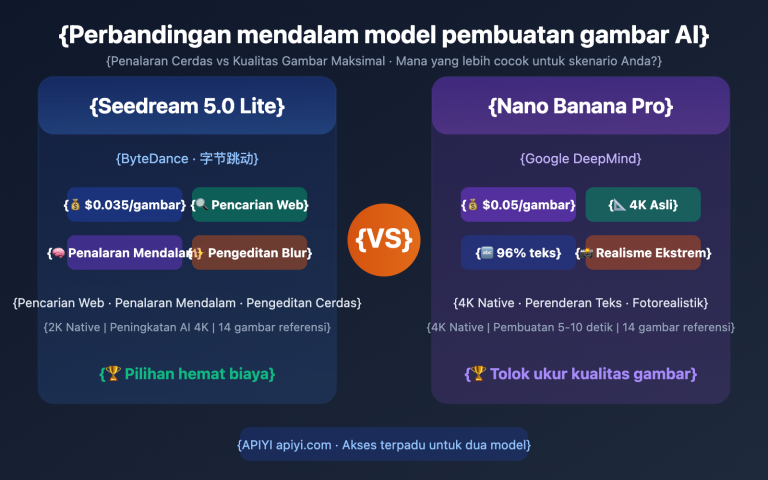
Banyak desainer yang baru pertama kali mencoba GPT-Image-2 sering kali memiliki pertanyaan: saat saya mengunggah foto dan meminta AI untuk "mengubah warna baju subjek menjadi biru", apakah AI benar-benar mengubah piksel secara presisi seperti Photoshop, atau sebenarnya ia menggambar ulang seluruh gambar dari awal? Jawaban atas pertanyaan ini sangat menentukan bagaimana kita menggunakan alat penyunting gambar berbasis AI dan bagaimana kita memahami prediktabilitas hasil keluarannya.
Faktanya, ini adalah detail teknis yang sering disalahpahami. Artikel ini akan membahas prinsip penyuntingan gambar AI, mengupas mekanisme kerja model gambar autoregresif generasi baru seperti GPT-Image-2 dan Nano Banana, menjawab pertanyaan inti "apakah ini modifikasi lokal atau penggambaran ulang", serta mengungkap bagaimana mereka tetap mempertahankan konsistensi visual yang luar biasa meskipun melakukan penggambaran ulang secara keseluruhan.
| Pertanyaan Inti | Jawaban Intuitif | Jawaban Sebenarnya |
|---|---|---|
| Metode Penyuntingan | Penimpaan lokal ala PS | Penggambaran ulang token gambar |
| Sumber Konsistensi | Mempertahankan piksel asli | Penjangkaran fitur gambar asli via self-attention |
| Arsitektur Utama | Difusi denoising | Transformer autoregresif |
| Penyuntingan Multi-putaran | Mudah terakumulasi artefak | GPT-Image-2 tanpa pergeseran signifikan |
Setelah memahami prinsip ini, Anda akan menyadari bahwa penulisan petunjuk, penggunaan mask, dan strategi input gambar referensi memiliki dasar teoretis yang baru. Kami menyarankan pembaca untuk mencoba langsung melalui antarmuka GPT-Image-2 di platform APIYI apiyi.com sambil membaca, agar prinsip ini dapat diterapkan pada hasil nyata.
Prinsip Penyuntingan Gambar AI: Bukan Modifikasi Lokal PS, Melainkan Penggambaran Ulang Cerdas
Banyak pengguna, berdasarkan pengalaman interaksi di situs web ChatGPT, secara alami menganggap bahwa penyuntingan gambar AI seperti "modifikasi lokal" di Photoshop: sistem mengenali area yang ingin Anda ubah, menimpa beberapa piksel pada gambar asli, dan membiarkan bagian lainnya tetap utuh. Model mental ini sangat intuitif, tetapi sepenuhnya salah.
Semua model penyuntingan gambar AI arus utama pada dasarnya menggunakan logika "penggambaran ulang". Baik itu GPT-Image-2, Nano Banana, atau seri Stable Diffusion, semuanya perlu mengodekan gambar asli ke dalam representasi internal tertentu (token atau laten), kemudian model "membayangkan" representasi internal lengkap dari gambar baru, dan akhirnya mendekodekannya kembali menjadi piksel. Tidak ada langkah "menggoreskan kuas di atas gambar asli" dalam proses ini.
Itulah sebabnya terkadang saat Anda hanya meminta AI mengubah warna satu mata, Anda mendapati helai rambut atau tekstur latar belakang juga mengalami perubahan halus. Model tidak bermalas-malasan, ia memang sedang "menggambar ulang" seluruh gambar, hanya saja di sebagian besar area ia menggambarnya sangat mirip dengan gambar aslinya.
Lalu pertanyaannya: jika ini adalah penggambaran ulang, mengapa gambar yang disunting oleh GPT-Image-2 terlihat sangat konsisten dengan gambar asli, bahkan memungkinkan penyuntingan berulang tanpa "melenceng"? Jawabannya tersembunyi dalam arsitekturnya. Jika Anda ingin memverifikasi perilaku ini secara langsung, Anda dapat memanggil API /v1/images/edits untuk gpt-image-2 di APIYI apiyi.com, menggunakan petunjuk yang sama untuk menyunting gambar yang sama berulang kali, dan mengamati perubahan detailnya.
