Seed 2.0 モデルは Pro、Lite、Mini のどれを選ぶべきでしょうか?これは、ByteDance(字節跳動)の最新大規模言語モデルを導入する多くの開発者が直面する核心的な選択です。本記事では、Seed 2.0 Pro、Seed 2.0 Lite、そして Seed 2.0 Mini の 3 つのモデルを比較し、ベンチマークテスト、コスト、コンテキスト能力などの観点から明確な選定アドバイスを提供します。
核心的な価値: この記事を読み終える頃には、さまざまなビジネスシーンでどの Seed 2.0 モデルを選択すべきか、そして階層化戦略を通じてどのように最適なコストパフォーマンスを実現できるかが明確になります。
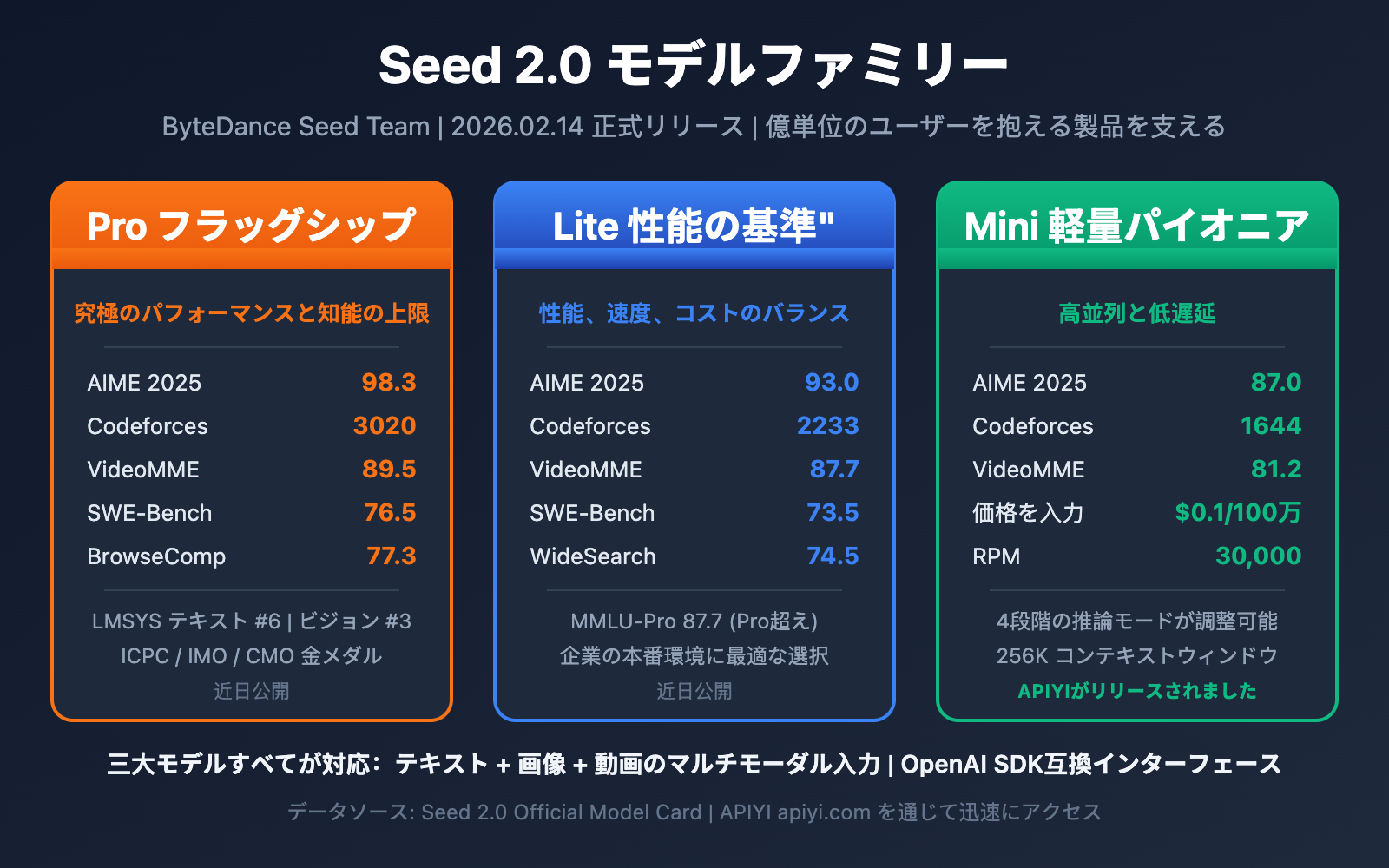
Seed 2.0 モデルファミリー概要
ByteDanceのSeedチームは、2026年2月14日に「Seed 2.0」シリーズの次世代大規模言語モデルを正式に発表しました。これはByteDanceの新しいマルチモーダル基盤モデルファミリーであり、すでに「豆包(Doubao)」などの製品を通じて億単位のユーザー規模を支えているほか、世界各地の公開ベンチマークでも業界トップクラスの成績を収めています。
Seed 2.0ファミリーは、それぞれ明確な役割とターゲットシーンを持つ3つの主要モデルで構成されています。
| モデル | ポジショニング | 主な強み | ターゲットユーザー |
|---|---|---|---|
| Seed 2.0 Pro | フラグシップモデル | 究極のパフォーマンスと知能の限界 | 高い複雑性・高価値な専門的タスク |
| Seed 2.0 Lite | 効率性のベンチマーク | 性能、速度、コストのバランス | 企業向け汎用プロダクション級モデル |
| Seed 2.0 Mini | 軽量パイオニア | 高い並列性と低レイテンシ | 高速レスポンスと高スループットのアプリ |
これら3つのモデルはシステム全体が最適化されており、強力なマルチモーダル理解能力(テキスト、画像、ビデオ入力に対応)を備えていると同時に、言語推論、コード生成、エージェントのツール呼び出しなどの次元で全面的にアップグレードされています。
Seed 2.0 Pro Preview のグローバル評価
Seed 2.0 ProのPreview版は、世界で最も権威のある評価体系において、すでにトップクラスの成績を収めています。
- LMSYS Chatbot Arena: Text Arena総合ランキングで6位、Vision Arenaで3〜4位(2026年2月時点)
- 数学競技: AIME 2025で98.3点、HMMT Febで97.3点を記録し、ICPC、IMO、CMOなどの競技で金メダル相当の評価を獲得
- 100以上の公開ベンチマーク: 言語推論、視覚理解、エージェント能力を網羅する総合評価において、世界トップティアに到達
🎯 技術アドバイス: Seed 2.0 Miniは現在、BytePlusプラットフォームを通じて先行公開されています。APIYI(apiyi.com)はBytePlusのパートナーとして、いち早くこのモデルを導入しました。開発者の皆様は、APIYIプラットフォームを通じてSeed 2.0 Miniの全機能をすぐに体験いただけます。ProおよびLiteバージョンも順次公開予定です。
Seed 2.0 Pro vs Lite vs Mini 主要ベンチマーク比較
以下は、主要な評価指標における3つのモデルの完全なスコア比較です。データはByteDance Seed 2.0の公式Model Cardおよび第三者機関による評価に基づいています。
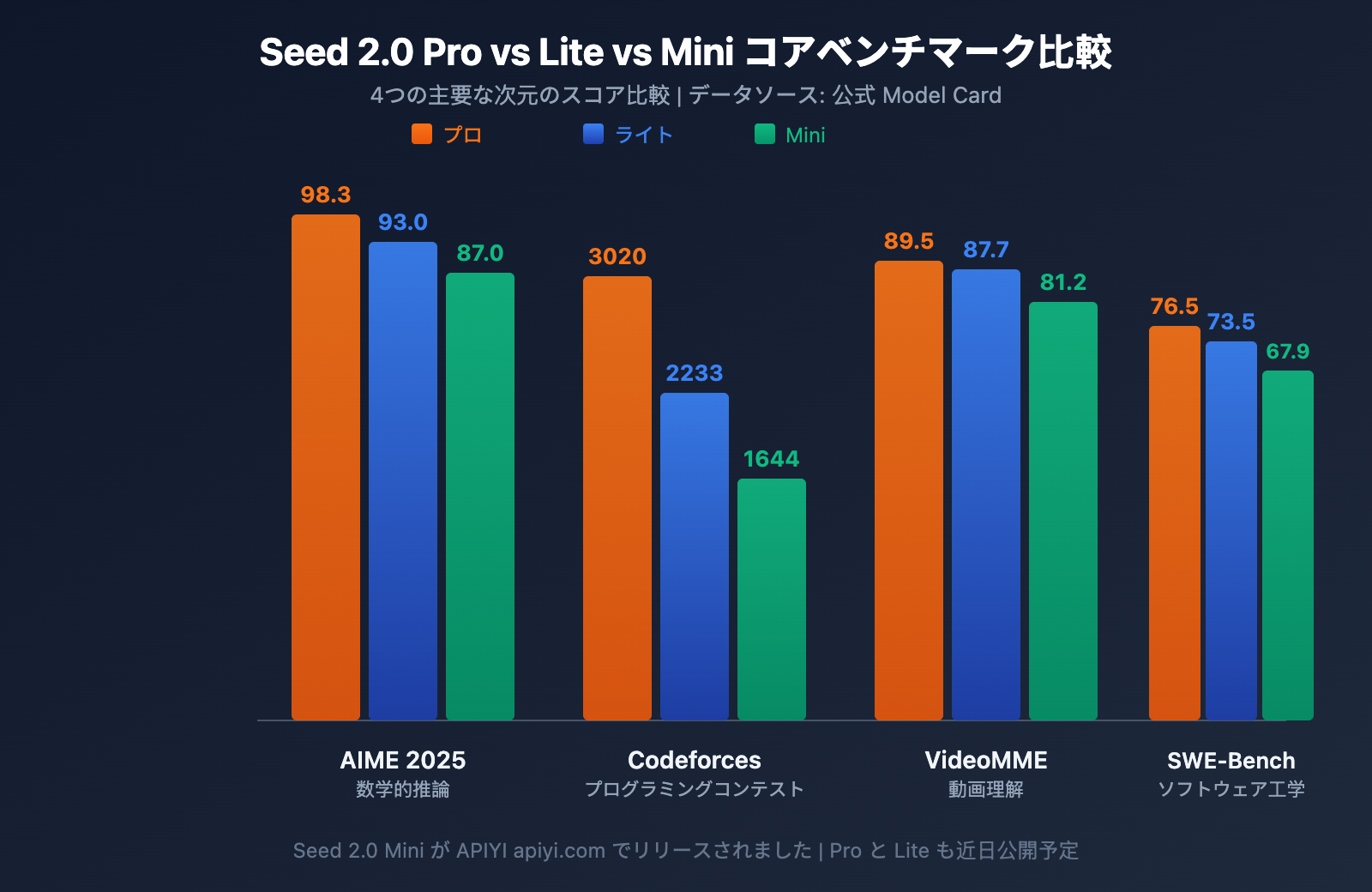
Seed 2.0 数学・推論能力の比較
| 評価項目 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 説明 |
|---|---|---|---|---|
| AIME 2025 | 98.3 | 93.0 | 87.0 | アメリカ数学招待競技会 |
| AIME 2026 | 94.2 | 88.3 | 86.7 | 最新年度の数学競技 |
| GPQA Diamond | 88.9 | 85.1 | 79.0 | 大学院レベルのQ&A |
| MMLU-Pro | 87.0 | 87.7 | 83.6 | 専門知識の理解 |
| HMMT Feb | 97.3 | 90.0 | 70.0 | ハーバード・MIT数学トーナメント |
| MathVision | 88.8 | 86.4 | 78.1 | 視覚的数学推論 |
数学的推論のデータを見ると、3つのモデルは明確な階層を形成しています。
- Pro級: AIME 2025で98.3、HMMTで97.3を達成。現在の大規模言語モデルにおける数学的推論の業界最高水準を代表しており、GPT-5.2やGemini 3 Proと直接競合できるレベルです。
- Lite級: AIME 2025で93.0を達成。MMLU-Proでは87.7と、Proの87.0をわずかに上回っており、知識理解タスクにおいてはLiteがすでにフラグシップ級の水準に達していることを示しています。
- Mini級: AIME 2025で87.0を達成。軽量かつ高並列性を重視した小規模モデルとしては、非常に優れたスコアです。
Seed 2.0 コード・エンジニアリング能力の比較
| 評価項目 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 説明 |
|---|---|---|---|---|
| Codeforces | 3020 | 2233 | 1644 | 競技プログラミングのレーティング |
| LiveCodeBench v6 | 87.8 | 81.7 | 64.1 | リアルタイムプログラミング評価 |
| SWE-Bench Verified | 76.5 | 73.5 | 67.9 | 実際のソフトウェア工学タスク |
コード能力に関しては、ProのCodeforces 3020というレーティングは、国際競技の金メダルレベルに相当します。注目すべきはSWE-Bench Verifiedの差です。Pro 76.5 vs Lite 73.5 vs Mini 67.9となっており、実際のソフトウェア工学タスクにおける3者の差は競技プログラミングほど大きくありません。これは、LiteとMiniが日常的な開発シーンにおいて非常に高い実用性を持っていることを示唆しています。
Seed 2.0 マルチモーダル・ビデオ理解の比較
| 評価項目 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 説明 |
|---|---|---|---|---|
| MMMU | 85.4 | 83.7 | 79.7 | マルチモーダル理解 |
| MMMU-Pro | 78.2 | 76.0 | 71.4 | 専門的マルチモーダル理解 |
| VideoMME | 89.5 | 87.7 | 81.2 | ビデオコンテンツ分析 |
| MotionBench | 75.2 | 70.9 | 64.4 | 動作認識 |
| TempCompass | 89.6 | 87.0 | 83.7 | 時系列推論 |
マルチモーダルはSeed 2.0シリーズの大きな強みの一つです。ProのVideoMMEにおける89.5というスコアは、極めて強力なビデオ理解能力を示しており、その動作認識や時系列推論能力は人間の基準値さえも超えています。Liteもビデオ理解(87.7)と時系列推論(87.0)でProに肉薄しており、企業向けのビデオ分析シーンにおいて非常にコストパフォーマンスの高い選択肢となります。
Seed 2.0 エージェント能力の比較
| 評価項目 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 説明 |
|---|---|---|---|---|
| BrowseComp | 77.3 | 72.1 | 48.1 | Webブラウジング理解 |
| Terminal Bench | 55.8 | 45.0 | 36.9 | ターミナル操作能力 |
| WideSearch | 74.7 | 74.5 | 37.7 | 広域検索タスク |
| HLE-Verified | 73.6 | 70.7 | 56.4 | 高難易度推論検証 |
エージェント能力は、3つのモデルを差別化する重要な要素です。ProとLiteはBrowseCompとWideSearchにおいて差が極めて小さく(Pro 74.7 vs Lite 74.5)、Liteが自律的な検索や情報の統合においてフラグシップ級の性能を持っていることがわかります。一方、Miniはエージェントタスクのスコアが顕著に低いため、エージェントシステム内での意思決定側ではなく、単純な指示を処理する実行側としての利用が適しています。
Seed 2.0 Mini モデルカード詳細パラメータ
