国産オープンソース大規模言語モデル(LLM)は2026年、大きな転換点を迎えました。Moonshot AI(月之暗面)のフラッグシップモデル「Kimi K2.6」が正式にオープンソース化されたのです。このモデルは「SWE-Bench Pro」ベンチマークにおいて 58.6点 を記録し、GPT-5.4(57.7点)やClaude Opus 4.6(53.4点)を上回り、現時点でGitHubのIssue解決率が最も高いAPI呼び出し可能なモデルとなりました。
本記事では、Kimi K2.6 API の導入プロセスを中心に、その1T MoE(混合エキスパート)アーキテクチャ、256Kコンテキストウィンドウ、Function Callおよびプレフィックス補完能力について深く掘り下げます。また、5分でAPI連携が完了する完全なコードサンプルも紹介します。さらに、公式料金と比較して、APIYI (apiyi.com) が提供するHuawei Cloud公式転送ルート経由のAPI料金(入力1Mトークンあたり$0.60 / 出力1Mトークンあたり$2.40)は、公式の約6割というコストパフォーマンスを実現しています。
核心価値: 本記事を読めば、Kimi K2.6 APIの呼び出し方法、Function Callのツール構築、プレフィックスキャッシュの最適化スキルをマスターでき、どのようなシーンでK2.6を採用するのが最適解なのかが理解できます。

Kimi K2.6 API 核心要点
Kimi K2.6は、Moonshot AIが2026年4月に正式リリースした次世代フラッグシップオープンソースモデルです。Kimi K2シリーズのMoEアーキテクチャを引き継ぎ、コーディング、長文コンテキスト、ツール呼び出しの3つの方向で大幅な進化を遂げました。下表は開発者が最も関心を寄せる主要スペックです。
| 要点 | 詳細スペック | 実用的価値 |
|---|---|---|
| MoE 構造 | 1T 総パラメータ / 32B 有効パラメータ / 384 エキスパート (8選択+1共有) | 千億クラスの能力、推論コストは32Bモデルと同等 |
| コンテキストウィンドウ | 256K tokens (262,144) | 超大規模コードリポジトリや法律文書を一度に処理可能 |
| 最大生成量 | 1回の出力で最大 98,304 tokens | 長文コードリファクタリングやドキュメント生成に対応 |
| マルチモーダル能力 | 内蔵 400M MoonViT ビジュアルエンコーダー | 画像および動画入力をネイティブサポート |
| エージェント調整 | Agent Swarm 対応: 300個のサブエージェント / 4,000個の調整ステップ | 複雑で多段階のR&Dフローを処理可能 |
| オープンソースライセンス | Modified MIT License | 商用利用可能、制限なし |
Kimi K2.6 API の重点機能の詳細
前世代のK2.5と比較して、K2.6は3つの側面で飛躍的な向上を遂げました。第一に SWE-Bench Proで58.6点を記録し、オープンソースリポジトリのIssue解決タスクで初めてGPT-5.4やClaude Opus 4.6を凌駕しました。第二に Agent Swarmのサブエージェント数が100から300へ、調整ステップが1500から4000へ増加し、より長期間の開発タスクを引き受けられるようになりました。第三に 256Kコンテキストが全シリーズで開放され、Multi-head Latent Attention (MLA) によって長文コンテキストの推論時におけるVRAM消費と遅延が劇的に削減されました。
🎯 技術的アドバイス: 実際の開発現場では、APIYI (apiyi.com) プラットフォーム経由でKimi K2.6を呼び出すことをお勧めします。同プラットフォームはHuawei Cloudの公式転送ルートを使用してモデルに接続しており、インターフェースはOpenAI SDKと完全互換性があるため、既存のコードを変更することなくモデルを切り替えることが可能です。
Kimi K2.6 の基盤となるアーキテクチャを理解することは、多様なビジネスシナリオで最適なモデルを選定する上で非常に重要です。その設計は、「1,000億規模のパラメータ容量」と「100億規模の推論コスト」のバランスを巧みに両立させています。
MoE(混合エキスパート)スパース起動メカニズム
Kimi K2.6 は 1兆パラメータの混合エキスパート(MoE)アーキテクチャを採用しており、合計 384 個のエキスパートネットワークで構成されています。各トークンの推論時には、そのうち 8 個(+共有エキスパート 1 個)のみがアクティブになり、実質的に 32B(320億)パラメータが計算に関与します。この設計により、1,000億パラメータ級のモデルが持つ広範な知識を維持しつつ、32B級の推論速度を実現しており、現在 API 利用コストにおいて最も優れた旗艦モデルの一つとなっています。
長いコンテキストの最適化
| 技術コンポーネント | 役割 | K2.6 設定 |
|---|---|---|