Perbedaan Esensial antara Modifikasi Lokal PS dan Penggambaran Ulang AI
| Dimensi Perbandingan | Modifikasi Lokal Photoshop | Penggambaran Ulang Cerdas GPT-Image-2 |
|---|---|---|
| Unit Operasi | Piksel | Token visual (blok piksel 8×8 atau 16×16) |
| Area yang Tidak Disunting | Secara fisik tetap sama | Melalui proses encoding-decoding, secara teoretis ada rekonstruksi mikro |
| Jaminan Konsistensi | 100% (menyalin langsung piksel asli) | Dijamin oleh mekanisme atensi model |
| Pemahaman Semantik | Tidak ada, hanya melihat nilai piksel | Memahami semantik seperti "baju", "latar belakang", "pencahayaan" |
| Transisi Batas | Perlu feathering manual | Transisi alami otomatis berdasarkan semantik |
PS adalah "modifikasi mekanis" berbasis piksel, sedangkan AI adalah "pemahaman diikuti penggambaran" berbasis semantik. Itulah sebabnya AI mampu menyelesaikan penyuntingan menyeluruh seperti "mengubah siang hari menjadi senja" yang tidak akan pernah bisa dilakukan oleh PS—AI mengubah representasi semantik gambar, bukan nilai RGB piksel.
Prinsip Pengeditan gpt-image-2: Bagaimana Transformer Autoregresif "Memahami" Gambar Asli
Untuk benar-benar memahami prinsip pengeditan gpt-image-2, kita tidak bisa mengabaikan pilihan arsitektur kunci yang dibuat OpenAI saat merilis model ini pada 21 April 2026: meninggalkan model difusi yang digunakan seri DALL-E dan beralih ke Transformer autoregresif. Keputusan ini secara langsung mengadopsi arsitektur multimodal dari GPT-4o.