Seed 2.0 Mini は、現在 APIYI プラットフォームで提供されている Seed 2.0 シリーズの最初のモデルです。完全なモデルパラメータは以下の通りです。
| パラメータ項目 | 仕様 |
|---|---|
| モデルID | seed-2-0-mini-260215 |
| モデル料金 (Prompt ≤ 128K) | 入力 $0.1/100万トークン, 出力 $0.4/100万トークン |
| 入力タイプ | テキスト + 画像 + 動画 |
| 出力タイプ | テキスト |
| コンテキストウィンドウ | 256K |
| 最大入力トークン | 256K |
| 最大出力トークン | 128K |
| 最大思考トークン | 128K |
| TPM (Tokens Per Minute) | 1,500K |
| RPM (Requests Per Minute) | 30K |
| 推論モード | 4段階調整可能: minimal / low / medium / hi |
| 利用可能なプラットフォーム | APIYI apiyi.com(BytePlus パートナー) |
Seed 2.0 Mini の価格設定は非常に競争力があります。入力 $0.1/M tokens、出力 $0.4/M tokens です。参考までに、GPT-5.2 の入力価格は $1.75/M tokens、Claude Opus 4.5 は $5.0/M tokens です。Seed 2.0 Mini の入力コストは GPT-5.2 のわずか 1/17.5 であり、コストパフォーマンスが極めて際立っています。
💰 コスト最適化: コストに敏感なプロジェクトにおいて、Seed 2.0 Mini は究極のコストパフォーマンスを提供します。APIYI apiyi.com プラットフォーム経由でアクセスすれば、価格は BytePlus 公式サイトと同等であり、100ドルのチャージで10%以上のボーナスが付与され、最大で実質20%OFFに相当します。
Seed 2.0 シリーズ選定ガイド
Seed 2.0 Pro を選択すべきシーン
Seed 2.0 Pro は、究極のインテリジェンスを追求するフラッグシップモデルであり、以下のような高価値なシーンに適しています。
- 最先端の科学研究: 数学の証明、科学的推論、論文作成補助(AIME 98.3, GPQA 88.9)
- 高難易度プログラミング: アルゴリズム競技、複雑なシステムアーキテクチャ設計(Codeforces 3020)
- 高度な Agent タスク: 自律的なブラウジング、多段階検索、複雑なツールのオーケストレーション(BrowseComp 77.3, WideSearch 74.7)
- 専門的な動画分析: 長尺動画の理解、動作感知、時系列推論(VideoMME 89.5)
- 意思決定層の AI: 最高品質の推論が求められるコアビジネスの意思決定
Seed 2.0 Lite を選択すべきシーン
Seed 2.0 Lite は、企業の生産環境において最もバランスの取れた選択肢です。
- 企業向け汎用タスク: 日常的なコード開発、ドキュメント処理、データ分析(SWE-Bench 73.5)
- コンテンツ生成: ビジネスコピー、技術文書、レポート作成(MMLU-Pro 87.7)
- マルチモーダル業務: 画像・テキスト理解、動画要約、ドキュメント解析(MMMU 83.7, VideoMME 87.7)
- Agent ワークフロー: 検索アシスタント、情報統合、ツール呼び出し(WideSearch 74.5、Pro に匹敵する性能)
- コストを抑えた推論タスク: 高品質を求めつつ予算に制限がある中大型企業
Seed 2.0 Mini を選択すべきシーン
Seed 2.0 Mini は、高並列・低コストが求められるシーンに最適な選択肢です。
- 大量のコンテンツ処理: テキスト分類、感情分析、キーワード抽出(RPM 30K, TPM 1500K)
- コンテンツモデレーション: 画像審査、動画パトロール、コンプライアンスチェック(異常パターンを 40% 削減)
- リアルタイムカスタマーサポート: 高並列な対話、FAQ 自動応答、インテリジェントルーティング
- データアノテーション補助: 大量のアノテーション、フォーマット変換、構造化出力
- 軽量なコードタスク: コード補完、簡単なバグ修正、コードレビュー(SWE-Bench 67.9)
- コスト優先のシーン: 100万トークンあたりわずか $0.1(入力)、圧倒的なコストパフォーマンス
💡 選定アドバイス: どの Seed 2.0 モデルを選択するかは、主にタスクの複雑さと並列処理のニーズによって決まります。多くの企業には、「Lite を主力とし、Mini を補助とする」階層化戦略をお勧めします。APIYI apiyi.com プラットフォームを通じて、現在は Seed 2.0 Mini をいち早く体験でき、今後 Pro と Lite がリリースされた際も迅速にサポートされる予定です。
Seed 2.0 モデル比較と導入のアドバイス
Seed 2.0 階層型デプロイ戦略
品質とコストの両立が必要な企業には、以下の階層型アーキテクチャの採用を推奨します。
意思決定層(Pro)— リクエストの 5-10% を想定:
複雑な推論、重要な意思決定、高価値なコンテンツ生成など、最高レベルの推論品質が求められるコアタスクを処理します。Pro の AIME 98.3 と Codeforces 3020 というスコアは、最高品質のアウトプットを保証します。
実行層(Lite)— リクエストの 20-30% を想定:
コード開発、ドキュメント生成、マルチモーダル分析など、日常的な中程度の複雑さのタスクを処理します。Lite の SWE-Bench 73.5 と WideSearch 74.5 という数値は、実際の業務シナリオにおいて非常に信頼性が高く、かつコストが Pro より大幅に低いことを示しています。
スループット層(Mini)— リクエストの 60-70% を想定:
分類・アノテーション、コンテンツ検閲、フォーマット変換など、高頻度で標準化されたバッチタスクを処理します。Mini の RPM 30K と TPM 1500K は超高スループット能力を提供し、入力 $0.1/M トークンという価格は極めて高い競争力を持っています。
Seed 2.0 vs 競合モデルの価格比較
| モデル | 入力価格 ($/M tokens) | 出力価格 ($/M tokens) | ポジショニング |
|---|---|---|---|
| Seed 2.0 Mini | $0.10 | $0.40 | 軽量・高並列 |
| GPT-4.1 mini | $0.40 | $1.60 | 軽量・汎用 |
| GPT-5.2 | $1.75 | $14.00 | フラッグシップ推論 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | バランス・高効率 |
| Claude Opus 4.5 | $5.00 | $25.00 | 究極の推論 |
| Gemini 3 Pro | $1.25 | $10.00 | マルチモーダル・フラッグシップ |
Seed 2.0 Mini の入力価格は GPT-4.1 mini のわずか 1/4、出力価格も 1/4 です。GPT-5.2 と比較すると、入力コストは 17.5 倍安く、出力コストは 35 倍安くなっており、コストパフォーマンスにおいて圧倒的な優位性を誇ります。
Seed 2.0 モデル比較に関するよくある質問(FAQ)
Q1: Seed 2.0 Mini は現在利用可能な唯一のバージョンですか?
はい。2026年2月現在、Seed 2.0 Mini(モデルID: seed-2-0-mini-260215)は BytePlus プラットフォームを通じてリリースされた Seed 2.0 シリーズの最初のモデルです。APIYI(apiyi.com)は BytePlus のパートナーとして、いち早くこのモデルを導入しており、公式サイトと同等の価格で提供しています。Seed 2.0 Pro と Lite も順次リリースされる予定で、APIYI でも同時期にサポートを開始する予定です。
Q2: Seed 2.0 Lite はどのようなシーンで Pro の代わりになりますか?
ベンチマークデータを見ると、Lite は多くの次元で Pro に非常に近い性能を持っています:WideSearch(74.5 vs 74.7)、MMLU-Pro(87.7 vs 87.0、Lite の方が高い)、SWE-Bench(73.5 vs 76.5)。日常的な開発、ドキュメント処理、情報の検索・統合などのタスクにおいて、Lite は Pro の完全な代替となり得、同時に大幅なコスト削減が可能です。最先端の数学的推論(AIME 98.3 vs 93.0)や難易度の高い競技プログラミング(Codeforces 3020 vs 2233)などの極端なシナリオにおいてのみ、Pro が明確な優位性を示します。
Q3: Seed 2.0 Mini の 4 段階の推論モードは選定にどう影響しますか?
Seed 2.0 Mini は reasoning_effort パラメータで 4 つの段階(minimal:推論なし、low、medium、hi)をサポートしています。minimal モードでは、全体的なパフォーマンスは hi モードの約 85% ですが、トークン消費量は約 1/10 に抑えられます。これは、Mini + minimal モードが深い推論を必要としない大量のタスク(分類、アノテーション、フォーマット化)をカバーできる一方で、Mini + hi モードのパフォーマンスは Lite の基準レベルに近いことを意味します。APIYI(apiyi.com)プラットフォームを通じて推論モードを柔軟に設定することで、精密なコストコントロールが可能です。
Q4: Seed 2.0 シリーズは GPT や Claude とどう競合しますか?
ベンチマークデータに基づくと、Seed 2.0 Pro は多くの評価項目で GPT-5.2 や Gemini 3 Pro のレベルに達しており、LMSYS Arena では 6 位(テキスト)および 3-4 位(ビジョン)にランクインしています。しかし、Seed 2.0 の核心的な競争力はその価格にあります。Mini の入力価格 $0.1/M トークンは GPT-5.2 のわずか 1/17.5 であり、Pro の価格も GPT-5.2 の約 1/3.7 です。性能が拮抗している状況において、Seed 2.0 シリーズは極めて強力なコストメリットを提供します。
Q5: Seed 2.0 Mini API に素早くアクセスするにはどうすればよいですか?
Seed 2.0 Mini は OpenAI SDK のインターフェース仕様と互換性があるため、移行コストは極めて低いです。base_url を https://api.apiyi.com/v1 に変更し、model を seed-2-0-mini-260215 に設定するだけで完了します。APIYI(apiyi.com)プラットフォームは、すぐに使える統合インターフェースを提供しており、複数の主要モデルの切り替え呼び出しをサポートしています。また、100ドルのチャージで 10% 以上のボーナスが付与されるキャンペーンも実施中です。
Seed 2.0 モデル比較まとめ
Seed 2.0 シリーズは、ByteDanceのSeedチームが発表した次世代の大規模言語モデルファミリーです。3つの主要モデルには、それぞれ明確なポジショニングが設定されています。Proは究極のインテリジェンスの限界(AIME 98.3、Codeforces 3020)を追求し、Liteは性能とコストのバランス(SWE-Bench 73.5、WideSearch 74.5)を最適化、Miniは高並列・低遅延(RPM 30K、入力わずか $0.1/M トークン)に特化しています。
現在、Seed 2.0 Miniが先行してリリースされており、**APIYI(apiyi.com)**プラットフォームを通じて迅速に導入可能です。価格はBytePlus公式サイトと同等に設定されているほか、チャージ時にはさらにお得な特典も用意されています。ProおよびLiteバージョンも順次リリース予定で、開発者は同じプラットフォームから全シリーズのモデルをシームレスに切り替え、比較検討できるようになります。
参考資料
-
ByteDance Seed 2.0 公式ページ: モデル紹介と完全なベンチマークデータ
- リンク:
seed.bytedance.com/en/seed2 - 説明: Pro、Lite、Mini 全シリーズの評価比較を掲載
- リンク:
-
Seed 2.0 Model Card 技術白皮書: 詳細なモデルアーキテクチャと評価手法
- リンク:
github.com/ByteDance-Seed/Seed2.0 - 説明: 学習手法、評価データセットの詳細を掲載
- リンク:
-
LMSYS Chatbot Arena: 世界最大規模の人間によるブラインドテスト(好感度評価)
- リンク:
lmarena.ai - 説明: Seed 2.0 Pro Preview が Text部門で第6位、Vision部門で第3〜4位にランクイン
- リンク:
-
Seed 2.0 Benchmarks Guide: サードパーティによる評価のまとめ
- リンク:
digitalapplied.com/blog/bytedance-seed-2-doubao-ai-model-benchmarks-guide - 説明: GPT-5.2(仮称)や Claude 3.5 Opus などとの横断的な比較を掲載
- リンク:
著者: APIYI Team | AIモデルのAPI比較や選定ガイドの詳細については、APIYI (apiyi.com) 技術ブログをご覧ください。