If you've recently seen people buzzing about "Magi AI" or "MAGI-1" but aren't sure how it differs from Sora, Kling, or Veo, this guide is for you. Magi AI is a fascinating open-source video generation model from Sand AI—it's the world's first "autoregressive video generation model" to reach top-tier performance, and it supports infinite-length video generation.
Core Value: By the end of this article, you'll understand what Magi AI is, why it takes a different path than Sora/Kling, what you can do with it, and how to get it running in 5 minutes.

What is Magi AI: Key Takeaways
In a nutshell: Magi AI = An open-source video generation model by Sand AI based on a hybrid "autoregressive + diffusion" architecture.
It was developed by the Sand.ai team (led by CEO Yue Cao, a co-author of the classic Swin Transformer paper). MAGI-1 was first open-sourced on April 21, 2025, and iterated to Magi-1.1 in 2026. The code, weights, and inference tools are all available on GitHub and Hugging Face under the Apache 2.0 license.
| Feature | Description | Value |
|---|---|---|
| License | Apache 2.0 | Fully commercial-ready |
| Model Scale | 4.5B / 24B dual versions | Covers everyone from individuals to enterprises |
| Core Architecture | Autoregressive + Diffusion Transformer | World's first top-tier autoregressive video model |
| Killer Feature | Infinite-length video generation | Something Sora/Kling can't do |
| Building Block | 24-frame chunk-by-chunk generation | Supports streaming generation |
| Physics Understanding | Physics-IQ 56.02% | Significantly outperforms peers |
| Controllability | Chunk-wise prompting | Frame-level precision control |
| GitHub | SandAI-org/MAGI-1 | Full code + weights |
💡 Quick Take: Magi AI takes a completely different route than Sora, Veo, or Kling. Those mainstream models generate the entire clip at once, which imposes a length limit. Magi-1, however, uses chunk-by-chunk autoregressive generation, meaning it can theoretically keep going forever. This is a genuine, disruptive innovation in the AI video space. If you want to compare current mainstream video generation models, you can use APIYI (apiyi.com) to access Veo, Kling, and Wan in one place, then pair that with the open-source Magi running locally—it's the most cost-effective way to benchmark them.
Magi AI Core Technical Architecture
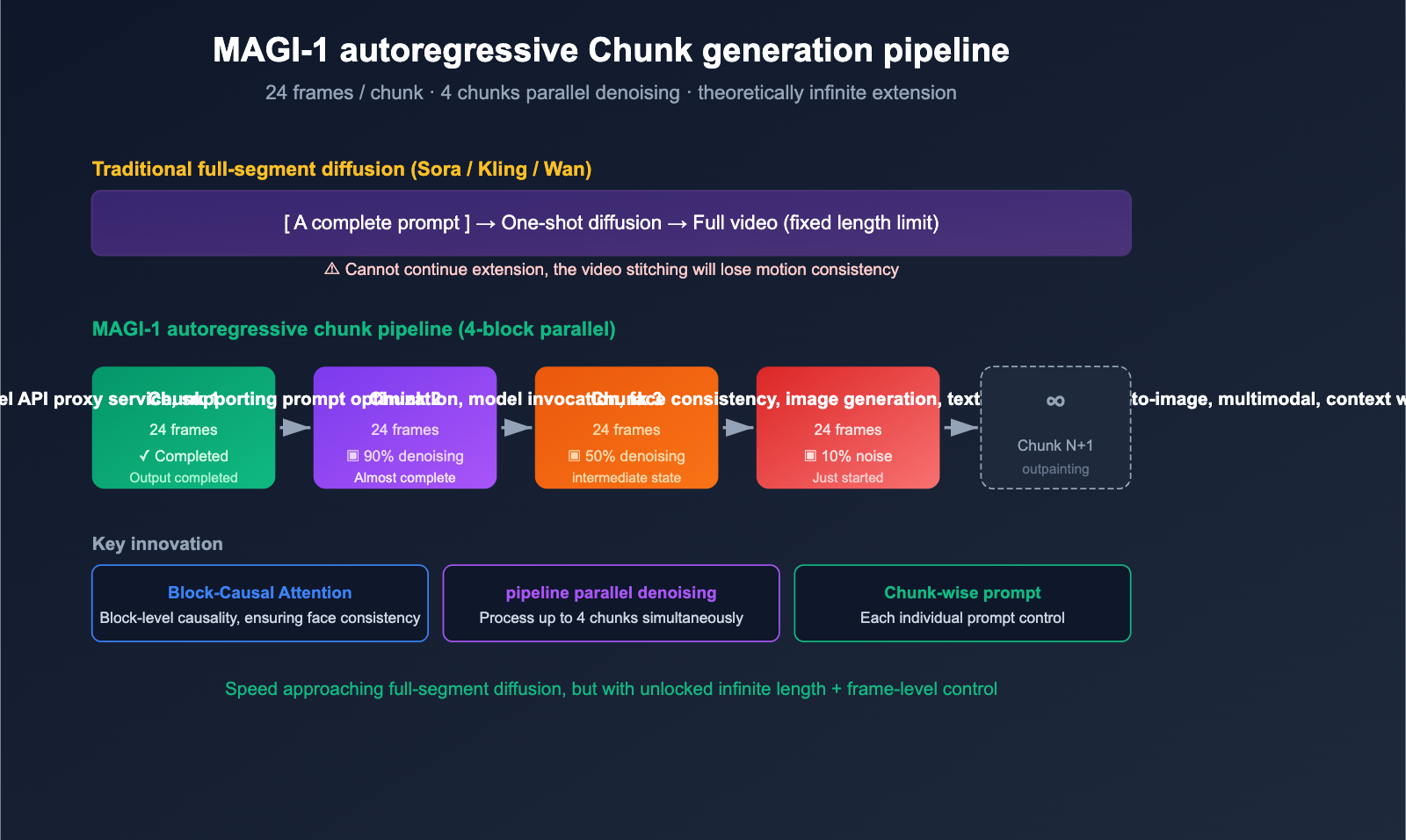
To understand what makes Magi AI different, you first need to grasp its "autoregressive chunk generation" mechanism—this is the key differentiator between it and all other mainstream video models.
Chunk-by-Chunk Autoregressive Generation
The vast majority of mainstream video models (like Sora, Veo, Kling, and Wan) follow a full-sequence diffusion approach:
[Full video prompt] → [One-shot diffusion denoising] → [Full video output]
The problem with this approach is that the maximum length is fixed. Sora 1.0 is capped at 60 seconds, while Kling handles 5-10 seconds at a time. Anything longer requires "stitching," which often leads to a loss of motion consistency.
Magi-1, however, uses a hybrid autoregressive + chunk-level diffusion approach:
prompt → Chunk 1 (24 frames) diffusion denoising → Chunk 2 (24 frames) → Chunk 3 → ... → ∞
While each chunk still uses diffusion denoising to ensure quality, the chunks themselves are autoregressive—each subsequent chunk is generated based on the previous one. This unlocks the ability to create "infinite-length videos," a capability other models simply don't have.
Pipelined Parallelism: 4-Chunk Simultaneous Denoising
Even smarter, Magi-1 doesn't make you wait for "Chunk 1 to finish completely before starting Chunk 2." Its pipeline design supports up to 4 chunks being processed simultaneously—once the current chunk is denoised to a certain point, the next one can begin pre-warming. This ensures that autoregressive generation isn't significantly slower than full-sequence diffusion.
Diffusion Transformer + Multiple Innovations
At its core, Magi-1 uses a Diffusion Transformer (DiT) architecture and integrates a host of training efficiency optimizations:
| Technical Point | Function |
|---|---|
| Block-Causal Attention | Chunk-level causal attention to ensure autoregressive consistency |
| Parallel Attention Block | Parallel attention blocks for speed |
| QK-Norm + GQA | Training stability + inference efficiency |
| Sandwich Normalization in FFN | Large Language Model training stability |
| SwiGLU | Modern activation function |
| Softcap Modulation | Prevents attention score explosion |
This tech stack is nearly identical to the "modern Transformer arsenal" used by top-tier Large Language Models like Llama 3 and Mistral. This is exactly why Magi-1 can achieve top-tier video quality at a 4.5B/24B parameter scale that's actually "runnable" for individuals.
Dual Versions: 4.5B / 24B
| Version | Parameters | Use Case | Hardware Requirements |
|---|---|---|---|
| MAGI-1 4.5B | 4.5 B | Individual developers, local experiments | Single GPU (24GB+) |
| MAGI-1 24B | 24 B | Production deployment, highest quality | Multi-GPU / H100 recommended |
Sand AI has open-sourced both versions simultaneously. The 4.5B version is designed so that "independent developers can play with it," while the 24B version is the flagship model aimed at setting new benchmarks.
title: Core Capabilities of Magi AI
description: An overview of Magi AI's standout features, including infinite video generation, advanced physics understanding, and precise frame-level control.
Core Capabilities of Magi AI
Capability 1: Infinite Video Generation
This is Magi-1's most unique feature—something other mainstream video models simply can't do. The official documentation explicitly states: "Magi-1 is the sole model in AI video generation that provides infinite video extension capabilities."
What this means for you: You can have Magi-1 generate a 5-minute, 10-minute, or even 1-hour continuous video. The consistency of motion and scenes is far superior to "stitching" clips together. This is a huge win for short dramas, long-form commercials, and educational videos.
Capability 2: Top-Tier Physics Understanding
On the Physics-IQ benchmark, Magi-1 scored 56.02%, significantly outperforming all current peer models. Physics-IQ tests a model's ability to predict how the physical world will behave—where a ball will roll, how water will flow, or how clothing will flutter.
With better physics understanding, the "AI look" of the footage decreases, making the motion feel much closer to the real world.
Capability 3: Chunk-wise Prompting
Because it generates content chunk-by-chunk, Magi-1 allows you to provide a specific prompt for every 24-frame block:
chunk 1: "A cat running on the grass"
chunk 2: "The cat starts to jump"
chunk 3: "The cat is distracted by a butterfly and stops"
chunk 4: "The cat chases the butterfly into the sky"
This level of fine-grained control is nearly impossible with traditional diffusion models that generate the entire sequence at once. It effectively brings the workload of "long-form video storyboarding" down to an engineering-friendly level.
Capability 4: Powerful Image-to-Video (I2V)
Magi-1 performs exceptionally well on Image-to-Video tasks. By providing a static image plus a text description, it can generate a video that is highly consistent with the image while maintaining natural motion. This is much more controllable than pure text-to-image generation, making it better suited for real-world production scenarios.
Capability 5: Superior Prompt Following
In its research paper, Sand AI specifically tested instruction following. The results show that Magi-1’s ability to follow instructions is significantly better than Wan 2.1 and HunyuanVideo, putting it on par with the closed-source Hailuo i2v-01. This means the prompt you write is actually taken seriously, rather than the model just "doing its own thing."
