如果你最近看到大家在讨论 "Magi AI" 或 "MAGI-1",但不知道它和 Sora、Kling、Veo 有什么不同,本文就是写给你的入门科普。Magi AI 是 Sand AI 开源的一个非常有意思的视频生成模型 —— 它是全球第一个达到一线水准的"自回归视频生成模型",并且支持无限长度视频生成。
核心价值: 读完本文,你将清楚 Magi AI 是什么、它为什么和 Sora/Kling 走的不是一条路、能用来做什么,以及如何 5 分钟跑起来。

Magi AI 是什么 核心要点
一句话定义: Magi AI = Sand AI 开源的、基于"自回归 + 扩散"混合架构的视频生成模型。
它由 Sand.ai 团队(CEO 是 Yue Cao,也就是经典 Swin Transformer 论文的共同作者)开发,2025 年 4 月 21 日首次开源 MAGI-1,2026 年迭代到 Magi-1.1。代码、权重、推理工具全部在 GitHub 和 Hugging Face 上以 Apache 2.0 协议开放。
| 要点 | 说明 | 价值 |
|---|---|---|
| 开源协议 | Apache 2.0 | 完全可商用 |
| 模型规模 | 4.5B / 24B 双版本 | 个人到企业全覆盖 |
| 核心架构 | 自回归 + Diffusion Transformer | 全球首个一线自回归视频模型 |
| 杀手特性 | 无限长度视频生成 | Sora/Kling 都做不到 |
| 基础块 | 24 帧 chunk-by-chunk 生成 | 支持流式生成 |
| 物理理解 | Physics-IQ 56.02% | 大幅超越同类 |
| 可控性 | chunk-wise prompting | 帧级别精准控制 |
| GitHub | SandAI-org/MAGI-1 | 完整代码 + 权重 |
💡 快速理解: Magi AI 走的是一条与 Sora、Veo、Kling 完全不同的路线。这些主流模型都是整段一次性生成,因此长度有上限;而 Magi-1 是逐 chunk 自回归生成,理论上可以一直生成下去。这在 AI 视频领域是一个真正的差异化创新。如果你想测试当前主流的视频生成模型做对比,可以通过 API易 apiyi.com 一站接入 Veo、Kling、Wan 等,配合开源的 Magi 在本地跑,是性价比最高的对比方案。
Magi AI 的核心技术架构
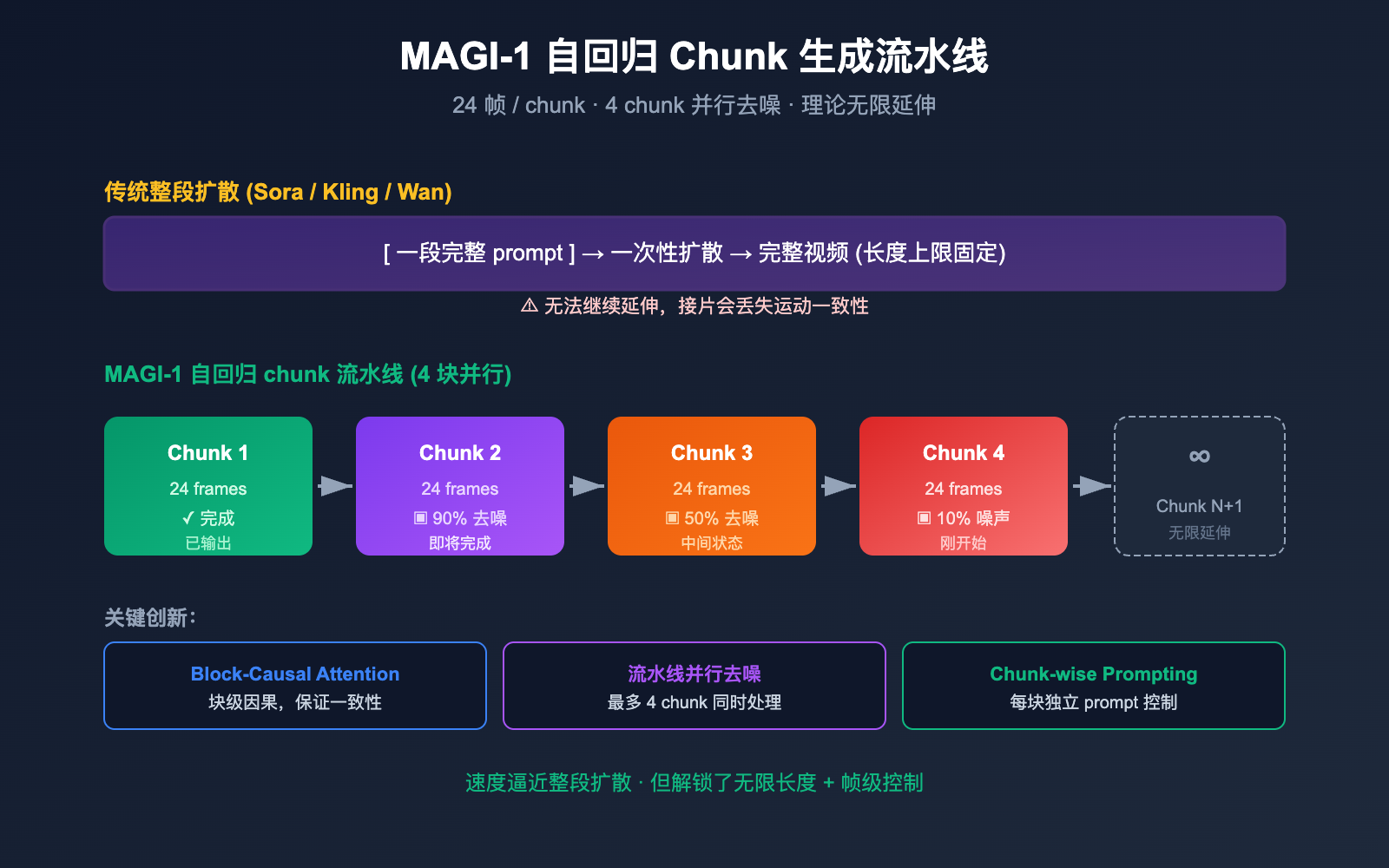
要理解 Magi AI 的差异化,必须先理解它的"自回归 chunk 生成"机制 —— 这是它和所有主流视频模型最大的不同。
chunk-by-chunk 自回归生成
绝大多数主流视频模型(Sora、Veo、Kling、Wan 等)走的都是整段扩散路线:
[一段完整视频 prompt] → [一次性扩散去噪] → [完整视频输出]
这种方式的问题是: 长度上限是固定的。Sora 1.0 一次最多 60 秒,Kling 一次 5-10 秒,再长就需要"接片",而接片往往会丢失运动一致性。
Magi-1 则是自回归 + 块级扩散的混合路线:
prompt → 第 1 块 (24 帧) 扩散去噪 → 第 2 块 (24 帧) → 第 3 块 → ... → ∞
每一个 chunk 内部仍然用扩散去噪保证质量,但 chunk 之间是自回归的 —— 后一块基于前一块继续生成。这就解锁了"无限长度视频"这个其他模型做不到的能力。
流水线并行:4 块同时去噪
更聪明的是,Magi-1 没有让你等"第 1 块全部完成才开始第 2 块"。它的 pipeline 设计支持最多 4 个 chunk 同时处理 —— 当前块去噪到一定程度后,下一块就可以开始预热。这让自回归生成的速度并没有比整段扩散慢多少。
Diffusion Transformer + 多项创新
Magi-1 底层是 Diffusion Transformer (DiT) 架构,并集成了大量训练效率优化:
| 技术点 | 作用 |
|---|---|
| Block-Causal Attention | 块级因果注意力,保证自回归一致性 |
| Parallel Attention Block | 并行注意力块,提速 |
| QK-Norm + GQA | 训练稳定 + 推理高效 |
| Sandwich Normalization in FFN | 大模型训练稳定性 |
| SwiGLU | 现代激活函数 |
| Softcap Modulation | 控制注意力分数爆炸 |
这套技术栈和 Llama 3 / Mistral 这类一线 LLM 用的"现代 Transformer 武器库"几乎一致 —— 这也是 Magi-1 能在 4.5B/24B 这种"个人可跑"的参数量级下达到一线视频质量的根本原因。
双版本: 4.5B / 24B
| 版本 | 参数量 | 适合场景 | 硬件要求 |
|---|---|---|---|
| MAGI-1 4.5B | 4.5 B | 个人开发者、本地实验 | 单卡可跑 (24GB+) |
| MAGI-1 24B | 24 B | 生产部署、最高质量 | 多卡 / H100 推荐 |
Sand AI 同时开源了两个版本,4.5B 的目的是让"独立开发者也能玩",24B 才是冲榜用的旗舰。
Magi AI 的核心能力
能力 1: 无限长度视频生成
这是 Magi-1 最独特的能力,也是其他主流视频模型做不到的。官方文档明确写道:"Magi-1 is the sole model in AI video generation that provides infinite video extension capabilities."
