Nota del autor: Los datos reales revelan la razón fundamental por la que Gemini y DeepSeek consumen 2-2.5 veces más tokens al traducir el mismo artículo — diferencias en la eficiencia del Tokenizer, con recomendaciones de optimización de costos para escenarios multilingües.
Un mismo artículo en chino, traducido a inglés, japonés y francés respectivamente con Gemini y DeepSeek, produce una calidad y completitud de traducción idénticas — pero los Completion Token devueltos por la API difieren en 2-2.5 veces. ¿Es un bug en la facturación de la API? ¿O hay una razón técnica más profunda?
Valor central: A través de datos de pruebas reales, te ayudamos a entender cómo las diferencias en el Tokenizer afectan los costos de API y dominar el método para elegir el modelo más rentable en escenarios de traducción multilingüe.
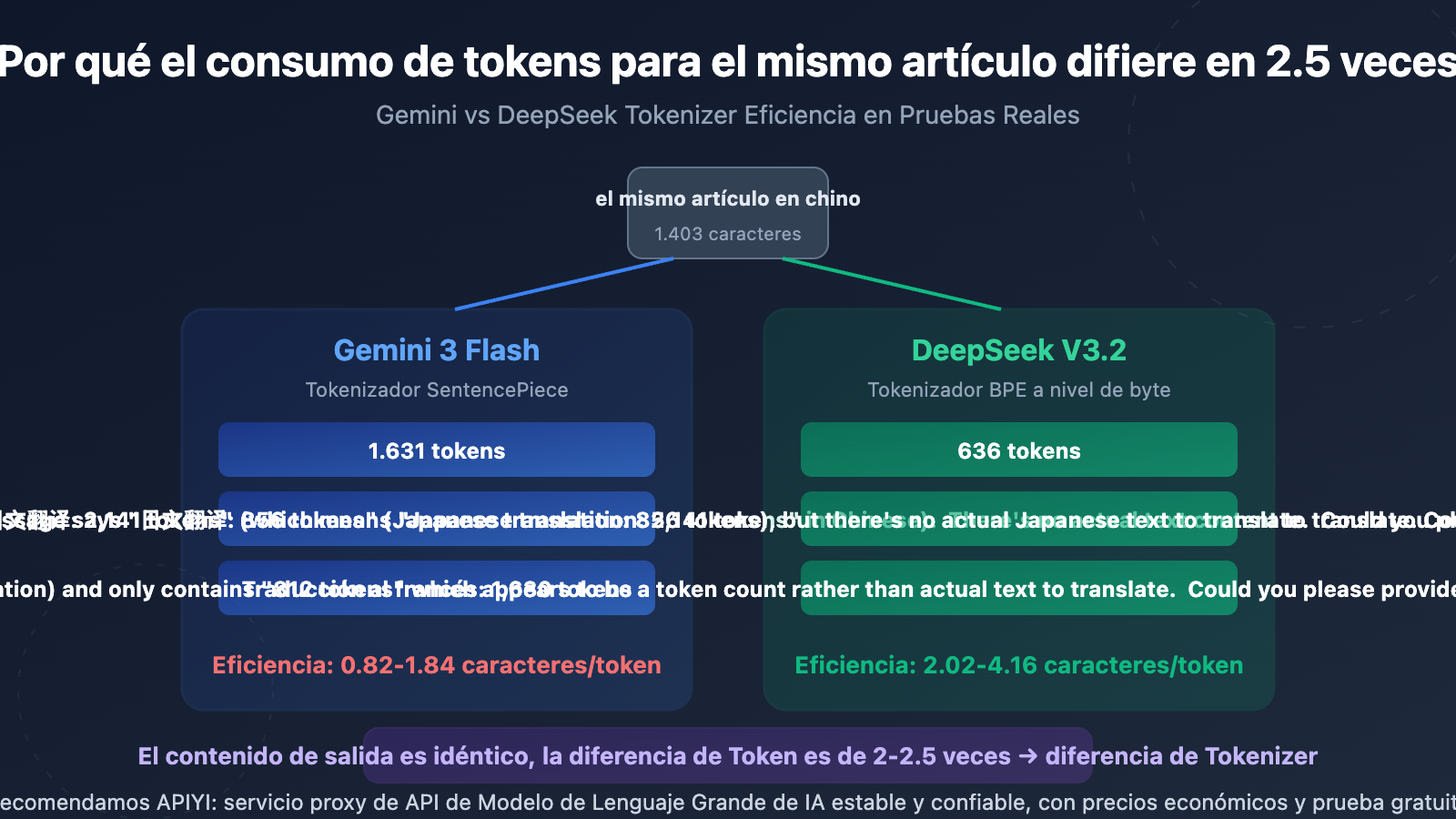
Datos principales de eficiencia del Tokenizer: Gemini vs DeepSeek
| Dimensión de comparación | Gemini 3 Flash | DeepSeek V3.2 | Múltiplo de diferencia |
|---|---|---|---|
| Completion Token en traducción al inglés | 1.631 | 636 | Gemini 2.56x más |
| Completion Token en traducción al japonés | 2.141 | 856 | Gemini 2.50x más |
| Completion Token en traducción al francés | 1.630 | 812 | Gemini 2.01x más |
| Eficiencia de codificación (caracteres/Token) | 0.82-1.84 | 2.02-4.16 | DeepSeek 2-2.8x superior |
| Líneas de salida de traducción | 64 líneas | 64 líneas | Completamente idénticas |
La razón fundamental detrás de las diferencias del Tokenizer entre Gemini y DeepSeek
Utilizamos el mismo texto de prueba de 1.403 caracteres en chino (que incluye tablas Markdown, bloques de código, marcadores de posición SVG y llamadas a la acción), invocamos respectivamente gemini-3-flash-preview y deepseek-v3.2 para traducir a 3 idiomas: inglés, japonés y francés. Luego comparamos las estadísticas de tokens devueltas por la API y el contenido real de salida.
El resultado es muy claro: el número de caracteres de salida es casi idéntico (diferencia menor al 1%), pero el número de tokens difiere en 2-2.5 veces. Esto prueba que el problema está en el Tokenizer (divisor de palabras), no en la estrategia de salida del modelo.
Los principios técnicos detrás de los Tokenizers de Gemini vs DeepSeek
¿Qué es un Tokenizer? En pocas palabras, un Tokenizer es una herramienta que divide el texto en las unidades más pequeñas que el modelo puede entender (Tokens). Diferentes modelos utilizan diferentes Tokenizers, como diferentes software de compresión — el mismo archivo, comprimido con ZIP y RAR, tendrá tamaños diferentes, pero al descomprimirse el contenido es idéntico.
Tokenizer SentencePiece de Gemini: Utiliza un modelo de lenguaje Unigram, con un vocabulario de aproximadamente 256.000 tokens. Tiende a dividir caracteres CJK (chino, japonés, coreano) en unidades de subpalabras más pequeñas. En nuestras pruebas, la salida en japonés alcanzó una eficiencia de codificación de solo 0.82 caracteres/Token, lo que significa que en promedio cada carácter japonés requiere 1.2 tokens para representarse.
Tokenizer BPE a nivel de bytes de DeepSeek: Con un vocabulario de aproximadamente 128.000 tokens, pero optimizado específicamente para escenarios multilingües. Introduce tokens de puntuación combinada y saltos de línea, mejorando la eficiencia de compresión del texto CJK. La salida en japonés alcanza 2.02 caracteres/Token, una eficiencia 2.46 veces superior a la de Gemini.
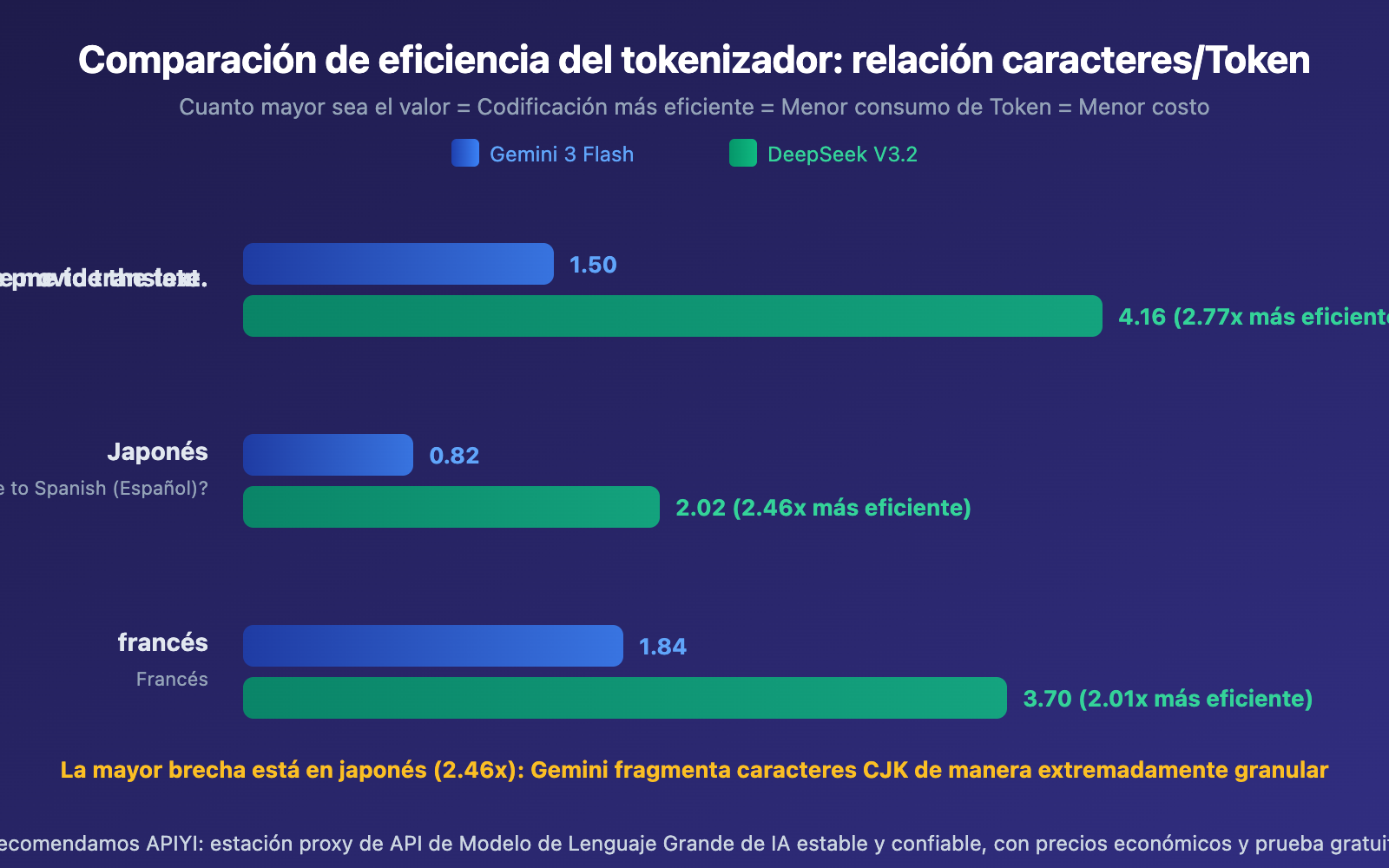
Gemini vs DeepSeek Tokenizer – Análisis del Impacto en Costos
Después de entender las diferencias de eficiencia del Tokenizer, surge la pregunta clave: ¿Más tokens siempre significa gastar más dinero? No necesariamente. El costo final depende de: Cantidad de tokens × Precio unitario.
Costo de traducción real: Gemini vs DeepSeek
Tomemos como ejemplo la traducción de un artículo técnico típico (aproximadamente 30,000 Prompt Token) a 11 idiomas:
| Dimensión de costo | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Completion Token estimado por idioma | ~80,000 | ~30,000 |
| Total Completion Token para 11 idiomas | ~880,000 | ~330,000 |
| Precio Output (por millón de tokens) | $3.00 | $0.42 |
| Costo total Output para 11 idiomas | $2.64 | $0.14 |
| Precio Input (por millón de tokens) | $0.50 | $0.28 |
| Costo total Input para 11 idiomas | $0.17 | $0.09 |
| Costo total traducción por artículo | $2.81 | $0.23 |
Según los datos de costo reales, la ventaja de DeepSeek en escenarios de traducción multilingüe es muy evidente: para la misma tarea de traducción, el costo de DeepSeek es apenas 1/12 del de Gemini. Esta diferencia proviene de dos factores combinados: eficiencia del Tokenizer (2-2.5x) × diferencia en precio unitario de tokens (5-7x).
Velocidad y calidad de traducción: Gemini vs DeepSeek
Pero el costo no es el único factor a considerar:
| Métrica | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Velocidad de inferencia | 145-189 tokens/s | 12-26 tokens/s |
| Múltiplo de velocidad | 6-10x más rápido | Referencia |
| Calidad de traducción | Excelente | Excelente |
| Completitud de traducción | 100% (64 líneas) | 100% (64 líneas) |
| Preservación de formato Markdown | Buena | Buena |
Gemini tiene una velocidad de inferencia 6-10 veces superior a DeepSeek. Si necesitas traducir grandes volúmenes rápidamente o el tiempo es más valioso que el costo de tokens, Gemini sigue siendo la mejor opción.
🎯 Recomendación de selección: Si tienes un gran volumen de traducciones y no tienes prisa, la ventaja de costo de DeepSeek es significativa. Si necesitas entregas rápidas, la ventaja de velocidad de Gemini es evidente. A través de APIYI en apiyi.com puedes acceder a ambos modelos simultáneamente, cambiar entre ellos con una interfaz unificada y encontrar el equilibrio óptimo para tu caso de uso.
Impacto de las diferencias de eficiencia del Tokenizer en diferentes idiomas
El Tokenizer afecta de manera muy diferente a distintos idiomas. Los idiomas CJK (chino, japonés, coreano) se ven más afectados, mientras que los idiomas de la familia latina sufren menos impacto.
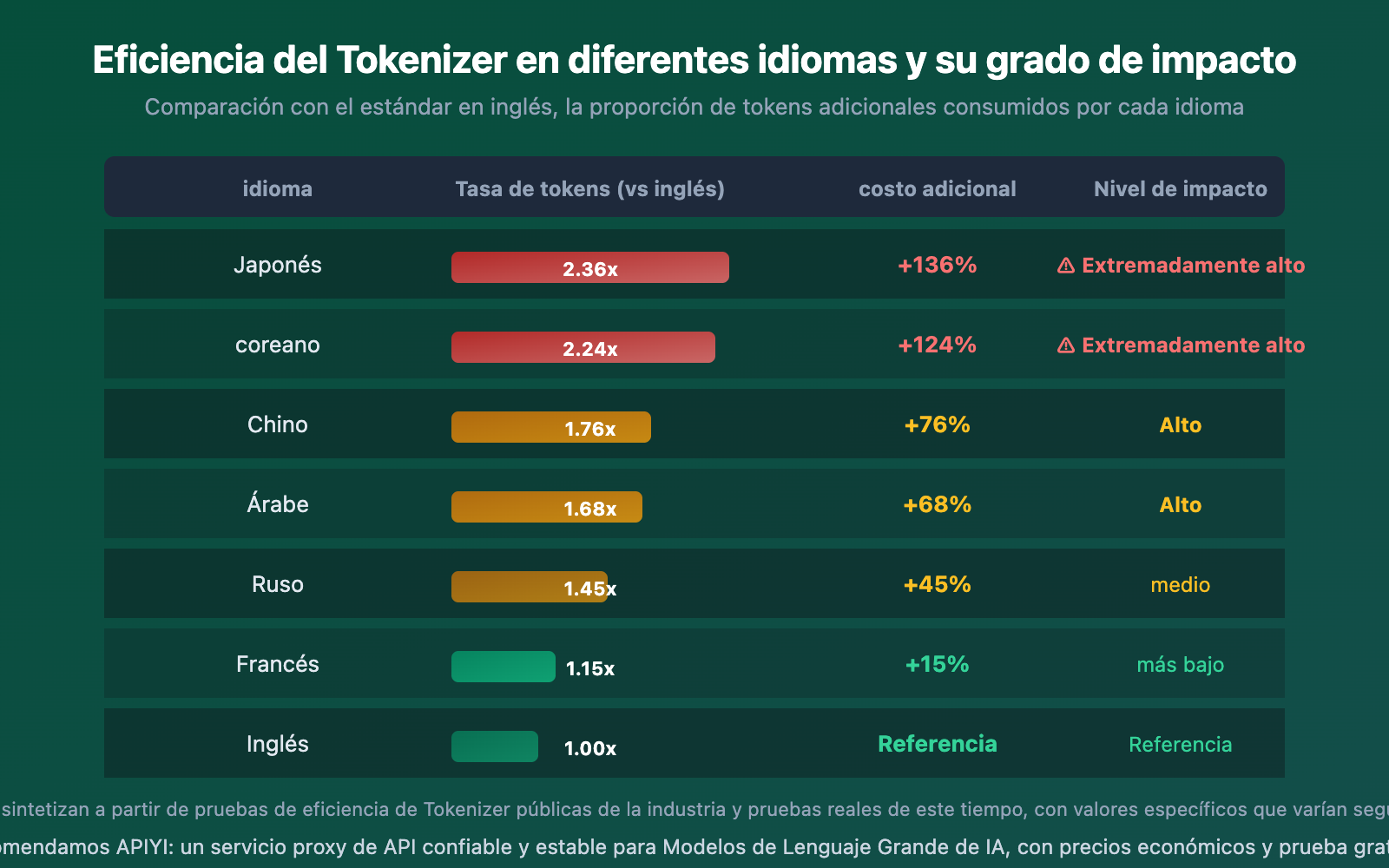
Los datos muestran claramente:
- El japonés se ve más afectado: La eficiencia de codificación del japonés en Gemini es solo de 0.82 caracteres/Token, lo que explica por qué el consumo de tokens aumenta significativamente al traducir artículos con mucho contenido en chino o japonés
- El francés tiene la menor diferencia: Los idiomas de la familia latina tienen diferencias de eficiencia del Tokenizer relativamente pequeñas (solo 2.01x), porque la mayoría de los Tokenizers se entrenan principalmente con corpus en inglés, lo que beneficia a los idiomas latinos
- El chino está en el medio: Aproximadamente 1.76 veces la referencia del inglés, pero la brecha se reduce cuando usas modelos optimizados para chino como DeepSeek o Qwen
🎯 Recomendación para traducción multilingüe: Si tus tareas de traducción incluyen idiomas CJK como japonés o coreano, elegir un modelo con mayor eficiencia de Tokenizer (como DeepSeek o Qwen) puede reducir significativamente los costos. A través de la interfaz unificada de APIYI en apiyi.com, puedes cambiar fácilmente entre diferentes modelos para hacer pruebas.
Guía de selección de escenarios: Gemini vs DeepSeek Tokenizer
| Caso de uso | Modelo recomendado | Razón principal |
|---|---|---|
| Traducción multilingüe a gran escala | DeepSeek V3.2 | Eficiencia de tokens alta + precio bajo, costo solo 1/12 |
| Entrega de traducción urgente | Gemini 3 Flash | 6-10 veces más rápido, ideal para escenarios con tiempo limitado |
| Traducción intensiva en idiomas CJK | DeepSeek V3.2 | Ventaja de eficiencia del Tokenizer CJK de 2.5x |
| Traducción de idiomas latinos | Diferencia mínima | Brecha de eficiencia entre ambos solo 2x, elige por precio |
| Escenarios de diálogo en tiempo real | Gemini 3 Flash | Baja latencia, mejor experiencia de usuario |
| Procesamiento por lotes sensible al costo | DeepSeek V3.2 | Costo total más bajo |
🎯 Consejo práctico: En proyectos reales a menudo necesitas equilibrar costo y velocidad. Te recomendamos integrar simultáneamente Gemini y DeepSeek a través de APIYI en apiyi.com, cambiando dinámicamente entre modelos según la urgencia de la tarea. La plataforma admite invocación unificada de todos los modelos principales.
Preguntas frecuentes
P1: ¿Es un error de facturación de API que Gemini consuma más tokens?
No es un error. Es un fenómeno normal causado por diferencias en la eficiencia de codificación del Tokenizer. Es como comprimir el mismo archivo con ZIP y RAR, que produce tamaños diferentes. Diferentes modelos generan cantidades distintas de tokens para el mismo texto con sus respectivos Tokenizers, pero el contenido procesado es exactamente el mismo. Nuestras pruebas verificaron que la diferencia en caracteres de salida es menor al 1%.
P2: ¿Significa que más tokens implica mejor calidad de traducción?
No. La cantidad de tokens solo refleja la forma de codificación del Tokenizer, no tiene relación con la calidad de la traducción. En pruebas reales, ambos modelos mostraron excelente calidad y completitud de traducción, con el número de líneas de salida completamente idéntico (64 líneas). Al elegir un modelo, debes enfocarte en calidad de traducción, velocidad y costo total, no solo en la cantidad de tokens.
P3: ¿Cómo optimizar el costo de tokens en traducción multilingüe en un proyecto?
Recomendamos las siguientes estrategias:
- Para idiomas CJK (chino, japonés, coreano), prioriza modelos con alta eficiencia de Tokenizer como DeepSeek
- Para idiomas latinos puedes elegir con flexibilidad, la brecha es menor
- Integra múltiples modelos a través de APIYI en apiyi.com, implementa enrutamiento automático por idioma con una API unificada
- Al configurar monitoreo de consumo de tokens, establece umbrales diferentes para cada modelo para evitar falsos positivos
Resumen
Conclusiones clave de la comparativa de eficiencia de Tokenizer entre Gemini y DeepSeek:
- Las diferencias de Token provienen del Tokenizer, no de un error: Para el mismo texto, el Tokenizer de DeepSeek codifica con una eficiencia 2-2.8 veces superior a Gemini, siendo la brecha más notable en idiomas CJK
- Las diferencias de costo se amplifican: Diferencia de eficiencia del Tokenizer (2-2.5x) × Diferencia de precio por Token (5-7x) = La brecha real de costos puede alcanzar 12 veces
- Equilibrio entre velocidad y costo: Gemini es 6-10 veces más rápido pero con costos de Token más altos, DeepSeek tiene costos bajos pero es más lento — elige según tu caso de uso
Entender las diferencias de eficiencia del Tokenizer es clave para optimizar los costos de uso de APIs de IA. En escenarios intensivos en Tokens como traducción multilingüe, elegir el modelo correcto puede ahorrar significativamente.
Recomendamos usar APIYI (apiyi.com) para acceder a múltiples modelos de forma unificada, cambiar entre ellos con una sola clave y encontrar la mejor relación costo-beneficio para cada escenario.
📚 Referencias
-
Benchmark de rendimiento de Tokenizer: Comparativa exhaustiva de eficiencia de Tokenizer en modelos principales
- Enlace:
llm-calculator.com/blog/tokenization-performance-benchmark - Descripción: Incluye datos de eficiencia de Tokenizer para GPT-4o, DeepSeek, Qwen y otros modelos
- Enlace:
-
Texto CJK y mejores prácticas con Modelos de Lenguaje Grande: Mecanismo de procesamiento de caracteres CJK en Tokenizers
- Enlace:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - Descripción: Análisis profundo de las diferencias de consumo de Tokens para idiomas CJK en diferentes Tokenizers
- Enlace:
-
Análisis del Tokenizer de Gemini: Principios del segmentador SentencePiece de Google Gemini
- Enlace:
dejan.ai/blog/gemini-toknizer - Descripción: Análisis detallado del mecanismo de codificación y características de eficiencia del vocabulario de 256K de Gemini
- Enlace:
-
Reporte técnico de DeepSeek V3: Optimización multilingüe del Tokenizer BPE a nivel de bytes
- Enlace:
arxiv.org/html/2412.19437v1 - Descripción: Filosofía de diseño del vocabulario de 128K de DeepSeek y eficiencia de compresión multilingüe
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a discutir en los comentarios. Para más recursos, visita el centro de documentación de APIYI en docs.apiyi.com