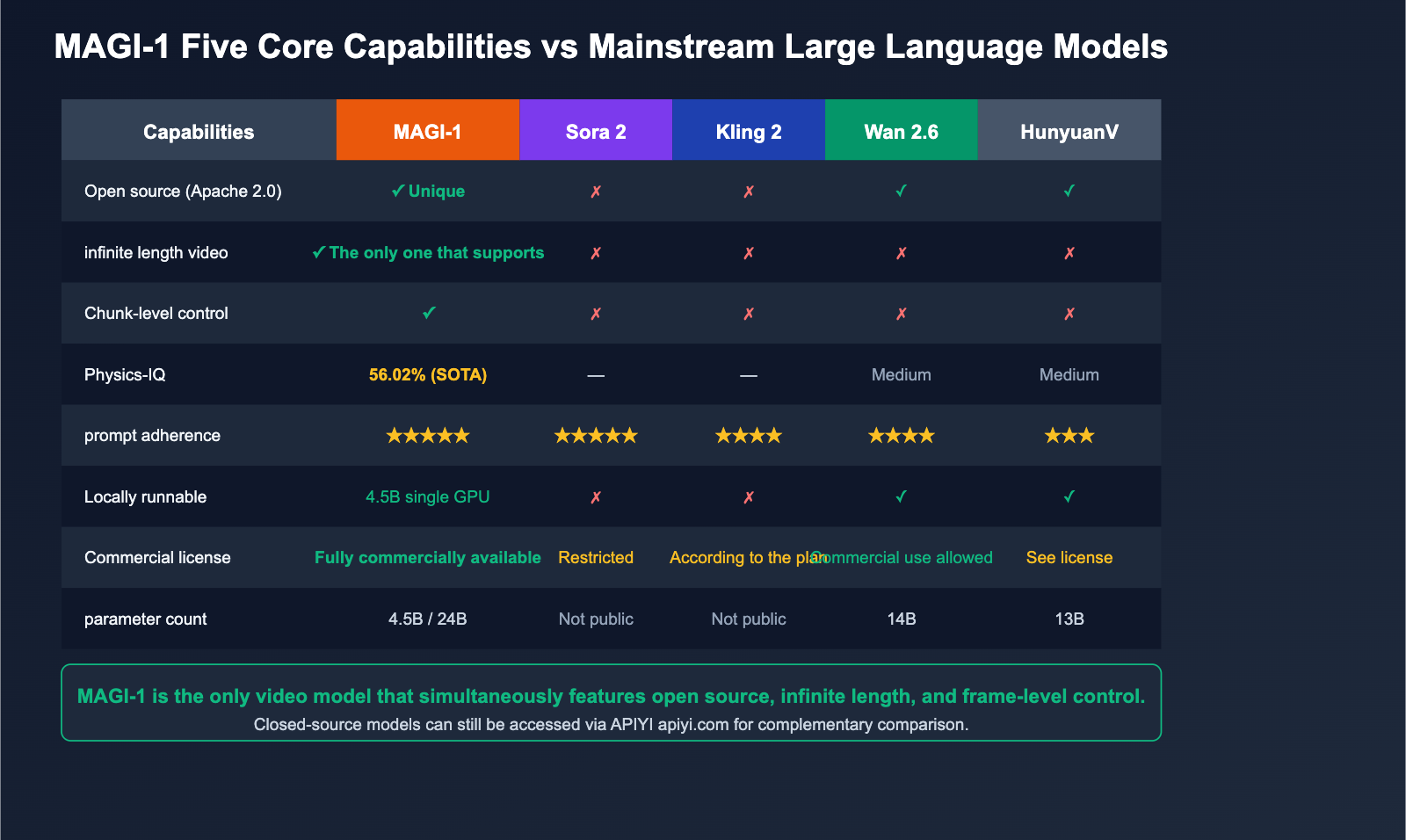
Magi AI vs. Mainstream Video Models
The question we hear most from new users is: "How does Magi compare to Sora, Kling, and Wan?" Here is a clear comparison table for you.
| Comparison Dimension | MAGI-1 | Sora 2 | Kling 2 | Wan 2.6 | HunyuanVideo |
|---|---|---|---|---|---|
| Open Source | ✅ Apache 2.0 | ❌ | ❌ | ✅ | ✅ |
| Architecture | Autoregressive + Diffusion | Diffusion | Diffusion | Diffusion | Diffusion |
| Infinite Length | ✅ Only one supported | ❌ | ❌ | ❌ | ❌ |
| Chunk-level Control | ✅ | ❌ | ❌ | ❌ | ❌ |
| Parameter Count | 4.5B / 24B | Undisclosed | Undisclosed | 14B | 13B |
| Physics-IQ | 56.02% | — | — | Medium | Medium |
| Prompt Adherence | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| Local Execution | ✅ 4.5B Single GPU | ❌ | ❌ | ✅ | ✅ |
| Commercial Use | ✅ Apache 2.0 | ⚠ Restricted | ⚠ Per plan | ✅ | ⚠ See license |
🎯 Verdict: If you need "top-tier image quality + one-off short videos," Sora 2 / Kling 2 remain the top choices. If you need "open source + long-form video + frame-level control," Magi AI is currently the only answer. If you want to "run locally while using APIs for benchmarking," I recommend deploying MAGI-1 4.5B locally and using the APIYI (apiyi.com) API proxy service to call closed-source models like Veo or Sora for a comprehensive comparison.
