Author's Note: Meta has released Llama 4 Scout and Maverick, featuring a native multimodal MoE architecture. Scout boasts a 10 million token context window, while Maverick outperforms GPT-4o in comprehensive benchmarks. This article provides an in-depth look at the technical details and the impact on developers.
Meta has officially launched the Llama 4 model family, with the first native multimodal MoE open-source models, Llama 4 Scout and Maverick, sparking widespread excitement in the AI community. This article offers a quick breakdown of how this milestone event will impact AI developers and the industry at large.
Core Value: Get up to speed in 3 minutes on the key technical breakthroughs, benchmark performance, and real-world application value of Llama 4 Scout and Maverick.

Quick Overview of Llama 4 Scout and Maverick
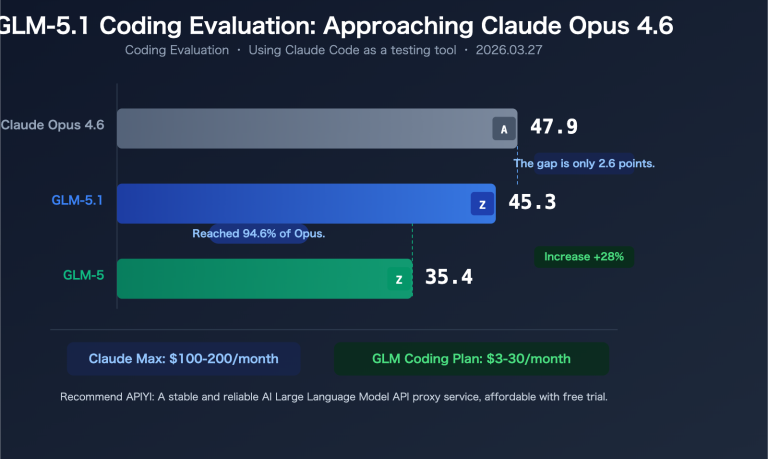
| Feature | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|
| Release Date | April 5, 2025 | April 5, 2025 |
| Architecture | Native Multimodal MoE | Native Multimodal MoE |
| Active Parameters | 17 Billion | 17 Billion |
| Number of Experts | 16 | 128 |
| Total Parameters | 109 Billion | 400 Billion |
| Context Window | 10 Million tokens | 1 Million tokens |
| License | Llama License | Llama License |
Key Positioning of Llama 4 Scout and Maverick
Llama 4 is the fourth generation of Meta's Large Language Model family and the first in the Llama series to adopt native multimodal and Mixture-of-Experts (MoE) architectures. Compared to the previous Llama 3 series, Llama 4 has undergone a fundamental architectural overhaul.
Scout is positioned as an efficient long-context processing model, offering the industry's longest 10 million token context window at an extremely low inference cost. Maverick is positioned as a high-performance general-purpose model, leveraging 128 expert networks to achieve comprehensive capabilities that surpass GPT-4o.
Both models have had their weights released and are available for download via llama.com and Hugging Face.
