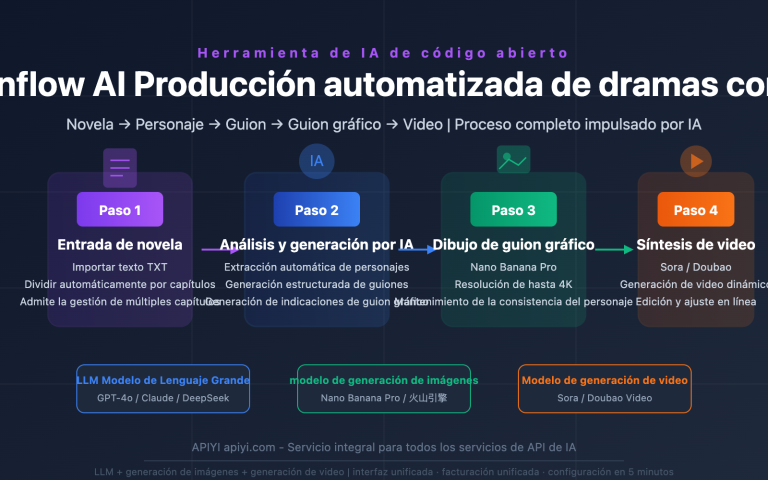
Si últimamente has visto a todo el mundo hablando de "Magi AI" o "MAGI-1" y no sabes en qué se diferencia de Sora, Kling o Veo, este artículo es para ti. Magi AI es un modelo de generación de vídeo de código abierto creado por Sand AI; es el primer "modelo de generación de vídeo autorregresivo" de nivel competitivo a nivel mundial, y además permite la generación de vídeo de longitud infinita.
Valor principal: Al terminar de leer este artículo, tendrás claro qué es Magi AI, por qué sigue un camino distinto al de Sora/Kling, para qué sirve y cómo ponerlo en marcha en 5 minutos.

¿Qué es Magi AI? Puntos clave
Definición en una frase: Magi AI = Modelo de generación de vídeo de código abierto de Sand AI, basado en una arquitectura híbrida de "autorregresión + difusión".
Fue desarrollado por el equipo de Sand.ai (cuyo CEO es Yue Cao, coautor del clásico artículo sobre Swin Transformer). La primera versión, MAGI-1, se publicó el 21 de abril de 2025, y en 2026 se actualizó a Magi-1.1. El código, los pesos y las herramientas de inferencia están disponibles en GitHub y Hugging Face bajo la licencia Apache 2.0.
| Punto clave | Descripción | Valor |
|---|---|---|
| Licencia | Apache 2.0 | Completamente comercializable |
| Escala del modelo | Versiones duales de 4.5B / 24B | Desde uso personal hasta empresarial |
| Arquitectura | Autorregresión + Diffusion Transformer | Primer modelo autorregresivo de vídeo de nivel competitivo |
| Característica estrella | Generación de vídeo de longitud infinita | Algo que ni Sora ni Kling pueden hacer |
| Bloque base | Generación chunk-by-chunk de 24 frames | Soporta generación en streaming |
| Comprensión física | Physics-IQ 56.02% | Supera ampliamente a sus pares |
| Controlabilidad | chunk-wise prompting | Control preciso a nivel de frame |
| GitHub | SandAI-org/MAGI-1 | Código completo + pesos |
💡 Comprensión rápida: Magi AI sigue una ruta completamente distinta a la de Sora, Veo y Kling. Estos modelos convencionales generan toda la secuencia de una sola vez, por lo que tienen un límite de duración; en cambio, Magi-1 realiza una generación autorregresiva por bloques (chunk), lo que teóricamente permite generar contenido indefinidamente. Esta es una innovación diferenciadora real en el campo del vídeo mediante IA. Si quieres comparar los modelos de generación de vídeo actuales, puedes usar el servicio proxy de API APIYI (apiyi.com) para integrar Veo, Kling, Wan, etc., y combinarlo con el Magi de código abierto ejecutado localmente; es la forma más rentable de realizar comparaciones.
