When translating the same Chinese article into English, Japanese, and French using Gemini and DeepSeek respectively, the translation quality and completeness are virtually identical — yet the API's Completion Token counts differ by 2-2.5x. Is this an API billing bug? Or is there a deeper technical reason?
Core Value: Through real test data, understand how Tokenizer differences impact API costs and master how to choose the most cost-effective model for multilingual translation scenarios.

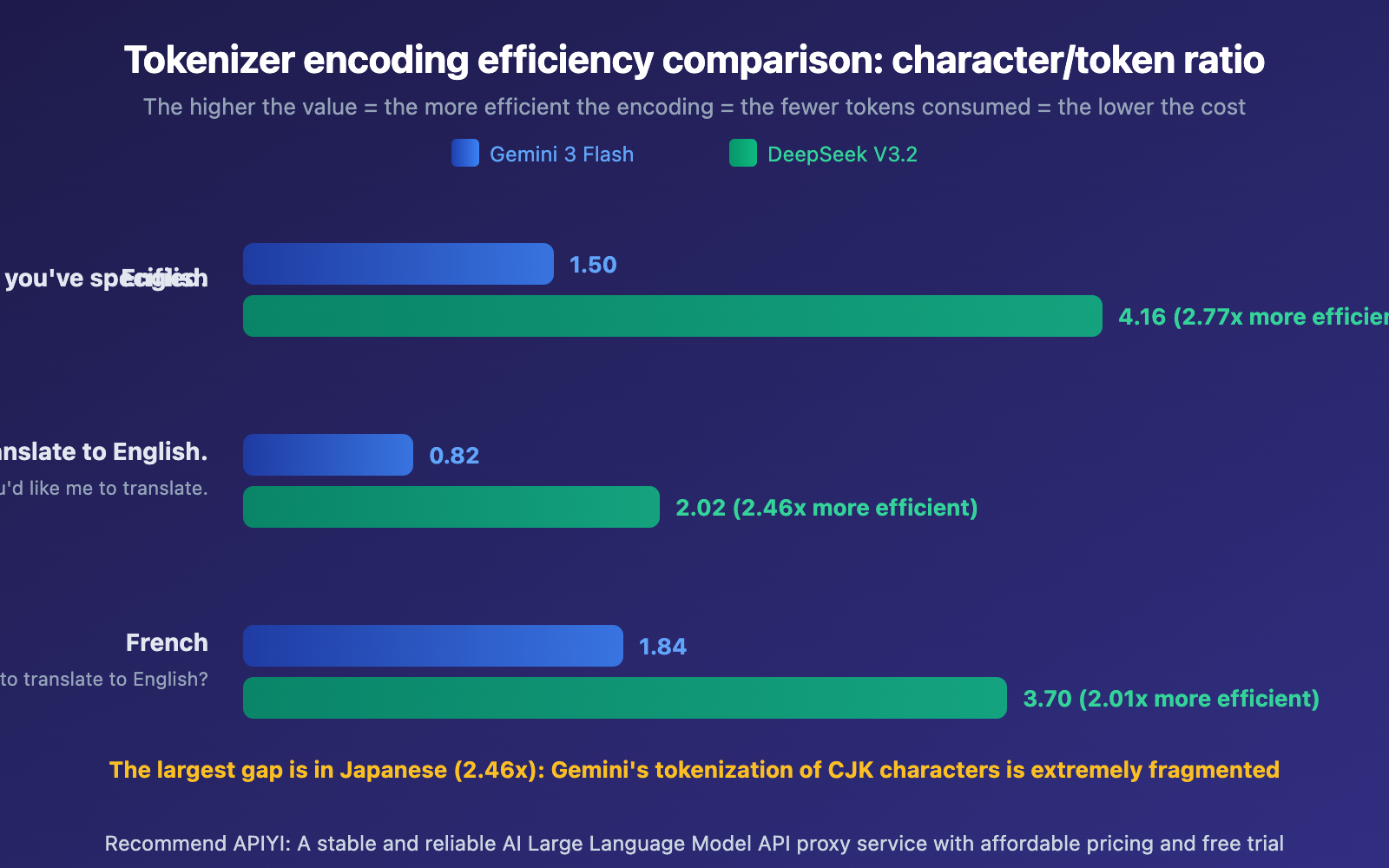
Gemini vs DeepSeek Tokenizer Efficiency: Core Data
| Comparison Dimension | Gemini 3 Flash | DeepSeek V3.2 | Difference Ratio |
|---|---|---|---|
| English Translation Completion Token | 1,631 | 636 | Gemini 2.56x higher |
| Japanese Translation Completion Token | 2,141 | 856 | Gemini 2.50x higher |
| French Translation Completion Token | 1,630 | 812 | Gemini 2.01x higher |
| Encoding Efficiency (characters/Token) | 0.82-1.84 | 2.02-4.16 | DeepSeek 2-2.8x higher |
| Translation Output Lines | 64 lines | 64 lines | Identical |
The Root Cause Behind Gemini vs DeepSeek Tokenizer Differences
We used the same 1,403-character Chinese test text (containing Markdown tables, code blocks, SVG placeholders, and CTAs) to call gemini-3-flash-preview and deepseek-v3.2 separately for translation into English, Japanese, and French. We then compared the Token statistics returned by the API against the actual output content.
The results are crystal clear: output character counts are nearly identical (less than 1% variance), yet Token counts differ by 2-2.5x. This proves the issue lies in the Tokenizer (the text segmentation tool), not the model's output strategy.
The Technical Principles Behind Gemini vs DeepSeek Tokenizers
What's a Tokenizer? Simply put, a Tokenizer breaks text into the smallest units that a model can understand (Tokens). Different models use different Tokenizers — think of it like different compression software. The same file compressed with ZIP versus RAR will have different sizes, but when decompressed, the content is identical.
Gemini's SentencePiece Tokenizer: Uses a Unigram language model with a vocabulary of roughly 256,000 Tokens. It tends to break CJK (Chinese, Japanese, Korean) characters into smaller subword units. In our tests, the Japanese output achieved only 0.82 characters/Token encoding efficiency, meaning each Japanese character requires an average of 1.2 Tokens to represent.
DeepSeek's Byte-level BPE Tokenizer: Has a vocabulary of about 128,000 Tokens, but it's specifically optimized for multilingual scenarios. It introduces combined punctuation and newline Tokens, boosting compression efficiency for CJK text. Japanese output reaches 2.02 characters/Token — 2.46x more efficient than Gemini.
Gemini vs DeepSeek Tokenizer Cost Impact Analysis
Once you understand the tokenizer efficiency differences, the key question becomes: Does more tokens always mean higher costs? Not necessarily. Your final cost depends on token count × unit price.
Real-World Gemini vs DeepSeek Translation Cost Comparison
Let's look at translating a typical technical blog post (approximately 30,000 prompt tokens) into 11 languages:
| Cost Dimension | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Estimated Completion Tokens per Language | ~80,000 | ~30,000 |
| Total Completion Tokens for 11 Languages | ~880,000 | ~330,000 |
| Output Price (per million tokens) | $3.00 | $0.42 |
| Total Output Cost for 11 Languages | $2.64 | $0.14 |
| Input Price (per million tokens) | $0.50 | $0.28 |
| Total Input Cost for 11 Requests | $0.17 | $0.09 |
| Total Cost per Article Translation | $2.81 | $0.23 |
The real-world cost comparison shows DeepSeek's advantage in multilingual translation scenarios is striking—the same translation task costs only about 1/12 as much on DeepSeek compared to Gemini. This gap comes from two compounding factors: tokenizer efficiency (2-2.5x) × token price difference (5-7x).
Gemini vs DeepSeek Translation Speed and Quality
But cost isn't the only consideration:
| Metric | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Inference Speed | 145-189 tokens/s | 12-26 tokens/s |
| Speed Multiple | 6-10x Faster | Baseline |
| Translation Quality | Excellent | Excellent |
| Translation Completeness | 100% (64 lines) | 100% (64 lines) |
| Markdown Format Preservation | Good | Good |
Gemini's inference speed is 6-10 times faster than DeepSeek. If you need rapid batch translations and time costs outweigh token costs, Gemini remains the better choice.
🎯 Selection Tips: If you have large translation volumes and aren't time-sensitive, DeepSeek's cost advantage is significant. If you need fast delivery, Gemini's speed advantage is clear. Through APIYI at apiyi.com, you can access both models simultaneously with a unified interface and flexibly switch between them to find the optimal balance for your use case.
Tokenizer Efficiency Impact Across Different Languages
Tokenizer impact varies dramatically across languages. CJK (Chinese, Japanese, Korean) languages are hit hardest, while Latin-based languages are relatively unaffected.

The data clearly shows:
- Japanese is most affected: Japanese encoding efficiency on Gemini is only 0.82 characters/token, which explains why translating articles with large amounts of Chinese and Japanese text significantly increases token consumption
- French has the smallest gap: Latin-based languages show relatively small tokenizer efficiency differences (only 2.01x), since most tokenizers are trained primarily on English-language data, giving Latin languages an advantage
- Chinese falls in the middle: About 1.76 times the English baseline, but this gap narrows when using Chinese-optimized models like DeepSeek or Qwen
🎯 Multilingual Translation Tips: If your translation work involves CJK languages like Japanese and Korean, choosing a model with higher tokenizer efficiency (such as DeepSeek or Qwen) can significantly reduce costs. Through APIYI's unified interface at apiyi.com, you can easily switch between different models for testing.
Gemini vs DeepSeek Tokenizer Scenario Selection Guide
| Use Case | Recommended Model | Core Reason |
|---|---|---|
| Large-scale multilingual translation | DeepSeek V3.2 | High token efficiency + low pricing, cost only 1/12 |
| Urgent translation delivery | Gemini 3 Flash | 6-10x faster, ideal for time-sensitive scenarios |
| CJK language-intensive translation | DeepSeek V3.2 | CJK Tokenizer efficiency advantage reaches 2.5x |
| Latin-based language translation | Minor difference | Efficiency gap only 2x between models, choose by pricing |
| Real-time conversation | Gemini 3 Flash | Low latency, better user experience |
| Cost-sensitive batch processing | DeepSeek V3.2 | Lowest overall cost |
🎯 Practical Tip: Real-world projects typically need to balance both cost and speed. We recommend integrating both Gemini and DeepSeek through APIYI at apiyi.com, then dynamically switch models based on task urgency. The platform supports unified key access to all mainstream models.
Frequently Asked Questions
Q1: Is Gemini’s higher token consumption an API billing bug?
No, it's not a bug. This is a normal phenomenon caused by differences in tokenizer encoding efficiency. It's like how the same file compressed with ZIP versus RAR results in different sizes—different models' tokenizers generate different token counts for the same text, but the content being processed is identical. Our testing verified that output character count differences are less than 1%.
Q2: Does higher token count mean better translation quality?
No. Token count only reflects the tokenizer's encoding method and has no correlation with translation quality. In our testing, both models demonstrated excellent translation quality and completeness, with identical output line counts (64 lines). When selecting a model, focus on translation quality, speed, and overall cost rather than token count alone.
Q3: How do I optimize token costs for multilingual translation in my project?
We recommend the following strategies:
- Prioritize DeepSeek and other models with high tokenizer efficiency for CJK languages (Chinese, Japanese, Korean)
- For Latin-based languages, you can choose flexibly since the gap is smaller
- Integrate multiple models through APIYI at apiyi.com and implement automatic language-based routing with a unified API
- When setting up token consumption monitoring, configure different thresholds for different models to avoid false alarms
Summary
The core conclusions from the Gemini vs DeepSeek Tokenizer efficiency comparison:
- Token Differences Come from Tokenizers, Not Bugs: For the same text, DeepSeek's tokenizer encoding efficiency is 2-2.8x higher than Gemini's, with the most significant gap in CJK languages
- Cost Differences Compound and Amplify: Tokenizer efficiency difference (2-2.5x) × token price difference (5-7x) = actual cost gap can reach 12x
- Speed vs Cost Trade-off: Gemini is 6-10x faster but has higher token costs, while DeepSeek is cheaper but slower—choose flexibly based on your use case
Understanding tokenizer efficiency differences is a key step in optimizing your AI API usage costs. In token-intensive scenarios like multilingual translation, selecting the right model can save substantial expenses.
We recommend using APIYI at apiyi.com to access multiple models through a unified integration, switching flexibly with a single API key to find the best cost-performance solution for each scenario.
📚 References
-
Tokenizer Performance Benchmark: Comprehensive comparison of mainstream model tokenizer efficiency
- Link:
llm-calculator.com/blog/tokenization-performance-benchmark - Description: Contains tokenizer efficiency data for GPT-4o, DeepSeek, Qwen, and other models
- Link:
-
CJK Text and Large Language Model Best Practices: CJK character tokenizer processing mechanisms
- Link:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - Description: In-depth analysis of token consumption differences for CJK languages across different tokenizers
- Link:
-
Gemini Tokenizer Analysis: Google Gemini's SentencePiece tokenizer principles
- Link:
dejan.ai/blog/gemini-toknizer - Description: Detailed analysis of the encoding mechanism and efficiency characteristics of Gemini's 256K vocabulary
- Link:
-
DeepSeek V3 Technical Report: Byte-level BPE tokenizer multilingual optimization
- Link:
arxiv.org/html/2412.19437v1 - Description: Design philosophy and multilingual compression efficiency of DeepSeek's 128K vocabulary
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to discuss in the comments section. For more resources, visit the APIYI documentation center at docs.apiyi.com