Catatan Penulis: Data pengujian nyata mengungkapkan penyebab mendasar perbedaan konsumsi Token 2-2,5x antara Gemini dan DeepSeek saat menerjemahkan artikel yang sama — perbedaan efisiensi Tokenizer, dan memberikan saran optimasi biaya untuk skenario multibahasa
Artikel Mandarin yang sama, diterjemahkan ke bahasa Inggris, Jepang, dan Prancis menggunakan Gemini dan DeepSeek secara terpisah — kualitas terjemahan dan kelengkapan sepenuhnya identik — namun Completion Token yang dikembalikan API ternyata berbeda 2-2,5 kali lipat. Apakah ini bug penagihan API? Atau ada alasan teknis yang lebih mendalam?
Nilai Inti: Melalui data pengujian nyata, membantu Anda memahami bagaimana perbedaan Tokenizer mempengaruhi biaya API, dan menguasai metode memilih model dengan rasio harga-kinerja terbaik dalam skenario terjemahan multibahasa.

Data Inti Perbandingan Efisiensi Tokenizer Gemini vs DeepSeek
| Dimensi Perbandingan | Gemini 3 Flash | DeepSeek V3.2 | Perbedaan Kelipatan |
|---|---|---|---|
| Completion Token Terjemahan Inggris | 1.631 | 636 | Gemini lebih banyak 2,56x |
| Completion Token Terjemahan Jepang | 2.141 | 856 | Gemini lebih banyak 2,50x |
| Completion Token Terjemahan Prancis | 1.630 | 812 | Gemini lebih banyak 2,01x |
| Efisiensi Pengkodean (karakter/Token) | 0,82-1,84 | 2,02-4,16 | DeepSeek lebih tinggi 2-2,8x |
| Jumlah Baris Output Terjemahan | 64 baris | 64 baris | Sepenuhnya identik |
Penyebab Mendasar Perbedaan Tokenizer Gemini vs DeepSeek
Kami menggunakan teks pengujian Mandarin yang sama dengan 1.403 karakter (mencakup tabel Markdown, blok kode, placeholder SVG, CTA), memanggil gemini-3-flash-preview dan deepseek-v3.2 secara terpisah untuk menerjemahkan ke 3 bahasa (Inggris, Jepang, Prancis), kemudian membandingkan statistik Token yang dikembalikan API dan konten output aktual.
Hasilnya sangat jelas: jumlah karakter output hampir identik (perbedaan kurang dari 1%), namun jumlah Token berbeda 2-2,5 kali lipat. Ini membuktikan masalahnya terletak pada Tokenizer (pembagi kata), bukan strategi output model.
Prinsip Teknis Tokenizer Gemini vs DeepSeek
Apa itu Tokenizer? Sederhananya, Tokenizer adalah alat yang memotong teks menjadi unit terkecil yang dapat dipahami model (Token). Model berbeda menggunakan Tokenizer berbeda, seperti perangkat lunak kompresi yang berbeda — file yang sama, ZIP dan RAR menghasilkan ukuran berbeda setelah kompresi, namun konten setelah dekompresi identik.
Tokenizer SentencePiece Gemini: Menggunakan model bahasa Unigram, dengan ukuran kamus sekitar 256.000 Token. Cenderung memecah karakter CJK (Cina-Jepang-Korea) menjadi unit sub-kata yang lebih kecil. Dalam pengujian, efisiensi pengkodean output Jepang hanya 0,82 karakter/Token, artinya rata-rata setiap karakter Jepang memerlukan 1,2 Token untuk direpresentasikan.
Tokenizer Byte-level BPE DeepSeek: Ukuran kamus sekitar 128.000 Token, namun dioptimalkan khusus untuk skenario multibahasa. Memperkenalkan Token tanda baca gabungan dan baris baru, meningkatkan efisiensi kompresi teks CJK. Output Jepang mencapai 2,02 karakter/Token, efisiensi 2,46 kali lebih tinggi dari Gemini.
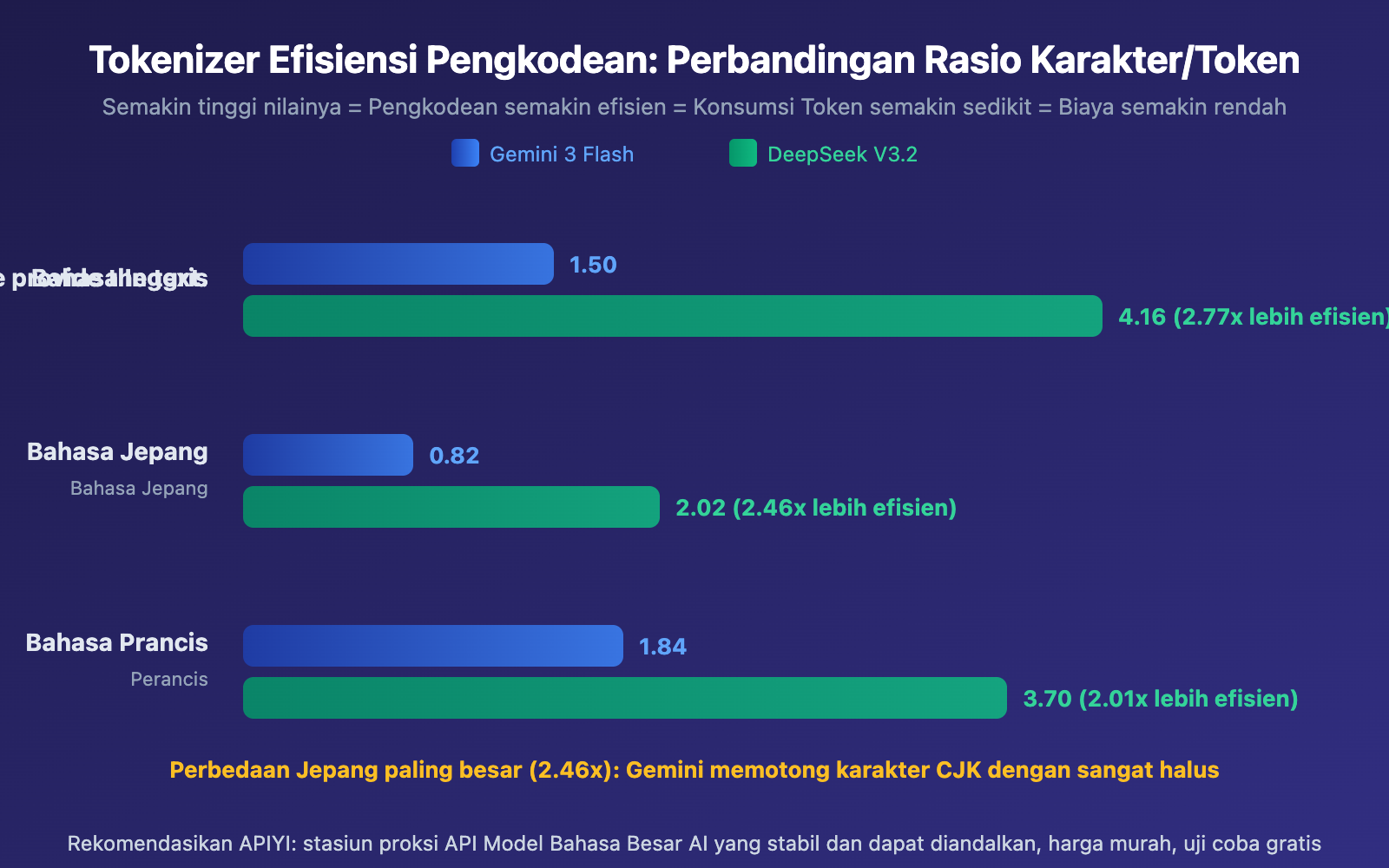
Gemini vs DeepSeek Tokenizer 分析Dampak Biaya
Setelah memahami perbedaan efisiensi Tokenizer, pertanyaan krusialnya adalah: Lebih banyak Token berarti pengeluaran lebih besar? Tidak selalu. Biaya akhir tergantung pada jumlah Token × harga satuan.
Pengujian Biaya Terjemahan Gemini vs DeepSeek
Dengan contoh menerjemahkan satu artikel blog teknis (sekitar 30.000 Prompt Token) ke 11 bahasa:
| Dimensi Biaya | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Perkiraan Completion Token per Bahasa | ~80.000 | ~30.000 |
| Total Completion Token 11 Bahasa | ~880.000 | ~330.000 |
| Harga Output (per juta Token) | $3,00 | $0,42 |
| Total Biaya Output 11 Bahasa | $2,64 | $0,14 |
| Harga Input (per juta Token) | $0,50 | $0,28 |
| Total Biaya Input 11 Kali | $0,17 | $0,09 |
| Total Biaya Terjemahan per Artikel | $2,81 | $0,23 |
Dari perbandingan biaya aktual, keunggulan DeepSeek dalam skenario terjemahan multibahasa sangat jelas—untuk tugas terjemahan yang sama, biaya DeepSeek hanya sekitar 1/12 dari Gemini. Perbedaan ini dihasilkan dari dua faktor yang saling menggandakan: efisiensi Tokenizer (2-2,5x) × perbedaan harga Token (5-7x).
Kecepatan dan Kualitas Terjemahan Gemini vs DeepSeek
Namun biaya bukan satu-satunya pertimbangan:
| Metrik | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Kecepatan Inferensi | 145-189 token/detik | 12-26 token/detik |
| Kelipatan Kecepatan | 6-10x lebih cepat | Baseline |
| Kualitas Terjemahan | Sangat Baik | Sangat Baik |
| Kelengkapan Terjemahan | 100% (64 baris) | 100% (64 baris) |
| Pemeliharaan Format Markdown | Baik | Baik |
Kecepatan inferensi Gemini adalah 6-10 kali lebih cepat dari DeepSeek. Jika Anda membutuhkan terjemahan batch cepat dan biaya waktu lebih tinggi dari biaya Token, Gemini tetap menjadi pilihan yang lebih baik.
🎯 Saran Pemilihan: Jika volume terjemahan besar dan tidak sensitif terhadap waktu, keunggulan biaya DeepSeek sangat signifikan. Jika membutuhkan pengiriman cepat, keunggulan kecepatan Gemini jelas. Melalui APIYI apiyi.com, Anda dapat mengakses kedua model sekaligus dengan antarmuka terpadu dan beralih dengan fleksibel untuk menemukan titik keseimbangan optimal dalam skenario Anda.
Dampak Perbedaan Tokenizer pada Berbagai Bahasa
Dampak Tokenizer pada berbagai bahasa sangat berbeda. Bahasa CJK (Cina, Jepang, Korea) paling terpengaruh, sementara bahasa Latin relatif lebih ringan.
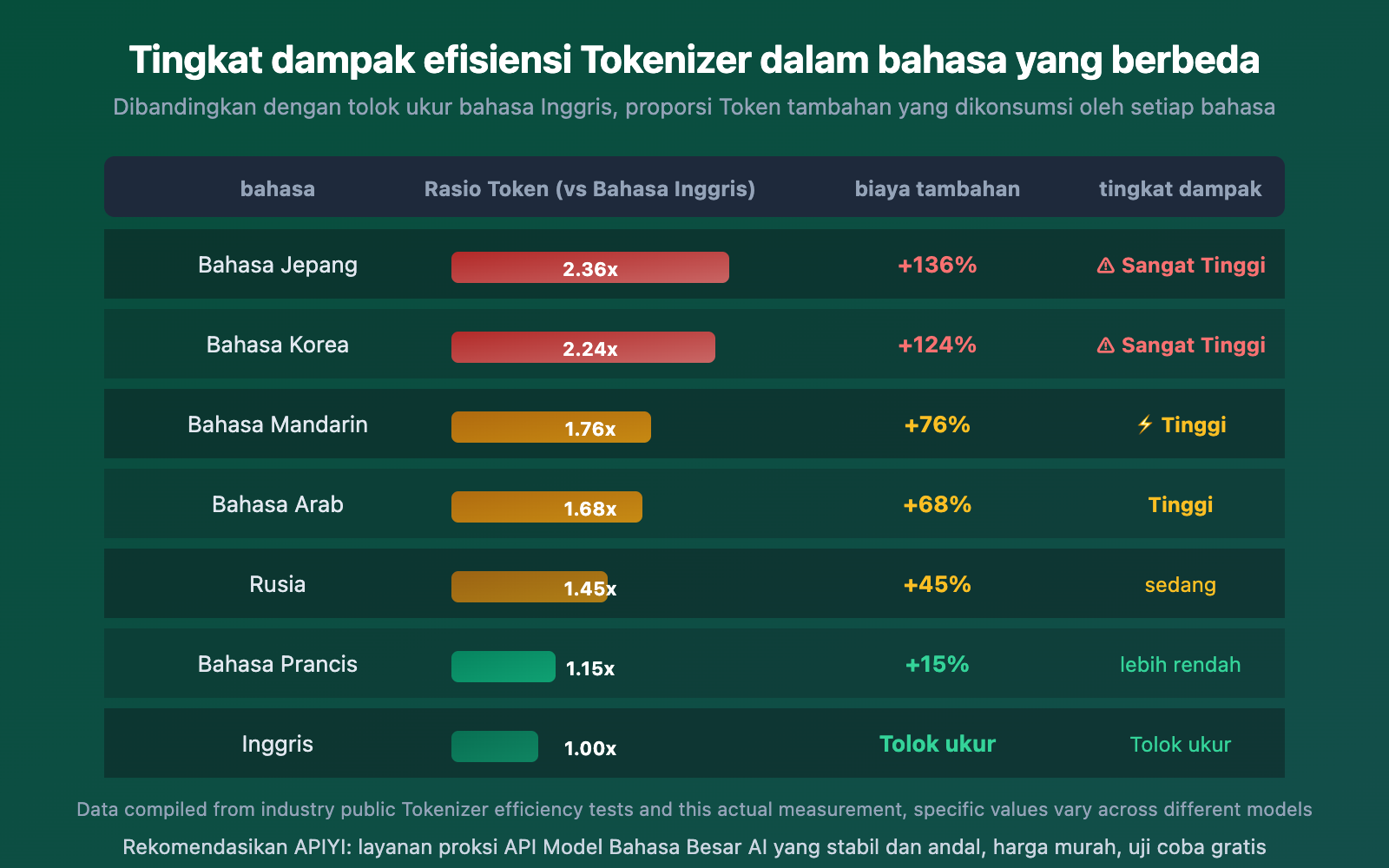
Data dengan jelas menunjukkan:
- Bahasa Jepang Paling Terpengaruh: Efisiensi pengkodean bahasa Jepang di Gemini hanya 0,82 karakter/Token, yang menjelaskan mengapa konsumsi Token meningkat signifikan saat menerjemahkan artikel dengan banyak konten Cina dan Jepang
- Bahasa Prancis Perbedaannya Paling Kecil: Perbedaan efisiensi Tokenizer untuk bahasa Latin relatif kecil (hanya 2,01x), karena sebagian besar data pelatihan Tokenizer berbasis bahasa Inggris, dan bahasa Latin mendapat manfaat
- Bahasa Cina Berada di Tengah: Sekitar 1,76 kali lebih tinggi dari baseline bahasa Inggris, tetapi perbedaannya akan berkurang saat menggunakan model yang dioptimalkan untuk Cina seperti DeepSeek dan Qwen
🎯 Rekomendasi Terjemahan Multibahasa: Jika tugas terjemahan Anda melibatkan bahasa CJK seperti Jepang dan Korea, memilih model dengan efisiensi Tokenizer lebih tinggi (seperti DeepSeek, Qwen) dapat secara signifikan mengurangi biaya. Melalui antarmuka terpadu APIYI apiyi.com, Anda dapat dengan mudah beralih antar model untuk pengujian.
Panduan Pemilihan Skenario Gemini vs DeepSeek Tokenizer
| Skenario Penggunaan | Model yang Direkomendasikan | Alasan Utama |
|---|---|---|
| Terjemahan multibahasa dalam jumlah besar | DeepSeek V3.2 | Efisiensi token tinggi + harga rendah, biaya hanya 1/12 |
| Pengiriman terjemahan mendesak | Gemini 3 Flash | Kecepatan 6-10x lebih cepat, cocok untuk skenario waktu terbatas |
| Terjemahan intensif bahasa CJK | DeepSeek V3.2 | Keunggulan efisiensi Tokenizer CJK mencapai 2.5x |
| Terjemahan sistem bahasa Latin | Perbedaan kecil | Perbedaan efisiensi kedua model hanya 2x, pilih berdasarkan harga saja |
| Skenario dialog real-time | Gemini 3 Flash | Latensi rendah, pengalaman pengguna lebih baik |
| Pemrosesan batch sensitif biaya | DeepSeek V3.2 | Biaya total terendah |
🎯 Saran praktis: Dalam proyek nyata, Anda sering perlu menyeimbangkan biaya dan kecepatan. Kami merekomendasikan untuk mengintegrasikan Gemini dan DeepSeek secara bersamaan melalui APIYI apiyi.com, dan beralih model secara dinamis berdasarkan tingkat urgensi tugas. Platform mendukung pemanggilan model terpadu dengan satu kunci untuk semua model utama.
Pertanyaan Umum
Q1: Apakah konsumsi token Gemini yang lebih banyak adalah bug penagihan API?
Bukan bug. Ini adalah fenomena normal yang disebabkan oleh perbedaan efisiensi encoding tokenizer. Sama seperti file yang sama dikompres dengan ZIP dan RAR menghasilkan ukuran berbeda, tokenizer model yang berbeda menghasilkan jumlah token berbeda untuk teks yang sama, tetapi konten yang diproses sepenuhnya identik. Verifikasi pengujian kami menunjukkan perbedaan jumlah karakter output kurang dari 1%.
Q2: Apakah jumlah token yang lebih banyak berarti kualitas terjemahan lebih baik?
Tidak. Jumlah token hanya mencerminkan cara encoding tokenizer, tidak ada hubungannya dengan kualitas terjemahan. Dalam pengujian, kedua model menunjukkan kualitas terjemahan dan kelengkapan yang sangat baik, dengan jumlah baris output yang sama persis (64 baris). Saat memilih model, Anda harus fokus pada kualitas terjemahan, kecepatan, dan biaya total, bukan hanya jumlah token.
Q3: Bagaimana cara mengoptimalkan biaya token terjemahan multibahasa dalam proyek?
Kami merekomendasikan strategi berikut:
- Untuk bahasa CJK (Cina, Jepang, Korea), prioritaskan penggunaan model dengan efisiensi tokenizer tinggi seperti DeepSeek
- Untuk sistem bahasa Latin, Anda dapat memilih dengan fleksibel, perbedaannya kecil
- Integrasikan beberapa model melalui APIYI apiyi.com, dan implementasikan perutean otomatis berdasarkan bahasa dengan API terpadu
- Saat menyiapkan pemantauan konsumsi token, tetapkan ambang batas berbeda untuk model yang berbeda, hindari alarm palsu
Ringkasan
Kesimpulan inti dari perbandingan efisiensi Tokenizer Gemini vs DeepSeek:
- Perbedaan Token Berasal dari Tokenizer, Bukan Bug: Untuk teks yang sama, Tokenizer DeepSeek memiliki efisiensi encoding 2-2,8 kali lebih tinggi dibanding Gemini, dengan perbedaan paling signifikan pada bahasa CJK
- Perbedaan Biaya Berlipat Ganda: Perbedaan efisiensi Tokenizer (2-2,5x) × perbedaan harga per token (5-7x) = perbedaan biaya aktual bisa mencapai 12 kali lipat
- Pertukaran Kecepatan vs Biaya: Gemini 6-10 kali lebih cepat tetapi biaya token lebih tinggi, DeepSeek biayanya rendah tetapi lebih lambat — pilih fleksibel sesuai kebutuhan
Memahami perbedaan efisiensi Tokenizer adalah langkah kunci untuk mengoptimalkan biaya penggunaan API AI. Dalam skenario padat token seperti terjemahan multibahasa, memilih model yang tepat bisa menghemat biaya secara signifikan.
Kami merekomendasikan menggunakan APIYI di apiyi.com untuk akses terpadu ke berbagai model, gunakan satu kunci API untuk beralih fleksibel antar model, dan temukan solusi terbaik untuk setiap skenario.
📚 Referensi
-
Benchmark Performa Tokenizer: Perbandingan komprehensif efisiensi Tokenizer model utama
- Tautan:
llm-calculator.com/blog/tokenization-performance-benchmark - Keterangan: Mencakup data efisiensi Tokenizer untuk GPT-4o, DeepSeek, Qwen, dan model lainnya
- Tautan:
-
Teks CJK dan Praktik Terbaik Model Bahasa Besar AI: Mekanisme pemrosesan karakter CJK oleh Tokenizer
- Tautan:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - Keterangan: Analisis mendalam tentang perbedaan konsumsi token untuk bahasa CJK di berbagai Tokenizer
- Tautan:
-
Analisis Tokenizer Gemini: Prinsip pemisah kata SentencePiece Google Gemini
- Tautan:
dejan.ai/blog/gemini-toknizer - Keterangan: Analisis detail tentang mekanisme encoding dan karakteristik efisiensi kosakata 256K Gemini
- Tautan:
-
Laporan Teknis DeepSeek V3: Optimasi multibahasa Tokenizer Byte-level BPE
- Tautan:
arxiv.org/html/2412.19437v1 - Keterangan: Filosofi desain kosakata 128K DeepSeek dan efisiensi kompresi multibahasa
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Silakan diskusikan di bagian komentar, untuk materi lebih lanjut kunjungi pusat dokumentasi APIYI di docs.apiyi.com