Author's Note: GPT-5.4 or Claude Opus 4.6? The two most noteworthy flagship AI models of 2026 go head-to-head. This article summarizes the latest real-world data from Chatbot Arena, SWE-bench, ARC-AGI-2, and OpenClaw PinchBench, providing clear selection advice across four dimensions: coding, reasoning, agent tasks, and cost-effectiveness.

GPT-5.4 vs Claude Opus 4.6: Core Differences at a Glance
When choosing a flagship Large Language Model, these key dimensions tell you everything you need to know:
| Comparison Dimension | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| Release Date | Late 2025 | Feb 2026 |
| Chatbot Arena ELO | 1463 | 1503 (#1) |
| AI General Intelligence Index | 57 | 53 |
| API Input Price | $2.50/M tokens | $5.00/M tokens |
| API Output Price | $15.00/M tokens | $25.00/M tokens |
| Context Window | ~1M tokens | 200K (1M Beta) |
| Max Output Length | — | 128K tokens |
| Status | Active | Active |
Core Conclusion: GPT-5.4 has a higher general intelligence index and is roughly 50% cheaper. Claude Opus 4.6 ranks #1 globally in Chatbot Arena user satisfaction and is more powerful for complex coding and agent-based tasks.
🎯 Quick Suggestion: If you're a price-sensitive developer, GPT-5.4 offers better value. If your project demands complex code generation or long-document processing, Opus 4.6 is the better investment. We recommend using APIYI (apiyi.com) to access both models simultaneously for real-world testing; the platform supports quick switching via a unified API interface.
Authoritative Benchmarks: GPT-5.4 vs. Claude Opus 4.6 Full-Dimensional Comparison
Reasoning and Knowledge Capability Comparison
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Description |
|---|---|---|---|
| GPQA Diamond (Graduate-level Science) | 93.2% | 91.3% | GPT-5.4 Wins |
| MMLU (Encyclopedic Knowledge) | 89.6% | 91.1% | Opus 4.6 Wins |
| ARC-AGI-2 (Abstract Reasoning) | 52.9% | 68.8% | Opus 4.6 Significant Lead |
| BigLaw Bench (Legal Professional) | — | 90.2% | Opus 4.6 Specialized Advantage |
| MRCR v2 (1M Long Context) | — | 76% | Opus 4.6 Leading in Ultra-long Documents |
| GDPval-AA ELO (Professional Tasks) | 1462 | 1606 | Opus 4.6 Significantly Outperforms |
Analysis: GPT-5.4 holds a slight edge in scientific reasoning (GPQA Diamond). However, Claude Opus 4.6 performs stronger in abstract reasoning (leading by 16 percentage points in ARC-AGI-2), professional knowledge work, and long context processing.
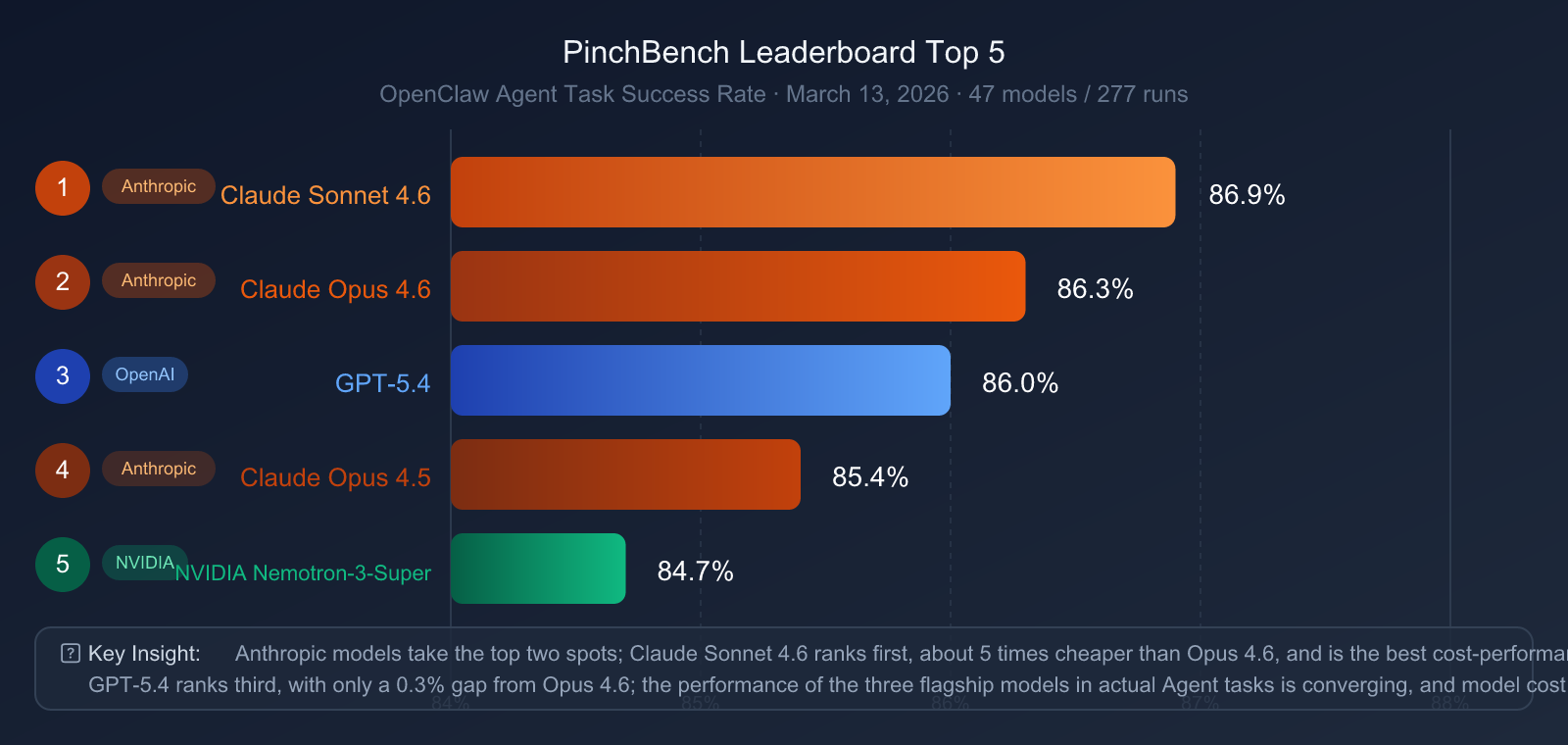
| Rank | Model | PinchBench Success Rate |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% |
| 🥈 2 | Claude Opus 4.6 | 86.3% |
| 🥉 3 | GPT-5.4 | 86.0% |
| 4 | Claude Opus 4.5 | 85.4% |
| 5 | NVIDIA Nemotron-3-Super | 84.7% |
Key Findings:
- Claude series sweeps the top two spots: Sonnet 4.6 and Opus 4.6 take first and second place respectively, demonstrating Anthropic's systematic advantage in agent engineering.
- GPT-5.4 ranks third: It's trailing Opus 4.6 by only 0.3 percentage points—an incredibly narrow gap.
- Price-performance highlight: Claude Sonnet 4.6 (which is about 5x cheaper than Opus 4.6) actually ranks higher on PinchBench, proving that more expensive isn't always better.
- Claude Sonnet 4.6 deserves a second look: For OpenClaw-style agent tasks, Sonnet 4.6 is the most cost-effective choice.
🔍 Agent Project Recommendation: If you're building an AI Agent based on OpenClaw, the performance gap between the top three models (Sonnet 4.6, Opus 4.6, GPT-5.4) is less than 1%. We recommend accessing them on-demand via APIYI (apiyi.com) to dynamically choose models based on your specific task type, keeping costs down while maintaining a high success rate.
Chatbot Arena ELO: The Strongest Models Voted by Real Users
Chatbot Arena (formerly LMSYS) is currently the most authoritative leaderboard for AI model user preferences, with ELO scores generated through millions of blind tests and real-world user votes.
February 2026 Latest Rankings (Top 5):
| Rank | Model | ELO Score |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
Claude Opus 4.6 leads GPT-5.4 by a 40-point ELO gap, excelling particularly in multi-turn dialogues, style control, and creative writing. In the Chatbot Arena evaluation system, this gap represents a significant lead.
GPT-4.5 (Historical Reference): OpenAI released GPT-4.5 (codenamed "Orion") in February 2025, focusing on emotional intelligence and conversation quality. It briefly topped the Chatbot Arena upon release. However, the model was taken offline from the API on July 14, 2025, and completely phased out of ChatGPT by August 2025. GPT-5.4 is its current successor, surpassing it in every capability.
API Pricing & Value: Choosing for Cost-Sensitive Projects
| Cost Item | GPT-5.4 | Claude Opus 4.6 | Difference |
|---|---|---|---|
| Input Price (per 1M tokens) | $2.50 | $5.00 | Opus 4.6 is 2x pricier |
| Output Price (per 1M tokens) | $15.00 | $25.00 | Opus 4.6 is 1.67x pricier |
| Context Window | ~1M tokens | 200K (1M Beta) | GPT-5.4 wins |
| Max Output Length | — | 128K tokens | Opus 4.6 wins |
| Multimodal Support | ✅ Image Input | ✅ Image Input | Comparable |
Cost Estimation (Daily processing of 1M input tokens + 200K output tokens):
- GPT-5.4: Approx. $5.50/day ($165/month avg)
- Claude Opus 4.6: Approx. $10.00/day ($300/month avg)
💰 Cost Optimization Tip: For high-concurrency or budget-sensitive projects, we recommend using Claude Sonnet 4.6 on APIYI (apiyi.com) for daily tasks. You can then reserve Opus 4.6 model invocations for when you need the absolute strongest reasoning capabilities. This strategy can slash your API costs by 60-75%. APIYI supports unified billing for multiple models under a single account, making granular cost management a breeze.
Scenario Recommendations: GPT-5.4 vs. Claude Opus 4.6—Which One Should You Choose?
When to Choose GPT-5.4
✅ Cost-Effective General Tasks
- You're on a budget but still need flagship-level capabilities.
- Great for daily content creation, customer service Q&A, and information extraction.
- You'll see significant cost savings when your monthly model invocation fees exceed $500.
✅ Scientific Research & Technical Q&A
- It leads in GPQA Diamond, showing stronger performance in PhD-level scientific reasoning.
- Ideal for professional Q&A in academic fields like chemistry, physics, and biology.
✅ Enterprise-Level Complex Code (Leading in SWE-bench Pro)
- Best for handling architecture-level modifications in massive codebases.
- Perfect for refactoring tasks that require a deep understanding of complex dependencies.
✅ Ultra-Long Context Scenarios
- When you need to process nearly 1M tokens for massive documents or entire code repositories.
- Note that Opus 4.6's 1M context window is still in Beta.
When to Choose Claude Opus 4.6
✅ Production-Grade Code Generation & Fixes
- With 80.8% on SWE-bench Verified, it's more reliable for daily bug fixes and feature development.
- Its 84% BrowseComp score makes it excellent for RAG-enhanced applications requiring web research.
✅ OpenClaw-style Agent Projects
- Ranking in the top two on PinchBench, Anthropic models are systematically superior for practical Agent tasks.
✅ Products Requiring High Conversation Quality
- With a Chatbot Arena ELO of 1503, it ranks #1 globally for user satisfaction.
- It offers better multi-turn conversation coherence and style adaptation.
✅ Professional Knowledge Work
- It leads by 16 percentage points in ARC-AGI-2, showing stronger abstract reasoning.
- Scoring 90.2% on BigLaw Bench, it's more reliable for legal, compliance, and document analysis.
✅ Long Document Output
- Supports up to 128K output tokens, making it perfect for generating full reports and long-form documents.
🎯 Scenario Decision Advice: Both models have their strengths, and the gap usually shows up in specific tasks. We recommend performing A/B testing via the APIYI (apiyi.com) platform before going live. The platform provides a unified interface that supports quick model switching, helping you find the optimal choice for your specific business needs.
Quick Integration: Using Both Models via a Unified API
You don't need to register separate OpenAI and Anthropic accounts. Through APIYI, you can access all mainstream models using a single unified interface:
from openai import OpenAI
# Access GPT-5.4 and Claude Opus 4.6 via APIYI's unified interface
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # APIYI unified access URL
)
# Call Claude Opus 4.6
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "Please help me analyze potential bugs in the following code..."}
],
max_tokens=4096
)
# Call GPT-5.4 (Same interface, just switch the model name)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "Please help me analyze potential bugs in the following code..."}
],
max_tokens=4096
)
print("Opus 4.6:", response_opus.choices[0].message.content)
print("GPT-5.4:", response_gpt.choices[0].message.content)
💡 Integration Note: Simply set the
base_urltohttps://vip.apiyi.com/v1and replace theapi_keywith the one you applied for on APIYI (apiyi.com) to switch models instantly. There's a bonus credit for your first deposit, making it easy to test the actual differences between the two models before your official launch.
Model Name Reference:
| Model | API Model Name | Avg. Monthly Cost (100M tokens/month) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
Approx. $500+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
Approx. $100+ |
| GPT-5.4 | gpt-5-4 |
Approx. $250+ |
FAQ
Q: Are GPT-4.5 and GPT-5.4 the same model?
No, they aren't. GPT-4.5 (codenamed "Orion") was a transition model released by OpenAI in February 2025. It focused heavily on emotional intelligence and conversational quality but came with a massive price tag ($75/$150 per M tokens). It was officially deprecated from the API on July 14, 2025. GPT-5.4 is OpenAI's current flagship model; it outperforms GPT-4.5 across the board, and the price has dropped significantly to $2.50/$15 per M tokens. If you want to use the most powerful OpenAI model available, you should go with GPT-5.4, which you can access via APIYI (apiyi.com).
Q: What is OpenClaw? How does it differ from Cursor or Claude Code?
OpenClaw is an open-source, self-hostable AI agent platform. It supports terminal access, multi-file code editing, and integrates with over 50 tools like WhatsApp, Telegram, and Slack. It even has "self-evolving" capabilities, meaning it can automatically generate new skills. Compared to Cursor (a commercial IDE plugin) and Claude Code (Anthropic's official CLI), OpenClaw's main advantage is that it's fully open-source and supports private deployment—perfect for enterprises with strict data security needs. PinchBench is the specific benchmark used to evaluate how Large Language Models perform on OpenClaw agent tasks.
Q: Which model is better for AI writing tasks?
According to Chatbot Arena ELO ratings, Claude Opus 4.6 currently ranks number one globally with a score of 1503 in user preference tests. It really shines in creative writing, multi-turn conversations, and style adaptation. While GPT-5.4 is also excellent at writing, its user satisfaction ranking is slightly lower. We recommend testing your specific writing scenarios via APIYI (apiyi.com), as different styles and types of writing tasks can yield different results.
Q: How big is the gap between Claude Sonnet 4.6 and Claude Opus 4.6?
Looking at the PinchBench agent tests, Sonnet 4.6 (86.9%) actually scored slightly higher than Opus 4.6 (86.3%). On the Chatbot Arena ELO scale, Opus 4.6 sits at 1503 while Sonnet 4.6 is around 1438—a gap of about 65 points. For most programming and analytical tasks, Sonnet 4.6 is the more cost-effective choice (costing only about 20% of Opus 4.6). You'll only really need to upgrade to Opus 4.6 for complex reasoning, long document processing, or scenarios requiring extreme precision.
Summary: How to Choose a Flagship Model in 2026?
| Use Case | Recommended Model | Key Reason |
|---|---|---|
| Daily Dev + Cost Control | GPT-5.4 | 50% cheaper, strong overall capabilities |
| Complex Code Fixing (SWE-bench) | Claude Opus 4.6 | 80.8% score, leading GPT-5.4's 77.2% |
| AI Agent Tasks (OpenClaw) | Claude Sonnet 4.6 | #1 on PinchBench, cheaper than Opus |
| Conversational Products / User Satisfaction | Claude Opus 4.6 | Chatbot Arena ELO #1 (1503) |
| Scientific Research / Academic Q&A | GPT-5.4 | GPQA Diamond 93.2%, slight lead |
| Long Document Analysis | Claude Opus 4.6 | 128K output + MRCR v2 76% |
| Abstract Reasoning / AGI Tasks | Claude Opus 4.6 | ARC-AGI-2 68.8% vs 52.9% |
Key Takeaways:
- GPT-5.4 is the best overall value. Its AI Comprehensive Intelligence Index (57 vs 53) is slightly better, and it costs about half as much as Opus 4.6.
- Claude Opus 4.6 is the world leader in user satisfaction (ELO 1503), showing clear advantages in complex coding, agents, and abstract reasoning.
- For most real-world projects, Claude Sonnet 4.6 is the most cost-effective solution—it ranks first on PinchBench and costs far less than Opus 4.6.
There's no "forever best" model, only the one that fits your specific use case.
🚀 Test it now: On the APIYI (apiyi.com) platform, you can use a single API key to access GPT-5.4, Claude Opus 4.6, and Claude Sonnet 4.6 simultaneously. Compare the performance and cost of all three models using your actual business data. New users get a test credit upon registration to help you make the best decision before going live.
Data sources: Anthropic official documentation, OpenAI API documentation, Chatbot Arena Leaderboard (Feb 2026), PinchBench Leaderboard (March 13, 2026), Artificial Analysis model comparisons, and DigitalApplied technical evaluations. Data may change as models are updated; please refer to the latest official documentation.
Author: APIYI Team | Published on AI123.dev