Prompt Caching is arguably the most critical cost-related topic for every Large Language Model API user in 2026. For a RAG application running an 8K system prompt, the difference in monthly bills between having caching enabled and disabled can easily exceed 10x. However, many developers switching between OpenAI and Anthropic get tripped up by a hidden detail: the two companies use completely different billing models for caching.

The most crucial difference boils down to one point: GPT series cache writes are billed at 1x the base price with no premium, while Claude series cache writes incur a 1.25x (5-minute) or 2x (1-hour) premium. This might seem minor, but in real-world production traffic, it significantly impacts your break-even point. In this article, we've cross-referenced official documentation to break down billing rules, trigger conditions, read discounts, TTL strategies, and ROI calculations to help you make more accurate cost estimates.
5 Core Differences Between GPT and Claude Prompt Caching
Let's get straight to the point. The table below is the most valuable part of this article; it highlights the 5 most overlooked key points in caching for both providers, making it easy to compare.
| Dimension | OpenAI GPT | Anthropic Claude |
|---|---|---|
| Write Billing | 1x base price, no premium | 5min: 1.25x; 1h: 2x |
| Read Billing | ~0.1x (up to 90% discount) | 0.1x (price after 10% discount) |
| Trigger Method | Fully automatic, no code changes | Explicit opt-in, requires cache_control |
| Min Token Threshold | Uniform 1024 tokens | 1024 / 2048 / 4096 (varies by model) |
| Cache TTL | Default 5–10 min idle, max 1 hour; extended mode 24 hours | Default 5 minutes, optional 1 hour (2x write) |
The key to understanding this table is the "Write Billing" row. OpenAI's logic is: caching is free for you—the first write is charged at the base price, and subsequent hits are discounted. Therefore, as long as you have at least one hit, you immediately enter the profit zone. Claude's logic is: you pay a premium for the write first, and then receive a discount on hits. You need "enough hits" to recoup that premium.
🎯 Configuration Advice: If your business traffic is unpredictable or hit rates are unstable, we recommend prioritizing GPT's automatic caching mechanism to reduce risk. If your hit rates are very stable (e.g., customer service, Agents, long document analysis), Claude's explicit control can actually squeeze out higher discounts. Both model APIs are available on APIYI (apiyi.com), allowing you to perform comparative testing within a single token without needing to manage multiple accounts.
A Detailed Breakdown of OpenAI GPT Prompt Caching Billing
OpenAI's official documentation describes Prompt Caching quite simply: "Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature." In other words: it's automatic, costs nothing extra, and requires zero code changes.
GPT Caching: Write and Read Billing
GPT models don't charge a premium for writing to the cache. When you send an 8K system prompt for the first time, you're charged the base input price—exactly the same as if caching were disabled. From the second request onwards, if the system identifies that this prefix has been cached, it charges for the hit portion at a discount of approximately 90% off the base price.
| Item | Billing Method | Ratio to Base Price |
|---|---|---|
| Initial Cache Write | Base input price | 1x (no premium) |
| Cache Hit Read | Cache hit discount | ~0.1x |
| Activation Fee | Completely free | 0 |
| Code Changes | Zero | None required |
The actual discount is officially stated as "up to 90%," which varies slightly depending on the model and pricing table. For example, GPT-5.4 has a base input price of $2/1M tokens, and a cache hit price of $0.20/1M tokens, which is exactly 10%. Supported models like GPT-4.1 and GPT-4o generally follow this ratio.
🎯 Price Verification: Since OpenAI models update frequently, always refer to the official pricing table for the actual discounted rates. We recommend checking the current effective prices in the Model Plaza on APIYI (apiyi.com). The platform syncs with official adjustments, charges no additional proxy fees, and developers simply settle based on actual token usage.
GPT Caching Hit Conditions
To trigger a cache hit, two conditions must be met simultaneously:
- The prompt length must be ≥ 1024 tokens (shorter prompts won't be cached).
- The prefix of the prompt must be identical to a previous request, with hits processed in 128-token increments.
OpenAI sets the minimum granularity for cache hits at 128 tokens. This means for a stable prefix of 1500 tokens, as long as the first 1024 tokens match, the remaining part will be cached incrementally in 128-token chunks. The trade-off for this automated design is less control—developers cannot explicitly specify "which part must be cached" and must ensure all stable content is placed at the beginning.
GPT Caching TTL Behavior
OpenAI provides a crucial detail regarding TTL: cached prefixes are typically reclaimed after 5–10 minutes of inactivity, with a maximum retention of 1 hour. Newer models like GPT-5 and GPT-4.1 also support "extended retention," which can last up to 24 hours.
🎯 Usage Tip: When accessing the GPT series via APIYI (apiyi.com), OpenAI's automatic caching strategy is transparent to the API proxy service, meaning hit rates are identical to connecting directly to official endpoints. This allows you to manage your OpenAI and Claude billing and tokens centrally via APIYI without incurring any extra costs.
A Detailed Breakdown of Anthropic Claude Prompt Caching Billing
Claude’s design philosophy is the exact opposite of OpenAI's—it treats caching as an "actively configurable optimization capability." Developers must explicitly declare what content to cache and for how long. The trade-off is that writing incurs a premium, but the reward is extremely high control.
Claude Caching: Write Premiums and Read Discounts
| Item | Billing Multiplier | Description |
|---|---|---|
| 5-minute Write | 1.25x base input price | Default TTL, covers most scenarios |
| 1-hour Write | 2x base input price | Suitable for long sessions, Agents, etc. |
| Cache Hit Read | 0.1x base input price | 90% discount |
| Activation Fee | 0 | No extra setup fee |
| Configuration Changes | Must add cache_control |
Explicit opt-in |
For a concrete example: Claude Opus 4.7 has a base input price of $5/1M tokens. A 5-minute write costs $6.25/1M, a 1-hour write costs $10/1M, and a cache hit read costs only $0.50/1M. This pricing table has been documented in Anthropic's official docs for several quarters.
Claude Caching: Minimum Token Thresholds
Claude's minimum cacheable token count varies by model, which is the first pitfall many users encounter.
| Model | Minimum Cacheable Tokens |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
If your stable prefix is below the model's minimum threshold, even if you add cache_control, it won't actually enter the cache layer. The request will be silently treated as a non-cached path—no error will be thrown, but you'll be operating without the cache you thought you enabled. This is especially important for Opus 4.7: 4096 tokens is a significant hurdle, and short conversation scenarios will rarely benefit from it.
🎯 Model Selection Advice: If your business context length is unstable, we recommend prioritizing Claude Sonnet 4.5 or 4.6, as they have lower thresholds and are easier to hit. You can switch between Sonnet and Opus with one click via APIYI (apiyi.com) to avoid having your caching strategy rendered ineffective due to model thresholds.
Claude Caching: Breakpoints and Concurrency Limits
Claude allows you to set up to 4 cache breakpoints in a single request, with different TTLs for different breakpoints. This is Claude's most powerful feature compared to GPT—you can have "system prompts" cached for 1 hour, "knowledge base snippets" for 5 minutes, and "user context" not cached at all, with each section billed and expiring independently.
In concurrent scenarios, note that Claude's cache entries only become effective for other requests after the first response begins returning. If you send N identical requests in parallel, only the first one will write to the cache, and the remaining N-1 will still be billed at the base price without the hit discount. Therefore, for batch calls, you should send a "warm-up" request first to trigger the cache write before firing off the remaining parallel requests.
🎯 Batch Calling Advice: When calling Claude via APIYI (apiyi.com), we recommend sending a single "warm-up" request to trigger the cache write before initiating your concurrent batch. Once the response begins, you can proceed with the parallel requests to avoid unnecessary write premiums and save significantly on your budget.
The Impact of Write Premiums on Real Bills: Calculating the Break-Even Point
In this section, we'll convert abstract multipliers into actual dollar amounts. Let's assume a stable system prompt of 10,000 tokens is requested N times within a 1-hour window, with a uniform output of 500 tokens. We'll compare the total costs for both providers at different values of N.
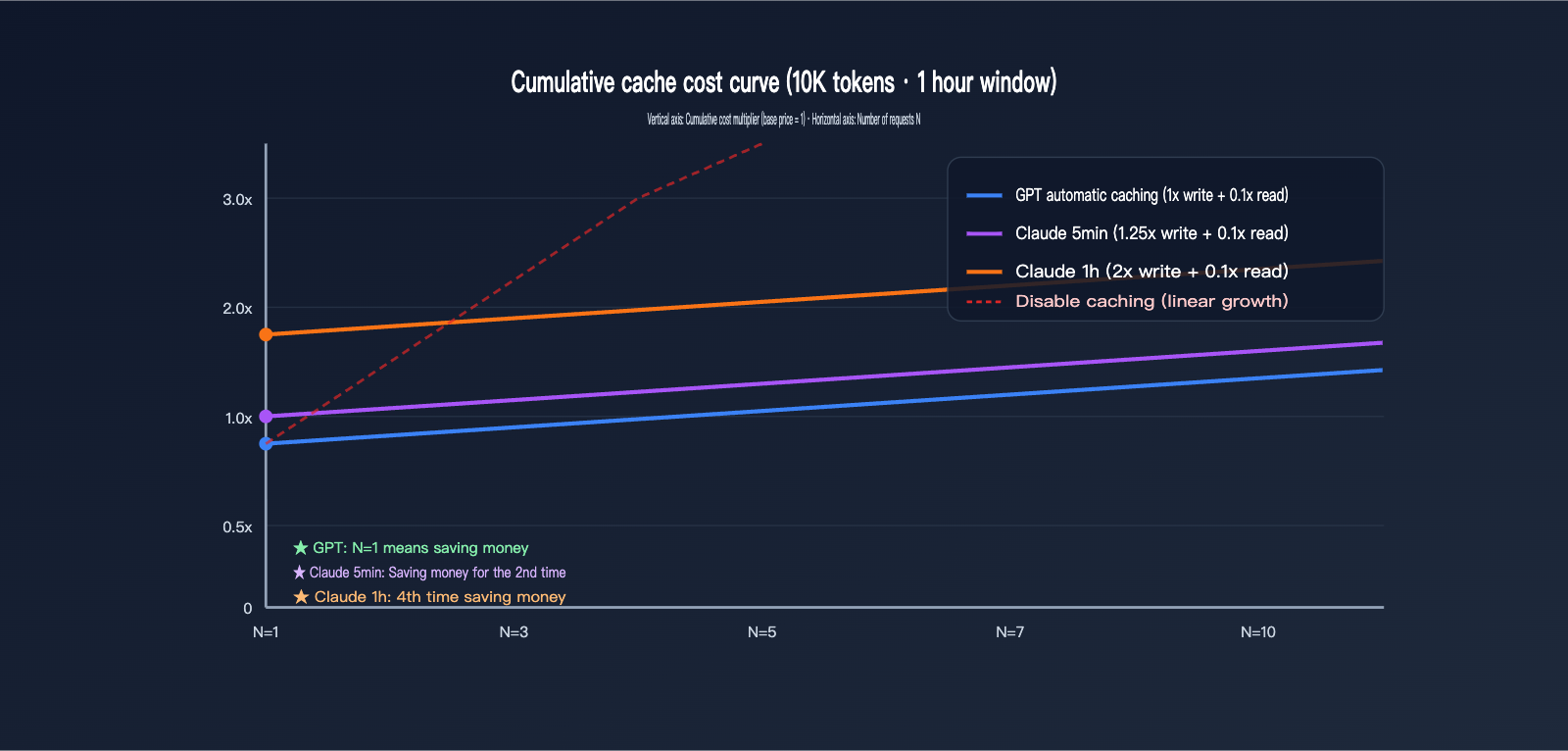
For comparison, let's assume the base input price for both is normalized to $X/1M tokens. The base cost for a single 10,000-token request = 10 × $X / 1000 = $0.01X. We'll focus only on the input caching billing, ignoring output (which is calculated at each provider's standard rate).
| Request Count (N) | GPT Auto-Cache | Claude 5min Cache | Claude 1h Cache |
|---|---|---|---|
| N=1 (First write) | $0.01X | $0.0125X | $0.02X |
| N=2 | $0.011X | $0.0135X | $0.021X |
| N=5 | $0.014X | $0.0165X | $0.024X |
| N=10 | $0.019X | $0.0215X | $0.029X |
| No Cache (Ref) | $0.01X × N | $0.01X × N | $0.01X × N |
| Hits to Break Even | 0 (Saves from 1st) | 1 (Saves from 2nd) | 3 (Saves from 4th) |
A key fact emerges: GPT caching is never a loss, even at N=1—because the write is charged at 1x and you get a discount on hits, it's always a win. Claude's 5-minute cache requires at least 1 hit to offset the 0.25x write premium, while the 1-hour cache requires 3 hits. If your stable prefix only hits once a day, using Claude's 1-hour cache is actually more expensive than not caching at all.
How to Choose TTL for Real-World Business
This calculation provides clear practical advice:
- Low/Irregular Frequency: Prioritize GPT auto-caching; it's a no-brainer for savings.
- High Frequency, Multiple Hits within 5 Minutes (e.g., customer service chats, Web apps): Claude's 5-minute cache maximizes gains with a small write premium and deep read discounts.
- Long Tasks, Reused across Hours (e.g., Coding Agents, long document dialogues): Claude's 1-hour cache is worth it, provided you hit at least 3 times.
- Uncertain Hit Rate: Always start with 5 minutes; consider switching to 1 hour only after verifying performance.
🎯 Calculation Tip: The APIYI (apiyi.com) dashboard provides
cached_tokensstatistics per request, allowing you to see your actual hit rate directly. We recommend running production traffic for a week before deciding whether to aggressively set your TTL to 1 hour.
Recommended Caching Strategies for Different Business Scenarios
Once you understand the billing differences, you can apply them to your specific business. Here are the recommended strategies for common scenarios.
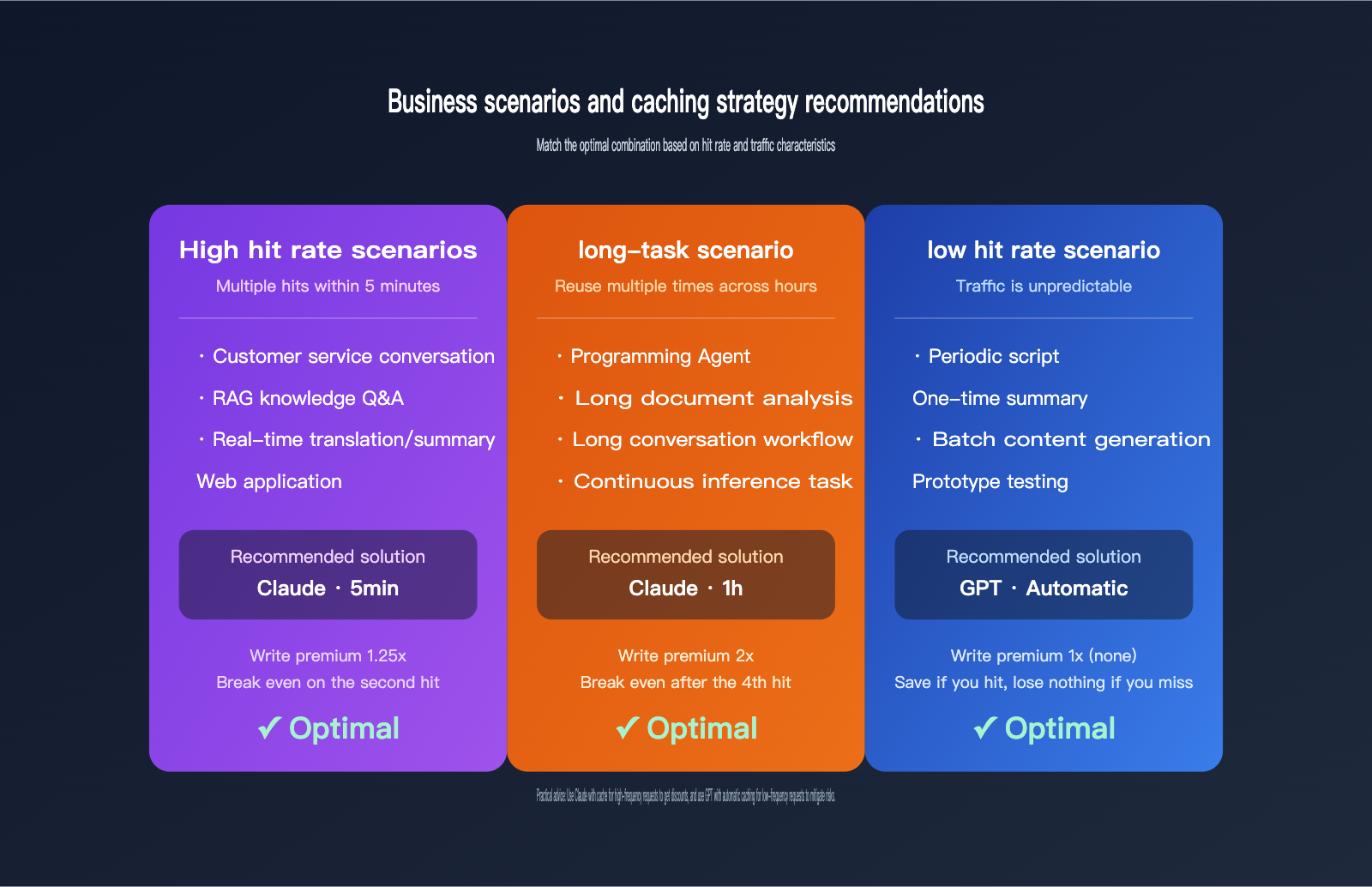
Scenario 1: High-Frequency RAG and Enterprise Knowledge Q&A
In these scenarios, the stable prefix usually includes system prompts + knowledge base snippets. Multiple hits occur within a single session, and cumulative requests easily exceed 10 within 5 minutes. Claude's 5-minute cache can reduce input costs by over 80% here, making it the most cost-effective choice. For 1-hour long sessions, consider the 1-hour cache.
Scenario 2: Programming Agents and Long-Task Workflows
For coding agents like Claude Code or OpenCode, a single task might last for half an hour or even several hours, during which the agent repeatedly reads project structures, CLAUDE.md, and previous tool call results. In this scenario, Claude's 1-hour cache is the optimal solution because the number of hits far exceeds the 3-hit break-even point.
Scenario 3: Low-Frequency or Unpredictable Requests
For tasks like periodic scripts, batch SEO article generation, or one-off long document summaries, the interval between requests may far exceed 5 minutes. We recommend prioritizing the GPT series with auto-caching; if it hits, you save money, and if it doesn't, you don't lose anything. It's much more fault-tolerant than Claude's explicit caching.
Scenario 4: Cost-Sensitive Pure Input Compression
If your core goal is to minimize the cost of 10K+ token prompts, we recommend using Claude Sonnet 4.6 + 5-minute cache: the write premium is only 25%, and you only need 1 hit to break even, bringing the read price down to $0.075/1M (base $3 × 0.025).
| Business Scenario | Recommended Model Family | Recommended TTL | Reason |
|---|---|---|---|
| CS/RAG/Instant Q&A | Claude Sonnet | 5 Minutes | Frequent hits, fast break-even |
| Coding/Long Agent Tasks | Claude Sonnet/Opus | 1 Hour | >3 hits across hours |
| Periodic Scripts/Batch | GPT-4.1 / GPT-5.x | Auto | Unstable hits, zero write premium |
| One-off Long Doc Analysis | GPT-5.x | Auto | Single task, low hit rate |
| Pure Cost-Sensitive | Claude Sonnet 4.6 | 5 Minutes | Lowest effective cache price |
🎯 Hybrid Architecture Suggestion: In production, GPT and Claude aren't mutually exclusive; they should be paired based on the scenario. We recommend using APIYI (apiyi.com) as a single entry point to access both, dynamically routing traffic based on business needs: high-hit traffic goes to Claude with caching, while low-hit traffic goes to GPT with auto-caching, potentially reducing your overall bill by over 40%.
FAQ
Q1: Does GPT really not charge a premium for cache writes? Is it hidden in some other fee?
Yes, according to OpenAI's official documentation: "No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature." Cache writes are billed at the standard input price without any hidden premiums. You only pay the discounted rate for the hits, while misses are charged at the base rate, effectively giving you the caching feature for free.
Q2: Does Claude's 1.25x or 2x write premium apply to the entire prompt or just the cached portion?
It only applies to the parts marked for caching via cache_control. For example, if only 8K of a 10K prompt is marked for caching, the 1.25x premium only applies to that 8K, while the remaining 2K is charged at the 1x base rate. We recommend setting breakpoints precisely to avoid incurring unnecessary premiums on content that doesn't need to be cached.
Q3: Does the APIYI API proxy service pass through the caching billing for both providers?
APIYI (apiyi.com) provides native pass-through for both GPT and Claude caching billing. The hit discounts for GPT's automatic caching and the 1.25x/2x write and 0.1x read premiums for Claude's explicit caching are identical to the official billing. The cache_control field is also supported, so developers can reuse their official SDK code directly.
Q4: When is using Claude's 1-hour cache actually more expensive than not using it at all?
When the actual hit count within the 1-hour window is less than 3, the premium for the 1-hour cache (2x write) cannot be amortized. For example, if a prompt is only requested twice a day—once when the user starts and once when they exit—using the 1-hour cache will cost 1x more in write premiums than not using it at all. In such scenarios, it's better to switch to a 5-minute cache or disable it entirely.
Q5: Will GPT's automatic caching leak my prompt data?
OpenAI's documentation clearly states that caching is isolated at the organization level and is not shared across accounts. As of February 5, 2026, Claude has further tightened this to workspace-level isolation. Both companies have consistent commitments to data security, so enterprise users can use these features with confidence. When accessing via APIYI (apiyi.com), token-level isolation further strengthens this protection.
Q6: How can I monitor cache hit rates? Do both providers expose fields for this?
OpenAI returns the cached_tokens field in the usage object, while Claude returns cache_creation_input_tokens and cache_read_input_tokens in its usage object. The former represents the write volume, and the latter represents the hit volume. We recommend logging these fields to build a hit-rate dashboard before adjusting your TTL strategy.
Q7: If my project uses both GPT and Claude, how should I configure my tokens?
We recommend using the unified token solution from APIYI (apiyi.com), which allows a single sk-xxx key to cover both GPT and Claude. You can view billing by model in the backend, avoiding the hassle of managing separate accounts, balances, and reconciliation for each provider. This unified access also makes A/B testing easier, allowing you to compare the actual costs of both models for the same business use case.
Conclusion: Understanding Write Premiums is the First Step to Cache Optimization
Returning to the core point of this article: The fundamental difference in caching billing between GPT and Claude lies in the write-side premium model. GPT opts for "zero-friction automatic activation with no write premium," while Claude chooses "explicit control, trading write premiums for more granular discount opportunities." Neither approach is strictly better; the key is matching them to your business traffic patterns.
If your application involves high hit rates, stable traffic, and requires fine-grained control, Claude's 1.25x/2x write premiums can be easily amortized through high hit rates, and its dual 5min/1h TTLs offer flexibility that GPT lacks. If your application involves low hit rates, bursty traffic, and you prioritize out-of-the-box simplicity, GPT's zero-premium automatic caching model is the safest choice.
🎯 Final Recommendation: The best practice for cost optimization is not to choose one over the other. We recommend using APIYI (apiyi.com) to access both models and routing traffic based on your business scenarios—use Claude for high-frequency tasks to squeeze out discounts, and GPT for low-frequency tasks to avoid unnecessary premiums. One token, one bill, and easy comparison—this is the most efficient cost management strategy for technical teams in 2026.
— APIYI Technical Team | Continuously tracking Large Language Model billing dynamics. For more in-depth comparisons, visit the APIYI (apiyi.com) Help Center.