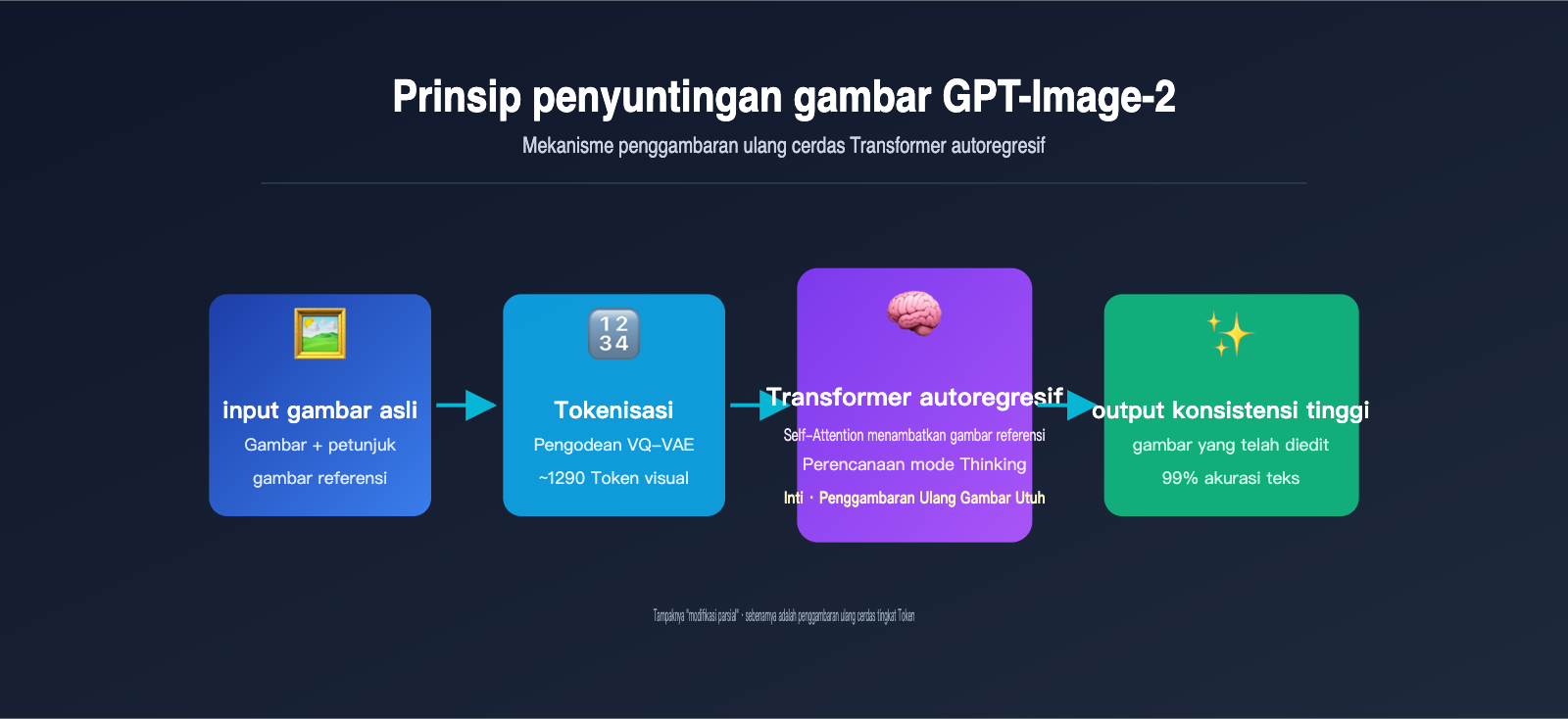
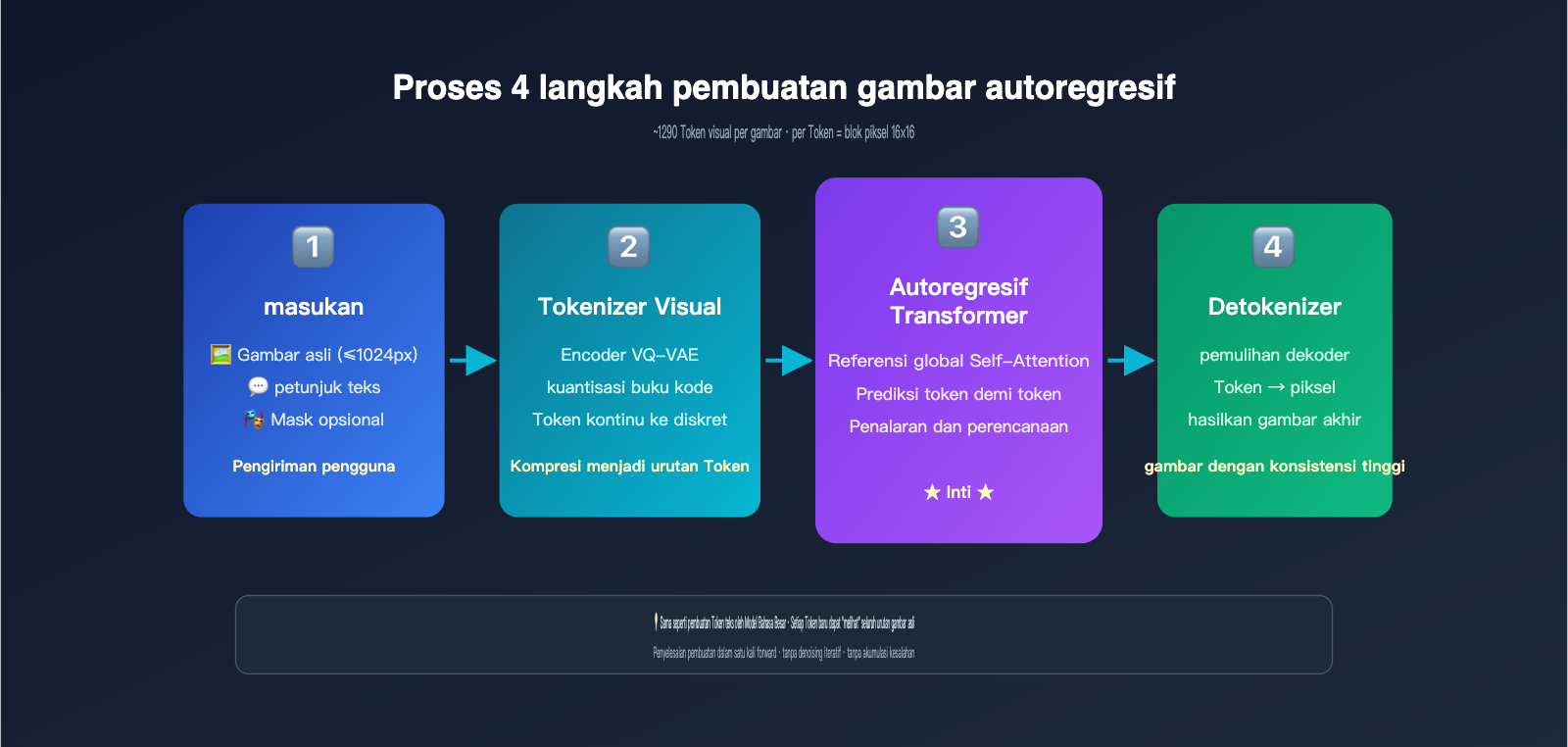
Generasi autoregresif pada dasarnya menggunakan mekanisme yang sama dengan ChatGPT saat menulis artikel, yaitu memprediksi token berikutnya. Bedanya, "token" di sini bukanlah teks, melainkan token visual. Model akan melakukan:
- Tokenisasi Gambar: Melalui mekanisme diskritisasi yang mirip dengan VQ-VAE, gambar dipecah menjadi sekitar 1024-1290 token visual, di mana setiap token kira-kira mewakili blok 8×8 atau 16×16 piksel dari gambar asli.
- Penggabungan Urutan: Menggabungkan petunjuk teks pengguna dengan token visual gambar asli menjadi satu urutan panjang, lalu memasukkannya ke dalam Transformer terpadu.
- Generasi Per Token: Model memprediksi setiap token visual gambar keluaran satu per satu dari kiri ke kanan (atau sesuai urutan pemindaian raster). Setiap kali token baru dihasilkan, model dapat "melihat" semua input sebelumnya dan konten yang telah dihasilkan.
- Dekode ke Piksel: Setelah semua token visual selesai dihasilkan, dekoder akan mengembalikannya menjadi gambar piksel akhir.
Wawasan kuncinya adalah: Saat menghasilkan gambar baru, semua token gambar asli berada dalam "pandangan" GPT-Image-2. Ini sama persis dengan prinsip saat Anda mengobrol dengan ChatGPT, di mana ia dapat melihat semua pesan sebelumnya. Mekanisme Self-Attention memungkinkan setiap token yang baru dihasilkan untuk "merujuk" pada fitur di posisi mana pun dari gambar asli.
