إذا كنت قد لاحظت مؤخراً النقاشات الدائرة حول "Magi AI" أو "MAGI-1"، ولكنك لا تدرك الفرق بينه وبين Sora أو Kling أو Veo، فهذا المقال هو دليلك التمهيدي. يُعد Magi AI نموذجاً مفتوح المصدر لتوليد الفيديو من تطوير Sand AI، وهو أول "نموذج توليد فيديو ذاتي الانحدار" (Autoregressive) في العالم يصل إلى مستوى النماذج الرائدة، كما يدعم توليد فيديوهات ذات طول غير محدود.
القيمة الجوهرية: بعد قراءة هذا المقال، ستفهم ماهية Magi AI، ولماذا يسلك مساراً مختلفاً عن Sora/Kling، وما هي استخداماته، وكيف يمكنك تشغيله في 5 دقائق.

ما هو Magi AI: النقاط الجوهرية
تعريف موجز: Magi AI = نموذج توليد فيديو مفتوح المصدر من Sand AI، يعتمد على بنية هجينة تجمع بين "النموذج ذاتي الانحدار + الانتشار" (Autoregressive + Diffusion).
تم تطويره بواسطة فريق Sand.ai (الرئيس التنفيذي هو Yue Cao، وهو أحد المشاركين في تأليف ورقة Swin Transformer الكلاسيكية)، وتم إطلاق MAGI-1 لأول مرة في 21 أبريل 2025، ثم تم تحديثه إلى Magi-1.1 في عام 2026. الكود المصدري، والأوزان، وأدوات الاستدلال متاحة بالكامل على GitHub و Hugging Face بموجب ترخيص Apache 2.0.
| النقطة | الوصف | القيمة |
|---|---|---|
| ترخيص مفتوح | Apache 2.0 | تجاري بالكامل |
| حجم النموذج | نسختان 4.5B / 24B | تغطية شاملة من الأفراد إلى الشركات |
| البنية الأساسية | ذاتي الانحدار + Diffusion Transformer | أول نموذج فيديو ذاتي الانحدار رائد عالمياً |
| الميزة القاتلة | توليد فيديو بطول غير محدود | ميزة لا تتوفر في Sora/Kling |
| وحدة البناء | توليد 24 إطاراً لكل قطعة (chunk) | دعم التوليد المتدفق (Streaming) |
| الفهم الفيزيائي | Physics-IQ بنسبة 56.02% | تفوق كبير على النماذج المماثلة |
| التحكم | توجيه لكل قطعة (chunk-wise prompting) | تحكم دقيق على مستوى الإطارات |
| GitHub | SandAI-org/MAGI-1 | كود كامل + أوزان |
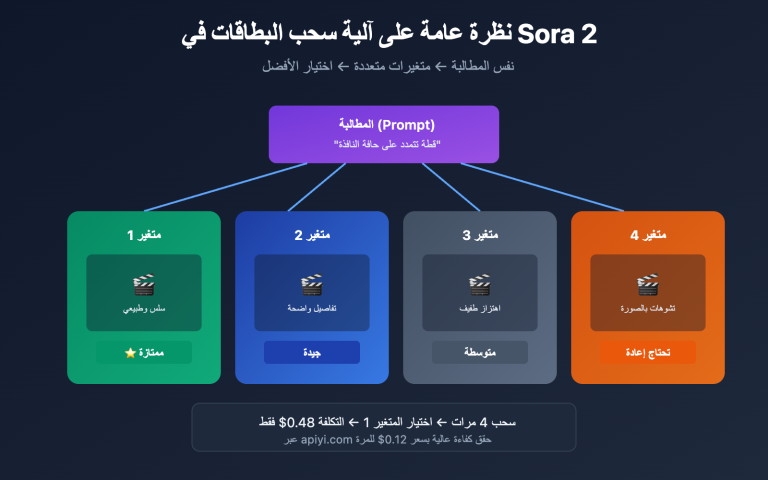
💡 فهم سريع: يسلك Magi AI مساراً مختلفاً تماماً عن Sora و Veo و Kling. فهذه النماذج الرئيسية تقوم بتوليد المقطع كاملاً دفعة واحدة، مما يضع حداً أقصى للطول؛ بينما يقوم Magi-1 بالتوليد الذاتي لكل قطعة (chunk) تلو الأخرى، مما يعني نظرياً إمكانية الاستمرار في التوليد إلى ما لا نهاية. هذا ابتكار حقيقي ومميز في مجال فيديو الذكاء الاصطناعي. إذا كنت ترغب في اختبار ومقارنة نماذج توليد الفيديو الرائدة حالياً، يمكنك استخدام خدمة وكيل API عبر APIYI (apiyi.com) للوصول إلى Veo و Kling و Wan وغيرها، ودمجها مع Magi مفتوح المصدر محلياً، مما يجعله الخيار الأكثر فعالية من حيث التكلفة للمقارنة.
لفهم ما يميز Magi AI، يجب أولاً استيعاب آلية "توليد الكتل ذاتية الانحدار" (Auto-regressive chunk generation) الخاصة بها، وهي الميزة التي تجعلها مختلفة جذرياً عن جميع نماذج الفيديو السائدة.
التوليد ذاتي الانحدار كتلة بكتلة (chunk-by-chunk)
تعتمد الغالبية العظمى من نماذج الفيديو السائدة (مثل Sora وVeo وKling وWan وغيرها) على مسار الانتشار الكامل للقطعة (Full-segment diffusion):
[موجه فيديو كامل] → [انتشار إزالة الضجيج دفعة واحدة] → [مخرج فيديو كامل]
تكمن مشكلة هذه الطريقة في أن: الحد الأقصى للطول ثابت. حيث يقتصر Sora 1.0 على 60 ثانية كحد أقصى، وKling على 5-10 ثوانٍ، وأي زيادة في الطول تتطلب "ربط المقاطع"، وهو ما يؤدي غالباً إلى فقدان اتساق الحركة.
أما Magi-1 فتتبع مساراً هجيناً يعتمد على الانتشار ذاتي الانحدار + الكتل (Auto-regressive + Chunk-based diffusion):
موجه → الكتلة 1 (24 إطاراً) انتشار إزالة الضجيج → الكتلة 2 (24 إطاراً) → الكتلة 3 → ... → ∞
يتم ضمان الجودة داخل كل كتلة (chunk) باستخدام انتشار إزالة الضجيج، ولكن بين الكتل يتم الاعتماد على الآلية ذاتية الانحدار، حيث تعتمد الكتلة التالية على الكتلة السابقة لمواصلة التوليد. وهذا يفتح الباب أمام قدرة "توليد فيديو بطول غير محدود"، وهي ميزة لا توفرها النماذج الأخرى.
خط أنابيب متوازٍ: إزالة الضجيج لـ 4 كتل في وقت واحد
الأمر الأكثر ذكاءً هو أن Magi-1 لا تجعلك تنتظر "اكتمال الكتلة الأولى تماماً قبل البدء في الثانية". فقد صُممت خطوط الأنابيب (pipeline) الخاصة بها لدعم معالجة ما يصل إلى 4 كتل في وقت واحد، حيث تبدأ الكتلة التالية في "الإحماء" بمجرد وصول الكتلة الحالية إلى مستوى معين من إزالة الضجيج. وهذا يجعل سرعة التوليد ذاتي الانحدار لا تختلف كثيراً عن سرعة الانتشار الكامل.
بنية Diffusion Transformer + ابتكارات متعددة
تعتمد Magi-1 في جوهرها على بنية Diffusion Transformer (DiT)، وقد دمجت العديد من تحسينات كفاءة التدريب:
| النقطة التقنية | الدور |
|---|---|
| Block-Causal Attention | انتباه سببي على مستوى الكتلة، لضمان اتساق التوليد ذاتي الانحدار |
| Parallel Attention Block | كتلة انتباه متوازية، لزيادة السرعة |
| QK-Norm + GQA | استقرار التدريب + كفاءة الاستدلال |
| Sandwich Normalization in FFN | استقرار تدريب نموذج اللغة الكبير |
| SwiGLU | دالة تنشيط حديثة |
| Softcap Modulation | التحكم في انفجار درجات الانتباه |
تتطابق هذه الحزمة التقنية مع "ترسانة Transformer الحديثة" المستخدمة في نماذج اللغة الكبيرة الرائدة مثل Llama 3 وMistral، وهذا هو السبب الجوهري وراء قدرة Magi-1 على تحقيق جودة فيديو تضاهي النماذج الرائدة بمستوى معلمات يتراوح بين 4.5 مليار و24 مليار، وهو مستوى "قابل للتشغيل على الأجهزة الشخصية".
إصداران: 4.5B / 24B
| الإصدار | عدد المعلمات | سيناريو الاستخدام | متطلبات العتاد |
|---|---|---|---|
| MAGI-1 4.5B | 4.5 مليار | المطورون المستقلون، التجارب المحلية | بطاقة واحدة (24GB+) |
| MAGI-1 24B | 24 مليار | النشر الإنتاجي، أعلى جودة | بطاقات متعددة / يوصى بـ H100 |
أطلقت Sand AI الإصدارين كمصدر مفتوح؛ حيث يهدف إصدار 4.5B إلى تمكين "المطورين المستقلين من التجربة"، بينما يمثل إصدار 24B النسخة الرائدة المخصصة للمنافسة في الأداء.
القدرات الأساسية لـ Magi AI

القدرة 1: توليد فيديو بطول غير محدود
هذه هي القدرة الأكثر تميزاً في Magi-1، وهي ميزة لا توفرها نماذج الفيديو الرئيسية الأخرى. تنص الوثائق الرسمية بوضوح على: "Magi-1 هو النموذج الوحيد في مجال توليد الفيديو بالذكاء الاصطناعي الذي يوفر إمكانيات تمديد الفيديو إلى ما لا نهاية."
الأهمية العملية: يمكنك جعل Magi-1 يولد فيديو مستمراً لمدة 5 دقائق، 10 دقائق، أو حتى ساعة كاملة، مع اتساق في الحركة والمشاهد أفضل بكثير من أسلوب "ربط المقاطع". وهذا يمثل ميزة كبيرة للمسلسلات القصيرة، الإعلانات الطويلة، ومقاطع الفيديو التعليمية.
القدرة 2: فهم فيزيائي فائق
في معيار Physics-IQ، حصل Magi-1 على 56.02%، متجاوزاً بذلك جميع النماذج المماثلة الحالية بفارق كبير. يقيس اختبار Physics-IQ قدرة النموذج على التنبؤ بـ "كيف سيستمر العالم الفيزيائي" — إلى أين ستتدحرج الكرة، كيف سيتدفق الماء، وكيف ستتحرك الملابس.
بفضل هذا الفهم الفيزيائي المتقدم، تقل "لمسة الذكاء الاصطناعي" (AI-look) في المشاهد، وتصبح الحركة أقرب إلى الواقع.
القدرة 3: تحكم دقيق على مستوى الإطارات (Chunk-wise Prompting)
بما أن التوليد يتم بنظام "كتلة تلو الأخرى" (chunk-by-chunk)، يدعم Magi-1 إضافة موجه (prompt) منفصل لكل كتلة مكونة من 24 إطاراً:
الكتلة 1: "قطة تجري على العشب"
الكتلة 2: "القطة تبدأ في القفز"
الكتلة 3: "القطة تتوقف بعد أن جذبت انتباهها فراشة"
الكتلة 4: "القطة تطارد الفراشة نحو السماء"
هذا المستوى من التحكم الدقيق يكاد يكون مستحيلاً في نماذج الانتشار التقليدية التي تولد المقطع ككتلة واحدة. إنه يحول مهمة "تخطيط لقطات الفيديو الطويل" إلى مستوى يمكن تنفيذه هندسياً.
القدرة 4: تحويل قوي من صورة إلى فيديو (I2V)
يتفوق Magi-1 بشكل خاص في مهام تحويل صورة إلى فيديو. عند تزويده بصورة ثابتة + وصف نصي، يمكنه توليد فيديو يتوافق بدرجة عالية مع الصورة ويتميز بحركة طبيعية. هذا أكثر قابلية للتحكم من التحويل النصي البحت (T2V)، مما يجعله أكثر ملاءمة لسيناريوهات الإنتاج الفعلي.
القدرة 5: التزام فائق بالموجّه (Prompt)
في الورقة البحثية، اختبر فريق Sand AI بشكل خاص مدى الالتزام بالتعليمات، وأظهرت النتائج أن قدرة Magi-1 على اتباع التعليمات أفضل بكثير من Wan 2.1 و HunyuanVideo، ويمكنه منافسة نموذج Hailuo i2v-01 المغلق. وهذا يعني أن الموجه الذي تكتبه سيؤخذ بجدية تامة، ولن يكتفي النموذج بـ "الارتجال الحر".
مقارنة بين Magi AI ونماذج الفيديو الرائدة
السؤال الأكثر شيوعاً بين المستخدمين الجدد هو: "كيف يقارن Magi بنماذج مثل Sora وKling وWan؟" إليك جدول مقارنة يوضح الفروقات الجوهرية:
| وجه المقارنة | MAGI-1 | Sora 2 | Kling 2 | Wan 2.6 | HunyuanVideo |
|---|---|---|---|---|---|
| مفتوح المصدر | ✅ Apache 2.0 | ❌ | ❌ | ✅ | ✅ |
| البنية | انحدار ذاتي + Diffusion | Diffusion | Diffusion | Diffusion | Diffusion |
| طول غير محدود | ✅ الوحيد الذي يدعمه | ❌ | ❌ | ❌ | ❌ |
| تحكم بمستوى القطع | ✅ | ❌ | ❌ | ❌ | ❌ |
| عدد البارامترات | 4.5B / 24B | غير معلن | غير معلن | 14B | 13B |
| الفيزياء (Physics-IQ) | 56.02% | — | — | متوسط | متوسط |
| اتباع الموجه | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| التشغيل محلياً | ✅ 4.5B بطاقة واحدة | ❌ | ❌ | ✅ | ✅ |
| تجاري | ✅ Apache 2.0 | ⚠ مقيد تجارياً | ⚠ حسب الخطة | ✅ | ⚠ راجع الرخصة |
🎯 الخلاصة: إذا كنت تبحث عن "أعلى جودة + فيديو قصير بلقطة واحدة"، فإن Sora 2 / Kling 2 لا يزالان الخيار الأفضل؛ أما إذا كنت تحتاج إلى "مصدر مفتوح + فيديو طويل + تحكم دقيق بالإطارات"، فإن Magi AI هو الحل الوحيد حالياً؛ وإذا كنت ترغب في "التشغيل محلياً واستخدام API للمقارنة"، ننصحك بنشر MAGI-1 4.5B محلياً واستخدام خدمة وكيل API مثل APIYI (apiyi.com) لاستدعاء نماذج مغلقة المصدر مثل Veo / Sora لإجراء اختبارات مقارنة شاملة.
دليل البدء السريع لـ Magi AI

الطريقة 1: التجربة عبر الويب (الأسرع)
أبسط طريقة هي الدخول مباشرة إلى تطبيق الويب الرسمي:
- الرابط:
magi.sand.ai/app/projects - سجل حساباً وابدأ الاستخدام فوراً.
- لا حاجة لأي إعدادات بيئة، يعمل مباشرة من المتصفح.
مناسب للمستخدمين الذين يرغبون في "رؤية النتائج أولاً".
الطريقة 2: النشر المحلي عبر كود المصدر من GitHub
إذا كنت ترغب في إجراء أبحاث أو استخدامه محلياً على المدى الطويل، يمكنك سحب الكود من GitHub:
# استنساخ المستودع
git clone https://github.com/SandAI-org/MAGI-1.git
cd MAGI-1
# تثبيت الاعتمادات
pip install -r requirements.txt
# تحميل أوزان 4.5B (حوالي 9 جيجابايت)
huggingface-cli download sand-ai/MAGI-1 --local-dir ./ckpt/
# تشغيل مثال تجريبي بسيط
python inference.py \
--model_path ./ckpt/4.5B_base \
--prompt "قطة تمشي على الثلج، إضاءة سينمائية" \
--output ./output/cat.mp4 \
--num_chunks 4
💡 نصيحة: عند التشغيل المحلي لأول مرة، يُنصح باستخدام نموذج 4.5B مع بطاقة رسوميات بذاكرة 24 جيجابايت (مثل RTX 3090/4090). على الرغم من أن نسخة 24B تقدم جودة أفضل، إلا أنها تتطلب عدة بطاقات H100، مما يرفع التكلفة بشكل كبير.
الطريقة 3: تحميل الأوزان مباشرة من Hugging Face
huggingface-cli download sand-ai/MAGI-1 \
--include "ckpt/magi/4.5B_base/*" \
--local-dir ./
يتم تخزين الأوزان بتنسيق safetensors القياسي، ويمكن تحميلها مباشرة باستخدام diffusers أو transformers.
سير العمل الموصى به: Magi محلياً + مقارنة مع API النماذج المغلقة
بالنسبة للمطورين، سير العمل الأكثر عملية هو كالتالي:
- تشغيل MAGI-1 4.5B محلياً: للاستفادة من قدراته الفريدة في الفيديوهات ذات الطول غير المحدود والتحكم الدقيق بالإطارات.
- استدعاء API لنماذج Veo / Sora / Kling: للحصول على أعلى جودة ممكنة للمقاطع الفردية.
- الربط الموحد: استخدم خدمة وكيل API مثل APIYI (apiyi.com) للوصول إلى أفضل نماذج الفيديو العالمية المغلقة في مكان واحد، لتجنب مشاكل الحسابات والشبكة والفوترة.
- المقارنة العرضية: قم بتشغيل نفس الموجه (Prompt) على كلا النظامين، واختر المخرج الأكثر ملاءمة لمهمتك الحالية.
لمن يصلح Magi AI؟
السيناريو 1: صناع المحتوى الذين يحتاجون إلى فيديوهات طويلة
المسلسلات القصيرة، الإعلانات الطويلة، الفيديوهات التعليمية، والأفلام الوثائقية؛ في هذه المجالات، وصلت الحلول التقليدية التي تعتمد على "ربط المقاطع كل 5 ثوانٍ" إلى طريق مسدود. يُعد التوليد غير المحدود للطول في Magi-1 هو الحل الوحيد المتاح حالياً للاستخدام المباشر.
السيناريو 2: المخرجون الذين يحتاجون إلى تحكم دقيق في اللقطات
تتيح لك خاصية "chunk-wise prompting" التحكم في كل جزء من المشهد تماماً كما تكتب جدول اللقطات (Storyboard). هذا مفيد جداً لصناع الفيديوهات القصيرة، ورسامي الأنيميشن، ومخرجي الإعلانات.
السيناريو 3: باحثو توليد الفيديو / المساهمون في المصادر المفتوحة
بفضل ترخيص Apache 2.0، والأوزان الكاملة، والأوراق البحثية، ومستودع GitHub، يُعد Magi حالياً أفضل نموذج مفتوح المصدر للبحث في "توليد الفيديو ذاتي الانحدار" (Autoregressive Video Generation). إذا كنت تجري أبحاثاً في هذا المجال، فإن Magi-1 هو مشروع لا بد من قراءته وتجربته.
السيناريو 4: الفرق الصغيرة والمتوسطة التي ترغب في النشر المحلي
نماذج مثل Sora وKling مغلقة المصدر ولا يمكن استخدامها إلا عبر API، مما يعني عدم القدرة على التحكم الكامل في البيانات. أما Magi-1 فهو مرخص بـ Apache 2.0، ويمكن تحميل أوزانه، وبالتالي يمكن نشره بالكامل في سحابتك الخاصة، وهو أمر مثالي للصناعات الحساسة للبيانات (مثل الطب، والتمويل، والتعليم).
الأسئلة الشائعة حول Magi AI
س1: هل Magi AI مجاني؟ وهل يمكن استخدامه تجارياً؟
نعم، هو مجاني تماماً، وقابل للاستخدام التجاري بموجب ترخيص Apache 2.0. هذه واحدة من أكبر مزايا Magi مقارنة بالنماذج مغلقة المصدر مثل Sora وKling. أنت تتحمل فقط تكاليف الأجهزة / معالجة GPU، ولا توجد رسوم استدعاء API، ولا اشتراكات شهرية، ولا قيود على الاستخدام التجاري.
س2: أيهما أفضل: Magi-1 أم Wan 2.6 أم HunyuanVideo؟
وفقاً لبيانات المقارنة في ورقة Sand AI البحثية، يتفوق Magi-1 على Wan 2.1 وHunyuanVideo في ثلاثة مؤشرات: فهم الفيزياء (Physics-IQ)، اتباع الموجه (Prompt Following)، وجودة الحركة (Motion Quality). لكن Wan 2.6 هو إصدار أحدث، ويتمتع بنظام بيئي وأدوات مجتمعية أكثر نضجاً. نصيحة عملية: استخدم Wan 2.6 للفيديوهات القصيرة والمشاهد عالية الجودة، واستخدم Magi-1 للفيديوهات الطويلة والتحكم الدقيق؛ فكلاهما يكمل الآخر.
س3: هل “الفيديو غير محدود الطول” يعني أنه لا نهائي حقاً؟
نظرياً، نعم. آلية توليد المقاطع (chunk generation) ذاتية الانحدار في Magi-1 لا تحتوي على حد أقصى للطول، ويمكنك الاستمرار في التوليد. القيود الفعلية تأتي من ذاكرة الفيديو (VRAM) والوقت: ذاكرة الفيديو تحتاج فقط إلى حفظ حالة المقاطع الحالية، لذا لن تنفد الذاكرة؛ أما الوقت فهو ينمو خطياً، فالفيديو لمدة 5 دقائق يستغرق حوالي 5 أضعاف وقت الفيديو لمدة دقيقة واحدة.
س4: ما الفرق بين إصدار 4.5B وإصدار 24B؟
إصدار 4.5B هو "أقوى نموذج فيديو ذاتي الانحدار يمكن تشغيله على بطاقات الرسوميات الاستهلاكية"، وتتجاوز جودته معظم النماذج مغلقة المصدر المبكرة، لكنه لا يزال أقل من النماذج الرائدة مثل Sora 2 وKling 2. أما إصدار 24B فهو "إصدار المنافسة الحقيقي"، حيث تقترب جودته من النماذج الرائدة مغلقة المصدر. إذا كنت تعمل على مشاريع شخصية أو بحثية، فإن 4.5B كافٍ تماماً؛ أما للإنتاج التجاري، فننصح باستخدام 24B مع بطاقات H100 متعددة.
س5: هل أحتاج إلى استبدال Sora / Kling بـ Magi؟
لا داعي للاستبدال، بل يُنصح بالاستخدام التكاملي. لا تزال Sora وKling تتفوقان في جودة اللقطة الواحدة ولغة الكاميرا، بينما يتميز Magi في الطول والتحكم والحرية في المصادر المفتوحة. الاستراتيجية المثلى هي: استخدام APIYI (apiyi.com) للوصول إلى النماذج الأجنبية مغلقة المصدر لإنتاج مقاطع قصيرة عالية الجودة، واستخدام Magi للنشر المحلي لإنتاج فيديوهات طويلة وتحكم دقيق، واختيار الأداة الأنسب لكل سيناريو.
س6: كيف يمكن للمطورين تحميل أوزان Magi-1؟
يمكنك تحميلها مباشرة من Hugging Face (huggingface.co/sand-ai/MAGI-1). إذا واجهت مشاكل في الشبكة، يمكنك استخدام مرآة hf-mirror أو مرآة modelscope. Sand AI هي شركة ناشئة صينية في مجال الذكاء الاصطناعي، وهي تدعم المطورين بشكل كبير، وهناك الكثير من الدروس والمناقشات باللغة الصينية في مجتمعها.
ملخص
يُعد Magi AI أحد أكثر المشاريع ابتكاراً في مجال توليد الفيديو مفتوح المصدر للفترة 2025-2026. وهو يمثل ثلاث ركائز أساسية:
- التحقق من جدوى مسار توليد الفيديو ذاتي الانحدار (Autoregressive): يُعد Magi-1 أول نموذج فيديو ذاتي الانحدار على مستوى العالم يصل إلى مستوى النماذج الرائدة، مما يثبت أن تقنية "الكتلة تلو الأخرى + الانتشار" (chunk-by-chunk + Diffusion) هي مسار عملي بديل لتقنية "الانتشار الكامل للمقطع".
- تحويل الفيديو غير محدود الطول من الخيال العلمي إلى واقع: وهي قدرة تعجز عنها نماذج مثل Sora وKling وVeo، ويقدمها Magi لأول مرة كحل مفتوح المصدر.
- الارتقاء بنظام الفيديو مفتوح المصدر: بفضل ترخيص Apache 2.0، وتوفر الأوزان الكاملة، وإصدار 4.5B المخصص للأجهزة الاستهلاكية، أصبح بإمكان "المطورين الأفراد استخدام نماذج فيديو من الطراز الأول" واقعاً ملموساً.
🚀 نصيحة عملية: إذا كنت ترغب في تجربة قدرات Magi AI اليوم، فإن أسرع مسار هو: الخطوة الأولى، افتح
magi.sand.ai/app/projectsوسجل حساباً لتجربته عبر الإنترنت؛ الخطوة الثانية، إذا أعجبتك النتائج، قم بنشر إصدار 4.5B محلياً وفقاً لملف README على GitHub؛ الخطوة الثالثة، قم بإجراء مقارنة أفقية بين مخرجات Magi (محلياً) ومخرجات Veo / Sora / Kling (عبر خدمة وكيل API من APIYI apiyi.com)، لبناء "صندوق أدوات النماذج" الخاص بك. بهذه الطريقة، سيكون لديك الأدوات المناسبة سواء كنت تعمل على مقاطع فيديو طويلة، أو لقطات دقيقة، أو تسعى لأعلى جودة في مقطع واحد.
المؤلف: فريق APIYI — متخصصون في توفير وصول مستقر للمطورين إلى نماذج اللغة الكبيرة الرائدة، تفضل بزيارة apiyi.com لمعرفة المزيد.
المراجع
-
المستودع الرئيسي لـ MAGI-1 على GitHub
- الرابط:
github.com/SandAI-org/MAGI-1 - الوصف: الكود المصدري، نصوص تحميل الأوزان، وأمثلة على الاستدلال.
- الرابط:
-
بطاقة نموذج MAGI-1 على Hugging Face
- الرابط:
huggingface.co/sand-ai/MAGI-1 - الوصف: أوزان الإصدارين 4.5B / 24B مع الشروحات.
- الرابط:
-
الورقة البحثية الرسمية لـ MAGI-1 (PDF)
- الرابط:
static.magi.world/static/files/MAGI_1.pdf - الوصف: التفاصيل التقنية الكاملة ونتائج اختبارات الأداء (Benchmarks).
- الرابط:
-
صفحة التعريف الرسمية بـ Magi من Sand AI
- الرابط:
sand.ai/magi - الوصف: الصفحة الرئيسية للمشروع والتعريف بالمنتج.
- الرابط:
-
تطبيق الويب لـ MAGI-1
- الرابط:
magi.sand.ai/app/projects - الوصف: تجربة مباشرة عبر المتصفح.
- الرابط:
-
ComfyUI Wiki – تقرير عن MAGI-1
- الرابط:
comfyui-wiki.com/en/news/2025-04-23-magi-1-autoregressive-video-generation-model-released - الوصف: تقرير تحليلي ومقارنة من طرف ثالث.
- الرابط: