Note de l'auteur : Meta lance Llama 4 Scout et Maverick, basés sur une architecture MoE multimodale native. Scout propose une fenêtre de contexte de 10 millions de jetons, tandis que Maverick surpasse GPT-4o lors des évaluations globales. Cet article analyse en profondeur les détails techniques et les implications pour les développeurs.
Meta a officiellement dévoilé la famille de modèles Llama 4, avec les premiers modèles open source multimodaux natifs MoE, Llama 4 Scout et Maverick, qui suscitent un vif intérêt dans la communauté IA. Voici une analyse rapide de l'impact majeur de cet événement pour les développeurs et l'industrie.
Valeur ajoutée : Découvrez en 3 minutes les percées techniques, les performances et la valeur pratique de Llama 4 Scout et Maverick.

Aperçu des informations clés sur Llama 4 Scout et Maverick
| Élément | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|
| Date de sortie | 5 avril 2025 | 5 avril 2025 |
| Type d'architecture | MoE multimodal natif | MoE multimodal natif |
| Paramètres actifs | 17 milliards | 17 milliards |
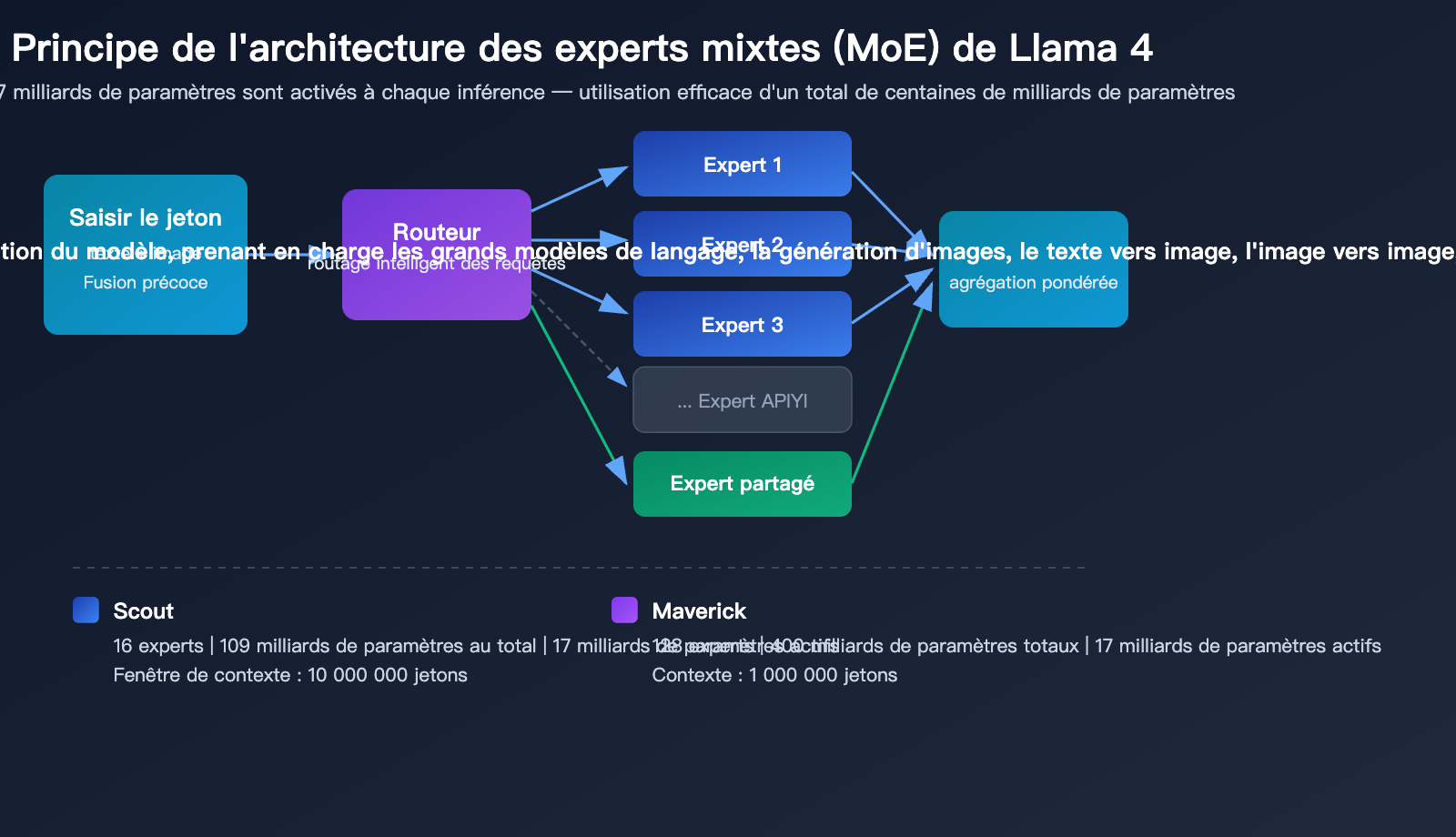
| Nombre d'experts | 16 | 128 |
| Nombre total de paramètres | 109 milliards | 400 milliards |
| Fenêtre de contexte | 10 millions de jetons | 1 million de jetons |
| Licence open source | Licence Llama | Licence Llama |
Positionnement clé de Llama 4 Scout et Maverick
Llama 4 est la quatrième génération de la famille de grands modèles de langage de Meta, et la première série Llama à adopter une architecture multimodale native et MoE (Mixture of Experts). Par rapport à la série Llama 3, Llama 4 a fait l'objet d'une refonte architecturale fondamentale.
Scout est positionné comme un modèle efficace pour le traitement de textes longs, offrant la plus grande fenêtre de contexte de l'industrie (10 millions de jetons) avec un coût d'inférence très réduit. Maverick est quant à lui positionné comme un modèle généraliste haute performance, atteignant des capacités globales supérieures à GPT-4o grâce à ses 128 réseaux d'experts.
Les poids des deux modèles sont déjà disponibles au téléchargement ; les développeurs peuvent les obtenir via llama.com et Hugging Face.
Analyse de l'architecture technique de Llama 4 Scout et Maverick
Architecture multimodale native Early Fusion
L'innovation architecturale majeure de Llama 4 réside dans son entraînement multimodal natif. Contrairement aux approches précédentes qui consistaient à greffer des modules visuels sur des modèles de langage existants, Llama 4 adopte dès la phase de pré-entraînement une stratégie d'Early Fusion (fusion précoce), intégrant les tokens textuels et visuels directement dans le réseau dorsal du modèle.
Cela signifie que pour comprendre des contenus mixtes texte-image, Llama 4 ne procède plus en deux étapes ("regarder l'image puis parler"), mais traite et raisonne sur l'image et le texte comme une entrée unifiée.
Mécanisme d'experts mixtes (MoE) de Llama 4
| Détails techniques | Scout (16 experts) | Maverick (128 experts) |
|---|---|---|
| Paramètres totaux | 109 milliards | 400 milliards |
| Activation par inférence | 17 milliards de paramètres | 17 milliards de paramètres |
| Experts routés | 16 + experts partagés | 128 + experts partagés |
| Efficacité d'inférence | Exécutable sur une H100 (INT4) | Exécutable sur un nœud H100 DGX |
| Architecture de contexte | iRoPE (attention sans entrelacement) | Attention standard |
L'avantage principal de l'architecture MoE est le suivant : bien que le nombre total de paramètres atteigne respectivement 109 et 400 milliards, seuls 17 milliards de paramètres sont activés à chaque inférence. Cela permet à Llama 4 Scout de fonctionner sur une seule carte graphique NVIDIA H100 avec une quantification INT4, abaissant considérablement les barrières au déploiement.
Données d'entraînement et échelle de Llama 4
Le volume de données d'entraînement de Llama 4 atteint plus de 30 000 milliards de tokens, soit le double de Llama 3. Le volume de données multilingues est dix fois supérieur à celui de Llama 3, couvrant 200 langues. L'entraînement utilise la précision FP8, atteignant une efficacité de 390 TFLOPs par GPU sur le modèle Behemoth.
