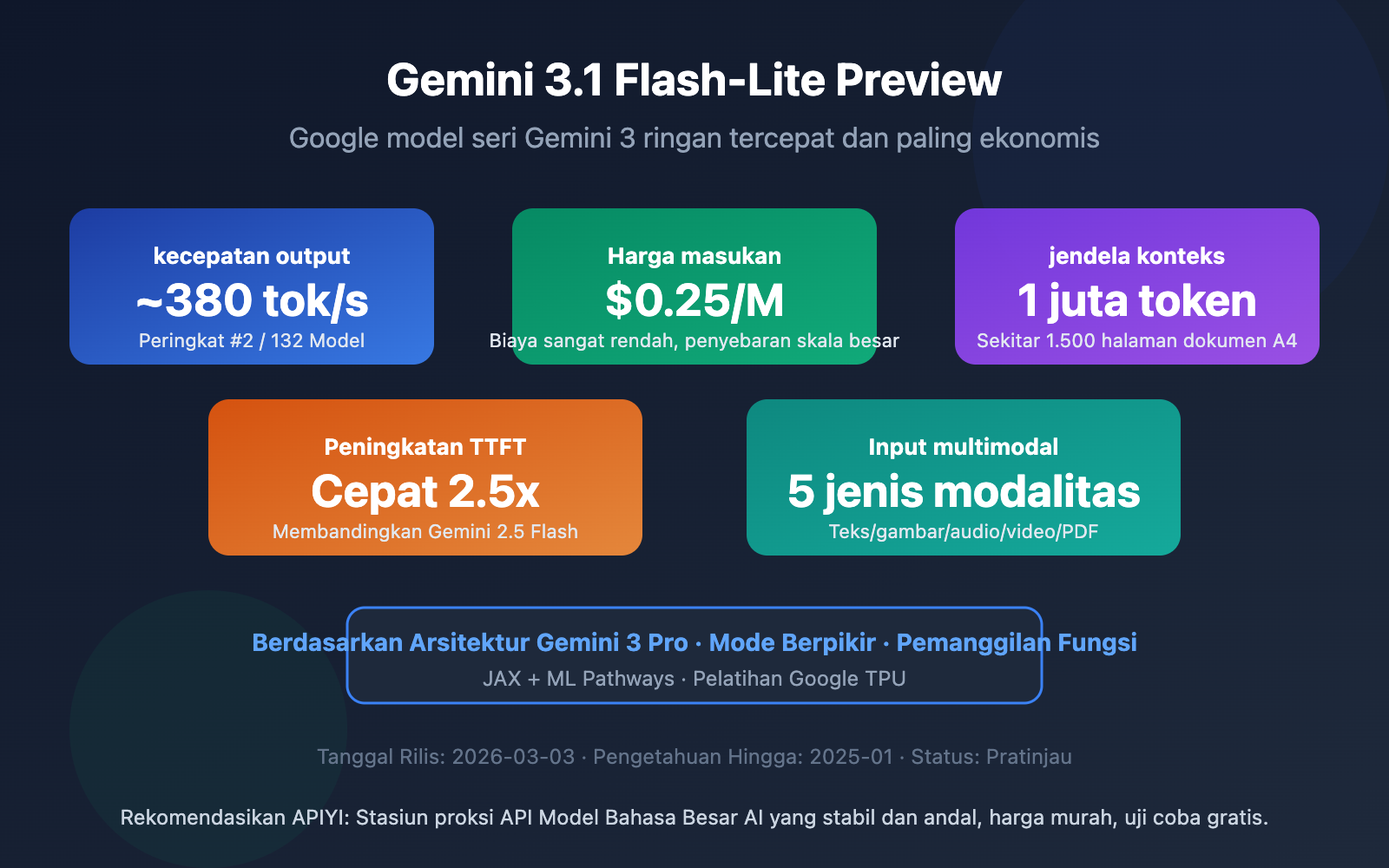
Google DeepMind secara resmi meluncurkan Gemini 3.1 Flash-Lite Preview pada 3 Maret 2026—model tercepat dan termurah dalam seri Gemini 3. Berbasis arsitektur Gemini 3 Pro, kecepatan outputnya mencapai sekitar 380 token/detik, dengan respons token pertama 2.5 kali lebih cepat dari Gemini 2.5 Flash dan peningkatan kecepatan output sebesar 45%.
Nilai Inti: Artikel ini akan membantu Anda memahami model ringan baru ini secara komprehensif dari 5 dimensi—benchmark performa, perbandingan biaya, fitur, skenario penggunaan, dan metode integrasi API—untuk menilai apakah cocok untuk skenario bisnis Anda.
Tinjauan Cepat Parameter Inti Gemini 3.1 Flash-Lite Preview
Berikut adalah parameter teknis inti yang diambil dari dokumentasi resmi Google AI dan kartu model DeepMind:
| Parameter | Gemini 3.1 Flash-Lite Preview | Keterangan |
|---|---|---|
| ID Model | gemini-3.1-flash-lite-preview |
Gunakan ID ini saat memanggil API |
| Dasar Arsitektur | Gemini 3 Pro | Mewarisi arsitektur multimodal tingkat Pro |
| Jendela Konteks | 1,048,576 token (1M) | Setara dengan ~1.500 halaman dokumen A4 |
| Output Maksimum | 65,536 token (64K) | Mendukung pembuatan teks panjang |
| Kecepatan Output | ~380 token/detik | Peringkat ke-2 di antara 132 model |
| Harga Input | $0.25 / juta token | Terendah dalam seri Gemini 3 |
| Harga Output | $1.50 / juta token | 1/8 dari harga versi Pro |
| Pemutakhiran Pengetahuan | Januari 2025 | Sama dengan Gemini 3 Pro |
| Status | Preview | Versi pratinjau, versi resmi akan menyusul |
Perlu dicatat, Gemini 3.1 Flash-Lite Preview dibangun berdasarkan arsitektur Gemini 3 Pro, yang berarti model "versi ringkas" ini tetap mempertahankan kemampuan pemahaman multimodal tingkat Pro. Google memposisikannya sebagai model pilihan utama untuk "tugas ringan dan berfrekuensi tinggi".
🎯 Saran Integrasi: Gemini 3.1 Flash-Lite Preview telah tersedia di APIYI apiyi.com, dengan harga yang sama dengan Google resmi. Isi ulang mulai $100 dapat bonus $10, diskon hingga 20%, akses 400+ Model Bahasa Besar dalam satu platform.
Keunggulan 1: Inferensi Super Cepat – Kecepatan Output 380 tok/s
Kecepatan output Gemini 3.1 Flash-Lite Preview mencapai sekitar 380 token/detik. Berdasarkan data evaluasi dari Artificial Analysis, ini menempati peringkat ke-2 dari 132 model utama. Dibandingkan dengan pendahulunya, Gemini 2.5 Flash yang 249 tok/s, performanya meningkat sekitar 45%.
Waktu Respons Token Pertama (TTFT) bahkan lebih mencolok – 2.5 kali lebih cepat daripada Gemini 2.5 Flash. Peningkatan ini sangat signifikan untuk skenario aplikasi yang membutuhkan umpan balik instan, seperti chatbot atau penerjemahan real-time.
Keunggulan 2: Biaya Sangat Rendah – Input Hanya $0.25/Juta Token
Dalam seri Gemini 3, harga Flash-Lite hanya 1/8 dari versi Pro. Secara spesifik:
| Model | Harga Input | Harga Output | Tarif Campuran (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0.25/Jt | $1.50/Jt | $0.56/Jt |
| Gemini 3 Pro | $2.00/Jt | $12.00/Jt | $4.50/Jt |
| Claude 4.5 Haiku | $1.00/Jt | $5.00/Jt | $2.00/Jt |
| GPT-5 mini | $0.15/Jt | $0.60/Jt | $0.26/Jt |
Flash-Lite mencapai keseimbangan yang sangat baik antara harga dan performa – meski bukan yang termurah secara absolut, namun dengan kecepatan output 380 tok/s dan jendela konteks 1 juta token, nilai untuk uangnya sangat tinggi.
Keunggulan 3: Jendela Konteks Jutaan Token
Jendela konteks 1.048.576 token berarti Anda dapat memproses dalam satu permintaan:
- Sekitar 1.500 halaman dokumen A4
- Repositori kode lengkap
- Konten audio/video berdurasi berjam-jam
Ini adalah konfigurasi yang sangat langka untuk model ringan. Sebagai perbandingan, GPT-5 mini hanya mendukung 128K, dan Claude 4.5 Haiku mendukung 200K.
Keunggulan 4: Dukungan Input Multimodal Lengkap
Meski diposisikan sebagai model ringan, Gemini 3.1 Flash-Lite Preview mendukung 5 modalitas input:
- Teks: Kemampuan inti
- Gambar: Analisis dan pemahaman konten gambar
- Audio: Transkripsi dan analisis ucapan
- Video: Pemahaman konten video
- PDF: Parsing dan ringkasan dokumen
Untuk output, hanya mendukung teks, namun ini sudah cukup untuk sebagian besar tugas pemrosesan dan analisis data.
Keunggulan 5: Dukungan Thinking Mode
Sebagai model ringan, Gemini 3.1 Flash-Lite Preview ternyata mendukung Thinking Mode (Mode Pemikiran Terperinci), yang hampir unik di antara model sejenisnya. Saat diaktifkan, model akan melakukan penalaran langkah demi langkah, meningkatkan akurasi secara signifikan pada tugas seperti pengetahuan ilmiah dan perhitungan matematika.
🎯 Rekomendasi Platform: Ingin menguji performa Thinking Mode Gemini 3.1 Flash-Lite Preview dengan cepat? Anda dapat langsung memanggilnya melalui APIYI apiyi.com, yang mendukung antarmuka terpadu untuk 400+ Model Bahasa Besar utama.
Data Uji Patokan Gemini 3.1 Flash-Lite Preview
Berikut adalah data evaluasi dari kartu model Google DeepMind dan Artificial Analysis:
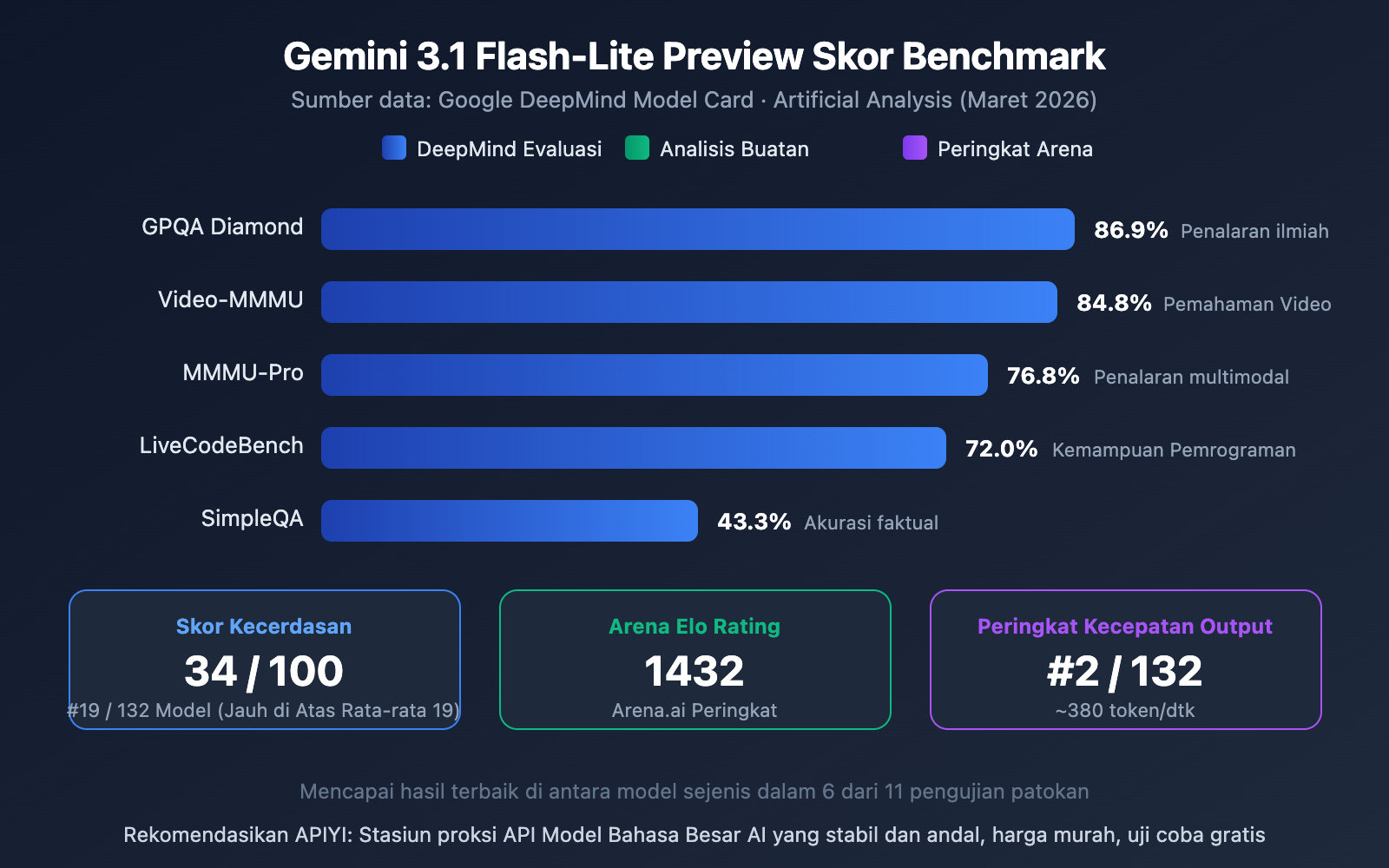
Interpretasi Uji Patokan Gemini 3.1 Flash-Lite Preview
Dari data tersebut, performa Flash-Lite di antara model ringan cukup mencolok:
- GPQA Diamond 86.9%: Kemampuan penalaran pengetahuan ilmiah unggul di antara model sejenis.
- Video-MMMU 84.8%: Kemampuan pemahaman video mencerminkan keunggulan multimodalnya.
- MMMU-Pro 76.8%: Performa penalaran multimodal yang sangat baik.
- Arena Elo 1432: Mendapat skor tinggi di papan peringkat Arena.ai, membuktikan pengalaman penggunaan yang baik.
- Indeks Kecerdasan 34/100: Jauh melampaui rata-rata model sejenis (19), menempati peringkat ke-19 dari 132 model.
Dari 11 uji patokan, Flash-Lite mencapai hasil terbaik di kelasnya untuk 6 item, sebuah pencapaian yang sangat baik untuk model ringan.
🎯 Saran Pengujian Nyata: Data uji patokan hanya sebagai referensi, hasil aktual bervariasi tergantung skenario. Disarankan untuk melakukan pengujian pada skenario nyata melalui APIYI apiyi.com. Platform ini menyediakan kuota gratis dan mendukung perbandingan cepat beberapa model.
Perbandingan Gemini 3.1 Flash-Lite Preview dengan Kompetitor

| Dimensi Perbandingan | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| Kecepatan Output | ~380 tok/s ⚡ | ~108 tok/s | ~71 tok/s |
| Harga Input | $0.25/M | $1.00/M | $0.15/M ⚡ |
| Harga Output | $1.50/M | $5.00/M | $0.60/M ⚡ |
| Jendela Konteks | 1M tokens ⚡ | 200K tokens | 128K tokens |
| Input Multimodal | 5 jenis ⚡ | 2 jenis | 2 jenis |
| Thinking Mode | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| Batch API | ✅ | ✅ | ✅ |
Ringkasan Perbandingan:
- Prioritas Kecepatan: Flash-Lite dengan 380 tok/s adalah 3.5x lebih cepat dari Haiku dan 5.4x lebih cepat dari GPT-5 mini
- Prioritas Biaya: GPT-5 mini memiliki harga absolut lebih rendah, tetapi keunggulan kecepatan Flash-Lite dapat menutupi perbedaan biaya
- Prioritas Fitur: Flash-Lite unggul jelas dalam panjang konteks (1M) dan dukungan multimodal (5 jenis)
🎯 Saran Pemilihan: Model ringan mana yang dipilih tergantung pada skenario spesifik. Kami menyarankan untuk melakukan uji perbandingan praktis melalui APIYI apiyi.com, platform ini mendukung pemanggilan antarmuka terpadu untuk semua model di atas, memudahkan peralihan cepat dan evaluasi.
Mulai Cepat dengan Gemini 3.1 Flash-Lite Preview
Contoh Minimalis
Berikut adalah kode paling sederhana untuk memanggil Gemini 3.1 Flash-Lite Preview melalui platform APIYI, dapat dijalankan hanya dengan 10 baris:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "Jelaskan komputasi kuantum dalam satu kalimat"}]
)
print(response.choices[0].message.content)
Lihat kode implementasi lengkap (termasuk Thinking Mode)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
Memanggil Gemini 3.1 Flash-Lite Preview
Args:
prompt: Input pengguna
system_prompt: Petunjuk sistem
max_tokens: Jumlah token output maksimum
enable_thinking: Apakah mengaktifkan Thinking Mode
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Contoh penggunaan
result = call_flash_lite(
prompt="Analisis kompleksitas waktu kode berikut dan berikan saran optimasi",
system_prompt="Kamu adalah seorang insinyur algoritma senior"
)
print(result)
Saran: Dapatkan Kunci API dan kuota uji coba gratis melalui APIYI apiyi.com untuk memverifikasi performa Gemini 3.1 Flash-Lite Preview dalam skenario Anda dengan cepat. Isi ulang mulai dari 100 USD dapat bonus 10 USD, diskon hingga 20%.
Skenario Penggunaan Gemini 3.1 Flash-Lite Preview
Skenario Penggunaan yang Direkomendasikan
| Skenario | Penjelasan | Mengapa Memilih Flash-Lite |
|---|---|---|
| Terjemahan Skala Besar | Alur kerja penerjemahan konten multibahasa | Output sangat cepat 380 tok/s + biaya rendah |
| Moderasi Konten | Klasifikasi dan penyaringan konten buatan pengguna | Pemanggilan frekuensi tinggi + biaya terkontrol |
| Ekstraksi Data | Ekstraksi dan pengaturan data terstruktur | Mendukung output JSON Schema |
| Routing Agent | Sebagai lapisan routing untuk mendistribusikan permintaan | Latensi sangat rendah + Function Calling |
| Pemrosesan Dokumen | Parsing dan ringkasan PDF/dokumen panjang | Konteks 1M + input multimodal |
| Transkripsi Audio | Konversi ucapan ke teks dan analisis | Dukungan input audio native |
Skenario yang Tidak Direkomendasikan
- Penulisan Kreatif Kompleks: Model tingkat Pro memiliki keunggulan lebih dalam penciptaan mendalam
- Pembuatan Gambar/Audio: Flash-Lite hanya mendukung output teks
- Percakapan Streaming Real-time: Tidak mendukung Live API
- Membutuhkan Akurasi Penalaran Tertinggi: Untuk skenario yang memerlukan akurasi maksimal, disarankan menggunakan Gemini 3.1 Pro
🎯 Saran Skenario: Tidak yakin model mana yang paling cocok untuk skenario Anda? Melalui APIYI apiyi.com, Anda dapat dengan cepat beralih dan membandingkan antara Gemini 3.1 Flash-Lite, Claude Haiku, dan GPT-5 mini untuk menemukan solusi optimal.
Pertanyaan Umum
Q1: Apa perbedaan antara Gemini 3.1 Flash-Lite Preview dan Gemini 2.5 Flash?
Perbedaan inti terletak pada arsitektur dan performa: Flash-Lite berbasis arsitektur Gemini 3 Pro (bukan arsitektur Gemini 2), respons token pertama 2.5 kali lebih cepat, kecepatan output meningkat 45% mencapai ~380 tok/s. Selain itu, menambahkan fitur lanjutan seperti Thinking Mode, eksekusi kode, dll.
Q2: Bagaimana stabilitas versi Preview? Apakah cocok untuk digunakan di lingkungan produksi?
Fungsi dan performa versi Preview mungkin akan disesuaikan di versi resmi. Disarankan untuk melakukan pengujian terlebih dahulu pada bisnis non-kritis, untuk bisnis kritis dapat disiapkan skema fallback. Saat dipanggil melalui APIYI apiyi.com, Anda dapat dengan mudah beralih antar model, mengimplementasikan strategi fallback yang fleksibel.
Q3: Bagaimana cara cepat memulai pengujian Gemini 3.1 Flash-Lite Preview?
Disarankan untuk melakukan pengujian melalui platform agregasi API yang mendukung banyak model:
- Kunjungi APIYI apiyi.com untuk mendaftar akun
- Dapatkan Kunci API dan kuota gratis
- Gunakan contoh kode dalam artikel ini, atur model menjadi
gemini-3.1-flash-lite-previewsaja - Isi ulang mulai dari 100 USD dapatkan bonus 10 USD, diskon hingga 20% tersedia
Ringkasan
Inti dari Gemini 3.1 Flash-Lite Preview:
- Performanya Sangat Cepat: Kecepatan output ~380 tok/s, peringkat ke-2 dari 132 model, respons token pertama 2.5x lebih cepat dari Flash 2.5
- Rasio Biaya-Manfaat Tinggi: Input $0.25/M, Output $1.50/M, hanya 1/8 dari Gemini 3 Pro, cocok untuk pemanggilan skala besar dan frekuensi tinggi
- Fungsionalitas Lengkap: Konteks 1M + 5 modalitas input + Thinking Mode + Function Calling, konfigurasi paling komprehensif di antara model ringan
- Gen Pro: Berdasarkan arsitektur Gemini 3 Pro, menunjukkan performa luar biasa dalam benchmark seperti GPQA Diamond (86.9%)
Untuk skenario aplikasi AI yang membutuhkan skala besar, biaya rendah, dan kecepatan tinggi, Gemini 3.1 Flash-Lite Preview adalah salah satu model ringan yang paling layak diperhatikan saat ini.
Direkomendasikan untuk mengakses dan mengujinya dengan cepat melalui APIYI apiyi.com. Harga platform konsisten dengan harga resmi Google, top-up $100 dapat bonus $10, diskon hingga 20%, dan dapat menggunakan 400+ Model Bahasa Besar secara terpusat.
📚 Referensi
-
Dokumentasi Model Resmi Google AI: Spesifikasi teknis lengkap Gemini 3.1 Flash-Lite Preview
- Tautan:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - Penjelasan: Dokumentasi API resmi, berisi daftar parameter dan fungsi terbaru
- Tautan:
-
Kartu Model Google DeepMind: Data benchmark dan evaluasi keamanan
- Tautan:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - Penjelasan: Kartu model resmi, berisi skor benchmark detail dan informasi pelatihan
- Tautan:
-
Evaluasi Artificial Analysis: Analisis performa dan harga independen pihak ketiga
- Tautan:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - Penjelasan: Berisi data evaluasi independen seperti kecepatan output, TTFT, indeks kecerdasan
- Tautan:
-
Blog Resmi Google: Pengumuman peluncuran Gemini 3.1 Flash-Lite
- Tautan:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - Penjelasan: Artikel peluncuran resmi, memperkenalkan posisi produk dan fitur inti
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Selamat berdiskusi di kolom komentar, materi lebih lanjut dapat diakses di pusat dokumentasi APIYI docs.apiyi.com