최근 "Magi AI"나 "MAGI-1"에 대한 이야기가 많이 들리는데, Sora, Kling, Veo와는 도대체 뭐가 다른지 궁금하셨나요? 이 글은 그런 분들을 위한 입문 가이드입니다. Magi AI는 Sand AI에서 오픈소스로 공개한 매우 흥미로운 비디오 생성 모델로, **전 세계 최초로 일류 수준에 도달한 "자기회귀(Autoregressive) 비디오 생성 모델"**이며 무제한 길이의 비디오 생성을 지원합니다.
핵심 가치: 이 글을 읽고 나면 Magi AI가 무엇인지, 왜 Sora나 Kling과는 다른 길을 가고 있는지, 어디에 활용할 수 있는지, 그리고 5분 만에 실행하는 방법까지 확실히 알게 되실 겁니다.

Magi AI란 무엇인가: 핵심 요약
한 문장 정의: Magi AI = Sand AI가 오픈소스로 공개한, "자기회귀 + 확산(Diffusion)" 혼합 아키텍처 기반의 비디오 생성 모델.
이 모델은 Sand.ai 팀(CEO는 클래식 Swin Transformer 논문의 공동 저자인 Yue Cao)이 개발했습니다. 2025년 4월 21일 MAGI-1을 처음 공개했고, 2026년에는 Magi-1.1로 업그레이드되었습니다. 코드, 가중치, 추론 도구 모두 GitHub와 Hugging Face를 통해 Apache 2.0 라이선스로 공개되어 있습니다.
| 항목 | 설명 | 가치 |
|---|---|---|
| 오픈소스 라이선스 | Apache 2.0 | 완전 상업적 이용 가능 |
| 모델 규모 | 4.5B / 24B 듀얼 버전 | 개인부터 기업까지 전 범위 지원 |
| 핵심 아키텍처 | 자기회귀 + Diffusion Transformer | 세계 최초 일류 자기회귀 비디오 모델 |
| 킬러 기능 | 무제한 길이 비디오 생성 | Sora/Kling도 불가능한 기능 |
| 기본 블록 | 24프레임 chunk-by-chunk 생성 | 스트리밍 생성 지원 |
| 물리 이해도 | Physics-IQ 56.02% | 동종 모델 대비 압도적 우위 |
| 제어 가능성 | chunk-wise 프롬프트 | 프레임 단위 정밀 제어 |
| GitHub | SandAI-org/MAGI-1 | 전체 코드 + 가중치 |
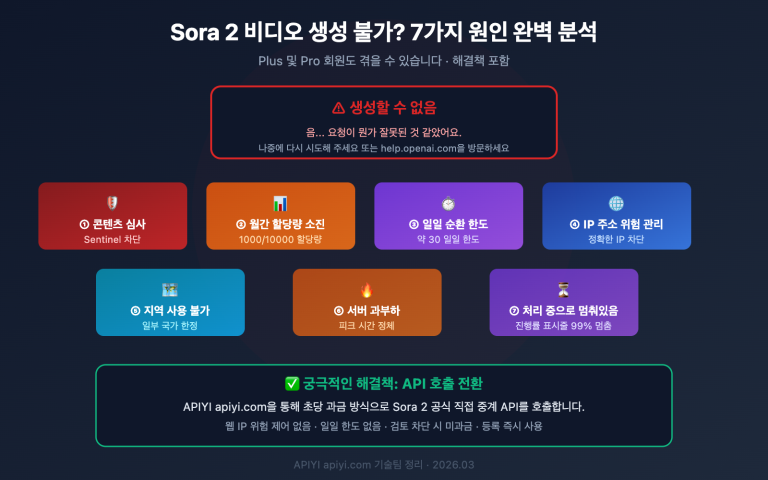
💡 빠른 이해: Magi AI는 Sora, Veo, Kling과는 완전히 다른 길을 걷고 있습니다. 기존 주류 모델들은 전체 영상을 한 번에 생성하기 때문에 길이에 제한이 있지만, Magi-1은 청크(chunk) 단위로 자기회귀 생성을 수행하므로 이론상 무한히 영상을 이어갈 수 있습니다. 이는 AI 비디오 분야에서 진정한 차별화 혁신입니다. 현재 주류 비디오 생성 모델들을 비교 테스트하고 싶다면, APIYI(apiyi.com)를 통해 Veo, Kling, Wan 등을 한 번에 호출하고 로컬에서 오픈소스인 Magi를 실행해 보는 것이 가장 가성비 좋은 비교 전략입니다.
Magi AI의 차별점을 이해하려면, 다른 주류 비디오 모델들과 가장 큰 차이점인 '자기회귀(Autoregressive) 청크 생성' 메커니즘을 먼저 살펴봐야 해요.
Magi AI의 핵심 기술 아키텍처
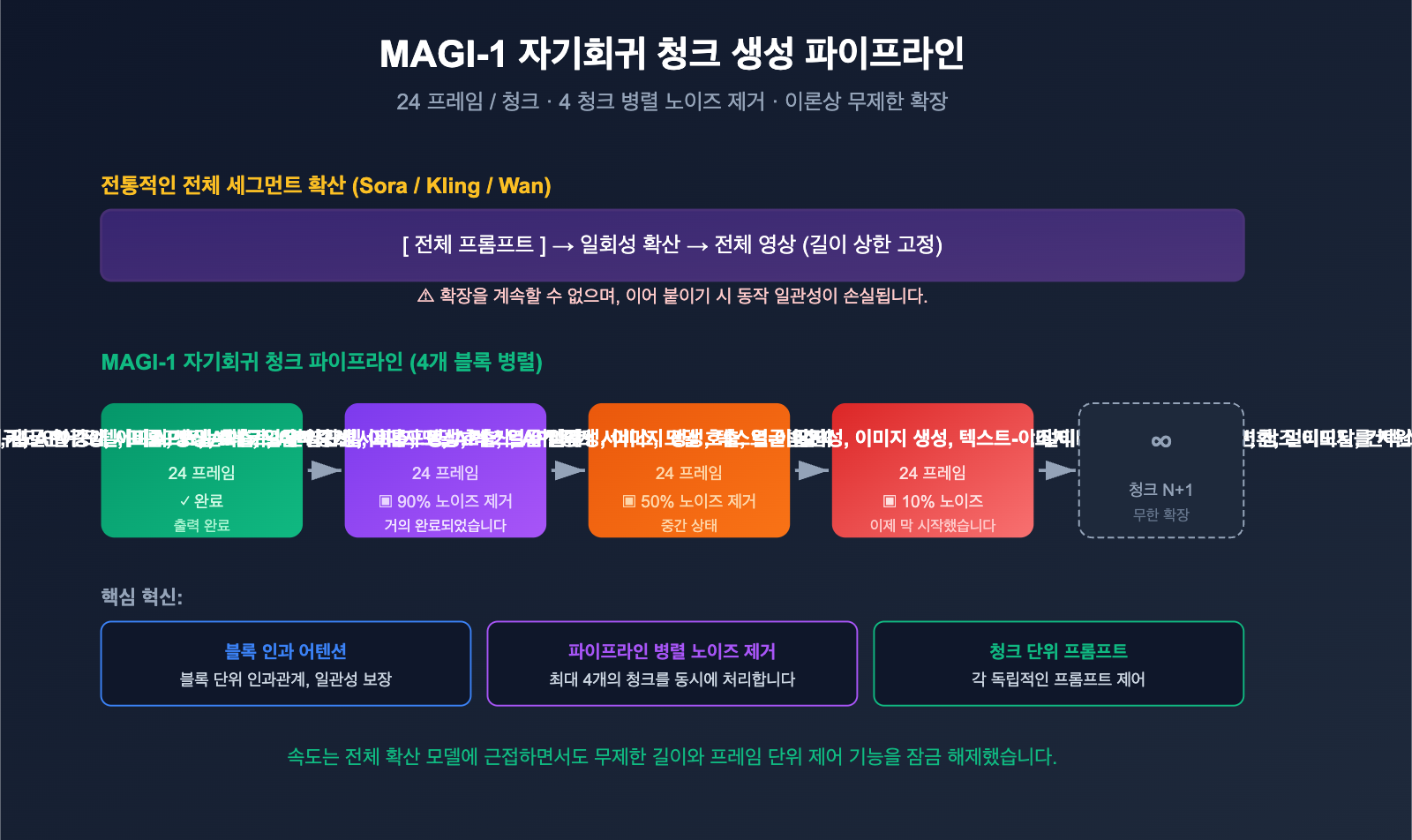
청크 단위(Chunk-by-chunk) 자기회귀 생성
대부분의 주류 비디오 모델(Sora, Veo, Kling, Wan 등)은 전체 구간 확산(Full-sequence diffusion) 방식을 사용합니다.
[전체 비디오 프롬프트] → [일괄 확산 노이즈 제거] → [전체 비디오 출력]
이 방식의 문제점은 길이 제한이 고정되어 있다는 점이에요. Sora 1.0은 한 번에 최대 60초, Kling은 5~10초 정도인데, 더 길게 만들려면 '이어 붙이기(접합)'가 필요하며, 이 과정에서 동작의 일관성이 깨지기 쉽습니다.
반면 Magi-1은 자기회귀 + 청크 단위 확산의 하이브리드 방식을 택했습니다.
프롬프트 → 1번째 청크(24프레임) 확산 노이즈 제거 → 2번째 청크(24프레임) → 3번째 청크 → ... → ∞
각 청크 내부에서는 확산 노이즈 제거를 통해 품질을 유지하고, 청크 간에는 자기회귀 방식을 사용하여 이전 청크를 기반으로 다음 청크를 생성합니다. 덕분에 다른 모델들은 구현하기 어려운 '무제한 길이 비디오' 생성이 가능해졌죠.
파이프라인 병렬 처리: 4개 청크 동시 노이즈 제거
더 똑똑한 점은 "1번째 청크가 완전히 끝날 때까지 기다렸다가 2번째를 시작"하지 않는다는 거예요. Magi-1의 파이프라인은 최대 4개의 청크를 동시에 처리할 수 있도록 설계되었습니다. 현재 청크의 노이즈 제거가 일정 수준에 도달하면 다음 청크가 미리 준비를 시작하죠. 이 덕분에 자기회귀 생성 속도가 전체 구간 확산 방식과 비교해도 크게 뒤처지지 않습니다.
Diffusion Transformer + 다양한 혁신
Magi-1은 기본적으로 Diffusion Transformer (DiT) 아키텍처를 기반으로 하며, 학습 효율을 높이는 다양한 기술이 통합되어 있습니다.
| 기술 요소 | 역할 |
|---|---|
| Block-Causal Attention | 청크 단위 인과적 어텐션, 자기회귀 일관성 보장 |
| Parallel Attention Block | 병렬 어텐션 블록, 속도 향상 |
| QK-Norm + GQA | 학습 안정성 + 추론 효율성 |
| Sandwich Normalization in FFN | 대규모 언어 모델 학습 안정성 |
| SwiGLU | 최신 활성화 함수 |
| Softcap Modulation | 어텐션 스코어 폭주 제어 |
이 기술 스택은 Llama 3나 Mistral 같은 최신 대규모 언어 모델이 사용하는 '현대적 Transformer 무기'와 거의 일치합니다. 이것이 바로 Magi-1이 4.5B/24B라는 '개인이 실행 가능한' 파라미터 규모에서도 최고 수준의 비디오 품질을 구현할 수 있는 근본적인 이유입니다.
두 가지 버전: 4.5B / 24B
| 버전 | 파라미터 규모 | 적합한 환경 | 하드웨어 요구사항 |
|---|---|---|---|
| MAGI-1 4.5B | 4.5 B | 개인 개발자, 로컬 실험 | 단일 GPU (24GB+) |
| MAGI-1 24B | 24 B | 프로덕션 배포, 최고 품질 | 멀티 GPU / H100 권장 |
Sand AI는 두 가지 버전을 동시에 오픈소스로 공개했습니다. 4.5B는 '개인 개발자도 즐길 수 있도록' 만든 버전이며, 24B는 성능 경쟁을 위한 플래그십 모델입니다.
Magi AI의 핵심 역량
역량 1: 무제한 길이 비디오 생성
이는 Magi-1만의 독보적인 능력으로, 다른 주요 비디오 모델들은 구현하지 못하는 기능입니다. 공식 문서에는 "Magi-1은 AI 비디오 생성 분야에서 무제한 비디오 확장 기능을 제공하는 유일한 모델"이라고 명시되어 있습니다.
실제 활용 측면에서, Magi-1을 사용하면 5분, 10분, 심지어 1시간짜리 연속 비디오를 생성할 수 있으며, 기존의 '이어 붙이기' 방식보다 움직임과 장면의 일관성이 훨씬 뛰어납니다. 단편 드라마, 긴 광고, 교육용 영상 제작에 엄청난 이점을 제공하죠.
역량 2: 최고 수준의 물리 이해도
Physics-IQ 벤치마크에서 Magi-1은 **56.02%**를 기록하며 동종 모델들을 압도했습니다. Physics-IQ는 모델이 '물리적 세계가 어떻게 변화할지' 예측하는 능력을 측정합니다. 예를 들어 공이 어디로 굴러갈지, 물이 어떻게 흐를지, 옷이 어떻게 휘날릴지 등을 파악하는 것이죠.
물리적 이해도가 높아지면 영상 특유의 'AI 느낌'이 줄어들고, 실제 세계의 움직임과 더 가까워집니다.
역량 3: 프레임 단위 정밀 제어 (Chunk-wise Prompting)
청크(Chunk) 단위로 생성하는 방식 덕분에, Magi-1은 24프레임 단위의 각 블록마다 개별 프롬프트를 입력할 수 있습니다.
chunk 1: "고양이 한 마리가 잔디밭을 달린다"
chunk 2: "고양이가 점프를 시작한다"
chunk 3: "고양이가 나비에 이끌려 멈춰 선다"
chunk 4: "고양이가 나비를 쫓아 하늘로 뛰어오른다"
이 정도 수준의 정밀 제어는 기존의 전체 구간 확산 모델에서는 거의 불가능했습니다. 덕분에 '장편 비디오 스토리보드' 작업이 실무 가능한 수준으로 간소화되었습니다.
역량 4: 강력한 이미지-비디오 변환 (I2V)
Magi-1은 이미지-비디오 변환 작업에서 특히 뛰어난 성능을 보여줍니다. 정지 이미지 한 장과 텍스트 설명을 입력하면, 이미지와 일관성이 높고 움직임이 자연스러운 영상을 생성합니다. 이는 단순 텍스트-비디오 변환(T2V)보다 제어가 용이해 실제 제작 현장에 더욱 적합합니다.
역량 5: 최상급 프롬프트 준수 능력
Sand AI가 논문에서 진행한 지시 사항 준수(instruction following) 테스트 결과, Magi-1은 Wan 2.1이나 HunyuanVideo보다 훨씬 뛰어난 성능을 보였으며, 폐쇄형 모델인 Hailuo i2v-01과도 어깨를 나란히 했습니다. 즉, 사용자가 입력한 프롬프트를 모델이 '자유롭게 해석'하는 것이 아니라, 의도한 대로 정확히 반영한다는 뜻입니다.
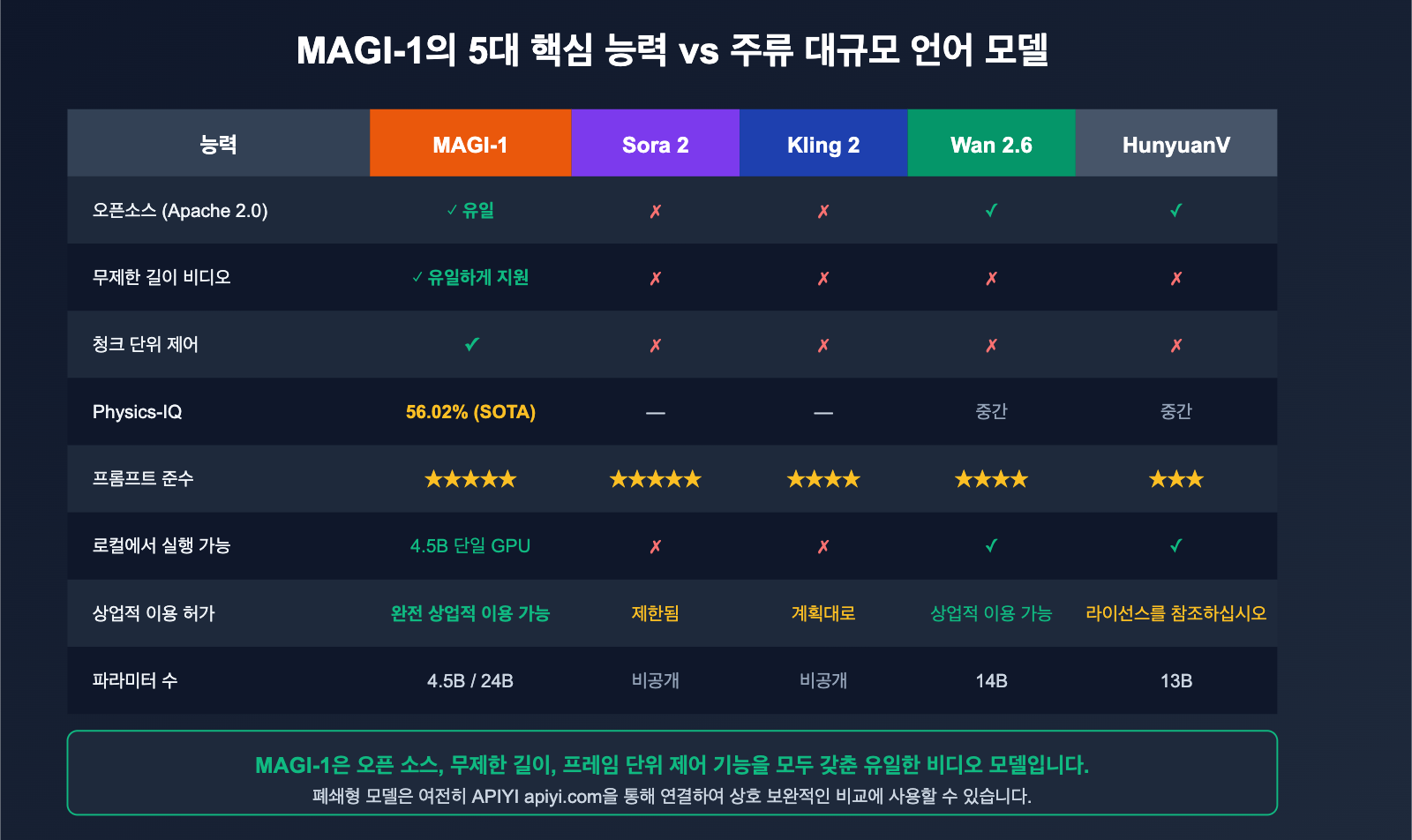
Magi AI와 주요 비디오 모델 비교
많은 신규 사용자들이 가장 궁금해하는 질문은 "Magi가 Sora, Kling, Wan과 비교하면 어떤가요?"입니다. 아래에 명확한 비교표를 정리해 드립니다.
| 비교 항목 | MAGI-1 | Sora 2 | Kling 2 | Wan 2.6 | HunyuanVideo |
|---|---|---|---|---|---|
| 오픈소스 | ✅ Apache 2.0 | ❌ | ❌ | ✅ | ✅ |
| 아키텍처 | 자기회귀 + Diffusion | Diffusion | Diffusion | Diffusion | Diffusion |
| 무제한 길이 | ✅ 유일하게 지원 | ❌ | ❌ | ❌ | ❌ |
| 청크 단위 제어 | ✅ | ❌ | ❌ | ❌ | ❌ |
| 파라미터 수 | 4.5B / 24B | 비공개 | 비공개 | 14B | 13B |
| Physics-IQ | 56.02% | — | — | 보통 | 보통 |
| 프롬프트 준수 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 로컬 실행 | ✅ 4.5B 단일 카드 | ❌ | ❌ | ✅ | ✅ |
| 상업적 이용 | ✅ Apache 2.0 | ⚠ 상업적 제한 | ⚠ 플랜별 상이 | ✅ | ⚠ 라이선스 확인 |
🎯 결론: "최고 화질 + 일회성 짧은 영상"이 필요하다면 Sora 2 / Kling 2가 여전히 우선순위입니다. 하지만 "오픈소스 + 긴 영상 + 프레임 단위 제어"가 필요하다면 Magi AI가 현재 유일한 해답입니다. "로컬 실행과 API 호출을 병행하며 비교"하고 싶다면, MAGI-1 4.5B를 로컬에 배포하고 APIYI(apiyi.com)를 통해 Veo, Sora 등 폐쇄형 모델을 동시에 호출하여 가장 완벽한 비교 테스트를 진행해 보세요.
Magi AI 빠르게 시작하기
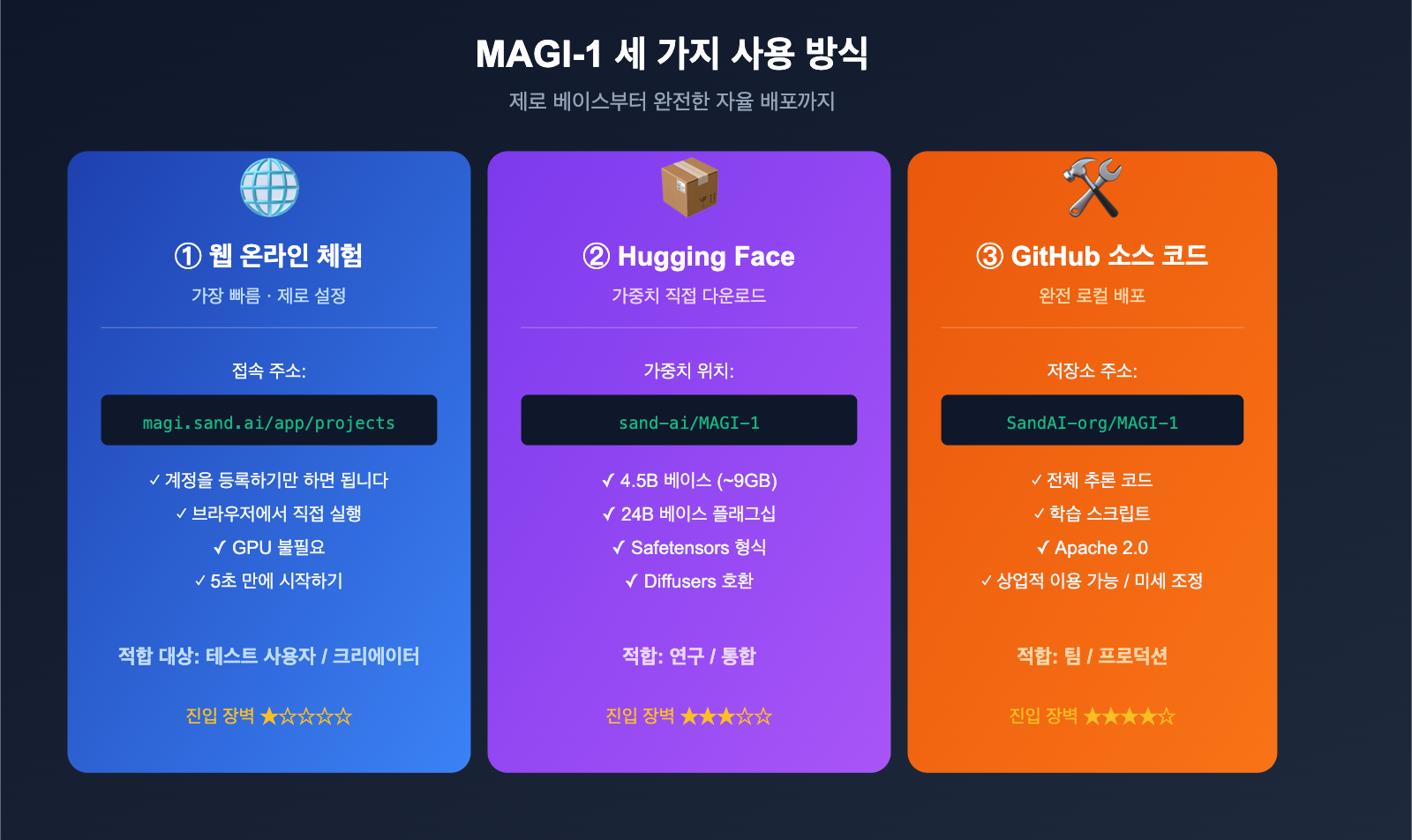
방식 1: Web 온라인 체험 (가장 빠름)
가장 간단한 방법은 공식 웹 앱에 접속하는 것입니다:
- 접속:
magi.sand.ai/app/projects - 계정 등록 후 바로 사용 가능
- 별도의 환경 설정 없이 브라우저에서 즉시 실행
"일단 효과부터 확인해보고 싶다"는 분들께 추천합니다.
방식 2: GitHub 소스 코드 로컬 배포
연구 목적이나 장기적으로 로컬에서 사용하고 싶다면 GitHub에서 소스 코드를 가져오세요:
# 저장소 복제
git clone https://github.com/SandAI-org/MAGI-1.git
cd MAGI-1
# 의존성 설치
pip install -r requirements.txt
# 4.5B 가중치 다운로드 (약 9GB)
huggingface-cli download sand-ai/MAGI-1 --local-dir ./ckpt/
# 최소 예제 실행
python inference.py \
--model_path ./ckpt/4.5B_base \
--prompt "A cat walking on the snow, cinematic lighting" \
--output ./output/cat.mp4 \
--num_chunks 4
💡 제언: 로컬에서 처음 실행할 때는 4.5B 모델 + 단일 카드 24GB VRAM(RTX 3090/4090이면 충분) 환경을 권장합니다. 24B 버전은 품질은 더 뛰어나지만, 여러 대의 H100 GPU가 필요하여 비용이 훨씬 많이 듭니다.
방식 3: Hugging Face에서 가중치 바로 가져오기
huggingface-cli download sand-ai/MAGI-1 \
--include "ckpt/magi/4.5B_base/*" \
--local-dir ./
가중치는 표준 safetensors 형식으로 저장되어 있어 diffusers나 transformers로 바로 로드할 수 있습니다.
추천 워크플로우: Magi 로컬 + 주요 폐쇄형 API 비교
개발자에게 가장 실용적인 워크플로우는 다음과 같습니다:
- MAGI-1 4.5B 로컬 실행: 무제한 길이 영상, 프레임 단위 제어 등 독보적인 기능 활용
- Veo / Sora / Kling API 호출: 최고 수준의 단일 영상 화질을 추구할 때 사용
- 통합 접속: APIYI(apiyi.com)를 통해 해외 최고 수준의 폐쇄형 비디오 모델을 한 번에 접속하여 계정, 네트워크, 결제 문제를 한 번에 해결
- 교차 비교: 동일한 프롬프트로 두 환경에서 모두 실행해 보고, 현재 작업에 가장 적합한 결과물을 선택하세요.
Magi AI, 이런 분들에게 추천합니다
시나리오 1: 긴 영상이 필요한 크리에이터
숏폼 드라마, 장편 광고, 교육용 영상, 다큐멘터리 등 기존의 "5초 단위로 이어 붙이는" 방식은 이제 한계에 다다랐습니다. Magi-1의 무제한 길이 생성 기능은 현재 바로 사용할 수 있는 유일한 솔루션입니다.
시나리오 2: 정교한 스토리보드 제어가 필요한 감독
"청크 단위 프롬프트(chunk-wise prompting)"를 사용하면 마치 스토리보드를 작성하듯 각 장면을 세밀하게 제어할 수 있습니다. 이는 숏폼 크리에이터, 애니메이션 스토리보드 작가, 광고 감독에게 매우 유용합니다.
시나리오 3: 영상 생성 연구자 / 오픈소스 기여자
Apache 2.0 라이선스, 전체 가중치(weights), 논문, GitHub 저장소까지 제공하는 Magi는 현재 "자기회귀 영상 생성"을 연구하는 데 있어 가장 훌륭한 오픈소스 참고 구현체입니다. 이 분야를 연구 중이라면 Magi-1은 반드시 확인하고 실행해 봐야 할 프로젝트입니다.
시나리오 4: 로컬 배포를 원하는 중소 규모 팀
Sora나 Kling 같은 폐쇄형 모델은 API를 통해서만 사용할 수 있어 데이터를 완전히 통제하기 어렵습니다. 반면 Apache 2.0 기반의 Magi-1은 가중치를 다운로드할 수 있어 자체 프라이빗 클라우드에 완벽하게 배포할 수 있습니다. 데이터 보안이 중요한 의료, 금융, 교육 분야에 매우 적합합니다.
Magi AI 자주 묻는 질문 (FAQ)
Q1: Magi AI는 무료인가요? 상업적 이용이 가능한가요?
완전 무료이며, Apache 2.0 라이선스에 따라 상업적 이용이 가능합니다. 이는 Sora, Kling 등 폐쇄형 모델 대비 Magi가 가진 가장 큰 장점 중 하나입니다. 하드웨어 및 GPU 연산 비용만 부담하면 되며, API 호출 비용, 월 구독료, 상업적 제한이 없습니다.
Q2: Magi-1과 Wan 2.6, HunyuanVideo 중 무엇이 더 나은가요?
Sand AI 논문의 비교 데이터에 따르면, Magi-1은 Physics-IQ(물리 이해도), 프롬프트 준수, 모션 품질 등 세 가지 지표에서 Wan 2.1과 HunyuanVideo를 앞섭니다. 하지만 Wan 2.6은 더 최신 버전으로 커뮤니티 생태계와 툴체인이 더 성숙합니다. 현실적인 조언: 숏폼이나 고화질 영상에는 Wan 2.6을, 장편 영상이나 정교한 제어가 필요한 경우에는 Magi-1을 사용하는 것을 추천합니다. 두 모델은 서로 충돌하지 않습니다.
Q3: “무제한 길이 영상”은 정말 무제한인가요?
이론적으로는 그렇습니다. Magi-1의 자기회귀 청크 생성 메커니즘 자체에는 길이 제한이 없어 계속해서 생성할 수 있습니다. 실제 제한은 주로 비디오 메모리(VRAM)와 시간에서 옵니다. VRAM은 현재 생성 중인 몇 개의 청크 상태만 유지하면 되므로 부족할 일은 없지만, 시간은 길이에 비례하여 증가합니다. (예: 5분짜리 영상은 1분짜리보다 약 5배의 시간이 소요됨)
Q4: 4.5B 버전과 24B 버전의 차이는 어느 정도인가요?
4.5B는 "소비자용 그래픽카드로 돌릴 수 있는 가장 강력한 자기회귀 영상 모델"로, 품질 면에서 초기 폐쇄형 모델들을 이미 넘어섰지만, Sora 2나 Kling 2 같은 최상위 폐쇄형 플래그십 모델과는 여전히 격차가 있습니다. 24B는 진정한 "성능 지향 버전"으로, 품질 면에서 일류 폐쇄형 모델에 근접합니다. 개인 창작이나 연구용이라면 4.5B로 충분하며, 상업적 수준의 제작이 필요하다면 24B와 다중 H100 구성을 권장합니다.
Q5: 지금 사용하는 Sora / Kling을 Magi로 대체해야 할까요?
대체하기보다는 상호 보완적으로 사용하는 것을 추천합니다. Sora와 Kling은 단일 장면의 화질과 영상미에서 여전히 강점이 있고, Magi는 길이, 제어 가능성, 오픈소스 자율성에서 독보적인 강점이 있습니다. 가장 좋은 전략은 APIYI(apiyi.com)를 통해 해외 폐쇄형 모델을 연동하여 고품질 숏폼을 만들고, Magi를 로컬에 배포하여 장편 영상이나 정교한 제어가 필요한 작업을 수행하는 식으로 상황에 맞춰 최적의 도구를 선택하는 것입니다.
Q6: 개발자는 Magi-1 가중치를 어떻게 다운로드하나요?
Hugging Face(huggingface.co/sand-ai/MAGI-1)에서 직접 다운로드할 수 있습니다. 네트워크 문제가 발생할 경우 hf-mirror나 modelscope 미러를 활용하세요. Sand AI는 중국의 AI 스타트업으로 개발자 친화적이며, 커뮤니티에 다양한 중국어 튜토리얼과 토론이 활발히 이루어지고 있습니다.
요약
Magi AI는 2025-2026년 오픈 소스 비디오 생성 분야에서 가장 혁신적인 프로젝트 중 하나입니다. 이 프로젝트는 다음 세 가지 의미를 갖습니다.
- 자기회귀 비디오 생성 경로의 검증: Magi-1은 세계 최초로 일류 수준에 도달한 자기회귀 비디오 모델로, "청크 단위(chunk-by-chunk) + 확산(Diffusion)" 방식이 "전체 세그먼트 확산" 외에 또 다른 실행 가능한 경로임을 증명했습니다.
- 무한 길이 비디오의 현실화: Sora, Kling, Veo조차 구현하지 못한 기능을 Magi가 최초로 오픈 소스로 제공합니다.
- 오픈 소스 비디오 생태계의 도약: Apache 2.0 라이선스, 전체 가중치 공개, 4.5B 소비자용 버전 제공을 통해 "개인 개발자도 최상급 비디오 모델을 다룰 수 있는" 시대를 열었습니다.
🚀 활용 제안: 지금 바로 Magi AI의 성능을 경험하고 싶다면 다음 단계를 따라보세요. 첫째,
magi.sand.ai/app/projects에 접속해 계정을 생성하고 온라인으로 체험해 보세요. 둘째, 결과물이 만족스럽다면 GitHub README를 참고하여 4.5B 버전을 로컬에 배포해 보세요. 셋째, Magi(로컬)와 Veo / Sora / Kling(APIYI apiyi.com을 통해 연동)의 결과물을 비교 분석하여 나만의 "모델 툴박스"를 구축해 보세요. 이렇게 하면 긴 영상 제작, 정밀한 컷 구성, 혹은 최고 품질의 단일 영상 생성 등 상황에 맞는 최적의 도구를 선택할 수 있습니다.
작성자: APIYI Team — 개발자에게 주요 대규모 언어 모델의 안정적인 연동 서비스를 제공합니다. 자세한 내용은 apiyi.com을 방문하세요.
참고 자료
-
MAGI-1 GitHub 메인 저장소
- 링크:
github.com/SandAI-org/MAGI-1 - 설명: 소스 코드, 가중치 다운로드 스크립트, 추론 예제
- 링크:
-
MAGI-1 Hugging Face 모델 카드
- 링크:
huggingface.co/sand-ai/MAGI-1 - 설명: 4.5B / 24B 두 가지 버전의 가중치 및 설명
- 링크:
-
MAGI-1 공식 논문 (PDF)
- 링크:
static.magi.world/static/files/MAGI_1.pdf - 설명: 전체 기술 세부 사항 및 벤치마크 결과
- 링크:
-
Sand AI 공식 Magi 소개 페이지
- 링크:
sand.ai/magi - 설명: 프로젝트 홈페이지 및 제품 소개
- 링크:
-
MAGI-1 온라인 Web App
- 링크:
magi.sand.ai/app/projects - 설명: 브라우저에서 직접 체험 가능
- 링크:
-
ComfyUI Wiki – MAGI-1 보도
- 링크:
comfyui-wiki.com/en/news/2025-04-23-magi-1-autoregressive-video-generation-model-released - 설명: 제3자 심층 보도 및 비교 분석
- 링크: