作者注:實測數據揭示 Gemini 和 DeepSeek 翻譯同一篇文章時 Token 消耗差 2-2.5 倍的根本原因——Tokenizer 編碼效率差異,並提供多語言場景下的成本優化建議
同一篇中文文章,用 Gemini 和 DeepSeek 分別翻譯成英文、日語、法語,翻譯質量和完整性完全一致——但 API 返回的 Completion Token 竟然差了 2-2.5 倍。這是 API 計費 Bug 嗎?還是有更深層的技術原因?
核心價值: 通過真實測試數據,幫你理解 Tokenizer 差異如何影響 API 成本,並掌握在多語言翻譯場景下選擇最具性價比模型的方法。
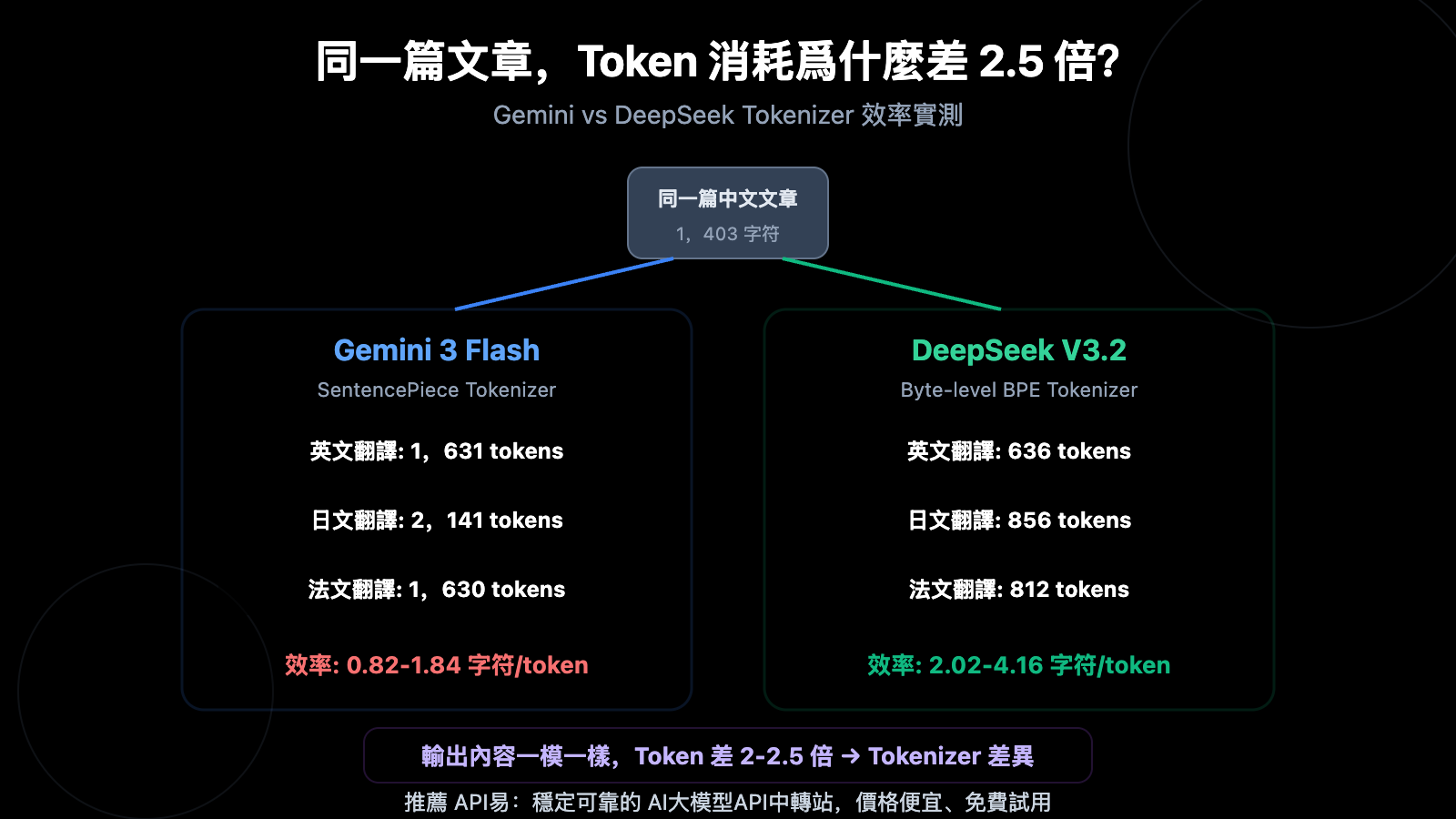
Gemini vs DeepSeek Tokenizer 效率核心數據
| 對比維度 | Gemini 3 Flash | DeepSeek V3.2 | 差異倍數 |
|---|---|---|---|
| 英文翻譯 Completion Token | 1,631 | 636 | Gemini 多 2.56x |
| 日文翻譯 Completion Token | 2,141 | 856 | Gemini 多 2.50x |
| 法文翻譯 Completion Token | 1,630 | 812 | Gemini 多 2.01x |
| 編碼效率(字符/Token) | 0.82-1.84 | 2.02-4.16 | DeepSeek 高 2-2.8x |
| 翻譯輸出行數 | 64 行 | 64 行 | 完全一致 |
Gemini vs DeepSeek Tokenizer 差異的根本原因
我們使用同一段 1,403 字符的中文測試文本(包含 Markdown 表格、代碼塊、SVG 佔位符、CTA),分別調用 gemini-3-flash-preview 和 deepseek-v3.2 翻譯到英文、日語、法語 3 種語言,然後對比 API 返回的 Token 統計和實際輸出內容。
結果非常明確:輸出字符數幾乎完全相同(差異不到 1%),但 Token 數差 2-2.5 倍。這證明問題出在 Tokenizer(分詞器),而非模型的輸出策略。
Gemini vs DeepSeek Tokenizer 的技術原理
Tokenizer 是什麼? 簡單來說,Tokenizer 就是將文本切分成模型能理解的最小單元(Token)的工具。不同模型使用不同的 Tokenizer,就像不同的壓縮軟件——同一個文件,ZIP 和 RAR 壓縮後大小不同,但解壓後內容完全一致。
Gemini 的 SentencePiece Tokenizer:使用 Unigram 語言模型,詞表大小約 256,000 個 Token。對 CJK(中日韓)字符傾向於拆分爲更小的子詞單元。實測中,日文輸出的編碼效率僅 0.82 字符/Token,意味着平均每個日文字符需要 1.2 個 Token 來表示。