OpenAI juga memperkenalkan "Mode Berpikir" (Thinking mode) di GPT-Image-2, yang memungkinkan model melakukan penalaran internal sebelum benar-benar mulai menghasilkan token visual: apa yang ingin diubah pengguna, bagian mana yang harus dipertahankan, dan bagaimana tata letak spasial diatur. Ini semakin meningkatkan akurasi eksekusi instruksi pengeditan yang kompleks, mencapai akurasi teks 99% dan tata letak multi-objek yang presisi. Jika Anda perlu menguji kemampuan ini di lingkungan produksi, Anda dapat mengakses gpt-image-2 melalui APIYI (apiyi.com), platform yang menyediakan spesifikasi antarmuka yang konsisten dengan resmi dan kemudahan dalam beralih antar model.
Tokenizer Visual: Keseimbangan antara Kompresi dan Retensi Informasi
Tokenizer visual adalah hambatan utama dari seluruh sistem generasi gambar autoregresif. Ia harus menyeimbangkan dua tujuan:
- Rasio kompresi tinggi: Semakin sedikit jumlah token, semakin cepat Transformer memproses, dan semakin rendah biayanya.
- Kualitas rekonstruksi tinggi: Piksel yang didekode harus sedapat mungkin mengembalikan gambar asli tanpa kehilangan detail.
Pendekatan utama adalah VQ-VAE (Vector Quantized Variational Autoencoder): menggunakan enkoder untuk mengompresi area gambar menjadi vektor kontinu, lalu memetakannya ke dalam indeks "buku kode" terbatas untuk menemukan indeks kode yang paling mendekati. Indeks inilah yang menjadi token. Gambar 1024×1024 biasanya dikompresi menjadi sekitar 1024 token dengan kepadatan informasi yang sangat tinggi.
Karena kompresi ini bersifat lossy (kehilangan data), alat pengeditan AI mana pun tidak dapat "mempertahankan 100% nilai piksel di area yang tidak diubah". Hal ini membawa kita pada pertanyaan kunci berikutnya—konsistensi.
Mekanisme Inti Konsistensi Gambar AI: Tokenisasi Visual dan Penjangkaran Perhatian
Karena GPT-Image-2 menggambar ulang seluruh gambar, bagaimana konsistensi gambar AI dicapai? Mengapa saat Anda menggunakannya untuk memperbaiki foto potret, fitur wajah, warna kulit, dan gaya rambut Anda tidak berubah menjadi orang lain? Jawabannya ada pada empat lapisan.
Lapisan pertama: Abstraksi tinggi dari token visual itu sendiri. Setelah wajah diproses melalui tokenizer, urutan token yang dihasilkan telah mengodekan fitur inti "orang tersebut"—bentuk wajah, proporsi fitur wajah, warna kulit, dll. Selama "token identitas" ini dipertahankan saat menghasilkan gambar baru, karakter tidak akan berubah.
Lapisan kedua: Referensi global Self-Attention. Transformer autoregresif menghitung bobot perhatian antara token baru dengan semua token input (termasuk token gambar asli) saat menghasilkan setiap token baru. Jika pengguna tidak menentukan perubahan pada area tertentu, model akan memberikan bobot tinggi pada token di posisi yang sesuai pada gambar asli, yang pada dasarnya "menyalin" gambar asli.
Lapisan ketiga: Bias induktif data pelatihan. OpenAI menggunakan data pasangan "gambar asli-gambar hasil edit" dalam jumlah besar untuk melatih GPT-Image-2. Model mempelajari aturan implisit selama pelatihan: kecuali diminta secara eksplisit oleh petunjuk, cobalah untuk menjaga area lain tetap tidak berubah. Bias ini tertanam dalam bobot dan berlaku secara alami saat inferensi.
Lapisan keempat: Perencanaan eksplisit Mode Berpikir. GPT-Image-2 akan menggunakan penalaran internal untuk memilah "area mana yang perlu diubah dan mana yang dipertahankan" sebelum menghasilkan gambar, yang berarti ia membuat daftar retensi untuk dirinya sendiri sebelum mulai bekerja.