Arquitectura técnica central de Magi AI
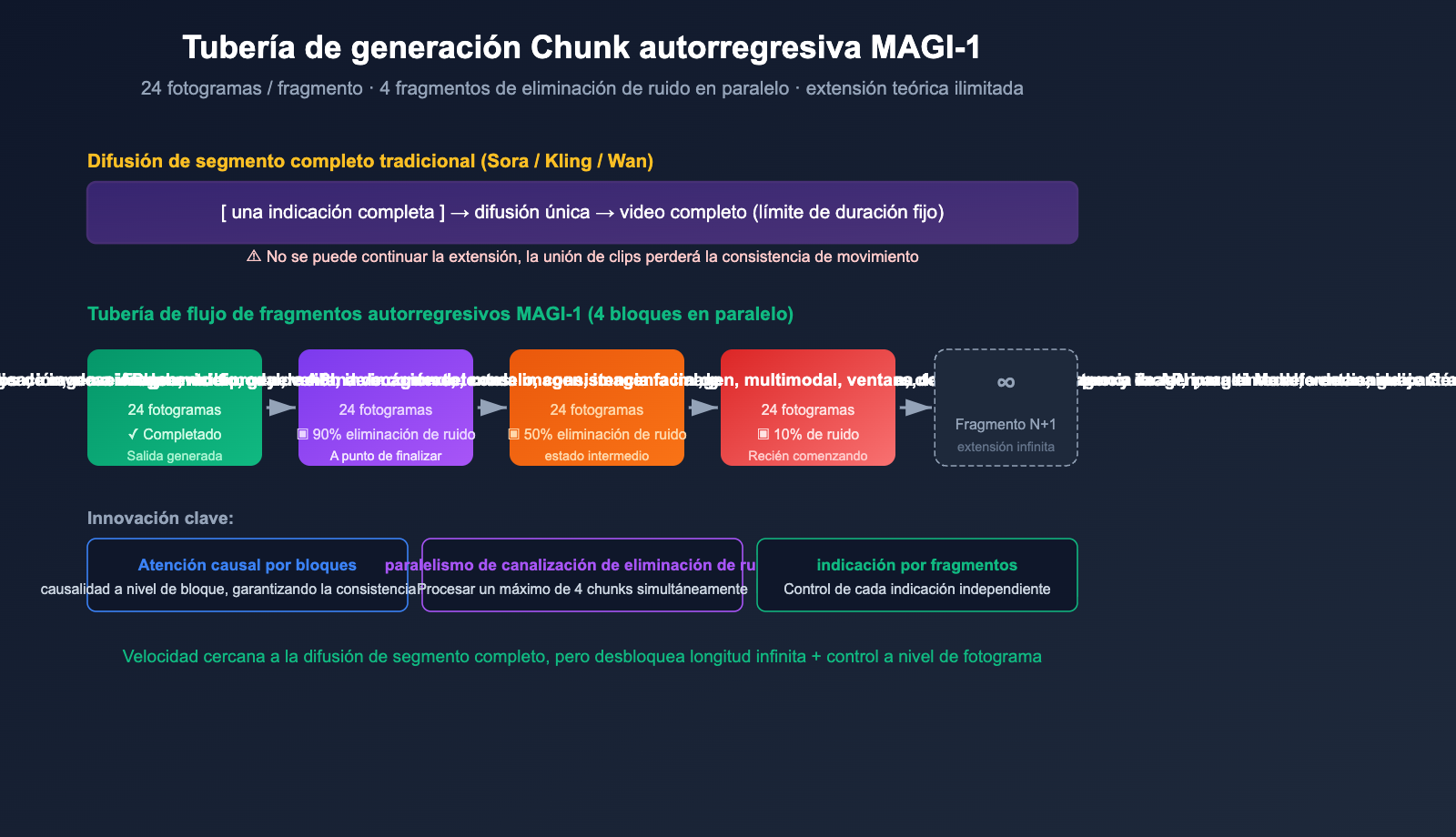
Para entender la diferenciación de Magi AI, primero debemos comprender su mecanismo de "generación de fragmentos autorregresivos", que es lo que lo distingue de la mayoría de los modelos de video actuales.
Generación autorregresiva fragmento a fragmento
La gran mayoría de los modelos de video convencionales (Sora, Veo, Kling, Wan, etc.) utilizan un enfoque de difusión de segmento completo:
[Indicación de video completo] → [Difusión de eliminación de ruido de una sola vez] → [Salida de video completo]
El problema con este enfoque es que: el límite de longitud es fijo. Sora 1.0 tiene un máximo de 60 segundos por vez, Kling entre 5 y 10 segundos, y para duraciones mayores se requiere "empalmar" clips, lo cual suele provocar la pérdida de la consistencia del movimiento.
Magi-1, por otro lado, utiliza una ruta híbrida de autorregresión + difusión a nivel de fragmento (chunk):
indicación → 1er fragmento (24 cuadros) difusión de eliminación de ruido → 2do fragmento (24 cuadros) → 3er fragmento → ... → ∞
Dentro de cada fragmento se sigue utilizando la difusión para garantizar la calidad, pero entre fragmentos el proceso es autorregresivo: el siguiente fragmento se genera basándose en el anterior. Esto desbloquea la capacidad de generar "videos de longitud infinita", algo que otros modelos no pueden hacer.
Paralelismo de tubería: eliminación de ruido en 4 fragmentos simultáneos
Lo más inteligente es que Magi-1 no te obliga a esperar a que "el primer fragmento termine por completo para empezar el segundo". Su diseño de tubería (pipeline) admite el procesamiento simultáneo de hasta 4 fragmentos: una vez que el fragmento actual alcanza cierto nivel de eliminación de ruido, el siguiente puede comenzar a precalentarse. Esto hace que la velocidad de generación autorregresiva no sea mucho más lenta que la difusión de segmento completo.
Diffusion Transformer + múltiples innovaciones
La base de Magi-1 es la arquitectura Diffusion Transformer (DiT), que integra una gran cantidad de optimizaciones en la eficiencia del entrenamiento:
| Punto técnico | Función |
|---|---|
| Block-Causal Attention | Atención causal a nivel de bloque, garantiza la consistencia autorregresiva |
| Parallel Attention Block | Bloque de atención paralelo, aumenta la velocidad |
| QK-Norm + GQA | Entrenamiento estable + inferencia eficiente |
| Sandwich Normalization in FFN | Estabilidad en el entrenamiento de Modelos de Lenguaje Grandes |
| SwiGLU | Función de activación moderna |
| Softcap Modulation | Controla la explosión de las puntuaciones de atención |
Este conjunto de tecnologías es casi idéntico al "arsenal moderno de Transformer" utilizado por los Modelos de Lenguaje Grandes de primer nivel como Llama 3 o Mistral. Esta es la razón fundamental por la que Magi-1 puede alcanzar una calidad de video de primer nivel con una cantidad de parámetros de 4.5B/24B, que son ejecutables a nivel personal.
Versión dual: 4.5B / 24B
| Versión | Cantidad de parámetros | Escenario adecuado | Requisitos de hardware |
|---|---|---|---|
| MAGI-1 4.5B | 4.5 B | Desarrolladores independientes, experimentos locales | Ejecutable en una sola tarjeta (24GB+) |
| MAGI-1 24B | 24 B | Despliegue en producción, máxima calidad | Recomendado multi-tarjeta / H100 |
Sand AI ha lanzado ambas versiones como código abierto; el objetivo de la versión 4.5B es permitir que los "desarrolladores independientes también puedan experimentar", mientras que la 24B es el modelo insignia diseñado para liderar los rankings.
Capacidades principales de Magi AI

Capacidad 1: Generación de video de duración infinita
Esta es la capacidad más distintiva de Magi-1 y algo que otros modelos de video convencionales no pueden hacer. La documentación oficial lo afirma claramente: "Magi-1 es el único modelo en la generación de video por IA que proporciona capacidades de extensión de video infinita".
Significado práctico: puedes hacer que Magi-1 genere un video continuo de 5 minutos, 10 minutos o incluso una hora, con una consistencia de movimiento y escena mucho mejor que el método de "empalmar clips". Esto es una gran ventaja para cortometrajes, anuncios largos y videos educativos.
Capacidad 2: Comprensión física de primer nivel
En el benchmark Physics-IQ, Magi-1 obtuvo un 56.02%, superando significativamente a todos los modelos similares actuales. Physics-IQ mide la capacidad del modelo para predecir "qué sucederá a continuación en el mundo físico": hacia dónde rodará una pelota, cómo fluirá el agua o cómo se moverá la ropa.
Al mejorar la comprensión física, el "toque artificial" de la imagen disminuye, acercándose más al movimiento del mundo real.
Capacidad 3: Control preciso a nivel de fotogramas (Chunk-wise Prompting)
Debido a que la generación es bloque a bloque (chunk-by-chunk), Magi-1 permite asignar una indicación (prompt) específica a cada bloque de 24 fotogramas:
bloque 1: "un gato corriendo por el césped"
bloque 2: "el gato comienza a saltar"
bloque 3: "el gato se detiene, atraído por una mariposa"
bloque 4: "el gato persigue a la mariposa hacia el cielo"
Este nivel de control detallado es casi imposible de lograr en los modelos de difusión tradicionales de segmento completo. Reduce directamente la carga de trabajo del "guion gráfico de video largo" a un nivel manejable y profesional.
Capacidad 4: Potente imagen a imagen (I2V)
Magi-1 destaca especialmente en tareas de imagen a imagen. Con una imagen estática y una descripción de texto, puede generar un video altamente consistente con la imagen y con un movimiento natural. Esto es más controlable que el texto a imagen (T2V) puro, lo que lo hace más adecuado para escenarios de producción real.
Capacidad 5: Seguimiento de indicaciones (prompt) de primer nivel
En su artículo, Sand AI probó específicamente el seguimiento de instrucciones, y los resultados muestran que la capacidad de seguimiento de indicaciones de Magi-1 es significativamente mejor que la de Wan 2.1 y HunyuanVideo, compitiendo de tú a tú con el modelo cerrado Hailuo i2v-01. Esto significa que la indicación que escribas será realmente tomada en cuenta, en lugar de que el modelo simplemente "improvise".
Comparativa de Magi AI frente a los principales modelos de vídeo
Una de las preguntas que más nos hacen los nuevos usuarios es: "¿Cómo se compara Magi con Sora, Kling o Wan?". A continuación, presentamos una tabla comparativa clara.
| Dimensión de comparación | MAGI-1 | Sora 2 | Kling 2 | Wan 2.6 | HunyuanVideo |
|---|---|---|---|---|---|
| Código abierto | ✅ Apache 2.0 | ❌ | ❌ | ✅ | ✅ |
| Arquitectura | Autorregresivo + Difusión | Difusión | Difusión | Difusión | Difusión |
| Longitud infinita | ✅ Único soporte | ❌ | ❌ | ❌ | ❌ |
| Control a nivel de fragmento | ✅ | ❌ | ❌ | ❌ | ❌ |
| Parámetros | 4.5B / 24B | No público | No público | 14B | 13B |
| Physics-IQ | 56.02% | — | — | Medio | Medio |
| Seguimiento de indicación | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| Ejecución local | ✅ 4.5B una GPU | ❌ | ❌ | ✅ | ✅ |
| Uso comercial | ✅ Apache 2.0 | ⚠ Limitado | ⚠ Según plan | ✅ | ⚠ Ver licencia |
🎯 Conclusión: Si buscas "la máxima calidad de imagen + vídeos cortos de una sola toma", Sora 2 / Kling 2 siguen siendo la mejor opción. Si necesitas "código abierto + vídeos largos + control a nivel de frame", Magi AI es actualmente la única respuesta. Si quieres "ejecutar localmente y usar una API para comparar", te recomendamos desplegar localmente MAGI-1 4.5B y utilizar el servicio proxy de API APIYI (apiyi.com) para invocar modelos de código cerrado como Veo o Sora, logrando así las pruebas comparativas más completas.
Primeros pasos con Magi AI

Método 1: Prueba online vía Web (el más rápido)
La forma más sencilla es acceder directamente a la Web App oficial:
- Acceso:
magi.sand.ai/app/projects - Regístrate y empieza a usarlo.
- Sin configuraciones de entorno, funciona directamente en el navegador.
Ideal para usuarios que quieren "ver los resultados antes de decidir".
Método 2: Despliegue local desde el código fuente en GitHub
Si quieres investigar o usarlo a largo plazo en local, clona el código desde GitHub:
# Clonar el repositorio
git clone https://github.com/SandAI-org/MAGI-1.git
cd MAGI-1
# Instalar dependencias
pip install -r requirements.txt
# Descargar pesos 4.5B (aprox. 9GB)
huggingface-cli download sand-ai/MAGI-1 --local-dir ./ckpt/
# Ejecutar un ejemplo mínimo
python inference.py \
--model_path ./ckpt/4.5B_base \
--prompt "A cat walking on the snow, cinematic lighting" \
--output ./output/cat.mp4 \
--num_chunks 4
💡 Sugerencia: Para la primera ejecución local, recomendamos usar el modelo 4.5B con una GPU de 24GB de VRAM (una RTX 3090/4090 es suficiente). Aunque la versión 24B ofrece mayor calidad, requiere varias tarjetas H100, lo que aumenta el coste significativamente.
Método 3: Descarga directa de pesos desde Hugging Face
huggingface-cli download sand-ai/MAGI-1 \
--include "ckpt/magi/4.5B_base/*" \
--local-dir ./
Los pesos se almacenan en formato estándar safetensors, por lo que se pueden cargar directamente usando diffusers o transformers.
