作者注:Seed 2.0 Lite 260228 输入仅 $0.25/M tokens,Gemini 3.1 Pro Preview 拥有 1M 上下文和 ARC-AGI-2 77.1% 的推理能力。本文从基准测试、定价、上下文窗口等 6 个维度深度对比两款模型。
2026 年 2 月,两款定位截然不同的模型先后上线。字节跳动的 Seed 2.0 Lite 260228 通过 BytePlus 官转渠道发布,主打极致性价比;Google DeepMind 的 Gemini 3.1 Pro Preview 以 ARC-AGI-2 翻倍的推理能力刷新记录。
核心价值: 看完本文,你将明确在不同业务场景下该选择 Seed 2.0 Lite 260228 还是 Gemini 3.1 Pro Preview,以及如何在 8 倍价差中找到最优解。

Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview 核心差异
| 维度 | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview | 差异分析 |
|---|---|---|---|
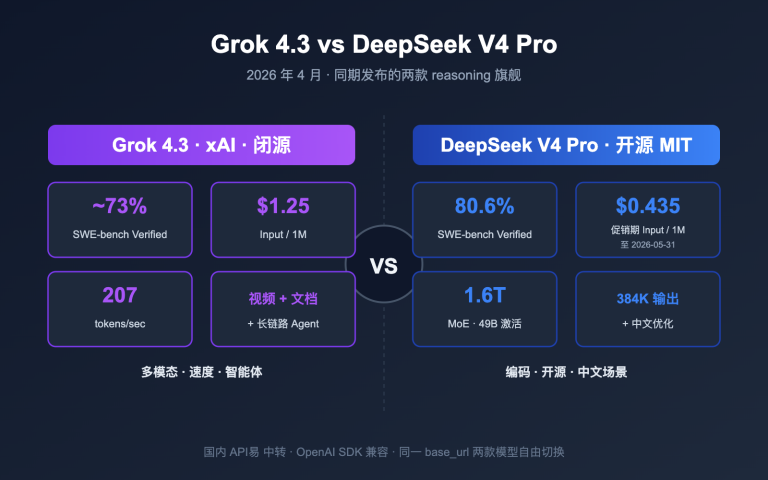
| 输入价格 | $0.25/M tokens | $2.00/M tokens | Seed 便宜 8 倍 |
| 输出价格 | $2.00/M tokens | $12.00/M tokens | Seed 便宜 6 倍 |
| 上下文窗口 | 256K tokens | 1M tokens | Gemini 大 4 倍 |
| AIME 2025 | 93.0 | 91.2 | Seed 略高 |
| MMLU-Pro | 87.7 | 89.8 | Gemini 略高 |
| SWE-Bench Verified | 73.5% | 80.6% | Gemini 领先 7 个点 |
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro 定位差异
这两款模型的定位有本质区别。Seed 2.0 Lite 260228 是字节跳动 Seed 2.0 系列的中端模型,定位于高性价比的生产环境通用模型。而 Gemini 3.1 Pro Preview 是 Google DeepMind 的旗舰级模型,在 Gemini 3 Pro 基础上实现了推理能力的大幅升级。
从价格上看,Seed 2.0 Lite 的输入成本仅为 Gemini 3.1 Pro 的八分之一。但 Gemini 3.1 Pro 提供了 4 倍大的上下文窗口和更强的代码工程能力。选择哪个模型,取决于你的应用场景对成本和能力的具体需求。
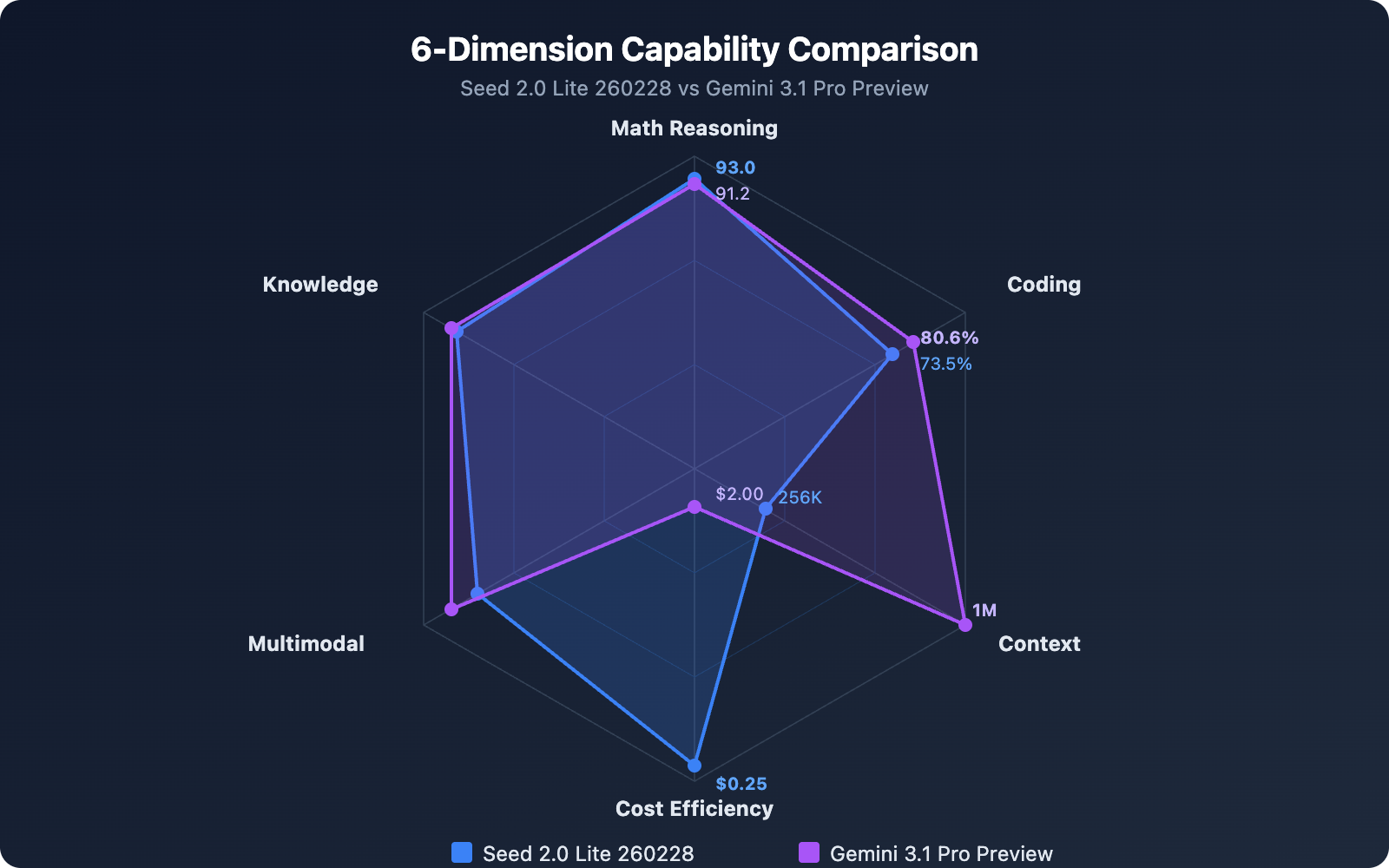
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview 基准测试对比
数学推理能力对比
在 AIME 2025 数学推理基准测试中,Seed 2.0 Lite 260228 得分 93.0,略高于 Gemini 3.1 Pro Preview 的 91.2。这个结果颇为出人意料——一个中端定价的模型在数学推理上超过了旗舰级竞品。
需要注意的是,Seed 2.0 Pro (旗舰版) 在 AIME 2025 上达到了 98.3 分,说明字节跳动 Seed 系列在数学推理方面有深厚的技术积累,Lite 版本也继承了这一优势。
知识理解能力对比
MMLU-Pro 是衡量模型综合知识理解能力的核心基准。Gemini 3.1 Pro Preview 在这项测试中得分 89.8,领先 Seed 2.0 Lite 260228 的 87.7 约 2 个百分点。两者的差距不大,都处于同一梯队的水平。
编程能力对比
编程能力是两个模型差距最明显的领域。
Gemini 3.1 Pro Preview 在 SWE-Bench Verified 上达到 80.6%,LiveCodeBench Pro Elo 评分 2887,表现出色。Seed 2.0 Lite 260228 在 SWE-Bench Verified 上得分 73.5%,Codeforces 评分 2233。
在实际软件工程任务 (SWE-Bench) 中,Gemini 3.1 Pro 领先约 7 个百分点,这对于代码密集型项目来说是一个值得考量的差距。
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview 完整基准对比
| 基准测试 | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview | 优势方 |
|---|---|---|---|
| AIME 2025 | 93.0 | 91.2 | Seed Lite |
| MMLU-Pro | 87.7 | 89.8 | Gemini |
| SWE-Bench Verified | 73.5% | 80.6% | Gemini |
| Codeforces / LiveCodeBench | 2233 | 2887 Elo | Gemini |
| ARC-AGI-2 | – | 77.1% | Gemini |
| GPQA Diamond | – | 94.3% | Gemini |
总体来看,Gemini 3.1 Pro Preview 在编程和推理方面整体更强,尤其是 ARC-AGI-2 和 SWE-Bench 的表现。而 Seed 2.0 Lite 260228 在数学推理 (AIME) 上反超,且知识理解 (MMLU-Pro) 差距很小。
选择建议: 如果你的核心需求是代码工程和复杂推理,Gemini 3.1 Pro 在 SWE-Bench 80.6% 的表现更有保障。如果预算有限但需要全面的通用能力,Seed 2.0 Lite 用八分之一的价格提供了 90% 的数学推理能力。通过 API易 apiyi.com 平台可以同时调用这两款模型,快速对比在你具体场景下的实际表现。
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview 定价对比
定价是这两款模型最大的差异点。以下是完整的费用对比:
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview 阶梯定价对比
| 定价维度 | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview |
|---|---|---|
| 输入 (标准区间) | $0.25/M tokens (0-128K) | $2.00/M tokens (0-200K) |
| 输入 (长文本区间) | $0.50/M tokens (128K-256K) | $4.00/M tokens (200K-1M) |
| 输出 (标准区间) | $2.00/M tokens (0-128K) | $12.00/M tokens (0-200K) |
| 输出 (长文本区间) | $4.00/M tokens (128K-256K) | $18.00/M tokens (200K-1M) |
| 计费方式 | 按量付费 Chat | 按量付费 |
| 免费额度 | BytePlus 新用户赠送 | Google AI Studio 免费层 |
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview 实际成本模拟
以下是不同使用场景下的月度成本估算:
| 使用场景 | 月调用量 | Seed 2.0 Lite 260228 成本 | Gemini 3.1 Pro Preview 成本 | 节省比例 |
|---|---|---|---|---|
| 轻度使用 (日常对话) | 10M in + 5M out | $12.50 | $80.00 | 84% |
| 中度使用 (文档处理) | 50M in + 20M out | $52.50 | $340.00 | 85% |
| 重度使用 (代码生成) | 200M in + 100M out | $250.00 | $1,600.00 | 84% |
在所有使用量级下,Seed 2.0 Lite 260228 的成本都低于 Gemini 3.1 Pro Preview 约 84-85%。对于月度 API 预算在 $100 以内的个人开发者和小团队,Seed 2.0 Lite 的成本优势非常明显。
成本优化建议: 混合使用两款模型是最优策略。将日常对话和文档处理交给 Seed 2.0 Lite,将复杂代码工程和深度推理交给 Gemini 3.1 Pro。API易 apiyi.com 平台支持统一接口调用两款模型,只需修改 model 参数即可切换,无需维护两套 SDK。
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview 快速上手
极简示例 — 统一接口切换两个模型
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # API易统一接口
)
# 调用 Seed 2.0 Lite 260228 (低成本日常任务)
response = client.chat.completions.create(
model="seed-2-0-lite-260228",
messages=[{"role": "user", "content": "总结这份报告的核心观点"}]
)
print("Seed Lite:", response.choices[0].message.content)
# 调用 Gemini 3.1 Pro Preview (复杂推理任务)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "分析这段代码的安全漏洞并给出修复方案"}]
)
print("Gemini Pro:", response.choices[0].message.content)
查看完整对比测试代码 (含耗时和成本计算)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
MODELS = {
"seed-2-0-lite-260228": {"input_price": 0.25, "output_price": 2.00},
"gemini-3.1-pro-preview": {"input_price": 2.00, "output_price": 12.00},
}
def compare_models(prompt: str, system_prompt: str = None):
"""对比两个模型的响应质量、速度和成本"""
results = {}
for model_name, pricing in MODELS.items():
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=messages,
max_tokens=2000
)
elapsed = time.time() - start
usage = response.usage
cost = (usage.prompt_tokens * pricing["input_price"]
+ usage.completion_tokens * pricing["output_price"]) / 1_000_000
results[model_name] = {
"content": response.choices[0].message.content,
"time": f"{elapsed:.2f}s",
"tokens": f"{usage.prompt_tokens}+{usage.completion_tokens}",
"cost": f"${cost:.6f}"
}
for name, r in results.items():
print(f"\n{'='*50}")
print(f"Model: {name}")
print(f"Time: {r['time']} | Tokens: {r['tokens']} | Cost: {r['cost']}")
print(f"Response: {r['content'][:200]}...")
compare_models("解释快速排序算法的时间复杂度分析")
快速开始: 通过 API易 apiyi.com 平台可以一个 API Key 同时调用 Seed 2.0 Lite 和 Gemini 3.1 Pro,免去分别注册 BytePlus 和 Google Cloud 的麻烦。平台提供免费测试额度,5 分钟完成接入。
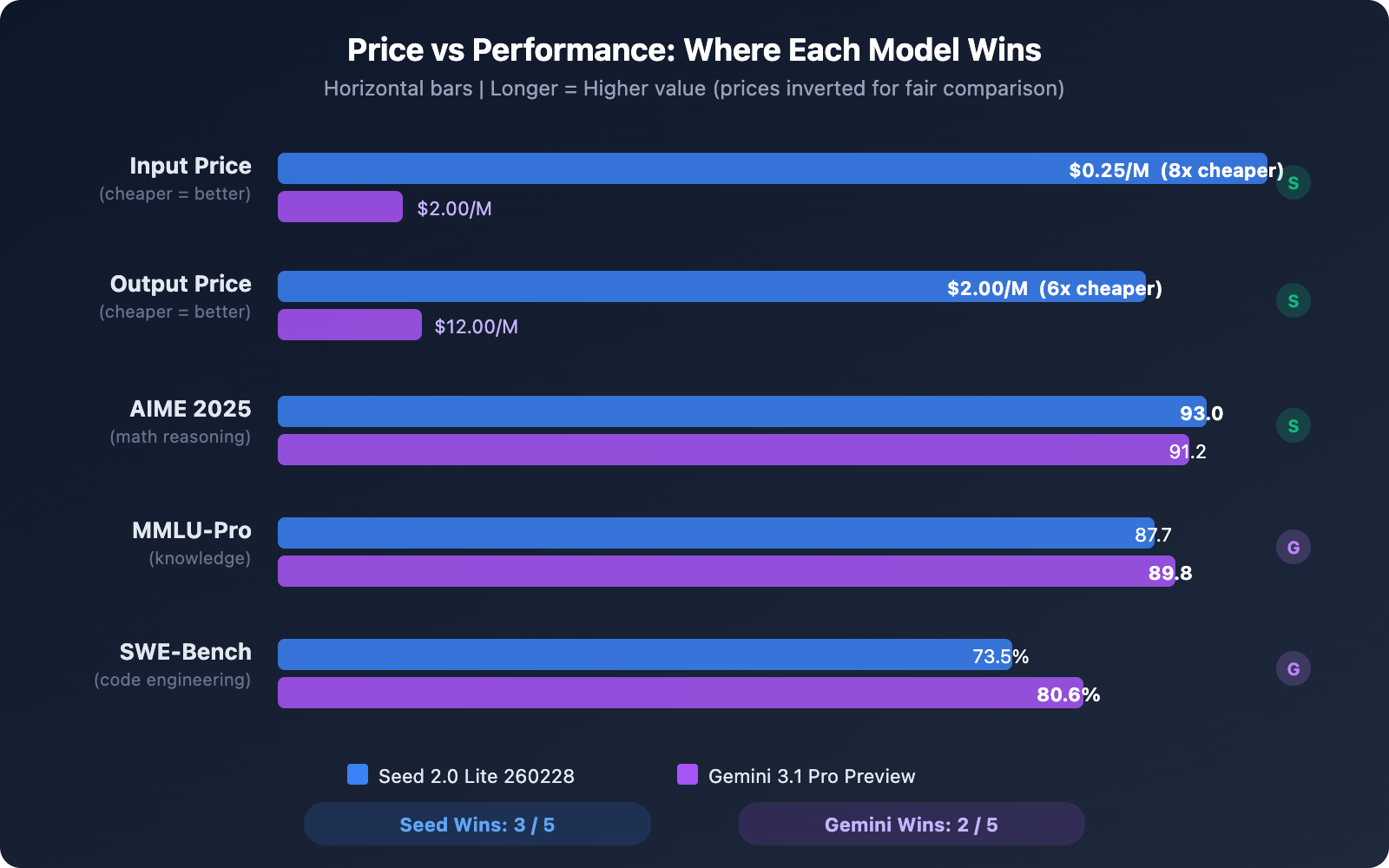
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview 场景推荐
根据两个模型的能力和定价差异,以下是不同场景的推荐:
选 Seed 2.0 Lite 260228 的场景:
- 日常对话和客服系统: 成本低至 $0.25/M tokens,适合高频调用场景
- 文档总结和信息提取: AIME 93.0 和 MMLU-Pro 87.7 表明知识理解能力足够
- 预算敏感的创业项目: 月成本仅为 Gemini 的 15-16%
- 多模态内容理解: 支持文本、图像、视频输入,256K 上下文满足大多数需求
- 批量数据处理: 低单价让大规模批处理的总成本可控
选 Gemini 3.1 Pro Preview 的场景:
- 复杂代码工程: SWE-Bench 80.6% 在实际开发任务中更可靠
- 超长文档分析: 1M tokens 上下文可处理整本书籍或大型代码库
- 前沿推理任务: ARC-AGI-2 77.1% 和 GPQA Diamond 94.3% 代表顶级推理
- 需要深度思考的任务: thinking_level 参数支持 low/medium/high/max 四级调节
- 代码安全审计: LiveCodeBench Pro 2887 Elo 的竞赛级编程能力
场景建议: 最佳实践是混合部署两款模型。API易 apiyi.com 平台支持统一接口调用,你可以在应用层根据任务复杂度自动路由到不同模型,实现性能和成本的最优平衡。
常见问题
Q1: Seed 2.0 Lite 260228 数学推理超过 Gemini 3.1 Pro,为什么还要选 Gemini?
AIME 2025 只是数学推理的一个维度。Gemini 3.1 Pro 在 ARC-AGI-2 (77.1%) 测试的是全新逻辑模式的推理能力,在 GPQA Diamond (94.3%) 测试的是研究生级科学推理,这些维度 Gemini 的优势更大。此外,SWE-Bench 80.6% 的实际代码工程能力是很多开发者最看重的指标。如果你的场景侧重数学计算,Seed Lite 确实更划算;如果侧重复杂推理和代码,Gemini 更适合。
Q2: 8 倍价差值得吗? 什么情况下该选贵的 Gemini 3.1 Pro?
当以下条件满足时值得选 Gemini: (1) 单次任务需要处理超过 256K tokens 的输入; (2) 需要 SWE-Bench 80%+ 级别的代码工程可靠性; (3) 任务对推理深度有极高要求 (需要 thinking_level=max)。对于大多数日常 API 调用,Seed 2.0 Lite 的性能完全够用,8 倍的成本差异意味着同样预算下可以做 8 倍的调用量。通过 API易 apiyi.com 可以灵活切换,不必二选一。
Q3: 如何快速对比两个模型在我的场景下的表现?
最快的方式:
- 访问 API易 apiyi.com 注册账号,获取统一 API Key
- 使用本文提供的对比测试代码,将你的实际业务 prompt 作为输入
- 对比两个模型的响应质量、速度和成本,选择最适合的
总结
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview 的核心结论:
- 价格差 8 倍: Seed Lite 输入 $0.25/M vs Gemini $2.00/M,输出 $2.00/M vs $12.00/M,同等预算下 Seed 的调用量是 Gemini 的 6-8 倍
- 数学推理 Seed 略胜: AIME 2025 上 Seed Lite 93.0 超过 Gemini 91.2,以中端价格实现旗舰水平
- 代码工程 Gemini 领先: SWE-Bench 80.6% vs 73.5%,LiveCodeBench 2887 vs Codeforces 2233,Gemini 在实际开发任务中更可靠
- 上下文 Gemini 碾压: 1M vs 256K,Gemini 适合超长文档和大型代码库分析
- 最佳策略是混合使用: 日常任务走 Seed Lite 省成本,复杂推理走 Gemini 保质量
推荐通过 API易 apiyi.com 统一接入两款模型,平台提供免费额度和 OpenAI 兼容接口,一个 API Key 即可自由切换。
参考资料
-
ByteDance Seed 2.0 官方介绍: Seed 2.0 系列模型能力和基准数据
- 链接:
seed.bytedance.com/en/seed2 - 说明: Pro/Lite/Mini 全系列模型技术规格和测试结果
- 链接:
-
Google Gemini 3.1 Pro 官方博客: Gemini 3.1 Pro 发布信息和能力详解
- 链接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 说明: ARC-AGI-2、SWE-Bench 等核心基准成绩和功能特性
- 链接:
-
Gemini 3.1 Pro Model Card: Google DeepMind 官方模型卡片
- 链接:
deepmind.google/models/model-cards/gemini-3-1-pro/ - 说明: 详细的技术规格、安全评估和使用指南
- 链接:
-
BytePlus ModelArk 定价: Seed 模型官方 API 定价
- 链接:
docs.byteplus.com/en/docs/ModelArk/1544106 - 说明: 阶梯计费详情和各模型价格表
- 链接:
-
Artificial Analysis – 模型对比: 独立第三方评测平台
- 链接:
artificialanalysis.ai/models/gemini-3-1-pro-preview - 说明: 性能、价格和延迟的综合分析数据
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区分享你对 Seed 2.0 Lite 和 Gemini 3.1 Pro 的使用体验,更多模型对比指南可访问 API易 docs.apiyi.com 文档中心