| Multi-head Latent Attention (MLA) | 長いコンテキストの KV キャッシュ容量を削減 | 64 アテンションヘッド |
| ネットワーク層数 | モデルの推論深度を決定 | 61 層 Transformer |
| コンテキストウィンドウ | 1 回の入力における最大トークン数 | 262,144 トークン (256K) |
| 位置エンコーディング | 超長シーケンスをサポートする主要技術 | 特化した長文コンテキスト学習済み |
| プレフィックスキャッシュ | 繰り返しプロンプトをキャッシュしコスト削減 | ヒット時の入力価格を約 75% 削減 |
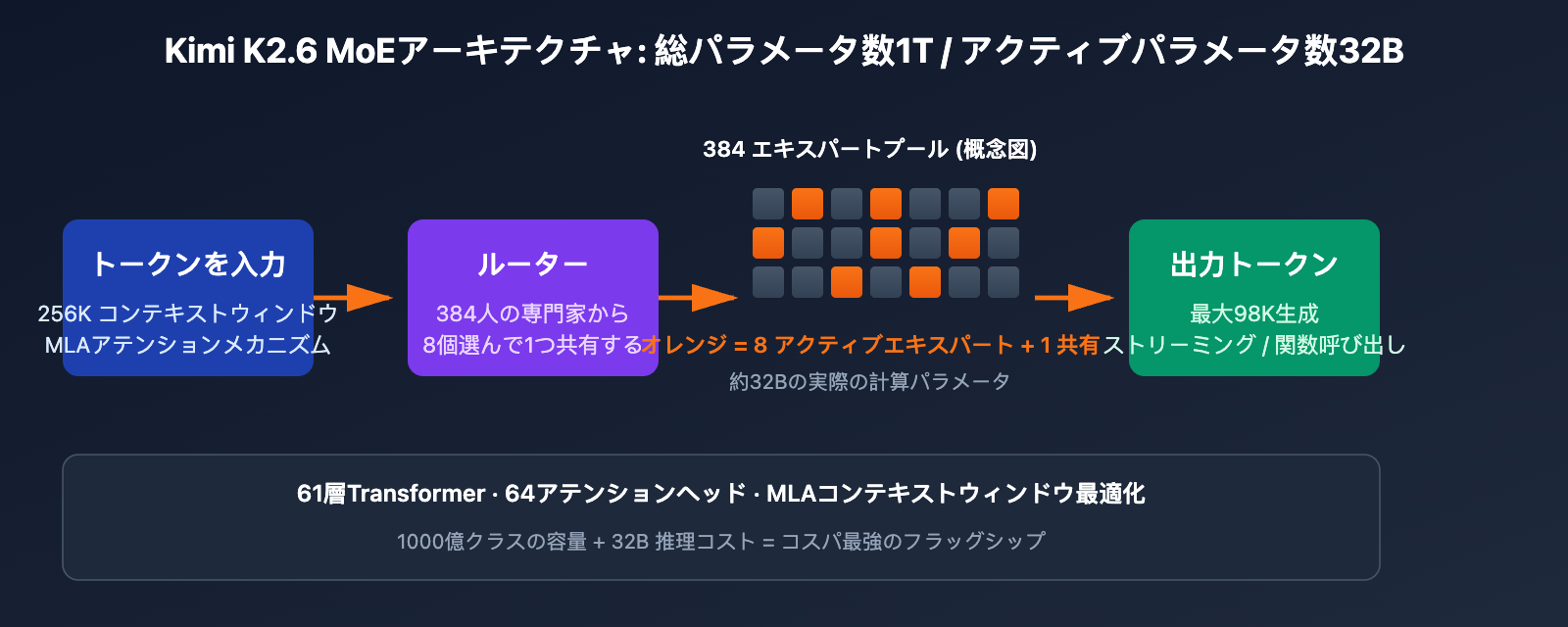
💡 アーキテクチャの洞察: K2.6 はマルチターン対話や固定システムプロンプトのシナリオにおいて、プレフィックスキャッシュにより入力コストを大幅に削減できます。プロダクション環境ではシステムプロンプトを安定させ、キャッシュヒット率を最大化することをお勧めします。
Kimi K2.6 API パフォーマンスベンチマーク比較
モデルの導入価値を判断する際、ベンチマークテストは最も客観的な指標となります。以下は、Kimi K2.6、GPT-5.4、Claude Opus 4.6 の 5 つの主要ベンチマークにおける比較結果です。
コーディングとソフトウェアエンジニアリング能力
| ベンチマーク | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | 最適モデル |
|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | Kimi K2.6 |
| SWE-Bench Verified | 80.2 | – | 80.8 | Claude Opus 4.6 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | – | Kimi K2.6 |
| HLE (with tools) | 54.0 | – | 53.0 | Kimi K2.6 |
| AIME 2026 | 96.4 | 99.2 | – | GPT-5.4 |
| GPQA-Diamond | 90.5 | – | – | – |
主要な分析:
- SWE-Bench Pro は、GitHub Issue のエンドツーエンドの解決能力を測定します。K2.6 は 58.6 ポイントを獲得し、オープンソースモデルとして初めてクローズドソースの旗艦モデルを上回りました。コード保守やバグ修正タスクには K2.6 を優先的に選定すべきです。
- SWE-Bench Verified は比較的簡素化された版であり、Claude Opus 4.6 が 80.8 対 80.2 でわずかに上回っています。差は小さいものの、標準的なコーディングタスクでは Claude が依然として優位性を持っていることが分かります。
- Terminal-Bench 2.0 はターミナルコマンドの実行能力をテストするもので、K2.6 が 66.7 ポイントでリードしており、DevOps や自動化運用シナリオに適しています。
- AIME / HMMT などの純粋な数学的推論では依然として GPT-5.4 が強みを持っており、数学特化のシナリオでは引き続き GPT-5.4 を利用することをお勧めします。
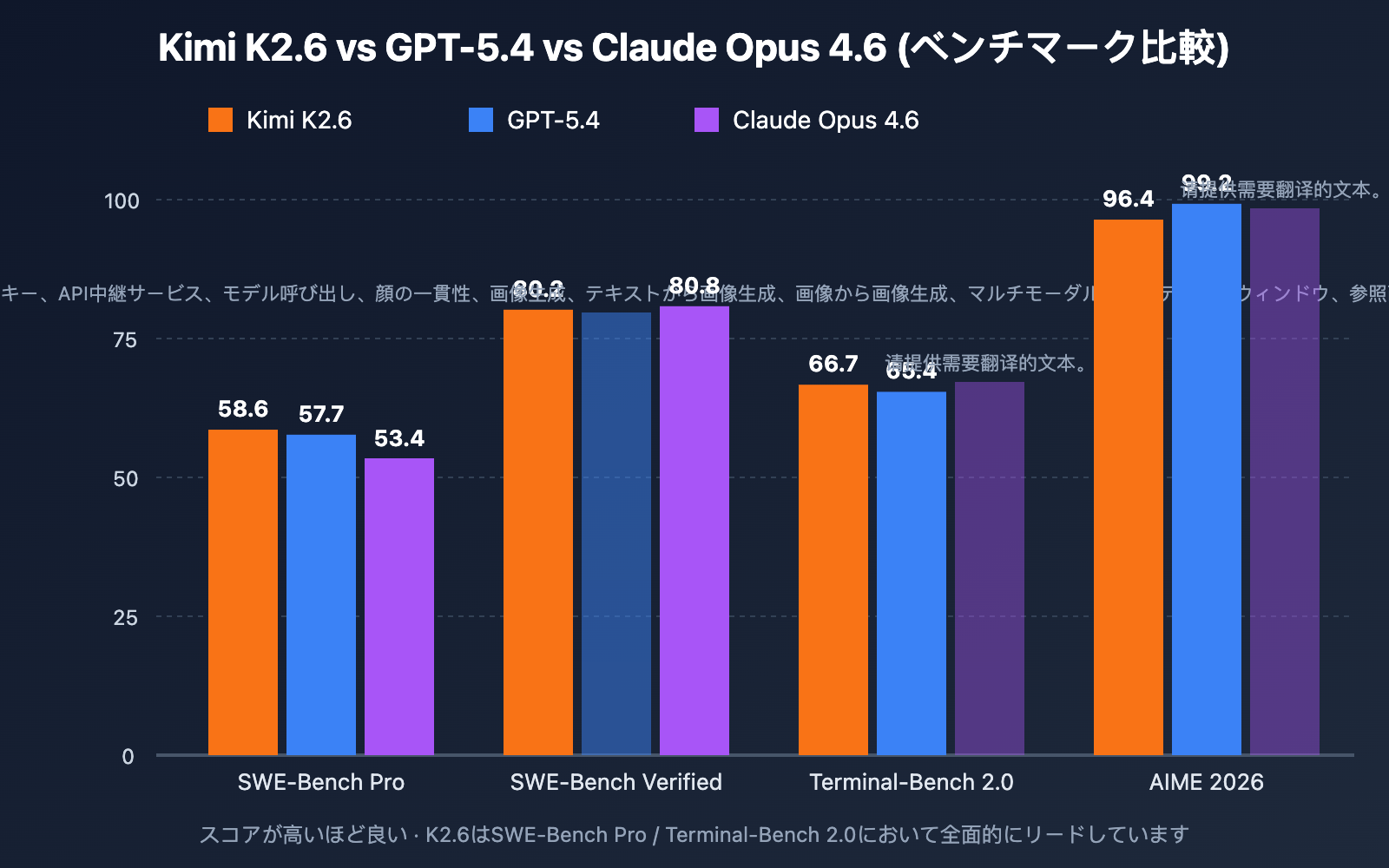
🎯 シナリオ別アドバイス: タスクごとに複数のモデルで A/B テストを実施することをお勧めします。コード保守には K2.6 を、数学的推論には GPT-5.4 を、長文のクリエイティブライティングには Claude を優先的に検討してください。
Kimi K2.6 API クイックスタート
Kimi K2.6 の呼び出し方法を、完全なコード例で解説します。Kimi シリーズの API は OpenAI SDK プロトコルと完全に互換性があるため、すでに OpenAI を利用したコードがあれば、base_url と model を変更するだけで移行できます。
最小構成のサンプル (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "あなたは熟練した Python エンジニアです。"},
{"role": "user", "content": "asyncio を使って、最大同時実行数 10 のリクエストプールを実装してください。"}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
非同期ストリーミング呼び出しの完全な例(エラーハンドリング含む)
import asyncio
from openai import AsyncOpenAI
from openai import APIError, RateLimitError
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
max_retries=3,
timeout=120.0