DeepSeek 的 Byte-level BPE Tokenizer:詞表大小約 128,000 個 Token,但專門針對多語言場景進行了優化。引入了組合標點和換行符 Token,提升了 CJK 文本的壓縮效率。日文輸出達到 2.02 字符/Token,效率是 Gemini 的 2.46 倍。

Gemini vs DeepSeek Tokenizer 成本影響分析
理解了 Tokenizer 效率差異後,關鍵問題是:Token 數多就意味着花錢更多嗎? 不一定。最終成本取決於 Token 數量 × 單價。
Gemini vs DeepSeek 翻譯成本實測
以翻譯一篇典型的技術博客文章(約 30,000 Prompt Token)到 11 種語言爲例:
| 成本維度 | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| 預估單語言 Completion Token | ~80,000 | ~30,000 |
| 11 種語言總 Completion Token | ~880,000 | ~330,000 |
| Output 單價(每百萬 Token) | $3.00 | $0.42 |
| 11 語言 Output 總費用 | $2.64 | $0.14 |
| Input 單價(每百萬 Token) | $0.50 | $0.28 |
| 11 次 Input 總費用 | $0.17 | $0.09 |
| 單篇文章翻譯總成本 | $2.81 | $0.23 |
從實測成本對比來看,DeepSeek 在多語言翻譯場景下的費用優勢非常明顯——同樣的翻譯任務,DeepSeek 的成本僅爲 Gemini 的約 1/12。這個差距由兩個因素疊加造成:Tokenizer 效率(2-2.5x)× Token 單價差異(5-7x)。
Gemini vs DeepSeek 翻譯速度與質量
但成本不是唯一的考量因素:
| 指標 | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| 推理速度 | 145-189 tokens/s | 12-26 tokens/s |
| 速度倍數 | 6-10x 更快 | 基準 |
| 翻譯質量 | 優秀 | 優秀 |
| 翻譯完整性 | 100%(64 行) | 100%(64 行) |
| Markdown 格式保持 | 良好 | 良好 |
Gemini 的推理速度是 DeepSeek 的 6-10 倍。如果你需要快速批量翻譯、時間成本高於 Token 成本,Gemini 仍然是更好的選擇。
🎯 選擇建議: 如果翻譯量大且對時間不敏感,DeepSeek 的成本優勢顯著。如果需要快速交付,Gemini 的速度優勢明顯。通過 API易 apiyi.com 可以同時接入兩個模型,用統一接口靈活切換,找到你場景下的最優平衡點。
Tokenizer 效率差異對不同語言的影響
Tokenizer 對不同語言的影響程度差異很大。CJK(中日韓)語言受影響最嚴重,拉丁語系相對較輕。
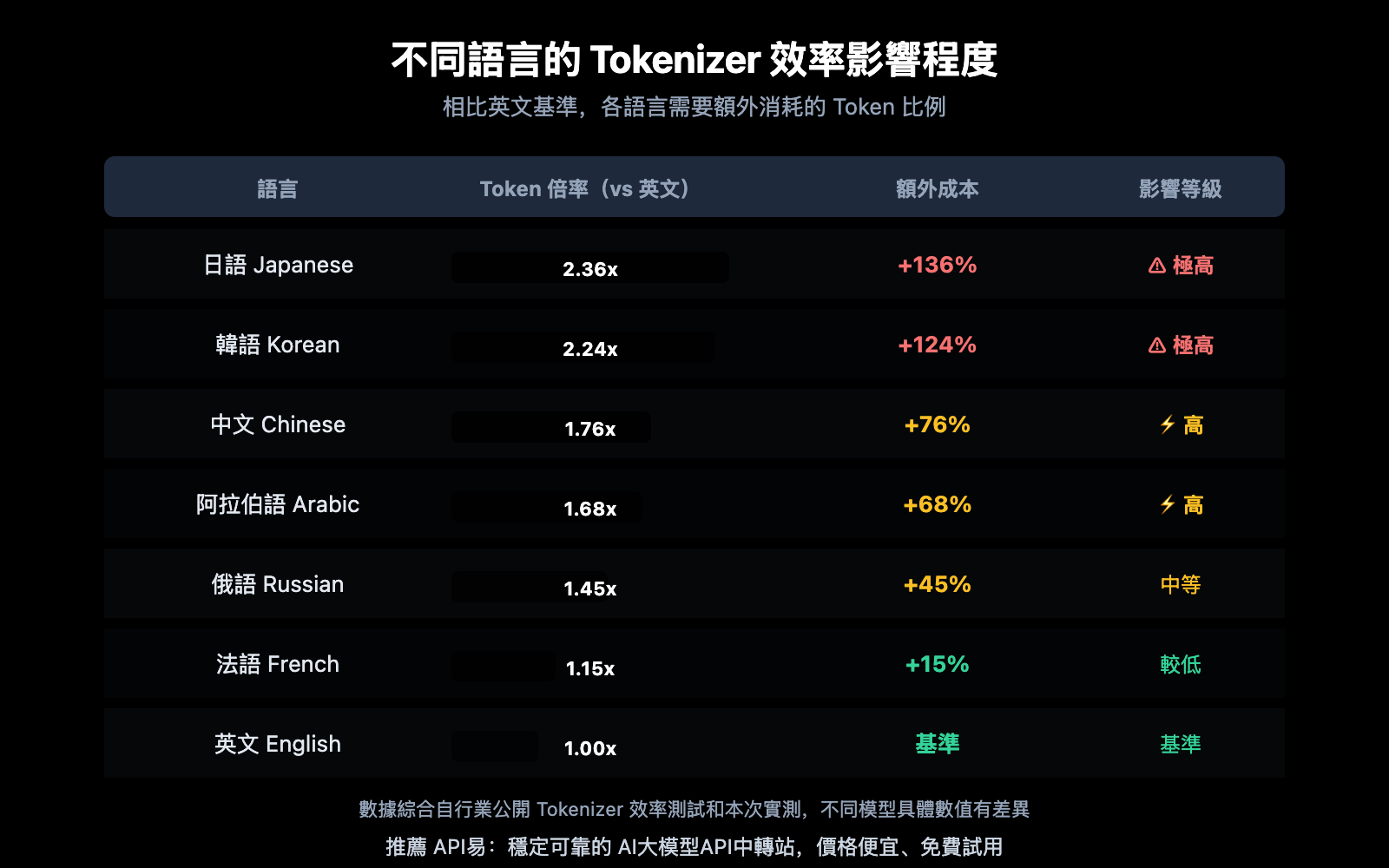
從數據中可以明確看到:
- 日語受影響最大:在 Gemini 上日語編碼效率僅 0.82 字符/Token,這解釋了爲什麼翻譯含大量中日文的文章時 Token 消耗會顯著增加
- 法語差異最小:拉丁語系語言的 Tokenizer 效率差距相對較小(僅 2.01x),因爲大多數 Tokenizer 的訓練語料以英文爲主,拉丁語系受益
- 中文處於中間:約 1.76 倍於英文基準,但使用 DeepSeek 等中文優化模型時差距會縮小
🎯 多語言翻譯建議: 如果你的翻譯任務涉及日語、韓語等 CJK 語言,選擇 Tokenizer 效率更高的模型(如 DeepSeek、Qwen)可以顯著降低成本。通過 API易 apiyi.com 的統一接口,你可以方便地在不同模型間切換測試。
Gemini vs DeepSeek Tokenizer 場景選擇指南
| 使用場景 | 推薦模型 | 核心原因 |
|---|---|---|
| 大批量多語言翻譯 | DeepSeek V3.2 | Token 效率高 + 單價低,成本僅 1/12 |
| 緊急翻譯交付 | Gemini 3 Flash | 速度快 6-10 倍,適合時間緊迫場景 |
| CJK 語言密集翻譯 | DeepSeek V3.2 | CJK Tokenizer 效率優勢達 2.5x |
| 拉丁語系翻譯 | 差異較小 | 兩者效率差距僅 2x,按單價選擇即可 |
| 實時對話場景 | Gemini 3 Flash | 低延遲,用戶體驗更好 |
| 成本敏感批處理 | DeepSeek V3.2 | 綜合成本最低 |
🎯 實用建議: 實際項目中往往需要兼顧成本和速度。我們建議通過 API易 apiyi.com 同時接入 Gemini 和 DeepSeek,根據任務緊急程度動態切換模型。平臺支持統一 Key 調用所有主流模型。
常見問題
Q1: Gemini Token 消耗多是不是 API 計費 Bug?
不是 Bug。這是 Tokenizer 編碼效率差異導致的正常現象。就像同一個文件用 ZIP 和 RAR 壓縮後大小不同一樣,不同模型的 Tokenizer 對同一段文本生成的 Token 數量不同,但處理的內容完全一致。我們的實測驗證了輸出字符數差異不到 1%。
Q2: Token 數多是否意味着翻譯質量更好?
不是。Token 數量只反映 Tokenizer 的編碼方式,與翻譯質量無關。實測中兩個模型的翻譯質量和完整性均表現優秀,輸出行數完全一致(64 行)。選擇模型時應該關注翻譯質量、速度和綜合成本,而非單純的 Token 數。
Q3: 如何在項目中優化多語言翻譯的 Token 成本?
推薦以下策略:
- 對 CJK 語言(中、日、韓)優先使用 DeepSeek 等 Tokenizer 效率高的模型
- 對拉丁語系可以靈活選擇,差距較小
- 通過 API易 apiyi.com 接入多個模型,用統一 API 實現按語言自動路由
- 設置 Token 消耗監控時,針對不同模型設置不同的閾值,避免誤報
總結
Gemini vs DeepSeek Tokenizer 效率對比的核心結論:
- Token 差異源於 Tokenizer,不是 Bug: 同一段文本,DeepSeek 的 Tokenizer 編碼效率比 Gemini 高 2-2.8 倍,CJK 語言差距最顯著
- 成本差異疊加放大: Tokenizer 效率差異(2-2.5x)× Token 單價差異(5-7x)= 實際成本差距可達 12 倍
- 速度 vs 成本的權衡: Gemini 速度快 6-10 倍但 Token 成本高,DeepSeek 成本低但速度慢——根據場景靈活選擇
理解 Tokenizer 效率差異,是優化 AI API 使用成本的關鍵一步。在多語言翻譯等 Token 密集型場景下,選對模型可以節省大量費用。
推薦通過 API易 apiyi.com 統一接入多個模型,用一個 Key 靈活切換,找到每個場景下的最佳性價比方案。
📚 參考資料
-
Tokenizer 性能基準測試: 全面對比主流模型 Tokenizer 效率
- 鏈接:
llm-calculator.com/blog/tokenization-performance-benchmark - 說明: 包含 GPT-4o、DeepSeek、Qwen 等模型的 Tokenizer 效率數據
- 鏈接:
-
CJK 文本與 AI 大模型最佳實踐: CJK 字符 Tokenizer 處理機制
- 鏈接:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - 說明: 深入分析 CJK 語言在不同 Tokenizer 下的 Token 消耗差異
- 鏈接:
-
Gemini Tokenizer 解析: Google Gemini 的 SentencePiece 分詞器原理
- 鏈接:
dejan.ai/blog/gemini-toknizer - 說明: 詳細分析 Gemini 256K 詞表的編碼機制和效率特點
- 鏈接:
-
DeepSeek V3 技術報告: Byte-level BPE Tokenizer 的多語言優化
- 鏈接:
arxiv.org/html/2412.19437v1 - 說明: DeepSeek 128K 詞表的設計理念和多語言壓縮效率
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區討論,更多資料可訪問 API易 docs.apiyi.com 文檔中心