实际意义:你可以让 Magi-1 生成一个 5 分钟、10 分钟甚至 1 小时的连续视频,运动和场景的一致性比"接片"方式好得多。这对短剧、长广告、教学视频是巨大利好。
能力 2: 顶级的物理理解
在 Physics-IQ benchmark 上,Magi-1 拿到 56.02%,大幅超越当前所有同类模型。Physics-IQ 测的是模型对"物理世界继续会怎样"的预测能力 —— 球会往哪滚、水会怎么流、衣服会怎么飘。
物理理解上去了,画面"AI 味"就下降,更接近真实世界的运动。
能力 3: 帧级精准控制 (Chunk-wise Prompting)
因为是 chunk-by-chunk 生成,Magi-1 支持给每一个 24 帧的块分别打 prompt:
chunk 1: "一只猫在草地上奔跑"
chunk 2: "猫开始跳跃"
chunk 3: "猫被一只蝴蝶吸引,停下来"
chunk 4: "猫追蝴蝶飞向天空"
这种级别的精细控制,在传统整段扩散的模型上是几乎不可能做到的。它直接把"长视频分镜"这个工作量降到了可工程化的水平。
能力 4: 强 Image-to-Video (I2V)
Magi-1 在 Image-to-Video 任务上表现尤其出色。给一张静态图 + 一段文本描述,它能生成与图像高度一致、运动自然的视频。这比纯 T2V (Text-to-Video) 更可控,更适合实际生产场景。
能力 5: 顶级 prompt 遵循
Sand AI 在论文中专门测试了 instruction following,结果显示 Magi-1 的指令遵循能力显著好于 Wan 2.1 和 HunyuanVideo,可以与闭源 Hailuo i2v-01 掰手腕。这意味着你写的 prompt 真的会被它当回事,而不是"自由发挥"。
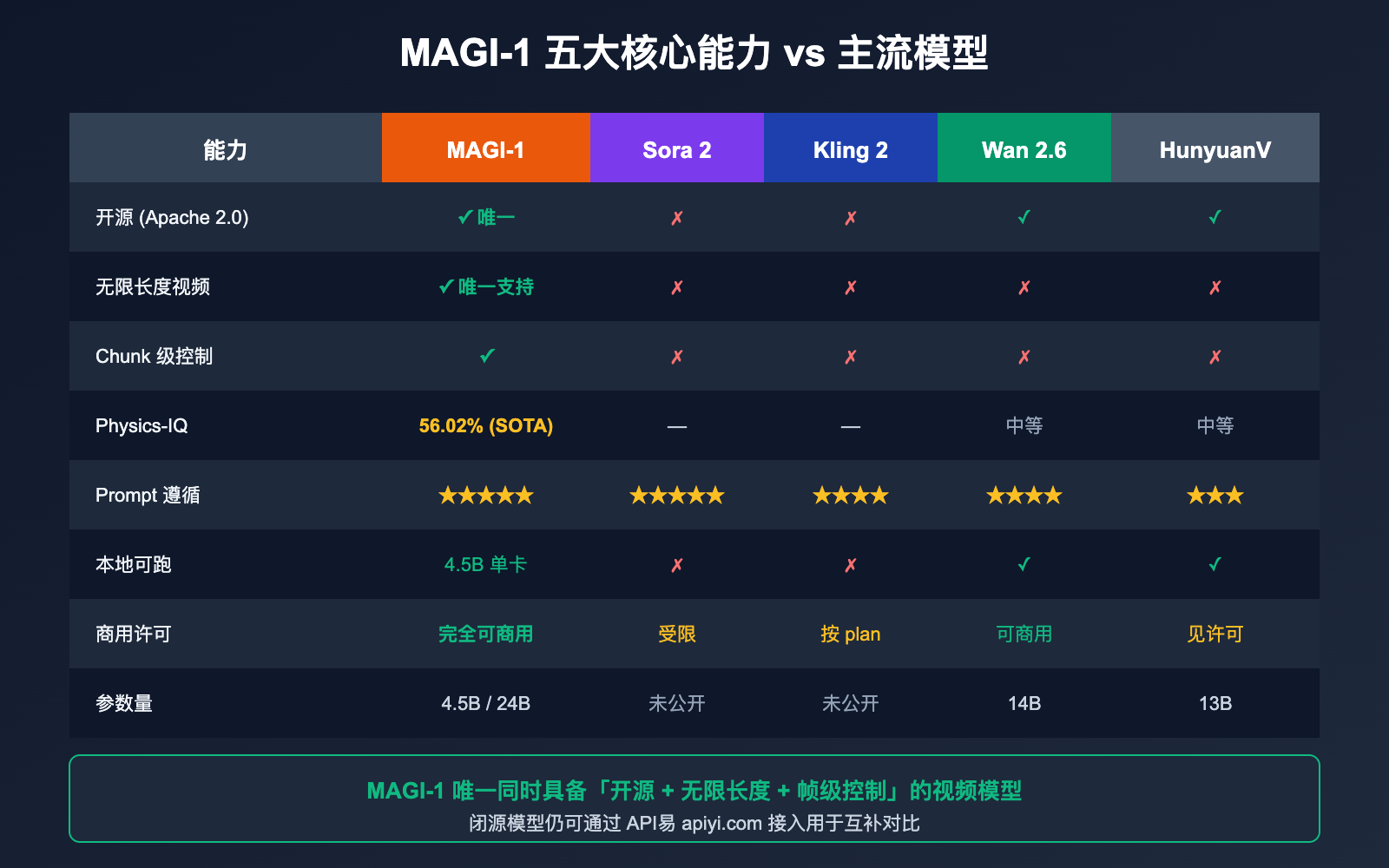
Magi AI 与主流视频模型对比
很多新用户最关心的问题是: "Magi 和 Sora、Kling、Wan 比起来怎么样?"下面给出一张明确的对比表。
| 对比维度 | MAGI-1 | Sora 2 | Kling 2 | Wan 2.6 | HunyuanVideo |
|---|---|---|---|---|---|
| 开源 | ✅ Apache 2.0 | ❌ | ❌ | ✅ | ✅ |
| 架构 | 自回归 + Diffusion | Diffusion | Diffusion | Diffusion | Diffusion |
| 无限长度 | ✅ 唯一支持 | ❌ | ❌ | ❌ | ❌ |