Getting Started with Magi AI

Method 1: Web Online Trial (Fastest)
The easiest way is to simply open the official Web App:
- Entry:
magi.sand.ai/app/projects - Register an account to get started.
- No environment configuration required; it runs right in your browser.
Perfect for users who want to "see the results before diving in."
Method 2: Local GitHub Source Deployment
If you're doing research or want to use it long-term locally, pull the source from GitHub:
# Clone the repository
git clone https://github.com/SandAI-org/MAGI-1.git
cd MAGI-1
# Install dependencies
pip install -r requirements.txt
# Download 4.5B weights (approx. 9GB)
huggingface-cli download sand-ai/MAGI-1 --local-dir ./ckpt/
# Run a minimal example
python inference.py \
--model_path ./ckpt/4.5B_base \
--prompt "A cat walking on the snow, cinematic lighting" \
--output ./output/cat.mp4 \
--num_chunks 4
💡 Tip: For your first local run, I recommend starting with the 4.5B model on a single 24GB VRAM GPU (like an RTX 3090/4090). While the 24B version offers higher quality, it requires multiple H100s, which increases costs by an order of magnitude.
Method 3: Pull Weights Directly from Hugging Face
huggingface-cli download sand-ai/MAGI-1 \
--include "ckpt/magi/4.5B_base/*" \
--local-dir ./
Weights are stored in the standard safetensors format and can be loaded directly using diffusers or transformers.
Recommended Workflow: Local Magi + Mainstream Closed-Source API Comparison
For developers, the most pragmatic workflow looks like this:
- Run MAGI-1 4.5B Locally: Utilize its unique capabilities for infinite-length video and frame-level control.
- API Call for Veo / Sora / Kling: Use these when you need the absolute highest single-segment image quality.
- Unified Access: Use APIYI (apiyi.com) to access top-tier overseas closed-source video models in one place, avoiding the headaches of managing multiple accounts, network restrictions, and billing.
- Side-by-Side Comparison: Run both sets on the same prompt to pick the output that best fits your current task.
Who is Magi AI for?
Scenario 1: Creators needing long-form video
For short dramas, long-form advertisements, educational videos, and documentaries, the traditional "5-second clip" approach has hit a bottleneck. Magi-1’s infinite-length generation is currently the only out-of-the-box solution.
Scenario 2: Directors requiring precise shot control
"Chunk-wise prompting" lets you control every segment of the footage just like writing a storyboard. This is incredibly useful for short-video creators, animation storyboard artists, and commercial directors.
Scenario 3: Video generation researchers / Open-source contributors
With an Apache 2.0 license, full weights, a research paper, and a GitHub repository, Magi is currently the best open-source reference implementation for studying "autoregressive video generation." If you're doing research in this field, Magi-1 is a must-read and must-run project.
Scenario 4: Small to medium-sized teams looking for local deployment
Closed-source models like Sora and Kling can only be used via API, meaning you don't have full control over your data. Magi-1 is released under the Apache 2.0 license with downloadable weights, so it can be fully deployed in your own private cloud, making it very friendly for data-sensitive industries (healthcare, finance, education).
Magi AI FAQ
Q1: Is Magi AI free? Can it be used commercially?
It is completely free and fully available for commercial use under the Apache 2.0 license. This is one of Magi's biggest advantages over closed-source models like Sora or Kling. You only need to cover the hardware/GPU compute costs; there are no model invocation fees, no monthly subscriptions, and no commercial restrictions.
Q2: Which is better: Magi-1, Wan 2.6, or HunyuanVideo?
According to the comparison data in the Sand AI paper, Magi-1 leads in Physics-IQ (physical understanding), prompt adherence, and motion quality compared to Wan 2.1 and HunyuanVideo. However, Wan 2.6 is a newer version with a more mature community ecosystem and toolchain. Our honest advice: Use Wan 2.6 for short videos and high-fidelity scenes, and use Magi-1 for long-form video and precise control scenarios. They aren't mutually exclusive.
