Note de l'auteur : Gemini 3.1 Flash-Lite Preview est désormais disponible avec une vitesse de sortie de 380 tok/s et un coût ultra-bas de 0,25 $/M. Cet article analyse en profondeur ses 5 principaux avantages, ses données de benchmark, sa comparaison avec les concurrents et la méthode d'accès à son API.
Google DeepMind a officiellement lancé le Gemini 3.1 Flash-Lite Preview le 3 mars 2026. C'est le modèle le plus rapide et le moins cher de la série Gemini 3. Basé sur l'architecture Gemini 3 Pro, sa vitesse de sortie atteint environ 380 tokens/s, soit 2,5 fois plus rapide pour le premier token et 45 % plus rapide en sortie que le Gemini 2.5 Flash.
Valeur clé : Cet article vous aidera à comprendre ce nouveau modèle léger sous tous ses aspects, à travers 5 dimensions : performances de référence, comparaison des coûts, caractéristiques fonctionnelles, scénarios d'application et intégration API, afin de déterminer s'il convient à vos cas d'usage.

Aperçu rapide des paramètres clés de Gemini 3.1 Flash-Lite Preview
Voici les principaux paramètres techniques extraits de la documentation officielle de Google AI et de la fiche technique DeepMind :
| Paramètre | Gemini 3.1 Flash-Lite Preview | Description |
|---|---|---|
| ID du modèle | gemini-3.1-flash-lite-preview |
À utiliser pour l'appel API |
| Architecture de base | Gemini 3 Pro | Hérite de l'architecture multimodale de niveau Pro |
| Fenêtre de contexte | 1 048 576 tokens (1M) | Environ 1 500 pages de document A4 |
| Sortie maximale | 65 536 tokens (64K) | Prise en charge de la génération de texte long |
| Vitesse de sortie | ~380 tokens/s | Classé 2ème parmi 132 modèles |
| Prix d'entrée | 0,25 $ / million de tokens | Le plus bas de la série Gemini 3 |
| Prix de sortie | 1,50 $ / million de tokens | 1/8 du prix de la version Pro |
| Limite de connaissances | Janvier 2025 | Identique à Gemini 3 Pro |
| Statut | Preview | Version préliminaire, version finale à venir |
Il est important de noter que Gemini 3.1 Flash-Lite Preview est construit sur l'architecture Gemini 3 Pro, ce qui signifie qu'il conserve les capacités de compréhension multimodale de niveau Pro dans un format « réduit ». Google le positionne comme le modèle de choix pour les « tâches légères et à haute fréquence ».
🎯 Conseil d'intégration : Gemini 3.1 Flash-Lite Preview est déjà disponible sur APIYI apiyi.com, aux mêmes tarifs que Google officiellement. Rechargez 100 $ et obtenez 10 $ offerts, avec des réductions pouvant aller jusqu'à 20 %. Utilisez plus de 400 grands modèles de langage en un seul endroit.
5 avantages clés de Gemini 3.1 Flash-Lite Preview
Avantage 1 : Inférence ultra-rapide — Vitesse de sortie de 380 tok/s
La vitesse de sortie de Gemini 3.1 Flash-Lite Preview atteint environ 380 tokens/s. Selon les données d'évaluation d'Artificial Analysis, elle se classe 2ème parmi 132 modèles principaux. Par rapport aux 249 tok/s de la génération précédente Gemini 2.5 Flash, les performances sont améliorées d'environ 45 %.
Le temps de réponse du premier token (TTFT) est encore plus impressionnant — 2,5 fois plus rapide que Gemini 2.5 Flash. Cette amélioration est significative pour les scénarios d'application nécessitant un retour instantané, comme les chatbots ou la traduction en temps réel.
Avantage 2 : Coût extrêmement bas — Entrée à seulement 0,25 $/M tokens
Dans la série Gemini 3, Flash-Lite coûte seulement 1/8 du prix de la version Pro. Plus précisément :
| Modèle | Prix d'entrée | Prix de sortie | Taux mixte (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | 0,25 $/M | 1,50 $/M | 0,56 $/M |
| Gemini 3 Pro | 2,00 $/M | 12,00 $/M | 4,50 $/M |
| Claude 4.5 Haiku | 1,00 $/M | 5,00 $/M | 2,00 $/M |
| GPT-5 mini | 0,15 $/M | 0,60 $/M | 0,26 $/M |
Flash-Lite offre un excellent équilibre entre prix et performances — bien que ce ne soit pas le moins cher en absolu, son rapport qualité-prix est exceptionnel compte tenu de sa vitesse de sortie de 380 tok/s et de sa fenêtre de contexte de 1M tokens.
Avantage 3 : Fenêtre de contexte d'un million de tokens
Une fenêtre de contexte de 1 048 576 tokens signifie que vous pouvez traiter en une seule requête :
- Environ 1 500 pages de documents A4
- Un dépôt de code complet
- Des contenus audio/vidéo de plusieurs heures
Cette configuration est très rare pour un modèle léger. En comparaison, GPT-5 mini ne prend en charge que 128K, et Claude 4.5 Haiku 200K.
Avantage 4 : Prise en charge d'entrées multimodales complètes
Bien que positionné comme un modèle léger, Gemini 3.1 Flash-Lite Preview prend en charge 5 modalités d'entrée :
- Texte : Capacité principale
- Image : Analyse et compréhension du contenu des images
- Audio : Transcription et analyse vocale
- Vidéo : Compréhension du contenu vidéo
- PDF : Analyse et résumé de documents
En sortie, seul le texte est pris en charge, mais cela est suffisant pour la plupart des tâches de traitement et d'analyse de données.
Avantage 5 : Prise en charge du mode de réflexion (Thinking Mode)
Pour un modèle léger, il est presque unique que Gemini 3.1 Flash-Lite Preview prenne en charge le Thinking Mode (mode de réflexion étendu). Une fois activé, le modèle effectue un raisonnement étape par étape, améliorant significativement la précision sur des tâches comme les connaissances scientifiques ou les calculs mathématiques.
🎯 Recommandation de plateforme : Vous voulez tester rapidement les performances du Thinking Mode de Gemini 3.1 Flash-Lite Preview ? Vous pouvez l'appeler directement via APIYI (apiyi.com), qui propose une interface unifiée pour plus de 400 grands modèles de langage principaux.
Données de référence de Gemini 3.1 Flash-Lite Preview
Voici les données d'évaluation provenant de la fiche technique de Google DeepMind et d'Artificial Analysis :
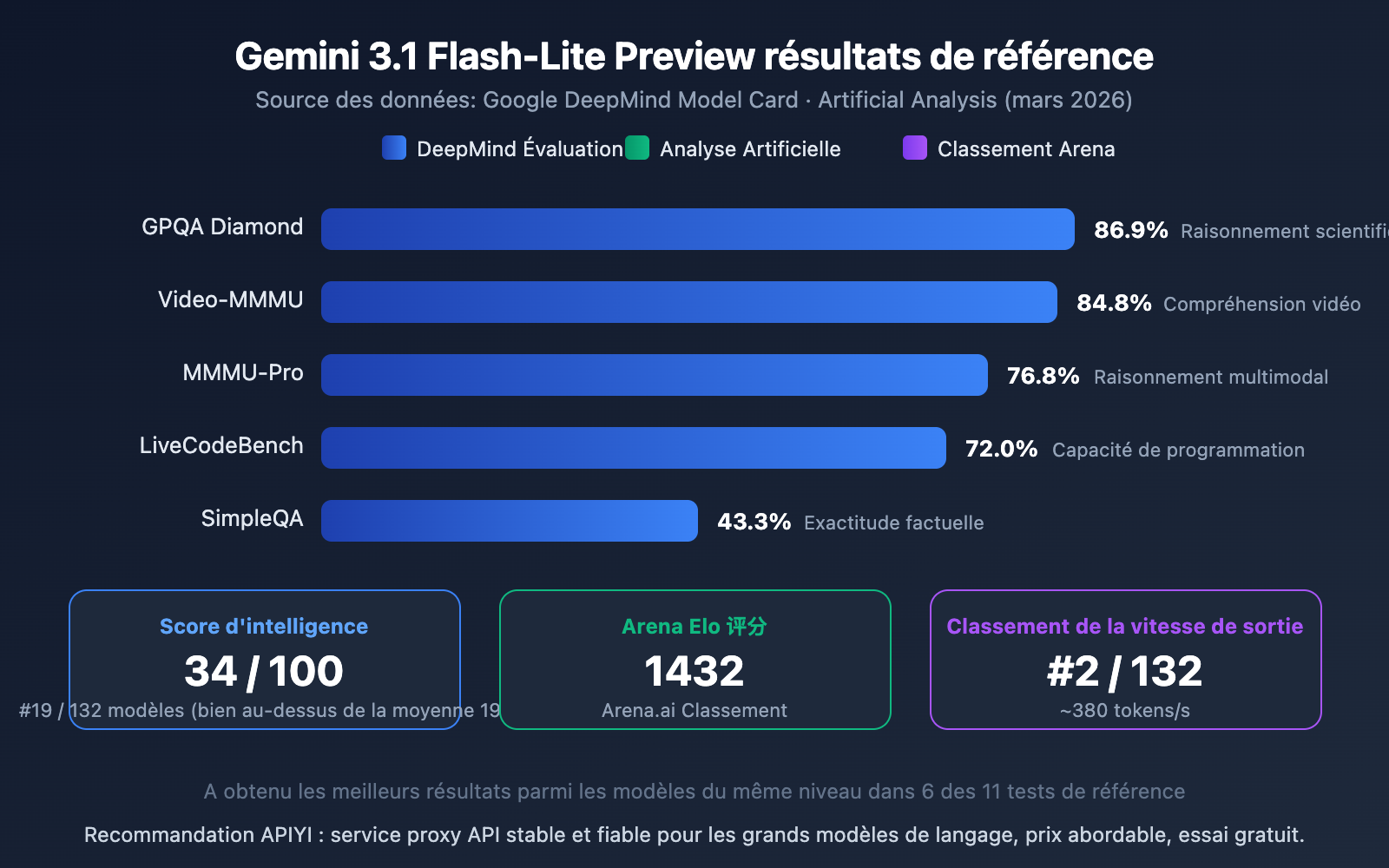
Interprétation des tests de référence de Gemini 3.1 Flash-Lite Preview
D'après les données, Flash-Lite présente des performances assez remarquables parmi les modèles légers :
- GPQA Diamond 86,9 % : Capacité de raisonnement scientifique en tête parmi les modèles de sa catégorie.
- Video-MMMU 84,8 % : Capacité de compréhension vidéo, reflétant son avantage multimodal.
- MMMU-Pro 76,8 % : Excellentes performances en raisonnement multimodal.
- Arena Elo 1432 : Score élevé sur le classement Arena.ai, prouvant une bonne expérience d'utilisation réelle.
- Indice d'intelligence 34/100 : Bien supérieur à la moyenne de 19 pour les modèles de sa catégorie, se classant 19ème parmi 132 modèles.
Sur 11 tests de référence, Flash-Lite a obtenu les meilleurs résultats dans sa catégorie pour 6 d'entre eux, ce qui est une performance très solide pour un modèle léger.
🎯 Conseil pour les tests pratiques : Les données de référence sont à titre indicatif, les résultats réels varient selon les scénarios. Il est recommandé d'effectuer des tests dans des scénarios réels via APIYI (apiyi.com). La plateforme offre un crédit gratuit et permet une comparaison rapide de plusieurs modèles.
Comparaison de Gemini 3.1 Flash-Lite Preview avec ses concurrents

| Dimension de comparaison | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| Vitesse de sortie | ~380 tok/s ⚡ | ~108 tok/s | ~71 tok/s |
| Prix d'entrée | 0,25 $/M | 1,00 $/M | 0,15 $/M ⚡ |
| Prix de sortie | 1,50 $/M | 5,00 $/M | 0,60 $/M ⚡ |
| Fenêtre de contexte | 1M tokens ⚡ | 200K tokens | 128K tokens |
| Entrée multimodale | 5 types ⚡ | 2 types | 2 types |
| Mode Thinking | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| API Batch | ✅ | ✅ | ✅ |
Résumé de la comparaison:
- Priorité vitesse : Les 380 tok/s de Flash-Lite sont 3,5 fois plus rapides que Haiku et 5,4 fois plus rapides que GPT-5 mini.
- Priorité coût : GPT-5 mini a des prix absolus plus bas, mais l'avantage en vitesse de Flash-Lite peut compenser l'écart de coût.
- Priorité fonctionnalités : Flash-Lite est nettement en avance sur la longueur de contexte (1M) et le support multimodal (5 types).
🎯 Conseil de choix : Le choix du modèle léger dépend du scénario spécifique. Nous recommandons de réaliser des tests de comparaison pratiques via APIYI (apiyi.com). La plateforme prend en charge l'invocation via une interface unifiée pour tous les modèles ci-dessus, facilitant ainsi la commutation rapide et l'évaluation.
Démarrage rapide avec Gemini 3.1 Flash-Lite Preview
Exemple minimal
Voici le code minimal pour appeler Gemini 3.1 Flash-Lite Preview via la plateforme APIYI, fonctionnel en seulement 10 lignes :
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "Expliquez l'informatique quantique en une phrase"}]
)
print(response.choices[0].message.content)
Voir le code d’implémentation complet (avec Thinking Mode)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
Appelle Gemini 3.1 Flash-Lite Preview
Args:
prompt: Entrée utilisateur
system_prompt: Invite système
max_tokens: Nombre maximum de tokens de sortie
enable_thinking: Activer le mode Thinking
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Erreur : {str(e)}"
# Exemple d'utilisation
result = call_flash_lite(
prompt="Analysez la complexité temporelle du code suivant et donnez des suggestions d'optimisation",
system_prompt="Vous êtes un ingénieur algorithmique senior"
)
print(result)
Recommandation : Obtenez une clé API et des crédits de test gratuits via APIYI (apiyi.com) pour valider rapidement les performances de Gemini 3.1 Flash-Lite Preview dans votre scénario. Rechargez 100 USD minimum et recevez 10 USD offerts, avec des réductions pouvant atteindre 20 %.
Scénarios d'utilisation de Gemini 3.1 Flash-Lite Preview
Scénarios recommandés
| Scénario | Description | Pourquoi choisir Flash-Lite |
|---|---|---|
| Traduction à grande échelle | Flux de travail de traduction de contenu multilingue | Sortie ultra-rapide à 380 tok/s + faible coût |
| Modération de contenu | Classification et filtrage de contenu généré par les utilisateurs | Appels à haute fréquence + coût maîtrisable |
| Extraction de données | Extraction et organisation de données structurées | Prise en charge de la sortie JSON Schema |
| Routage d'Agent | Agir comme couche de routage pour distribuer les requêtes | Latence ultra-faible + Function Calling |
| Traitement de documents | Analyse et résumé de PDF/documents longs | Contexte de 1M + entrées multimodales |
| Transcription audio | Transcription et analyse de la parole | Prise en charge native de l'entrée audio |
Scénarios non recommandés
- Écriture créative complexe: Les modèles de niveau Pro ont un avantage pour la création en profondeur
- Génération d'images/audio: Flash-Lite ne prend en charge que la sortie texte
- Conversation en flux continu en temps réel: Ne prend pas en charge l'API Live
- Besoins en précision de raisonnement maximale: Pour les scénarios exigeant une précision extrême, il est recommandé d'utiliser Gemini 3.1 Pro
🎯 Conseil de scénario: Vous ne savez pas quel modèle convient le mieux à votre cas d'usage ? Grâce à APIYI apiyi.com, vous pouvez rapidement basculer et comparer entre Gemini 3.1 Flash-Lite, Claude Haiku et GPT-5 mini pour trouver la solution optimale.
Questions fréquentes
Q1 : Quelle est la différence entre Gemini 3.1 Flash-Lite Preview et Gemini 2.5 Flash ?
La différence fondamentale réside dans l'architecture et les performances : Flash-Lite est basé sur l'architecture Gemini 3 Pro (et non Gemini 2), avec un temps de réponse du premier Token 2,5 fois plus rapide et une vitesse de sortie augmentée de 45% pour atteindre ~380 tok/s. Il ajoute également des fonctionnalités avancées comme le Thinking Mode et l'exécution de code.
Q2 : Quelle est la stabilité de la version Preview ? Est-elle adaptée à un usage en environnement de production ?
Les fonctionnalités et performances de la version Preview peuvent être ajustées dans la version finale. Il est recommandé de la tester d'abord dans des applications non critiques. Pour les applications critiques, il est conseillé de prévoir un plan de repli (dégradation). Lors de l'appel via APIYI apiyi.com, vous pouvez facilement basculer entre les modèles, ce qui permet une stratégie de repli flexible.
Q3 : Comment démarrer rapidement un test avec Gemini 3.1 Flash-Lite Preview ?
Il est recommandé de tester via une plateforme d'agrégation d'API prenant en charge plusieurs modèles :
- Visitez APIYI apiyi.com pour créer un compte
- Obtenez une clé API et un crédit gratuit
- Utilisez les exemples de code de cet article, en définissant le paramètre
modelsurgemini-3.1-flash-lite-preview - Un dépôt de 100 USD minimum offre un bonus de 10 USD, avec des réductions pouvant atteindre 20%
Résumé
Points clés de Gemini 3.1 Flash-Lite Preview :
- Performance ultra-rapide : Vitesse de sortie d'environ ~380 tok/s, classée 2ᵉ sur 132 modèles, temps de réponse du premier jeton 2,5 fois plus rapide que le 2.5 Flash.
- Rapport qualité-prix élevé : Entrée à 0,25 $/M, sortie à 1,50 $/M, soit seulement 1/8 du prix de Gemini 3 Pro, idéal pour des appels à grande échelle et haute fréquence.
- Fonctionnalités complètes : Fenêtre de contexte de 1M + 5 modalités d'entrée + Mode Réflexion (Thinking Mode) + Appel de fonctions, la configuration la plus complète parmi les modèles légers.
- ADN de niveau Pro : Basé sur l'architecture de Gemini 3 Pro, avec d'excellentes performances sur des benchmarks comme GPQA Diamond (86,9 %).
Pour les scénarios d'application d'IA nécessitant une grande échelle, un faible coût et une vitesse élevée, Gemini 3.1 Flash-Lite Preview est actuellement l'un des modèles légers les plus intéressants à surveiller.
Nous recommandons de le tester rapidement via APIYI apiyi.com. Les prix de la plateforme sont alignés sur ceux de Google officiel, avec un crédit de 10 $ offert à partir d'un dépôt de 100 $ et des réductions pouvant aller jusqu'à 20 %. Une solution unique pour utiliser 400+ grands modèles de langage.
📚 Références
-
Documentation officielle des modèles Google AI : Spécifications techniques complètes de Gemini 3.1 Flash-Lite Preview
- Lien :
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - Description : Documentation API officielle, incluant la liste des paramètres et fonctionnalités les plus récentes.
- Lien :
-
Fiche technique (Model Card) Google DeepMind : Données de benchmark et évaluation de sécurité
- Lien :
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - Description : Fiche technique officielle, contenant les scores détaillés des benchmarks et des informations sur l'entraînement.
- Lien :
-
Évaluation Artificial Analysis : Analyse indépendante des performances et des prix
- Lien :
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - Description : Contient des données d'évaluation indépendantes sur la vitesse de sortie, le TTFT, l'indice d'intelligence, etc.
- Lien :
-
Blog officiel Google : Annonce de lancement de Gemini 3.1 Flash-Lite
- Lien :
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - Description : Article de lancement officiel, présentant le positionnement produit et les caractéristiques principales.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : Bienvenue dans les commentaires pour discuter. Plus de ressources sont disponibles sur le centre de documentation APIYI docs.apiyi.com.