Anmerkung des Autors: Meta veröffentlicht Llama 4 Scout und Maverick, basierend auf einer nativen, multimodalen MoE-Architektur. Scout bietet ein Kontextfenster von 10 Millionen Token, während Maverick in umfassenden Benchmarks GPT-4o übertrifft. Dieser Artikel bietet eine tiefgehende Analyse der technischen Details und der Auswirkungen auf Entwickler.
Meta hat offiziell die Llama 4 Modellfamilie veröffentlicht. Die ersten nativen, multimodalen Open-Source-MoE-Modelle Llama 4 Scout und Maverick haben in der KI-Community für großes Aufsehen gesorgt. Dieser Artikel bietet einen schnellen Überblick über die weitreichenden Auswirkungen dieses Meilensteins auf KI-Entwickler und die gesamte Branche.
Kernwert: Erfahren Sie in 3 Minuten alles über die technischen Durchbrüche, die Bewertungsergebnisse und den praktischen Nutzwert von Llama 4 Scout und Maverick.

Llama 4 Scout und Maverick: Kurzüberblick
| Information | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|
| Veröffentlichungsdatum | 5. April 2025 | 5. April 2025 |
| Architekturtyp | Natives multimodales MoE | Natives multimodales MoE |
| Aktive Parameter | 17 Mrd. | 17 Mrd. |
| Anzahl der Experten | 16 | 128 |
| Gesamtparameter | 109 Mrd. | 400 Mrd. |
| Kontextfenster | 10 Mio. Token | 1 Mio. Token |
| Open-Source-Lizenz | Llama-Lizenz | Llama-Lizenz |
Llama 4 Scout und Maverick: Wichtige Positionierung
Llama 4 ist die vierte Generation der Großes Sprachmodell-Familie von Meta und die erste Llama-Serie, die auf einer nativen, multimodalen und Mixture-of-Experts (MoE) Architektur basiert. Im Vergleich zur Llama 3-Serie wurde Llama 4 architektonisch grundlegend neu konzipiert.
Scout ist als Modell für die effiziente Verarbeitung langer Texte positioniert und bietet mit einem Kontextfenster von 10 Millionen Token das branchenweit längste Fenster bei extrem niedrigen Inferenzkosten. Maverick hingegen ist als leistungsstarkes Allzweckmodell konzipiert, das durch seine 128 Expertennetzwerke eine Gesamtleistung erzielt, die über der von GPT-4o liegt.
Die Gewichte beider Modelle sind bereits zum Download verfügbar; Entwickler können sie über llama.com und Hugging Face beziehen.
Analyse der technischen Architektur von Llama 4 Scout und Maverick
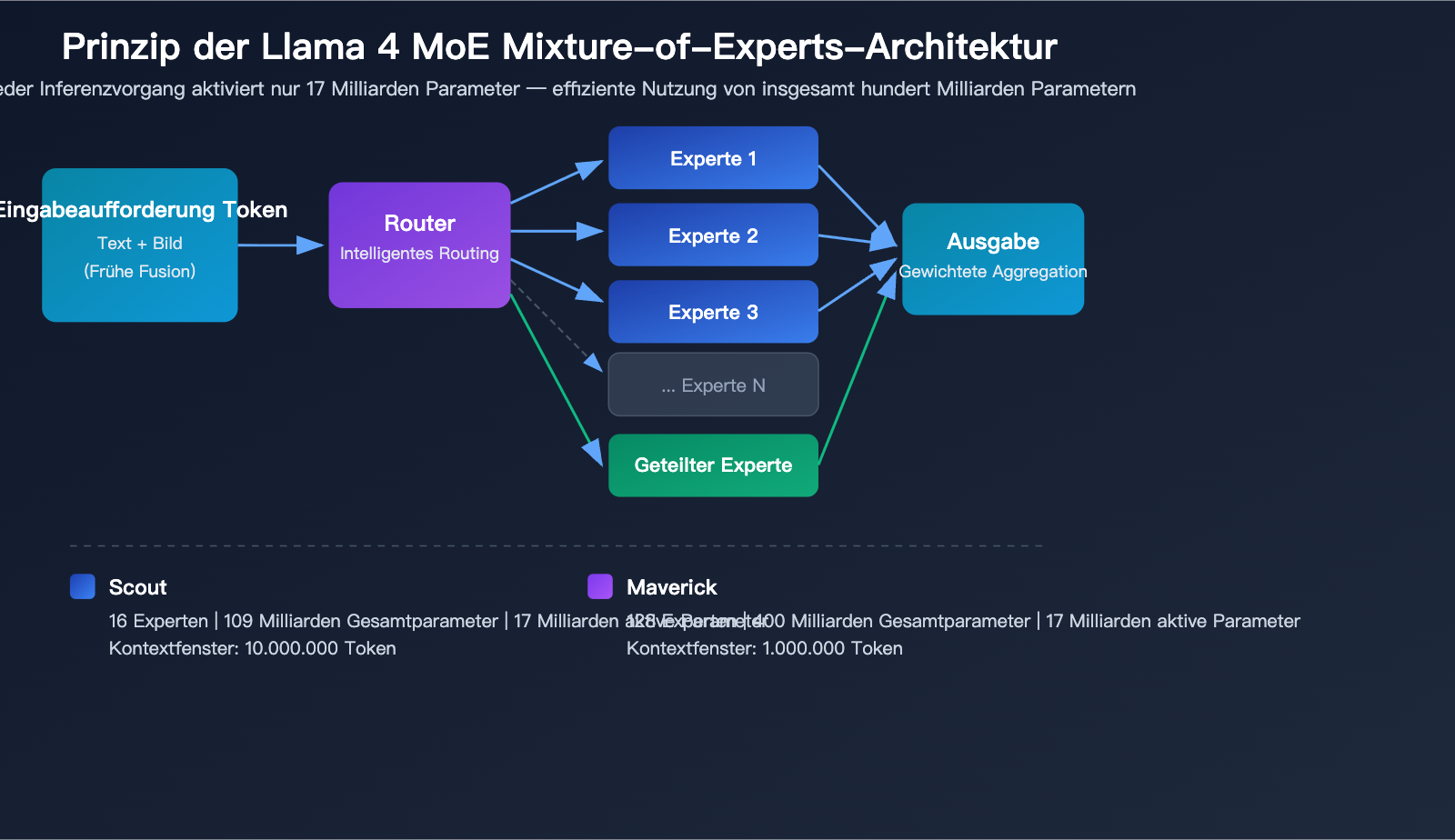
Native multimodale Early-Fusion-Architektur
Die größte architektonische Innovation von Llama 4 liegt im nativen multimodalen Training. Im Gegensatz zu früheren Ansätzen, bei denen visuelle Module nachträglich an ein Sprachmodell angebunden wurden, setzt Llama 4 bereits in der Vortrainingsphase auf ein Early-Fusion-Konzept (frühe Fusion). Dabei werden Text- und Bild-Token direkt in das Backbone-Netzwerk des Modells integriert.
Das bedeutet, dass Llama 4 bei der Verarbeitung von gemischten Inhalten aus Text und Bild nicht mehr in zwei Schritten vorgeht („erst Bild ansehen, dann sprechen“), sondern Bilder und Texte als eine einheitliche Eingabe versteht und verarbeitet.
Llama 4 MoE (Mixture of Experts)
| Technische Details | Scout (16 Experten) | Maverick (128 Experten) |
|---|---|---|
| Gesamtparameter | 109 Mrd. | 400 Mrd. |
| Aktive Parameter pro Inferenz | 17 Mrd. | 17 Mrd. |
| Routing-Experten | 16 + geteilte Experten | 128 + geteilte Experten |
| Inferenz-Effizienz | Auf einer H100 ausführbar (INT4) | Auf einer H100 DGX ausführbar |
| Kontext-Architektur | iRoPE (ohne Positions-Interleaving) | Standard-Attention |
Der entscheidende Vorteil der MoE-Architektur: Obwohl die Gesamtparameterzahl bei 109 bzw. 400 Milliarden liegt, werden pro Inferenzvorgang nur 17 Milliarden Parameter aktiviert. Dies ermöglicht es, Llama 4 Scout mittels INT4-Quantisierung auf einer einzelnen NVIDIA H100 GPU zu betreiben, was die Hürden für die Bereitstellung massiv senkt.
Trainingsdaten und Skalierung von Llama 4
Das Trainingsdatenvolumen von Llama 4 umfasst über 30 Billionen Token, was dem Doppelten von Llama 3 entspricht. Die Menge an mehrsprachigen Daten ist sogar zehnmal so groß wie bei Llama 3 und deckt 200 Sprachen ab. Das Training erfolgt mit FP8-Präzision, wodurch beim Behemoth-Modell eine Trainingseffizienz von 390 TFLOPs pro GPU erreicht wurde.
Llama 4 Scout und Maverick: Leistungsanalyse
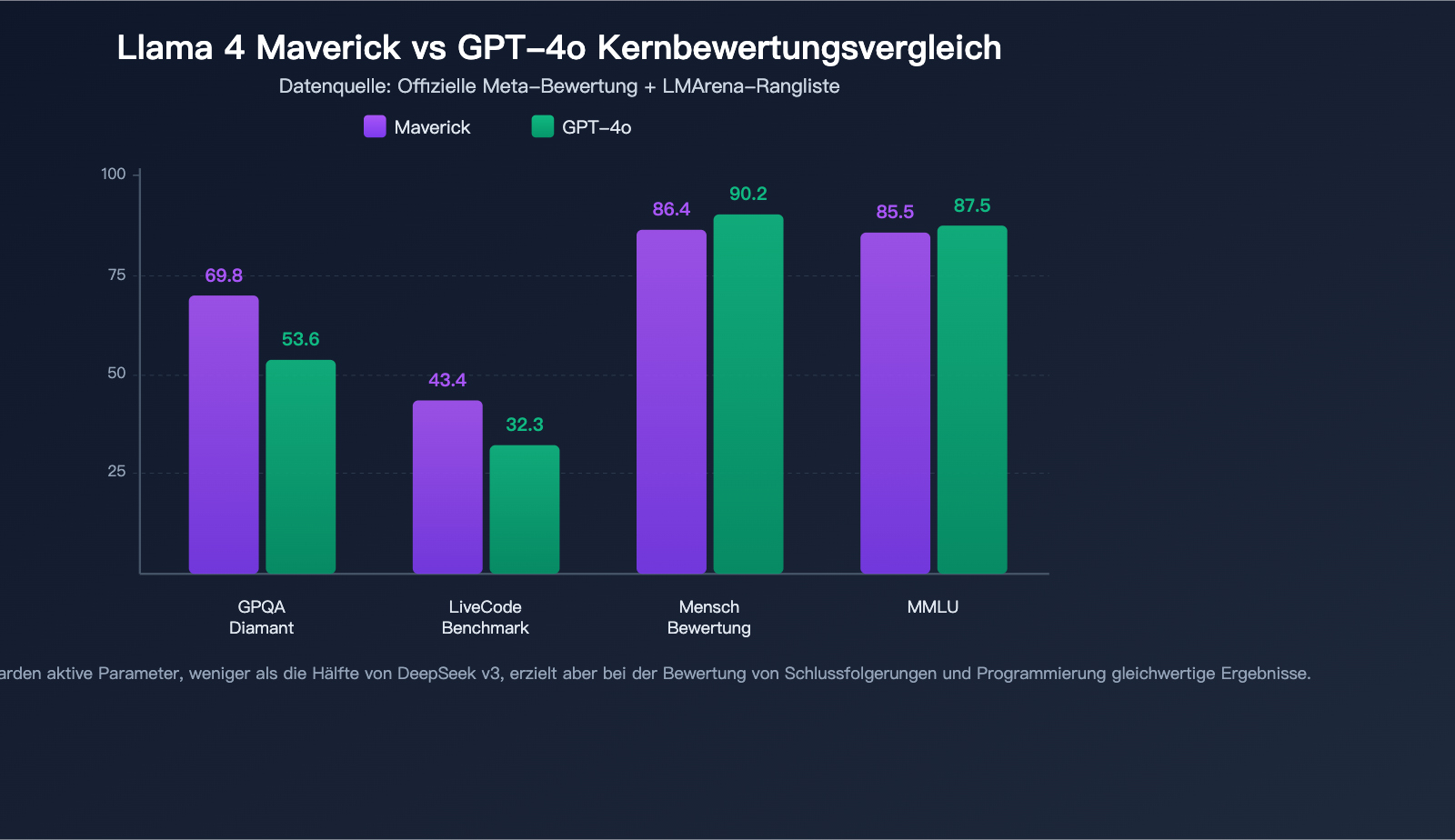
Llama 4 Maverick: Leistungsdaten
Maverick überzeugt in mehreren maßgeblichen Benchmarks und übertrifft in der Gesamtleistung GPT-4o sowie Gemini 2.0 Flash:
| Benchmark | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | Bewertung |
|---|---|---|---|---|
| MMLU | 85,5 | ~87-88 | – | Nahe an der Spitze |
| GPQA Diamond | 69,8 | 53,6 | – | Deutlich voraus |
| LiveCodeBench | 43,4 | 32,3 | – | Signifikant voraus |
| HumanEval | 86,4 % | 90,2 % | – | Auf Augenhöhe |
| LMArena ELO | 1417 | unter 1417 | unter 1417 | Top-Niveau |
Besonders hervorzuheben sind folgende Punkte:
Führend bei wissenschaftlicher Schlussfolgerung (GPQA Diamond): Mit einem Score von 69,8 übertrifft Maverick GPT-4o (53,6) um mehr als 16 Prozentpunkte und beweist damit eine beeindruckende Fähigkeit zur fachspezifischen Schlussfolgerung.
Herausragende Programmierleistung (LiveCodeBench): Im Live-Programmier-Benchmark LiveCodeBench liegt Maverick mit 43,4 Punkten vor GPT-4o (32,3). Dabei erreicht es bei Schlussfolgerungs- und Programmieraufgaben das Niveau von DeepSeek v3 – und das bei weniger als der Hälfte der aktiven Parameter von DeepSeek v3.
Top-Platzierung bei menschlicher Präferenz (LMArena): Die experimentelle Version von Maverick erreichte im LMArena (Chatbot Arena) einen ELO-Score von 1417 und zählt damit zu den weltweit führenden Modellen.
Llama 4 Scout: Highlights
Als "kleines" Modell mit nur 17 Milliarden aktiven Parametern liefert Scout eine beeindruckende Performance:
- Übertrifft in zahlreichen Benchmarks Gemma 3, Gemini 2.0 Flash-Lite und Mistral 3.1
- Übertrifft alle Llama-3-Modelle der vorherigen Generation, einschließlich des größeren Llama 3.3 70B
- Verfügt über das branchenweit längste Kontextfenster von 10 Millionen Token, was etwa 7,5 Millionen Wörtern entspricht
- Läuft auf einer einzelnen H100 GPU bei extrem niedrigen Kosten für den Modellaufruf
🎯 Empfehlung für Entwickler: Llama 4 Scout und Maverick unterstützen beide den OpenAI-kompatiblen API-Aufruf. Für einen schnellen Test der Modelle können Sie die einheitliche API-Schnittstelle über die Plattform APIYI (apiyi.com) nutzen. Ein einziger API-Schlüssel genügt, um zwischen verschiedenen Open-Source- und Closed-Source-Modellen zu wechseln.
Auswirkungen von Llama 4 Scout und Maverick auf Entwickler
Anwendungswert des 10-Millionen-Token-Kontextfensters
Das 10-Millionen-Token-Kontextfenster von Scout ist das derzeit längste bei öffentlich verfügbaren Modellen. Diese Kapazität eröffnet Entwicklern völlig neue Anwendungsbereiche:
- Analyse vollständiger Codebasen: Ganze mittelgroße bis große Projekte können zur Analyse in einem Durchgang in das Modell geladen werden.
- Verarbeitung langer Dokumente: Hunderte Seiten technischer Dokumentationen, Rechtsverträge oder Forschungsarbeiten lassen sich in einem Schritt verarbeiten.
- Langzeitgedächtnis für Dialoge: Aufrechterhaltung extrem langer Kontextspeicher in dialogorientierten Anwendungen.
- Massive Datenextraktion: Stapelweise Extraktion strukturierter Informationen aus riesigen Mengen unstrukturierter Texte.
Auswirkungen auf das Llama 4 Open-Source-Ökosystem
| Einflussbereich | Konkrete Änderung | Nutzen für Entwickler |
|---|---|---|
| Bereitstellungshürde | Scout auf einer einzelnen GPU ausführbar | Senkung der Hardwarekosten |
| Modellleistung | Übertrifft GPT-4o-Niveau | Open Source zieht mit Closed Source gleich |
| Multimodalität | Native Bild-Text-Verständnis | Keine zusätzlichen visuellen Module nötig |
| Kontext | 10 Millionen Token | Völlig neue Anwendungsszenarien |
| Anpassung | Offene Gewichte für Fine-Tuning | Optimierung für vertikale Szenarien |
Die Veröffentlichung von Llama 4 markiert den ersten Zeitpunkt, an dem Open-Source-Modelle in ihrer Gesamtleistung mit führenden kommerziellen Modellen gleichziehen oder diese sogar übertreffen. Für Entwickler bedeutet das:
Kostenvorteil: Eine private Bereitstellung auf Basis von Llama 4 kann die Kosten für Modellaufrufe erheblich senken, was besonders für Produktionsszenarien mit hoher Frequenz geeignet ist.
Freiheit bei der Anpassung: Offene Gewichte bedeuten, dass Entwickler Llama 4 feinabstimmen, quantisieren oder destillieren können, um maßgeschneiderte Modelle für spezifische Fachbereiche zu erstellen.
Ökologisches Wachstum: Llama 4 erhielt bereits am ersten Tag Unterstützung von Cloud-Plattformen wie AWS, Google Cloud, Azure, Together.ai, Groq und Fireworks.
Llama 4 Plattform-Integration
Meta hat Llama 4 in seine sozialen Plattformen integriert, um dem Meta AI-Assistenten multimodale Fähigkeiten zu verleihen:
- WhatsApp: Unterstützung beim Senden von Bildern für KI-Analysen und Dialoge.
- Messenger: Multimodale interaktive Fragen und Antworten.
- Instagram Direct: Bildverständnis und kreative Unterstützung.
- Meta.ai: Direkte Nutzung über die Weboberfläche.
Dies ist das erste Mal, dass ein großes Sprachmodell in einem derart massiven Maßstab direkt für Verbraucher bereitgestellt wird und Milliarden von Nutzern erreicht.
Llama 4 Behemoth: Das Flaggschiff-Modell noch im Training
Neben Scout und Maverick hat Meta das Flaggschiff-Modell der Llama 4-Familie angekündigt: Behemoth.
| Parameter | Behemoth-Spezifikationen |
|---|---|
| Aktive Parameter | 288 Milliarden |
| Anzahl der Experten | 16 |
| Gesamtparameteranzahl | ca. 2 Billionen |
| Trainingsstatus | Laufend |
Basierend auf den von Meta veröffentlichten Daten aus frühen Checkpoints übertrifft Behemoth in mehreren STEM-Benchmarks bereits GPT-4.5, Claude Sonnet 3.7 und Gemini 2.0 Pro. Maverick erzielt während des Trainings durch Wissensdestillation von Behemoth Leistungssteigerungen, was erklärt, warum Maverick trotz geringerer aktiver Parameter eine Spitzenleistung erreicht.
💡 Empfehlung: Die endgültige Veröffentlichung von Behemoth wird die Leistungsgrenzen von Open-Source-Modellen weiter verschieben. Entwickler können bereits jetzt Anwendungen auf Basis von Scout und Maverick erstellen, auf der Plattform APIYI (apiyi.com) Vergleichstests zwischen verschiedenen Modellen durchführen und nach der Veröffentlichung von Behemoth nahtlos wechseln.
Schneller Zugriff auf Llama 4 Scout und Maverick
Minimalistisches Beispiel für den Modellaufruf
Über die OpenAI-kompatible Schnittstelle können Sie das Llama 4-Modell mit nur 10 Zeilen Code aufrufen:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{"role": "user", "content": "Erkläre die Funktionsweise der MoE-Architektur"}]
)
print(response.choices[0].message.content)
Multimodalen Aufruf anzeigen
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Lokales Bild lesen und kodieren
with open("image.jpg", "rb") as f:
image_data = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Bitte beschreibe den Inhalt dieses Bildes"},
{"type": "image_url", "image_url": {
"url": f"data:image/jpeg;base64,{image_data}"
}}
]
}]
)
print(response.choices[0].message.content)
🚀 Schnellstart: Wir empfehlen, Ihren API-Schlüssel und kostenloses Testguthaben über APIYI (apiyi.com) zu beziehen. Die Plattform unterstützt eine einheitliche Schnittstelle für Llama 4 Scout, Maverick und andere gängige Modelle, was den direkten Vergleich der Modellleistung erleichtert.
Häufig gestellte Fragen (FAQ)
Q1: Wie wähle ich zwischen Llama 4 Scout und Maverick?
Wenn Sie extrem lange Texte verarbeiten müssen (z. B. vollständige Code-Repositories oder umfangreiche Dokumentenanalysen), wählen Sie Scout (10 Millionen Token Kontextfenster). Wenn Sie ein universelles Modell mit der stärksten Gesamtleistung suchen, wählen Sie Maverick (128 Experten, übertrifft GPT-4o in Benchmarks). Beide können über die APIYI-Plattform (apiyi.com) getestet werden, um die beste Wahl zu treffen.
Q2: Ist Llama 4 komplett kostenlos?
Llama 4 verwendet die Llama-Lizenz für offene Gewichte und erlaubt die kommerzielle Nutzung. Unternehmen mit mehr als 700 Millionen monatlich aktiven Nutzern müssen jedoch eine spezielle Genehmigung bei Meta beantragen. Für die überwiegende Mehrheit der Entwickler und Unternehmen ist die Nutzung kostenlos. Wer keine eigene Infrastruktur betreiben möchte, kann die Modelle auch über Drittplattformen wie APIYI (apiyi.com) per API-Aufruf nutzen.
Q3: Ist Llama 4 Maverick wirklich besser als GPT-4o?
Bei wichtigen Benchmarks wie GPQA Diamond (wissenschaftliches Schlussfolgern) und LiveCodeBench (Echtzeit-Programmierung) liegt Maverick tatsächlich deutlich vor GPT-4o. Bei MMLU und HumanEval liegen beide Modelle nah beieinander. Im LMArena-Ranking für menschliche Präferenzen hat Maverick ebenfalls einen erstklassigen ELO-Wert erreicht. Insgesamt spielt Maverick in der gleichen Liga wie GPT-4o und führt bei einigen Metriken sogar.
Zusammenfassung
Die Kernpunkte zu Llama 4 Scout und Maverick:
- Architektur-Innovation: Die ersten nativen, multimodalen MoE-Open-Source-Modelle. Die Early-Fusion-Architektur ermöglicht ein echtes, integriertes Verständnis von Text und Bild.
- Leistungssprung: Maverick übertrifft GPT-4o bei GPQA Diamond um mehr als 16 Prozentpunkte; Scout übertrifft mit 17 Milliarden aktiven Parametern das Modell Llama 3.3 70B.
- Anwendungswandel: Ein Kontextfenster von 10 Millionen Token und offene Gewichte eröffnen Entwicklern völlig neue Anwendungsszenarien und Bereitstellungsmöglichkeiten.
Die Veröffentlichung von Llama 4 markiert den Beginn einer neuen Ära für große Sprachmodelle im Open-Source-Bereich. Ob für Unternehmensanwendungen oder private Projekte – Entwickler können nun auf Basis von Llama 4 Fähigkeiten nutzen, die mit führenden geschlossenen Modellen vergleichbar sind. Wir empfehlen, die Llama 4-Modellreihe schnell und einfach über APIYI (apiyi.com) zu testen. Die Plattform bietet kostenlose Kontingente sowie eine einheitliche Schnittstelle für verschiedene Modelle, um Entwicklern bei der effizienten Modellauswahl zu helfen.
📚 Referenzen
-
Meta AI Offizieller Blog – Llama 4 Ankündigung: Maßgebliche Quelle für technische Details und Evaluierungsdaten des Modells
- Link:
ai.meta.com/blog/llama-4-multimodal-intelligence - Beschreibung: Enthält die vollständige Architekturvorstellung, Evaluierungsdaten und Details zur Veröffentlichung
- Link:
-
Llama Website – Modell-Download: Zugriff auf Llama 4 Modellgewichte und Dokumentation
- Link:
llama.com/models/llama-4 - Beschreibung: Bietet Modell-Downloads, Lizenzinformationen und technische Dokumentationen
- Link:
-
Hugging Face – Llama 4 Modell-Repository: Hosting und Nutzungsleitfaden der Open-Source-Community
- Link:
huggingface.co/meta-llama - Beschreibung: Bietet Modellkarten, quantisierte Versionen und Community-Diskussionen
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Wir freuen uns auf Ihre Erfahrungen mit Llama 4 in den Kommentaren. Weitere Informationen zur Anbindung von KI-Modellen finden Sie im Dokumentationszentrum von APIYI unter docs.apiyi.com.