Nota do Autor: Dados reais revelam a razão fundamental pela qual Gemini e DeepSeek consomem 2-2.5x mais tokens ao traduzir o mesmo artigo — diferenças na eficiência do Tokenizer, com dicas de otimização de custos para cenários multilíngues
O mesmo artigo em chinês, traduzido separadamente com Gemini e DeepSeek para inglês, japonês e francês, apresenta qualidade e completude de tradução idênticas — mas o Completion Token retornado pela API diferencia em 2-2.5 vezes. É um bug na cobrança da API? Ou há uma razão técnica mais profunda?
Valor central: através de dados de testes reais, ajuda você a entender como as diferenças do Tokenizer impactam os custos da API e dominar o método para escolher o modelo com melhor custo-benefício em cenários de tradução multilíngue.
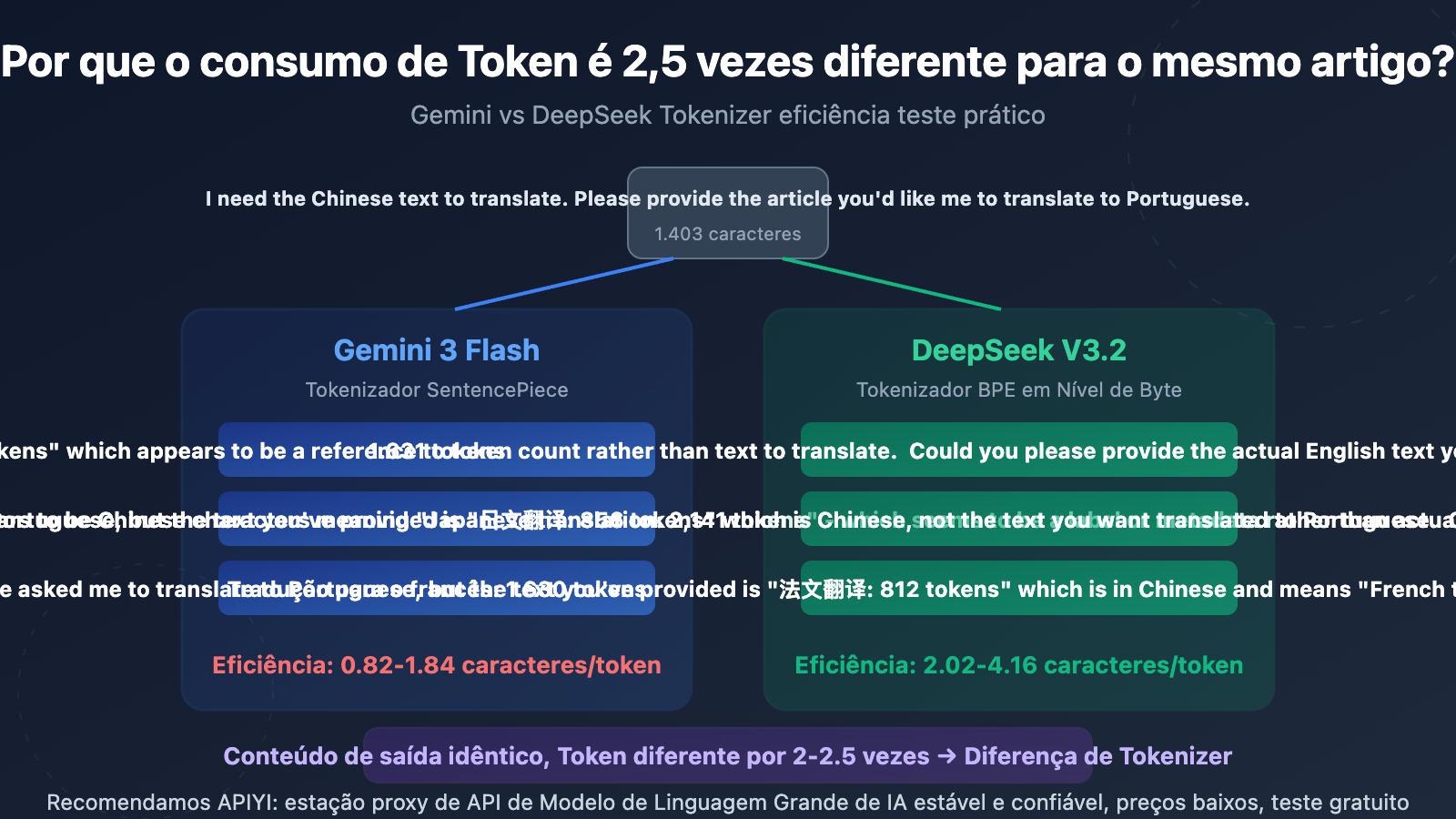
Dados principais de eficiência do Tokenizer: Gemini vs DeepSeek
| Dimensão de comparação | Gemini 3 Flash | DeepSeek V3.2 | Múltiplo de diferença |
|---|---|---|---|
| Completion Token – Tradução para inglês | 1.631 | 636 | Gemini 2,56x maior |
| Completion Token – Tradução para japonês | 2.141 | 856 | Gemini 2,50x maior |
| Completion Token – Tradução para francês | 1.630 | 812 | Gemini 2,01x maior |
| Eficiência de codificação (caracteres/Token) | 0,82-1,84 | 2,02-4,16 | DeepSeek 2-2,8x superior |
| Linhas de saída da tradução | 64 linhas | 64 linhas | Completamente idêntico |
A razão fundamental por trás da diferença de Tokenizer entre Gemini e DeepSeek
Usamos o mesmo texto de teste com 1.403 caracteres em chinês (incluindo tabelas Markdown, blocos de código, espaços reservados SVG e CTA), chamando separadamente gemini-3-flash-preview e deepseek-v3.2 para traduzir para inglês, japonês e francês em 3 idiomas, depois comparamos as estatísticas de Token retornadas pela API e o conteúdo real da saída.
O resultado é muito claro: o número de caracteres de saída é quase idêntico (diferença inferior a 1%), mas o número de Token diferencia em 2-2,5 vezes. Isso prova que o problema está no Tokenizer (divisor de palavras), não na estratégia de saída do modelo.
Os princípios técnicos por trás da diferença de Tokenizer entre Gemini e DeepSeek
O que é um Tokenizer? Simplificando, um Tokenizer é uma ferramenta que divide o texto em unidades mínimas que o modelo consegue entender (Tokens). Diferentes modelos usam Tokenizers diferentes, assim como diferentes softwares de compressão — o mesmo arquivo, comprimido com ZIP e RAR, terá tamanhos diferentes, mas o conteúdo descompactado é exatamente o mesmo.
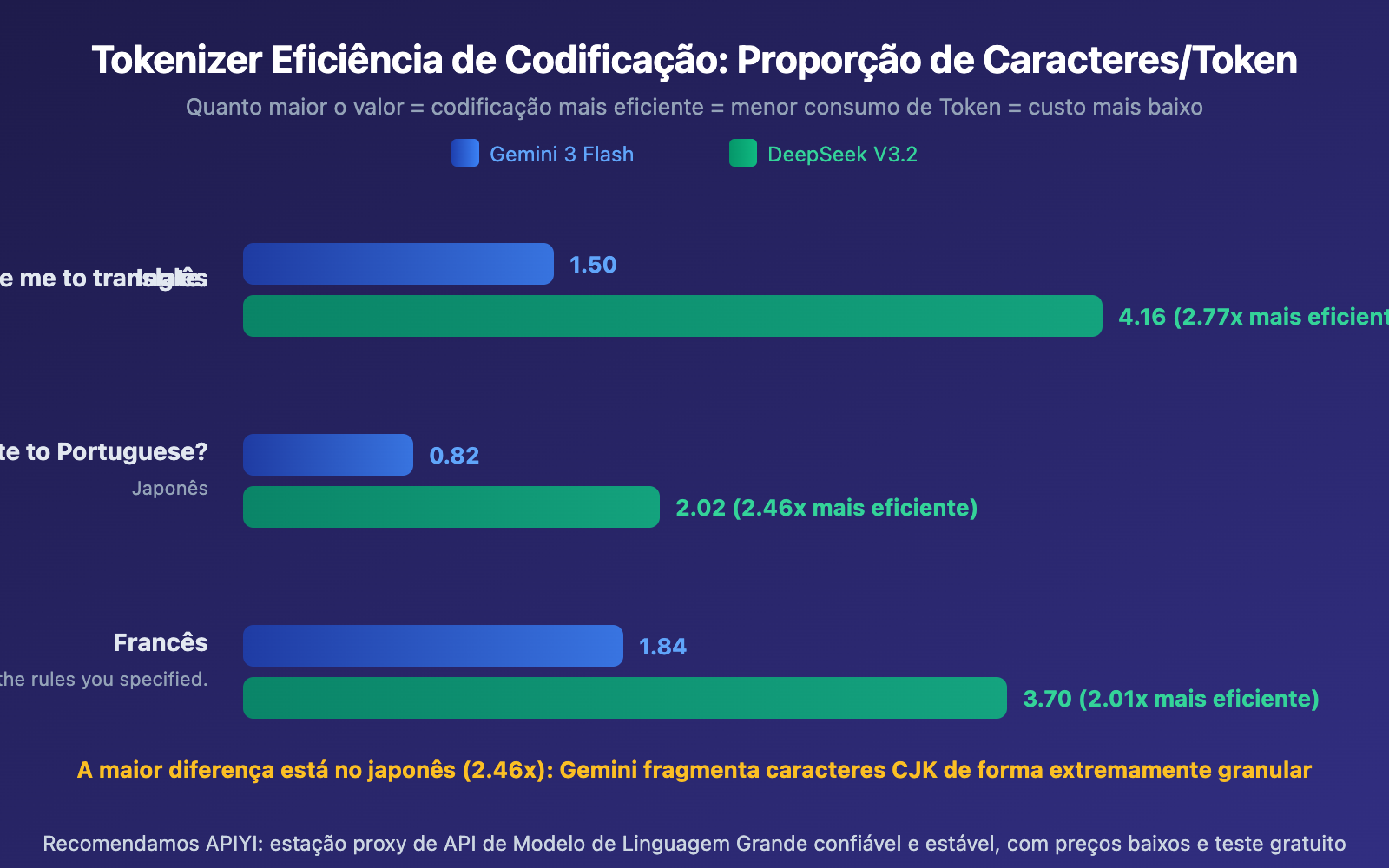
Tokenizer SentencePiece do Gemini: usa um modelo de linguagem Unigram, com tamanho de vocabulário de aproximadamente 256.000 Tokens. Tende a dividir caracteres CJK (chinês, japonês, coreano) em unidades de subpalavras ainda menores. Nos testes, a eficiência de codificação da saída em japonês foi apenas 0,82 caracteres/Token, o que significa que em média cada caractere japonês precisa de 1,2 Tokens para ser representado.
Tokenizer BPE em nível de byte do DeepSeek: tamanho de vocabulário de aproximadamente 128.000 Tokens, mas foi especialmente otimizado para cenários multilíngues. Introduz Tokens de pontuação combinada e quebra de linha, melhorando a eficiência de compressão de texto CJK. A saída em japonês atingiu 2,02 caracteres/Token, uma eficiência 2,46 vezes superior à do Gemini.
Gemini vs DeepSeek Tokenizer – Análise de Impacto de Custos
Depois de entender as diferenças de eficiência do Tokenizer, a pergunta-chave é: mais Tokens sempre significam gastar mais dinheiro? Não necessariamente. O custo final depende de Número de Tokens × Preço Unitário.
Custo Real de Tradução: Gemini vs DeepSeek
Tomando como exemplo a tradução de um artigo técnico típico (cerca de 30.000 Prompt Tokens) para 11 idiomas:
| Dimensão de Custo | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Completion Token Estimado por Idioma | ~80.000 | ~30.000 |
| Total de Completion Tokens para 11 Idiomas | ~880.000 | ~330.000 |
| Preço de Output (por milhão de Tokens) | $3.00 | $0.42 |
| Custo Total de Output para 11 Idiomas | $2.64 | $0.14 |
| Preço de Input (por milhão de Tokens) | $0.50 | $0.28 |
| Custo Total de Input para 11 Idiomas | $0.17 | $0.09 |
| Custo Total de Tradução por Artigo | $2.81 | $0.23 |
Pelos testes de custo realizados, a vantagem do DeepSeek em cenários de tradução multilíngue é muito evidente — para a mesma tarefa de tradução, o custo do DeepSeek é apenas cerca de 1/12 do Gemini. Essa diferença resulta da combinação de dois fatores: eficiência do Tokenizer (2-2,5x) × diferença de preço por Token (5-7x).
Velocidade e Qualidade de Tradução: Gemini vs DeepSeek
Mas o custo não é o único fator a considerar:
| Métrica | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Velocidade de Inferência | 145-189 tokens/s | 12-26 tokens/s |
| Múltiplo de Velocidade | 6-10x mais rápido | Baseline |
| Qualidade de Tradução | Excelente | Excelente |
| Completude da Tradução | 100% (64 linhas) | 100% (64 linhas) |
| Preservação de Formato Markdown | Bom | Bom |
A velocidade de inferência do Gemini é 6-10 vezes maior que a do DeepSeek. Se você precisa de tradução em lote rápida e o custo de tempo é superior ao custo de Tokens, o Gemini continua sendo a melhor escolha.
🎯 Recomendação de Escolha: Se o volume de tradução é grande e você não tem pressa, a vantagem de custo do DeepSeek é significativa. Se precisa de entrega rápida, a vantagem de velocidade do Gemini é evidente. Através da APIYI em apiyi.com, você pode integrar ambos os modelos simultaneamente e usar uma interface unificada para alternar com flexibilidade, encontrando o ponto ótimo para seu cenário.
Impacto das Diferenças de Tokenizer em Diferentes Idiomas
O Tokenizer tem um impacto muito diferente em idiomas distintos. Idiomas CJK (chinês, japonês, coreano) são os mais afetados, enquanto idiomas latinos são relativamente menos impactados.
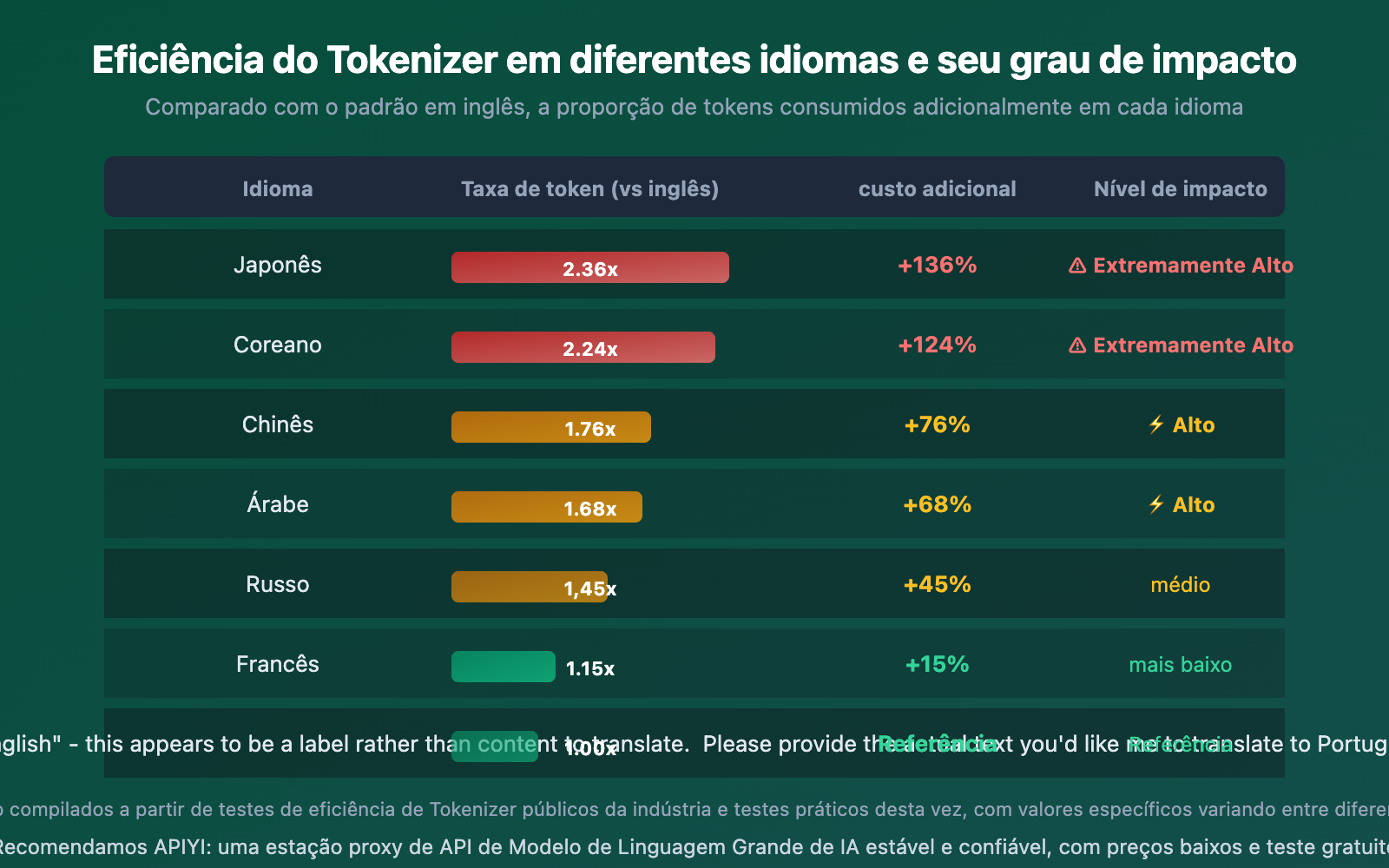
Os dados deixam claro:
- Japonês é o mais afetado: A eficiência de codificação do japonês no Gemini é apenas 0,82 caracteres/Token, o que explica por que o consumo de Tokens aumenta significativamente ao traduzir artigos com muito conteúdo em chinês e japonês
- Francês tem a menor diferença: Idiomas latinos têm diferenças de eficiência do Tokenizer relativamente pequenas (apenas 2,01x), pois a maioria dos Tokenizers foi treinada principalmente com corpus em inglês, beneficiando idiomas latinos
- Chinês está no meio: Cerca de 1,76 vezes o baseline do inglês, mas a diferença diminui ao usar modelos otimizados para chinês como DeepSeek e Qwen
🎯 Recomendação para Tradução Multilíngue: Se suas tarefas de tradução envolvem idiomas CJK como japonês e coreano, escolher um modelo com eficiência de Tokenizer mais alta (como DeepSeek, Qwen) pode reduzir significativamente os custos. Através da interface unificada da APIYI em apiyi.com, você pode alternar facilmente entre diferentes modelos para testes.
Gemini vs DeepSeek Tokenizer – Guia de Seleção de Cenários
| Cenário de Uso | Modelo Recomendado | Razão Principal |
|---|---|---|
| Tradução multilíngue em larga escala | DeepSeek V3.2 | Eficiência de tokens alta + preço baixo, custo apenas 1/12 |
| Entrega de tradução urgente | Gemini 3 Flash | Velocidade 6-10x mais rápida, ideal para cenários com prazo apertado |
| Tradução intensiva em idiomas CJK | DeepSeek V3.2 | Vantagem de eficiência do Tokenizer CJK atinge 2.5x |
| Tradução de idiomas latinos | Diferença pequena | Diferença de eficiência entre os dois é apenas 2x, escolha conforme o preço |
| Cenários de diálogo em tempo real | Gemini 3 Flash | Baixa latência, melhor experiência do usuário |
| Processamento em lote sensível a custos | DeepSeek V3.2 | Custo total mais baixo |
🎯 Dica prática: Em projetos reais, geralmente é necessário equilibrar custo e velocidade. Recomendamos integrar simultaneamente Gemini e DeepSeek através da APIYI (apiyi.com) e alternar dinamicamente entre modelos conforme o grau de urgência da tarefa. A plataforma suporta chamadas de todos os modelos principais com uma chave unificada.
Perguntas Frequentes
P1: O alto consumo de tokens do Gemini é um bug na cobrança da API?
Não é um bug. Trata-se de um fenômeno normal causado pela diferença de eficiência de codificação do Tokenizer. É como quando o mesmo arquivo compactado com ZIP e RAR resulta em tamanhos diferentes – diferentes modelos geram quantidades diferentes de tokens para o mesmo texto, mas o conteúdo processado é exatamente o mesmo. Nossos testes verificaram que a diferença no número de caracteres de saída é inferior a 1%.
P2: Mais tokens significam melhor qualidade de tradução?
Não. A quantidade de tokens apenas reflete a forma de codificação do Tokenizer e não está relacionada à qualidade da tradução. Em testes práticos, ambos os modelos apresentaram excelente qualidade e completude de tradução, com número de linhas de saída completamente idêntico (64 linhas). Ao escolher um modelo, você deve focar na qualidade da tradução, velocidade e custo total, não apenas no número de tokens.
P3: Como otimizar o custo de tokens em tradução multilíngue em um projeto?
Recomendamos as seguintes estratégias:
- Para idiomas CJK (chinês, japonês, coreano), priorize modelos com alta eficiência de Tokenizer como DeepSeek
- Para idiomas latinos, você pode escolher com flexibilidade, pois a diferença é pequena
- Integre múltiplos modelos através da APIYI (apiyi.com) e implemente roteamento automático por idioma com uma API unificada
- Ao configurar monitoramento de consumo de tokens, defina limites diferentes para cada modelo para evitar falsos positivos
Resumo
Conclusões principais da comparação de eficiência do Tokenizer entre Gemini e DeepSeek:
- Diferença de Token vem do Tokenizer, não é Bug: Para o mesmo texto, o Tokenizer do DeepSeek tem eficiência de codificação 2-2,8 vezes maior que o Gemini, com a maior diferença em idiomas CJK
- Diferença de custo se amplifica: Diferença de eficiência do Tokenizer (2-2,5x) × Diferença de preço por token (5-7x) = Diferença de custo real pode chegar a 12 vezes
- Equilíbrio entre velocidade e custo: Gemini é 6-10 vezes mais rápido mas com custo de token alto, DeepSeek tem custo baixo mas velocidade lenta — escolha flexível conforme o cenário
Entender a diferença de eficiência do Tokenizer é um passo fundamental para otimizar o custo de uso de APIs de IA. Em cenários intensivos em tokens, como tradução multilíngue, escolher o modelo certo pode economizar uma quantidade significativa de recursos.
Recomendamos usar APIYI (apiyi.com) para integrar múltiplos modelos de forma unificada, alternar com uma única chave e encontrar a melhor relação custo-benefício para cada cenário.
📚 Referências
-
Benchmark de desempenho do Tokenizer: Comparação abrangente da eficiência do Tokenizer de modelos principais
- Link:
llm-calculator.com/blog/tokenization-performance-benchmark - Descrição: Contém dados de eficiência do Tokenizer para modelos como GPT-4o, DeepSeek, Qwen e outros
- Link:
-
Texto CJK e melhores práticas com Modelos de Linguagem Grande: Mecanismo de processamento do Tokenizer para caracteres CJK
- Link:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - Descrição: Análise aprofundada das diferenças de consumo de tokens para idiomas CJK em diferentes Tokenizers
- Link:
-
Análise do Tokenizer Gemini: Princípios do tokenizador SentencePiece do Google Gemini
- Link:
dejan.ai/blog/gemini-toknizer - Descrição: Análise detalhada do mecanismo de codificação e características de eficiência do vocabulário de 256K do Gemini
- Link:
-
Relatório técnico DeepSeek V3: Otimização multilíngue do Tokenizer BPE em nível de byte
- Link:
arxiv.org/html/2412.19437v1 - Descrição: Conceitos de design e eficiência de compressão multilíngue do vocabulário de 128K do DeepSeek
- Link:
Autor: Equipe técnica APIYI
Comunicação técnica: Bem-vindo para discutir nos comentários, mais recursos disponíveis em docs.apiyi.com