Performances de Llama 4 Scout et Maverick
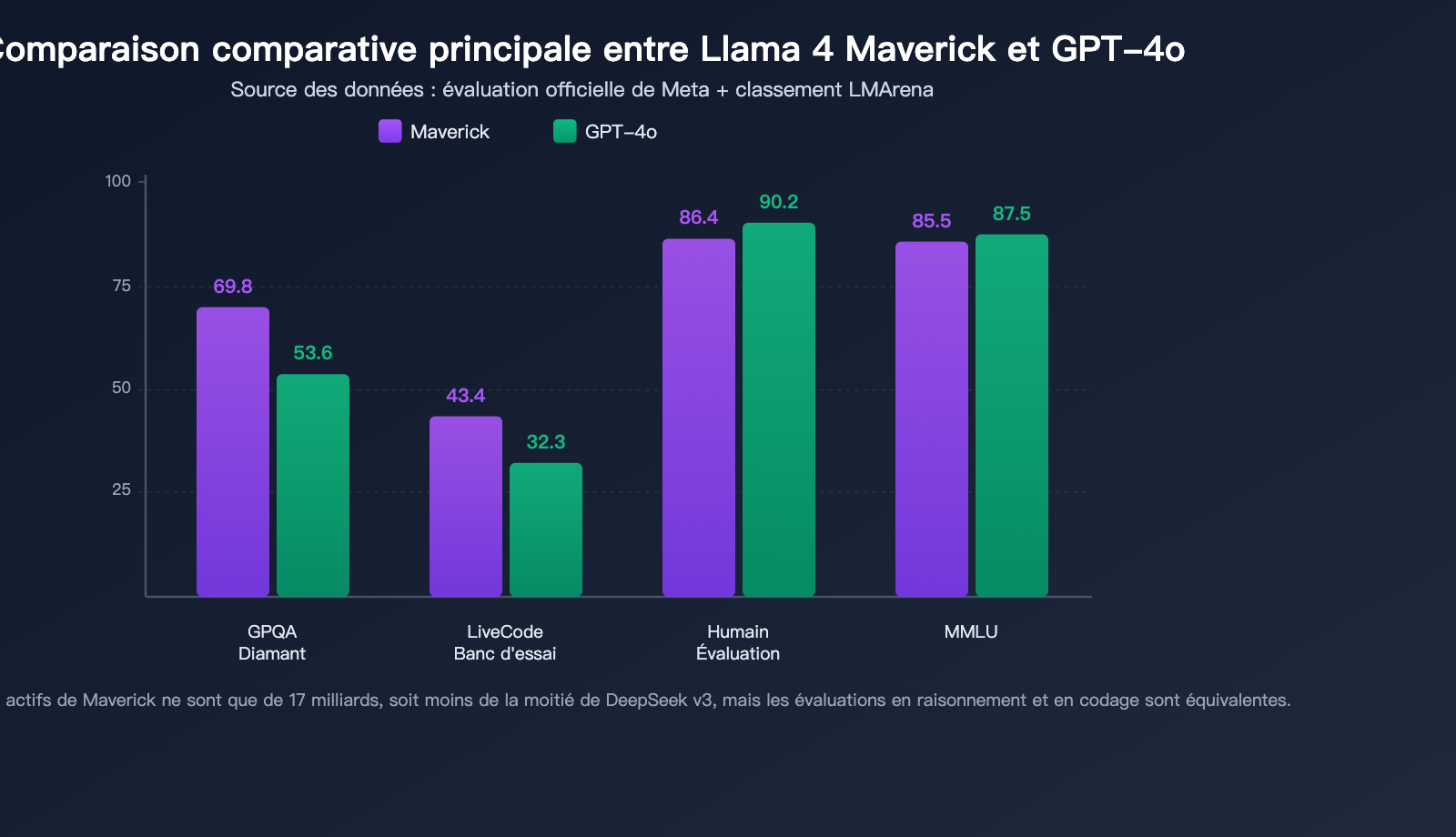
Données d'évaluation de Llama 4 Maverick
Maverick affiche des performances exceptionnelles dans plusieurs évaluations de référence, surpassant les capacités globales de GPT-4o et de Gemini 2.0 Flash :
| Benchmark | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | Évaluation |
|---|---|---|---|---|
| MMLU | 85.5 | ~87-88 | – | Proche du sommet |
| GPQA Diamond | 69.8 | 53.6 | – | Large avance |
| LiveCodeBench | 43.4 | 32.3 | – | Avance significative |
| HumanEval | 86.4% | 90.2% | – | Niveau similaire |
| LMArena ELO | 1417 | Inférieur à 1417 | Inférieur à 1417 | Niveau élite |
Quelques points forts à retenir :
Avance en raisonnement scientifique sur GPQA Diamond: Maverick obtient un score de 69.8 sur GPQA Diamond, soit plus de 16 points de pourcentage de plus que les 53.6 de GPT-4o, démontrant une solide capacité de raisonnement dans les disciplines spécialisées.
Excellence en codage sur LiveCodeBench: Dans le benchmark de programmation en temps réel LiveCodeBench, Maverick devance GPT-4o avec 43.4 points contre 32.3, tout en égalant DeepSeek v3 sur les tâches de raisonnement et de codage — alors que le nombre de paramètres actifs de Maverick représente moins de la moitié de celui de DeepSeek v3.
Niveau élite sur LMArena: La version expérimentale de Maverick a atteint un score ELO de 1417 sur LMArena (Chatbot Arena), se classant parmi les meilleurs modèles au monde.
Points forts de Llama 4 Scout
En tant que "petit" modèle avec seulement 17 milliards de paramètres actifs, les performances de Scout sont impressionnantes :
- Surpasse Gemma 3, Gemini 2.0 Flash-Lite et Mistral 3.1 sur une large gamme de benchmarks.
- Dépasse tous les modèles Llama 3 de la génération précédente, y compris le Llama 3.3 70B, pourtant bien plus volumineux.
- Dispose de la fenêtre de contexte de 10 millions de tokens la plus longue du secteur, capable de traiter environ 7,5 millions de mots.
- Peut être exécuté sur un seul GPU H100, avec un coût d'invocation du modèle extrêmement faible.
🎯 Conseil aux développeurs: Llama 4 Scout et Maverick prennent tous deux en charge les interfaces compatibles avec OpenAI. Pour tester rapidement les résultats réels de ces modèles, vous pouvez obtenir une interface API unifiée via la plateforme APIYI (apiyi.com). Une seule clé API suffit pour basculer entre l'invocation de divers modèles open source et propriétaires.
Llama 4 Scout et Maverick : quel impact pour les développeurs ?
La valeur ajoutée d'une fenêtre de contexte de 10 millions de tokens
La fenêtre de contexte de 10 millions de tokens de Scout est la plus longue disponible parmi les modèles publiés à ce jour. Cette capacité ouvre de nouveaux horizons applicatifs pour les développeurs :
- Analyse complète de bases de code : vous pouvez désormais soumettre l'intégralité d'un projet de taille moyenne à grande au modèle pour une analyse approfondie.
- Traitement de documents longs : traitez en une seule fois des centaines de pages de documentation technique, de contrats juridiques ou de rapports de recherche.
- Mémoire de conversation étendue : maintenez une mémoire contextuelle extrêmement longue dans vos applications conversationnelles.
- Extraction de données à grande échelle : extrayez par lots des informations structurées à partir de volumes massifs de textes non structurés.
Impact sur l'écosystème open source de Llama 4
| Dimension d'impact | Changement concret | Avantage pour le développeur |
|---|---|---|
| Seuil de déploiement | Scout exécutable sur une seule carte | Réduction des coûts matériels |
| Capacités du modèle | Niveau supérieur à GPT-4o | L'open source rattrape le propriétaire |
| Multimodal | Compréhension native texte-image | Aucun module visuel supplémentaire requis |
| Contexte | 10 millions de tokens | Nouveaux scénarios d'application |
| Personnalisation | Fine-tuning des poids ouvert | Optimisation pour des scénarios verticaux |
La sortie de Llama 4 marque la première fois qu'un modèle open source égale, voire dépasse, les modèles commerciaux fermés en termes de capacités globales. Pour les développeurs, cela signifie :
Avantage en termes de coûts : Le déploiement privé basé sur Llama 4 permet de réduire considérablement les coûts d'invocation du modèle, ce qui est particulièrement adapté aux environnements de production à haute fréquence.
Liberté de personnalisation : L'ouverture des poids signifie que les développeurs peuvent effectuer du fine-tuning, de la quantification ou de la distillation pour créer des modèles sur mesure adaptés à des domaines spécifiques.
Écosystème florissant : Dès le premier jour, Llama 4 a bénéficié du soutien de nombreuses plateformes cloud, dont AWS, Google Cloud, Azure, Together.ai, Groq et Fireworks.
Intégration de la plateforme Llama 4
Meta a intégré Llama 4 à ses plateformes sociales pour doter l'assistant Meta AI de capacités multimodales :
- WhatsApp : prise en charge de l'envoi d'images pour l'analyse et la conversation par IA.
- Messenger : questions-réponses interactives multimodales.
- Instagram Direct : compréhension d'images et assistance créative.
- Meta.ai : utilisation directe via l'interface web.
C'est la première fois qu'un grand modèle de langage est déployé à une telle échelle directement auprès des consommateurs, touchant des milliards d'utilisateurs.
Llama 4 Behemoth : le modèle phare toujours en entraînement
Outre Scout et Maverick, Meta a annoncé le modèle phare de la famille Llama 4 : Behemoth.
| Paramètre | Spécifications de Behemoth |
|---|---|
| Paramètres actifs | 288 milliards |
| Nombre d'experts | 16 |
| Nombre total de paramètres | Environ 2 000 milliards |
| État de l'entraînement | En cours |
Selon les données préliminaires publiées par Meta, Behemoth surpasse déjà GPT-4.5, Claude Sonnet 3.7 et Gemini 2.0 Pro dans plusieurs évaluations STEM. Maverick a bénéficié d'une amélioration de ses capacités grâce à la distillation des connaissances depuis Behemoth pendant son entraînement, ce qui explique comment Maverick atteint des performances de haut niveau avec un nombre de paramètres actifs réduit.
💡 Conseil : La sortie finale de Behemoth repoussera encore les limites des capacités des modèles open source. Les développeurs peuvent commencer dès maintenant à construire leurs applications sur Scout et Maverick, effectuer des tests comparatifs sur la plateforme APIYI (apiyi.com), puis basculer en toute transparence une fois Behemoth disponible.
Intégration rapide de Llama 4 Scout et Maverick
Exemple d'invocation API ultra-simple
Grâce à l'interface compatible OpenAI, vous pouvez appeler le modèle Llama 4 en seulement 10 lignes de code :
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{"role": "user", "content": "Explique le fonctionnement de l'architecture MoE"}]
)
print(response.choices[0].message.content)
Voir l’exemple d’invocation multimodal
import openai
import base64
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
# Lire et encoder une image locale
with open("image.jpg", "rb") as f:
image_data = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Veuillez décrire le contenu de cette image"},
{"type": "image_url", "image_url": {
"url": f"data:image/jpeg;base64,{image_data}"
}}
]
}]
)
print(response.choices[0].message.content)
🚀 Démarrage rapide : Nous vous recommandons d'obtenir votre clé API et des crédits de test gratuits via APIYI (apiyi.com). La plateforme prend en charge une interface unifiée pour Llama 4 Scout, Maverick et d'autres modèles populaires, facilitant ainsi la comparaison rapide des performances réelles de chaque modèle.
