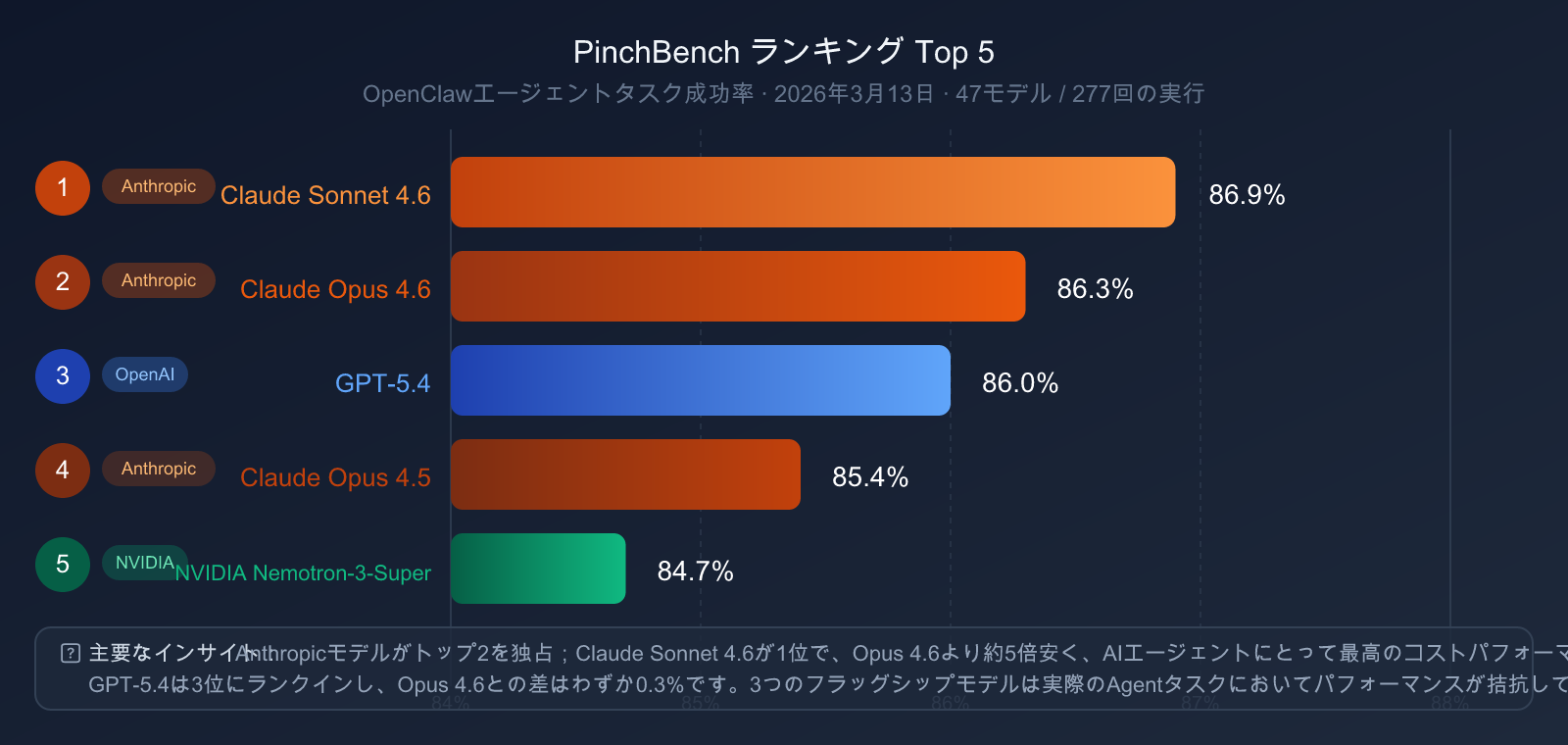
| 順位 | モデル | PinchBench 成功率 |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% |
| 🥈 2 | Claude Opus 4.6 | 86.3% |
| 🥉 3 | GPT-5.4 | 86.0% |
| 4 | Claude Opus 4.5 | 85.4% |
| 5 | NVIDIA Nemotron-3-Super | 84.7% |
主な発見:
- Claude シリーズが上位を独占:Sonnet 4.6 と Opus 4.6 がそれぞれ 1 位と 2 位を占めており、Anthropic がエージェント・エンジニアリングにおいて体系的な優位性を持っていることを示しています。
- GPT-5.4 は 3 位:Opus 4.6 との差はわずか 0.3 ポイントであり、その差は極めて小さいと言えます。
- コストパフォーマンスの高さ:Claude Sonnet 4.6(Opus 4.6 より約 5 倍安価)が PinchBench でより高い順位を記録しており、必ずしも高価なモデルほど優れているわけではないことが分かります。
- Claude Sonnet 4.6 の再評価:OpenClaw のようなエージェント・タスクにおいて、Sonnet 4.6 は最もコストパフォーマンスに優れた選択肢です。
🔍 エージェントプロジェクトへの推奨事項:OpenClaw ベースの AI エージェントを構築している場合、上位 3 つのモデル(Sonnet 4.6、Opus 4.6、GPT-5.4)の差は 1% 未満です。APIYI (apiyi.com) を通じて必要に応じてアクセスし、実際のタスクタイプに合わせてモデルを動的に選択することで、高い成功率を維持しながらコストを抑えることをお勧めします。
Chatbot Arena ELO:ユーザーのリアルな投票で選ばれた最強モデル
Chatbot Arena(旧 LMSYS)は、現在最も権威のある AI モデルのユーザー嗜好性ランキングです。数百万回に及ぶ実際の対話ブラインドテストの投票を通じて、ELO スコアが算出されています。
2026年2月最新ランキング(Top 5):
| 順位 | モデル | ELO スコア |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
Claude Opus 4.6 は、GPT-5.4 に対して 40 ポイントの ELO スコア差をつけてリードしており、マルチターン対話、スタイル制御、クリエイティブライティングなどの次元で特に際立っています。この差は、Chatbot Arena の評価体系において顕著な優位性とみなされます。
GPT-4.5(歴史的リファレンス):OpenAI が 2025年2月にリリースした GPT-4.5(コードネーム「Orion」)は、感情的知性と対話の質に焦点を当て、リリース初期には一時的に Chatbot Arena で首位に立ちました。しかし、同モデルは 2025年7月14日に API の提供を終了し、ChatGPT 内からも 2025年8月に完全に撤退しました。GPT-5.4 はその後継モデルであり、あらゆる能力において全面的に凌駕しています。
API 価格とコストパフォーマンス:コスト重視のプロジェクトでの選び方
| 費用項目 | GPT-5.4 | Claude Opus 4.6 | 差異 |
|---|---|---|---|
| 入力料金(100万トークンあたり) | $2.50 | $5.00 | Opus 4.6 は 2倍高価 |
| 出力料金(100万トークンあたり) | $15.00 | $25.00 | Opus 4.6 は 1.67倍高価 |
| コンテキストウィンドウ | ~1M トークン | 200K(1M Beta) | GPT-5.4 の勝利 |
| 最大出力長 | — | 128K トークン | Opus 4.6 の勝利 |
| マルチモーダル対応 | ✅ 画像入力 | ✅ 画像入力 | 同等 |
コスト見積もり(1日あたり 100万トークンの入力 + 20万トークンの出力を処理する場合):
- GPT-5.4:約 $5.50/日(月平均 $165)
- Claude Opus 4.6:約 $10.00/日(月平均 $300)
💰 コスト最適化プラン:高コンカレンシーや予算が限られているプロジェクトでは、APIYI (apiyi.com) を活用して、日常的なタスクには Claude Sonnet 4.6 を使用し、最強の推論能力が必要な場合にのみ Opus 4.6 を呼び出す構成をお勧めします。これにより、API コストを 60〜75% 削減できます。APIYI は同一アカウントでの複数モデル一括請求に対応しているため、きめ細やかなコスト管理が可能です。
シーン別おすすめ:GPT-5.4 vs Claude Opus 4.6 どちらを選ぶべき?
GPT-5.4 を優先すべきケース
✅ コスパ重視の汎用タスク
- 予算を抑えつつフラッグシップ級の能力が必要な場合
- 日常的なコンテンツ制作、カスタマーサポート、情報抽出
- 月間の API 呼び出し費用が $500 を超える場合、大幅なコスト削減が可能
✅ 科学研究および技術的な Q&A
- GPQA Diamond でリードしており、博士レベルの科学的推論に優れている
- 化学、物理、生物などの学術分野における専門的な回答
✅ エンタープライズ級の複雑なコード(SWE-bench Pro でリード)
- 超大規模なコードベースのアーキテクチャレベルの修正
- 複雑な依存関係の深い理解が必要なリファクタリングタスク
✅ 超長文コンテキストの活用シーン
- 1M トークンに近い超長文ドキュメントやコードベースの処理が必要な場合
- Opus 4.6 の 1M コンテキストはまだベータ段階
Claude Opus 4.6 を優先すべきケース
✅ プロダクトレベルのコード生成と修正
- SWE-bench Verified で 80.8% を記録し、日常的なバグ修正や機能開発において信頼性が高い
- BrowseComp で 84% のウェブ調査能力を持ち、RAG(検索拡張生成)アプリケーションに最適
✅ OpenClaw などのエージェントプロジェクト
- PinchBench でトップ 2 に入り、Anthropic のモデルは実際の Agent タスクにおいて体系的に優れている
✅ 対話の質が求められるプロダクト
- Chatbot Arena の ELO スコアが 1503 で、ユーザー満足度世界 1 位
- 複数ターンの対話の整合性やスタイルの適応能力が高い
✅ 専門的なナレッジワーク
- ARC-AGI-2 で 16 ポイントリードしており、抽象的推論に優れている
- BigLaw Bench で 90.2% を記録し、法律、コンプライアンス、ドキュメント分析において信頼性が高い
✅ 長文ドキュメントの出力
- 最大 128K の出力が可能で、完全なレポートや長編ドキュメントの生成に適している
🎯 シーン別の意思決定アドバイス:両モデルとも一長一短があり、その差は主に特定のタスクにおいて現れます。正式な導入前に、APIYI(apiyi.com)プラットフォームを通じて A/B テストを行うことをお勧めします。当プラットフォームは統一インターフェースを提供しており、モデルを素早く切り替えて、ご自身のビジネスシーンに最適な選択肢を見つけることができます。
クイックスタート:統一 API で両モデルを同時に利用する
OpenAI と Anthropic のアカウントを個別に登録する必要はありません。APIYI を利用すれば、統一されたインターフェースですべての主要モデルにアクセスできます。
from openai import OpenAI
# APIYI の統一インターフェースを通じて、GPT-5.4 と Claude Opus 4.6 をサポート
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # APIYI 統一アクセスURL
)
# Claude Opus 4.6 を呼び出す
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "以下のコードに潜む潜在的なバグを分析してください..."}
],
max_tokens=4096
)
# GPT-5.4 を呼び出す(同じインターフェースで、モデル名を変更するだけ)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "以下のコードに潜む潜在的なバグを分析してください..."}
],
max_tokens=4096
)
print("Opus 4.6:", response_opus.choices[0].message.content)
print("GPT-5.4:", response_gpt.choices[0].message.content)
💡 導入手順:
base_urlをhttps://vip.apiyi.com/v1に設定し、api_keyを APIYI(apiyi.com)で取得したキーに置き換えるだけで、簡単に切り替えが可能です。初回チャージ特典もあり、正式リリース前に両モデルの実際の差異をテストするのに便利です。
モデル名対応表:
| モデル | API 呼び出し名 | 月間平均コスト(1億 tokens/月) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
約 $500+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
約 $100+ |
| GPT-5.4 | gpt-5-4 |
約 $250+ |
よくある質問(FAQ)
Q: GPT-4.5 と GPT-5.4 は同じモデルですか?
いいえ、異なります。GPT-4.5(コードネーム「Orion」)は OpenAI が2025年2月にリリースした移行期のモデルで、感情的インテリジェンスと対話の質を重視したものでした。価格が非常に高く(100万トークンあたり $75/$150)、2025年7月14日に API の提供が正式に終了しました。一方、GPT-5.4 は OpenAI が現在提供しているフラッグシップモデルで、能力は GPT-4.5 を全面的に上回り、価格も 100万トークンあたり $2.50/$15 と大幅に引き下げられています。OpenAI の最強モデルを利用したい場合は GPT-5.4 を使用すべきであり、APIYI(apiyi.com) を通じてアクセス可能です。
Q: OpenClaw とは何ですか?Cursor や Claude Code との違いは?
OpenClaw は、オープンソースでセルフホスト可能な AI エージェントプラットフォームです。ターミナルアクセス、複数ファイルのコード編集、WhatsApp/Telegram/Slack など 50 以上のツール連携をサポートし、さらに新しいスキルを自動生成する「自己進化」能力を備えています。Cursor(商用 IDE プラグイン)や Claude Code(Anthropic 公式 CLI)と比較した OpenClaw の核心的な強みは、完全にオープンソースでありプライベート環境にデプロイできる点にあり、データセキュリティを重視する企業シナリオに適しています。PinchBench は、OpenClaw のエージェントタスクにおける AI モデルのパフォーマンスを評価するために特化したベンチマークテストです。
Q: AI ライティング業務にはどのモデルが適していますか?
Chatbot Arena の ELO レーティングによると、Claude Opus 4.6 がユーザー嗜好テストで 1503 ポイントを獲得し、世界第 1 位となっています。特にクリエイティブライティング、マルチターンの対話、文体の適応において非常に優れたパフォーマンスを示しています。GPT-5.4 もライティングにおいて優れていますが、ユーザー満足度のランキングではわずかに下回ります。ご自身の具体的な執筆シナリオに合わせて、APIYI(apiyi.com) で個別にテストすることをお勧めします。スタイルやジャンルによって最適な結果をもたらすモデルが異なる場合があります。
Q: Claude Sonnet 4.6 と Claude Opus 4.6 の差はどのくらいありますか?
PinchBench エージェントテストの結果を見ると、Sonnet 4.6(86.9%)は Opus 4.6(86.3%)をわずかに上回っています。Chatbot Arena の ELO レーティングでは、Sonnet 4.6 が約 1438、Opus 4.6 が 1503 で、その差は約 65 ポイントです。ほとんどのプログラミングや分析タスクにおいて、Sonnet 4.6 は非常にコストパフォーマンスの高い選択肢です(価格は Opus 4.6 の約 20%)。複雑な推論、長文ドキュメントの処理、あるいは極めて高い精度が要求されるシナリオにおいてのみ、Opus 4.6 へのアップグレードを検討する価値があります。
まとめ:2026 年のフラッグシップモデルはどう選ぶべきか?
| 利用シーン | 推奨モデル | 主な理由 |
|---|---|---|
| 日常的な開発 + コスト抑制 | GPT-5.4 | コストが 50% 安く、総合能力が高い |
| 複雑なコード修正(SWE-bench) | Claude Opus 4.6 | 80.8% のスコアで GPT-5.4(77.2%)をリード |
| AI エージェントタスク(OpenClaw) | Claude Sonnet 4.6 | PinchBench 第 1 位、Opus よりも安価 |
| 対話型プロダクト / ユーザー満足度 | Claude Opus 4.6 | Chatbot Arena ELO 第 1 位(1503) |
| 科学研究 / 学術的な回答 | GPT-5.4 | GPQA Diamond 93.2% で僅差のリード |
| 超長文ドキュメントの分析 | Claude Opus 4.6 | 128K 出力 + MRCR v2 76% |
| 抽象的推論 / AGI タスク | Claude Opus 4.6 | ARC-AGI-2 68.8% vs 52.9% |
重要なポイント:
- GPT-5.4 は総合的なコストパフォーマンスが最も高い選択肢です。AI 総合インテリジェンス指数(57 vs 53)でわずかに勝り、価格は Opus 4.6 の約半分です。
- Claude Opus 4.6 はユーザー満足度世界第 1 位(ELO 1503)のモデルであり、複雑なコード、エージェント、抽象的推論において明らかな優位性を持っています。
- ほとんどの実際のプロジェクトにおいて、Claude Sonnet 4.6 こそがコストパフォーマンスの最適解です。PinchBench で第 1 位を獲得しており、価格は Opus 4.6 よりも遥かに低く抑えられています。
「常に最高」のモデルは存在しません。あなたの利用シーンに最も適したモデルがあるだけです。
🚀 今すぐテストする:APIYI(apiyi.com) プラットフォームでは、1 つの API キーで GPT-5.4、Claude Opus 4.6、Claude Sonnet 4.6 に同時にアクセスできます。実際のビジネスデータを用いて、3 つのモデルのパフォーマンスとコストを比較してみましょう。新規登録ユーザーにはテスト用クレジットが付与されます。本番導入前の最適な意思決定にお役立てください。
本文のデータソース:Anthropic 公式発表ドキュメント、OpenAI API ドキュメント、Chatbot Arena ランキング(2026年2月)、PinchBench ランキング(2026年3月13日)、Artificial Analysis モデル比較、DigitalApplied 技術評価。データはモデルの更新に伴い変動する可能性があるため、公式の最新ドキュメントを参照することをお勧めします。
著者:APIYI Team | AI123.dev にて公開