作者注:Gemini 3.1 Flash-Lite Preview 以 380 tok/s 輸出速度和 $0.25/M 超低成本上線,本文深度解析其 5 大核心優勢、基準測試數據、競品對比與 API 接入方法
Google DeepMind 在 2026 年 3 月 3 日正式發佈了 Gemini 3.1 Flash-Lite Preview——這是 Gemini 3 系列中速度最快、成本最低的模型。基於 Gemini 3 Pro 架構,輸出速度達到約 380 tokens/s,比 Gemini 2.5 Flash 首 Token 響應快 2.5 倍,輸出速度提升 45%。
核心價值: 本文將從性能基準、成本對比、功能特性、適用場景和 API 接入 5 個維度,幫你全面瞭解這個新上線的輕量級模型,判斷是否適合你的業務場景。

Gemini 3.1 Flash-Lite Preview 核心參數速覽
以下是從 Google AI 官方文檔和 DeepMind 模型卡提取的核心技術參數:
| 參數項 | Gemini 3.1 Flash-Lite Preview | 說明 |
|---|---|---|
| 模型 ID | gemini-3.1-flash-lite-preview |
API 調用時使用此 ID |
| 架構基礎 | Gemini 3 Pro | 繼承 Pro 級多模態架構 |
| 上下文窗口 | 1,048,576 tokens (1M) | 約 1,500 頁 A4 文檔 |
| 最大輸出 | 65,536 tokens (64K) | 支持長文本生成 |
| 輸出速度 | ~380 tokens/s | 在 132 個模型中排名第 2 |
| 輸入價格 | $0.25 / 百萬 tokens | Gemini 3 系列最低 |
| 輸出價格 | $1.50 / 百萬 tokens | Pro 版的 1/8 |
| 知識截止 | 2025 年 1 月 | 與 Gemini 3 Pro 一致 |
| 狀態 | Preview | 預覽版,正式版待發布 |
值得注意的是,Gemini 3.1 Flash-Lite Preview 基於 Gemini 3 Pro 架構構建,這意味着它在「縮小版」的體量下保留了 Pro 級別的多模態理解能力。Google 將其定位爲「高頻、輕量級任務」的首選模型。
🎯 接入建議: Gemini 3.1 Flash-Lite Preview 已在 API易 apiyi.com 上線,價格與 Google 官方一致。充值 100 美金起送 10 美金,最低可享八折優惠,一站式使用 400+ 大模型。
Gemini 3.1 Flash-Lite Preview 5 大核心優勢
優勢 1: 極速推理——380 tok/s 輸出速度
Gemini 3.1 Flash-Lite Preview 的輸出速度達到約 380 tokens/s,根據 Artificial Analysis 的評測數據,在 132 個主流模型中排名第 2。相比前代 Gemini 2.5 Flash 的 249 tok/s,性能提升約 45%。
首 Token 響應時間 (TTFT) 方面更是亮眼——比 Gemini 2.5 Flash 快 2.5 倍。對於需要即時反饋的應用場景(如聊天機器人、實時翻譯),這個提升意義重大。
優勢 2: 極低成本——輸入僅 $0.25/M tokens
在 Gemini 3 系列中,Flash-Lite 的價格僅爲 Pro 版本的 1/8。具體而言:
| 模型 | 輸入價格 | 輸出價格 | 混合費率 (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0.25/M | $1.50/M | $0.56/M |
| Gemini 3 Pro | $2.00/M | $12.00/M | $4.50/M |
| Claude 4.5 Haiku | $1.00/M | $5.00/M | $2.00/M |
| GPT-5 mini | $0.15/M | $0.60/M | $0.26/M |
Flash-Lite 在價格和性能之間取得了出色的平衡——雖然不是絕對最便宜的,但考慮到其 380 tok/s 的輸出速度和 1M 上下文窗口,性價比極高。
優勢 3: 百萬級上下文窗口
1,048,576 tokens 的上下文窗口意味着你可以在單次請求中處理:
- 約 1,500 頁 A4 文檔
- 完整的代碼倉庫
- 長達數小時的音頻/視頻內容
這在輕量模型中是非常罕見的配置。相比之下,GPT-5 mini 僅支持 128K,Claude 4.5 Haiku 支持 200K。
優勢 4: 全模態輸入支持
儘管定位爲輕量模型,Gemini 3.1 Flash-Lite Preview 支持 5 種輸入模態:
- 文本: 核心能力
- 圖像: 圖片內容分析和理解
- 音頻: 語音轉錄和分析
- 視頻: 視頻內容理解
- PDF: 文檔解析和摘要
輸出方面僅支持文本,但對於大多數數據處理和分析任務來說,這已經足夠。
優勢 5: Thinking Mode 支持
作爲輕量模型,Gemini 3.1 Flash-Lite Preview 竟然支持 Thinking Mode(擴展思考模式),這在同級模型中幾乎是獨一無二的。啓用後模型會進行逐步推理,在科學知識、數學計算等任務上顯著提升準確率。
🎯 平臺推薦: 想快速測試 Gemini 3.1 Flash-Lite Preview 的 Thinking Mode 表現?通過 API易 apiyi.com 可直接調用,支持 400+ 主流大模型的統一接口。
Gemini 3.1 Flash-Lite Preview 基準測試數據
以下是來自 Google DeepMind 模型卡和 Artificial Analysis 的評測數據:

Gemini 3.1 Flash-Lite Preview 基準測試解讀
從數據來看,Flash-Lite 在輕量模型中的表現相當亮眼:
- GPQA Diamond 86.9%: 科學知識推理能力在同級模型中領先
- Video-MMMU 84.8%: 視頻理解能力是其多模態優勢的體現
- MMMU-Pro 76.8%: 多模態推理表現優秀
- Arena Elo 1432: 在 Arena.ai 排行榜上獲得高分,證明實際使用體驗好
- 智能指數 34/100: 遠超同級模型平均水平 19,在 132 個模型中排名第 19
在 11 項基準測試中,Flash-Lite 有 6 項取得了同級別最佳成績,這對於一個輕量級模型來說是非常出色的表現。
🎯 實測建議: 基準測試數據僅供參考,實際效果因場景而異。建議通過 API易 apiyi.com 進行真實場景測試,平臺提供免費額度,支持快速對比多個模型。
Gemini 3.1 Flash-Lite Preview 與競品對比
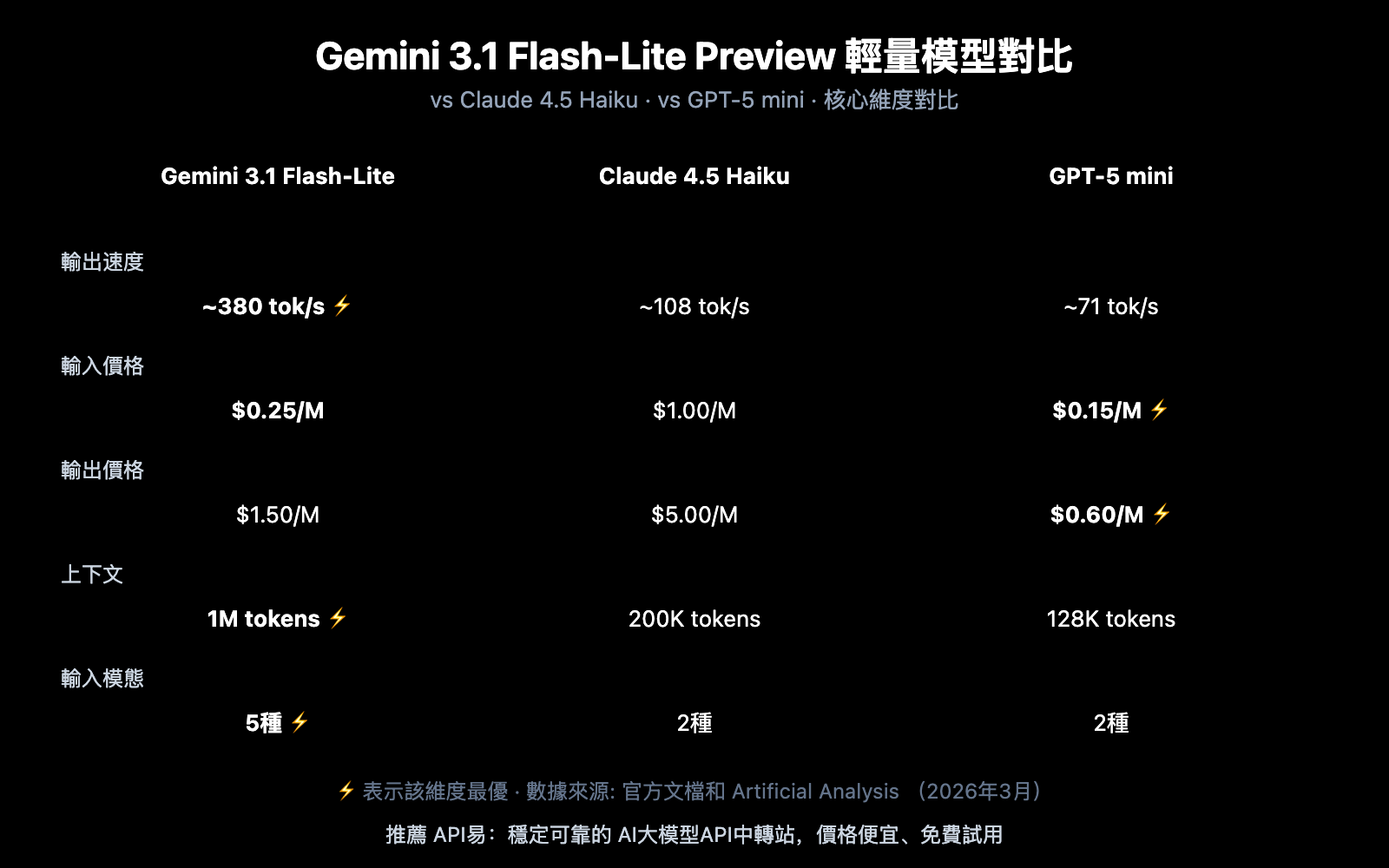
| 對比維度 | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| 輸出速度 | ~380 tok/s ⚡ | ~108 tok/s | ~71 tok/s |
| 輸入價格 | $0.25/M | $1.00/M | $0.15/M ⚡ |
| 輸出價格 | $1.50/M | $5.00/M | $0.60/M ⚡ |
| 上下文窗口 | 1M tokens ⚡ | 200K tokens | 128K tokens |
| 多模態輸入 | 5 種 ⚡ | 2 種 | 2 種 |
| Thinking Mode | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| Batch API | ✅ | ✅ | ✅ |
對比總結:
- 速度優先: Flash-Lite 的 380 tok/s 是 Haiku 的 3.5 倍、GPT-5 mini 的 5.4 倍
- 成本優先: GPT-5 mini 的絕對價格更低,但 Flash-Lite 在速度上的優勢可以彌補成本差距
- 功能優先: Flash-Lite 在上下文長度(1M)和多模態支持(5 種)上明顯領先
🎯 選擇建議: 選擇哪個輕量模型取決於具體場景。我們建議通過 API易 apiyi.com 進行實際對比測試,平臺支持以上所有模型的統一接口調用,便於快速切換和評估。
Gemini 3.1 Flash-Lite Preview 快速上手
極簡示例
以下是通過 API易平臺調用 Gemini 3.1 Flash-Lite Preview 的最簡代碼,10 行即可運行:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "用一句話解釋量子計算"}]
)
print(response.choices[0].message.content)
查看完整實現代碼(含 Thinking Mode)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
調用 Gemini 3.1 Flash-Lite Preview
Args:
prompt: 用戶輸入
system_prompt: 系統提示詞
max_tokens: 最大輸出token數
enable_thinking: 是否啓用 Thinking Mode
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例
result = call_flash_lite(
prompt="分析以下代碼的時間複雜度並給出優化建議",
system_prompt="你是一個高級算法工程師"
)
print(result)
建議: 通過 API易 apiyi.com 獲取 API Key 和免費測試額度,快速驗證 Gemini 3.1 Flash-Lite Preview 在你的場景下的表現。充值 100 美金起送 10 美金,最低可享八折優惠。
Gemini 3.1 Flash-Lite Preview 適用場景
推薦使用場景
| 場景 | 說明 | 爲什麼選 Flash-Lite |
|---|---|---|
| 大規模翻譯 | 多語言內容翻譯工作流 | 380 tok/s 極速輸出 + 低成本 |
| 內容審覈 | 用戶生成內容分類過濾 | 高頻調用 + 成本可控 |
| 數據提取 | 結構化數據抽取和整理 | 支持 JSON Schema 輸出 |
| Agent 路由 | 作爲路由層分發請求 | 超低延遲 + Function Calling |
| 文檔處理 | PDF/長文檔解析摘要 | 1M 上下文 + 多模態輸入 |
| 音頻轉錄 | 語音轉文字和分析 | 原生音頻輸入支持 |
不推薦的場景
- 複雜創意寫作: Pro 級模型在深度創作上更有優勢
- 圖像/音頻生成: Flash-Lite 僅支持文本輸出
- 實時流式對話: 不支持 Live API
- 需要最高推理準確性: 對於要求極致準確度的場景,建議使用 Gemini 3.1 Pro
🎯 場景建議: 不確定哪個模型最適合你的場景?通過 API易 apiyi.com 可以快速在 Gemini 3.1 Flash-Lite、Claude Haiku、GPT-5 mini 之間切換對比,找到最優方案。
常見問題
Q1: Gemini 3.1 Flash-Lite Preview 與 Gemini 2.5 Flash 有什麼區別?
核心區別在於架構和性能: Flash-Lite 基於 Gemini 3 Pro 架構(而非 Gemini 2 架構),首 Token 響應快 2.5 倍,輸出速度提升 45% 達到 ~380 tok/s。同時新增了 Thinking Mode、代碼執行等高級功能。
Q2: Preview 版本穩定性如何?適合生產環境使用嗎?
Preview 版本功能和性能可能在正式版中有調整。建議在非關鍵業務中先行測試,關鍵業務可設置降級方案。通過 API易 apiyi.com 調用時,可以方便地在模型之間切換,實現靈活的降級策略。
Q3: 如何快速開始測試 Gemini 3.1 Flash-Lite Preview?
推薦通過支持多模型的 API 聚合平臺進行測試:
- 訪問 API易 apiyi.com 註冊賬號
- 獲取 API Key 和免費額度
- 使用本文的代碼示例,將 model 設爲
gemini-3.1-flash-lite-preview即可 - 充值 100 美金起送 10 美金,最低可享八折優惠
總結
Gemini 3.1 Flash-Lite Preview 的核心要點:
- 極速性能: ~380 tok/s 輸出速度,132 個模型中排名第 2,首 Token 響應比 2.5 Flash 快 2.5 倍
- 高性價比: 輸入 $0.25/M、輸出 $1.50/M,僅爲 Gemini 3 Pro 的 1/8,適合高頻大規模調用
- 功能全面: 1M 上下文 + 5 種輸入模態 + Thinking Mode + Function Calling,輕量模型中配置最全面
- Pro 級基因: 基於 Gemini 3 Pro 架構,在 GPQA Diamond(86.9%)等基準測試中表現出色
對於需要大規模、低成本、高速度的 AI 應用場景,Gemini 3.1 Flash-Lite Preview 是當前最值得關注的輕量模型之一。
推薦通過 API易 apiyi.com 快速接入測試,平臺價格與 Google 官方一致,充值 100 美金起送 10 美金,最低可享八折優惠,一站式使用 400+ 大模型。
📚 參考資料
-
Google AI 官方模型文檔: Gemini 3.1 Flash-Lite Preview 完整技術規格
- 鏈接:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - 說明: 官方 API 文檔,包含最新參數和功能列表
- 鏈接:
-
Google DeepMind 模型卡: 基準測試數據和安全評估
- 鏈接:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - 說明: 官方模型卡,包含詳細基準測試成績和訓練信息
- 鏈接:
-
Artificial Analysis 評測: 獨立第三方性能和價格分析
- 鏈接:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - 說明: 包含輸出速度、TTFT、智能指數等獨立評測數據
- 鏈接:
-
Google 官方博客: Gemini 3.1 Flash-Lite 發佈公告
- 鏈接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - 說明: 官方發佈文章,介紹產品定位和核心特性
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區討論,更多資料可訪問 API易 docs.apiyi.com 文檔中心