Questions fréquentes
Q1 : Comment choisir entre Llama 4 Scout et Maverick ?
Si vous devez traiter des textes très longs (comme des bases de code complètes ou l'analyse de longs documents), choisissez Scout (fenêtre de contexte de 10 millions de jetons). Si vous avez besoin du modèle généraliste le plus performant (128 experts, surpassant GPT-4o dans les évaluations), choisissez Maverick. Les deux peuvent être testés en conditions réelles via la plateforme APIYI (apiyi.com) pour vous aider à faire le meilleur choix.
Q2 : Llama 4 est-il entièrement gratuit ?
Llama 4 utilise la licence Llama pour ses poids ouverts, autorisant un usage commercial. Cependant, les entreprises comptant plus de 700 millions d'utilisateurs actifs mensuels doivent demander une licence spéciale à Meta. Pour la grande majorité des développeurs et des entreprises, l'utilisation est gratuite. Si vous ne souhaitez pas effectuer votre propre déploiement, vous pouvez également y accéder via des plateformes tierces comme APIYI (apiyi.com) pour une invocation du modèle à la demande.
Q3 : Llama 4 Maverick est-il vraiment meilleur que GPT-4o ?
Sur des évaluations clés comme GPQA Diamond (raisonnement scientifique) et LiveCodeBench (programmation en temps réel), Maverick surpasse effectivement GPT-4o de manière significative. Sur MMLU et HumanEval, les deux modèles sont proches. Dans le classement des préférences humaines LMArena, Maverick a également atteint un score ELO de premier plan. Dans l'ensemble, Maverick se situe dans la même catégorie que GPT-4o dans les évaluations globales, avec une avance sur certains indicateurs.
Résumé
Points clés de Llama 4 Scout et Maverick :
- Innovation architecturale : Premiers modèles open source MoE nativement multimodaux, utilisant une architecture Early Fusion pour une compréhension véritablement unifiée du texte et de l'image.
- Percée des performances : Maverick surpasse GPT-4o de plus de 16 points sur le benchmark GPQA Diamond, tandis que Scout, avec 17 milliards de paramètres actifs, surpasse Llama 3.3 70B.
- Révolution des usages : Une fenêtre de contexte de 10 millions de jetons et des poids ouverts ouvrent de nouveaux scénarios d'application et des possibilités de déploiement inédites pour les développeurs.
La sortie de Llama 4 marque l'entrée des grands modèles de langage open source dans une nouvelle ère. Que ce soit pour concevoir des applications d'entreprise ou des projets personnels, les développeurs peuvent désormais s'appuyer sur Llama 4 pour obtenir des capacités comparables aux meilleurs modèles propriétaires. Nous vous recommandons d'utiliser APIYI (apiyi.com) pour tester rapidement la série Llama 4 ; la plateforme propose des crédits gratuits et une interface unifiée pour plusieurs modèles, facilitant ainsi le choix et l'intégration pour les développeurs.
📚 Références
-
Blog officiel de Meta AI – Annonce de Llama 4 : Source faisant autorité sur les détails techniques et les données d'évaluation des modèles.
- Lien :
ai.meta.com/blog/llama-4-multimodal-intelligence - Description : Contient une présentation complète de l'architecture, les données d'évaluation et les détails de la publication.
- Lien :
-
Site officiel de Llama – Téléchargement des modèles : Accédez aux poids et à la documentation de Llama 4.
- Lien :
llama.com/models/llama-4 - Description : Propose le téléchargement des modèles, les informations de licence et la documentation technique.
- Lien :
-
Hugging Face – Bibliothèque de modèles Llama 4 : Hébergement par la communauté open source et guide d'utilisation.
- Lien :
huggingface.co/meta-llama - Description : Fournit les fiches des modèles, les versions quantifiées et les discussions de la communauté.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à partager vos retours d'expérience sur Llama 4 dans les commentaires. Pour plus d'informations sur l'intégration des modèles d'IA, consultez le centre de documentation APIYI sur docs.apiyi.com.