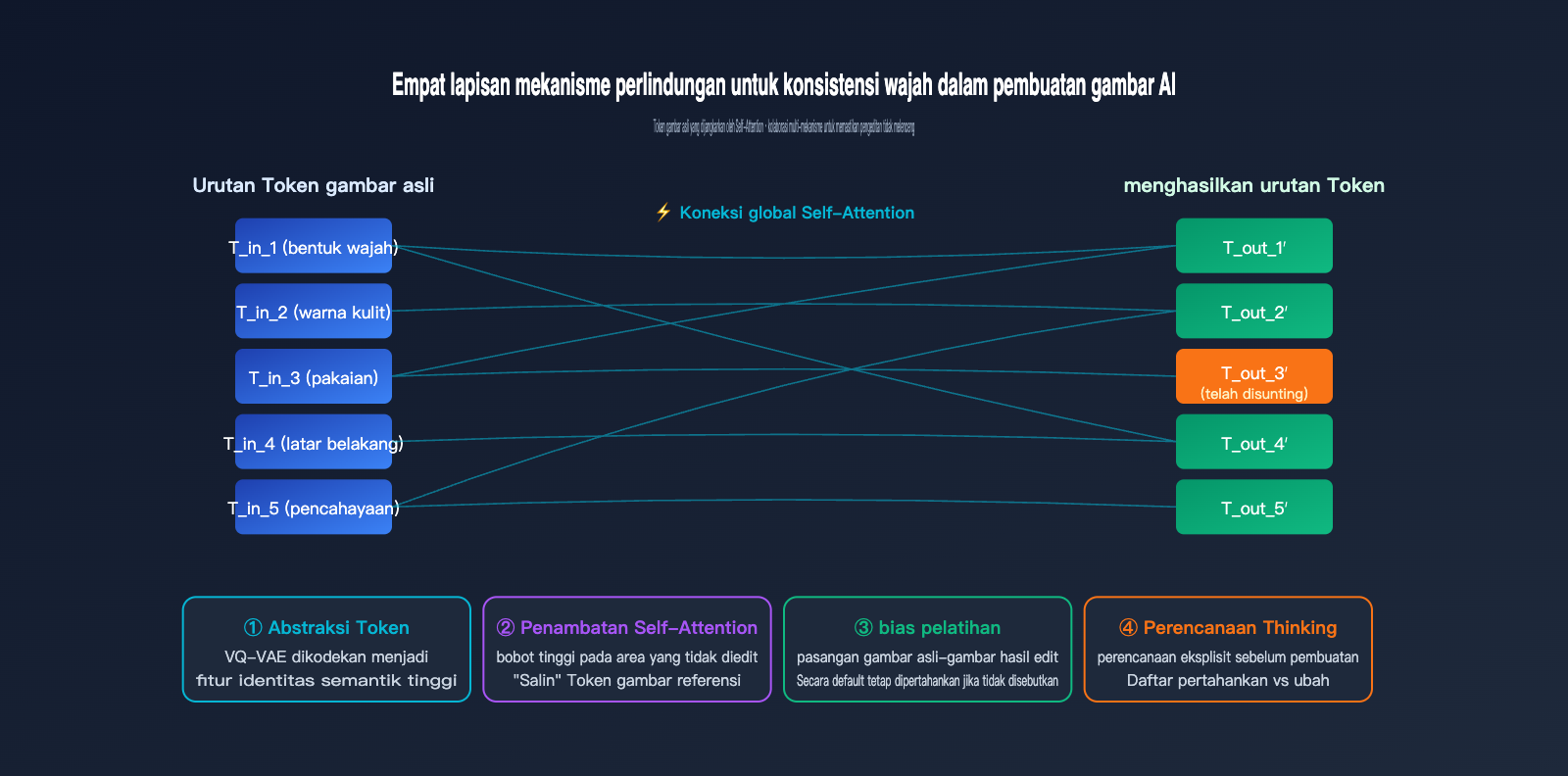
Perbandingan Empat Lapisan Mekanisme Konsistensi
| Lapisan Mekanisme | Cakupan | Skenario Kegagalan |
|---|---|---|
| Abstraksi Token | Fitur identitas global | Wajah terlalu jauh sehingga token tidak cukup |
| Self-Attention | Penjangkaran detail lokal | Konflik semantik antara petunjuk dan gambar asli |
| Bias Pelatihan | Mempertahankan area yang tidak disebutkan | Petunjuk terlalu agresif |
| Perencanaan Thinking | Instruksi pengeditan kompleks | Memerlukan uji coba berulang |
Setelah memahami empat lapisan perlindungan ini, Anda dapat menulis petunjuk yang lebih akurat untuk menghindari "pergeseran". Misalnya, daripada mengatakan "gambar ulang pakaian orang ini", lebih baik katakan "pertahankan identitas orang tersebut, hanya ubah warna pakaian dari putih menjadi biru". Saat kami menguji GPT-Image-2 di APIYI (apiyi.com), kami menemukan bahwa menambahkan batasan eksplisit seperti "pertahankan elemen lain agar tidak berubah" dapat membuat Mode Berpikir bekerja lebih efektif.
Mode Mask: Membuat Penggambaran Ulang "Berpura-pura" Menjadi Modifikasi Lokal
Jika pengguna menginginkan pengalaman "modifikasi lokal" yang lebih pasti, GPT-Image-2 menyediakan parameter mask pada endpoint /v1/images/edits. Pengguna dapat memasukkan gambar mask biner: area putih memungkinkan AI untuk menghasilkan, area hitam harus mempertahankan gambar asli.
Namun, perlu ditekankan bahwa mode mask tidak mengubah esensi dari penggambaran ulang. Fungsinya adalah menambahkan batasan keras saat menghasilkan token: token yang sesuai dengan area hitam harus benar-benar sama dengan token gambar asli. Ini adalah bentuk "generasi dengan batasan" dalam kerangka kerja generasi autoregresif, bukan penimpaan piksel ala Photoshop.
Untuk memahami keunggulan GPT-Image-2 sepenuhnya, kita perlu membandingkannya secara sistematis dengan model difusi generasi sebelumnya (seperti Stable Diffusion, DALL-E 3, dan Midjourney). Kedua sistem ini memiliki perbedaan mendasar dalam prinsip pengeditan gambar AI.
