작가의 말: Gemini 3.1 Flash-Lite Preview가 380 tok/s의 출력 속도와 $0.25/M의 초저비용으로 출시되었습니다. 본문은 그 5가지 핵심 장점, 벤치마크 데이터, 경쟁 모델 비교, API 접속 방법을 깊이 있게 분석합니다.
Google DeepMind는 2026년 3월 3일에 공식적으로 Gemini 3.1 Flash-Lite Preview를 발표했습니다. 이는 Gemini 3 시리즈 중 가장 빠르고 비용이 가장 낮은 모델입니다. Gemini 3 Pro 아키텍처를 기반으로 하여, 출력 속도는 약 380 tokens/s에 달하며, Gemini 2.5 Flash보다 첫 토큰 응답 속도가 2.5배 빠르고, 출력 속도는 45% 향상되었습니다.
핵심 가치: 본문은 성능 벤치마크, 비용 비교, 기능 특성, 적합한 사용 시나리오, API 접속이라는 5가지 차원에서 이 새롭게 출시된 경량 모델을 종합적으로 이해하고, 여러분의 비즈니스 시나리오에 적합한지 판단하는 데 도움을 드릴 것입니다.

Gemini 3.1 Flash-Lite Preview 핵심 매개변수 빠른 확인
다음은 Google AI 공식 문서와 DeepMind 모델 카드에서 추출한 핵심 기술 매개변수입니다:
| 매개변수 항목 | Gemini 3.1 Flash-Lite Preview | 설명 |
|---|---|---|
| 모델 ID | gemini-3.1-flash-lite-preview |
API 호출 시 이 ID 사용 |
| 아키텍처 기반 | Gemini 3 Pro | Pro급 멀티모달 아키텍처 상속 |
| 컨텍스트 윈도우 | 1,048,576 토큰 (1M) | 약 1,500페이지 A4 문서 |
| 최대 출력 | 65,536 토큰 (64K) | 긴 텍스트 생성 지원 |
| 출력 속도 | ~380 토큰/s | 132개 모델 중 2위 |
| 입력 가격 | $0.25 / 백만 토큰 | Gemini 3 시리즈 최저 |
| 출력 가격 | $1.50 / 백만 토큰 | Pro 버전의 1/8 |
| 지식 컷오프 | 2025년 1월 | Gemini 3 Pro와 일치 |
| 상태 | Preview | 프리뷰 버전, 정식 버전 출시 예정 |
주목할 점은, Gemini 3.1 Flash-Lite Preview가 Gemini 3 Pro 아키텍처를 기반으로 구축되었다는 점입니다. 이는 '축소판' 규모에서도 Pro급 멀티모달 이해 능력을 유지한다는 의미입니다. Google은 이를 '고빈도, 경량 작업'의 최적 모델로 포지셔닝하고 있습니다.
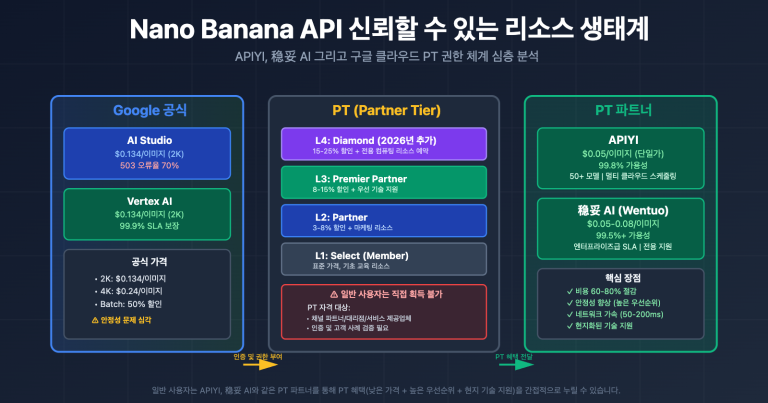
🎯 접속 제안: Gemini 3.1 Flash-Lite Preview는 이미 APIYI apiyi.com에서 출시되었으며, 가격은 Google 공식 가격과 동일합니다. 100달러 충전 시 10달러를 증정하며, 최저 8할 할인 혜택을 제공하고, 400개 이상의 대규모 언어 모델을 한 곳에서 사용할 수 있습니다.
Gemini 3.1 Flash-Lite Preview의 5가지 핵심 장점
장점 1: 극한의 속도 – 380 tok/s 출력 속도
Gemini 3.1 Flash-Lite Preview의 출력 속도는 약 380 tokens/s에 달하며, Artificial Analysis의 벤치마크 데이터에 따르면 132개의 주요 모델 중 2위를 기록했습니다. 전작인 Gemini 2.5 Flash의 249 tok/s와 비교하면 성능이 약 45% 향상된 수치입니다.
첫 번째 토큰 응답 시간(TTFT) 측면에서는 더욱 인상적입니다. Gemini 2.5 Flash보다 2.5배 빠릅니다. 채팅봇이나 실시간 번역처럼 즉각적인 피드백이 필요한 애플리케이션에서는 이 개선이 매우 큰 의미를 가집니다.
장점 2: 극한의 비용 – 입력당 단 $0.25/M tokens
Gemini 3 시리즈에서 Flash-Lite의 가격은 Pro 버전의 1/8에 불과합니다. 구체적으로 살펴보면:
| 모델 | 입력 가격 | 출력 가격 | 혼합 요율 (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0.25/M | $1.50/M | $0.56/M |
| Gemini 3 Pro | $2.00/M | $12.00/M | $4.50/M |
| Claude 4.5 Haiku | $1.00/M | $5.00/M | $2.00/M |
| GPT-5 mini | $0.15/M | $0.60/M | $0.26/M |
Flash-Lite는 가격과 성능 사이에서 탁월한 균형을 찾았습니다. 절대적으로 가장 저렴한 모델은 아니지만, 380 tok/s의 출력 속도와 1M 컨텍스트 윈도우를 고려하면 가성비가 매우 뛰어납니다.
장점 3: 백만 토큰 급 컨텍스트 윈도우
1,048,576 토큰의 컨텍스트 윈도우는 단일 요청으로 다음과 같은 작업을 처리할 수 있음을 의미합니다:
- 약 1,500페이지 분량의 A4 문서
- 완전한 코드 저장소
- 수 시간 분량의 오디오/비디오 콘텐츠
이는 경량 모델에서는 매우 드문 구성입니다. 비교하자면, GPT-5 mini는 128K만 지원하고, Claude 4.5 Haiku는 200K를 지원합니다.
장점 4: 전(全) 모달 입력 지원
경량 모델이라는 포지션에도 불구하고, Gemini 3.1 Flash-Lite Preview는 5가지 입력 모달리티를 지원합니다:
- 텍스트: 핵심 능력
- 이미지: 사진 내용 분석 및 이해
- 오디오: 음성 전사 및 분석
- 비디오: 비디오 콘텐츠 이해
- PDF: 문서 파싱 및 요약
출력은 텍스트만 지원하지만, 대부분의 데이터 처리 및 분석 작업에는 이 정도면 충분합니다.
장점 5: Thinking Mode 지원
경량 모델임에도 불구하고, Gemini 3.1 Flash-Lite Preview는 Thinking Mode(확장 사고 모드)를 지원합니다. 이는 동급 모델 중 거의 유일무이한 특징입니다. 활성화하면 모델이 단계별 추론을 수행하여 과학 지식, 수학 계산 등의 작업에서 정확도를 크게 향상시킵니다.
🎯 플랫폼 추천: Gemini 3.1 Flash-Lite Preview의 Thinking Mode 성능을 빠르게 테스트해 보고 싶으신가요? APIYI apiyi.com을 통해 직접 호출할 수 있으며, 400개 이상의 주요 대규모 언어 모델을 위한 통합 인터페이스를 제공합니다.
Gemini 3.1 Flash-Lite Preview 벤치마크 데이터
다음은 Google DeepMind 모델 카드와 Artificial Analysis의 평가 데이터입니다:
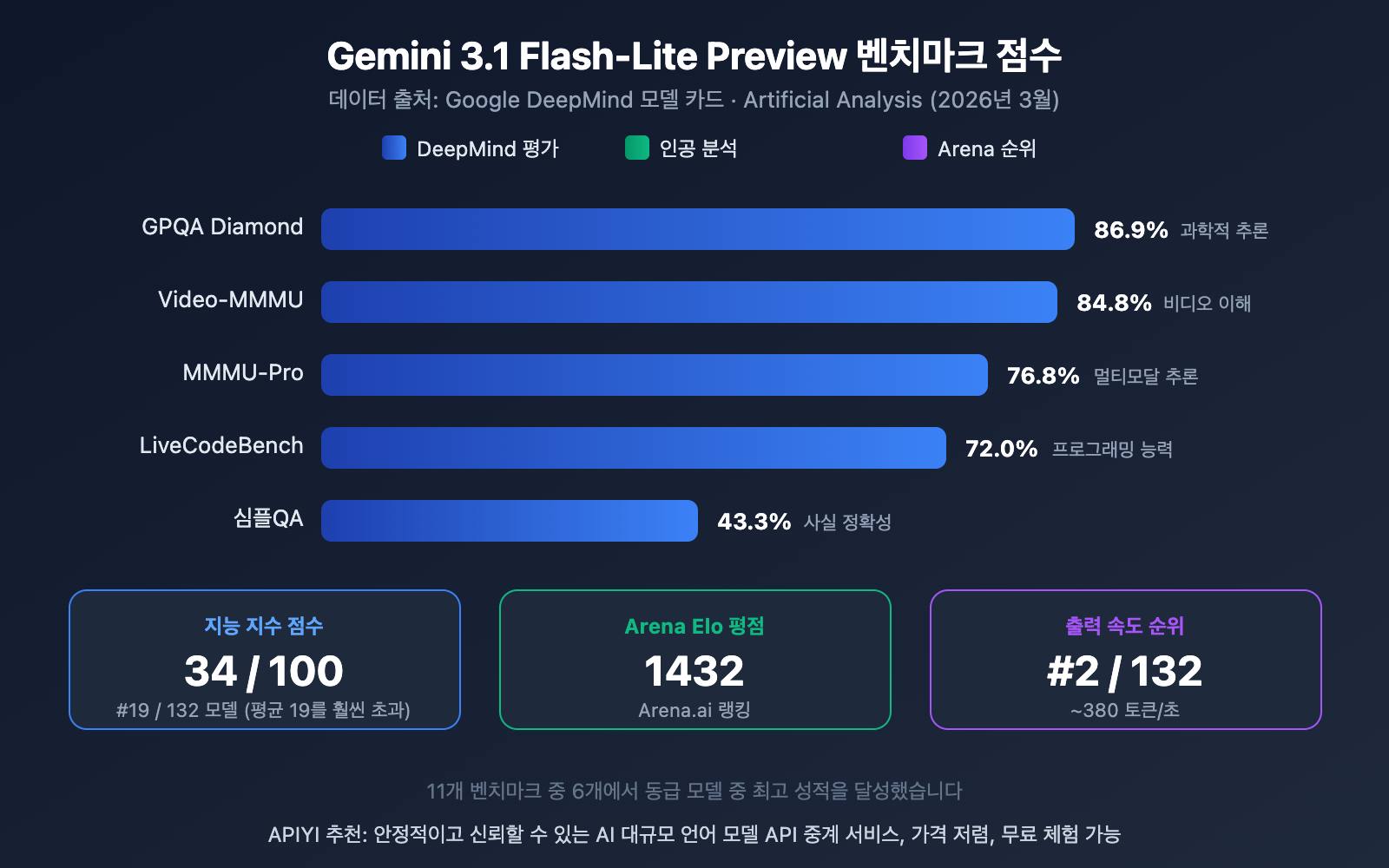
Gemini 3.1 Flash-Lite Preview 벤치마크 해석
데이터를 보면 Flash-Lite는 경량 모델 중에서도 상당히 인상적인 성능을 보여줍니다:
- GPQA Diamond 86.9%: 과학 지식 추론 능력이 동급 모델 중 선두
- Video-MMMU 84.8%: 비디오 이해 능력은 멀티모달 장점의 발현
- MMMU-Pro 76.8%: 멀티모달 추론 성능 우수
- Arena Elo 1432: Arena.ai 순위표에서 높은 점수 획득, 실제 사용 경험 우수함 증명
- 지능 지수 34/100: 동급 모델 평균 19점을 크게 상회, 132개 모델 중 19위
11개의 벤치마크 테스트 중 Flash-Lite는 6개 항목에서 동급 최고 성적을 거두었습니다. 이는 경량급 모델에게는 매우 뛰어난 성과입니다.
🎯 실제 테스트 권장사항: 벤치마크 데이터는 참고용입니다. 실제 효과는 시나리오에 따라 다릅니다. APIYI apiyi.com을 통해 실제 시나리오 테스트를 진행해 보시길 권장합니다. 플랫폼은 무료 크레딧을 제공하며, 여러 모델을 빠르게 비교할 수 있습니다.
Gemini 3.1 Flash-Lite Preview와 경쟁 모델 비교

| 비교 항목 | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| 출력 속도 | ~380 tok/s ⚡ | ~108 tok/s | ~71 tok/s |
| 입력 가격 | $0.25/M | $1.00/M | $0.15/M ⚡ |
| 출력 가격 | $1.50/M | $5.00/M | $0.60/M ⚡ |
| 컨텍스트 윈도우 | 1M tokens ⚡ | 200K tokens | 128K tokens |
| 멀티모달 입력 | 5 종류 ⚡ | 2 종류 | 2 종류 |
| Thinking Mode | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| Batch API | ✅ | ✅ | ✅ |
비교 요약:
- 속도 우선: Flash-Lite의 380 tok/s는 Haiku보다 3.5배, GPT-5 mini보다 5.4배 빠릅니다.
- 비용 우선: GPT-5 mini의 절대 가격은 더 낮지만, Flash-Lite의 속도 장점이 비용 차이를 상쇄할 수 있습니다.
- 기능 우선: Flash-Lite는 컨텍스트 길이(1M)와 멀티모달 지원(5종)에서 확실히 앞섭니다.
🎯 선택 가이드: 어떤 경량 모델을 선택할지는 구체적인 사용 시나리오에 따라 다릅니다. APIYI apiyi.com을 통해 실제 비교 테스트를 진행해보시길 권장합니다. 플랫폼은 위 모든 모델의 통합 인터페이스 호출을 지원하여 빠른 전환과 평가가 가능합니다.
Gemini 3.1 Flash-Lite Preview 빠른 시작
최소한의 예제
다음은 APIYI 플랫폼을 통해 Gemini 3.1 Flash-Lite Preview를 호출하는 가장 간단한 코드입니다. 10줄만으로 실행할 수 있어요:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "양자 컴퓨팅을 한 문장으로 설명해주세요"}]
)
print(response.choices[0].message.content)
전체 구현 코드 보기 (Thinking Mode 포함)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
Gemini 3.1 Flash-Lite Preview 호출하기
Args:
prompt: 사용자 입력
system_prompt: 시스템 프롬프트
max_tokens: 최대 출력 토큰 수
enable_thinking: Thinking Mode 활성화 여부
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 사용 예시
result = call_flash_lite(
prompt="다음 코드의 시간 복잡도를 분석하고 최적화 제안을 해주세요",
system_prompt="당신은 고급 알고리즘 엔지니어입니다"
)
print(result)
권장사항: APIYI apiyi.com에서 API 키와 무료 테스트 크레딧을 받아, Gemini 3.1 Flash-Lite Preview가 여러분의 시나리오에서 어떻게 작동하는지 빠르게 검증해보세요. 100달러 충전 시 10달러를 추가로 드리며, 최대 20% 할인 혜택을 제공합니다.
Gemini 3.1 Flash-Lite Preview 적용 사례
권장 사용 사례
| 사례 | 설명 | Flash-Lite를 선택하는 이유 |
|---|---|---|
| 대규모 번역 | 다국어 콘텐츠 번역 워크플로 | 380 tok/s 초고속 출력 + 저비용 |
| 콘텐츠 심사 | 사용자 생성 콘텐츠 분류 및 필터링 | 고빈도 호출 + 비용 통제 가능 |
| 데이터 추출 | 구조화된 데이터 추출 및 정리 | JSON Schema 출력 지원 |
| 에이전트 라우팅 | 라우팅 계층으로 요청 분배 | 초저지연 + Function Calling |
| 문서 처리 | PDF/장문서 파싱 및 요약 | 1M 컨텍스트 + 멀티모달 입력 |
| 오디오 전사 | 음성 텍스트 변환 및 분석 | 네이티브 오디오 입력 지원 |
비권장 사례
- 복잡한 창작 글쓰기: Pro 급 모델이 깊이 있는 창작에 더 유리합니다
- 이미지/오디오 생성: Flash-Lite는 텍스트 출력만 지원합니다
- 실시간 스트리밍 대화: Live API를 지원하지 않습니다
- 최고 수준의 추론 정확도 필요: 극한의 정확도가 요구되는 사례에는 Gemini 3.1 Pro 사용을 권장합니다
🎯 사례 제안: 어떤 모델이 여러분의 사례에 가장 적합한지 모르겠나요? APIYI apiyi.com을 통해 Gemini 3.1 Flash-Lite, Claude Haiku, GPT-5 mini 간에 빠르게 전환하며 비교하여 최적의 솔루션을 찾을 수 있습니다.
자주 묻는 질문
Q1: Gemini 3.1 Flash-Lite Preview와 Gemini 2.5 Flash의 차이점은 무엇인가요?
핵심 차이는 아키텍처와 성능에 있습니다: Flash-Lite는 Gemini 3 Pro 아키텍처(而非 Gemini 2 아키텍처)를 기반으로 하며, 첫 토큰 응답 속도가 2.5배 빠르고, 출력 속도가 45% 향상되어 ~380 tok/s에 도달합니다. 동시에 Thinking Mode, 코드 실행 등 고급 기능이 새롭게 추가되었습니다.
Q2: Preview 버전의 안정성은 어떻습니까? 프로덕션 환경에 사용하기 적합한가요?
Preview 버전의 기능과 성능은 정식 버전에서 조정될 수 있습니다. 중요하지 않은 비즈니스에서 먼저 테스트해보고, 핵심 비즈니스에는 다운그레이드 방안을 마련하는 것을 권장합니다. APIYI apiyi.com을 통해 호출할 때는 모델 간 전환이 편리하여 유연한 다운그레이드 전략을 구현할 수 있습니다.
Q3: Gemini 3.1 Flash-Lite Preview를 빠르게 테스트하려면 어떻게 해야 하나요?
다중 모델을 지원하는 API 통합 플랫폼을 통한 테스트를 권장합니다:
- APIYI apiyi.com 방문 후 계정 등록
- API 키와 무료 크레딧 획득
- 본문의 코드 예제를 사용하여 model을
gemini-3.1-flash-lite-preview로 설정 - 100달러 충전 시 10달러 추가 증정, 최대 20% 할인 혜택
요약
Gemini 3.1 Flash-Lite Preview의 핵심 포인트:
- 극속 성능: ~380 tok/s 출력 속도, 132개 모델 중 2위, 첫 토큰 응답 시간이 2.5 Flash보다 2.5배 빠름
- 높은 가성비: 입력 $0.25/M, 출력 $1.50/M, Gemini 3 Pro의 1/8 수준으로 고빈도 대규모 호출에 적합
- 포괄적인 기능: 1M 컨텍스트 윈도우 + 5가지 입력 모달리티 + Thinking Mode + Function Calling, 경량 모델 중 가장 포괄적인 구성
- Pro급 유전자: Gemini 3 Pro 아키텍처 기반, GPQA Diamond(86.9%) 등 벤치마크에서 우수한 성능
대규모, 저비용, 고속 AI 애플리케이션 시나리오가 필요한 경우, Gemini 3.1 Flash-Lite Preview는 현재 가장 주목할 만한 경량 모델 중 하나입니다.
APIYI apiyi.com을 통해 빠르게 접속하여 테스트해 보시길 추천합니다. 플랫폼 가격은 Google 공식 가격과 동일하며, 100달러 충전 시 10달러를 추가로 드리고, 최대 20% 할인 혜택을 제공합니다. 400개 이상의 대규모 언어 모델을 한 곳에서 사용할 수 있습니다.
📚 참고 자료
-
Google AI 공식 모델 문서: Gemini 3.1 Flash-Lite Preview 완전한 기술 사양
- 링크:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - 설명: 최신 파라미터와 기능 목록을 포함한 공식 API 문서
- 링크:
-
Google DeepMind 모델 카드: 벤치마크 데이터와 안전성 평가
- 링크:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - 설명: 상세한 벤치마크 점수와 훈련 정보를 포함한 공식 모델 카드
- 링크:
-
Artificial Analysis 평가: 독립 제3자 성능 및 가격 분석
- 링크:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - 설명: 출력 속도, TTFT, 지능 지수 등의 독립 평가 데이터 포함
- 링크:
-
Google 공식 블로그: Gemini 3.1 Flash-Lite 출시 공지
- 링크:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - 설명: 제품 포지셔닝과 핵심 특성을 소개하는 공식 출시 글
- 링크:
저자: APIYI 기술 팀
기술 교류: 댓글에서 토론을 환영합니다. 더 많은 자료는 APIYI docs.apiyi.com 문서 센터를 방문하세요.