Llama 4 Scout and Maverick Technical Architecture Analysis
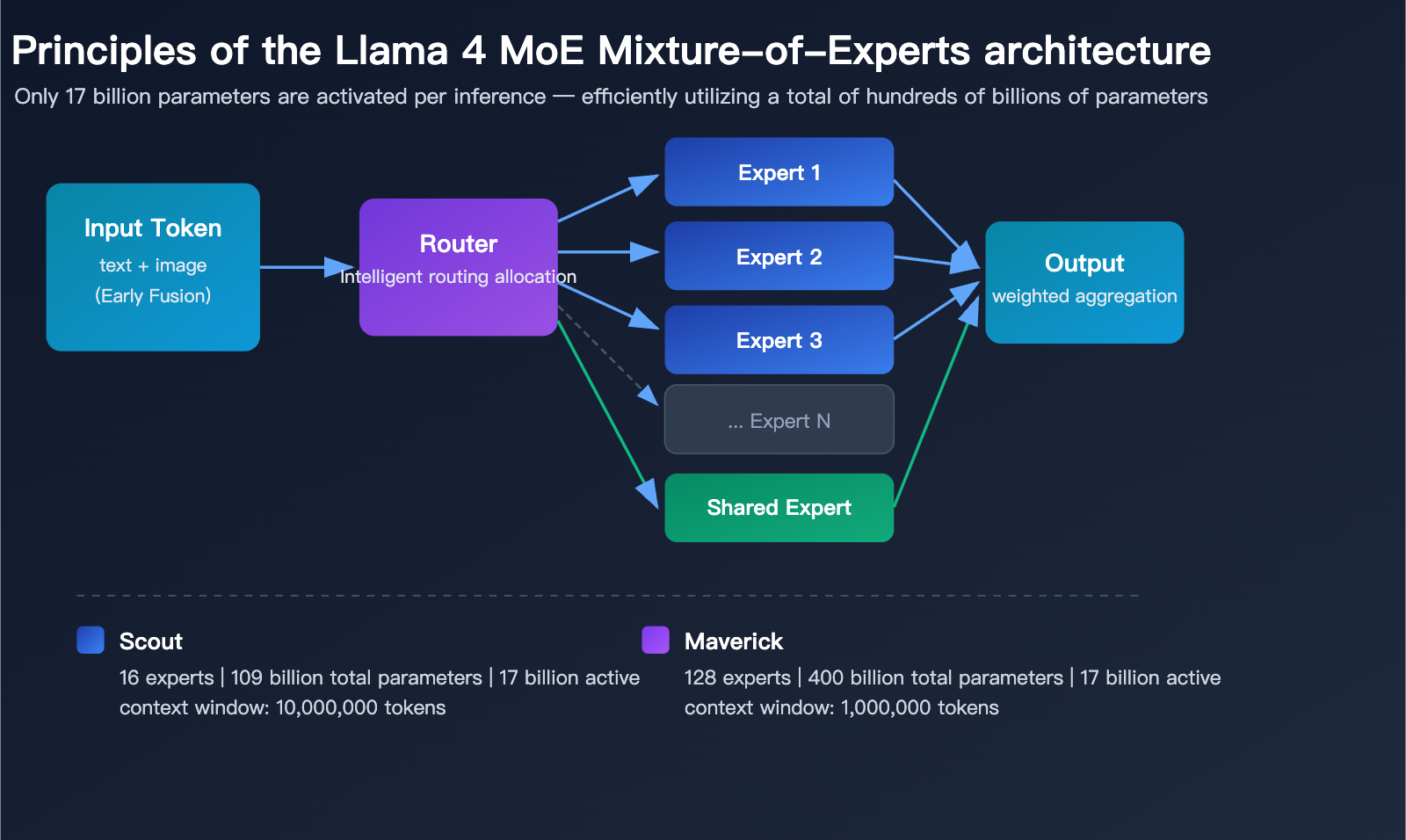
Native Multimodal Early Fusion Architecture
The biggest architectural innovation in Llama 4 is its native multimodal training. Unlike previous approaches that tacked on a vision module to a language model, Llama 4 adopts an Early Fusion strategy from the pre-training stage, integrating text and visual tokens directly into the model's backbone network.
This means that when Llama 4 processes mixed image-text content, it no longer relies on a two-stage "look at the image, then speak" process. Instead, it treats images and text as a unified input for true understanding and reasoning.
Llama 4 MoE (Mixture of Experts) Mechanism
| Technical Details | Scout (16 Experts) | Maverick (128 Experts) |
|---|---|---|
| Total Parameters | 109 Billion | 400 Billion |
| Active Parameters per Inference | 17 Billion | 17 Billion |
| Routed Experts | 16 + Shared Expert | 128 + Shared Expert |
| Inference Efficiency | Runs on single H100 (INT4) | Runs on single H100 DGX |
| Context Architecture | iRoPE (Interleaved Rotary Positional Embedding) | Standard Attention |
The core advantage of the MoE architecture is that while the total parameter counts are massive (109B and 400B respectively), only 17 billion parameters are activated per inference. This allows Llama 4 Scout to run on a single NVIDIA H100 GPU using INT4 quantization, significantly lowering the barrier to deployment.
Llama 4 Training Data and Scale
Llama 4 was trained on over 30 trillion tokens, double that of Llama 3. The multilingual data volume is 10 times larger than Llama 3, covering 200 languages. Training utilized FP8 precision, achieving a training efficiency of 390 TFLOPs per GPU on the Behemoth model.
Llama 4 Scout and Maverick Performance Evaluation
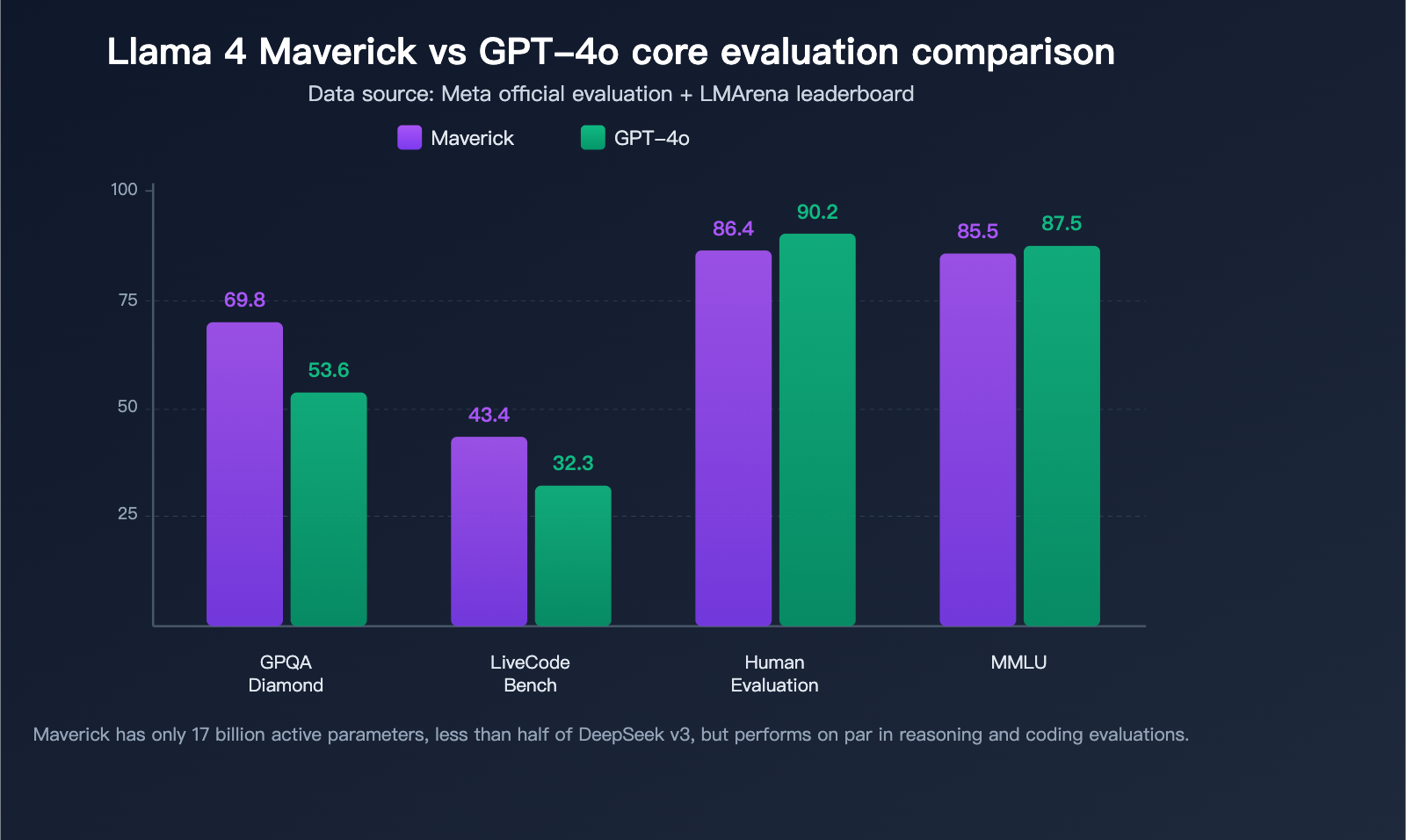
Llama 4 Maverick Evaluation Data
Maverick stands out in several authoritative benchmarks, with comprehensive capabilities surpassing GPT-4o and Gemini 2.0 Flash:
| Benchmark | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | Evaluation |
|---|---|---|---|---|
| MMLU | 85.5 | ~87-88 | – | Near top-tier |
| GPQA Diamond | 69.8 | 53.6 | – | Significantly ahead |
| LiveCodeBench | 43.4 | 32.3 | – | Significantly ahead |
| HumanEval | 86.4% | 90.2% | – | Near parity |
| LMArena ELO | 1417 | Below 1417 | Below 1417 | Top-tier |
Key highlights:
GPQA Diamond Scientific Reasoning Lead: Maverick scored 69.8 on GPQA Diamond, over 16 percentage points higher than GPT-4o's 53.6, demonstrating powerful professional-grade reasoning.