| Chunk 级控制 | ✅ | ❌ | ❌ | ❌ | ❌ |
| 参数量 | 4.5B / 24B | 未公开 | 未公开 | 14B | 13B |
| Physics-IQ | 56.02% | — | — | 中等 | 中等 |
| Prompt 遵循 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 本地可跑 | ✅ 4.5B 单卡 | ❌ | ❌ | ✅ | ✅ |
| 可商用 | ✅ Apache 2.0 | ⚠ 商用受限 | ⚠ 按 plan | ✅ | ⚠ 见许可 |
🎯 结论: 如果你要"最高画质 + 一次性短视频",Sora 2 / Kling 2 仍是首选;如果你要"开源 + 长视频 + 帧级控制",Magi AI 是目前唯一的答案;如果你要"既能本地跑又能接 API 做对比",建议用 MAGI-1 4.5B 本地部署 + 通过 API易 apiyi.com 同时调用 Veo / Sora 等闭源模型,做最完整的对比测试。
Magi AI 快速上手

方式 1: Web 在线试用 (最快)
最简单的方式是直接打开官方 Web App:
- 入口:
magi.sand.ai/app/projects - 注册账号即可使用
- 无需任何环境配置,浏览器就能跑
适合"我先看看效果再说"的用户。
方式 2: GitHub 源码本地部署
如果你想做研究或在本地长期使用,从 GitHub 拉源码:
# 克隆仓库
git clone https://github.com/SandAI-org/MAGI-1.git
cd MAGI-1
# 安装依赖
pip install -r requirements.txt
# 下载 4.5B 权重 (约 9GB)
huggingface-cli download sand-ai/MAGI-1 --local-dir ./ckpt/
# 跑一个最小示例
python inference.py \
--model_path ./ckpt/4.5B_base \
--prompt "A cat walking on the snow, cinematic lighting" \
--output ./output/cat.mp4 \
--num_chunks 4
💡 建议: 第一次本地跑建议先用 4.5B 模型 + 单卡 24GB 显存 (RTX 3090/4090 即可)。24B 版本虽然质量更好,但需要多卡 H100 配合,成本要高一个量级。
方式 3: Hugging Face 直接拉权重
huggingface-cli download sand-ai/MAGI-1 \
