ملاحظة المؤلف: يبلغ سعر إدخال Seed 2.0 Lite 260228 فقط 0.25 دولار لكل مليون رمز، بينما يتمتع Gemini 3.1 Pro Preview بنافذة سياق تبلغ مليون رمز وقدرة استدلالية بنسبة 77.1% في اختبار ARC-AGI-2. تقارن هذه المقالة بعمق بين النموذجين من 6 أبعاد: الاختبارات المعيارية، التسعير، نافذة السياق، وغيرها.
في فبراير 2026، تم إطلاق نموذجين مختلفين تمامًا في التوجه. أطلقت ByteDance Seed 2.0 Lite 260228 عبر قناة الترحيل الرسمية BytePlus، مع التركيز على القيمة المثلى مقابل السعر؛ بينما سجل Gemini 3.1 Pro Preview من Google DeepMind رقمًا قياسيًا جديدًا بقدرة استدلالية تضاعفت في اختبار ARC-AGI-2.
القيمة الأساسية: بعد قراءة هذه المقالة، ستتمكن من تحديد متى تختار Seed 2.0 Lite 260228 ومتى تختار Gemini 3.1 Pro Preview في سيناريوهات العمل المختلفة، وكيفية إيجاد الحل الأمثل ضمن فرق سعر يبلغ 8 أضعاف.
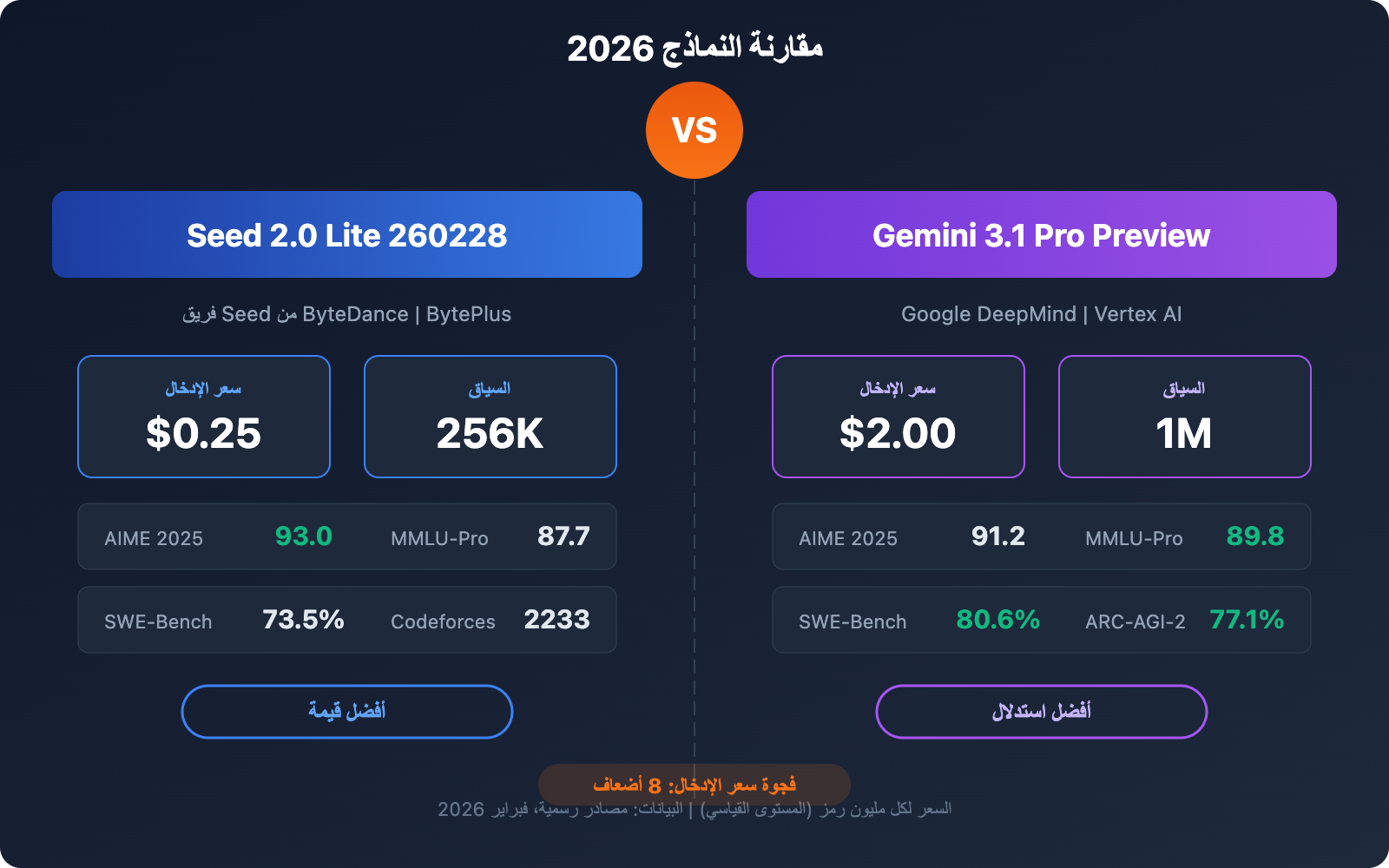
الفروق الأساسية بين Seed 2.0 Lite 260228 و Gemini 3.1 Pro Preview
| البعد | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview | تحليل الفرق |
|---|---|---|---|
| سعر الإدخال | 0.25 دولار / مليون رمز | 2.00 دولار / مليون رمز | Seed أرخص بـ 8 مرات |
| سعر الإخراج | 2.00 دولار / مليون رمز | 12.00 دولار / مليون رمز | Seed أرخص بـ 6 مرات |
| نافذة السياق | 256 ألف رمز | 1 مليون رمز | Gemini أكبر بـ 4 مرات |
| AIME 2025 | 93.0 | 91.2 | Seed أعلى قليلاً |
| MMLU-Pro | 87.7 | 89.8 | Gemini أعلى قليلاً |
| SWE-Bench Verified | 73.5% | 80.6% | Gemini يتقدم بـ 7 نقاط |
الفرق في التوجه بين Seed 2.0 Lite 260228 و Gemini 3.1 Pro
هناك فرق جوهري في توجه هذين النموذجين. Seed 2.0 Lite 260228 هو نموذج متوسط المستوى ضمن سلسلة Seed 2.0 من ByteDance، وموجه نحو أن يكون نموذجًا عامًا عالي الجودة من حيث التكلفة لبيئات الإنتاج. بينما Gemini 3.1 Pro Preview هو النموذج الرئيسي من Google DeepMind، وقد حقق تحسينًا كبيرًا في قدرات الاستدلال مقارنة بـ Gemini 3 Pro.
من ناحية السعر، تبلغ تكلفة إدخال Seed 2.0 Lite ثُمن تكلفة Gemini 3.1 Pro فقط. لكن Gemini 3.1 Pro يوفر نافذة سياق أكبر بأربع مرات وقدرات هندسة برمجية أقوى. اختيار النموذج المناسب يعتمد على متطلبات التكلفة والقدرات المحددة لسيناريو تطبيقك.
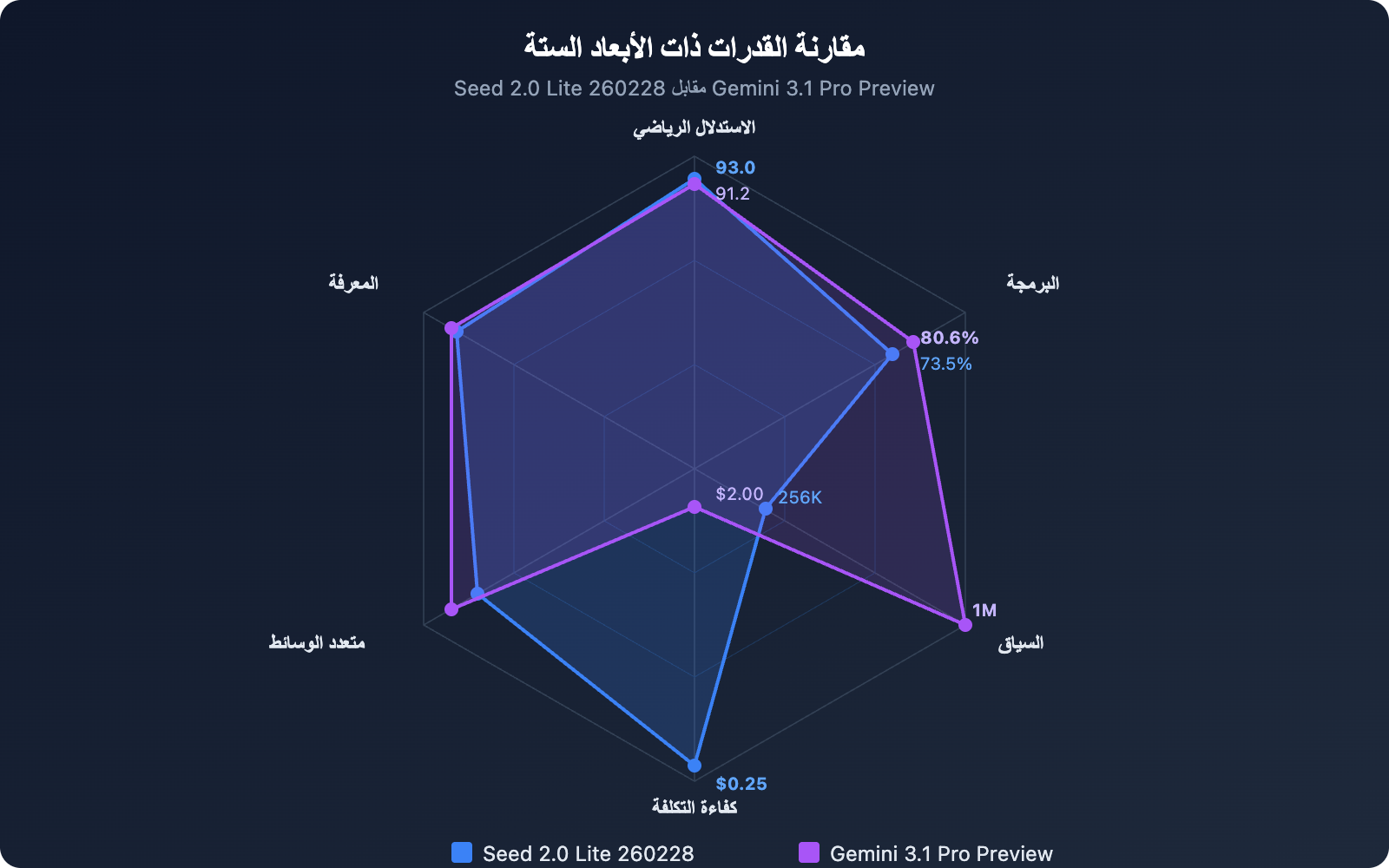
مقارنة معايير الأداء بين Seed 2.0 Lite 260228 و Gemini 3.1 Pro Preview
مقارنة قدرات التفكير الرياضي
في اختبار AIME 2025 المعياري للتفكير الرياضي، حصل Seed 2.0 Lite 260228 على درجة 93.0، متفوقًا قليلاً على Gemini 3.1 Pro Preview الذي حصل على 91.2. هذه النتيجة مفاجئة إلى حد ما – حيث تفوق نموذج متوسط السعر على منافسه الرائد في مجال التفكير الرياضي.
من المهم ملاحظة أن Seed 2.0 Pro (الإصدار الرائد) حقق 98.3 نقطة في AIME 2025، مما يدل على أن سلسلة Seed من ByteDance تمتلك تراكمًا تقنيًا عميقًا في التفكير الرياضي، وقد ورث الإصدار Lite هذه الميزة.
مقارنة قدرات الفهم المعرفي
يُعد MMLU-Pro معيارًا أساسيًا لقياس قدرات النموذج الشاملة في الفهم المعرفي. في هذا الاختبار، حصل Gemini 3.1 Pro Preview على درجة 89.8، متقدمًا على Seed 2.0 Lite 260228 الذي حصل على 87.7 بحوالي نقطتين مئويتين. الفرق بينهما ليس كبيرًا، وكلاهما في نفس المستوى.
مقارنة القدرات البرمجية
القدرات البرمجية هي المجال الذي يظهر فيه أكبر فرق بين النموذجين.
أظهر Gemini 3.1 Pro Preview أداءً متميزًا في SWE-Bench Verified حيث حقق 80.6%، وفي LiveCodeBench Pro Elo حصل على تصنيف 2887. بينما حصل Seed 2.0 Lite 260228 على 73.5% في SWE-Bench Verified، وتصنيف 2233 في Codeforces.
في مهام هندسة البرمجيات العملية (SWE-Bench)، تقدم Gemini 3.1 Pro Preview بحوالي 7 نقاط مئوية، وهو فرق يستحق النظر فيه للمشاريع المكثفة بالشفرة البرمجية.
مقارنة معايير الأداء الكاملة بين Seed 2.0 Lite 260228 و Gemini 3.1 Pro Preview
| اختبار المعيار | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview | الطرف المتفوق |
|---|---|---|---|
| AIME 2025 | 93.0 | 91.2 | Seed Lite |
| MMLU-Pro | 87.7 | 89.8 | Gemini |
| SWE-Bench Verified | 73.5% | 80.6% | Gemini |
| Codeforces / LiveCodeBench | 2233 | 2887 Elo | Gemini |
| ARC-AGI-2 | – | 77.1% | Gemini |
| GPQA Diamond | – | 94.3% | Gemini |
بشكل عام، يُظهر Gemini 3.1 Pro Preview قوة شاملة أكبر في البرمجة والاستدلال، خاصةً في أدائه في ARC-AGI-2 و SWE-Bench. بينما يتفوق Seed 2.0 Lite 260228 في التفكير الرياضي (AIME)، ويكون الفرق في الفهم المعرفي (MMLU-Pro) ضئيلًا.
نصيحة للاختيار: إذا كان احتياجك الأساسي هو هندسة البرمجيات والاستدلال المعقد، فإن أداء Gemini 3.1 Pro في SWE-Bench بنسبة 80.6% يوفر ضمانًا أكبر. إذا كان ميزانيتك محدودة ولكنك تحتاج إلى قدرات عامة شاملة، فإن Seed 2.0 Lite يقدم 90% من قدرات التفكير الرياضي بسعر ثمن سعر النموذج الآخر. يمكنك من خلال منصة APIYI على apiyi.com استدعاء هذين النموذجين في نفس الوقت، ومقارنة أدائهما الفعلي في سيناريوهاتك المحددة بسرعة.
مقارنة التسعير بين Seed 2.0 Lite 260228 و Gemini 3.1 Pro Preview
التسعير هو أكبر نقطة اختلاف بين هذين النموذجين. فيما يلي مقارنة تكلفة كاملة:
مقارنة التسعير المتدرج بين Seed 2.0 Lite 260228 و Gemini 3.1 Pro Preview
| بُعد التسعير | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview |
|---|---|---|
| الإدخال (النطاق القياسي) | 0.25 دولار / مليون رمز (0-128 ألف) | 2.00 دولار / مليون رمز (0-200 ألف) |
| الإدخال (نطاق النصوص الطويلة) | 0.50 دولار / مليون رمز (128 ألف-256 ألف) | 4.00 دولار / مليون رمز (200 ألف-1 مليون) |
| الإخراج (النطاق القياسي) | 2.00 دولار / مليون رمز (0-128 ألف) | 12.00 دولار / مليون رمز (0-200 ألف) |
| الإخراج (نطاق النصوص الطويلة) | 4.00 دولار / مليون رمز (128 ألف-256 ألف) | 18.00 دولار / مليون رمز (200 ألف-1 مليون) |
| طريقة الفوترة | الدفع حسب الاستخدام (Chat) | الدفع حسب الاستخدام |
| الحد المجاني | هدية للمستخدمين الجدد في BytePlus | الطبقة المجانية في Google AI Studio |
محاكاة التكلفة الفعلية بين Seed 2.0 Lite 260228 و Gemini 3.1 Pro Preview
فيما يلي تقديرات التكلفة الشهرية في سيناريوهات استخدام مختلفة:
| سيناريو الاستخدام | حجم الاستدعاءات الشهري | تكلفة Seed 2.0 Lite 260228 | تكلفة Gemini 3.1 Pro Preview | نسبة التوفير |
|---|---|---|---|---|
| استخدام خفيف (محادثات يومية) | 10 مليون إدخال + 5 مليون إخراج | 12.50 دولار | 80.00 دولار | 84% |
| استخدام متوسط (معالجة مستندات) | 50 مليون إدخال + 20 مليون إخراج | 52.50 دولار | 340.00 دولار | 85% |
| استخدام مكثف (توليد شفرة) | 200 مليون إدخال + 100 مليون إخراج | 250.00 دولار | 1,600.00 دولار | 84% |
في جميع مستويات الاستخدام، تبلغ تكلفة Seed 2.0 Lite 260228 أقل من تكلفة Gemini 3.1 Pro Preview بحوالي 84-85%. هذه الميزة التكلفية واضحة جدًا للمطورين الأفراد والفرق الصغيرة ذات ميزانية API الشهرية أقل من 100 دولار.
نصيحة لتحسين التكلفة: الاستخدام المختلط للنموذجين هو الاستراتيجية المثلى. يمكن تفويض المحادثات اليومية ومعالجة المستندات إلى Seed 2.0 Lite، بينما تُترك مهام هندسة البرمجيات المعقدة والاستدلال العميق لـ Gemini 3.1 Pro. تدعم منصة APIYI على apiyi.com استدعاء النموذجين من خلال واجهة موحدة، حيث يمكن التبديل بينهما بتغيير معلمة
modelفقط، دون الحاجة إلى صيانة مجموعتي SDK.
مثال بسيط للغاية — التبديل بين نموذجين بواجهة موحدة
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # واجهة APIYI الموحدة
)
# استدعاء Seed 2.0 Lite 260228 (لمهام يومية منخفضة التكلفة)
response = client.chat.completions.create(
model="seed-2-0-lite-260228",
messages=[{"role": "user", "content": "لخص النقاط الأساسية لهذا التقرير"}]
)
print("Seed Lite:", response.choices[0].message.content)
# استدعاء Gemini 3.1 Pro Preview (لمهام التفكير المعقدة)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "حلل الثغرات الأمنية في هذا الكود واقترح حلولاً لإصلاحها"}]
)
print("Gemini Pro:", response.choices[0].message.content)
عرض كود الاختبار المقارن الكامل (يشمل حساب الوقت والتكلفة)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
MODELS = {
"seed-2-0-lite-260228": {"input_price": 0.25, "output_price": 2.00},
"gemini-3.1-pro-preview": {"input_price": 2.00, "output_price": 12.00},
}
def compare_models(prompt: str, system_prompt: str = None):
"""مقارنة جودة وسرعة وتكلفة استجابة النموذجين"""
results = {}
for model_name, pricing in MODELS.items():
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=messages,
max_tokens=2000
)
elapsed = time.time() - start
usage = response.usage
cost = (usage.prompt_tokens * pricing["input_price"]
+ usage.completion_tokens * pricing["output_price"]) / 1_000_000
results[model_name] = {
"content": response.choices[0].message.content,
"time": f"{elapsed:.2f}s",
"tokens": f"{usage.prompt_tokens}+{usage.completion_tokens}",
"cost": f"${cost:.6f}"
}
for name, r in results.items():
print(f"\n{'='*50}")
print(f"النموذج: {name}")
print(f"الوقت: {r['time']} | الرموز: {r['tokens']} | التكلفة: {r['cost']}")
print(f"الرد: {r['content'][:200]}...")
compare_models("اشرح تحليل التعقيد الزمني لخوارزمية الفرز السريع")
بدء سريع: من خلال منصة APIYI (apiyi.com)، يمكنك استخدام مفتاح API واحد لاستدعاء كل من Seed 2.0 Lite و Gemini 3.1 Pro، مما يلغي الحاجة للتسجيل بشكل منفصل في BytePlus و Google Cloud. توفر المنصة رصيد تجريبي مجاني، ويمكنك إكمال عملية الدمج في 5 دقائق.

Seed 2.0 Lite 260228 مقابل Gemini 3.1 Pro Preview: توصيات حسب السيناريو
بناءً على اختلاف قدرات النموذجين وتكاليفهما، إليك توصياتنا للسيناريوهات المختلفة:
سيناريوهات تفضيل Seed 2.0 Lite 260228:
- المحادثات اليومية وأنظمة دعم العملاء: تكلفة منخفضة تصل إلى 0.25 دولار لكل مليون رمز، مما يجعلها مناسبة للاستدعاءات عالية التكرار.
- تلخيص المستندات واستخراج المعلومات: تشير درجات AIME 93.0 و MMLU-Pro 87.7 إلى قدرة كافية على فهم المعرفة.
- المشاريع الناشئة الحساسة للميزانية: التكلفة الشهرية تبلغ حوالي 15-16% فقط من تكلفة Gemini.
- فهم المحتوى متعدد الوسائط: يدخل النص والصور والفيديو، ونافذة سياق 256 ألف رمز تلبي معظم الاحتياجات.
- معالجة البيانات المجمعة: السعر المنخفض للوحدة يجعل التكلفة الإجمالية للمعالجة المجمعة واسعة النطاق قابلة للتحكم.
سيناريوهات تفضيل Gemini 3.1 Pro Preview:
- هندسة البرمجيات المعقدة: درجة SWE-Bench 80.6% توفر موثوقية أعلى في مهام التطوير الفعلية.
- تحليل المستندات فائقة الطول: نافذة سياق مليون رمز تتيح معالجة كتب كاملة أو مستودعات كود ضخمة.
- مهام الاستدلال المتقدمة: تمثل درجات ARC-AGI-2 77.1% و GPQA Diamond 94.3% قدرات استدلالية من الطراز الأول.
- المهام التي تتطلب تفكيرًا عميقًا: معلمة
thinking_levelتدعم أربعة مستويات للضبط: منخفض/متوسط/مرتفع/أقصى. - مراجعة أمان الكود: قدرة برمجة تنافسية بمستوى 2887 Elo على LiveCodeBench Pro.
نصيحة عملية: أفضل الممارسات هي النشر المختلط للنموذجين. تدعم منصة APIYI (apiyi.com) استدعاء واجهة موحدة، مما يتيح لك توجيه المهام تلقائيًا إلى النموذج المناسب بناءً على تعقيد المهمة على مستوى التطبيق، لتحقيق التوازن الأمثل بين الأداء والتكلفة.
الأسئلة الشائعة
س1: إذا كان Seed 2.0 Lite 260228 يتفوق في الاستدلال الرياضي على Gemini 3.1 Pro، فلماذا نختار Gemini؟
اختبار AIME 2025 هو مجرد بعد واحد من أبعاد الاستدلال الرياضي. يختبر Gemini 3.1 Pro في ARC-AGI-2 (77.1%) القدرة على استدلال أنماط منطقية جديدة تمامًا، وفي GPQA Diamond (94.3%) يختبر الاستدلال العلمي على مستوى الدراسات العليا، وهذه الأبعاد يكون فيها Gemini متفوقًا بشكل أكبر. بالإضافة إلى ذلك، قدرة هندسة الكود العملية بنسبة 80.6% في SWE-Bench هي المؤشر الأكثر أهمية للعديد من المطورين. إذا كان سيناريو استخدامك يركز على الحسابات الرياضية، فإن Seed Lite هو بالفعل خيار أكثر توفيرًا؛ أما إذا كان يركز على الاستدلال المعقد والبرمجة، فإن Gemini هو الأنسب.
س2: هل الفارق في السعر (8 أضعاف) يستحق ذلك؟ متى يجب اختيار Gemini 3.1 Pro الأغلى؟
يستحق اختيار Gemini عندما تتوفر الشروط التالية: (1) الحاجة إلى معالجة مدخلات تتجاوز 256 ألف رمز في مهمة واحدة؛ (2) الحاجة إلى موثوقية في هندسة الكود بمستوى 80%+ على SWE-Bench؛ (3) المهمة تتطلب عمقًا استدلاليًا عاليًا جدًا (بحاجة إلى thinking_level=max). بالنسبة لمعظم استدعاءات API اليومية، فإن أداء Seed 2.0 Lite كافٍ تمامًا، والفارق في التكلفة بمقدار 8 أضعاف يعني أنه بنفس الميزانية يمكنك إجراء 8 أضعاف عدد الاستدعاءات. من خلال APIYI (apiyi.com) يمكنك التبديل بمرونة دون الحاجة للاختيار بينهما.
س3: كيف يمكنني المقارنة السريعة لأداء النموذجين في سيناريو استخدامي؟
أسرع طريقة هي:
- زيارة APIYI (apiyi.com) وإنشاء حساب للحصول على مفتاح API موحد.
- استخدام كود الاختبار المقارن المقدم في هذه المقالة، وإدخال الموجه الفعلي الخاص بمشروعك.
- مقارنة جودة الاستجابة والسرعة والتكلفة للنموذجين، واختيار الأنسب.
الخلاصة
الاستنتاجات الأساسية لمقارنة Seed 2.0 Lite 260228 مقابل Gemini 3.1 Pro Preview:
- فارق السعر 8 أضعاف: إدخال Seed Lite بسعر $0.25 لكل مليون رمز مقابل $2.00 لكل مليون رمز لـ Gemini، والإخراج بسعر $2.00 لكل مليون رمز مقابل $12.00 لكل مليون رمز. بنفس الميزانية، يمكنك إجراء 6-8 أضعاف عدد الاستدعاءات باستخدام Seed مقارنة بـ Gemini.
- التفكير الرياضي: Seed يتفوق قليلاً: في اختبار AIME 2025، حقق Seed Lite 93.0 مقابل 91.2 لـ Gemini، مما يعني أداءً من الطراز الأول بسعر متوسط المدى.
- هندسة البرمجيات: Gemini يتقدم: في اختبار SWE-Bench، حقق Gemini 80.6% مقابل 73.5% لـ Seed، وفي LiveCodeBench 2887 مقابل 2233 في Codeforces. يبدو Gemini أكثر موثوقية في مهام التطوير الواقعية.
- نافذة السياق: Gemini يسحق المنافسة: 1 مليون رمز مقابل 256 ألف رمز، مما يجعل Gemini مناسبًا لتحليل المستندات الطويلة جدًا ومستودعات التعليمات البرمجية الكبيرة.
- أفضل استراتيجية هي الاستخدام المختلط: استخدم Seed Lite للمهام اليومية لتوفير التكلفة، واستخدم Gemini للتفكير المعقد لضمان الجودة.
نوصي بالوصول الموحد لكلا النموذجين عبر منصة APIYI على apiyi.com. توفر المنصة رصيدًا مجانيًا وواجهة متوافقة مع OpenAI، مما يتيح لك التبديل بحرية بين النماذج باستخدام مفتاح API واحد فقط.
المراجع
-
التعريف الرسمي لـ ByteDance Seed 2.0: قدرات وسلسلة نماذج Seed 2.0 وبيانات المعايير
- الرابط:
seed.bytedance.com/en/seed2 - الوصف: المواصفات الفنية ونتائج الاختبارات لسلسلة النماذج الكاملة Pro/Lite/Mini
- الرابط:
-
المدونة الرسمية لـ Google Gemini 3.1 Pro: معلومات إصدار Gemini 3.1 Pro وتفصيل القدرات
- الرابط:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - الوصف: النتائج الأساسية في المعايير مثل ARC-AGI-2 و SWE-Bench وخصائص الوظائف
- الرابط:
-
بطاقة النموذج الرسمية لـ Gemini 3.1 Pro: البطاقة الرسمية للنموذج من Google DeepMind
- الرابط:
deepmind.google/models/model-cards/gemini-3-1-pro/ - الوصف: المواصفات الفنية التفصيلية، وتقييمات السلامة، ودليل الاستخدام
- الرابط:
-
تسعير BytePlus ModelArk: التسعير الرسمي لـ API لنماذج Seed
- الرابط:
docs.byteplus.com/en/docs/ModelArk/1544106 - الوصف: تفاصيل التسعير التدريجي وجداول أسعار النماذج المختلفة
- الرابط:
-
Artificial Analysis – مقارنة النماذج: منصة تقييم مستقلة من طرف ثالث
- الرابط:
artificialanalysis.ai/models/gemini-3-1-pro-preview - الوصف: بيانات التحليل الشاملة للأداء والسعر وزمن الاستجابة
- الرابط:
المؤلف: فريق APIYI التقني
التواصل التقني: نرحب بمشاركتك لتجربتك في استخدام Seed 2.0 Lite و Gemini 3.1 Pro في قسم التعليقات. لمزيد من أدلة مقارنة النماذج، يمكنك زيارة مركز وثائق APIYI على docs.apiyi.com