Flujo de trabajo recomendado: Magi local + API de modelos cerrados
Para los desarrolladores, el flujo de trabajo más práctico es:
- Ejecutar MAGI-1 4.5B localmente: Para aprovechar sus capacidades únicas en vídeos de longitud infinita y control a nivel de frame.
- Llamadas API a Veo / Sora / Kling: Para buscar la máxima calidad de imagen en clips individuales.
- Integración unificada: Utiliza el servicio proxy de API APIYI (apiyi.com) para integrar los mejores modelos de vídeo cerrados del mercado en un solo lugar, evitando problemas de cuentas, red o facturación.
- Comparativa horizontal: Ejecuta ambos modelos con la misma indicación y elige la salida que mejor se adapte a tu tarea actual.
¿Para quién es Magi AI?
Escenario 1: Creadores que necesitan videos largos
Series cortas, anuncios largos, videos educativos, documentales… en estos escenarios, el enfoque tradicional de "unir clips de 5 segundos" ha llegado a su límite. La generación de longitud infinita de Magi-1 es actualmente la única solución lista para usar.
Escenario 2: Directores que necesitan un control preciso del guion gráfico
El "chunk-wise prompting" (indicación por fragmentos) te permite controlar cada segmento de la imagen como si estuvieras escribiendo un guion gráfico. Esto es extremadamente útil para creadores de videos cortos, artistas de guiones gráficos de animación y directores de publicidad.
Escenario 3: Investigadores de generación de video / Colaboradores de código abierto
Con licencia Apache 2.0, pesos completos, artículos de investigación y repositorio en GitHub, Magi es actualmente la mejor implementación de referencia de código abierto para estudiar la "generación de video autorregresiva". Si estás investigando en esta área, Magi-1 es casi un proyecto obligatorio de leer y ejecutar.
Escenario 4: Equipos pequeños que desean despliegue local
Modelos de código cerrado como Sora o Kling solo pueden usarse a través de API, por lo que los datos no pueden controlarse de forma totalmente autónoma. Magi-1 tiene licencia Apache 2.0, los pesos se pueden descargar y se puede desplegar completamente en tu propia nube privada, lo cual es muy amigable para industrias sensibles a los datos (medicina, finanzas, educación).
Preguntas frecuentes sobre Magi AI
Q1: ¿Es Magi AI gratuito? ¿Se puede usar comercialmente?
Es totalmente gratuito y completamente comercializable bajo la licencia Apache 2.0. Esta es una de las mayores ventajas de Magi frente a modelos de código cerrado como Sora o Kling. Solo tienes que asumir los costes de hardware / potencia de cálculo de GPU; no hay tarifas de invocación del modelo, ni cuotas mensuales, ni restricciones comerciales.
Q2: ¿Qué es mejor: Magi-1, Wan 2.6 o HunyuanVideo?
Según los datos comparativos del artículo de Sand AI, Magi-1 supera a Wan 2.1 y HunyuanVideo en tres indicadores: comprensión física Physics-IQ, seguimiento de la indicación y calidad de movimiento. Sin embargo, Wan 2.6 es una versión más reciente, con un ecosistema comunitario y una cadena de herramientas más maduros. Consejo real: usa Wan 2.6 para videos cortos y escenas de alta calidad, y usa Magi-1 para videos largos y escenas de control preciso; ambos no son excluyentes.
Q3: ¿La «generación de video de longitud infinita» es realmente infinita?
En teoría, sí. El mecanismo de generación de fragmentos autorregresivos de Magi-1 no tiene un límite de longitud intrínseco; puedes dejar que siga generando indefinidamente. Las limitaciones reales provienen principalmente de la memoria de video (VRAM) y el tiempo: la VRAM solo necesita guardar el estado de los fragmentos actuales, por lo que no colapsará; el tiempo, en cambio, crece linealmente: un video de 5 minutos toma aproximadamente 5 veces más tiempo que uno de 1 minuto.
Q4: ¿Qué tanta diferencia hay entre la versión 4.5B y la 24B?
La 4.5B es "el modelo de video autorregresivo más potente que puede ejecutar una tarjeta gráfica de consumo", y su calidad ya supera a la mayoría de los primeros modelos de código cerrado, aunque todavía hay una brecha con los modelos insignia de primer nivel como Sora 2 o Kling 2. La 24B es la verdadera "versión para romper récords", acercándose en calidad a los modelos de código cerrado líderes. Si solo haces creaciones personales o investigación, la 4.5B es suficiente; si es para producción a nivel comercial, se recomienda usar la 24B con múltiples tarjetas H100.
Q5: ¿Necesito reemplazar el Sora / Kling que uso actualmente por Magi?
No necesitas reemplazarlo, se recomienda usarlos de forma complementaria. Sora y Kling aún tienen ventajas en la calidad de imagen de un solo segmento y en el lenguaje cinematográfico, mientras que Magi tiene ventajas exclusivas en longitud, control y autonomía de código abierto. La estrategia óptima es: usar APIYI (apiyi.com) para acceder a modelos extranjeros de código cerrado para cortometrajes de alta calidad, y usar Magi con despliegue local para videos largos y control preciso, eligiendo la herramienta más adecuada según el escenario.
Q6: ¿Cómo pueden los desarrolladores descargar los pesos de Magi-1?
Puedes descargarlos directamente en Hugging Face (huggingface.co/sand-ai/MAGI-1). Si encuentras problemas de red, puedes usar el espejo hf-mirror o el espejo de modelscope. Sand AI es una startup china de IA muy amigable con los desarrolladores, y hay una gran cantidad de tutoriales y debates en chino dentro de la comunidad.
Resumen
Magi AI es uno de los proyectos más innovadores en el campo de la generación de vídeo de código abierto para 2025-2026. Representa tres hitos fundamentales:
- Validación de la ruta de generación de vídeo autorregresiva: Magi-1 es el primer Modelo de Lenguaje Grande de vídeo autorregresivo a nivel mundial que alcanza un estándar de primera línea, demostrando que el enfoque "fragmento a fragmento + difusión" es una vía viable más allá de la "difusión de segmento completo".
- El vídeo de duración infinita pasa de la ciencia ficción a la realidad: Esta es una capacidad que ni Sora, ni Kling, ni Veo han logrado, y Magi la entrega por primera vez de forma abierta.
- El ecosistema de vídeo de código abierto alcanza un nuevo nivel: Gracias a la licencia Apache 2.0, los pesos completos y una versión de 4.5B para consumo masivo, hacer que "cualquier desarrollador individual pueda utilizar un modelo de vídeo de primer nivel" es ahora una realidad.
🚀 Sugerencia de acción: Si quieres probar las capacidades de Magi AI hoy mismo, el camino más rápido es: primero, abre
magi.sand.ai/app/projectspara registrarte y probarlo en línea; segundo, si los resultados te convencen, despliega la versión de 4.5B de forma local siguiendo el README de GitHub; tercero, realiza una comparativa entre las salidas de Magi (local) y las de Veo / Sora / Kling (accediendo a través de APIYI apiyi.com) para crear tu propio "kit de herramientas de modelos". De esta forma, tendrás el arma adecuada tanto para vídeos largos y guiones gráficos detallados como para buscar la máxima calidad en segmentos individuales.
Autor: Equipo de APIYI — Enfocados en proporcionar a los desarrolladores un acceso estable a los principales Modelos de Lenguaje Grande de IA. Visita apiyi.com para más información.
Referencias
-
Repositorio principal de MAGI-1 en GitHub
- Enlace:
github.com/SandAI-org/MAGI-1 - Descripción: Código fuente, scripts de descarga de pesos y ejemplos de inferencia.
- Enlace:
-
Tarjeta de modelo de MAGI-1 en Hugging Face
- Enlace:
huggingface.co/sand-ai/MAGI-1 - Descripción: Pesos y documentación para las versiones de 4.5B y 24B.
- Enlace:
-
Documento oficial de MAGI-1 (PDF)
- Enlace:
static.magi.world/static/files/MAGI_1.pdf - Descripción: Detalles técnicos completos y resultados de pruebas de referencia.
- Enlace:
-
Página oficial de presentación de Magi de Sand AI
- Enlace:
sand.ai/magi - Descripción: Página principal del proyecto y presentación del producto.
- Enlace:
-
Aplicación web en línea de MAGI-1
- Enlace:
magi.sand.ai/app/projects - Descripción: Prueba directa desde el navegador.
- Enlace:
-
Wiki de ComfyUI – Reportaje sobre MAGI-1
- Enlace:
comfyui-wiki.com/en/news/2025-04-23-magi-1-autoregressive-video-generation-model-released - Descripción: Reportaje en profundidad y comparativa por parte de terceros.
- Enlace: