著者注:実測データが明かす Gemini と DeepSeek の翻訳時における Token 消費差 2~2.5 倍の根本原因——Tokenizer エンコーディング効率の差異と、多言語シナリオにおけるコスト最適化提案
同じ中国語の記事を Gemini と DeepSeek でそれぞれ英語、日本語、フランス語に翻訳した場合、翻訳品質と完全性は全く同じなのに、API が返す Completion Token がなんと 2~2.5 倍も異なります。これは API 課金のバグなのでしょうか?それとも、より深い技術的な理由があるのでしょうか?
コア価値:実測データを通じて、Tokenizer の差異が API コストにどう影響するかを理解し、多言語翻訳シナリオで最もコストパフォーマンスに優れたモデルを選択する方法を習得できます。
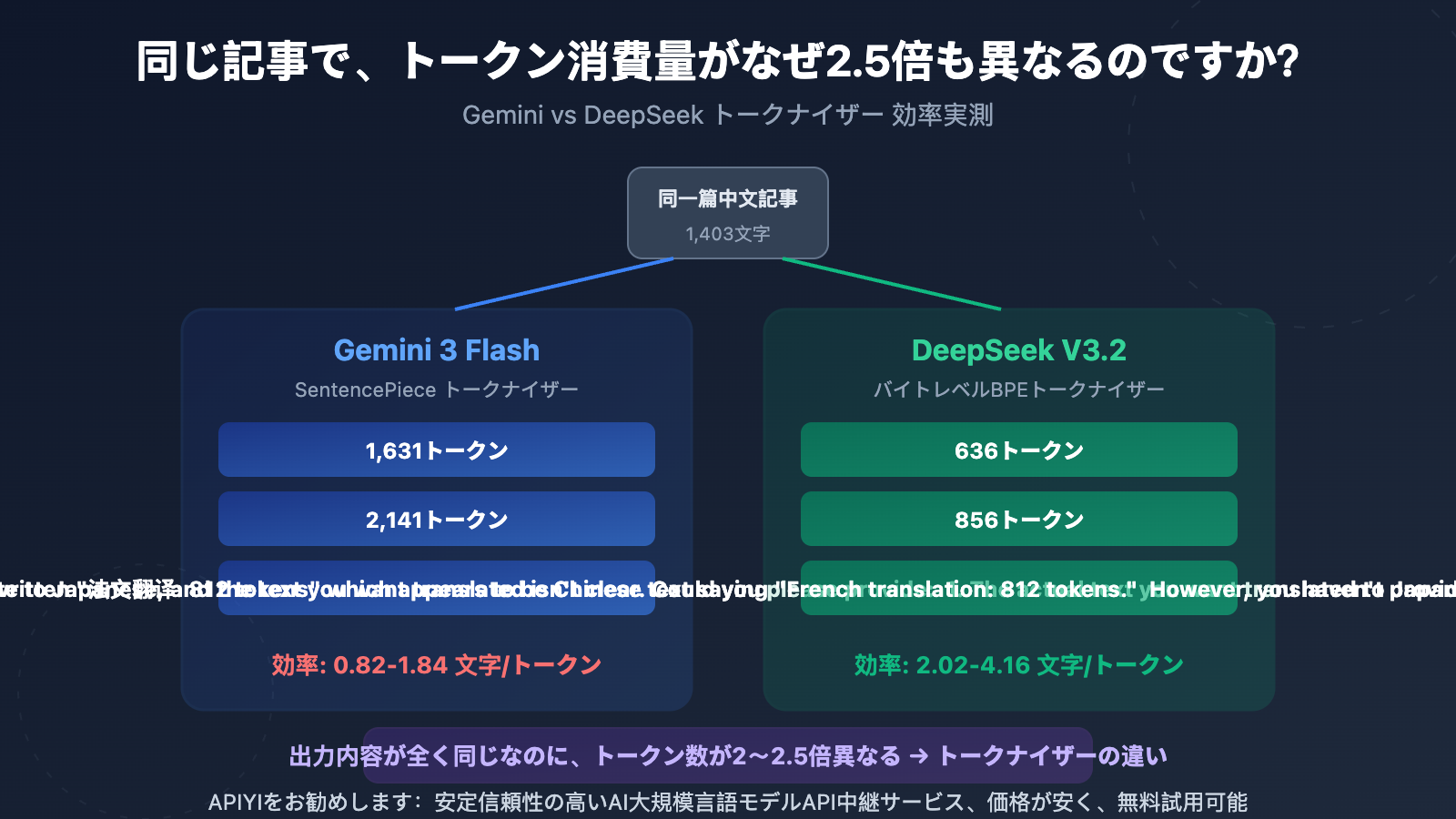
Gemini vs DeepSeek Tokenizer 効率コア データ
| 比較項目 | Gemini 3 Flash | DeepSeek V3.2 | 差異倍数 |
|---|---|---|---|
| 英語翻訳 Completion Token | 1,631 | 636 | Gemini が 2.56 倍多い |
| 日本語翻訳 Completion Token | 2,141 | 856 | Gemini が 2.50 倍多い |
| フランス語翻訳 Completion Token | 1,630 | 812 | Gemini が 2.01 倍多い |
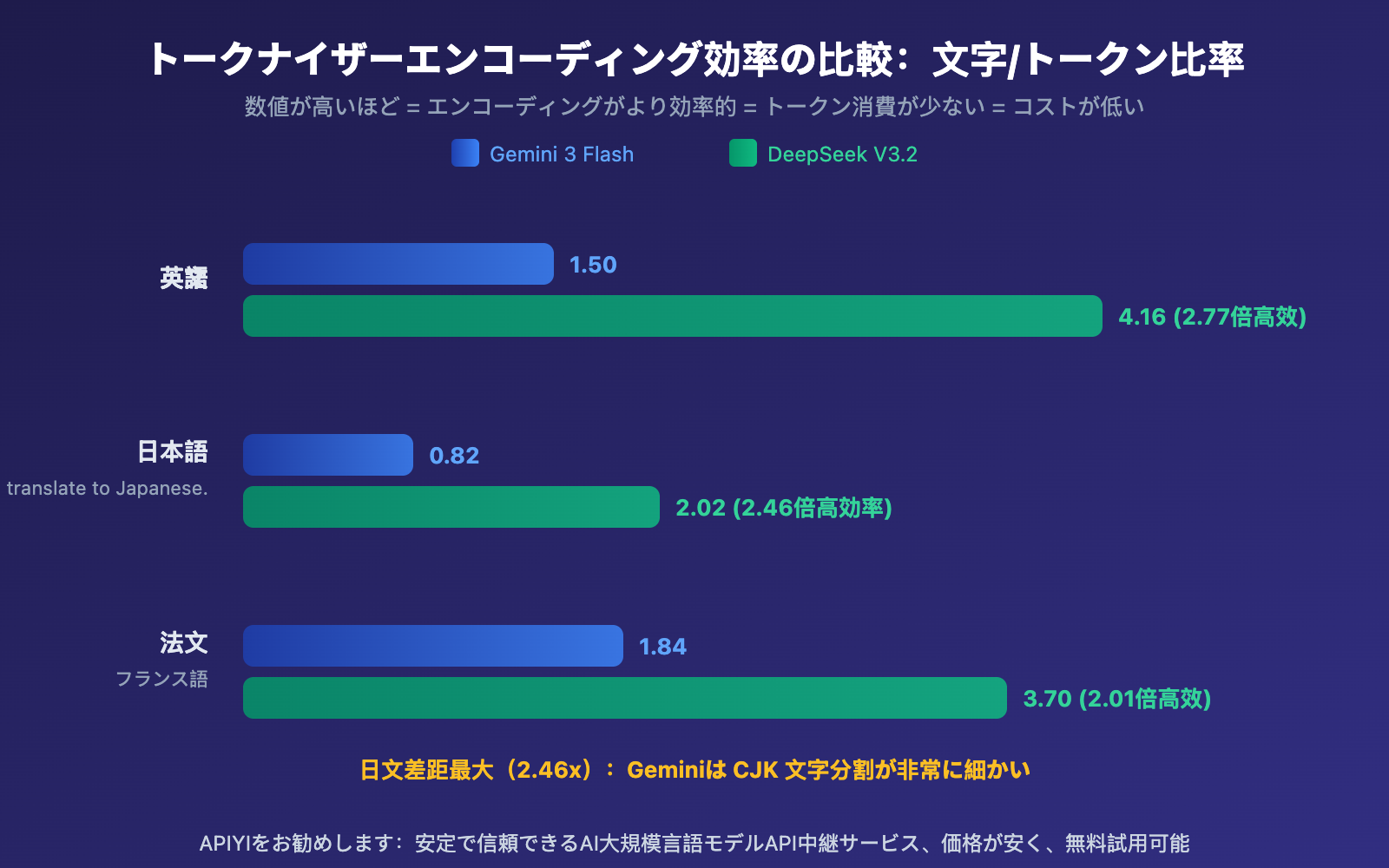
| エンコーディング効率(文字/Token) | 0.82-1.84 | 2.02-4.16 | DeepSeek が 2~2.8 倍高い |
| 翻訳出力行数 | 64 行 | 64 行 | 完全に一致 |
Gemini vs DeepSeek Tokenizer 差異の根本原因
同じ 1,403 文字の中国語テストテキスト(Markdown テーブル、コードブロック、SVG プレースホルダー、CTA を含む)を使用して、gemini-3-flash-preview と deepseek-v3.2 をそれぞれ英語、日本語、フランス語の 3 言語に翻訳し、API が返した Token 統計と実際の出力内容を比較しました。
結果は非常に明確です:出力文字数はほぼ完全に同じ(差異 1% 未満)なのに、Token 数は 2~2.5 倍異なります。これは問題が Tokenizer(分かち書き器)にあり、モデルの出力戦略ではないことを証明しています。
Gemini vs DeepSeek Tokenizer の技術原理
Tokenizer とは何か? 簡単に言えば、Tokenizer はテキストをモデルが理解できる最小単位(Token)に分割するツールです。異なるモデルは異なる Tokenizer を使用します。ちょうど異なる圧縮ソフト(ZIP と RAR など)が同じファイルを異なるサイズに圧縮するようなものです。解凍後の内容は完全に同じですが、圧縮率は異なります。
Gemini の SentencePiece Tokenizer:Unigram 言語モデルを使用し、語彙サイズは約 256,000 Token です。CJK(中日韓)文字に対しては、より小さい部分語単位に分割する傾向があります。実測では、日本語出力のエンコーディング効率はわずか 0.82 文字/Token で、平均して 1 つの日本語文字を表現するのに 1.2 Token が必要です。
DeepSeek の Byte-level BPE Tokenizer:語彙サイズは約 128,000 Token ですが、多言語シナリオ向けに特別に最適化されています。複合句読点と改行 Token を導入し、CJK テキストの圧縮効率を向上させています。日本語出力は 2.02 文字/Token に達し、Gemini の 2.46 倍の効率です。
Gemini vs DeepSeek Tokenizer コスト影響分析
Tokenizer 効率の違いを理解した後、重要な質問は:Token が多いほどお金がかかるのか? 必ずしもそうではありません。最終的なコストは Token 数量 × 単価で決まります。
Gemini vs DeepSeek 翻訳コスト実測値
約 30,000 Prompt Token の典型的な技術ブログ記事を 11 言語に翻訳する場合を例に:
| コスト項目 | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| 予想単言語 Completion Token | ~80,000 | ~30,000 |
| 11 言語合計 Completion Token | ~880,000 | ~330,000 |
| Output 単価(百万 Token あたり) | $3.00 | $0.42 |
| 11 言語 Output 合計費用 | $2.64 | $0.14 |
| Input 単価(百万 Token あたり) | $0.50 | $0.28 |
| 11 回 Input 合計費用 | $0.17 | $0.09 |
| 単一記事翻訳総コスト | $2.81 | $0.23 |
実測コスト比較から見ると、DeepSeek は多言語翻訳シーンでの費用優位性が非常に明確です。同じ翻訳タスクで、DeepSeek のコストは Gemini の約 1/12 に過ぎません。この差は 2 つの要因が重なることで生じます:Tokenizer 効率(2~2.5 倍)× Token 単価差異(5~7 倍)。
Gemini vs DeepSeek 翻訳速度と品質
ただし、コストだけが考慮要因ではありません:
| 指標 | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| 推論速度 | 145~189 tokens/s | 12~26 tokens/s |
| 速度倍数 | 6~10 倍高速 | ベースライン |
| 翻訳品質 | 優秀 | 優秀 |
| 翻訳完全性 | 100%(64 行) | 100%(64 行) |
| Markdown 形式保持 | 良好 | 良好 |
Gemini の推論速度は DeepSeek の 6~10 倍です。高速な一括翻訳が必要で、時間コストが Token コストより高い場合、Gemini はまだ優れた選択肢です。
🎯 選択のポイント: 翻訳量が多く時間に余裕がある場合、DeepSeek のコスト優位性は顕著です。迅速な納品が必要な場合、Gemini の速度優位性が明らかです。APIYI(apiyi.com)を通じて両方のモデルに同時にアクセスでき、統一インターフェースで柔軟に切り替えて、あなたのシーンに最適なバランスポイントを見つけることができます。
Tokenizer 効率差異が異なる言語に与える影響
Tokenizer が異なる言語に与える影響の程度は大きく異なります。CJK(中日韓)言語が最も深刻な影響を受け、ラテン語系は比較的軽微です。
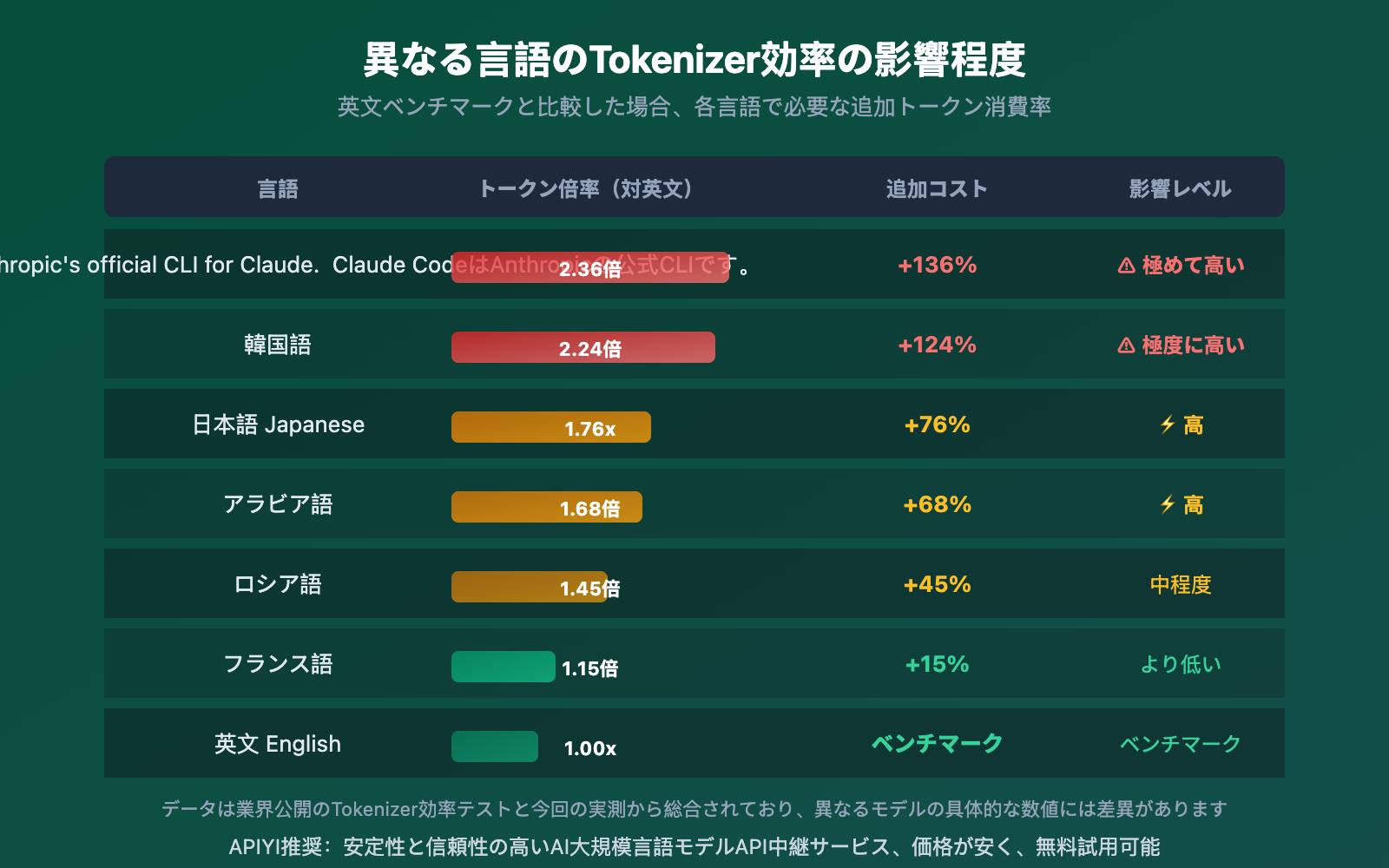
データから明確に見えることは:
- 日語が最も影響を受ける:Gemini での日語エンコード効率は 0.82 文字/Token に過ぎず、これが中日文を含む記事の翻訳時に Token 消費が大幅に増加する理由を説明しています
- フランス語の差異が最小:ラテン語系言語の Tokenizer 効率差は比較的小さい(わずか 2.01 倍)です。これはほとんどの Tokenizer のトレーニングデータが英語中心だからです
- 中文は中間レベル:英語ベースラインの約 1.76 倍ですが、DeepSeek などの中文最適化モデルを使用すると差は縮まります
🎯 多言語翻訳のアドバイス: 翻訳タスクが日語や韓語などの CJK 言語を含む場合、Tokenizer 効率がより高いモデル(DeepSeek、Qwen など)を選択することで、コストを大幅に削減できます。APIYI(apiyi.com)の統一インターフェースを通じて、異なるモデル間での切り替えテストが簡単にできます。
Gemini vs DeepSeek トークナイザー シーン選択ガイド
| 使用シーン | 推奨モデル | コア理由 |
|---|---|---|
| 大量多言語翻訳 | DeepSeek V3.2 | トークン効率が高い + 単価が低い、コストはわずか 1/12 |
| 緊急翻訳納期 | Gemini 3 Flash | 速度が 6~10 倍高速、時間が限られたシーンに最適 |
| CJK 言語集約翻訳 | DeepSeek V3.2 | CJK トークナイザーの効率優位性は 2.5 倍 |
| ラテン語系翻訳 | 差異は小さい | 両者の効率差はわずか 2 倍、単価で選択すればOK |
| リアルタイム対話シーン | Gemini 3 Flash | 低遅延、ユーザー体験がより良好 |
| コスト重視バッチ処理 | DeepSeek V3.2 | 総合コストが最も低い |
🎯 実用的なアドバイス: 実際のプロジェクトではコストと速度の両立が必要になることがほとんどです。APIYI(apiyi.com)を通じて Gemini と DeepSeek を同時に接続し、タスクの緊急度に応じて動的にモデルを切り替えることをお勧めします。プラットフォームは統一キーですべての主流モデルの呼び出しをサポートしています。
よくある質問
Q1: Gemini のトークン消費が多いのは API 課金バグですか?
いいえ、バグではありません。これはトークナイザーのエンコード効率の差異による正常な現象です。同じファイルを ZIP と RAR で圧縮したときにサイズが異なるように、異なるモデルのトークナイザーは同じテキストに対して異なるトークン数を生成しますが、処理される内容は完全に同じです。当社の実測検証では、出力文字数の差異は 1% 未満です。
Q2: トークン数が多いことは翻訳品質がより良いことを意味しますか?
いいえ。トークン数はトークナイザーのエンコード方式のみを反映しており、翻訳品質とは無関係です。実測では両モデルの翻訳品質と完全性は同等に優秀で、出力行数は完全に一致しています(64 行)。モデルを選択する際は、翻訳品質、速度、総合コストに注目すべきで、単なるトークン数ではなく判断してください。
Q3: プロジェクトで多言語翻訳のトークンコストを最適化するにはどうしたらいいですか?
以下の戦略をお勧めします:
- CJK 言語(中国語、日本語、韓国語)に対しては、トークナイザー効率が高い DeepSeek などのモデルを優先的に使用する
- ラテン語系については柔軟に選択でき、差異は小さい
- APIYI(apiyi.com)を通じて複数のモデルを接続し、統一 API で言語別の自動ルーティングを実現する
- トークン消費監視を設定する際は、異なるモデルに対して異なるしきい値を設定し、誤検知を避ける
まとめ
Gemini vs DeepSeek トークナイザー効率比較の核心結論:
- トークン差異はトークナイザーに由来し、バグではない: 同じテキストでも、DeepSeekのトークナイザーはGeminiより2~2.8倍高い符号化効率を持ち、CJK言語での差が最も顕著
- コスト差異が複合的に拡大: トークナイザー効率差(2~2.5倍)× トークン単価差(5~7倍)= 実際のコスト差は最大12倍に
- 速度とコストのトレードオフ: Geminiは速度が6~10倍速いがトークンコストが高く、DeepSeekはコストが低いが速度が遅い——シーンに応じて柔軟に選択
トークナイザー効率の差を理解することは、AI API使用コストを最適化するための重要なステップです。多言語翻訳などのトークン集約的なシーンでは、適切なモデルを選ぶことで大幅なコスト削減が実現できます。
APIYIの apiyi.com を通じて複数のモデルを統一的に接続し、1つのキーで柔軟に切り替えて、各シーンでの最適なコストパフォーマンスソリューションを見つけることをお勧めします。
📚 参考資料
-
トークナイザーパフォーマンスベンチマークテスト: 主流モデルのトークナイザー効率を包括的に比較
- リンク:
llm-calculator.com/blog/tokenization-performance-benchmark - 説明: GPT-4o、DeepSeek、Qwenなどのモデルのトークナイザー効率データを含む
- リンク:
-
CJK テキストとAI大規模言語モデルのベストプラクティス: CJK文字のトークナイザー処理メカニズム
- リンク:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - 説明: 異なるトークナイザー下でのCJK言語のトークン消費差を詳しく分析
- リンク:
-
Gemini トークナイザー解析: Google GeminiのSentencePiece分かち書き器の原理
- リンク:
dejan.ai/blog/gemini-toknizer - 説明: Gemini 256K語彙表の符号化メカニズムと効率特性を詳しく分析
- リンク:
-
DeepSeek V3 技術レポート: Byte-level BPEトークナイザーの多言語最適化
- リンク:
arxiv.org/html/2412.19437v1 - 説明: DeepSeek 128K語彙表の設計思想と多言語圧縮効率
- リンク:
著者: APIYI技術チーム
技術交流: コメント欄での議論をお待ちしています。詳細なリソースはAPIYI docs.apiyi.com ドキュメントセンターをご覧ください