Alur kerja model difusi dimulai dari gambar derau (noise) murni, yang kemudian melalui puluhan langkah iterasi penghilangan derau (denoising) hingga gambar akhir muncul. Saat melakukan pengeditan, model ini akan mengompres gambar asli ke ruang laten, menambahkan sebagian derau pada ruang laten tersebut, lalu menggunakan petunjuk (prompt) untuk memandu proses penghilangan derau, dan akhirnya melakukan dekode kembali ke piksel. Mode inpainting akan mengatur ulang laten di luar area mask ke laten asli pada setiap langkah penghilangan derau, sehingga "mengunci" area yang tidak diedit.
Alur kerja model autoregresif sangat berbeda: gambar dikodekan menjadi token, lalu diprediksi keluarannya token demi token seperti menulis artikel. Tidak ada iterasi penghilangan derau, tidak ada derau laten, dan proses pembuatan selesai dalam satu kali jalan.
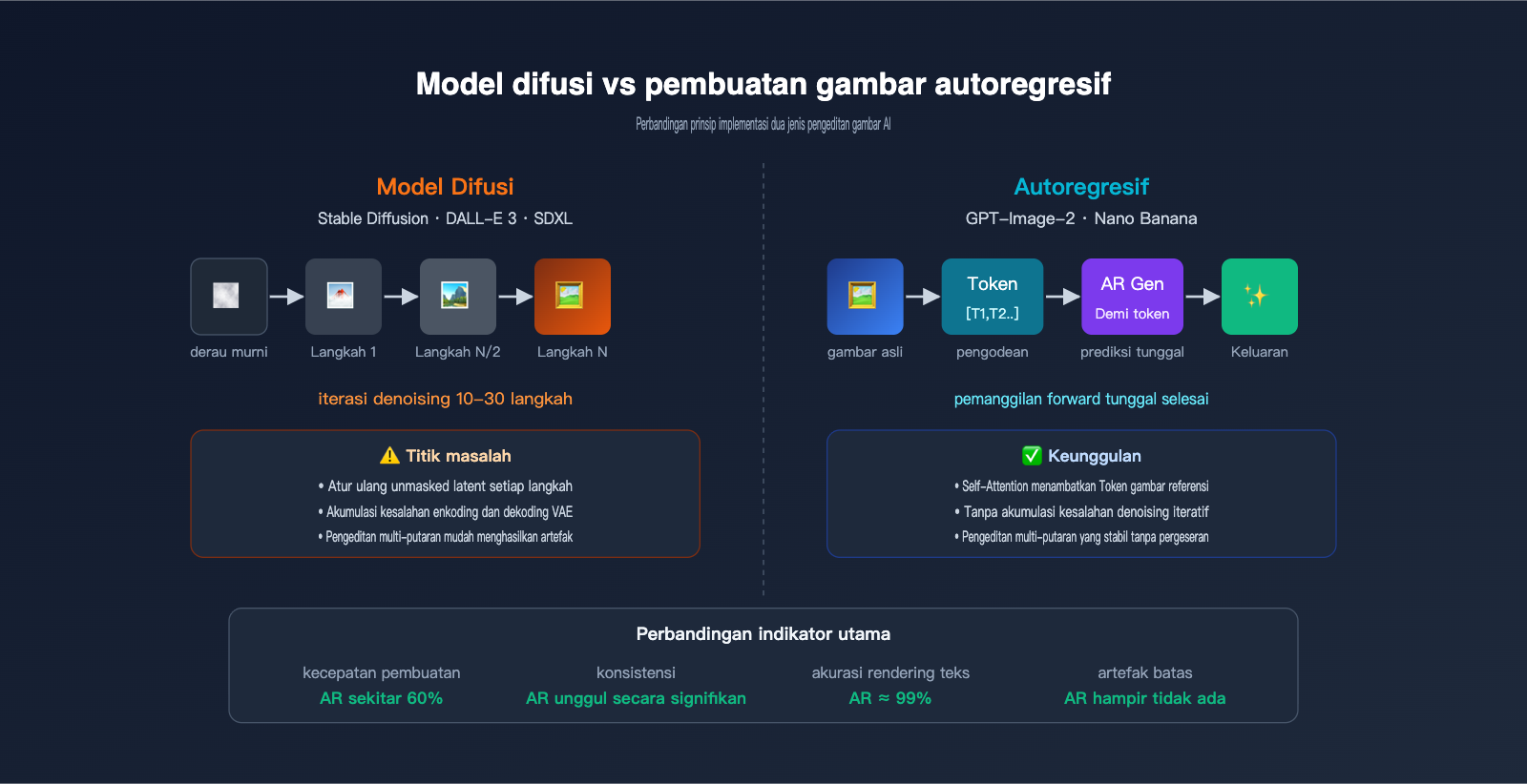
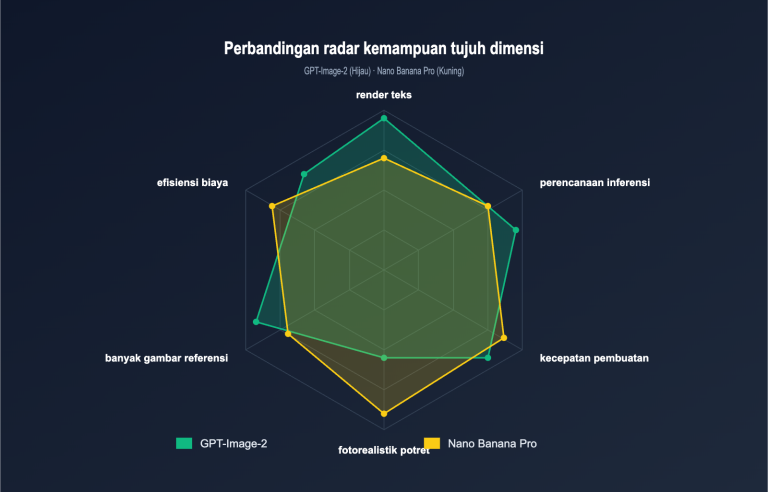
Perbedaan performa kedua paradigma ini dalam skenario pengeditan gambar sangat besar, seperti yang ditunjukkan pada tabel berikut:
| Perbandingan | Model Difusi (SD/DALL-E 3) | Model Autoregresif (GPT-Image-2/Nano Banana) |
|---|---|---|
| Metode Pembuatan | Iterasi penghilangan derau multi-langkah | Prediksi urutan token tunggal |
| Implementasi Mask | Mengatur ulang laten yang tidak di-mask setiap langkah | Batasan keras tingkat token |
| Pemrosesan Batas | Mudah muncul artefak jahitan laten | Transisi alami (tingkat semantik) |
| Render Teks | Sering gagal | Akurasi sekitar 99% |
| Pengeditan Multi-putaran | Akumulasi kehilangan pengkodean ulang | Hampir tidak ada pergeseran |
| Perintah Kompleks | Sulit untuk tata letak presisi | Mendukung tata letak 100+ objek |
| Kecepatan | Biasanya 10-30 detik | Sekitar 60% lebih cepat dari difusi |
| Render Teks Panjang | Sulit | Bahasa/skrip apa pun |
Masalah utama model difusi terletak pada kehilangan pengkodean ulang VAE — meskipun secara teori area yang tidak di-mask terkunci, konversi bolak-balik antara laten dan piksel akan menghasilkan perbedaan warna yang kecil. Setelah beberapa kali pengeditan, kehilangan tersebut terakumulasi menjadi artefak yang terlihat oleh mata. GPT-Image-2 melewati masalah ini dengan arsitektur autoregresif, di mana dekode token hanya terjadi sekali.
Namun, model autoregresif bukannya tanpa biaya. Biaya pembuatannya lebih tinggi, terutama karena jumlah token yang besar dan setiap token memerlukan forward Transformer yang lengkap. Kami menyarankan penggunaan GPT-Image-2 (dapat diakses melalui APIYI apiyi.com) untuk skenario yang mengutamakan konsistensi ekstrem dan render teks, sementara untuk skenario dengan konkurensi tinggi yang sensitif terhadap biaya, seri Stable Diffusion masih bisa dipertahankan sebagai pelengkap.
Praktik Prinsip Pengeditan gpt-image-2: Pemanggilan API dan Optimalisasi Konsistensi
Setelah memahami prinsip pengeditan gpt-image-2, mari kita lihat bagaimana menerapkan mekanisme ini secara maksimal. Berikut adalah contoh minimal yang dapat dijalankan untuk memanggil antarmuka pengeditan GPT-Image-2 melalui titik akhir yang kompatibel dengan APIYI:
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="Pertahankan identitas orang dan latar belakang, ubah warna baju dari putih menjadi biru tua saja",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Perhatikan penulisan prompt: jelaskan secara eksplisit apa yang harus dipertahankan dan apa yang harus diubah. Ini akan memicu mode Thinking pada GPT-Image-2 untuk merencanakan pembuatan gambar sesuai ekspektasi Anda. Jika ingin melakukan pengeditan area yang presisi, Anda bisa menambahkan parameter mask:
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="Ubah baju putih menjadi setelan jas biru tua",
size="1024x1024"
)
Mask adalah file PNG dengan ukuran yang sama, di mana area putih adalah area yang diizinkan untuk diubah, dan area hitam memaksa model untuk mempertahankan token gambar asli.
5 Saran Praktis untuk Optimalisasi Konsistensi
Terkait debugging konsistensi gambar AI yang nyata, kami merangkum 5 pengalaman dari pengujian langsung:
- Tentukan dengan jelas "apa yang harus dipertahankan" dalam prompt: Jangan hanya mengatakan "ubah X", katakan "pertahankan Y agar tetap sama, ubah X".
- Resolusi gambar referensi yang moderat: OpenAI merekomendasikan sisi terpanjang gambar referensi tidak melebihi 1024px; ukuran yang terlalu besar justru akan mengencerkan perhatian token.
- Gunakan gambar dasar yang sama untuk pengeditan multi-putaran: Jangan jadikan hasil edit sebelumnya sebagai input untuk putaran berikutnya. Sebaiknya gunakan gambar asli sebagai dasar untuk pengeditan dimensi yang berbeda, lalu gabungkan prompt di akhir.
- Pecah instruksi untuk skenario kompleks: Pecah perintah "ubah orang menjadi gaya Jepang dengan latar belakang senja" menjadi dua langkah, di mana setiap langkah hanya mengubah satu variabel.
- Pilih parameter kualitas high: Kualitas rendah akan mengurangi jumlah token dan secara langsung melemahkan konsistensi.