--include "ckpt/magi/4.5B_base/*" \
--local-dir ./
权重以标准 safetensors 格式存储,可以直接用 diffusers / transformers 加载。
推荐工作流: Magi 本地 + 主流闭源 API 对比
对开发者来说,最务实的工作流是这样:
- 本地跑 MAGI-1 4.5B: 用于无限长度视频、帧级控制等独特能力
- API 调用 Veo / Sora / Kling: 用于追求最高单段画质
- 统一接入: 通过 API易 apiyi.com 一站接入海外顶级闭源视频模型,避免账号、网络、计费三重问题
- 横向对比: 在同一个 prompt 上跑两套,挑最适合当前任务的输出
Magi AI 适合什么人
场景 1: 需要长视频的创作者
短剧、长广告、教学视频、纪录片 —— 这些场景下,"5 秒一接片"的传统方案已经走到瓶颈。Magi-1 的无限长度生成是当前唯一开箱即用的方案。
场景 2: 需要精细分镜控制的导演
"chunk-wise prompting" 让你可以像写分镜表一样控制每一段画面。这对短视频创作者、动画分镜师、广告导演非常有用。
场景 3: 视频生成研究者 / 开源贡献者
Apache 2.0 协议 + 完整权重 + 论文 + GitHub 仓库,Magi 是目前研究"自回归视频生成"最好的开源参考实现。如果你在做这个方向的研究,Magi-1 几乎是必读必跑的项目。
场景 4: 想本地部署的中小团队
Sora、Kling 这类闭源模型只能通过 API 用,数据不能完全自主控制。Magi-1 是 Apache 2.0,权重可下载,完全可以部署在自己的私有云里,对数据敏感的行业(医疗、金融、教育)非常友好。
Magi AI 常见问题
Q1: Magi AI 是免费的吗?可以商用吗?
完全免费,并且Apache 2.0 协议下完全可商用。这是 Magi 相对于 Sora、Kling 等闭源模型最大的优势之一。你只需要承担硬件 / GPU 算力成本,没有 API 调用费用,没有月费,没有商用限制。
Q2: Magi-1 和 Wan 2.6、HunyuanVideo 哪个更好?
按 Sand AI 论文的对比数据,Magi-1 在 Physics-IQ 物理理解、Prompt 遵循、Motion Quality 三项指标上均领先 Wan 2.1 和 HunyuanVideo。但 Wan 2.6 是更新的版本,社区生态和工具链更成熟。真实建议: 短视频和高画质场景用 Wan 2.6,长视频和精细控制场景用 Magi-1,两者并不冲突。
Q3: “无限长度视频” 是真的无限吗?
理论上是。Magi-1 的自回归 chunk 生成机制本身没有长度上限,你可以让它一直生成下去。实际限制主要来自显存和时间: 显存只需要保存当前几个 chunk 的状态,所以不会爆;时间则是线性增长的 —— 5 分钟视频大约需要 5 倍于 1 分钟的时间。
Q4: 4.5B 版本和 24B 版本差距有多大?
4.5B 是"消费级显卡能跑的最强自回归视频模型",质量上已经超过了大多数早期闭源模型,但与 Sora 2、Kling 2 这种最顶级的闭源旗舰仍有差距。24B 才是真正的"冲榜版本",在质量上接近一线闭源模型。如果你只是个人创作或研究,4.5B 完全够用;如果是商业级生产,建议用 24B + 多卡 H100。
Q5: 我需要用 Magi 替代我现在用的 Sora / Kling 吗?
不需要替代,建议互补使用。Sora、Kling 在单段画质和镜头语言上仍有优势,Magi 在长度、控制性和开源自主性上有独家优势。最优策略是: 用 API易 apiyi.com 接入海外闭源模型做高质量短片,用 Magi 本地部署做长视频和精细控制,按场景选最合适的工具。
Q6: 中国开发者如何下载 Magi-1 的权重?
直接在 Hugging Face 上 (huggingface.co/sand-ai/MAGI-1) 下载即可。如果遇到网络问题,可以使用 hf-mirror 镜像或 modelscope 镜像。Sand AI 是一家中国 AI 创业公司,对中国开发者非常友好,社区里有大量中文教程和讨论。
总结
Magi AI 是 2025-2026 年开源视频生成领域最有创新性的项目之一。它代表了三件事:
- 自回归视频生成路线被验证可行: Magi-1 是全球第一个达到一线水准的自回归视频模型,证明了"chunk-by-chunk + Diffusion"是除"整段扩散"之外的另一条可行路径
- 无限长度视频从科幻走入现实: 这是 Sora、Kling、Veo 都做不到的能力,Magi 第一次开源化交付
- 开源视频生态被再次推高: Apache 2.0 + 完整权重 + 4.5B 消费级版本,让"个人开发者也能玩顶级视频模型"成为现实
🚀 行动建议: 如果你今天就想体验 Magi AI 的能力,最快的路径是: 第一步打开
magi.sand.ai/app/projects注册账号在线试玩;第二步如果觉得效果不错,按 GitHub README 在本地部署 4.5B 版本;第三步把 Magi (本地) 和 Veo / Sora / Kling (通过 API易 apiyi.com 接入) 的输出做横向对比,建立属于你自己的"模型工具箱"。这样无论是做长视频、做精细分镜,还是追求最高单段质量,都有合适的武器可用。
作者: APIYI Team — 专注于为开发者提供主流 AI 大模型的稳定接入,访问 apiyi.com 了解更多。
参考资料
-
MAGI-1 GitHub 主仓库
- 链接:
github.com/SandAI-org/MAGI-1 - 说明: 源码、权重下载脚本、推理示例
- 链接:
-
MAGI-1 Hugging Face 模型卡
- 链接:
huggingface.co/sand-ai/MAGI-1 - 说明: 4.5B / 24B 双版本权重与说明
- 链接:
-
MAGI-1 官方论文 (PDF)
- 链接:
static.magi.world/static/files/MAGI_1.pdf - 说明: 完整技术细节与基准测试结果
- 链接:
-
Sand AI 官方 Magi 介绍页
- 链接:
sand.ai/magi - 说明: 项目主页与产品介绍
- 链接:
-
MAGI-1 在线 Web App
- 链接:
magi.sand.ai/app/projects - 说明: 浏览器端直接试用
- 链接:
-
ComfyUI Wiki – MAGI-1 报道
- 链接:
comfyui-wiki.com/en/news/2025-04-23-magi-1-autoregressive-video-generation-model-released - 说明: 第三方深度报道与对比
- 链接: