Author's Note: Seed 2.0 Lite 260228 has an input cost of just $0.25/M tokens, while Gemini 3.1 Pro Preview boasts a 1M context window and 77.1% reasoning capability on ARC-AGI-2. This article provides an in-depth comparison of the two models across six dimensions: benchmarks, pricing, context window, and more.
In February 2026, two models with distinctly different positioning were released in quick succession. ByteDance's Seed 2.0 Lite 260228 was launched via the official BytePlus channel, focusing on extreme cost-effectiveness. Meanwhile, Google DeepMind's Gemini 3.1 Pro Preview set a new record by doubling the reasoning capabilities of ARC-AGI-2.
Core Value: After reading this article, you'll know whether to choose Seed 2.0 Lite 260228 or Gemini 3.1 Pro Preview for different business scenarios, and how to find the optimal solution within an 8x price difference.

Core Differences: Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview
| Dimension | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview | Analysis |
|---|---|---|---|
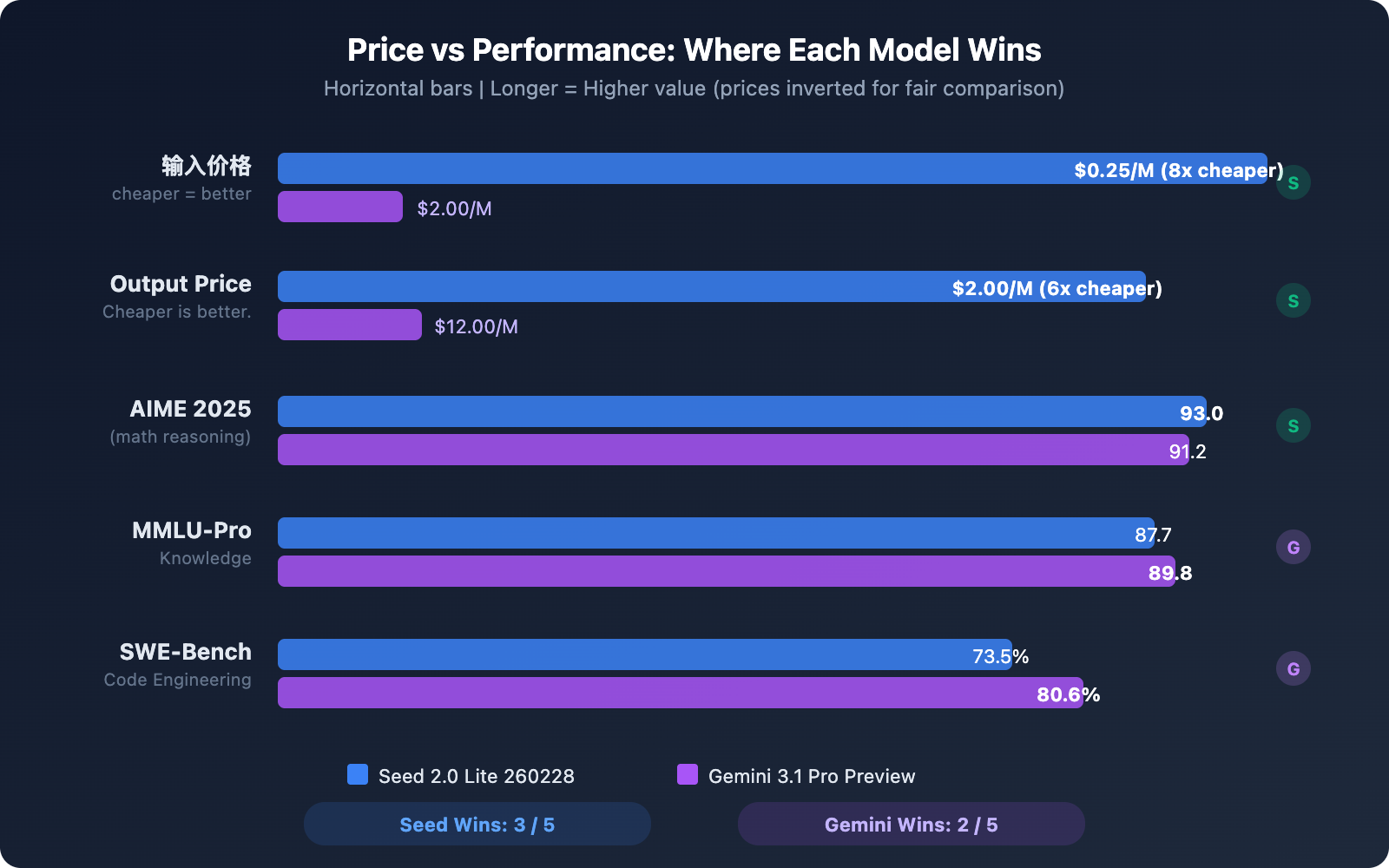
| Input Price | $0.25/M tokens | $2.00/M tokens | Seed is 8x cheaper |
| Output Price | $2.00/M tokens | $12.00/M tokens | Seed is 6x cheaper |
| Context Window | 256K tokens | 1M tokens | Gemini is 4x larger |
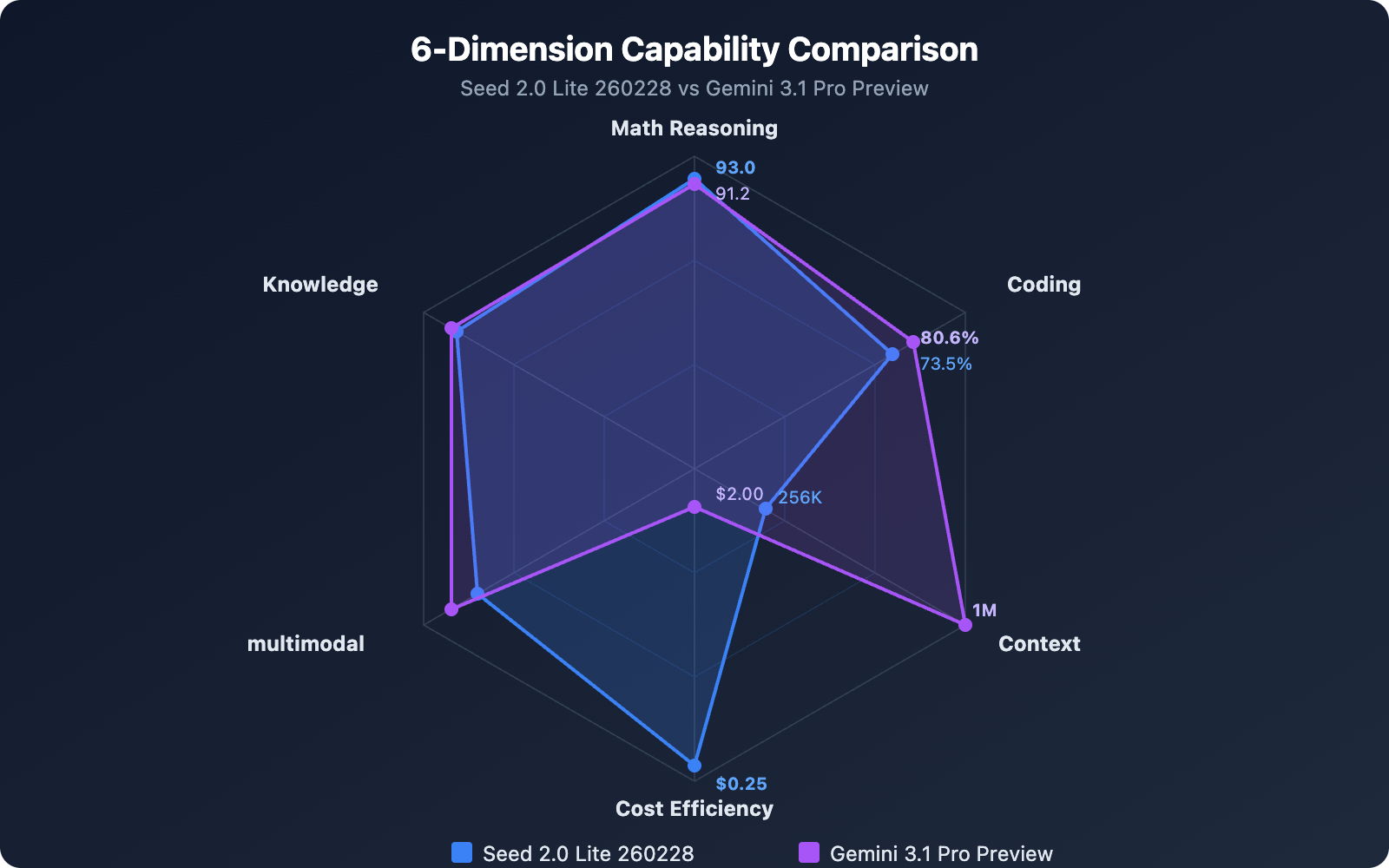
| AIME 2025 | 93.0 | 91.2 | Seed slightly higher |
| MMLU-Pro | 87.7 | 89.8 | Gemini slightly higher |
| SWE-Bench Verified | 73.5% | 80.6% | Gemini leads by 7 points |
Positioning Differences: Seed 2.0 Lite 260228 vs Gemini 3.1 Pro
These two models have fundamentally different positioning. Seed 2.0 Lite 260228 is a mid-tier model in ByteDance's Seed 2.0 series, targeting a cost-effective, general-purpose model for production environments. In contrast, Gemini 3.1 Pro Preview is Google DeepMind's flagship model, offering a significant upgrade in reasoning capabilities over Gemini 3 Pro.
From a pricing perspective, Seed 2.0 Lite's input cost is just one-eighth that of Gemini 3.1 Pro. However, Gemini 3.1 Pro offers a context window 4 times larger and stronger coding capabilities. Which model you choose depends on your specific application's needs regarding cost and performance.
Mathematical Reasoning Comparison
In the AIME 2025 mathematical reasoning benchmark, Seed 2.0 Lite 260228 scored 93.0, slightly edging out Gemini 3.1 Pro Preview's 91.2. This result is quite surprising—a mid-tier priced model outperforming a flagship competitor in mathematical reasoning.
It's worth noting that Seed 2.0 Pro (the flagship version) achieved a score of 98.3 on AIME 2025, indicating that ByteDance's Seed series has strong technical foundations in this area, an advantage that the Lite version inherits.
Knowledge Understanding Comparison
MMLU-Pro is a core benchmark for evaluating a model's comprehensive knowledge understanding. Gemini 3.1 Pro Preview scored 89.8 here, leading Seed 2.0 Lite 260228's 87.7 by about 2 percentage points. The gap is small, placing both models in the same performance tier.
Programming Capability Comparison
Programming is the area with the most significant performance gap between the two models.
Gemini 3.1 Pro Preview performed excellently with 80.6% on SWE-Bench Verified and a LiveCodeBench Pro Elo rating of 2887. Seed 2.0 Lite 260228 scored 73.5% on SWE-Bench Verified and 2233 on Codeforces.
In practical software engineering tasks (SWE-Bench), Gemini 3.1 Pro leads by about 7 percentage points, a gap worth considering for code-intensive projects.
Complete Benchmark Comparison: Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview
| Benchmark | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview | Advantage |
|---|---|---|---|
| AIME 2025 | 93.0 | 91.2 | Seed Lite |
| MMLU-Pro | 87.7 | 89.8 | Gemini |
| SWE-Bench Verified | 73.5% | 80.6% | Gemini |
| Codeforces / LiveCodeBench | 2233 | 2887 Elo | Gemini |
| ARC-AGI-2 | – | 77.1% | Gemini |
| GPQA Diamond | – | 94.3% | Gemini |
Overall, Gemini 3.1 Pro Preview is stronger in programming and reasoning, particularly in its performance on ARC-AGI-2 and SWE-Bench. Meanwhile, Seed 2.0 Lite 260228 pulls ahead in mathematical reasoning (AIME) and stays very close in knowledge understanding (MMLU-Pro).
Selection Advice: If your core needs are code engineering and complex reasoning, Gemini 3.1 Pro's 80.6% performance on SWE-Bench offers more assurance. If you're on a budget but need comprehensive general capabilities, Seed 2.0 Lite provides about 90% of the mathematical reasoning power for one-eighth of the price. You can call both models through the APIYI apiyi.com platform to quickly compare their actual performance in your specific use cases.
Pricing Comparison: Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview
Pricing is the most significant differentiator between these two models. Here's the complete cost comparison:
Tiered Pricing Comparison: Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview
| Pricing Dimension | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview |
|---|---|---|
| Input (Standard Range) | $0.25/M tokens (0-128K) | $2.00/M tokens (0-200K) |
| Input (Long Context Range) | $0.50/M tokens (128K-256K) | $4.00/M tokens (200K-1M) |
| Output (Standard Range) | $2.00/M tokens (0-128K) | $12.00/M tokens (0-200K) |
| Output (Long Context Range) | $4.00/M tokens (128K-256K) | $18.00/M tokens (200K-1M) |
| Billing Model | Pay-as-you-go Chat | Pay-as-you-go |
| Free Tier | BytePlus new user credits | Google AI Studio free tier |
Simulated Monthly Cost Comparison
Here are estimated monthly costs for different usage scenarios:
| Usage Scenario | Monthly Volume | Seed 2.0 Lite 260228 Cost | Gemini 3.1 Pro Preview Cost | Savings |
|---|---|---|---|---|
| Light Usage (Daily Chat) | 10M in + 5M out | $12.50 | $80.00 | 84% |
| Moderate Usage (Doc Processing) | 50M in + 20M out | $52.50 | $340.00 | 85% |
| Heavy Usage (Code Generation) | 200M in + 100M out | $250.00 | $1,600.00 | 84% |
Across all usage levels, Seed 2.0 Lite 260228 costs approximately 84-85% less than Gemini 3.1 Pro Preview. For individual developers and small teams with a monthly API budget under $100, Seed 2.0 Lite's cost advantage is very significant.
Cost Optimization Tip: A hybrid strategy using both models is optimal. Use Seed 2.0 Lite for daily conversations and document processing, and reserve Gemini 3.1 Pro for complex code engineering and deep reasoning tasks. The APIYI apiyi.com platform supports calling both models through a unified interface—you can switch by simply changing the
modelparameter without maintaining two separate SDKs.
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview Quick Start Guide
Minimal Example — Switch Between Models with a Unified Interface
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI Unified Interface
)
# Call Seed 2.0 Lite 260228 (Low-cost daily tasks)
response = client.chat.completions.create(
model="seed-2-0-lite-260228",
messages=[{"role": "user", "content": "Summarize the key points of this report"}]
)
print("Seed Lite:", response.choices[0].message.content)
# Call Gemini 3.1 Pro Preview (Complex reasoning tasks)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Analyze the security vulnerabilities in this code and provide fixes"}]
)
print("Gemini Pro:", response.choices[0].message.content)
View Full Comparison Test Code (Includes Latency and Cost Calculation)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
MODELS = {
"seed-2-0-lite-260228": {"input_price": 0.25, "output_price": 2.00},
"gemini-3.1-pro-preview": {"input_price": 2.00, "output_price": 12.00},
}
def compare_models(prompt: str, system_prompt: str = None):
"""Compare response quality, speed, and cost between the two models"""
results = {}
for model_name, pricing in MODELS.items():
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=messages,
max_tokens=2000
)
elapsed = time.time() - start
usage = response.usage
cost = (usage.prompt_tokens * pricing["input_price"]
+ usage.completion_tokens * pricing["output_price"]) / 1_000_000
results[model_name] = {
"content": response.choices[0].message.content,
"time": f"{elapsed:.2f}s",
"tokens": f"{usage.prompt_tokens}+{usage.completion_tokens}",
"cost": f"${cost:.6f}"
}
for name, r in results.items():
print(f"\n{'='*50}")
print(f"Model: {name}")
print(f"Time: {r['time']} | Tokens: {r['tokens']} | Cost: {r['cost']}")
print(f"Response: {r['content'][:200]}...")
compare_models("Explain the time complexity analysis of the quicksort algorithm")
Quick Start: With the APIYI apiyi.com platform, you can use a single API key to call both Seed 2.0 Lite and Gemini 3.1 Pro, eliminating the hassle of registering separately with BytePlus and Google Cloud. The platform offers free testing credits, and you can get set up in just 5 minutes.
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview: Scenario Recommendations
Based on the capabilities and pricing differences of the two models, here are recommendations for different scenarios:
Scenarios to choose Seed 2.0 Lite 260228:
- Daily conversation and customer service systems: Low cost of $0.25/M tokens, suitable for high-frequency invocation scenarios.
- Document summarization and information extraction: AIME 93.0 and MMLU-Pro 87.7 indicate sufficient knowledge comprehension.
- Budget-sensitive startup projects: Monthly cost is only 15-16% of Gemini's.
- Multimodal content understanding: Supports text, image, and video input; 256K context window meets most needs.
- Batch data processing: Low unit price makes the total cost of large-scale batch processing manageable.
Scenarios to choose Gemini 3.1 Pro Preview:
- Complex code engineering: SWE-Bench 80.6% is more reliable for real-world development tasks.
- Ultra-long document analysis: 1M token context window can process entire books or large codebases.
- Cutting-edge reasoning tasks: ARC-AGI-2 77.1% and GPQA Diamond 94.3% represent top-tier reasoning.
- Tasks requiring deep thinking: The
thinking_levelparameter supports low/medium/high/max four-level adjustment. - Code security audits: LiveCodeBench Pro 2887 Elo indicates competition-level programming ability.
Scenario Suggestion: The best practice is a hybrid deployment of both models. The APIYI apiyi.com platform supports unified API invocation. You can automatically route tasks to different models at the application layer based on task complexity, achieving the optimal balance of performance and cost.
Frequently Asked Questions
Q1: Seed 2.0 Lite 260228 surpasses Gemini 3.1 Pro in math reasoning. Why would I still choose Gemini?
AIME 2025 is just one dimension of mathematical reasoning. Gemini 3.1 Pro's ARC-AGI-2 (77.1%) tests reasoning with novel logical patterns, and its GPQA Diamond (94.3%) tests graduate-level scientific reasoning. Gemini has a greater advantage in these dimensions. Furthermore, the SWE-Bench 80.6% score for practical code engineering ability is a key metric for many developers. If your scenario focuses on mathematical calculations, Seed Lite is indeed more cost-effective. If it focuses on complex reasoning and code, Gemini is more suitable.
Q2: Is the 8x price difference worth it? When should I choose the more expensive Gemini 3.1 Pro?
Choosing Gemini is worth it when the following conditions are met: (1) A single task requires processing input exceeding 256K tokens; (2) You need SWE-Bench 80%+ level code engineering reliability; (3) The task has extremely high requirements for reasoning depth (requiring thinking_level=max). For most daily API calls, the performance of Seed 2.0 Lite is completely sufficient. An 8x cost difference means you can make 8x the number of calls with the same budget. Using APIYI apiyi.com allows for flexible switching; you don't have to choose just one.
Q3: How can I quickly compare the performance of the two models for my specific scenario?
The fastest way:
- Visit APIYI apiyi.com to register an account and obtain a unified API key.
- Use the comparative test code provided in this article, using your actual business prompt as input.
- Compare the response quality, speed, and cost of both models to choose the most suitable one.
Summary
The core conclusions for Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview:
- 8x Price Difference: Seed Lite input $0.25/M vs Gemini $2.00/M, output $2.00/M vs $12.00/M. With the same budget, you get 6-8 times more calls with Seed.
- Seed Slightly Better at Math Reasoning: On AIME 2025, Seed Lite scores 93.0, beating Gemini's 91.2. It delivers flagship-level performance at a mid-range price.
- Gemini Leads in Code Engineering: SWE-Bench 80.6% vs 73.5%, LiveCodeBench 2887 vs Codeforces 2233. Gemini is more reliable for real-world development tasks.
- Gemini Dominates Context Length: 1M vs 256K. Gemini is better suited for analyzing ultra-long documents and large codebases.
- Best Strategy is a Hybrid Approach: Use Seed Lite for daily tasks to save costs, and switch to Gemini for complex reasoning to ensure quality.
We recommend accessing both models through APIYI (apiyi.com). The platform offers free credits and an OpenAI-compatible interface, allowing you to switch between models freely with just one API key.
References
-
ByteDance Seed 2.0 Official Introduction: Capabilities and benchmark data for the Seed 2.0 series.
- Link:
seed.bytedance.com/en/seed2 - Description: Technical specifications and test results for the full Pro/Lite/Mini series.
- Link:
-
Google Gemini 3.1 Pro Official Blog: Release information and detailed capabilities of Gemini 3.1 Pro.
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Description: Core benchmark scores (like ARC-AGI-2, SWE-Bench) and feature details.
- Link:
-
Gemini 3.1 Pro Model Card: Official model card from Google DeepMind.
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Description: Detailed technical specifications, safety evaluations, and usage guidelines.
- Link:
-
BytePlus ModelArk Pricing: Official API pricing for Seed models.
- Link:
docs.byteplus.com/en/docs/ModelArk/1544106 - Description: Details on tiered pricing and price lists for each model.
- Link:
-
Artificial Analysis – Model Comparison: Independent third-party evaluation platform.
- Link:
artificialanalysis.ai/models/gemini-3-1-pro-preview - Description: Comprehensive analysis data on performance, price, and latency.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to share your experience using Seed 2.0 Lite and Gemini 3.1 Pro in the comments. For more model comparison guides, visit the APIYI documentation center at docs.apiyi.com.