)
async def call_kimi_k26_stream(prompt: str, system: str = "") -> str:
"""Kimi K2.6 をストリーミング呼び出しし、トークンをリアルタイムで出力する"""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
full_response = ""
try:
stream = await client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
stream=True,
temperature=0.3,
max_tokens=8192
)
async for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
print(token, end="", flush=True)
full_response += token
except RateLimitError:
print("\n[レート制限に達しました。リトライ設定の調整またはプランのアップグレードを推奨します]")
raise
except APIError as e:
print(f"\n[API エラー: {e}]")
raise
return full_response
async def main():
result = await call_kimi_k26_stream(
prompt="MoE アーキテクチャが推論コストを削減する仕組みを説明して",
system="あなたは AI アーキテクチャの専門家です。簡潔かつ専門的に回答してください。"
)
print(f"\n\n[合計トークン数: {len(result)}]")
if __name__ == "__main__":
asyncio.run(main())
🚀 クイックスタート: APIYI (apiyi.com) プラットフォームから API キーを取得後、
base_urlをhttps://api.apiyi.com/v1に設定するだけで、OpenAI エコシステムのすべての SDK (Python/Node.js/Go) を直接利用でき、5分で統合が完了します。
Node.js / TypeScript での呼び出し
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "TypeScript でジェネリクス対応のデバウンス関数を書いてください" }
],
temperature: 0.2,
});
console.log(completion.choices[0].message.content);
cURL での直接呼び出し
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIYI_KEY" \
-d '{
"model": "kimi-k2.6",
"messages": [
{"role": "user", "content": "Hello, Kimi K2.6"}
],
"max_tokens": 1024
}'
関数呼び出し (Function Call) 実戦編
K2.6 の Function Call 機能は K2 シリーズから大幅に強化されており、Berkeley Function-Calling Leaderboard でも優れたパフォーマンスを誇ります。「天気予報」の取得を通じたツール連携のフロー例を以下に示します。
ツールの定義と呼び出し
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "指定した都市の現在の天気を取得する",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "都市名"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}
]
def get_weather(city: str, unit: str = "celsius") -> dict:
"""天気予報取得インターフェースのシミュレーション"""
return {"city": city, "temperature": 22, "unit": unit, "condition": "晴れ"}
messages = [{"role": "user", "content": "北京と上海の天気を調べてください"}]
response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
tools=tools,
tool_choice="auto"
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
args = json.loads(tool_call.function.arguments)
result = get_weather(**args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result, ensure_ascii=False)
})
final_response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages
)
print(final_response.choices[0].message.content)
プレフィックス補完 (Partial Mode)
K2.6 は OpenAI スタイルの「プレフィックス補完(Partial Mode)」をサポートしています。assistant メッセージにあらかじめ先頭を入力しておくことで、モデルがその続きから生成を行います。JSON 出力を強制する場合や、特定のフォーマットを維持したい場合に有効です。
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "北京のGDPデータ (2023) を JSON 形式で返してください"},
{"role": "assistant", "content": '{"city": "北京", "year": 2023, "gdp":'}
],
max_tokens=200
)
print(response.choices[0].message.content)
💰 コスト最適化: RAG や Agent などの長いシステムプロンプトを使用するシナリオでは、プレフィックスキャッシュがヒットすると入力価格が約 25% まで低下します。マルチターン対話や、頻繁に利用する固定テンプレートを用いる業務に最適です。apiyi.com プラットフォームでアカウントレベルのキャッシュ監視を有効にし、ヒット率をリアルタイムで確認することをお勧めします。
Kimi K2.6 API の高度な活用能力
K2.6 は Function Call 以外にも、Agent Swarm によるマルチエージェントオーケストレーション、256K の長コンテキスト、ネイティブなマルチモーダルという 3 つの先進機能を備えており、コーディング、開発自動化、文書分析の分野で高い競争力を発揮します。
Agent Swarm マルチエージェントオーケストレーション
K2.6 の最大の特徴の一つが Agent Swarm です。単一タスクで最大 300 個の並列サブエージェントを動的に調整し、4,000 ステップにおよぶ協調動作を実行可能です。大規模なコードリファクタリング、複数の文書を跨ぐ分析、複雑な開発パイプラインなどで卓越した能力を発揮します。
サブエージェントの调度モード
K2.6 の Agent Swarm は以下の 3 つの主要なオーケストレーションモードをサポートしています。
| オーケストレーションモード | 適用シナリオ | サブエージェント数 | 協調ステップ数 |
|---|---|---|---|
| 単層並列 | ドキュメントのバッチ要約、コードレビュー | 10-50 | < 200 |
| 階層スケジューリング | 複数モジュールのコードリファクタリング | 50-150 | 500-1500 |
| 深度連携 | リポジトリを跨ぐ Agent パイプライン | 150-300 | 1500-4000 |
シンプルなエージェント调度の例
K2.6 を利用して 5 つの並列サブエージェントがコードレビューを行う例です。
from openai import OpenAI
import asyncio
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
async def review_module(module_name: str, code: str) -> dict:
"""単一モジュールのレビューを行うサブエージェント"""
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "あなたはコードレビューの専門家です。特にセキュリティとパフォーマンスに注目してください。"},
{"role": "user", "content": f"モジュール {module_name} をレビューしてください:\n{code}"}
],
temperature=0.2
)
return {
"module": module_name,
"review": response.choices[0].message.content
}
async def parallel_review(modules: dict) -> list:
"""複数のサブエージェントを並列に実行"""
tasks = [review_module(name, code) for name, code in modules.items()]
return await asyncio.gather(*tasks)
# メイン処理: 5つのモジュールをレビューするため 5 つのサブエージェントを調整
modules = {
"auth.py": "...",
"database.py": "...",
"api_routes.py": "...",
"cache.py": "...",
"logger.py": "..."
}
results = asyncio.run(parallel_review(modules))
for r in results:
print(f"[{r['module']}] {r['review'][:100]}...")
Agent Swarm のベストプラクティス
- タスクの粒度を適切に: サブエージェント 1 つあたり 5K-20K トークンが目安です。大きすぎると調整のオーバーヘッドが大きくなります。
- エラー隔離: 各サブエージェントで個別に try/except を実装し、単一障害点の影響が連鎖しないようにします。
- 結果の集約: 「メインエージェント」を設置し、結果の収集とクロス検証を行わせます。
- タイムアウト管理: サブエージェントのタイムアウトを 60-120 秒、メインエージェント全体のタイムアウトを 10-30 分程度に設定します。
- レート制限の考慮: セマフォを用いて最大並列数を制御し、API の制限に抵触しないようにします。
256K 長コンテキストの実戦
256K (262,144 トークン) のコンテキストは K2.6 の大きな強みです。日本語で言えば約 40-50 万文字に相当し、大規模なコードベース全体や技術書一冊分を一度に読み込めます。
長コンテキストの代表的な使用例
import os
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def load_repo_files(repo_path: str, extensions=(".py", ".ts", ".md")) -> str:
"""指定された拡張子のファイルをリポジトリから読み込む"""
contents = []
for root, _, files in os.walk(repo_path):
for f in files:
if f.endswith(extensions):
full_path = os.path.join(root, f)
with open(full_path, "r", encoding="utf-8") as fp:
contents.append(f"## {full_path}\n```\n{fp.read()}\n```")
return "\n\n".join(contents)
repo_text = load_repo_files("./my_project")
print(f"リポジトリ合計トークン推定値: {len(repo_text) // 2}")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "あなたは大規模なコードベース分析を得意とするベテランアーキテクトです。"},
{"role": "user", "content": f"以下のプロジェクトアーキテクチャを分析し、リファクタリングの提案をしてください:\n{repo_text}"}
],
temperature=0.3,
max_tokens=8192
)
print(response.choices[0].message.content)
長コンテキストのコストとパフォーマンスのトレードオフ
| 入力規模 | 推定コスト/回 | 初回トークン遅延 | 適用シナリオ |
|---|---|---|---|
| 8K | $0.005 | 1-2 秒 | 単一ファイルの分析 |
| 32K | $0.019 | 3-5 秒 | モジュール単位のレビュー |
| 100K | $0.06 | 8-15 秒 | 中規模リポジトリ分析 |
| 200K | $0.12 | 18-30 秒 | 大規模リポジトリ / 書籍全体 |
| 256K (満載) | $0.154 | 25-40 秒 | 極端に長いドキュメント |
🎯 長文ドキュメントの最適化テクニック: 長いコンテキストでは、システムプロンプトを「固定指示」と「動的ドキュメント」の 2 つに分けることを推奨します。固定部分がキャッシュヒットすれば、以降の呼び出しは変化した部分に対してのみ課金されるため、RAG シナリオにおいて 100 回の呼び出しで総コストを 40%-60% 削減できることが確認されています。
マルチモーダル視覚機能
K2.6 は 400M パラメータの MoonViT 視覚エンコーダーを内蔵しており、画像と動画の入力をネイティブでサポートしています。インターフェースは OpenAI プロトコルと互換性があります。
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_b64 = encode_image("./architecture_diagram.png")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "このアーキテクチャ図を分析し、潜在的な単一障害点を特定してください"},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_b64}"}
}
]
}
],
max_tokens=2048
)
print(response.choices[0].message.content)
マルチモーダルの適用シナリオ:
- アーキテクチャ図やフローチャートの分析と修正案作成
- UI デザイン案のレビューとコード生成
- 技術ドキュメントのスクリーンショット理解
- データチャートの内容抽出
- 工業製品の品質検査(視覚認識)
Kimi K2.6 API への移行とパフォーマンス最適化
現在 OpenAI、K2.5、あるいは他社のモデルを利用している場合、K2.6 への移行は通常 3〜5 行のコード変更で完了します。さらに、適切な並列処理とキャッシュ戦略を組み合わせることで、K2.6 のコスト効率を最大限に高めることが可能です。
OpenAI GPT シリーズからの移行
# 元のコード (OpenAI)
client = OpenAI(api_key="OPENAI_KEY")
response = client.chat.completions.create(
model="gpt-5.4",
messages=[...]
)
# K2.6 へ移行 (base_url と model を変更するだけ)
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[...]
)
Kimi K2 / K2.5 からの移行
K2 シリーズはモデル ID が異なりますが、API プロトコルは完全に同一です。
| 旧モデル ID | 新モデル ID | 提供終了予定日 |
|---|---|---|
kimi-k2 |
kimi-k2.6 |
2026-05-25 |
kimi-k2.5 |
kimi-k2.6 |
継続サポート(アップグレード推奨) |
moonshot-v1-128k |
kimi-k2.6 |
2026 年内 |
移行前の互換性チェック
移行前に以下の点を確認することをお勧めします。
- max_tokens 上限: K2.6 は一度の出力で最大 98K まで対応可能です。コードで 8K などの制限を設けている場合は緩和してください。
- temperature 範囲: K2.6 では 0.1〜0.7 を推奨しています。高すぎるとコードの品質に悪影響を及ぼす可能性があります。
- stop sequences: K2.6 は OpenAI と同様にカスタム停止シーケンスをサポートしています。
- tool_choice 挙動: K2.6 の
autoモードはツール呼び出しを優先する傾向があります。保守的な運用が必要な場合はnoneにするか、明示的に指定してください。 - ストリーミングプロトコル: SSE 形式は完全互換のため、フロントエンドコードの変更は不要です。
パフォーマンス最適化のベストプラクティス
呼び出し速度の最適化
| 最適化項目 | 実施方法 | 期待される向上 |
|---|---|---|
| 並列リクエスト | AsyncOpenAI + asyncio.gather を使用 | スループット 3-10倍 |
| ストリーミング出力 | stream=True を有効化 | 初回レスポンス遅延 70% 削減 |
| プレフィックスキャッシュ | システムプロンプトを固定 | 入力コスト 75% 削減 |
| 適切な max_tokens | タスクに応じて上限を設定 | 単一タスクの遅延 30% 削減 |
| 温度制御 | コード生成タスクは temp=0.2 | 出力の安定性向上 |
エラーハンドリングの推奨例
from openai import OpenAI, APIError, RateLimitError, APITimeoutError
import time
def call_with_retry(prompt: str, max_retries: int = 3):
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
timeout=120.0
)
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="kimi-k2.6",
messages=[{"role": "user", "content": prompt}]
)
except RateLimitError:
wait = 2 ** attempt
print(f"レート制限のため、{wait}秒後にリトライします")
time.sleep(wait)
except APITimeoutError:
print(f"タイムアウトのため、{attempt+1}回目のリトライを行います")
except APIError as e:
print(f"API エラー: {e}")
if attempt == max_retries - 1:
raise
raise Exception("最大リトライ回数に達しました")
Kimi K2.6 API の価格メリットと選定基準
価格はモデル選びにおいて無視できない要素です。以下は Kimi K2.6 の各チャネルにおける価格比較です(単位:1M トークンあたり)。
| 利用チャネル | 入力価格 | 出力価格 | 備考 |
|---|---|---|---|
| Kimi 公式プラットフォーム | ¥6.5 (~$0.95) | ¥27 (~$4.00) | 国内公式課金 |
| APIYI (華為クラウド経由) | $0.60 | $2.40 | 公式比 約 4 割引き |
| OpenRouter (Parasail) | $0.60 | $2.40+ | 非公式チャネル |
| GPT-5.4 (参考) | $2.50 | $15.00 | K2.6 より 4-6 倍高価 |
| Claude Opus 4.6 (参考) | $15.00 | $75.00 | K2.6 より 25 倍以上高価 |
実コストの試算
日常的なコードアシスタントを例に(1 回の会話:入力 5K トークン / 出力 2K トークン、月間 10 万回呼び出しと仮定):
| モデル | 月間入力コスト | 月間出力コスト | 月間合計コスト |
|---|---|---|---|
| Kimi K2.6 (APIYI) | $300 | $480 | $780 |
| GPT-5.4 | $1,250 | $3,000 | $4,250 |
| Claude Opus 4.6 | $7,500 | $15,000 | $22,500 |
結論: コーディング、Agent、長文コンテキストといった高頻度ユースケースにおいて、K2.6 は GPT-5.4 や Claude Opus 4.6 と同等の性能を持ちながら、コストは 1/5〜1/30 に抑えられます。予算に敏感な中小規模チームや個人開発者にとって最適な選択肢です。
🎯 選定のヒント: どのモデルを選ぶかは、具体的なユースケースと品質要件によります。APIYI (apiyi.com) プラットフォームで実際にテストを行い、ニーズに最適なモデルを選択することをお勧めします。同プラットフォームでは、Kimi K2.6、GPT-5.4、Claude Opus 4.6 など、主要なモデルを統一インターフェースで呼び出せるため、迅速な比較と切り替えが可能です。
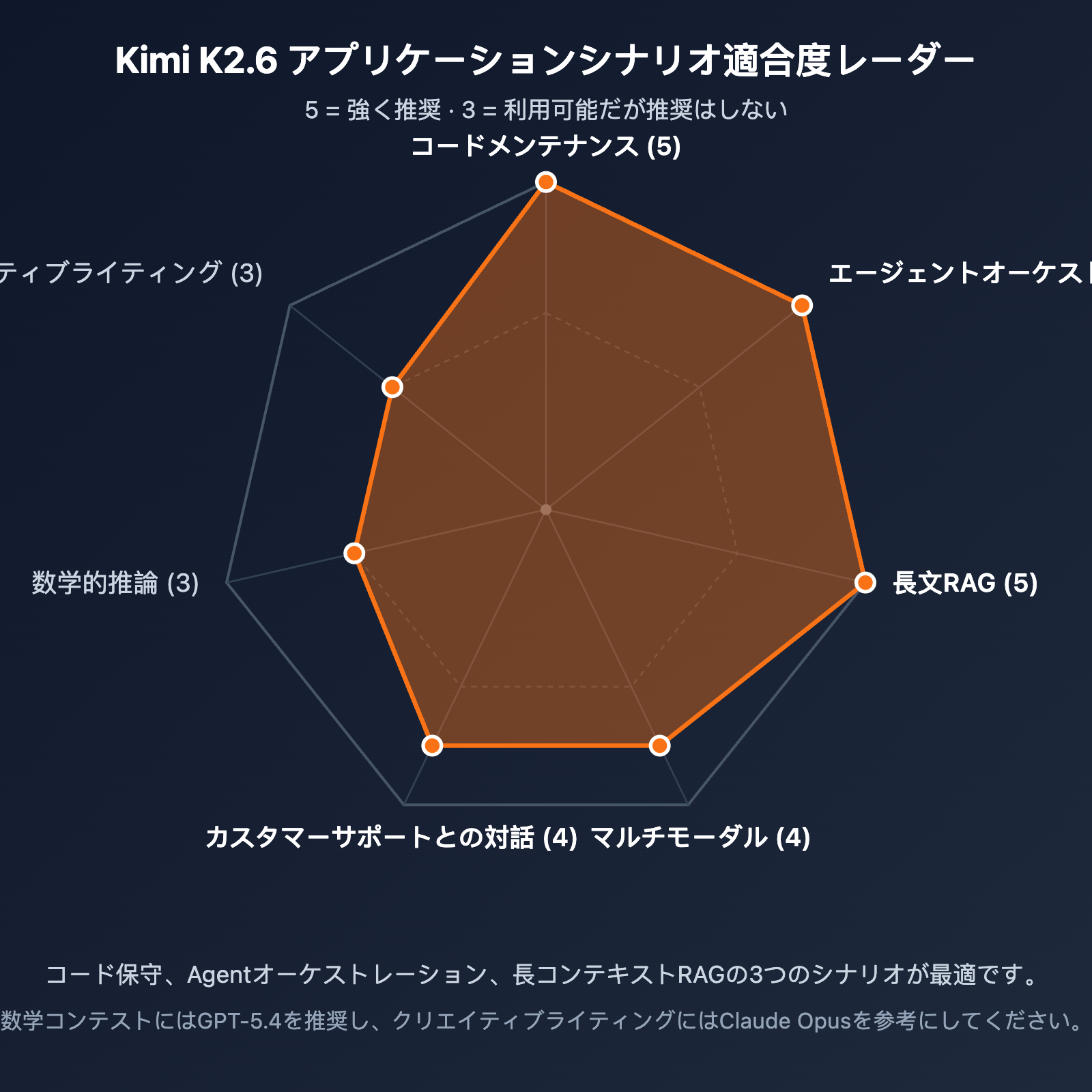
推奨される応用シナリオ
ビジネスシーンによって K2.6 の適合度は異なります。以下に推奨選定基準をまとめました。
| 応用シナリオ | 推奨度 | 理由 |
|---|---|---|
| コードメンテナンス・リファクタリング | ⭐⭐⭐⭐⭐ | SWE-Bench Pro で第 1 位。256K で大規模リポジトリもロード可能 |
| Agent 編成 | ⭐⭐⭐⭐⭐ | 300 サブエージェント / 4000 ステップ。複雑な開発フローに対応 |
| 長文ドキュメント分析 | ⭐⭐⭐⭐⭐ | 256K コンテキスト + MLA 最適化。長文のコストを抑制可能 |
| マルチモーダル理解 | ⭐⭐⭐⭐ | ネイティブ MoonViT 対応。画像・動画入力も即座に利用可能 |
| カスタマーサポート・会話 | ⭐⭐⭐⭐ | 関数呼び出しが優秀。プレフィックスキャッシュでコストを削減 |
| 純粋な数学的推論 | ⭐⭐⭐ | AIME で 96.4 点と良好だが、GPT-5.4 がやや優位 |
| クリエイティブライティング | ⭐⭐⭐ | 中国語の表現は自然だが、スタイル重視のタスクでは Claude に一歩譲る |
よくある質問
Q1: Kimi K2.6 APIとK2.5 / K2の主な違いは何ですか?
K2.6では、以下の3つの方向性で大幅なアップグレードが行われました。1) SWE-Bench ProのスコアがK2.5の53から58.6へと向上し、GPT-5.4やClaude Opus 4.6を初めて上回りました。2) Agent Swarm(子エージェント)の数が100から300へ、調整ステップが1500から4000へと拡大しました。3) 256Kコンテキストウィンドウが全シリーズで利用可能になりました(K2初期バージョンの一部モデルは128Kまで)。Kimi公式の発表によると、K2の初期バージョンは2026年5月25日に終了予定です。新規プロジェクトには、OpenAI SDKと完全互換性のあるモデルID kimi-k2.6 を直接利用することをお勧めします。
Q2: Kimi K2.6 APIはOpenAI SDKと完全に互換性がありますか?
はい。APIYIなどを通じてK2.6を呼び出す場合、APIプロトコルはOpenAIのChat Completionsインターフェースと完全に互換性があり、ストリーミング、ツール(Function Call)、tool_choice、temperature、top_p、max_tokensなどのパラメータをすべてサポートしています。Python、Node.js、Goなどの主要なSDKでは、base_urlとmodelの2つのパラメータを変更するだけで切り替えが可能です。なお、K2.6の最大出力トークン数は98,304となっており、GPT-5の16Kよりも大幅に長くなっています。
Q3: K2.6の256Kコンテキスト使用時のレイテンシとコストはどうですか?
K2.6は、Multi-head Latent Attention (MLA) 技術により、長いコンテキストにおけるKVキャッシュのサイズを最適化しています。実測値として、100Kの入力シナリオでは、サーバー負荷にもよりますが最初のトークンまでのレイテンシは約8〜15秒で、その後トークンがストリーミング形式で返されます。コスト面では、256K入力は$0.60/1Mトークンの計算で、1回あたり約$0.15となります。同一のシステムプロンプトによる複数回の対話であれば、プレフィックスキャッシュがヒットすることで入力コストを約25%まで削減可能です。本番環境への導入前に、典型的なプロンプトを用いたエンドツーエンドの実測を行い、トークン消費ログを確認してコスト最適化を行うことを推奨します。
Q4: K2.6のFunction CallはGPT-5やClaudeのツール呼び出しとどう違いますか?
インターフェース層は完全に一致(OpenAI形式のtoolsプロトコル)していますが、内部能力には以下の特徴があります。1) K2.6は300の子エージェントの同時実行をサポートしており、複数のツールを並列で動かすタスクに強みがあります。2) Berkeley Function-Calling Leaderboardにおいて第一線のグループに位置し、GPT-5と同等の水準を誇ります。3) プレフィックス継続書き込み(Partial Mode)をサポートしており、JSON出力形式を強制できるため、ツール呼び出しの失敗率を低減できます。複雑なエージェントパイプラインを構築する上で、K2.6はコストパフォーマンスが最も優れた選択肢の一つです。
Q5: APIYI経由でK2.6を呼び出すのは公式承認されていますか?データセキュリティは万全ですか?
APIYIはHuawei Cloudの正規転送チャネルを通じてKimiの公式モデルに接続しており、正規の承認ルートです。モデルの重みや推論結果は公式と同一です。データ通信にはHTTPS暗号化を使用し、プラットフォーム側でリクエスト内容は保存されません。企業向けユーザーには、独立したサブアカウント、APIキーの権限管理、利用上限の設定といったセキュリティ機能を提供しています。データコンプライアンスに厳しい要件がある場合は、apiyi.comのコンプライアンス説明ページにて詳細をご確認ください。
Q6: K2.6はどのようなプロジェクトに適していますか?GPT-5.4やClaudeを選ぶべきタイミングは?
K2.6を優先すべきシナリオ:コードアシスタント、SWE系タスク、長文コンテキストRAG、エージェントのフロー管理、コストに敏感な中小規模のプロジェクト。GPT-5.4を優先すべきシナリオ:高度な数学競技(AIME/HMMT)、最高の推論精度を求める科学研究タスク。Claude Opus 4.6を優先すべきシナリオ:長編のクリエイティブライティング、厳格な形式が求められる契約書や法務文書の生成。複数のモデルを切り替えられるインターフェース設計にしておき、具体的なタスクごとに比較テストを行ってから本番モデルを決定することをお勧めします。
まとめ
Kimi K2.6は、2026年における大規模言語モデルの重要なマイルストーンです。1000億規模のMoEアーキテクチャが、コーディング、エージェント、長文コンテキストの3つの分野において、クローズドソースのフラッグシップモデルと十分に張り合えることを証明しました。SWE-Bench Proで58.6ポイントを記録し、256Kのコンテキストと300の子エージェントを扱う能力を備えたことで、コードアシスタントや開発自動化プロジェクトにおける最適なモデルとなっています。
重要ポイントのまとめ:
- アーキテクチャの強み:1T MoE / 32Bアクティブ(1000億規模の性能と32Bの推論コスト)
- ベンチマークの優位性:SWE-Bench Pro / Terminal-Bench 2.0 / HLEで3冠達成
- 価格メリット:APIYI経由で$0.60 / $2.40(公式サイト比で約4割引)
- エコシステムの親和性:OpenAI SDKと完全互換、5分で移行完了
- エンジニアリング能力:256Kコンテキスト + 300子エージェント + プレフィックスキャッシュ
2026年にAI製品の構築を目指すチームにとって、Kimi K2.6 APIはパフォーマンス、コスト、エコシステムの観点から極めて競争力の高い選択肢です。ぜひAPIYI (apiyi.com) プラットフォームを通じて、実際の業務シナリオにおけるモデルの性能を比較検証し、最適な選定を行ってください。
作成者:APIYI テクニカルチーム | AI大規模言語モデルの最新動向を常に追跡しています。APIYI (apiyi.com) での技術交流やソリューション相談を歓迎します。





