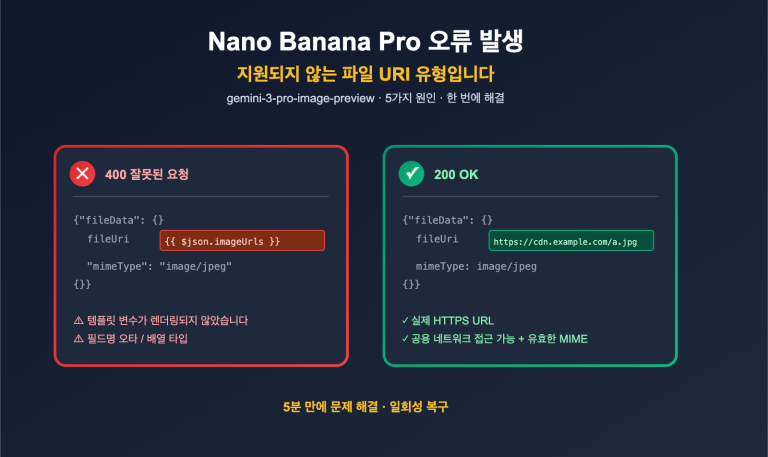
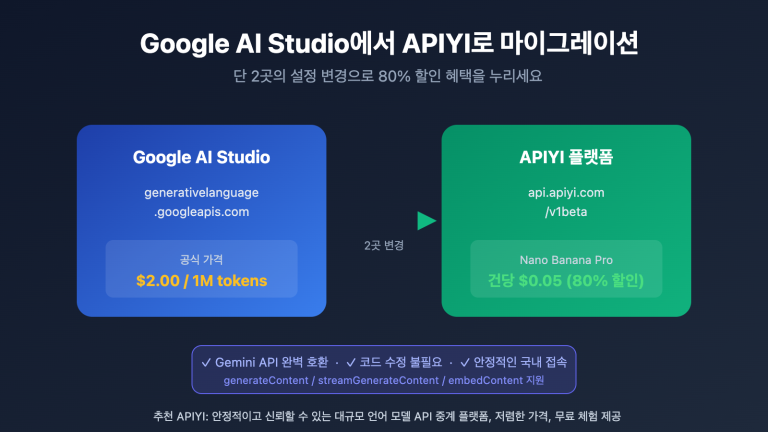
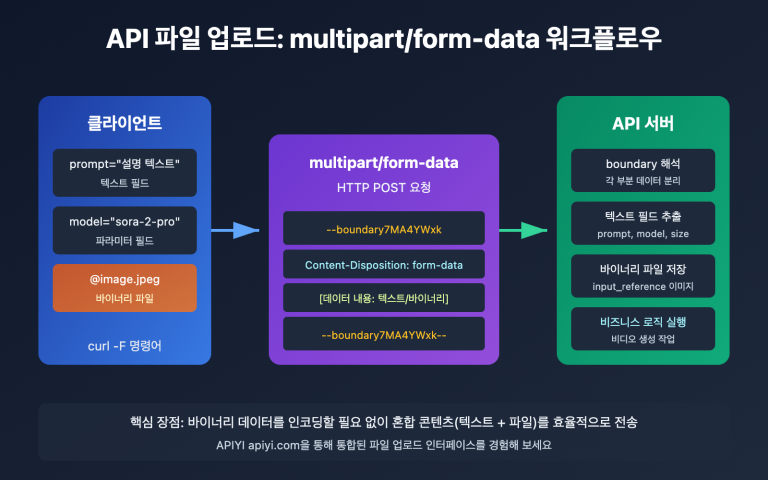
저자 주: 실제 데이터로 밝혀진 Gemini와 DeepSeek의 동일 문서 번역 시 Token 소비 차이 2-2.5배의 근본 원인——Tokenizer 인코딩 효율 차이, 다국어 시나리오에서의 비용 최적화 제안 제공
동일한 중문 문서를 Gemini와 DeepSeek으로 각각 영어, 일본어, 프랑스어로 번역했을 때 번역 품질과 완성도는 완전히 동일했습니다. 그런데 API가 반환한 Completion Token이 무려 2-2.5배 차이가 났습니다. 이게 API 계산 오류일까요? 아니면 더 깊은 기술적 이유가 있을까요?
핵심 가치: 실제 테스트 데이터를 통해 Tokenizer 차이가 API 비용에 어떤 영향을 미치는지 이해하고, 다국어 번역 시나리오에서 가장 비용 효율적인 모델을 선택하는 방법을 배워보세요.

Gemini vs DeepSeek Tokenizer 효율 핵심 데이터
| 비교 항목 | Gemini 3 Flash | DeepSeek V3.2 | 차이 배수 |
|---|---|---|---|
| 영문 번역 Completion Token | 1,631 | 636 | Gemini 2.56배 많음 |
| 일본어 번역 Completion Token | 2,141 | 856 | Gemini 2.50배 많음 |
| 프랑스어 번역 Completion Token | 1,630 | 812 | Gemini 2.01배 많음 |
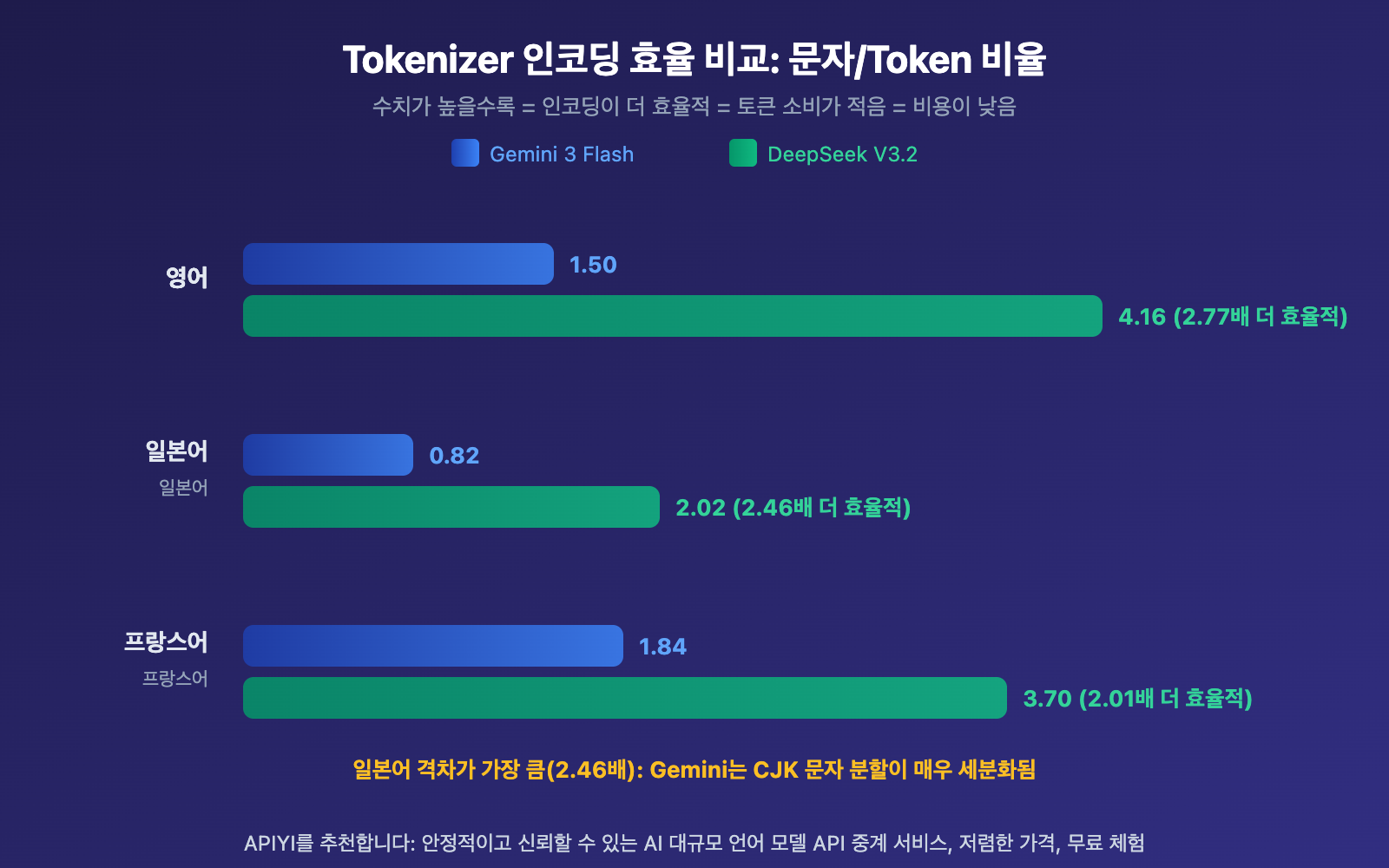
| 인코딩 효율(문자/Token) | 0.82-1.84 | 2.02-4.16 | DeepSeek 2-2.8배 높음 |
| 번역 출력 줄 수 | 64줄 | 64줄 | 완전히 동일 |
Gemini vs DeepSeek Tokenizer 차이의 근본 원인
동일한 1,403자의 중문 테스트 텍스트(Markdown 표, 코드 블록, SVG 플레이스홀더, CTA 포함)를 gemini-3-flash-preview와 deepseek-v3.2로 각각 영어, 일본어, 프랑스어 3개 언어로 번역한 후, API가 반환한 Token 통계와 실제 출력 내용을 비교했습니다.
결과는 명확합니다: 출력 문자 수는 거의 동일(1% 미만 차이)하지만 Token 수는 2-2.5배 차이가 납니다. 이는 문제가 모델의 출력 전략이 아니라 **Tokenizer(분어기)**에 있다는 것을 증명합니다.
Gemini vs DeepSeek Tokenizer의 기술 원리
Tokenizer란? 간단히 말해 Tokenizer는 텍스트를 모델이 이해할 수 있는 최소 단위(Token)로 자르는 도구입니다. 다른 모델은 다른 Tokenizer를 사용하는데, 이는 마치 다른 압축 소프트웨어처럼 작동합니다——같은 파일이라도 ZIP과 RAR로 압축하면 크기가 다르지만, 압축을 풀면 내용은 완전히 동일합니다.
Gemini의 SentencePiece Tokenizer: Unigram 언어 모델을 사용하며, 어휘 크기는 약 256,000개 Token입니다. CJK(중일한) 문자를 더 작은 부분 단어 단위로 분할하는 경향이 있습니다. 실제 테스트에서 일본어 출력의 인코딩 효율은 0.82 문자/Token에 불과했으며, 이는 평균적으로 각 일본어 문자가 1.2개의 Token이 필요하다는 의미입니다.
DeepSeek의 바이트 레벨 BPE Tokenizer: 어휘 크기는 약 128,000개 Token이지만, 다국어 시나리오에 특별히 최적화되었습니다. 조합 기호와 줄바꿈 Token을 도입하여 CJK 텍스트의 압축 효율을 높였습니다. 일본어 출력은 2.02 문자/Token에 달하며, 이는 Gemini의 2.46배 효율입니다.
Gemini vs DeepSeek 토크나이저 비용 영향 분석
토크나이저 효율 차이를 이해한 후 핵심 질문은 이거예요: 토큰이 많으면 돈을 더 많이 쓰는 건가요? 꼭 그렇지는 않아요. 최종 비용은 토큰 수량 × 단가에 따라 결정돼요.
Gemini vs DeepSeek 번역 비용 실측
약 30,000개의 프롬프트 토큰으로 이루어진 전형적인 기술 블로그 글을 11개 언어로 번역하는 경우를 예로 들어볼게요:
| 비용 항목 | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| 예상 단일 언어 Completion Token | ~80,000 | ~30,000 |
| 11개 언어 총 Completion Token | ~880,000 | ~330,000 |
| Output 단가(백만 Token당) | $3.00 | $0.42 |
| 11개 언어 Output 총 비용 | $2.64 | $0.14 |
| Input 단가(백만 Token당) | $0.50 | $0.28 |
| 11회 Input 총 비용 | $0.17 | $0.09 |
| 단일 문서 번역 총 비용 | $2.81 | $0.23 |
실측 비용 비교에서 보면 DeepSeek의 다국어 번역 비용 우위가 정말 명확해요. 같은 번역 작업이라도 DeepSeek의 비용은 Gemini의 약 1/12 수준이거든요. 이 격차는 두 가지 요소가 겹쳐서 생겨요: 토크나이저 효율(2-2.5배) × 토큰 단가 차이(5-7배).
Gemini vs DeepSeek 번역 속도와 품질
하지만 비용만이 고려 대상은 아니에요:
| 지표 | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| 추론 속도 | 145-189 tokens/s | 12-26 tokens/s |
| 속도 배수 | 6-10배 더 빠름 | 기준 |
| 번역 품질 | 우수 | 우수 |
| 번역 완전성 | 100%(64줄) | 100%(64줄) |
| Markdown 형식 유지 | 양호 | 양호 |
Gemini의 추론 속도가 DeepSeek보다 6-10배 빨라요. 빠른 대량 번역이 필요하거나 시간 비용이 토큰 비용보다 크다면 Gemini가 더 좋은 선택이에요.
🎯 선택 팁: 번역량이 많고 시간에 여유가 있다면 DeepSeek의 비용 우위가 두드러져요. 빠른 납기가 필요하다면 Gemini의 속도 우위가 명확해요. APIYI apiyi.com을 통해 두 모델을 동시에 연결하고 통일된 인터페이스로 유연하게 전환하면서 당신의 상황에 맞는 최적의 균형점을 찾을 수 있어요.
토크나이저 효율 차이가 다양한 언어에 미치는 영향
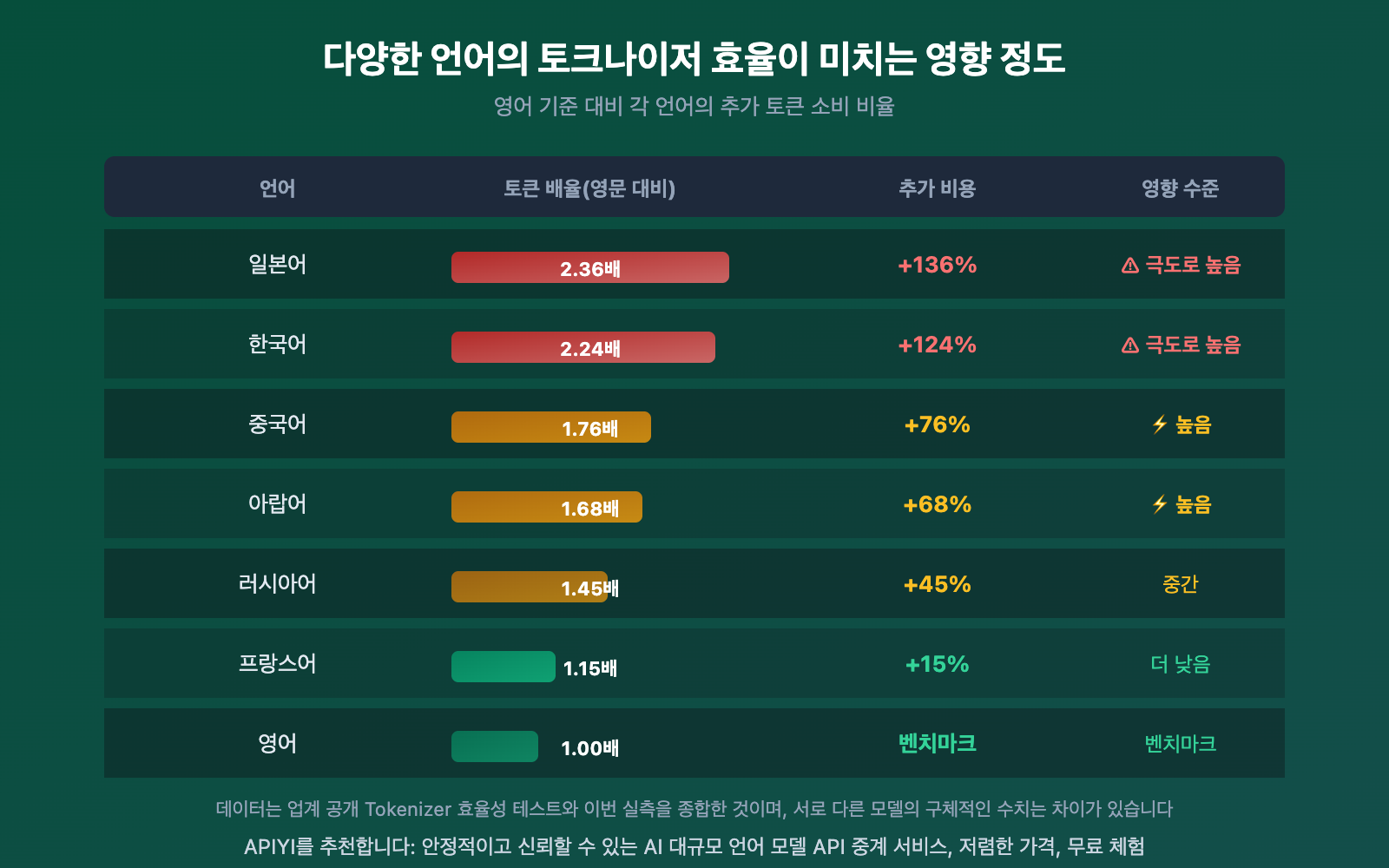
토크나이저가 언어마다 미치는 영향 정도가 크게 달라요. CJK(중일한) 언어가 가장 심하게 영향을 받고, 라틴 문자 계통은 상대적으로 덜 받아요.
데이터에서 명확하게 볼 수 있는 내용들이에요:
- 일본어가 가장 큰 영향을 받아요: Gemini에서 일본어 인코딩 효율이 0.82자/토큰에 불과해서, 중일문이 많은 글을 번역할 때 토큰 소비가 크게 증가하는 이유를 설명해줘요
- 프랑스어 차이가 가장 작아요: 라틴 문자 계통 언어들의 토크나이저 효율 차이가 상대적으로 작아요(2.01배만). 대부분의 토크나이저 학습 데이터가 영어 중심이기 때문에 라틴 문자 계통이 이득을 봐요
- 중국어는 중간 정도예요: 영어 기준의 약 1.76배 정도지만, DeepSeek이나 Qwen 같은 중국어 최적화 모델을 사용하면 그 격차가 줄어들어요
🎯 다국어 번역 팁: 일본어, 한국어 같은 CJK 언어가 포함된 번역 작업이라면 토크나이저 효율이 더 높은 모델(DeepSeek, Qwen 등)을 선택하면 비용을 크게 절감할 수 있어요. APIYI apiyi.com의 통일된 인터페이스를 통해 다양한 모델을 편하게 전환하면서 테스트할 수 있어요.
Gemini vs DeepSeek Tokenizer 시나리오 선택 가이드
| 사용 시나리오 | 추천 모델 | 핵심 이유 |
|---|---|---|
| 대량 다국어 번역 | DeepSeek V3.2 | Token 효율성 높음 + 저가격, 비용 1/12 수준 |
| 긴급 번역 납기 | Gemini 3 Flash | 속도 6-10배 빠름, 시간이 촉박한 상황에 적합 |
| CJK 언어 집약적 번역 | DeepSeek V3.2 | CJK Tokenizer 효율성 2.5배 우위 |
| 라틴 문자 번역 | 큰 차이 없음 | 두 모델 효율성 차이 2배 수준, 단가로 선택 |
| 실시간 대화 시나리오 | Gemini 3 Flash | 낮은 지연시간, 사용자 경험 우수 |
| 비용 민감 배치 처리 | DeepSeek V3.2 | 종합 비용 최저 |
🎯 실용 조언: 실제 프로젝트에서는 비용과 속도를 모두 고려해야 합니다. APIYI(apiyi.com)를 통해 Gemini와 DeepSeek을 동시에 연동한 후, 작업의 긴급도에 따라 동적으로 모델을 전환하는 방식을 추천합니다. 플랫폼은 통합 API 키로 모든 주요 모델 호출을 지원합니다.
자주 묻는 질문
Q1: Gemini Token 소비가 많은 것이 API 청구 버그인가요?
아닙니다. 이는 Tokenizer 인코딩 효율성의 차이로 인한 정상적인 현상입니다. 같은 파일을 ZIP과 RAR로 압축했을 때 크기가 다른 것처럼, 모델마다 다른 Tokenizer를 사용하므로 동일한 텍스트에 대해 생성되는 Token 수가 다릅니다. 하지만 처리하는 내용은 완전히 동일합니다. 저희 실측 검증 결과 출력 문자 수 차이는 1% 미만입니다.
Q2: Token 수가 많다는 것이 번역 품질이 더 좋다는 뜻인가요?
아닙니다. Token 수는 단순히 Tokenizer의 인코딩 방식을 반영할 뿐, 번역 품질과는 무관합니다. 실측에서 두 모델 모두 번역 품질과 완전성이 우수했으며, 출력 라인 수도 정확히 일치했습니다(64줄). 모델을 선택할 때는 번역 품질, 속도, 종합 비용에 주목해야 하며, 단순히 Token 수만 고려해서는 안 됩니다.
Q3: 프로젝트에서 다국어 번역의 Token 비용을 최적화하려면 어떻게 해야 하나요?
다음 전략을 추천합니다:
- CJK 언어(중국어, 일본어, 한국어)는 Tokenizer 효율성이 높은 DeepSeek 등의 모델을 우선 사용
- 라틴 문자 언어는 유연하게 선택 가능, 차이가 작음
- APIYI(apiyi.com)를 통해 여러 모델을 연동하고, 통합 API로 언어별 자동 라우팅 구현
- Token 소비 모니터링 설정 시 모델별로 다른 임계값을 설정하여 오경보 방지
요약
Gemini vs DeepSeek Tokenizer 효율성 비교의 핵심 결론:
- Token 차이는 Tokenizer 때문이지, 버그가 아닙니다: 동일한 텍스트에서 DeepSeek의 Tokenizer 인코딩 효율이 Gemini보다 2-2.8배 높으며, CJK 언어에서 차이가 가장 두드러집니다
- 비용 차이가 누적되어 확대됩니다: Tokenizer 효율 차이(2-2.5배) × Token 단가 차이(5-7배) = 실제 비용 차이는 최대 12배까지 벌어집니다
- 속도 vs 비용의 트레이드오프: Gemini는 속도가 6-10배 빠르지만 Token 비용이 높고, DeepSeek는 비용이 저렴하지만 속도가 느립니다. 상황에 맞게 유연하게 선택하세요
Tokenizer 효율 차이를 이해하는 것이 AI API 사용 비용을 최적화하는 핵심입니다. 다국어 번역 같은 Token 집약적인 작업에서는 올바른 모델을 선택하면 상당한 비용을 절감할 수 있습니다.
APIYI(apiyi.com)를 통해 여러 모델을 통합 접근하고, 하나의 API 키로 유연하게 전환하며, 각 상황에 최적의 성능 대비 가격 솔루션을 찾아보세요.
📚 참고 자료
-
Tokenizer 성능 벤치마크 테스트: 주요 모델의 Tokenizer 효율 종합 비교
- 링크:
llm-calculator.com/blog/tokenization-performance-benchmark - 설명: GPT-4o, DeepSeek, Qwen 등 모델의 Tokenizer 효율 데이터 포함
- 링크:
-
CJK 텍스트와 AI 대규모 언어 모델 모범 사례: CJK 문자의 Tokenizer 처리 메커니즘
- 링크:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - 설명: 다양한 Tokenizer에서 CJK 언어의 Token 소비 차이를 심층 분석
- 링크:
-
Gemini Tokenizer 분석: Google Gemini의 SentencePiece 분词기 원리
- 링크:
dejan.ai/blog/gemini-toknizer - 설명: Gemini 256K 어휘 테이블의 인코딩 메커니즘과 효율성 특성 상세 분석
- 링크:
-
DeepSeek V3 기술 보고서: Byte-level BPE Tokenizer의 다국어 최적화
- 링크:
arxiv.org/html/2412.19437v1 - 설명: DeepSeek 128K 어휘 테이블의 설계 철학과 다국어 압축 효율
- 링크:
작성자: APIYI 기술팀
기술 교류: 댓글 섹션에서 토론을 환영하며, 더 많은 자료는 APIYI docs.apiyi.com 문서 센터에서 확인할 수 있습니다