Примечание автора: Gemini 3.1 Flash-Lite Preview вышла с рекордной скоростью вывода 380 токенов/с и сверхнизкой стоимостью $0.25/М. В этой статье подробно разбираем 5 ключевых преимуществ, данные бенчмарков, сравнение с конкурентами и способы подключения через API.
Google DeepMind 3 марта 2026 года официально представила Gemini 3.1 Flash-Lite Preview — самую быструю и экономичную модель в семействе Gemini 3. Основанная на архитектуре Gemini 3 Pro, она демонстрирует скорость вывода около 380 токенов/с, что в 2.5 раза быстрее по времени до первого токена и на 45% быстрее по скорости вывода по сравнению с Gemini 2.5 Flash.
Основная ценность: Эта статья поможет вам всесторонне оценить новую облегчённую модель по 5 параметрам: производительность в тестах, сравнение стоимости, функциональные возможности, подходящие сценарии использования и подключение через API, чтобы понять, подходит ли она для ваших бизнес-задач.

Краткий обзор ключевых параметров Gemini 3.1 Flash-Lite Preview
Ниже приведены основные технические параметры, извлечённые из официальной документации Google AI и модельной карты DeepMind:
| Параметр | Gemini 3.1 Flash-Lite Preview | Описание |
|---|---|---|
| ID модели | gemini-3.1-flash-lite-preview |
Используется для вызова через API |
| Архитектурная основа | Gemini 3 Pro | Наследует мультимодальную архитектуру Pro-уровня |
| Контекстное окно | 1,048,576 токенов (1M) | ~1,500 страниц документа A4 |
| Максимальный вывод | 65,536 токенов (64K) | Поддерживает генерацию длинных текстов |
| Скорость вывода | ~380 токенов/с | 2-е место среди 132 моделей |
| Стоимость ввода | $0.25 / млн токенов | Самая низкая в семействе Gemini 3 |
| Стоимость вывода | $1.50 / млн токенов | 1/8 от стоимости Pro-версии |
| Обновление знаний | Январь 2025 г. | Совпадает с Gemini 3 Pro |
| Статус | Preview | Предварительная версия, официальный релиз ожидается |
Важно отметить, что Gemini 3.1 Flash-Lite Preview построена на архитектуре Gemini 3 Pro, что означает сохранение способностей к мультимодальному пониманию на уровне Pro в «уменьшенном» варианте. Google позиционирует её как модель первого выбора для «частых, лёгких задач».
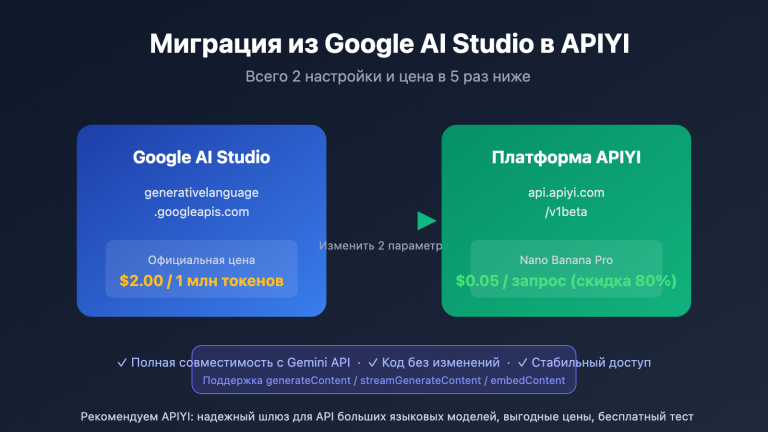
🎯 Рекомендация по подключению: Gemini 3.1 Flash-Lite Preview уже доступна на APIYI apiyi.com по ценам, идентичным официальным от Google. При пополнении от 100 долларов дарим 10 долларов, минимальная скидка — 20%. Единая точка доступа к 400+ большим языковым моделям.
5 ключевых преимуществ Gemini 3.1 Flash-Lite Preview
Преимущество 1: Молниеносная генерация — скорость вывода 380 токенов/с
Скорость генерации текста у Gemini 3.1 Flash-Lite Preview достигает примерно 380 токенов/с. Согласно данным оценки от Artificial Analysis, это 2-е место среди 132 основных моделей. По сравнению с предыдущим поколением Gemini 2.5 Flash (249 токенов/с), производительность выросла примерно на 45%.
Ещё более впечатляющим является время до первого токена (TTFT) — оно в 2.5 раза быстрее, чем у Gemini 2.5 Flash. Для приложений, требующих мгновенной обратной связи (например, чат-боты, перевод в реальном времени), это улучшение имеет огромное значение.
Преимущество 2: Крайне низкая стоимость — всего $0.25 за 1 млн токенов на входе
В линейке Gemini 3 модель Flash-Lite стоит всего 1/8 от цены версии Pro. Конкретно:
| Модель | Цена за вход (за 1 млн токенов) | Цена за выход (за 1 млн токенов) | Смешанный тариф (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | $0.56 |
| Gemini 3 Pro | $2.00 | $12.00 | $4.50 |
| Claude 4.5 Haiku | $1.00 | $5.00 | $2.00 |
| GPT-5 mini | $0.15 | $0.60 | $0.26 |
Flash-Lite демонстрирует отличный баланс между ценой и производительностью — она не самая дешёвая в абсолютном выражении, но с учётом скорости вывода 380 токенов/с и контекстного окна в 1 млн токенов, её ценность очень высока.
Преимущество 3: Контекстное окно на миллион токенов
Контекстное окно в 1 048 576 токенов означает, что за один запрос вы можете обработать:
- Примерно 1500 страниц документа формата A4
- Целый репозиторий с кодом
- Аудио- или видеоконтент длиной в несколько часов
Такая конфигурация для лёгких моделей встречается крайне редко. Для сравнения, GPT-5 mini поддерживает только 128K, а Claude 4.5 Haiku — 200K.
Преимущество 4: Поддержка всех модальностей на входе
Несмотря на позиционирование как лёгкой модели, Gemini 3.1 Flash-Lite Preview поддерживает 5 типов входных данных:
- Текст: основная возможность
- Изображения: анализ и понимание содержимого картинок
- Аудио: расшифровка и анализ речи
- Видео: понимание видеоконтента
- PDF: парсинг и суммаризация документов
На выходе модель поддерживает только текст, но для большинства задач по обработке и анализу данных этого вполне достаточно.
Преимущество 5: Поддержка Thinking Mode (режима размышления)
Для лёгкой модели невероятно, но Gemini 3.1 Flash-Lite Preview поддерживает Thinking Mode (режим расширенного размышления), что почти уникально среди моделей своего класса. При включении этого режима модель выполняет пошаговые рассуждения, что значительно повышает точность в таких задачах, как научные знания, математические вычисления и т.д.
🎯 Рекомендация платформы: Хотите быстро протестировать работу Thinking Mode в Gemini 3.1 Flash-Lite Preview? Через APIYI apiyi.com можно напрямую вызывать модель, используя унифицированный интерфейс для 400+ основных больших языковых моделей.
Данные бенчмарков Gemini 3.1 Flash-Lite Preview
Ниже представлены данные оценки из модели Google DeepMind и от Artificial Analysis:
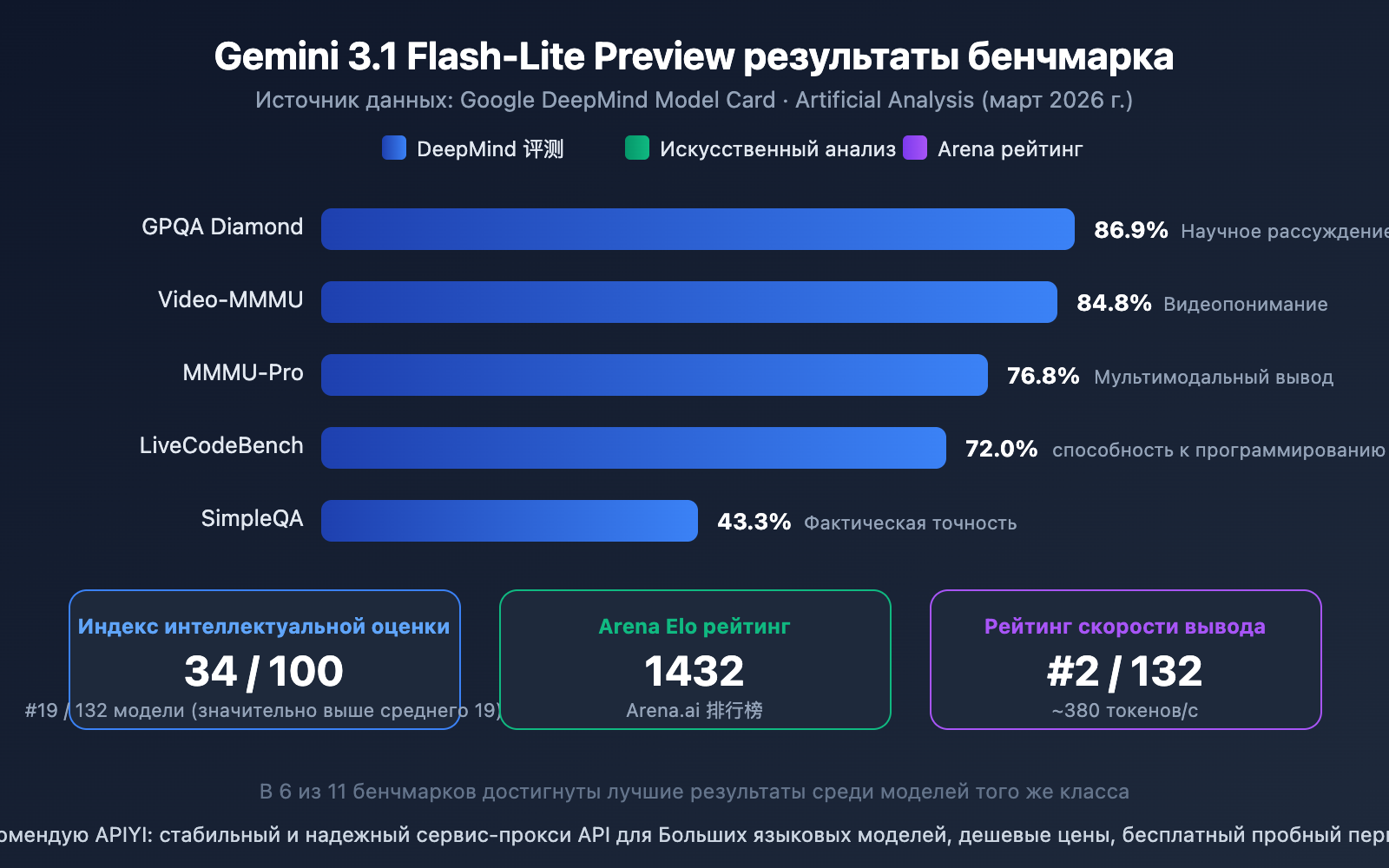
Интерпретация результатов бенчмарков Gemini 3.1 Flash-Lite Preview
Судя по данным, Flash-Lite показывает весьма впечатляющие результаты среди лёгких моделей:
- GPQA Diamond 86.9%: Способность к научным рассуждениям лидирует среди моделей своего класса.
- Video-MMMU 84.8%: Способность понимать видео демонстрирует её мультимодальные преимущества.
- MMMU-Pro 76.8%: Отличные результаты в мультимодальных рассуждениях.
- Arena Elo 1432: Высокий балл в рейтинге Arena.ai, что доказывает хороший опыт реального использования.
- Индекс интеллекта 34/100: Значительно превышает средний показатель для моделей своего класса (19), занимая 19-е место среди 132 моделей.
В 11 тестах Flash-Lite показала лучшие в своём классе результаты в 6 из них, что является выдающимся достижением для лёгкой модели.
🎯 Совет по тестированию: Данные бенчмарков носят справочный характер, фактическая эффективность зависит от сценария. Рекомендуем провести тестирование в реальных сценариях через APIYI apiyi.com. Платформа предоставляет бесплатный лимит и поддерживает быстрое сравнение нескольких моделей.
Сравнение Gemini 3.1 Flash-Lite Preview с конкурентами

| Критерий сравнения | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| Скорость вывода | ~380 токенов/с ⚡ | ~108 токенов/с | ~71 токенов/с |
| Цена ввода | $0.25/M | $1.00/M | $0.15/M ⚡ |
| Цена вывода | $1.50/M | $5.00/M | $0.60/M ⚡ |
| Контекстное окно | 1M токенов ⚡ | 200K токенов | 128K токенов |
| Мультимодальный ввод | 5 типов ⚡ | 2 типа | 2 типа |
| Thinking Mode | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| Batch API | ✅ | ✅ | ✅ |
Итоги сравнения:
- Приоритет скорости: Flash-Lite с 380 токенов/с в 3.5 раза быстрее Haiku и в 5.4 раза быстрее GPT-5 mini.
- Приоритет стоимости: Абсолютная цена GPT-5 mini ниже, но преимущество Flash-Lite в скорости может компенсировать разницу в цене.
- Приоритет функциональности: Flash-Lite явно лидирует по длине контекста (1M) и поддержке мультимодальности (5 типов).
🎯 Рекомендация по выбору: Какую легковесную модель выбрать, зависит от конкретной задачи. Мы советуем провести практическое сравнение через платформу APIYI apiyi.com, которая поддерживает единый интерфейс для вызова всех перечисленных моделей, что упрощает быстрое переключение и оценку.
Быстрый старт с Gemini 3.1 Flash-Lite Preview
Минимальный пример
Вот самый простой код для вызова Gemini 3.1 Flash-Lite Preview через платформу APIYI — всего 10 строк, и он готов к запуску:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "Объясни квантовые вычисления в одном предложении"}]
)
print(response.choices[0].message.content)
Посмотреть полный код (включая Thinking Mode)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
Вызов Gemini 3.1 Flash-Lite Preview
Args:
prompt: Пользовательский промпт
system_prompt: Системный промпт
max_tokens: Максимальное количество токенов на вывод
enable_thinking: Включить ли Thinking Mode
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Ошибка: {str(e)}"
# Пример использования
result = call_flash_lite(
prompt="Проанализируй временную сложность этого кода и дай рекомендации по оптимизации",
system_prompt="Ты — старший инженер по алгоритмам"
)
print(result)
Совет: Получите API-ключ и бесплатные тестовые кредиты на APIYI apiyi.com, чтобы быстро проверить, как Gemini 3.1 Flash-Lite Preview справляется с вашими задачами. При пополнении от 100$ дарим 10$, минимальная скидка — 20%.
Рекомендуемые сценарии использования
| Сценарий | Описание | Почему выбирают Flash-Lite |
|---|---|---|
| Массовый перевод | Рабочий процесс перевода многоязычного контента | Сверхбыстрая скорость вывода 380 ток/с + низкая стоимость |
| Модерация контента | Классификация и фильтрация пользовательского контента | Высокая частота вызовов + контролируемые затраты |
| Извлечение данных | Извлечение и структурирование данных | Поддержка вывода в формате JSON Schema |
| Маршрутизация агентов | Использование в качестве слоя маршрутизации для распределения запросов | Сверхнизкая задержка + Function Calling |
| Обработка документов | Парсинг и суммаризация PDF/длинных документов | Контекстное окно 1 млн токенов + мультимодальный ввод |
| Транскрипция аудио | Преобразование речи в текст и анализ | Поддержка нативного аудиоввода |
Не рекомендуемые сценарии
- Сложное креативное написание: Модели уровня Pro имеют преимущество в глубоком творчестве
- Генерация изображений/аудио: Flash-Lite поддерживает только текстовый вывод
- Диалоги в реальном времени с потоковой передачей: Не поддерживает Live API
- Требующие максимальной точности рассуждений: Для сценариев, требующих предельной точности, рекомендуется использовать Gemini 3.1 Pro
🎯 Совет по выбору модели: Не уверены, какая модель лучше всего подходит для вашей задачи? Через сервис APIYI (apiyi.com) можно быстро переключаться и сравнивать Gemini 3.1 Flash-Lite, Claude Haiku и GPT-5 mini, чтобы найти оптимальное решение.
Часто задаваемые вопросы
Вопрос 1: Чем Gemini 3.1 Flash-Lite Preview отличается от Gemini 2.5 Flash?
Ключевое отличие заключается в архитектуре и производительности: Flash-Lite основана на архитектуре Gemini 3 Pro (а не Gemini 2), время отклика на первый токен в 2.5 раза быстрее, а скорость вывода увеличена на 45%, достигая ~380 ток/с. Также добавлены расширенные функции, такие как Thinking Mode и выполнение кода.
Вопрос 2: Насколько стабильна Preview-версия? Подходит ли она для использования в production?
Функциональность и производительность Preview-версии могут быть скорректированы в финальном релизе. Рекомендуется сначала протестировать её на некритичных задачах, а для ключевых бизнес-процессов предусмотреть план отката. При вызове через APIYI (apiyi.com) можно легко переключаться между моделями, реализуя гибкую стратегию отката.
Вопрос 3: Как быстро начать тестирование Gemini 3.1 Flash-Lite Preview?
Рекомендуем проводить тестирование через агрегатор API, поддерживающий множество моделей:
- Зарегистрируйте аккаунт на APIYI (apiyi.com)
- Получите API-ключ и бесплатный кредит
- Используйте примеры кода из этой статьи, установив параметр
modelв значениеgemini-3.1-flash-lite-preview - Пополнение от 100 долларов даёт бонус 10 долларов, минимальная доступная скидка — 20%
Итоги
Ключевые моменты о Gemini 3.1 Flash-Lite Preview:
- Молниеносная производительность: скорость вывода ~380 токенов/с, занимает 2-е место среди 132 моделей, время до первого токена (TTFT) в 2.5 раза быстрее, чем у Gemini 2.5 Flash.
- Высокая экономичность: стоимость ввода $0.25/M, вывода $1.50/M, что составляет лишь 1/8 от стоимости Gemini 3 Pro. Идеально подходит для частых и масштабных вызовов.
- Полнофункциональность: контекстное окно 1M токенов + 5 типов входных данных + Thinking Mode + Function Calling — самая комплексная конфигурация среди легковесных моделей.
- Гены Pro-уровня: основана на архитектуре Gemini 3 Pro, демонстрирует выдающиеся результаты в бенчмарках, таких как GPQA Diamond (86.9%).
Для сценариев, требующих масштабируемости, низкой стоимости и высокой скорости работы с ИИ, Gemini 3.1 Flash-Lite Preview — одна из самых перспективных легковесных моделей на данный момент.
Рекомендуем быстро протестировать интеграцию через APIYI apiyi.com. Цены на платформе соответствуют официальным ценам Google, при пополнении от 100 долларов дарим 10 долларов, минимальная скидка — 20%. Единая точка доступа к 400+ большим языковым моделям.
📚 Ссылки и материалы
-
Официальная документация Google AI по модели: Полные технические характеристики Gemini 3.1 Flash-Lite Preview.
- Ссылка:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - Описание: Официальная документация API, содержит актуальные параметры и список функций.
- Ссылка:
-
Модельная карта Google DeepMind: Данные бенчмарков и оценка безопасности.
- Ссылка:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - Описание: Официальная модельная карта, содержит подробные результаты тестов и информацию о тренировке.
- Ссылка:
-
Оценка Artificial Analysis: Независимый анализ производительности и стоимости от третьей стороны.
- Ссылка:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - Описание: Включает независимые данные по скорости вывода, TTFT, индексу интеллекта и др.
- Ссылка:
-
Официальный блог Google: Анонс выпуска Gemini 3.1 Flash-Lite.
- Ссылка:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - Описание: Официальная статья о выпуске, описывающая позиционирование продукта и ключевые особенности.
- Ссылка:
Автор: Техническая команда APIYI
Технические обсуждения: Добро пожаловать в комментарии. Больше материалов доступно в документации APIYI docs.apiyi.com.