Q3: Is “infinite length video” actually infinite?
Theoretically, yes. Magi-1's autoregressive chunk generation mechanism has no inherent length limit, so you can keep it generating indefinitely. Practical limitations mainly come from VRAM and time: VRAM only needs to store the state of the current few chunks, so it won't crash; however, the time required grows linearly—a 5-minute video takes about 5 times longer than a 1-minute video.
Q4: How big is the gap between the 4.5B and 24B versions?
The 4.5B version is the "most powerful autoregressive video model that can run on consumer-grade graphics cards." Its quality already surpasses most early closed-source models, though it still trails top-tier flagships like Sora 2 or Kling 2. The 24B version is the true "benchmark-crushing" release, with quality approaching leading closed-source models. If you're doing personal creative work or research, 4.5B is perfectly sufficient; for commercial-grade production, we recommend the 24B version paired with multi-card H100s.
Q5: Should I replace the Sora / Kling models I currently use with Magi?
No need to replace them; we suggest using them complementarily. Sora and Kling still have advantages in single-segment image quality and cinematic language, while Magi has unique strengths in length, control, and open-source autonomy. The best strategy is: use APIYI (apiyi.com) to access overseas closed-source models for high-quality short clips, and use local Magi deployments for long-form videos and precise control. Choose the right tool for the specific scenario.
Q6: How can developers in China download the Magi-1 weights?
You can download them directly from Hugging Face (huggingface.co/sand-ai/MAGI-1). If you encounter network issues, you can use the hf-mirror or ModelScope mirrors. Sand AI is a Chinese AI startup and is very developer-friendly; there are plenty of Chinese tutorials and discussions in the community.
Summary
Magi AI stands out as one of the most innovative open-source video generation projects for 2025-2026. It represents three major breakthroughs:
- Validation of the Autoregressive Video Generation Path: Magi-1 is the world's first autoregressive video model to reach top-tier performance, proving that "chunk-by-chunk + Diffusion" is a viable alternative to the "full-sequence diffusion" approach.
- Infinite-Length Video Becomes Reality: This is a capability that Sora, Kling, and Veo haven't achieved yet, and Magi is the first to deliver it as an open-source solution.
- Raising the Bar for the Open-Source Video Ecosystem: With an Apache 2.0 license, full weights, and a 4.5B consumer-grade version, it's now a reality for individual developers to run top-tier video models on their own hardware.
🚀 Actionable Advice: If you want to experience Magi AI's capabilities today, here's the fastest path: First, head over to
magi.sand.ai/app/projectsto sign up and try it out online. If you like the results, follow the GitHub README to deploy the 4.5B version locally. Finally, compare the output of Magi (local) with Veo, Sora, or Kling (accessed via APIYI at apiyi.com) to build your own personal "model toolkit." This way, you'll have the right weapon for every task, whether you're creating long-form videos, detailed storyboards, or chasing the highest quality for a single shot.
Author: APIYI Team — Dedicated to providing developers with stable access to mainstream Large Language Models. Visit apiyi.com to learn more.
References
-
MAGI-1 GitHub Main Repository
- Link:
github.com/SandAI-org/MAGI-1 - Description: Source code, weight download scripts, and inference examples.
- Link:
-
MAGI-1 Hugging Face Model Card
- Link:
huggingface.co/sand-ai/MAGI-1 - Description: 4.5B / 24B dual-version weights and documentation.
- Link:
-
MAGI-1 Official Paper (PDF)
- Link:
static.magi.world/static/files/MAGI_1.pdf - Description: Complete technical details and benchmark results.
- Link:
-
Sand AI Official Magi Introduction Page
- Link:
sand.ai/magi - Description: Project homepage and product overview.
- Link:
-
MAGI-1 Online Web App
- Link:
magi.sand.ai/app/projects - Description: Try it directly in your browser.
- Link:
-
ComfyUI Wiki – MAGI-1 Report
- Link:
comfyui-wiki.com/en/news/2025-04-23-magi-1-autoregressive-video-generation-model-released - Description: In-depth third-party reporting and comparisons.
- Link: