Author's Note: Gemini 3.1 Flash-Lite Preview has launched with an impressive output speed of 380 tok/s and a super low cost of $0.25/M. This article provides an in-depth analysis of its 5 core advantages, benchmark data, competitor comparisons, and API integration methods.
Google DeepMind officially released Gemini 3.1 Flash-Lite Preview on March 3, 2026—the fastest and most cost-effective model in the Gemini 3 series. Based on the Gemini 3 Pro architecture, it achieves an output speed of approximately 380 tokens/s, making its first token response 2.5x faster than Gemini 2.5 Flash and its overall output speed 45% higher.
Core Value: This article will help you fully understand this newly launched lightweight model from 5 dimensions—performance benchmarks, cost comparison, functional features, applicable scenarios, and API integration—so you can decide if it's right for your business needs.
Gemini 3.1 Flash-Lite Preview Core Specs at a Glance
Here are the core technical parameters extracted from Google AI's official documentation and DeepMind's model card:
| Parameter | Gemini 3.1 Flash-Lite Preview | Description |
|---|---|---|
| Model ID | gemini-3.1-flash-lite-preview |
Use this ID for API calls |
| Architecture Base | Gemini 3 Pro | Inherits Pro-level multimodal architecture |
| Context Window | 1,048,576 tokens (1M) | Equivalent to ~1,500 A4 pages |
| Max Output | 65,536 tokens (64K) | Supports long text generation |
| Output Speed | ~380 tokens/s | Ranks 2nd among 132 models |
| Input Price | $0.25 / million tokens | Lowest in the Gemini 3 series |
| Output Price | $1.50 / million tokens | 1/8th the cost of the Pro version |
| Knowledge Cutoff | January 2025 | Consistent with Gemini 3 Pro |
| Status | Preview | Preview version; official release pending |
It's worth noting that Gemini 3.1 Flash-Lite Preview is built on the Gemini 3 Pro architecture, meaning it retains Pro-level multimodal understanding capabilities in a "scaled-down" package. Google positions it as the preferred model for "high-frequency, lightweight tasks."
🎯 Integration Tip: Gemini 3.1 Flash-Lite Preview is now available on APIYI (apiyi.com) at the same price as Google's official offering. Top up $100 and get $10 free, with discounts starting at 20% off. Access over 400 Large Language Models in one place.
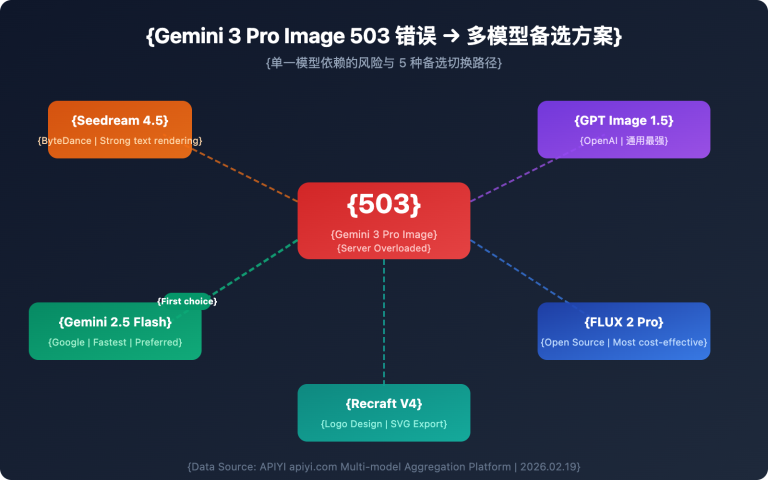
Gemini 3.1 Flash-Lite Preview: 5 Core Advantages
Advantage 1: Blazing-Fast Inference – 380 tok/s Output Speed
Gemini 3.1 Flash-Lite Preview boasts an output speed of approximately 380 tokens/s. According to Artificial Analysis benchmark data, this ranks it 2nd out of 132 mainstream models. Compared to the previous generation Gemini 2.5 Flash at 249 tok/s, that's a performance boost of about 45%.
The improvement in Time to First Token (TTFT) is even more impressive—it's 2.5 times faster than Gemini 2.5 Flash. This is a game-changer for applications requiring instant feedback, like chatbots or real-time translation.
Advantage 2: Extremely Low Cost – Input at Just $0.25/M Tokens
Within the Gemini 3 series, Flash-Lite is priced at just 1/8th the cost of the Pro version. Here's the breakdown:
| Model | Input Price | Output Price | Blended Rate (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0.25/M | $1.50/M | $0.56/M |
| Gemini 3 Pro | $2.00/M | $12.00/M | $4.50/M |
| Claude 4.5 Haiku | $1.00/M | $5.00/M | $2.00/M |
| GPT-5 mini | $0.15/M | $0.60/M | $0.26/M |
Flash-Lite strikes an excellent balance between price and performance. While not the absolute cheapest, its combination of 380 tok/s output speed and a 1M token context window offers incredible value for money.
Advantage 3: Million-Token Context Window
A context window of 1,048,576 tokens means you can process in a single request:
- Roughly 1,500 pages of A4 text
- An entire code repository
- Hours of audio or video content
This is a rare configuration for a lightweight model. In comparison, GPT-5 mini supports only 128K, and Claude 4.5 Haiku supports 200K.
Advantage 4: Full Multimodal Input Support
Despite being positioned as a lightweight model, Gemini 3.1 Flash-Lite Preview supports 5 input modalities:
- Text: Core capability
- Image: Image content analysis and understanding
- Audio: Speech transcription and analysis
- Video: Video content understanding
- PDF: Document parsing and summarization
It only outputs text, but for most data processing and analysis tasks, that's more than sufficient.
Advantage 5: Thinking Mode Support
Remarkably for a lightweight model, Gemini 3.1 Flash-Lite Preview supports Thinking Mode (Extended Reasoning), which is almost unique among its peers. When enabled, the model performs step-by-step reasoning, significantly boosting accuracy in tasks like scientific knowledge and mathematical calculations.
🎯 Platform Recommendation: Want to quickly test Gemini 3.1 Flash-Lite Preview's Thinking Mode performance? You can invoke it directly via APIYI at apiyi.com, which offers a unified interface supporting 400+ mainstream Large Language Models.
Gemini 3.1 Flash-Lite Preview Benchmark Data
The following data is sourced from the Google DeepMind model card and Artificial Analysis evaluations:
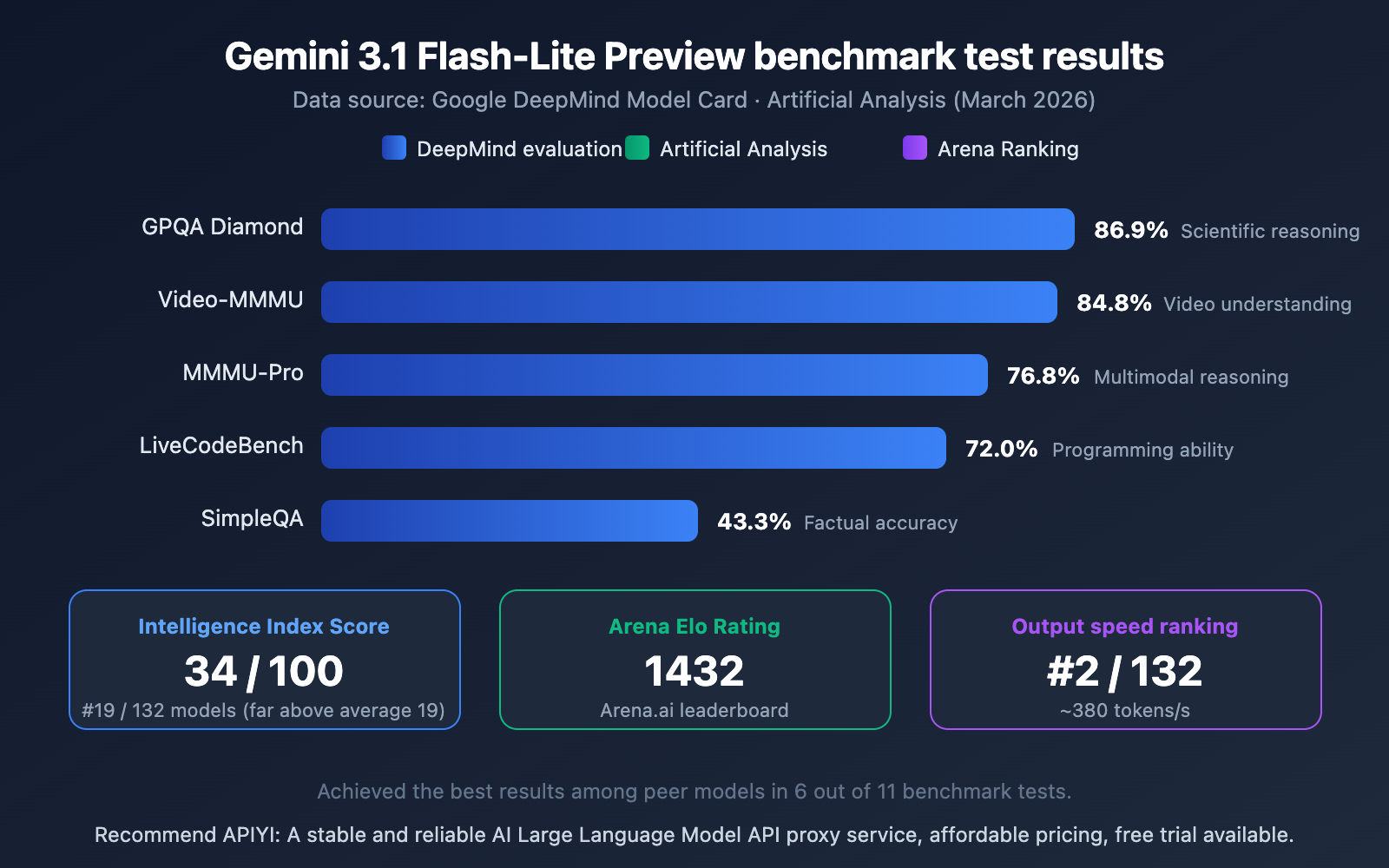
Interpreting the Gemini 3.1 Flash-Lite Preview Benchmarks
Looking at the data, Flash-Lite's performance among lightweight models is quite impressive:
- GPQA Diamond 86.9%: Leads its peers in scientific knowledge and reasoning.
- Video-MMMU 84.8%: Showcases its multimodal strength in video understanding.
- MMMU-Pro 76.8%: Excellent performance in multimodal reasoning.
- Arena Elo 1432: A high score on the Arena.ai leaderboard, proving its real-world usability is strong.
- Intelligence Index 34/100: Far exceeds the peer average of 19, ranking 19th out of 132 models.
Out of 11 benchmark tests, Flash-Lite achieved best-in-class results in 6 of them, which is an outstanding performance for a lightweight model.
🎯 Practical Testing Advice: Benchmark data is for reference only; actual results vary by use case. We recommend testing in real-world scenarios via APIYI at apiyi.com. The platform offers free credits and supports quick comparisons between multiple models.
Gemini 3.1 Flash-Lite Preview vs. Competitors

| Comparison Dimension | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| Output Speed | ~380 tok/s ⚡ | ~108 tok/s | ~71 tok/s |
| Input Price | $0.25/M | $1.00/M | $0.15/M ⚡ |
| Output Price | $1.50/M | $5.00/M | $0.60/M ⚡ |
| Context Window | 1M tokens ⚡ | 200K tokens | 128K tokens |
| Multimodal Input | 5 types ⚡ | 2 types | 2 types |
| Thinking Mode | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| Batch API | ✅ | ✅ | ✅ |
Comparison Summary:
- Speed First: Flash-Lite's 380 tok/s is 3.5x faster than Haiku and 5.4x faster than GPT-5 mini.
- Cost First: GPT-5 mini has lower absolute prices, but Flash-Lite's speed advantage can offset the cost difference.
- Features First: Flash-Lite clearly leads in context length (1M) and multimodal support (5 types).
🎯 Recommendation: Which lightweight model you choose depends on your specific scenario. We recommend doing a practical comparison test via APIYI at apiyi.com. The platform supports a unified interface for all the models above, making it easy to switch and evaluate quickly.
Getting Started with Gemini 3.1 Flash-Lite Preview
Minimal Example
Here's the simplest code to call the Gemini 3.1 Flash-Lite Preview via the APIYI platform—you can run it in just 10 lines:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "Explain quantum computing in one sentence."}]
)
print(response.choices[0].message.content)
View Complete Implementation Code (Including Thinking Mode)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
Call Gemini 3.1 Flash-Lite Preview
Args:
prompt: User input
system_prompt: System prompt
max_tokens: Maximum output tokens
enable_thinking: Whether to enable Thinking Mode
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Usage Example
result = call_flash_lite(
prompt="Analyze the time complexity of the following code and provide optimization suggestions.",
system_prompt="You are a senior algorithm engineer."
)
print(result)
Suggestion: Get an API Key and free testing credits via APIYI at apiyi.com to quickly verify how Gemini 3.1 Flash-Lite Preview performs in your specific scenario. Recharge $100 or more and get $10 free, with discounts as low as 20% off.
Gemini 3.1 Flash-Lite Preview Use Cases
Recommended Use Cases
| Use Case | Description | Why Choose Flash-Lite |
|---|---|---|
| Large-Scale Translation | Multilingual content translation workflows | 380 tok/s ultra-fast output + low cost |
| Content Moderation | Classifying and filtering user-generated content | High-frequency calls + controllable costs |
| Data Extraction | Extracting and organizing structured data | Supports JSON Schema output |
| Agent Routing | Acting as a routing layer to distribute requests | Ultra-low latency + Function Calling |
| Document Processing | Parsing and summarizing PDFs/long documents | 1M context window + multimodal input |
| Audio Transcription | Speech-to-text and analysis | Native audio input support |
Not Recommended Use Cases
- Complex Creative Writing: Pro-level models have an advantage in deep creative tasks.
- Image/Audio Generation: Flash-Lite only supports text output.
- Real-time Streaming Conversations: Does not support Live API.
- Scenarios Requiring Highest Reasoning Accuracy: For tasks demanding ultimate accuracy, Gemini 3.1 Pro is recommended.
🎯 Scenario Suggestion: Unsure which model is best for your use case? You can quickly switch and compare between Gemini 3.1 Flash-Lite, Claude Haiku, and GPT-5 mini via APIYI apiyi.com to find the optimal solution.
Frequently Asked Questions
Q1: What’s the difference between Gemini 3.1 Flash-Lite Preview and Gemini 2.5 Flash?
The core differences lie in architecture and performance: Flash-Lite is based on the Gemini 3 Pro architecture (not Gemini 2), with a first-token response time 2.5x faster and output speed increased by 45% to ~380 tok/s. It also adds advanced features like Thinking Mode and code execution.
Q2: How stable is the Preview version? Is it suitable for production use?
The Preview version's features and performance may be adjusted in the official release. It's recommended to test it first in non-critical business scenarios. For critical business, you can set up a fallback plan. When calling via APIYI apiyi.com, you can easily switch between models to implement a flexible fallback strategy.
Q3: How can I quickly start testing Gemini 3.1 Flash-Lite Preview?
It's recommended to test through a multi-model API aggregation platform:
- Visit APIYI apiyi.com to register an account.
- Obtain an API Key and free credits.
- Use the code examples in this article, setting the model to
gemini-3.1-flash-lite-preview. - Top up $100 or more and get a $10 bonus, with discounts as low as 20% off.
Summary
The key takeaways for Gemini 3.1 Flash-Lite Preview:
- Blazing Speed: ~380 tokens/sec output speed, ranking 2nd among 132 models. Its first token response time is 2.5x faster than 2.5 Flash.
- High Cost-Effectiveness: Input $0.25/M, Output $1.50/M, which is just 1/8th the cost of Gemini 3 Pro. Ideal for high-frequency, large-scale calls.
- Comprehensive Features: 1M context window + 5 input modalities + Thinking Mode + Function Calling. It's the most fully-featured lightweight model available.
- Pro-Level DNA: Built on the Gemini 3 Pro architecture, delivering strong performance on benchmarks like GPQA Diamond (86.9%).
For AI applications requiring large-scale, low-cost, and high-speed processing, Gemini 3.1 Flash-Lite Preview is currently one of the most noteworthy lightweight models.
We recommend testing it quickly via APIYI at apiyi.com. The platform's pricing matches Google's official rates, with a promotion of $10 bonus for every $100 top-up, and discounts as low as 20% off. It's a one-stop solution for accessing over 400 Large Language Models.
📚 References
-
Google AI Official Model Documentation: Complete technical specifications for Gemini 3.1 Flash-Lite Preview.
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - Description: Official API documentation containing the latest parameters and feature lists.
- Link:
-
Google DeepMind Model Card: Benchmark data and safety evaluations.
- Link:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - Description: Official model card with detailed benchmark scores and training information.
- Link:
-
Artificial Analysis Evaluation: Independent third-party performance and pricing analysis.
- Link:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - Description: Includes independent evaluation data on output speed, TTFT, intelligence index, etc.
- Link:
-
Google Official Blog: Gemini 3.1 Flash-Lite Announcement.
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - Description: Official announcement article detailing product positioning and core features.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to discuss in the comments. For more resources, visit the APIYI Documentation Center atdocs.apiyi.com.