Author's Note: We're comparing Gemini 3.1 Pro and Claude Sonnet 4.6 across five key dimensions—coding, reasoning, multimodal capabilities, knowledge work, and pricing—to help you pick the most cost-effective cutting-edge Large Language Model.
The AI landscape in February 2026 has reached a fascinating turning point: the real competition is no longer about "who is the strongest," but "who is the king of price-performance." Google's Gemini 3.1 Pro (released Feb 19) and Anthropic's Claude Sonnet 4.6 (released Feb 17) launched almost simultaneously with similar pricing and flagship-level performance claims. For developers, the choice has never been more difficult.
Core Value: By the end of this article, you'll understand the real performance gaps between these two models in coding, reasoning, multimodal tasks, and knowledge work, and know exactly which one to choose for your specific use case.

Gemini 3.1 Pro vs. Claude Sonnet 4.6: Basic Parameter Comparison
The positioning of these two models is remarkably similar—both are heavy hitters offering "near-flagship performance at a fraction of flagship prices," yet their technical approaches are worlds apart.
| Parameter | Gemini 3.1 Pro | Claude Sonnet 4.6 | Comparison Notes |
|---|---|---|---|
| Release Date | 2026.02.19 | 2026.02.17 | Only 2 days apart |
| Context Window | 1 Million (Standard) | 200K Standard / 1M Beta | Gemini features a native 1M context |
| Max Output | 64K tokens | 64K tokens | Identical |
| Input Price | $2/M tokens | $3/M tokens | ✅ Gemini is 33% cheaper |
| Output Price | $12/M tokens | $15/M tokens | ✅ Gemini is 20% cheaper |
| Long Context Input Price | $4 (>200K) | $3 (Unchanged) | ⚠️ Sonnet is cheaper for long context |
| Long Context Output Price | $18 (>200K) | $15 (Unchanged) | ⚠️ Sonnet is cheaper for long context |
| Input Modalities | Text, Image, Audio, Video, PDF | Text, Image, PDF | ✅ Gemini's multimodal support is more comprehensive |
| Reasoning Mode | Three-level thinking (Low/Med/High) | Adaptive thinking (Dynamic adjustment) | Different design philosophies |
| Prompt Caching | Supported | Cache reads only $0.30/M (90% savings) | ✅ Sonnet's caching is more cost-effective |
🎯 Key Pricing Detail: In standard scenarios under 200K, Gemini 3.1 Pro is the more economical choice ($2/$12 vs $3/$15). However, once the context exceeds 200K, Gemini's price jumps to $4/$18, making it more expensive than Sonnet 4.6's flat $3/$15 rate. Your average context length will be the deciding factor in which model is more cost-effective for you.
Gemini 3.1 Pro vs. Sonnet 4.6: A Comprehensive Benchmark Comparison
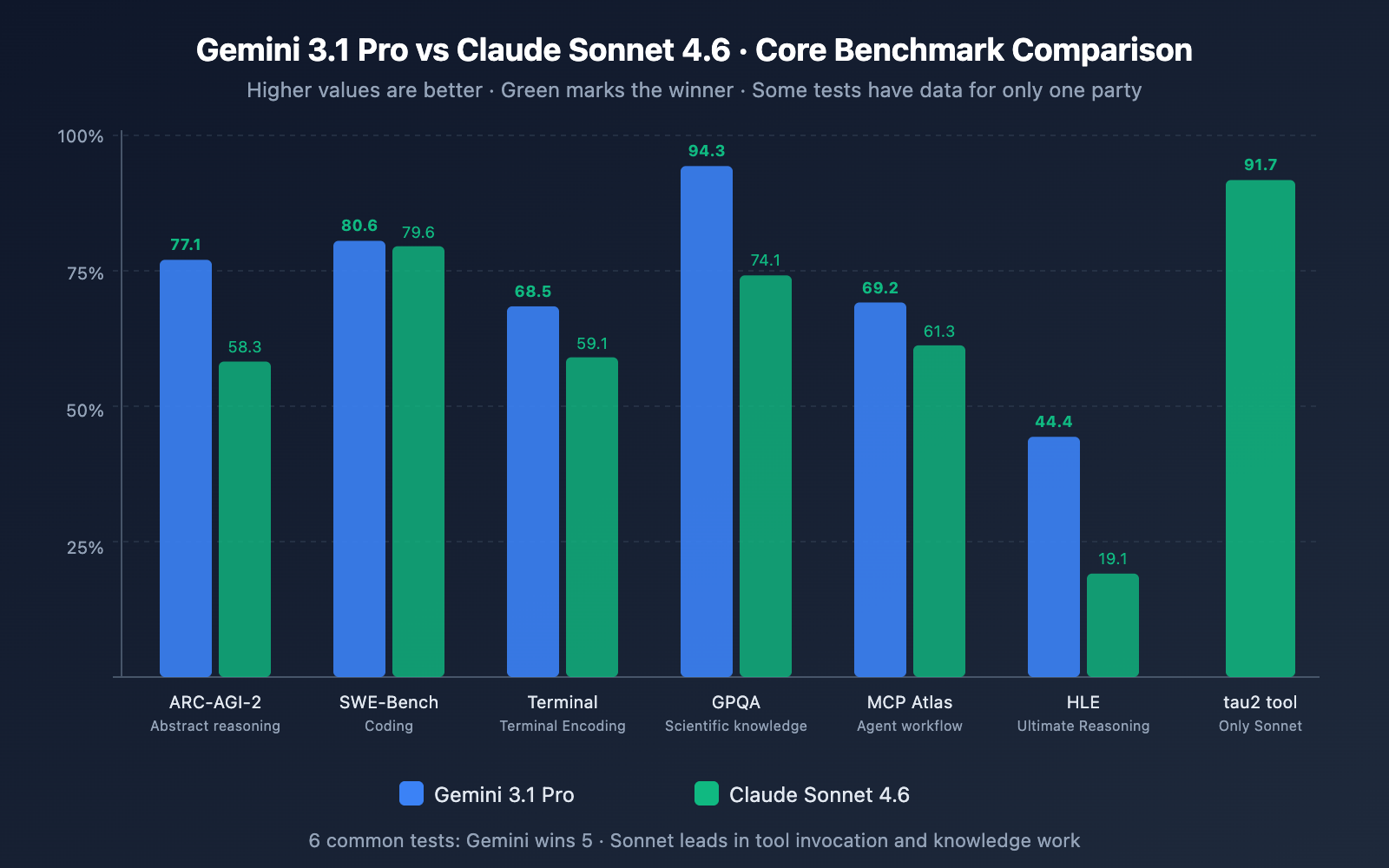
Coding Capability Comparison
| Coding Test | Gemini 3.1 Pro | Claude Sonnet 4.6 | Winner |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 79.6% | ✅ Gemini +1.0 pts |
| SWE-Bench Pro | 54.2% | 42.7% | ✅ Gemini +11.5 pts |
| Terminal-Bench 2.0 | 68.5% | 59.1% | ✅ Gemini +9.4 pts |
Analysis: Gemini 3.1 Pro takes a clean sweep across all three coding tests. Notably, the gap on SWE-Bench Pro (which involves more complex, real-world coding tasks) reaches 11.5 points, and Terminal-Bench (coding in terminal environments) shows a 9.4-point difference. However, it's worth noting that Sonnet 4.6 achieved a 0% error rate in Replit's internal production code editing tests and was selected as the base model for GitHub Copilot's coding agent—meaning the actual coding experience in production environments might be closer than what the benchmarks suggest.
Reasoning Capability Comparison
| Reasoning Test | Gemini 3.1 Pro | Claude Sonnet 4.6 | Winner |
|---|---|---|---|
| ARC-AGI-2 (Abstract Reasoning) | 77.1% | 58.3% | ✅ Gemini +18.8 pts |
| GPQA Diamond (Science) | 94.3% | 74.1% | ✅ Gemini +20.2 pts |
| HLE (Ultimate Reasoning) | 44.4% | 19.1% | ✅ Gemini +25.3 pts |
| MATH-500 | – | 97.8% | Sonnet shows strong math skills |
Analysis: Reasoning is where the gap between the two is most pronounced. Gemini 3.1 Pro leads significantly in ARC-AGI-2, GPQA Diamond, and HLE, with gaps ranging from 18 to 25 points. It's important to clarify that Gemini 3.1 Pro's reasoning scores were achieved using the "High" mode of its three-level thinking system, while Sonnet 4.6's adaptive thinking doesn't quite reach the same reasoning depth as Opus 4.6. If pure reasoning is your core requirement, Gemini 3.1 Pro holds a clear advantage.
Knowledge Work and Agent Capability Comparison
| Test | Gemini 3.1 Pro | Claude Sonnet 4.6 | Winner |
|---|---|---|---|
| GDPval-AA Elo (Knowledge Work) | 1,317 | 1,633 | ✅ Sonnet +316 pts |
| Finance Agent (Financial Analysis) | – | 63.3% | Sonnet shows strong performance |
| OSWorld (OS Control) | – | 72.5% | Sonnet shows strong performance |
| MCP Atlas (Multi-step Workflow) | 69.2% | 61.3% | ✅ Gemini +7.9 pts |
| tau2-bench Retail (Tool Use) | – | 91.7% | Sonnet shows strong performance |
Analysis: This is where we see the biggest plot twist. On GDPval-AA (which simulates real-world expert-level knowledge work), Sonnet 4.6's 1,633 Elo doesn't just blow Gemini 3.1 Pro (1,317) out of the water—it even surpasses its own flagship, Opus 4.6 (1,559). This means that in high-value knowledge work scenarios like research analysis, report writing, and business strategy, Sonnet 4.6 is currently the top-performing model available—even compared to Opus 4.6, which is five times more expensive.
Gemini 3.1 Pro vs. Sonnet 4.6: Scenario Selection Guide
The strengths and weaknesses of these two models are highly complementary, making scenario selection more important than simply asking "which is better."

When to Choose Gemini 3.1 Pro
- Algorithms and Competitive Programming: With a LiveCodeBench Elo of 2,887, it holds a crushing lead in algorithmic coding.
- Complex Reasoning and Scientific Research: Scoring 77.1% on ARC-AGI-2 and 94.3% on GPQA Diamond, its pure reasoning capability is on a completely different level compared to Sonnet 4.6.
- Multimodal Processing: Native support for video (up to 1 hour) and audio (up to 8.4 hours), which Sonnet 4.6 doesn't offer.
- MCP Agent Workflows: At 69.2% on MCP Atlas (a 7.9-point lead), it's more reliable for building multi-step Agent systems.
- High-frequency calls with short context: For contexts under 200K, the $2/$12 pricing makes it the more affordable option.
When to Choose Claude Sonnet 4.6
- Expert-level Knowledge Work: Its GDPval-AA score of 1,633 Elo is the highest among all current models. It's unmatched for research reports, financial analysis, and business strategy.
- Production Code Editing: Achieved a 0% error rate in Replit production environment testing and was chosen by GitHub Copilot as the foundation for its coding Agent.
- Tool Use and Computer Use: Scoring 91.7% on tau2-bench and 72.5% on OSWorld, it offers extremely high precision for automated operations and function calling.
- Long Context Scenarios: When exceeding a 200K context window, Sonnet 4.6's $3/$15 pricing is cheaper than Gemini's $4/$18.
- Enterprise-grade Applications: Features more mature safety alignment, prompt caching (reads at just $0.30/M tokens, saving 90%), and half-price batch processing.
Gemini 3.1 Pro and Claude Sonnet 4.6 API Quick Integration
Quick Start Example
Using the APIYI platform, both models share a unified interface:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - Stronger reasoning and multimodal capabilities
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Analyze the time complexity of this code and optimize it"}]
)
print(response.choices[0].message.content)
View Sonnet 4.6 invocation and auto-switching by scenario example
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - Excels at knowledge-based tasks and tool calling
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "Write a Q1 market analysis report, including competitor comparison and growth recommendations"}]
)
print(response.choices[0].message.content)
# Auto-routing based on scenario
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Pro Tip: You can access both models simultaneously via the APIYI (apiyi.com) platform and switch using a single API key. The platform offers free trial credits, so it's worth comparing the results in your specific use case.
Gemini 3.1 Pro vs. Sonnet 4.6: In-depth Cost Comparison
Estimating monthly costs based on three typical usage scenarios:
| Usage Scenario | Avg. Monthly Token Consumption | Gemini 3.1 Pro | Claude Sonnet 4.6 | Cheaper Option |
|---|---|---|---|---|
| Light Use (5M input + 1M output) | 6 million | $22 | $30 | Gemini saves 27% |
| Moderate Use (20M input + 5M output) | 25 million | $100 | $135 | Gemini saves 26% |
| Heavy Long-Context (50M input >200K + 10M output) | 60 million | $380 | $300 | ⚠️ Sonnet saves 21% |
🎯 Cost Conclusion: For standard usage, Gemini 3.1 Pro is about 26%-27% cheaper. However, if you're frequently working with long contexts over 200K (like full codebase analysis or long document processing), Sonnet 4.6 actually becomes more affordable—this is because Gemini's long-context pricing jumps to $4/$18, while Sonnet stays at $3/$15. Plus, with Sonnet's prompt caching (reads at just $0.30/million tokens), your actual costs could drop by another 30%-50%.
Accessing these via the APIYI (apiyi.com) platform gives you access to additional discounted rates, further lowering the cost for both Large Language Models.
FAQ
Q1: Sonnet 4.6’s GDPval-AA score is higher than Opus 4.6. Is this normal?
It actually is. Sonnet 4.6 scored 1,633 Elo on GDPval-AA, surpassing Opus 4.6's 1,559. Anthropic has officially confirmed these figures. The likely reason is that Sonnet 4.6 underwent specific optimizations for enterprise knowledge work scenarios, while Opus 4.6 remains more focused on general reasoning and long context window processing. Developer preference for Sonnet 4.6 is also quite high, reaching 70% (compared to Sonnet 4.5) and 59% (compared to Opus 4.5).
Q2: Which model is better suited for building AI Agents?
It really depends on the type of Agent you're building. If it's a multi-step workflow Agent based on MCP, Gemini 3.1 Pro leads by 7.9 points with an MCP Atlas score of 69.2%. If you're building a tool-calling intensive Agent (like OpenClaw), Sonnet 4.6's 91.7% on tau2-bench is more reliable. For "Computer Use" Agents that control browsers and desktops, Sonnet 4.6's OSWorld score of 72.5% is currently one of the best results available. You can jump in and test both models directly via the APIYI (apiyi.com) platform.
Q3: I’m currently using Sonnet 4.5. Should I upgrade to Sonnet 4.6 or switch to Gemini 3.1 Pro?
If you're happy with the knowledge work and coding experience of Sonnet 4.5, upgrading to Sonnet 4.6 is your safest bet—the API is compatible, the price remains the same, and performance has improved across the board (SWE-Bench jumped from 77.2% to 79.6%, and ARC-AGI-2 went from 13.6% to 58.3%, a 4.3x increase). However, if your core needs lean toward reasoning, multimodal capabilities, or algorithmic coding, Gemini 3.1 Pro offers significant advantages in those areas. We recommend trying both models through the APIYI (apiyi.com) platform to see which fits your workflow better.
Summary
Here are the core takeaways for Gemini 3.1 Pro vs. Claude Sonnet 4.6:
- Choose Gemini 3.1 Pro for reasoning and multimodal tasks: It leads by 18.8 points in ARC-AGI-2 and 20.2 points in GPQA Diamond. It also offers native video/audio support and is more affordable for short-context model invocations.
- Choose Claude Sonnet 4.6 for knowledge work and production coding: Its GDPval-AA score of 1,633 Elo is the highest among all models (including Opus 4.6). It boasts a 0% error rate on Replit and remains the top choice for GitHub Copilot.
- Sonnet is more cost-effective for long context scenarios: When exceeding a 200K context window, Sonnet costs $3/$15 compared to Gemini's $4/$18. Plus, using prompt caching can save you an additional 30%-50%.
As of February 2026, these two are the most cost-effective frontier models available. The best strategy is to use them in a hybrid setup based on your specific use case. We recommend connecting to both via APIYI (apiyi.com), allowing you to switch between them as needed using a single API key.
📚 References
-
Claude Sonnet 4.6 Release Announcement: Anthropic Official Blog
- Link:
anthropic.com/news/claude-sonnet-4-6 - Description: Full feature overview, benchmark data, and adaptive thinking capabilities for Sonnet 4.6.
- Link:
-
Gemini 3.1 Pro Official Blog: Google DeepMind Release Announcement
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Description: Gemini 3.1 Pro's three-tier thinking system and comprehensive performance data.
- Link:
-
Tom's Guide Hands-on Comparison: Testing Gemini 3.1 Pro vs. Sonnet 4.6 in 7 tough challenges
- Link:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - Description: Real-world performance comparison across various task scenarios.
- Link:
-
Artificial Analysis Leaderboard: Independent third-party model evaluation platform
- Link:
artificialanalysis.ai/leaderboards/models - Description: Objective side-by-side data on performance, speed, and pricing.
- Link:
Author: Technical Team
Join the Discussion: We'd love to hear about your experience in the comments! For more AI model updates, visit APIYI at apiyi.com.