Pertukaran Harga dan Konsistensi gpt-image-2
| Kombinasi Parameter | Biaya per Gambar | Skenario Penggunaan |
|---|---|---|
| 1024×1024 low | $0,006 | Sketsa kreatif/pratinjau cepat |
| 1024×1024 medium | $0,053 | Gambar pendukung media sosial |
| 1024×1024 high | $0,211 | Pengeditan kelas komersial/iterasi berulang |
| 4K high | $0,50+ | Pencetakan/tampilan resolusi tinggi |
Biaya berbanding lurus dengan konsistensi—mode berkualitas tinggi memberikan lebih banyak token kepada model, sehingga secara alami dapat mempertahankan lebih banyak fitur gambar asli. Kami menyarankan untuk memprioritaskan penggunaan mode high di lingkungan produksi, dan Anda dapat lebih menghemat biaya hingga 50% melalui Batch API di APIYI apiyi.com.
FAQ Prinsip Pengeditan Gambar AI dan Tren Masa Depan
Q1: Apakah GPT-Image-2 melakukan modifikasi lokal seperti Photoshop atau menggambar ulang?
A: Ini adalah penggambaran ulang. Semua model gambar autoregresif perlu mengodekan gambar asli menjadi token, menghasilkan urutan token output yang lengkap, dan akhirnya mendekodekannya menjadi gambar baru. Bahkan jika mask diaktifkan, itu hanya memberikan batasan selama proses penggambaran ulang, bukan benar-benar menimpa piksel secara lokal.
Q2: Karena ini adalah penggambaran ulang, mengapa gambar setelah diedit terlihat hampir sama?
A: Hal ini bergantung pada empat lapisan mekanisme konsistensi: abstraksi fitur token visual, referensi global Self-Attention terhadap gambar asli, bias induktif data pelatihan, dan perencanaan eksplisit mode Thinking. Mekanisme ini membuat AI "secara aktif memilih" untuk mempertahankan area yang tidak disebutkan.
Q3: Apakah inpainting pada model difusi dianggap sebagai modifikasi lokal yang sebenarnya?
A: Tidak. Inpainting pada Stable Diffusion juga harus melewati proses encoding-decoding VAE pada area yang tidak di-mask, yang akan menyebabkan kehilangan re-encoding kecil. Pengeditan multi-putaran akan terakumulasi menjadi artefak yang terlihat, yang justru menjadi salah satu motivasi utama GPT-Image-2 beralih ke autoregresif. Anda dapat menggunakan APIYI apiyi.com untuk memanggil kedua model tersebut secara bersamaan guna melakukan verifikasi perbandingan.
Q4: Mengapa GPT-Image-2 dapat melakukan pengeditan multi-putaran tanpa pergeseran (drift)?
A: Karena arsitektur autoregresif merujuk pada urutan token gambar asli yang lengkap setiap kali melakukan pembuatan, sehingga tidak ada kesalahan akumulasi dari iterasi denoising. Dikombinasikan dengan perencanaan retensi eksplisit dari mode Thinking, stabilitas pengeditan multi-putaran jauh melampaui model difusi.
Q5: Haruskah saya menggunakan mask atau pengeditan prompt murni?
A: Prioritaskan penggunaan prompt + instruksi retensi yang jelas, karena ini dapat memanfaatkan perencanaan otomatis mode Thinking. Gunakan mask untuk batasan keras hanya jika batas area yang perlu diubah jelas dan harus sangat presisi (seperti bagian wajah tertentu).
Q6: Bagaimana perkembangan pengeditan gambar AI di masa depan?
A: Ada tiga tren: (1) Kepadatan informasi Tokenizer terus meningkat, mengurangi jumlah token dan biaya; (2) Unifikasi multimodal, di mana teks/gambar/video berbagi Transformer yang sama; (3) Peningkatan kemampuan penalaran Thinking, mendukung rantai pengeditan multi-langkah yang lebih panjang. Kami menyarankan untuk terus memantau pembaruan model baru di APIYI apiyi.com agar dapat segera mengevaluasi jalur peningkatan.
Kesimpulan: Memahami Prinsip untuk Menggunakan Alat dengan Baik
Model gambar autoregresif seperti GPT-Image-2 telah mengubah intuisi kita tentang "AI yang mengedit gambar". Mereka bukanlah modifikasi lokal ala Photoshop, melainkan penggambaran ulang cerdas berdasarkan pembuatan gambar autoregresif. Konsistensi berasal dari kolaborasi empat mekanisme: abstraksi semantik tokenisasi, penjangkaran global Self-Attention, bias pelatihan, dan mode Thinking.
Dengan memahami prinsip ini, Anda dapat menulis prompt yang benar-benar memicu perencanaan Thinking, menghindari jebakan pengeditan multi-putaran, dan menemukan titik keseimbangan antara biaya dan kualitas. Kami menyarankan untuk melakukan pengujian dan perbandingan praktis melalui platform APIYI apiyi.com, yang mendukung pemanggilan antarmuka terpadu untuk berbagai model utama seperti GPT-Image-2, Nano Banana, dan Stable Diffusion, sehingga memudahkan verifikasi cepat terhadap semua prinsip dan teknik optimalisasi yang disebutkan dalam artikel ini.
Artikel ini ditulis oleh Tim APIYI, disusun berdasarkan materi resmi dari OpenAI, Google DeepMind, dan pengujian langsung. Jika Anda perlu memanggil gpt-image-2 di lingkungan produksi, kunjungi situs web APIYI: apiyi.com untuk mendapatkan dokumentasi akses.