LiveCodeBench Coding Prowess: In the real-time coding benchmark LiveCodeBench, Maverick led with 43.4 points compared to GPT-4o's 32.3, while matching DeepSeek v3 in reasoning and coding tasks—despite having less than half the active parameter count of DeepSeek v3.
LMArena Human Preference Top-Tier: The experimental version of Maverick achieved an ELO score of 1417 on LMArena (Chatbot Arena), placing it among the world's top models.
Llama 4 Scout Evaluation Highlights
As a "small" model with only 17 billion active parameters, Scout's performance is impressive:
- Outperforms Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 across a wide range of benchmarks.
- Surpasses all previous-generation Llama 3 models, including the larger Llama 3.3 70B.
- Features an industry-leading 10 million token context window, capable of processing approximately 7.5 million words.
- Runs on a single H100 GPU with extremely low inference costs.
🎯 Developer Tip: Both Llama 4 Scout and Maverick support OpenAI-compatible API calls. To quickly test these models, you can use the APIYI (apiyi.com) platform to access a unified API interface, allowing you to switch between various open-source and closed-source models with a single key.
The Impact of Llama 4 Scout and Maverick on Developers
The Value of a 10 Million Token Context Window
Scout’s 10 million token context window is currently the longest among publicly released models, opening up entirely new application possibilities for developers:
- Full Codebase Analysis: You can feed an entire medium-to-large project into the model for analysis in one go.
- Long Document Processing: Handle hundreds of pages of technical documentation, legal contracts, or research papers at once.
- Extended Conversation Memory: Maintain extremely long-term context memory in conversational applications.
- Large-Scale Data Extraction: Batch-extract structured information from massive amounts of unstructured text.
Impact on the Llama 4 Open Source Ecosystem
| Impact Dimension | Specific Change | Developer Benefits |
|---|---|---|
| Deployment Barrier | Scout runs on a single GPU | Lower hardware costs |
| Model Capability | Surpasses GPT-4o level | Open source catches up to closed source |
| Multimodal | Native image/text understanding | No extra vision modules needed |
| Context | 10 million tokens | Brand new application scenarios |
| Customization | Open weights for fine-tuning | Vertical scenario optimization |
The release of Llama 4 marks the first time open-source models have fully caught up to, or even surpassed, mainstream closed-source commercial models in comprehensive capabilities. For developers, this means:
Cost Advantage: Private deployment based on Llama 4 can significantly reduce model invocation costs, which is especially ideal for high-frequency production scenarios.
Customization Freedom: Open weights mean developers can perform fine-tuning, quantization, and distillation on Llama 4 to build specialized models for vertical domains.
Ecosystem Prosperity: On its first day, Llama 4 received support from multiple cloud platforms, including AWS, Google Cloud, Azure, Together.ai, Groq, and Fireworks.
Llama 4 Platform Integration
Meta has integrated Llama 4 into its social platforms, providing multimodal capabilities for the Meta AI assistant:
- WhatsApp: Supports sending images for AI analysis and conversation.
- Messenger: Multimodal interactive Q&A.
- Instagram Direct: Image understanding and creative assistance.
- Meta.ai: Direct usage via the web interface.
This is the first time a Large Language Model has been deployed directly to consumers on such a massive scale, reaching billions of users.
Llama 4 Behemoth: The Flagship Still in Training
In addition to Scout and Maverick, Meta has teased the flagship model of the Llama 4 family: Behemoth.
| Parameter | Behemoth Specs |
|---|---|
| Active Parameters | 288 billion |
| Number of Experts | 16 |
| Total Parameters | Approx. 2 trillion |
| Training Status | In progress |
According to early checkpoint data released by Meta, Behemoth has already outperformed GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro in several STEM benchmarks. Maverick gains performance boosts from Behemoth through knowledge distillation during training, which explains how Maverick achieves top-tier performance with fewer active parameters.
💡 Recommendation: The eventual release of Behemoth will further push the capability ceiling for open-source models. Developers can start building applications based on Scout and Maverick now, perform multi-model comparison tests on the APIYI (apiyi.com) platform, and switch seamlessly once Behemoth is released.
Quick Start: Llama 4 Scout and Maverick
Minimalist API Invocation Example
You can call the Llama 4 model in just 10 lines of code using the OpenAI-compatible interface:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{"role": "user", "content": "Explain how the MoE architecture works"}]
)
print(response.choices[0].message.content)
View Multimodal Invocation Example
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Read and encode a local image
with open("image.jpg", "rb") as f:
image_data = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Please describe the content of this image"},
{"type": "image_url", "image_url": {
"url": f"data:image/jpeg;base64,{image_data}"
}}
]
}]
)
print(response.choices[0].message.content)
🚀 Quick Start: We recommend getting your API key and free testing credits via APIYI (apiyi.com). The platform supports a unified interface for Llama 4 Scout, Maverick, and other mainstream models, making it easy to compare the real-world performance of different models.
FAQ
Q1: How do I choose between Llama 4 Scout and Maverick?
If you need to process ultra-long text (such as entire codebases or long document analysis), choose Scout (10 million token context window). If you need the most powerful general-purpose model, choose Maverick (128 experts, benchmarks surpassing GPT-4o). You can test the actual performance of both on the APIYI (apiyi.com) platform to help you make the best choice.
Q2: Is Llama 4 completely free?
Llama 4 uses the Llama license, which provides open weights and allows for commercial use. However, companies with over 700 million monthly active users must apply for a special license from Meta. For the vast majority of developers and businesses, it's free to use. If you don't want to deploy it yourself, you can also call it on-demand via API through third-party platforms like APIYI (apiyi.com).
Q3: Is Llama 4 Maverick really better than GPT-4o?
On key benchmarks like GPQA Diamond (scientific reasoning) and LiveCodeBench (real-time programming), Maverick does indeed lead GPT-4o significantly. They are neck-and-neck on MMLU and HumanEval. In the LMArena human preference evaluation, Maverick has also achieved a top-tier ELO score. Overall, Maverick is in the same league as GPT-4o in comprehensive evaluations, with some metrics even leading the pack.
Summary
Key takeaways for Llama 4 Scout and Maverick:
- Architectural Innovation: These are the first native multimodal MoE open-source models. The Early Fusion architecture enables true, unified understanding of text and images.
- Performance Breakthroughs: Maverick outperforms GPT-4o by over 16 percentage points on GPQA Diamond, while Scout—with 17 billion active parameters—surpasses Llama 3.3 70B.
- Application Transformation: With a 10 million token context window and open weights, these models unlock entirely new application scenarios and deployment possibilities for developers.
The release of Llama 4 marks a new era for open-source Large Language Models. Whether you're building enterprise-grade applications or personal projects, you can now leverage Llama 4 to achieve capabilities comparable to top-tier closed-source models. We recommend using APIYI (apiyi.com) to quickly experience the Llama 4 series; the platform offers free credits and a unified interface for multiple models, helping you select the right tools efficiently.
📚 References
-
Meta AI Official Blog – Llama 4 Announcement: The authoritative source for technical details and benchmark data.
- Link:
ai.meta.com/blog/llama-4-multimodal-intelligence - Description: Includes a complete architectural overview, benchmark data, and release details.
- Link:
-
Llama Official Website – Model Downloads: Get Llama 4 model weights and documentation.
- Link:
llama.com/models/llama-4 - Description: Provides model downloads, license information, and technical documentation.
- Link:
-
Hugging Face – Llama 4 Model Hub: Hosting and usage guides from the open-source community.
- Link:
huggingface.co/meta-llama - Description: Offers model cards, quantized versions, and community discussions.
- Link:
Author: APIYI Technical Team
Technical Discussion: We welcome you to share your experiences with Llama 4 in the comments. For more information on integrating AI models, visit the APIYI documentation center at docs.apiyi.com.